Presentamos AI Runtime: GPUs NVIDIA escalables y sin servidor en Databricks para entrenamiento y ajuste fino
Entrena los últimos LLMs con GPUs NVIDIA H100 disponibles al instante conectadas a tu Lakehouse
por Tejas Sundaresan, Jianwei Xie, Bandish Shah y Hanlin Tang
- Con la AI Runtime, Databricks ahora admite GPUs NVIDIA en el Cómputo Serverless, lo que permite el acceso bajo demanda a NVIDIA A10 y H100 escalables sin sobrecarga de infraestructura.
- Entrena modelos de visión por computadora, LLMs, sistemas de recomendación basados en deep learning y otros modelos con nuestro runtime dedicado para entrenamiento distribuido, todo incluido.
- La AI Runtime está integrada con carga de datos de alta velocidad desde datos de Lakehouse, orquestación de flujos de trabajo con Lakeflow y gobernanza con Unity Catalog.
Las GPUs potencian las cargas de trabajo de IA más avanzadas de la actualidad, desde predicciones y recomendaciones hasta modelos fundacionales multimodales. Sin embargo, los equipos tienen dificultades para adquirir y gestionar la infraestructura de GPUs, configurar entornos de entrenamiento distribuidos y depurar cuellos de botella en la carga de datos. Los investigadores de aprendizaje profundo prefieren centrarse en el modelado, no en la resolución de problemas de infraestructura.
Nos complace anunciar la Vista Previa Pública de AI Runtime (AIR), una nueva pila de entrenamiento que permite el entrenamiento distribuido de GPUs bajo demanda en A10 y H100. AI Runtime contiene toda la tecnología utilizada para el entrenamiento a gran escala de LLMs como MPT y DBRX. Incluso en Beta, varios cientos de clientes, incluidos Rivian, Factset y YipitData, han utilizado AIR para entrenar y lanzar modelos de aprendizaje profundo en producción. Los casos de uso abarcan desde modelos de visión por computadora hasta sistemas de recomendación y LLMs ajustados para tareas de agentes. Nuestro propio equipo de Investigación de IA de Databricks utilizó AIR para el aprendizaje por refuerzo de modelos como en nuestro reciente artículo sobre KARL.
Con AI Runtime, los usuarios de Databricks ahora tienen:
- GPUs NVIDIA sin servidor y bajo demanda: Simplemente configure su notebook en 2-3 clics y obtenga una conexión rápida a GPUs A10 y H100 sin servidor para comenzar a entrenar, sin necesidad de clúster. Pague solo por las GPUs que utiliza, sin preocuparse por la utilización del tiempo inactivo.
- Herramientas de orquestación robustas: Utilice toda la potencia de la suite de orquestación de Databricks con Lakeflow Jobs y soporte DABs para cargas de trabajo de GPU de larga duración
- Entrenamiento distribuido optimizado: AIR incluye mejoras de rendimiento para entrenamiento distribuido de GPUs, como RDMA y carga de datos de alto rendimiento
- Gobernanza y observabilidad centralizadas: ejecute, observe y gobierne cargas de trabajo de GPUs exactamente donde residen sus datos, con gestión de experimentos integrada a través de MLflow, gestión de acceso con Unity Catalog y depuración asistida por agente
GPUs NVIDIA H100 y A10 bajo demanda en notebooks
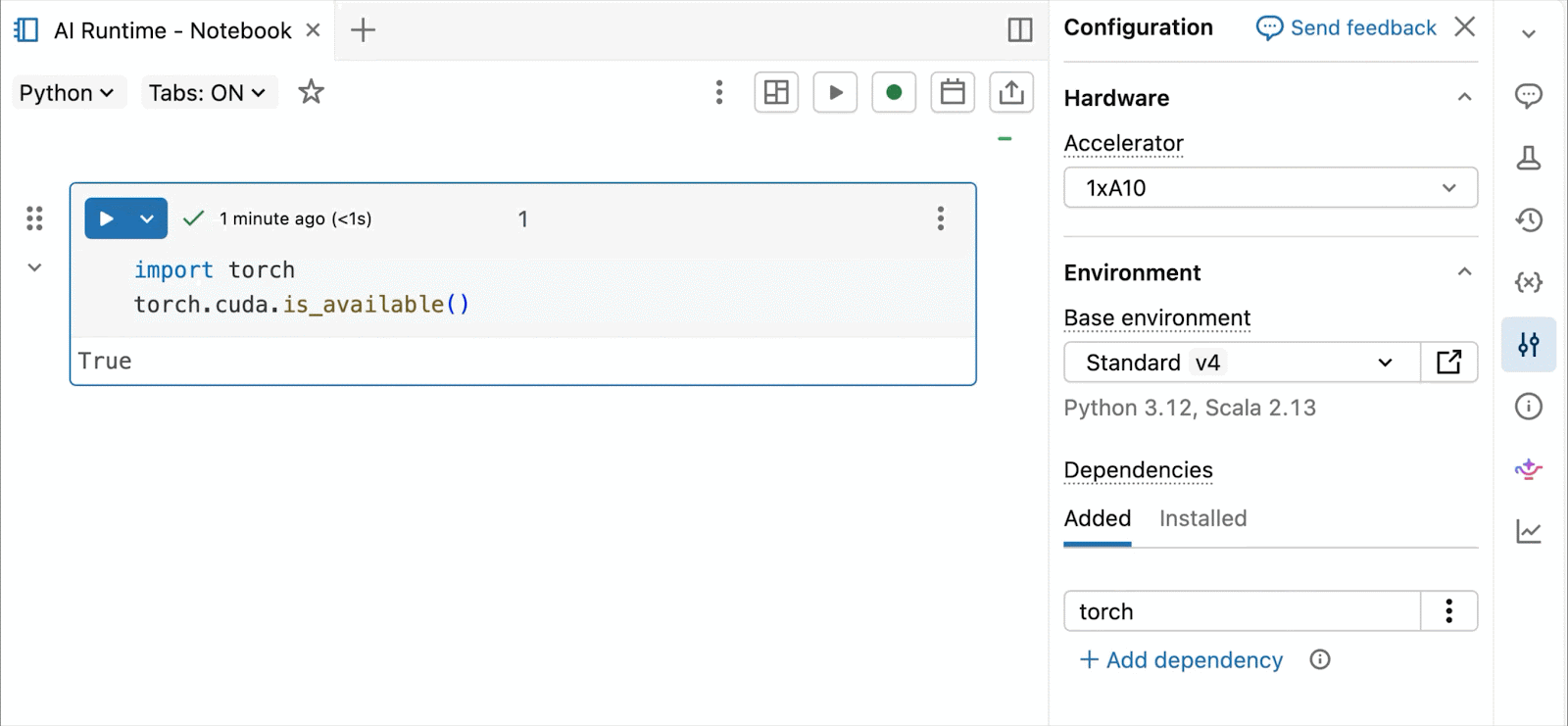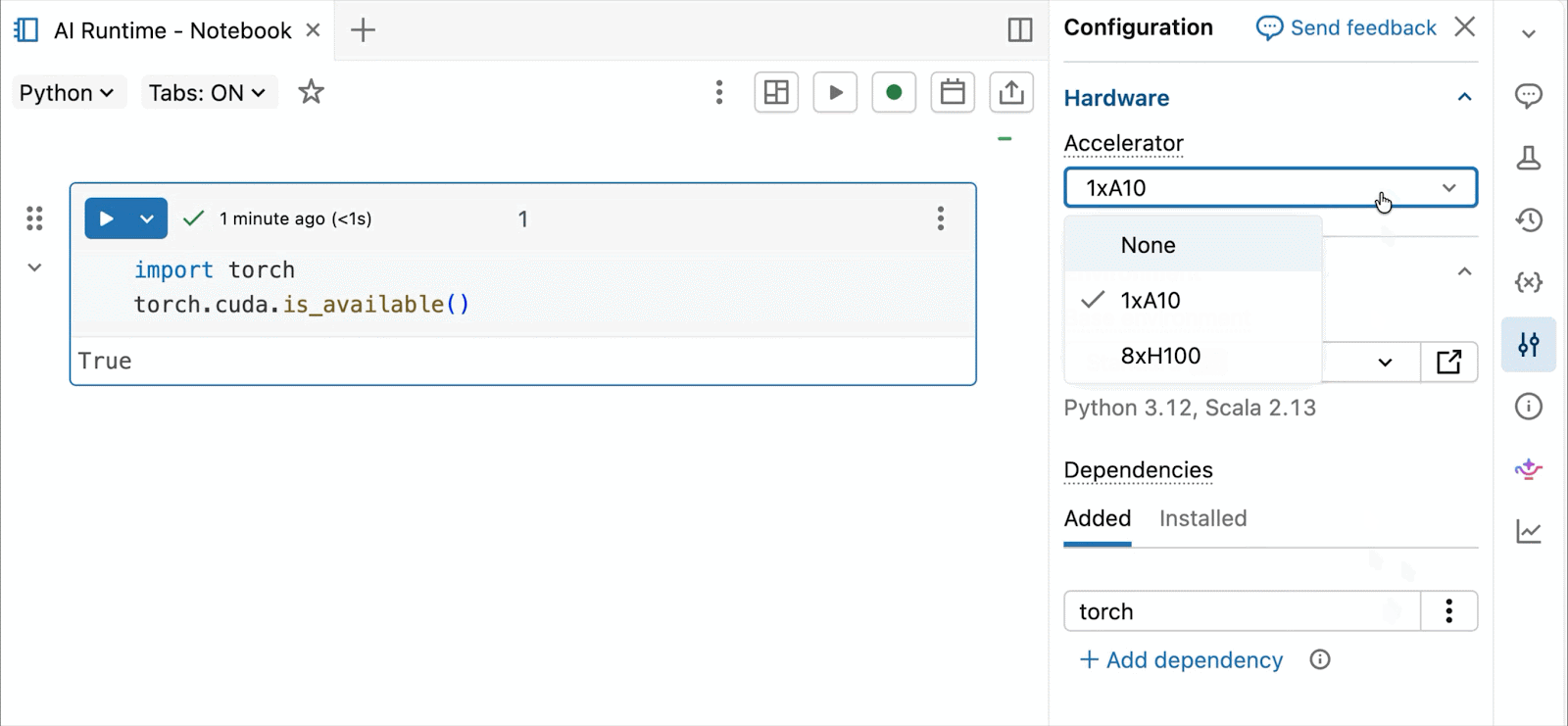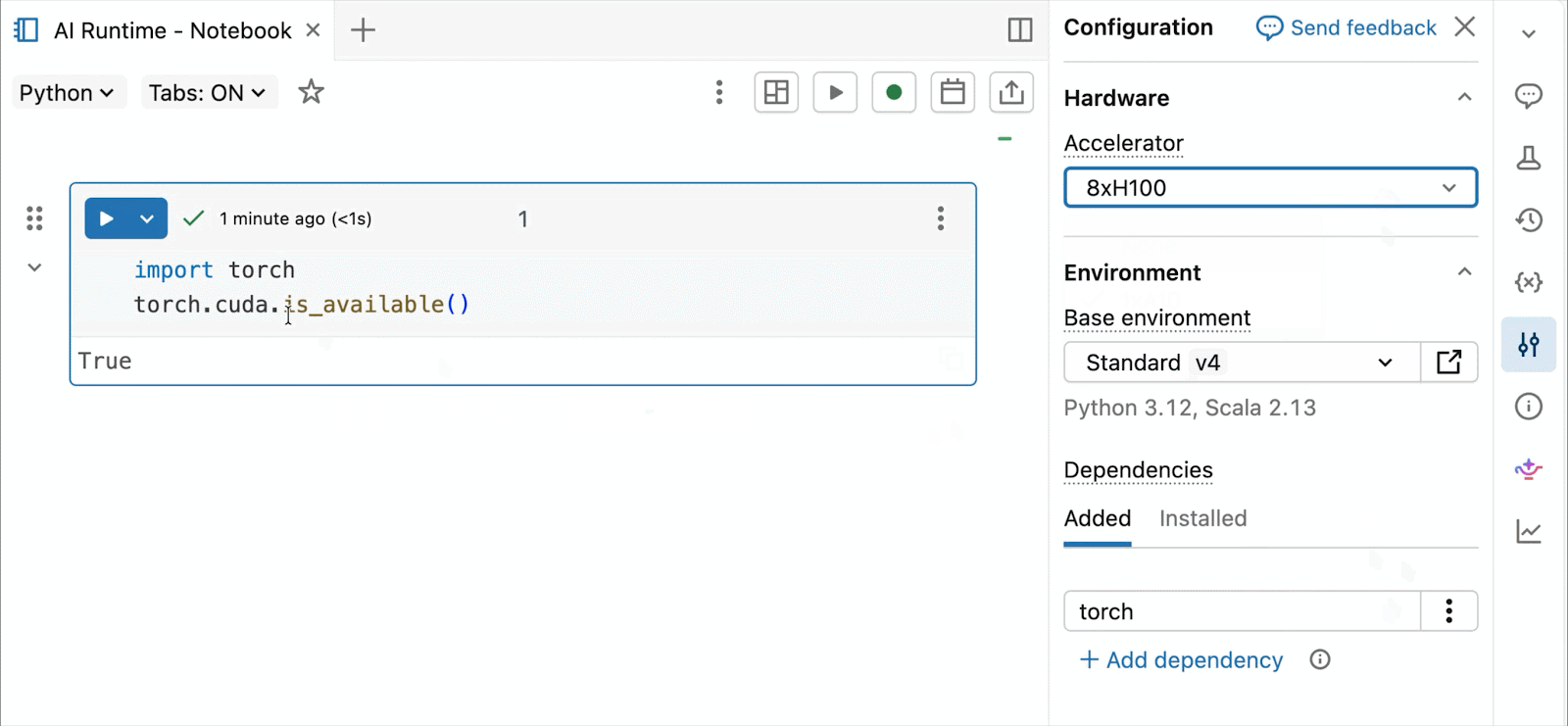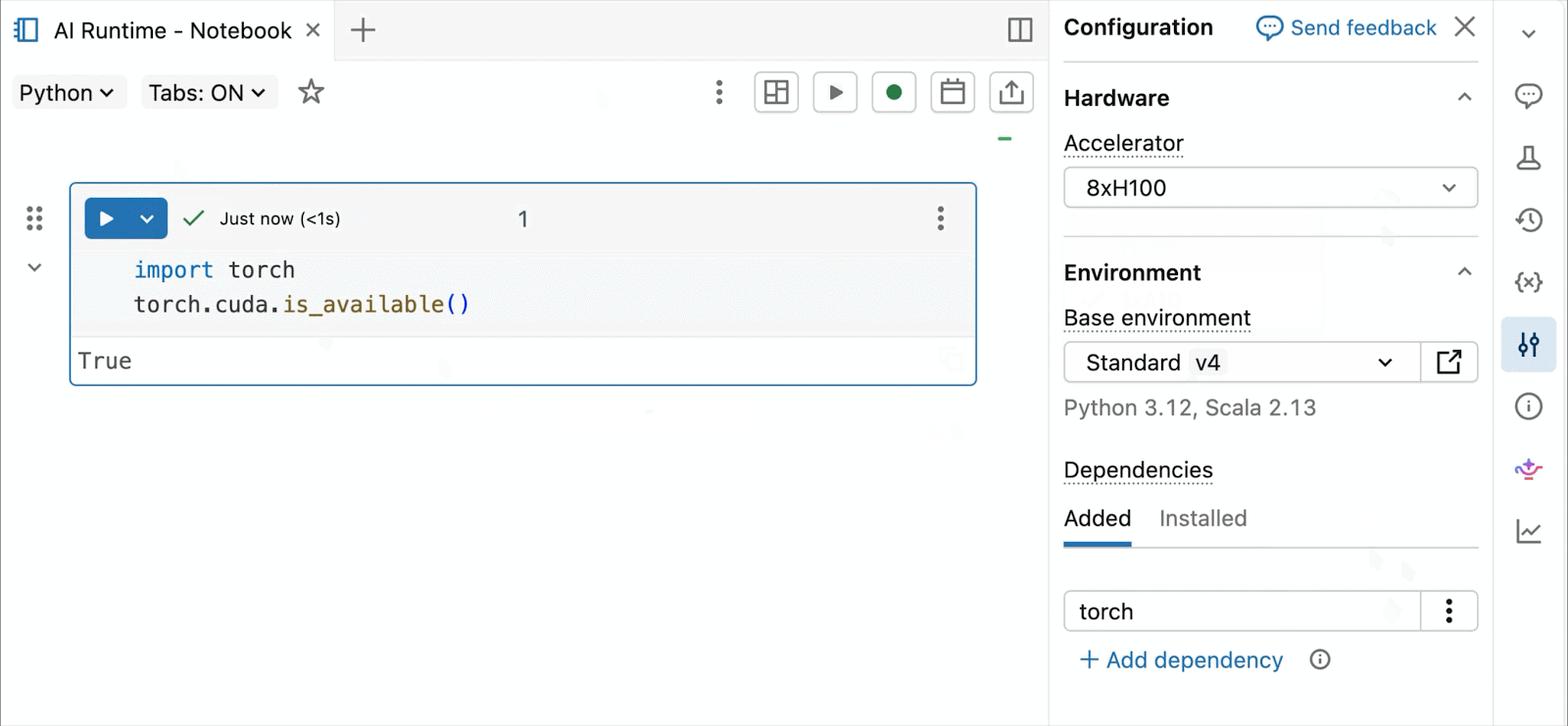
Para desarrollo interactivo y depuración, conéctese a A10 y H100 bajo demanda en Databricks Notebooks con solo unos pocos clics. Desde allí, aproveche toda la ergonomía del desarrollador por la que Databricks es conocida, desde la gestión de entornos para paquetes comunes de Python hasta la autoría y depuración asistida por agente con Genie Code. Monte fácilmente datos del Lakehouse para entrenar modelos de aprendizaje profundo, o incluso invoque una flota de CPUs remotas para cargas de trabajo de procesamiento de datos de Spark desde su notebook con GPU para preparar sus datos.
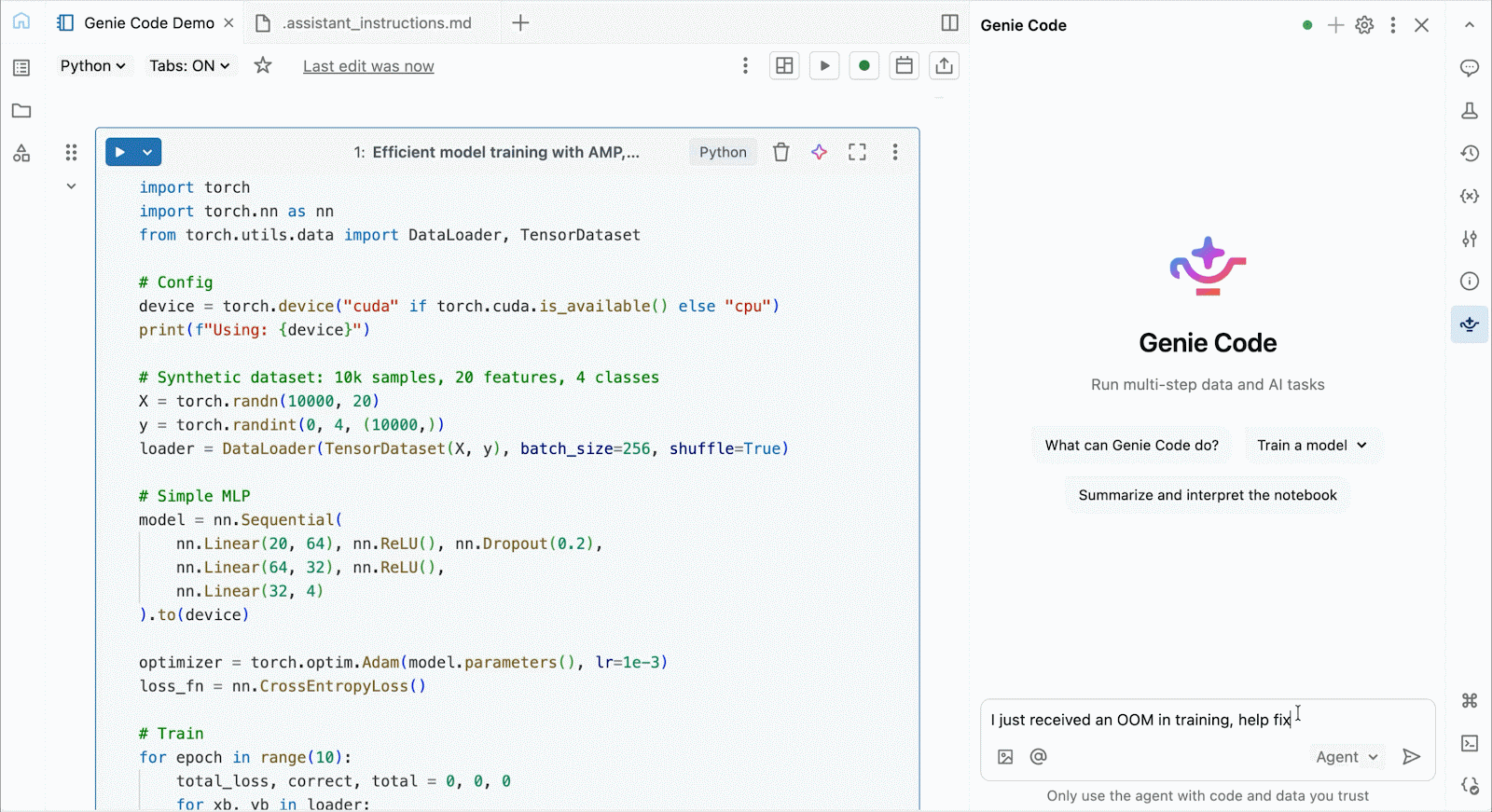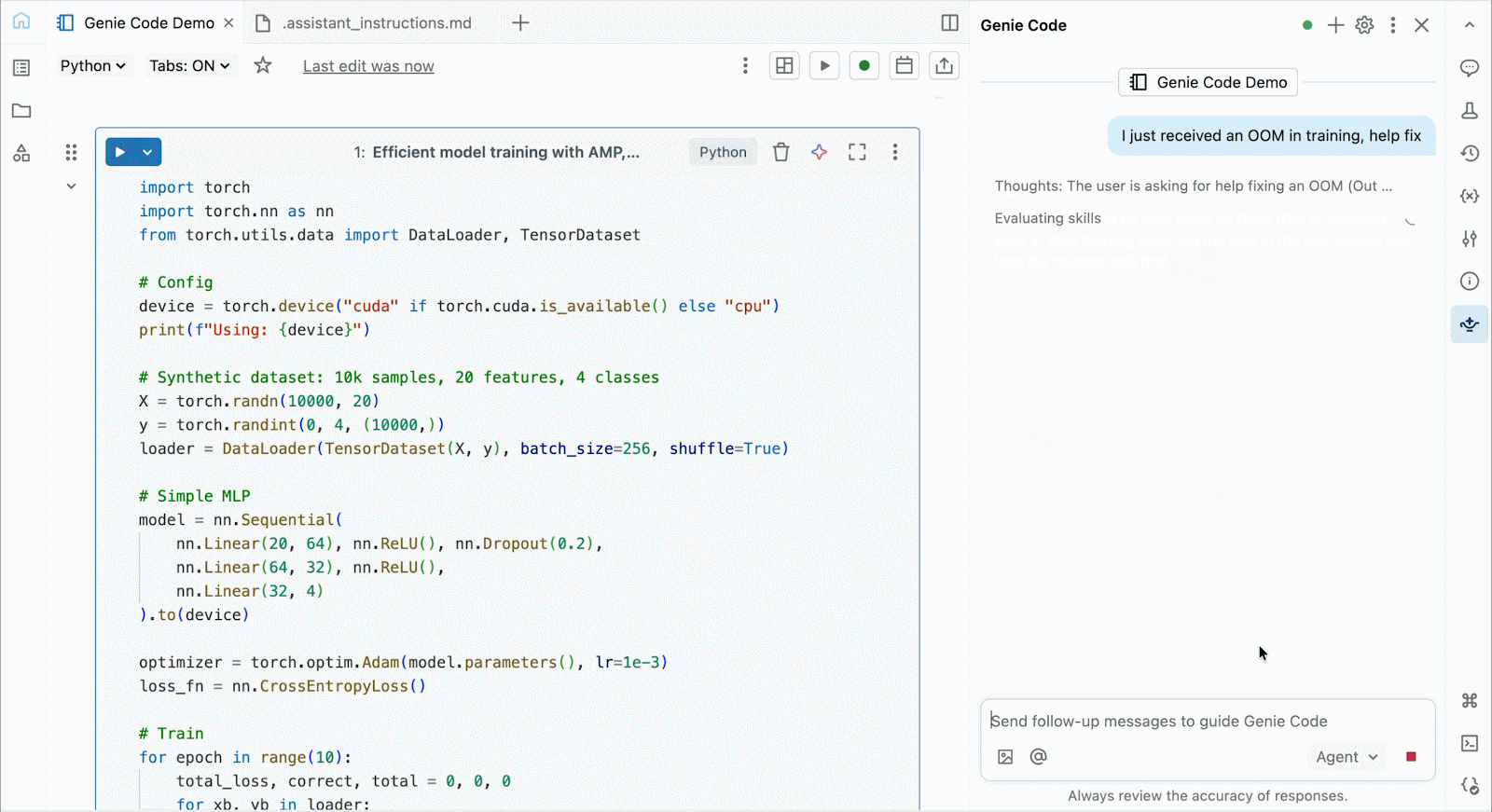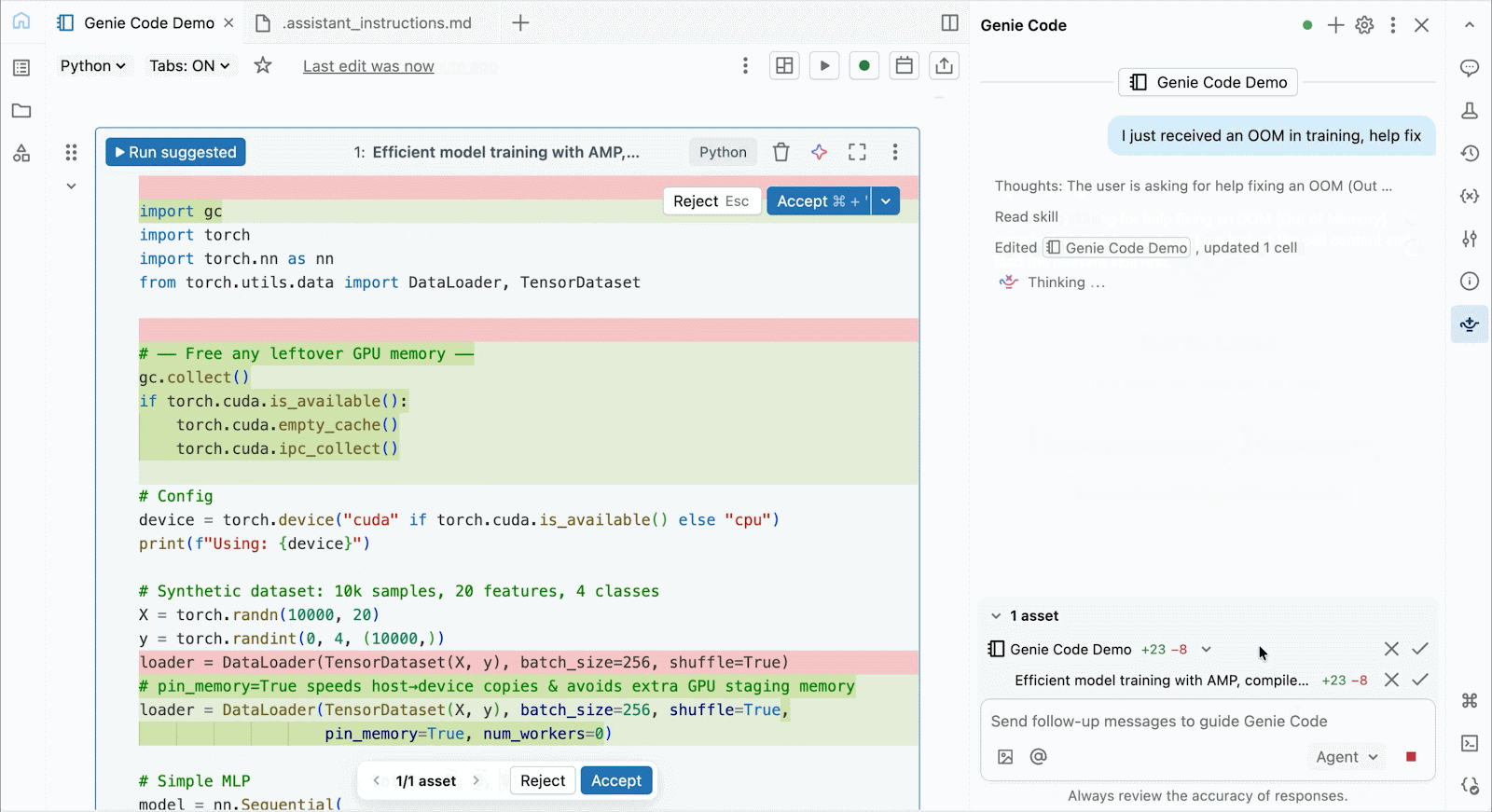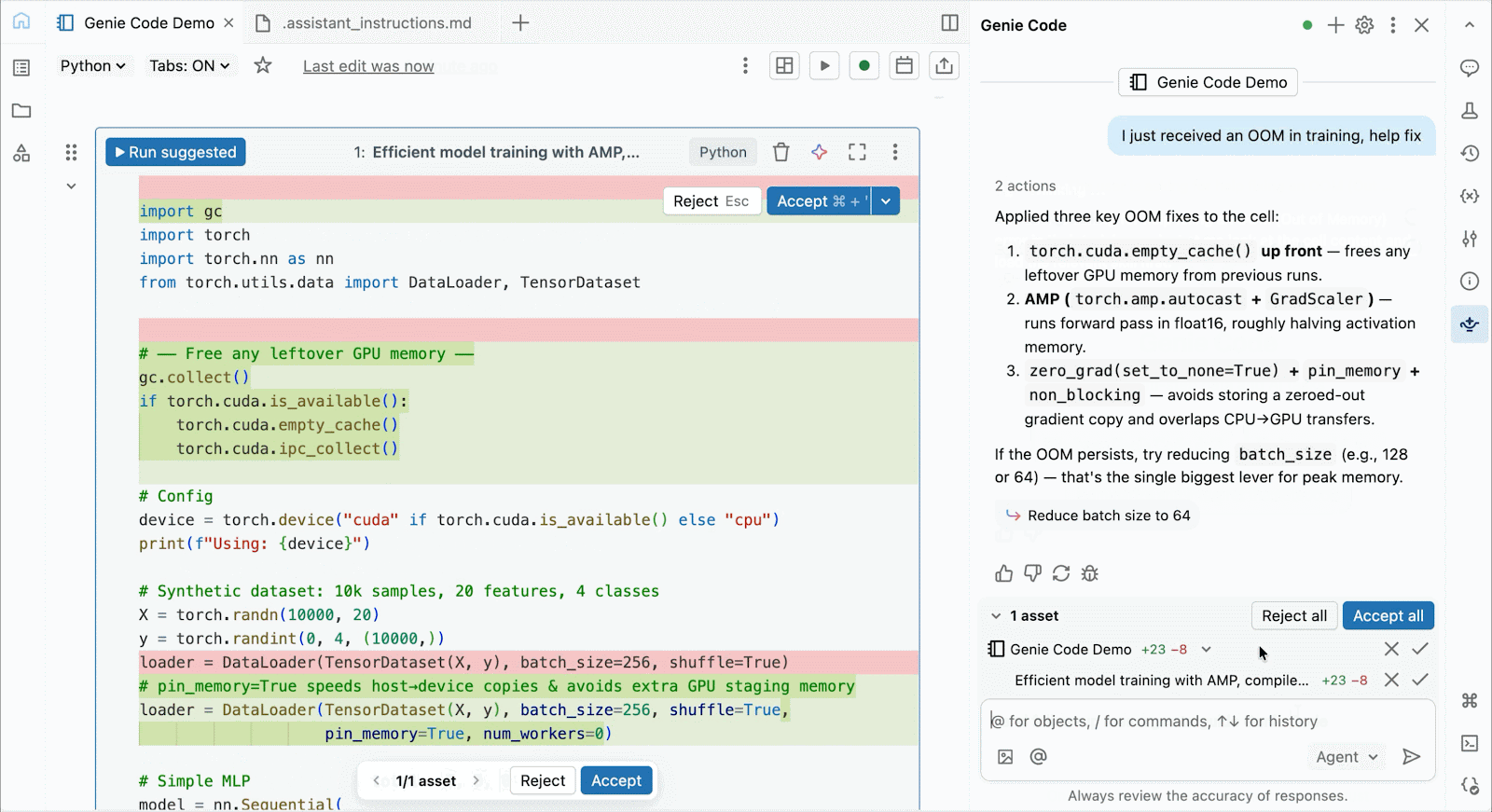
Use Genie Code para ayudar a resolver cuellos de botella de rendimiento, experimentar con nuevas arquitecturas o depurar errores complicados en torno a la convergencia del modelo o errores crípticos del framework.
Lakeflow para cargas de trabajo listas para producción
AI Runtime es una plataforma de grado de producción para computación acelerada. Desarrolle su código de aprendizaje profundo en notebooks interactivos y luego utilice toda la potencia de Lakeflow para enviar y orquestar trabajos en cómputo de GPU. Tanto los notebooks como los repositorios de código personalizado pueden ser ejecutados por Lakeflow para trabajos programados o de larga duración. Para necesidades de producción como CI/CD (integración continua y despliegue continuo), AI Runtime es totalmente compatible con nuestros Declarative Automation Bundles (DABs).
Con nuestra integración de Lakeflow, los clientes pueden mantener el entrenamiento y ajuste fino de modelos estrechamente sincronizados con los pipelines de datos upstream y los sistemas de producción downstream.
“El AI Runtime de Databricks simplificó enormemente el proceso de entrenamiento de un modelo personalizado de Texto a Fórmula (TTF). Sin configuración de infraestructura ni demoras, fue fácil elegir el cómputo adecuado según el tamaño del prompt y la generación de tokens de salida. Esto nos permitió avanzar rápidamente, mantener nuestros flujos de trabajo de Lakehouse y entregar un modelo de alta calidad con gobernanza completa, reduciendo el tiempo de configuración, entrenamiento y despliegue de nuestro modelo de días a horas.”—Nikhil Sunderraj, Ingeniero Principal de Machine Learning, FactSet Research Systems, Inc.
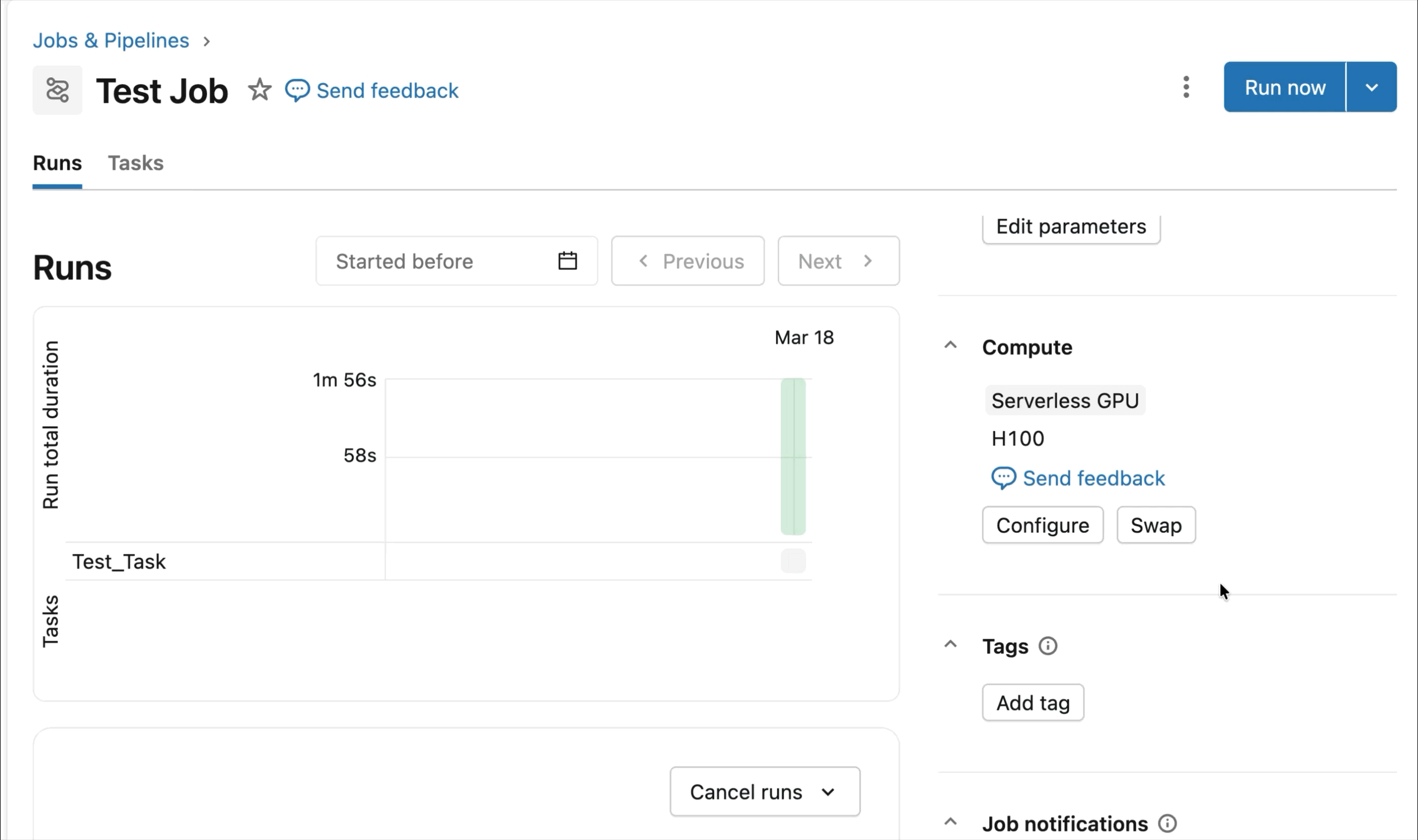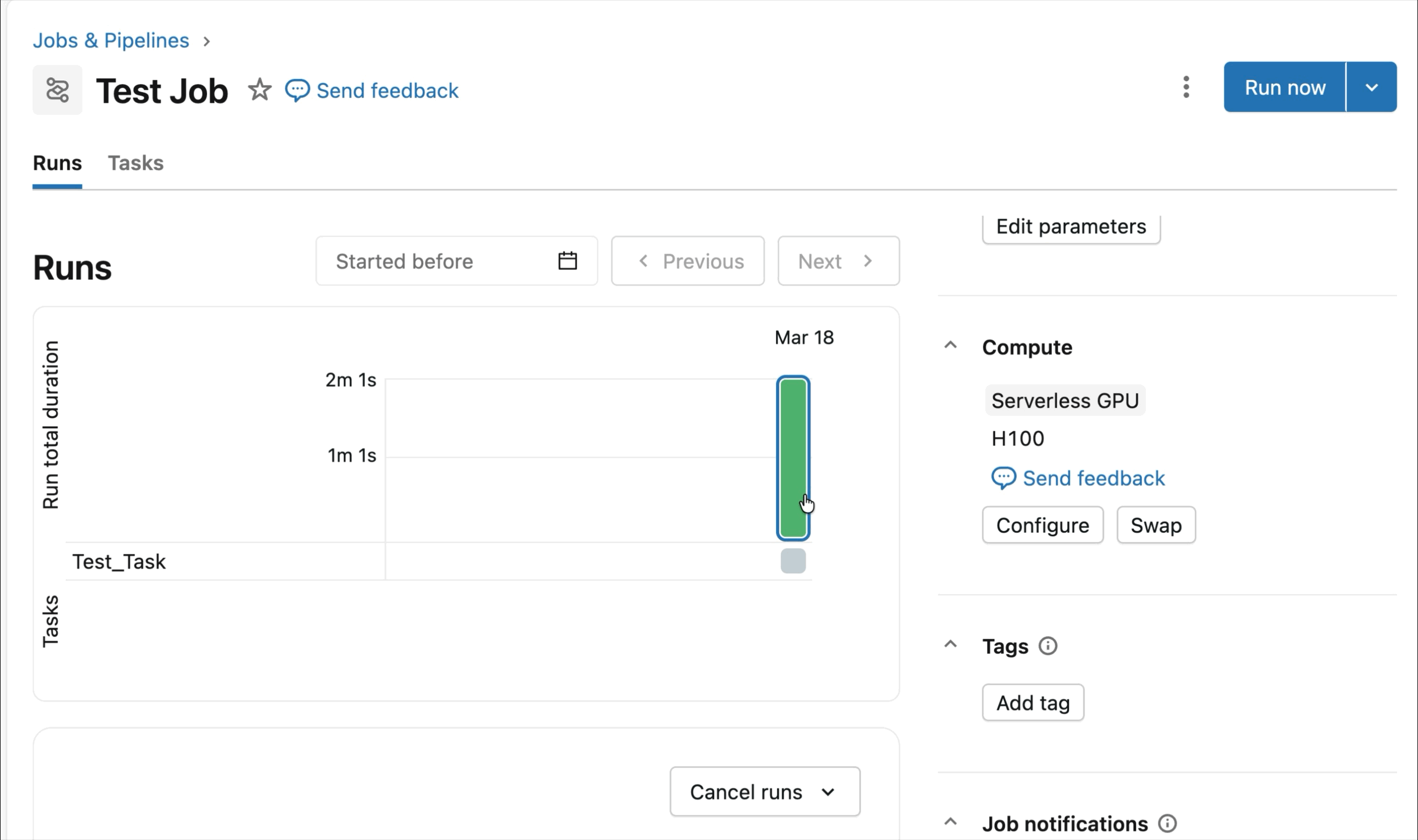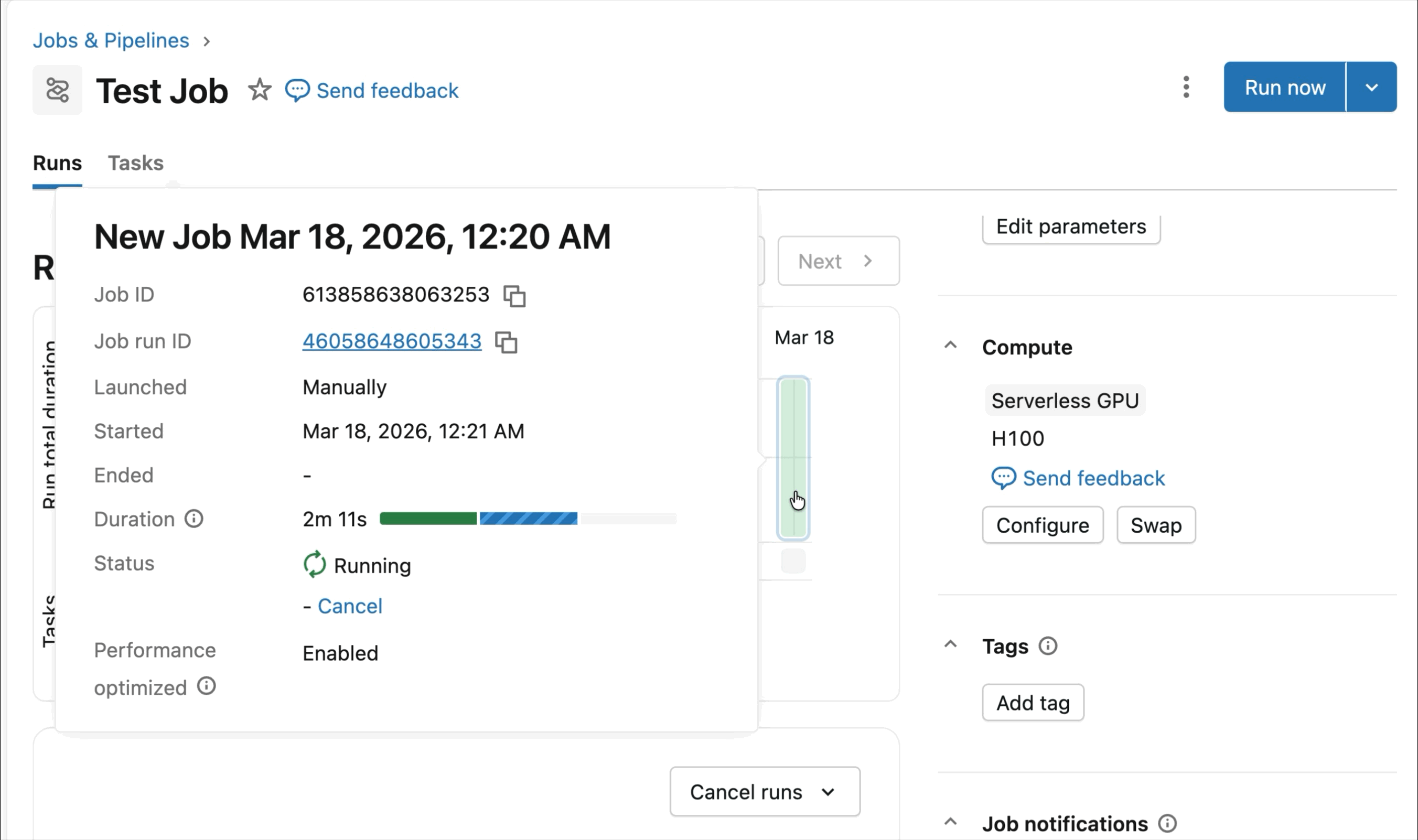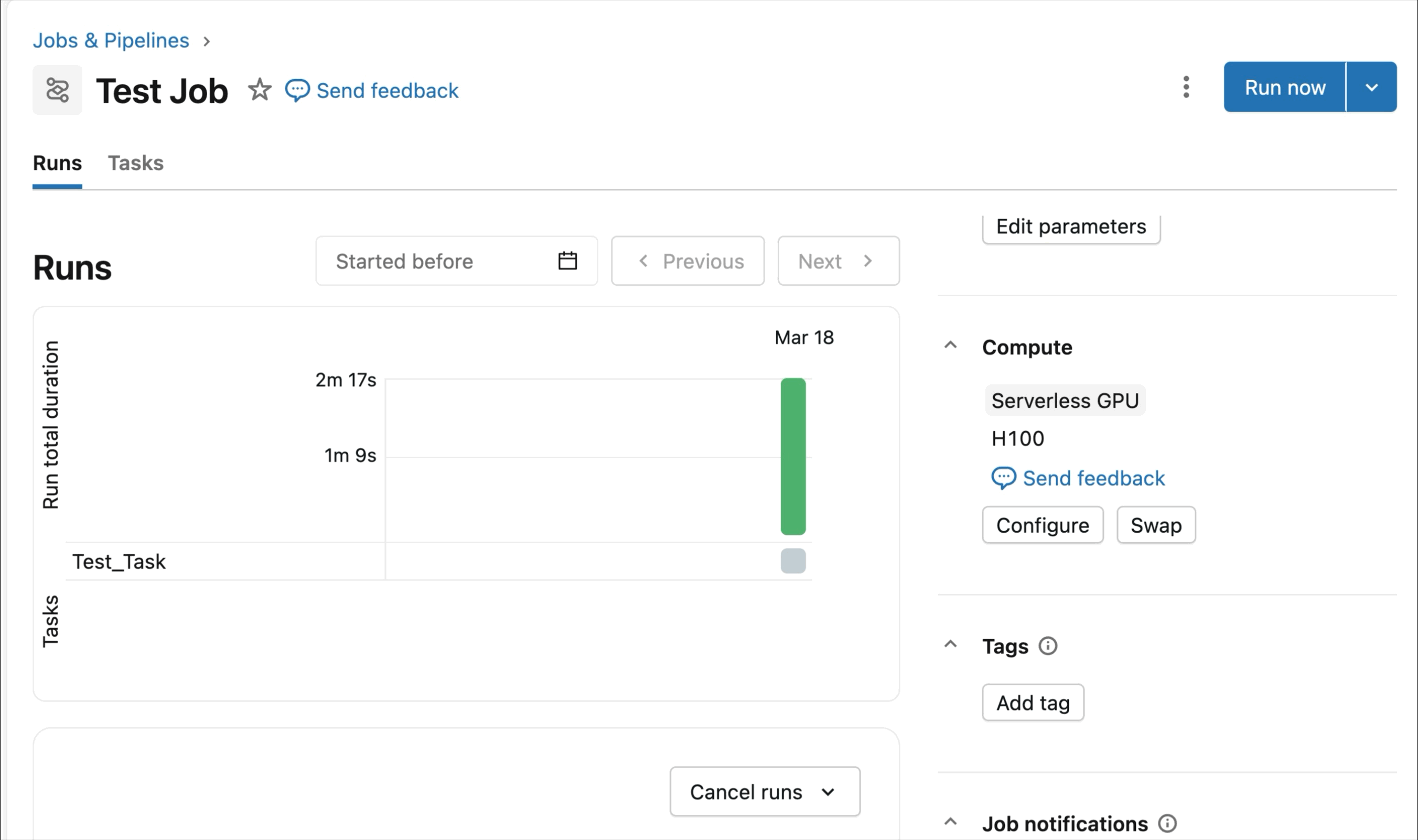
Runtime optimizado para aprendizaje profundo distribuido
Las cargas de trabajo de entrenamiento distribuido pueden ser difíciles de preparar, depurar y observar. Desde la resolución de problemas de configuración de RDMA hasta el seguimiento de telemetría de múltiples GPUs y la configuración adecuada del software, los usuarios pueden pasar por alto fácilmente detalles críticos que ralentizan drásticamente el entrenamiento del modelo.
En cambio, AI Runtime está optimizado para todo el ciclo de vida del aprendizaje profundo y está diseñado para ahorrarle tiempo. Dependencias clave como PyTorch y CUDA vienen preinstaladas, junto con soporte optimizado para frameworks de entrenamiento distribuido como Ray, Hugging Face Transformers, Composer y otras bibliotecas, para que pueda comenzar a entrenar de inmediato sin gestionar entornos. Los clientes también son bienvenidos a traer sus propias bibliotecas, desde Unsloth hasta TorchRec o bucles de entrenamiento personalizados.

Los SDKs integrados y las herramientas de observabilidad simplifican la gestión de cargas de trabajo de entrenamiento distribuido. MLFlow permite una profunda observabilidad de las cargas de trabajo de GPU, con seguimiento automático de la utilización de GPU y experimentos de entrenamiento. Ya sea que esté ajustando modelos fundacionales o entrenando modelos de pronóstico y personalización, el runtime está optimizado para acelerar los flujos de trabajo de entrenamiento con una configuración mínima.
La Vista Previa Pública actual de AI Runtime admite entrenamiento distribuido en 8x H100s en un solo nodo, con soporte multi-nodo actualmente en Vista Previa Privada.
"El AI Runtime de Databricks nos permite ejecutar eficientemente cargas de trabajo de LLM (ajuste fino e inferencia) sin sobrecarga de infraestructura, directamente en nuestro lakehouse. Esta integración perfecta simplifica nuestros pipelines y proporciona un uso eficiente de las GPUs, lo que nos permite ofrecer información de IA de alta calidad a nuestros clientes y centrarnos en la innovación, no en la infraestructura."—Lucas Froguel, Ingeniero Senior de Plataforma de IA, YipitData
Gobernanza y observabilidad de datos centralizadas
AI Runtime se integra de forma nativa con el Databricks Lakehouse, lo que le permite ejecutar y gobernar cargas de trabajo de GPU donde residen sus datos. Esto elimina los flujos de trabajo fragmentados y simplifica el camino desde la experimentación hasta la producción.
- Gobernanza centralizada con Unity Catalog: Aplique controles de acceso, linaje y políticas de gobernanza consistentes en cargas de trabajo de datos e IA, lo que permite un uso seguro y conforme de los recursos de GPU.
- Observabilidad unificada: Rastree y supervise todas las cargas de trabajo (CPU y GPU) en un solo lugar utilizando tablas de sistema nativas para auditoría unificada, seguimiento de uso y perspectivas operativas.
Sus cargas de trabajo de IA se ejecutan completamente dentro del perímetro de datos de su empresa, brindando una sólida gobernanza y seguridad sin sacrificar la flexibilidad para la experimentación y la escala.
"Aprovechar el soporte de GPU sin servidor de Databricks dentro de nuestro Lakehouse nos permite entrenar eficientemente modelos avanzados de audio y multimodales sin sobrecarga de infraestructura. Esta integración perfecta simplifica los flujos de trabajo y proporciona un uso eficiente de los recursos de GPU, asegurando que entreguemos sistemas de alto rendimiento y nos centremos en la innovación."—Arjuna Siva, VP de Infoentretenimiento y Conectividad, Rivian y Volkswagen Group Technologies
Integración de la Innovación de GPU de Próxima Generación de NVIDIA
La demanda de cómputo acelerado sigue creciendo en las cargas de trabajo de IA y los sistemas agénticos. AI Runtime permite a más clientes de Databricks aprovechar el hardware de NVIDIA para acelerar sus cargas de trabajo de IA e impulsar sus negocios. Estamos entusiasmados de continuar asociándonos con NVIDIA para llevar la última tecnología de NVIDIA, como el RTX PRO 4500 Blackwell Server Edition, anunciado en GTC 2026 a nuestros clientes.
"A medida que la adopción de la IA se acelera en todas las industrias, las organizaciones necesitan una infraestructura escalable y de alto rendimiento para potenciar sus cargas de trabajo de datos e IA. Las tecnologías de NVIDIA brindan un rendimiento acelerado a la oferta de AI Runtime para la Plataforma Databricks Lakehouse."—Pat Lee, Vicepresidente de Alianzas Estratégicas en NVIDIA.
Comienza hoy mismo con AI Runtime
Para ayudarte a empezar, hemos preparado varios cuadernos de plantillas y guías de inicio:
- Consulta nuestra documentación para obtener instrucciones detalladas sobre la configuración y el uso diario.
- Plantillas de inicio para entrenar sistemas de recomendación, modelos de ML clásicos, ajuste fino de LLMs y más.
- Guía de migración de cargas de trabajo de GPU de Cómputo Clásico a Serverless.
¡Ponte en contacto con tu equipo de cuentas para obtener más información o si tienes alguna pregunta!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.