Implementación de un almacén de datos dimensional con Databricks SQL: Parte 1
Definición de los objetos de datos
por Bryan Smith, Lorenz Verzosa, Krishna Satyavarapu, Peyman Mohajerian y Jesse Heravi
- Implementa almacenes de datos dimensionales en Databricks SQL para optimizar el rendimiento de las consultas rápidas.
- La estructura del modelo físico en Databricks SQL, incluida la creación de tablas de dimensiones y hechos, se realiza con sentencias SQL CREATE TABLE.
- Es importante agregar comentarios descriptivos a las tablas y columnas para una mejor gestión de metadatos.
Cada vez más organizaciones están migrando sus cargas de trabajo de data warehouse a Databricks. La naturaleza elástica de la plataforma y las mejoras significativas en su motor de ejecución de consultas han permitido a Databricks establecer récords mundiales tanto en rendimiento de consultas de data warehouse como en rendimiento de costos, lo que la convierte en una opción cada vez más atractiva para la consolidación de la infraestructura de análisis.
Para apoyar estos esfuerzos, hemos publicado anteriormente sobre cómo Databricks soporta varios enfoques de diseño de data warehouse. En esta serie de blogs, queremos examinar más de cerca uno de los enfoques más populares para el data warehousing, el modelado dimensional, un patrón de diseño caracterizado por esquemas de estrella y de copo de nieve, y profundizar en los patrones estandarizados de extracción, transformación y carga (ETL) ampliamente adoptados en apoyo de este enfoque.
Para hacer esto ampliamente accesible a la comunidad de modelado dimensional, nos adheriremos estrictamente a los patrones clásicos asociados con este enfoque de modelado. Esta información se distribuirá en las siguientes publicaciones de blog:
- Parte 1: Definición de los Objetos de Datos (Dimensionales) (esta publicación)
- Parte 2: Creación de los Flujos de Trabajo ETL de Dimensiones
- Parte 3: Creación de los Flujos de Trabajo ETL de Hechos
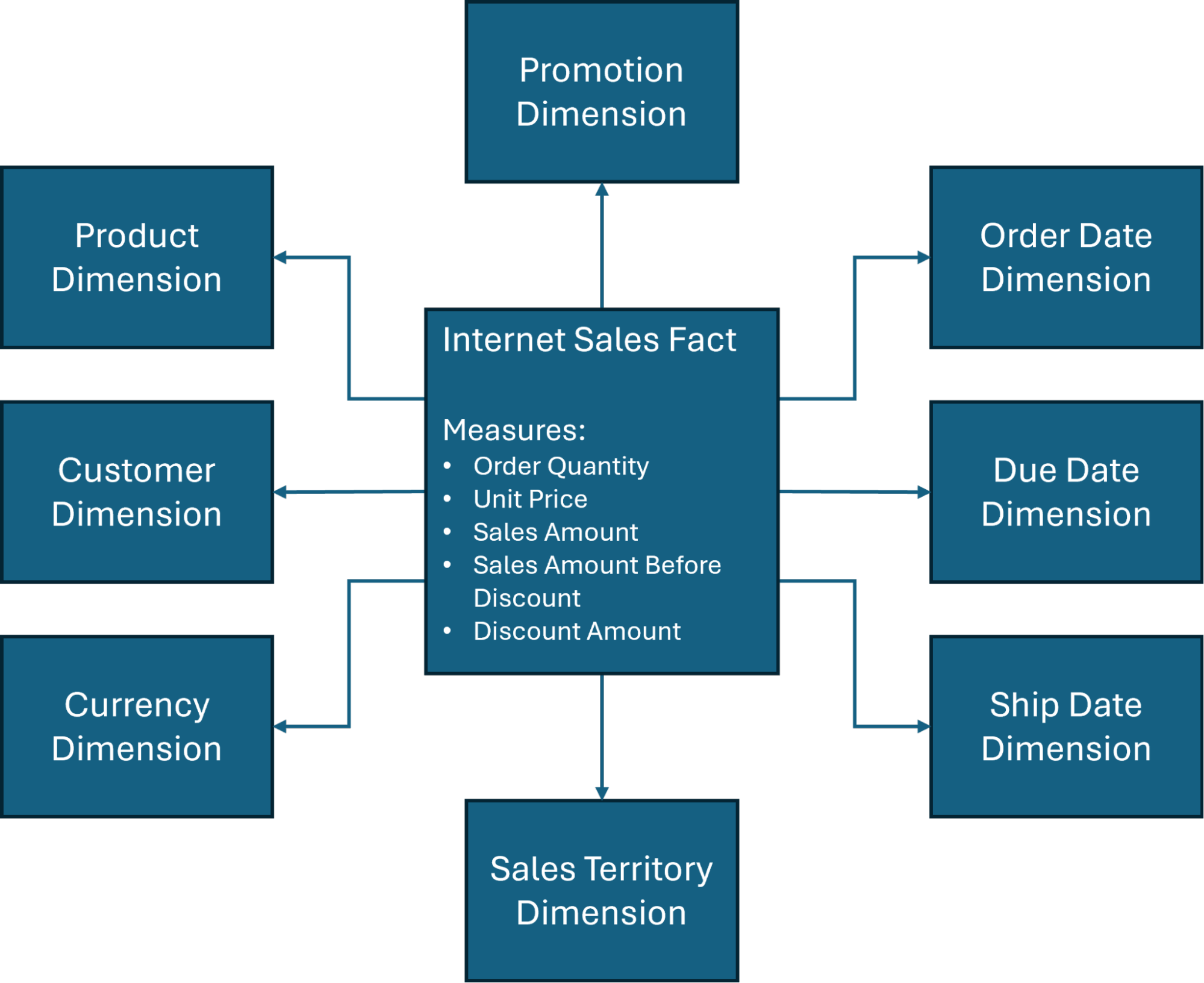
Además, centraremos nuestras discusiones de diseño en uno de los esquemas de estrella más comúnmente utilizados (Figura 1) en la base de datos AdventureWorksDW, una base de datos de ejemplo creada por Microsoft y ampliamente utilizada para fines de capacitación en data warehousing y Business Intelligence.
¿Qué es el modelado dimensional en data warehousing?
El modelado dimensional optimiza el almacenamiento de datos para un rendimiento de consulta rápido. Al estructurar los datos en hechos y dimensiones, puedes analizar fácilmente los datos desde múltiples perspectivas. También te permite explorar datos desde varios ángulos simultáneamente (análisis multidimensional).
¿Cuáles son las cuatro dimensiones de un data warehouse?
Como indica la Figura 1, hay varias dimensiones involucradas en el esquema de estrella del data warehousing, pero las cuatro dimensiones principales del data warehousing suelen incluir las siguientes:
Tiempo: Esto proporciona un marco de seguimiento histórico y es esencial para evaluar tendencias o realizar comparaciones. Puedes categorizar los datos según intervalos de tiempo específicos (días, semanas, años) para optimizar los cambios estacionales del negocio o la gestión de inventario.
Cliente: Las organizaciones necesitan información precisa sobre quién compra sus productos. Información como el nombre, la información de contacto y la demografía pueden ofrecer una segmentación de mercado útil y determinar decisiones como el gasto en publicidad o las estrategias generales de marketing.
Producto: Esta dimensión define qué bienes o servicios se están analizando, y puede ser útil para realizar un análisis de rendimiento para determinar cuánto se está vendiendo, la tasa de ventas y cualquier oportunidad de crecimiento futuro.
Ubicación: Contextualizar dónde ocurrieron los eventos, ya sea geográfica u operativamente, puede ayudar a las organizaciones a tomar decisiones críticas basadas en dónde es probable que residan sus clientes.
El modelo físico
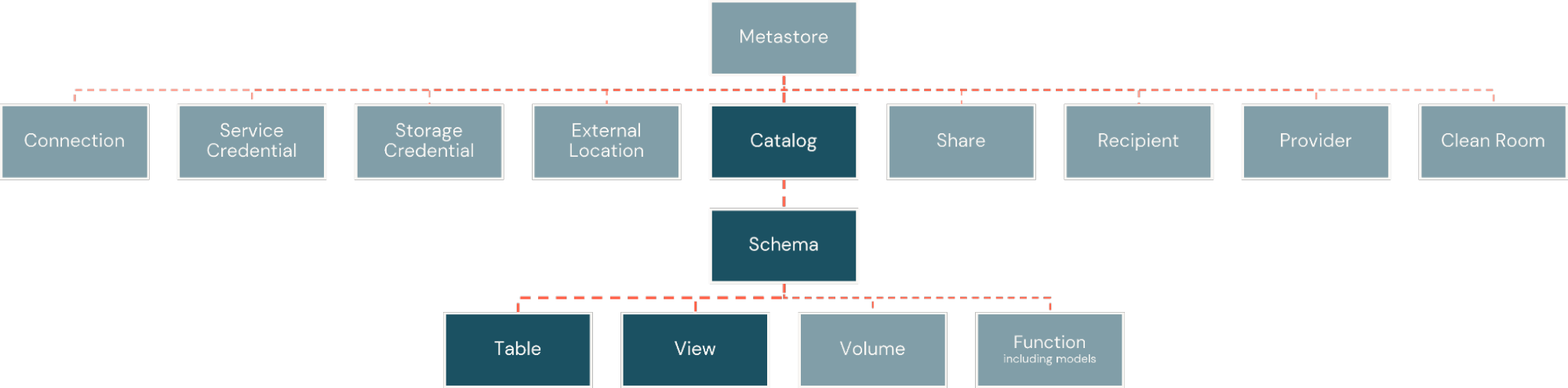
Dentro de la Plataforma Databricks, los hechos y las dimensiones se implementan como tablas físicas. Estas se organizan dentro de catálogos, similares a las bases de datos, pero con mayor flexibilidad para la amplitud de los activos de información que la plataforma soporta. Los catálogos se subdividen luego en esquemas, creando límites lógicos y de seguridad alrededor de subconjuntos de objetos en el catálogo (Figura 2).
Tablas de dimensión
Las tablas de dimensión se adhieren a un conjunto de patrones estructurales relativamente rígido. Se define típicamente un identificador secuencial, una clave sustituta, para soportar un enlace estable y eficiente entre las tablas de hechos y la dimensión. Los identificadores únicos de los sistemas operativos (a menudo referidos como claves naturales o claves de negocio), junto con una colección denormalizada de atributos de negocio relacionados, suelen seguir. Detrás de los identificadores suele haber una serie de columnas de metadatos destinadas a soportar los procesos ETL en curso. Dentro de la Plataforma Databricks, podemos implementar una tabla de dimensión utilizando la sentencia CREATE TABLE, como se muestra aquí para la dimensión del cliente:
Columnas de identidad
En este ejemplo, para la columna de clave sustituta, CustomerKey, utilizamos una columna de identidad que crea automáticamente un valor BIGINT secuencial para el campo al insertar filas. Si usamos la opción ALWAYS o BY DEFAULT con la columna de identidad depende de si queremos prohibir o permitir la inserción de nuestros propios valores para este campo.
Entrada de miembro faltante
Un patrón común implementado con tablas de dimensión es la creación de una entrada de miembro faltante. Esta entrada se utiliza en escenarios donde los registros de hechos llegan con un enlace faltante o desconocido a una dimensión y se puede crear con un valor de clave sustituta predeterminado, como se muestra aquí cuando se emplea la opción BY DEFAULT:
Campos de identidad
Como buena práctica, al insertar valores en un campo de identidad, es mejor asegurarse de que los metadatos del campo de identidad se actualicen mediante una instrucción ALTER TABLE con la opción SYNC IDENTITY empleada:
Tipos de datos
Para la clave de negocio/natural y otros campos vinculados a datos en sistemas de origen, necesitaremos alinear los tipos de datos del sistema de origen con los tipos de datos compatibles con la Plataforma Databricks (Tabla 1). Para los campos de metadatos donde se emplea un valor de bit, como 0 o 1, tenga en cuenta que a menudo usamos un tipo de dato INT en lugar de los tipos de datos BOOLEAN o TINYINT para facilitar un poco el manejo de literales.
|
BIGINT |
DECIMAL |
INTERVAL |
TIMESTAMP |
MAP |
|
BINARY |
DOUBLE |
VOID |
TIMESTAMP_NTZ |
STRUCT |
|
BOOLEAN |
FLOAT |
SMALLINT |
TINYINT |
VARIANT |
|
DATE |
INT |
STRING |
ARRAY |
OBJECT |
Tabla 1. Los tipos de datos compatibles con la Plataforma Databricks
Tablas de hechos
Las tablas de hechos también siguen sus convenciones estructurales. Compuestas principalmente por medidas y referencias de claves externas a dimensiones relacionadas, las tablas de hechos también pueden incluir identificadores únicos para registros transaccionales (u otros atributos descriptivos en una relación casi uno a uno con los registros de hechos), denominados dimensiones degeneradas. También pueden incluir campos de metadatos para admitir la carga incremental (también conocido como delta extract) de datos de sistemas de origen. Dentro de la Plataforma Databricks, podríamos implementar una tabla de hechos utilizando la instrucción CREATE TABLE similar a lo que se muestra aquí para el hecho de ventas por Internet:
Claves foráneas
Como se mencionó en la sección anterior sobre tablas de dimensiones, los tipos de datos en el entorno de Databricks se mapean de forma flexible a los utilizados por los sistemas de origen. Las referencias de clave foránea entre las tablas de hechos y las de dimensiones también se pueden hacer explícitas utilizando la instrucción ALTER TABLE como se muestra aquí:
Nota: Si prefiere definir las restricciones de clave foránea como parte de la instrucción CREATE TABLE, simplemente puede agregar una lista separada por comas de cláusulas FOREIGN KEY (con el formato FOREIGN KEY (foreign_key) REFERENCES table_name (primary_key) justo después de la lista de definiciones de columnas.
Metadatos y otras consideraciones
El atractivo del modelo dimensional es su relativa accesibilidad para los analistas de negocios. Teniendo esto en cuenta, muchas organizaciones adoptan convenciones de nomenclatura para hechos y dimensiones, como los prefijos Fact y Dim en los ejemplos anteriores, y fomentan el uso de nombres largos y autoexplicativos para tablas y campos que a menudo se desvían significativamente de los nombres utilizados en los sistemas de origen operativos.
Teniendo esto en cuenta, es importante tener en cuenta las limitaciones de Databricks en la nomenclatura de objetos. Estas incluyen:
- Los nombres de objetos no pueden exceder los 255 caracteres
- Los siguientes caracteres especiales no están permitidos:
- Punto (.)
- Espacio ( )
- Barra inclinada (/)
- Todos los caracteres de control ASCII (00-1F hex)
- El carácter DELETE (7F hex)
Además, es importante tener en cuenta que los nombres de los objetos no distinguen entre mayúsculas y minúsculas y, de hecho, se almacenan en el repositorio de metadatos en minúsculas. Si esto pudiera crear problemas con la legibilidad de los objetos, podría considerar adoptar una convención de snake case para mejorar la legibilidad de algunos nombres de objetos.
Independientemente de sus convenciones de nomenclatura, es una buena idea definir comentarios descriptivos para todos los objetos y campos dentro del almacén de datos. Esto se hace mediante el uso de la instrucción COMMENT ON para objetos de tabla y la instrucción ALTER TABLE para campos individuales, como se demuestra aquí:
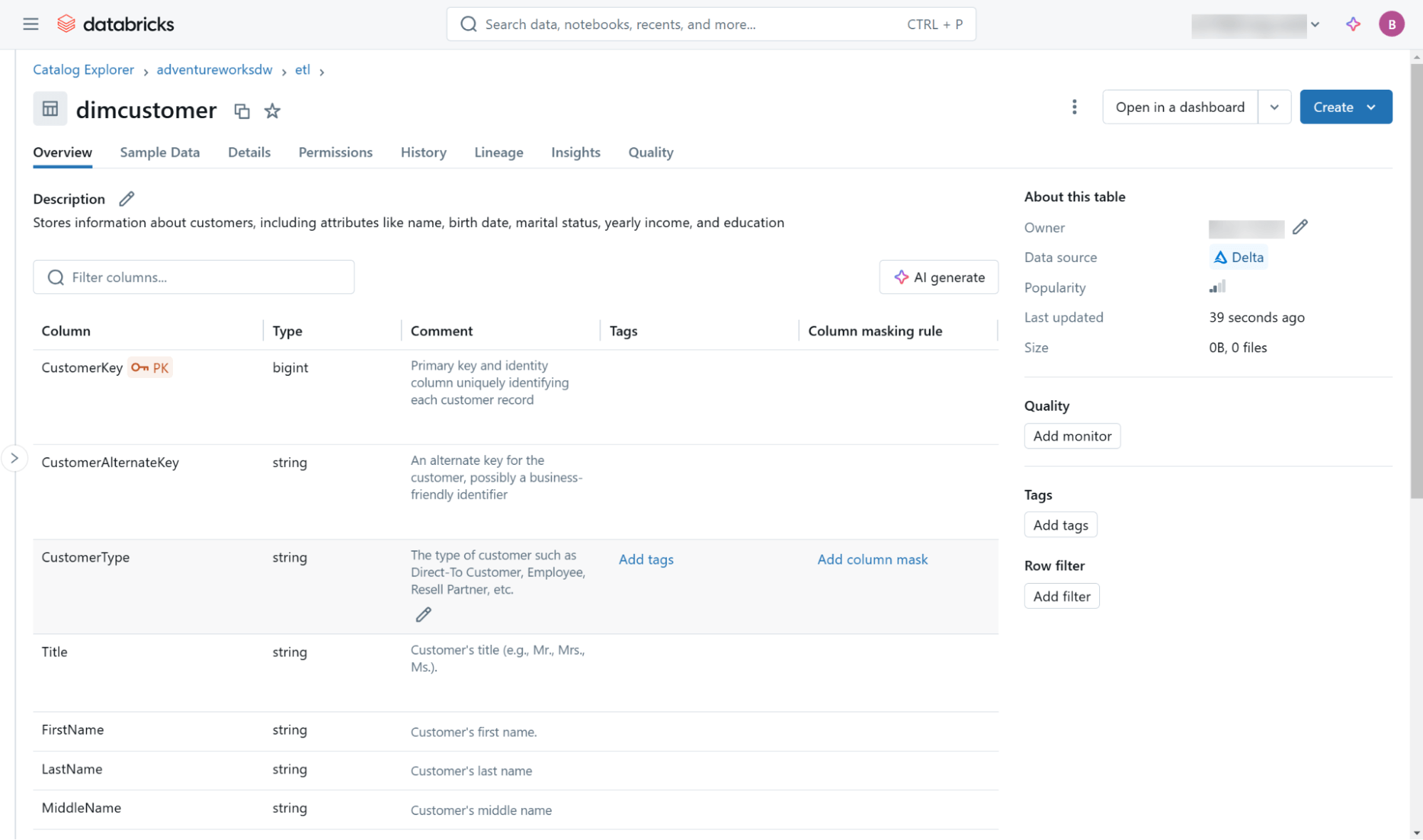
Estos y otros metadatos (incluida la información de linaje) son accesibles a través de la interfaz de usuario de Databricks Catalog Explorer (Figura 3) y a través de objetos en el esquema de información integrado que se encuentra dentro de cada catálogo.
Por último, este blog aborda la creación de tablas de hechos y dimensiones puramente desde la perspectiva de adherirse a los principios de diseño dimensional. Si desea explorar algunas opciones adicionales para la definición de tablas que consideren optimizaciones de rendimiento y mantenimiento, consulte este blog sobre la optimización del rendimiento del esquema de estrella.
Próximos pasos: implementación de ETL de tablas de dimensiones
Después de abordar los conceptos básicos de la creación de tablas de hechos y dimensiones, en el próximo artículo nos centraremos en la implementación de los patrones ETL que admiten las tablas de dimensiones, con especial énfasis en los patrones de dimensión de cambio lento (SCD) de Tipo 1 y Tipo 2 utilizando tanto Python como SQL. Finalmente, la Parte 3 cubrirá cómo se puede implementar el ETL para estas tablas.
Para obtener más información sobre Databricks SQL, visita nuestro sitio web o lee la documentación. También puedes consultar el recorrido del producto para Databricks SQL. Si deseas migrar tu almacén de datos existente a un almacén de datos sin servidor de alto rendimiento con una excelente experiencia de usuario y un menor costo total, Databricks SQL es la solución; pruébalo gratis.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.