Presentamos Apache Spark 4.0
Ahora disponible en Databricks Runtime 17.0
por Wenchen Fan, Serge Rielau, Herman van Hövell, Hyukjin Kwon, Allison Wang, Anish Shrigondekar, Daniel Tenedorio, Martin Grund, DB Tsai, Xiao Li y Reynold Xin
La Edición Gratuita ha reemplazado a la Edición Comunitaria, ofreciendo funciones mejoradas sin coste alguno. Empieza a usar la Edición Gratuita hoy mismo.
Apache Spark 4.0 marca un hito importante en la evolución del motor de análisis de Spark. Esta versión trae avances significativos en todos los ámbitos: desde mejoras en el lenguaje SQL y conectividad ampliada, hasta nuevas capacidades de Python, mejoras en streaming y mayor usabilidad. Spark 4.0 está diseñado para ser más potente, compatible con ANSI y fácil de usar que nunca, manteniendo al mismo tiempo la compatibilidad con las cargas de trabajo de Spark existentes. En esta publicación, explicamos las características y mejoras clave introducidas en Spark 4.0 y cómo elevan tu experiencia de procesamiento de big data.
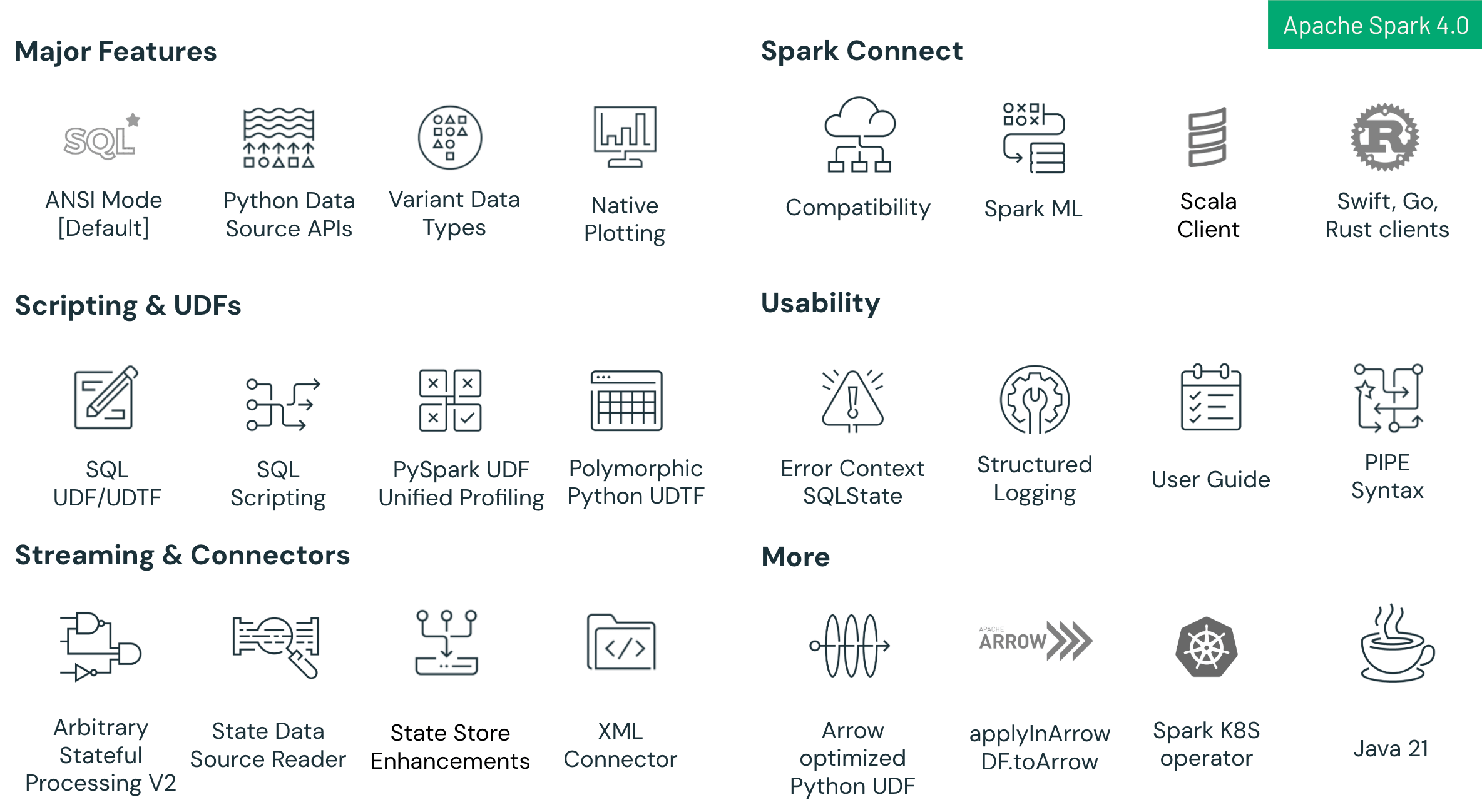
Aspectos destacados de Spark 4.0 incluyen:
- Mejoras en el Lenguaje SQL: Nuevas capacidades que incluyen scripting SQL con variables de sesión y flujo de control, Funciones Definidas por el Usuario (UDF) SQL reutilizables y una sintaxis PIPE intuitiva para optimizar y simplificar flujos de trabajo analíticos complejos.
- Mejoras en Spark Connect: Spark Connect —la nueva arquitectura cliente-servidor de Spark— ahora logra una alta paridad de funciones con Spark Clásico en Spark 4.0. Esta versión añade compatibilidad mejorada entre Python y Scala, soporte multilingüe (con nuevos clientes para Go, Swift y Rust), y una ruta de migración más sencilla a través de la nueva configuración spark.api.mode. Los desarrolladores pueden cambiar sin problemas de Spark Clásico a Spark Connect para beneficiarse de una arquitectura más modular, escalable y flexible.
- Mejoras de Fiabilidad y Productividad: El modo SQL ANSI habilitado por defecto garantiza una mayor integridad de los datos y una mejor interoperabilidad, complementado por el tipo de datos VARIANT para un manejo eficiente de datos JSON semiestructurados y el registro JSON estructurado para una mejor observabilidad y una solución de problemas más sencilla.
- Avances en la API de Python: Gráficos nativos basados en Plotly directamente en DataFrames de PySpark, una API de Origen de Datos de Python que permite conectores batch y de streaming personalizados en Python, y UDTF de Python polimórficas para soporte de esquemas dinámicos y mayor flexibilidad.
- Avances en Structured Streaming: Nueva API de Procesamiento de Estado Arbitrario llamada transformWithState en Scala, Java y Python para lógica personalizada de estado robusta y tolerante a fallos, mejoras en la usabilidad del almacén de estado y un nuevo Origen de Datos de Almacén de Estado para una mejor depuración y observabilidad.
En las secciones siguientes, compartimos más detalles sobre estas emocionantes funciones y, al final, proporcionamos enlaces a los esfuerzos de JIRA relevantes y publicaciones de blog detalladas para aquellos que quieran saber más. Spark 4.0 representa una plataforma robusta y preparada para el futuro para el procesamiento de datos a gran escala, combinando la familiaridad de Spark con nuevas capacidades que satisfacen las necesidades modernas de ingeniería de datos.
Principales Mejoras de Spark Connect
Una de las actualizaciones más emocionantes de Spark 4.0 es la mejora general de Spark Connect, en particular el cliente Scala. Con Spark 4, todas las funciones de Spark SQL ofrecen una compatibilidad casi completa entre Spark Connect y el modo de ejecución Clásico, quedando solo diferencias menores. Spark Connect es la nueva arquitectura cliente-servidor para Spark que desacopla la aplicación del usuario del clúster de Spark, y en 4.0, es más capaz que nunca:
- Compatibilidad Mejorada: Un logro importante para Spark Connect en Spark 4 es la compatibilidad mejorada de las API de Python y Scala, lo que hace que el cambio entre el uso de Spark Clásico y Spark Connect sea fluido. Esto significa que, para la mayoría de los casos de uso, todo lo que tienes que hacer es habilitar Spark Connect para tus aplicaciones estableciendo
spark.api.modeenconnect. Recomendamos empezar a desarrollar nuevos trabajos y aplicaciones con Spark Connect habilitado para que puedas beneficiarte al máximo del potente motor de optimización y ejecución de consultas de Spark. - Soporte Multilingüe: Spark Connect en 4.0 soporta una amplia gama de lenguajes y entornos. Los clientes Python y Scala son totalmente compatibles, y hay nuevos clientes de conexión soportados por la comunidad para Go, Swift y Rust disponibles. Este soporte políglota significa que los desarrolladores pueden usar Spark en el lenguaje de su elección, incluso fuera del ecosistema JVM, a través de la API de Connect. Por ejemplo, una aplicación de ingeniería de datos en Rust o un servicio en Go ahora pueden conectarse directamente a un clúster de Spark y ejecutar consultas DataFrame, ampliando el alcance de Spark más allá de su base de usuarios tradicional.
Funciones del Lenguaje SQL
Spark 4.0 añade nuevas capacidades para simplificar el análisis de datos:
- Funciones Definidas por el Usuario (UDF) SQL – Spark 4.0 introduce las UDF SQL, que permiten a los usuarios definir funciones personalizadas reutilizables directamente en SQL. Estas funciones simplifican la lógica compleja, mejoran la mantenibilidad y se integran perfectamente con el optimizador de consultas de Spark, mejorando el rendimiento de las consultas en comparación con las UDF basadas en código tradicionales. Las UDF SQL soportan definiciones temporales y permanentes, lo que facilita que los equipos compartan lógica común en múltiples consultas y aplicaciones. [Leer la publicación del blog]
- Sintaxis PIPE SQL – Spark 4.0 introduce una nueva sintaxis PIPE, que permite a los usuarios encadenar operaciones SQL utilizando el operador |>. Este enfoque de estilo funcional mejora la legibilidad y mantenibilidad de las consultas al permitir un flujo lineal de transformaciones. La sintaxis PIPE es totalmente compatible con SQL existente, lo que permite una adopción gradual y la integración en los flujos de trabajo actuales. [Leer la publicación del blog]
- Colaciones sensibles al idioma, acento y mayúsculas/minúsculas - Spark 4.0 introduce una nueva propiedad COLLATE para tipos STRING. Puedes elegir entre muchas colaciones sensibles al idioma y a la región para controlar cómo Spark determina el orden y las comparaciones. También puedes decidir si las colaciones deben ser insensibles a mayúsculas/minúsculas, acentos y espacios finales. [Leer la publicación del blog]
- Variables de sesión - Spark 4.0 introduce variables locales de sesión, que se pueden utilizar para mantener y gestionar el estado dentro de una sesión sin usar variables del lenguaje anfitrión. [Leer la publicación del blog]
- Marcadores de parámetros - Spark 4.0 introduce marcadores de parámetros de estilo con nombre (":var") y sin nombre ("?"). Esta función te permite parametrizar consultas y pasar valores de forma segura a través de la API spark.sql(). Esto mitiga el riesgo de inyección SQL. [Ver documentación]
- Scripting SQL: Escribir flujos de trabajo SQL de varios pasos es más fácil en Spark 4.0 gracias a las nuevas capacidades de scripting SQL. Ahora puedes ejecutar scripts SQL de varias sentencias con características como variables locales y flujo de control. Esta mejora permite a los ingenieros de datos mover partes de la lógica ETL a SQL puro, con Spark 4.0 soportando construcciones que antes solo eran posibles a través de lenguajes externos o procedimientos almacenados. Esta función pronto se mejorará aún más con el manejo de condiciones de error. [Leer la publicación del blog]
Integridad de Datos y Productividad del Desarrollador
Spark 4.0 introduce varias actualizaciones que hacen la plataforma más fiable, compatible con estándares y fácil de usar. Estas mejoras optimizan tanto los flujos de trabajo de desarrollo como los de producción, garantizando una mayor calidad de los datos y una solución de problemas más rápida.
- Modo SQL ANSI: Uno de los cambios más significativos en Spark 4.0 es la habilitación del modo SQL ANSI por defecto, alineando Spark más estrechamente con la semántica SQL estándar. Este cambio garantiza un manejo de datos más estricto al proporcionar mensajes de error explícitos para operaciones que anteriormente resultaban en truncamientos silenciosos o nulos, como desbordamientos numéricos o división por cero. Además, la adhesión a los estándares SQL ANSI mejora en gran medida la interoperabilidad, simplificando la migración de cargas de trabajo SQL desde otros sistemas y reduciendo la necesidad de reescrituras extensas de consultas y reentrenamiento de equipos. En general, este avance promueve flujos de trabajo de datos más claros, fiables y portátiles. [Ver documentación]
- Nuevo tipo de datos VARIANT: Apache Spark 4.0 presenta el nuevo tipo de datos VARIANT diseñado específicamente para datos semiestructurados, lo que permite almacenar estructuras complejas tipo JSON o tipo mapa en una sola columna, manteniendo la capacidad de consultar eficientemente campos anidados. Esta potente capacidad ofrece una flexibilidad de esquema significativa, lo que facilita la ingesta y gestión de datos que no se ajustan a esquemas predefinidos. Además, la indexación y el análisis integrados de Spark para campos JSON mejoran el rendimiento de las consultas, facilitando búsquedas y transformaciones rápidas. Al minimizar la necesidad de pasos repetidos de evolución de esquemas, VARIANT simplifica las canalizaciones ETL, lo que resulta en flujos de trabajo de procesamiento de datos más optimizados. [Leer la entrada del blog]
- Registro estructurado: Spark 4.0 introduce un nuevo marco de registro estructurado que simplifica la depuración y la supervisión. Al habilitar
spark.log.structuredLogging.enabled=true,Spark escribe registros como líneas JSON; cada entrada incluye campos estructurados como marca de tiempo, nivel de registro, mensaje y contexto completo de Mapped Diagnostic Context (MDC). Este formato moderno simplifica la integración con herramientas de observabilidad como Spark SQL, ELK y Splunk, lo que hace que los registros sean mucho más fáciles de analizar, buscar y procesar. [Más información]
Avances en la API de Python
Los usuarios de Python tienen mucho que celebrar en Spark 4.0. Esta versión hace que Spark sea más "Pythonic" y mejora el rendimiento de las cargas de trabajo de PySpark:
- Soporte de trazado nativo: La exploración de datos en PySpark ahora es más fácil: Spark 4.0 agrega capacidades de trazado nativas a los DataFrames de PySpark. Ahora puede llamar a un método .plot() o usar una API asociada en un DataFrame para generar gráficos directamente desde datos de Spark, sin necesidad de recopilar datos manualmente en pandas. Internamente, Spark utiliza Plotly como el backend de visualización predeterminado para renderizar gráficos. Esto significa que los tipos de gráficos comunes como histogramas y diagramas de dispersión se pueden crear con una sola línea de código en un DataFrame de PySpark, y Spark se encargará de obtener una muestra o un agregado de los datos para trazarlos en un cuaderno o GUI. Al admitir el trazado nativo, Spark 4.0 optimiza el análisis exploratorio de datos: puede visualizar distribuciones y tendencias de su conjunto de datos sin salir del contexto de Spark ni escribir código matplotlib/plotly por separado. Esta función es una gran ayuda para la productividad de los científicos de datos que utilizan PySpark para EDA.
- API de origen de datos de Python: Spark 4.0 introduce una nueva API de origen de datos de Python que permite a los desarrolladores implementar orígenes de datos personalizados para procesamiento por lotes y en tiempo real completamente en Python. Anteriormente, escribir un conector para un nuevo formato de archivo, base de datos o flujo de datos a menudo requería conocimientos de Java/Scala. Ahora, puede crear lectores y escritores en Python, lo que abre Spark a una comunidad más amplia de desarrolladores. Por ejemplo, si tiene un formato de datos personalizado o una API que solo tiene un cliente Python, puede envolverlo como un origen/destino de DataFrame de Spark utilizando esta API. Esta función mejora en gran medida la extensibilidad de PySpark tanto en contextos por lotes como en tiempo real. Consulte la entrada detallada de PySpark para ver un ejemplo de implementación de un origen de datos personalizado simple en Python o consulte una muestra de ejemplos aquí. [Leer la entrada del blog]
- UDTF de Python polimórficas: Basándose en la capacidad de UDTF de SQL, PySpark ahora admite Funciones de Tabla Definidas por el Usuario en Python, incluidas las UDTF polimórficas que pueden devolver diferentes formas de esquema según la entrada. Puede crear una clase de Python como UDTF utilizando un decorador que genera un iterador de filas de salida y registrarla para que pueda ser llamada desde Spark SQL o la API de DataFrame. Un aspecto potente son las UDTF de esquema dinámico: su UDTF puede definir un método analyze() para producir un esquema sobre la marcha basado en parámetros, como leer un archivo de configuración para determinar las columnas de salida. Este comportamiento polimórfico hace que las UDTF sean extremadamente flexibles, lo que permite escenarios como el procesamiento de un esquema JSON variable o la división de una entrada en un conjunto variable de salidas. Las UDTF de PySpark permiten efectivamente que la lógica de Python genere un resultado de tabla completo por invocación, todo dentro del motor de ejecución de Spark. [Ver documentación]
Mejoras en streaming
Apache Spark 4.0 continúa refinando Structured Streaming para mejorar el rendimiento, la usabilidad y la observabilidad:
- Procesamiento de estado arbitrario v2: Spark 4.0 introduce un nuevo operador de Procesamiento de estado arbitrario llamado transformWithState. TransformWithState permite la creación de canalizaciones operativas complejas con soporte para la definición de lógica orientada a objetos, tipos compuestos, soporte para temporizadores y TTL, soporte para el manejo del estado inicial, evolución del esquema de estado y una gran cantidad de otras características. Esta nueva API está disponible en Scala, Java y Python y proporciona integraciones nativas con otras características importantes como el lector de origen de datos de estado, el manejo de metadatos del operador, etc. [Leer la entrada del blog]
- Origen de datos de estado - Lector: Spark 4.0 agrega la capacidad de consultar el estado de streaming como una tabla. Este nuevo origen de datos de almacenamiento de estado expone el estado interno utilizado en agregaciones de streaming con estado (como contadores, ventanas de sesión, etc.), uniones, etc., como un DataFrame legible. Con opciones adicionales, esta función también permite a los usuarios rastrear cambios de estado por actualización para una visibilidad detallada. Esta función también ayuda a comprender qué estado está procesando su trabajo de streaming y puede ayudar aún más a solucionar problemas y monitorear la lógica con estado de sus flujos, así como a detectar cualquier corrupción subyacente o violación de invariantes. [Leer la entrada del blog]
- Mejoras en el almacén de estado: Spark 4.0 también agrega numerosas mejoras en el almacén de estado, como una mejor gestión de la reutilización de archivos SST (Static Sorted Table), mejoras en la gestión de instantáneas y mantenimiento, un formato de punto de control de estado renovado, así como mejoras de rendimiento adicionales. Junto con esto, se han agregado numerosos cambios en torno a la mejora del registro y la clasificación de errores para facilitar la supervisión y la depuración.
Agradecimientos
Spark 4.0 es un gran paso adelante para el proyecto Apache Spark, con optimizaciones y nuevas funciones que tocan todas las capas, desde mejoras centrales hasta API más ricas. En esta versión, la comunidad cerró más de 5000 incidencias de JIRA y alrededor de 400 contribuyentes individuales, desde desarrolladores independientes hasta organizaciones como Databricks, Apple, Linkedin, Intel, OpenAI, eBay, Netease, Baidu, han impulsado estas mejoras.
Extendemos nuestro sincero agradecimiento a cada contribuyente, ya sea que haya presentado un ticket, revisado código, mejorado la documentación o compartido comentarios en listas de correo. Más allá de las mejoras destacadas en SQL, Python y streaming, Spark 4.0 también ofrece soporte para Java 21, operador Spark K8S, conectores XML, soporte de ML de Spark en Connect y perfilado unificado de UDF de PySpark. Para obtener la lista completa de cambios y todos los demás refinamientos a nivel de motor, consulte las notas de la versión de Spark 4.0.
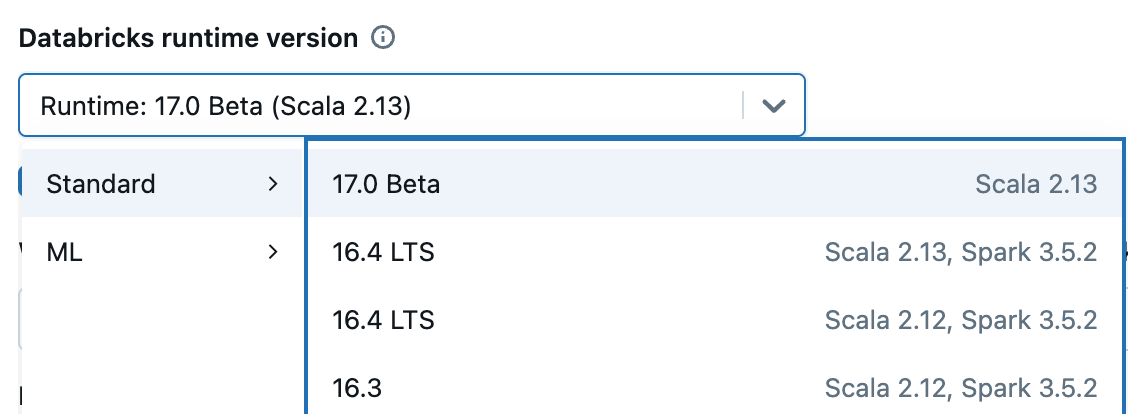
Obtener Spark 4.0: Es completamente de código abierto, descárguelo desde spark.apache.org. Muchas de sus características ya estaban disponibles en Databricks Runtime 15.x y 16.x, y ahora se incluyen de serie con Runtime 17.0. Para explorar Spark 4.0 en un entorno administrado, regístrese para obtener la Edición Comunitaria o comience una prueba, elija "17.0" cuando inicie su clúster y estará ejecutando Spark 4.0 en minutos.
Si se perdió nuestra reunión de Spark 4.0 donde discutimos estas características, puede ver las grabaciones aquí. Además, estad atentos a futuras reuniones detalladas sobre estas características de Spark 4.0.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.