Presentando la Vista Previa Pública de Búsqueda Vectorial de Databricks
por Akhil Gupta, Sergei Tsarev y Eric Peter
Tras el anuncio que hicimos ayer sobre Recuperación Aumentada de Generación (RAG), hoy nos complace anunciar la vista previa pública de Databricks AI Search. Anunciamos la vista previa privada a un grupo limitado de clientes en la Cumbre Data + AI en junio, que ya está disponible para todos nuestros clientes. Databricks La búsqueda vectorial permite a los desarrolladores mejorar la precisión de sus aplicaciones de Generación Aumentada de Recuperación (RAG) y de IA generativa mediante la búsqueda de similitudes sobre documentos no estructurados como PDFs, documentos de oficina, wikis y más. La búsqueda vectorial forma parte de la Plataforma de Inteligencia de Datos Databricks, lo que facilita que tus aplicaciones RAG y IA generativa empleen los datos propietarios almacenados en tu Lakehouse de forma rápida y segura y ofrezcan respuestas precisas.
Diseñamos la búsqueda vectorial de Databricks para que sea rápida, segura y fácil de usar.
- Rápido con bajo TCO - La búsqueda vectorial está diseñada para ofrecer un alto rendimiento con menor TCO, con hasta 5 veces menor latencia que otros proveedores
- Experiencia sencilla y rápida para desarrolladores : la búsqueda vectorial permite sincronizar cualquier Tabla Delta en un índice vectorial con un solo clic, sin necesidad de procesos complejos y personalizados de ingestión/sincronización de datos.
- Gobernanza Unificada - AI Search emplea las mismas herramientas de seguridad y gobernanza de datos basadas en el Catálogo Unity que ya alimentan tu Plataforma de Inteligencia de Datos, lo que significa que no tienes que crear ni mantener un conjunto separado de políticas de gobernanza de datos para tus datos no estructurados
- Escalabilidad sin servidor : nuestra infraestructura sin servidor se adapta automáticamente a tus flujos de trabajo sin necesidad de configurar instancias y tipos de servidores.
¿Qué es la búsqueda vectorial?
La búsqueda vectorial es un método empleado en aplicaciones de recuperación de información y Generación Aumentada de Recuperación (RAG) para encontrar documentos o registros basar en su similitud con una consulta. La búsqueda vectorial es la razón por la que puedes escribir una consulta en lenguaje sencillo como "zapatos azules que son buenos para viernes por la noche" y obtener resultados relevantes.
Los gigantes tecnológicos emplearon la búsqueda vectorial durante años para impulsar sus experiencias de producto; con la llegada de la IA generativa, estas capacidades finalmente se democratizan en todas las organizaciones.
Aquí tienes un desglose de cómo funciona la búsqueda vectorial:
Incrustaciones: En la búsqueda vectorial, los datos y consultas se representan como vectores en un espacio multidimensional llamado embeddings de un modelo de IA generativa.
Tomemos un ejemplo sencillo donde queremos usar la búsqueda vectorial para encontrar palabras semánticamente similares en un gran corpus de palabras. Así que, si consultas el corpus con la palabra 'perro', quieres que se devuelvan palabras como 'puppy'. Pero, si buscas 'auto', quieres encontrar palabras como 'furgoneta'. En la búsqueda tradicional, tendrás que mantener una lista de sinónimos o "palabras similares", que es difícil de generar o escalar. Para usar la búsqueda vectorial, puedes usar un modelo de IA generativa para convertir estas palabras en vectores en un espacio n-dimensional llamado embeddings. Estos vectores tendrán la propiedad de que palabras semánticamente similares como 'perro' y 'cachorro' estarán más cercanas entre sí en el espacio n-dimensional que las palabras 'perro' y 'auto'.
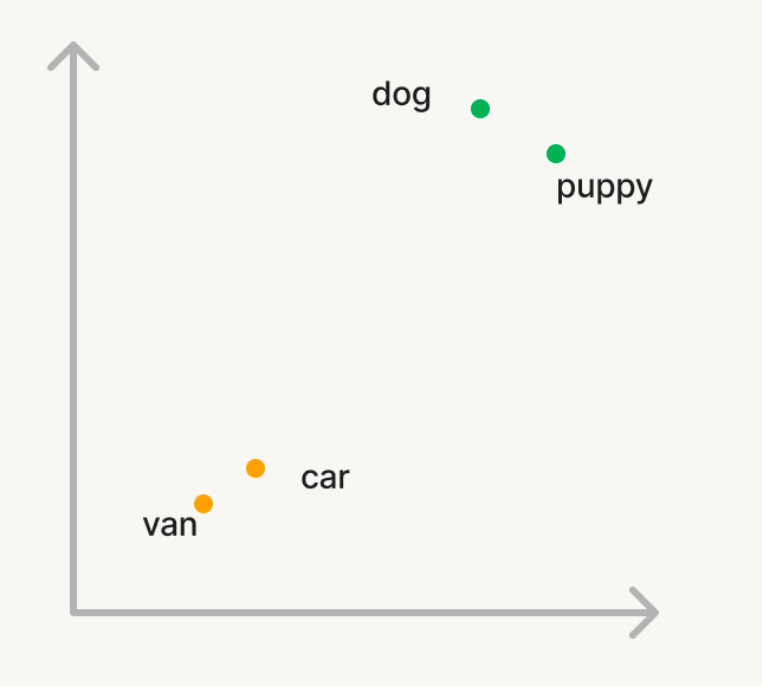
Cálculo de similitud: Para encontrar documentos relevantes para una consulta, se calcula la similitud entre el vector de consulta y cada vector de documento para medir la proximidad entre sí en el espacio n-dimensional. Esto se hace típicamente usando similitud coseno, que mide el coseno del ángulo entre los dos vectores. Existen varios algoritmos que se emplean para encontrar vectores similares de manera eficiente, siendo los algoritmos basados en HNSW los que consistentemente son los mejores en su clase.
Aplicaciones: La búsqueda vectorial tiene muchos casos de uso:
- Recomendaciones: recomendaciones personalizadas y conscientes del contexto para los usuarios
- RAG: entrega de documentos no estructurados relevantes para ayudar a una aplicación RAG a responder a las preguntas del usuario
- Búsqueda semántica: habilitar consultas de búsqueda en lenguaje sencillo que ofrezcan resultados relevantes
- Agrupamiento de documentos: entender las similitudes y diferencias entre datos
¿Por qué los clientes aman la búsqueda vectorial de Databricks?
"Estamos encantados de aprovechar las poderosas soluciones de Databricks para transformar nuestras operaciones de atención al cliente en Lippert. Gestionar un entorno dinámico de call center para una compañía de nuestro tamaño, el reto de poner a los nuevos agentes al día en medio de la típica rotación de agentes es considerable. Databricks es la clave de nuestra solución: al establecer una experiencia de asistencia de agentes impulsada por AI Search, podemos capacitar a nuestros agentes para encontrar respuestas rápidas a las consultas de los clientes. Al incorporar contenido de manuales de productos, videos de YouTube y casos de soporte en nuestra Búsqueda Vectorial, Databricks garantiza que nuestros agentes tengan el conocimiento que necesitan al alcance de la mano. Este enfoque innovador es un cambio radical para Lippert, mejorando la eficiencia y elevando la experiencia de atención al cliente."-Chris Nishnick, Inteligencia Artificial, Lippert
Ingesta automatizada de datos
Antes de que una base de datos vectorial pueda almacenar información, requiere una tubería de ingestión de datos donde los datos en bruto y no procesados de diversas fuentes deben ser limpiados, procesados (analizados/fragmentados) e integrados con un modelo de IA antes de almacenar como vectores en la base de datos. Este proceso para construir y mantener otro conjunto de canalizaciones de ingestión de datos es costoso y lleva mucho tiempo, ya que consume valiosos recursos de ingeniería. La búsqueda vectorial de Databricks está totalmente integrada con la plataforma de inteligencia de datos de Databricks, lo que le permite extraer datos e incrustarlos automáticamente sin necesidad de construir y mantener nuevas canalizaciones de datos.
Nuestras APIs Delta Sync sincronizan automáticamente los datos fuente con índices vectoriales. A medida que se agregan, actualizan o eliminan datos fuente, actualizamos automáticamente el índice vectorial correspondiente para que coincida. En el fondo, AI Search gestiona fallos, gestiona intentos y optimiza los tamaños de lote para ofrecerte el mejor rendimiento y rendimiento sin ningún trabajo ni entrada. Estas optimizaciones reducen tu costo total de propiedad debido a la mayor utilización de tu endpoint de modelo de embebido.
Veamos un ejemplo en el que creamos un índice vectorial en tres sencillos pasos. Todas las capacidades de búsqueda vectorial están disponibles a través de APIs REST, nuestro SDK en Python o dentro de la interfaz de Databricks.
Paso 1. Crea un endpoint de búsqueda vectorial que se emplee para crear y consultar un índice vectorial usando la interfaz de usuario o nuestra REST API/SDK.
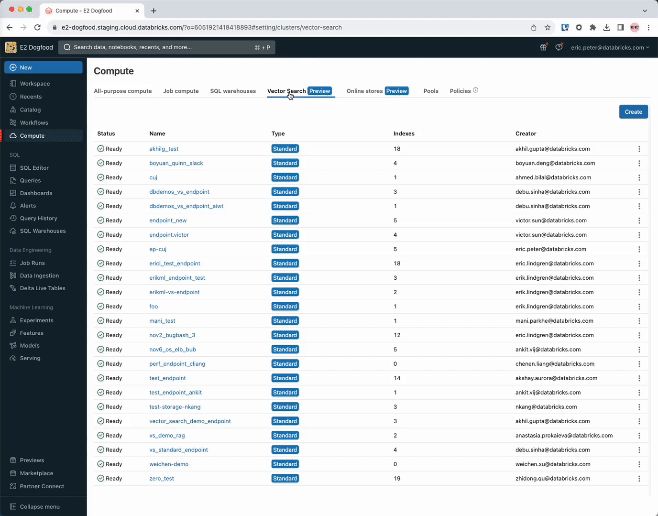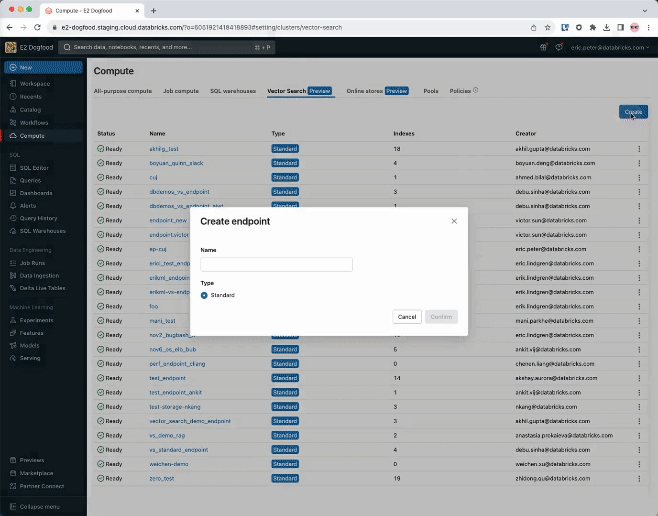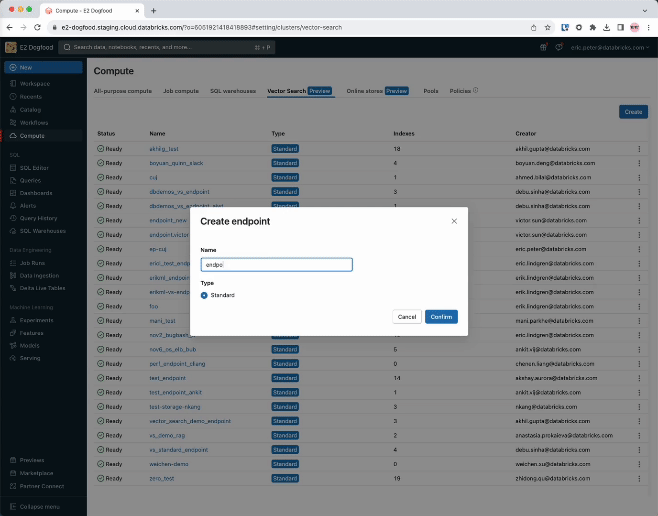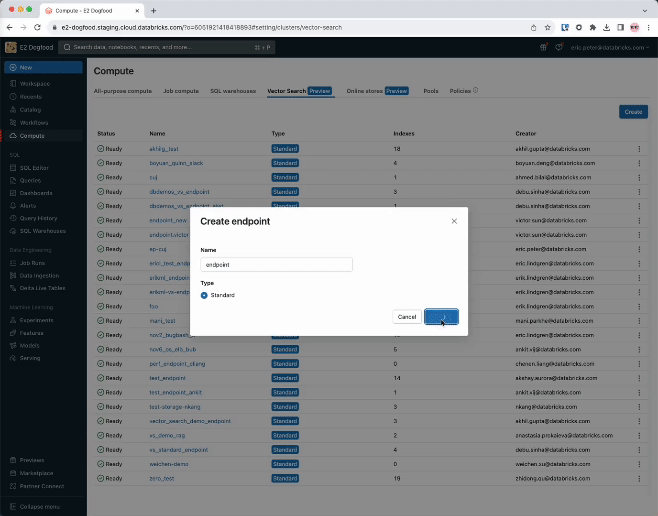
Paso 2. Luego de crear una Tabla Delta con tus datos fuente, seleccionas una columna en la Tabla Delta para incrustar y luego seleccionas un endpoint Model Serving que se usa para generar incrustaciones para los datos.
El modelo de incrustación puede ser:
- Un modelo que tú perfeccionaste
- Un modelo de código abierto comercial (como E5, BGE, InstructorXL, etc.)
- Un modelo de incrustación propietario disponible mediante API (como OpenAI, Cohere, Anthropic, etc.)
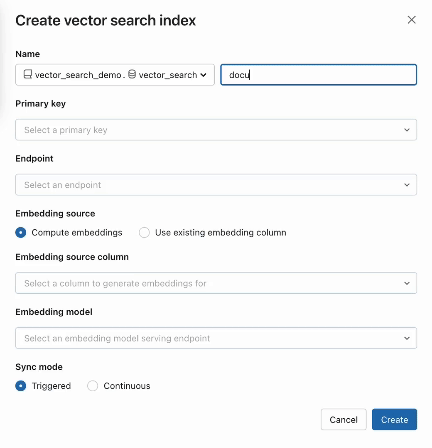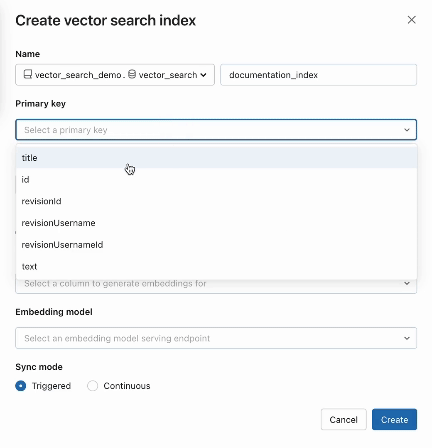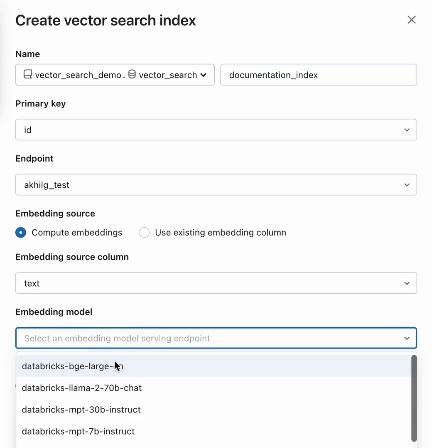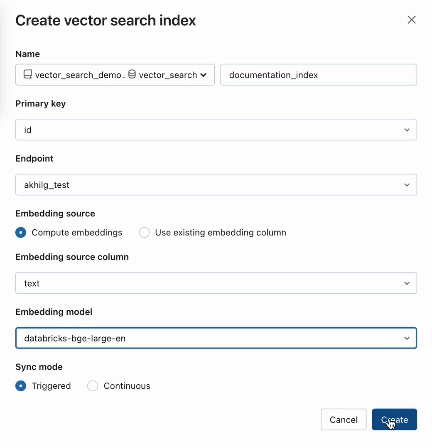
La búsqueda vectorial también ofrece modos avanzados para clientes que prefieren gestionar sus incrustaciones en una Tabla Delta o crear pipelines de ingestión de datos usando APIs REST. Para ejemplos, consulta la documentación de AI Search.
Paso 3. Una vez que el índice esté listo, puedes hacer consultas para encontrar vectores relevantes para tu consulta. Estos resultados pueden enviar a tu aplicación de Generación Aumentada por Recuperación (RAG).
"Este producto es fácil de usar, y estuvimos en marcha en cuestión de horas. Todos nuestros datos ya están en Delta, así que la experiencia integrada gestionada de AI Search con delta sync es asombroso." —- Alex Dalla Piazza (EQT Corporation)"
Gobernanza integrada
Las organizaciones empresariales requieren controles estrictos de seguridad y acceso sobre sus datos, por lo que los usuarios no pueden emplear modelos de IA generativa para proporcionarles datos confidenciales a los que no deberían tener acceso. Sin embargo, las bases de datos actuales de Vector o bien no cuentan con controles de seguridad y acceso robustos o requieren que las organizaciones construyan y mantengan un conjunto separado de políticas de seguridad separadas de su plataforma de datos. Contar con múltiples conjuntos de seguridad y gobernanza agrega costo y complejidad, y es propenso a errores para mantener de forma fiable.
Databricks AI Search aprovecha los mismos controles de seguridad y gobernanza de datos que ya protegen el resto de la Plataforma de Inteligencia de Datos habilitada por la integración con Unity Catalog. Los índices vectoriales se almacenan como entidades dentro de tu catálogo de Unity y aprovechan la misma interfaz unificada para definir políticas sobre los datos, con un control detallado sobre las incrustaciones.
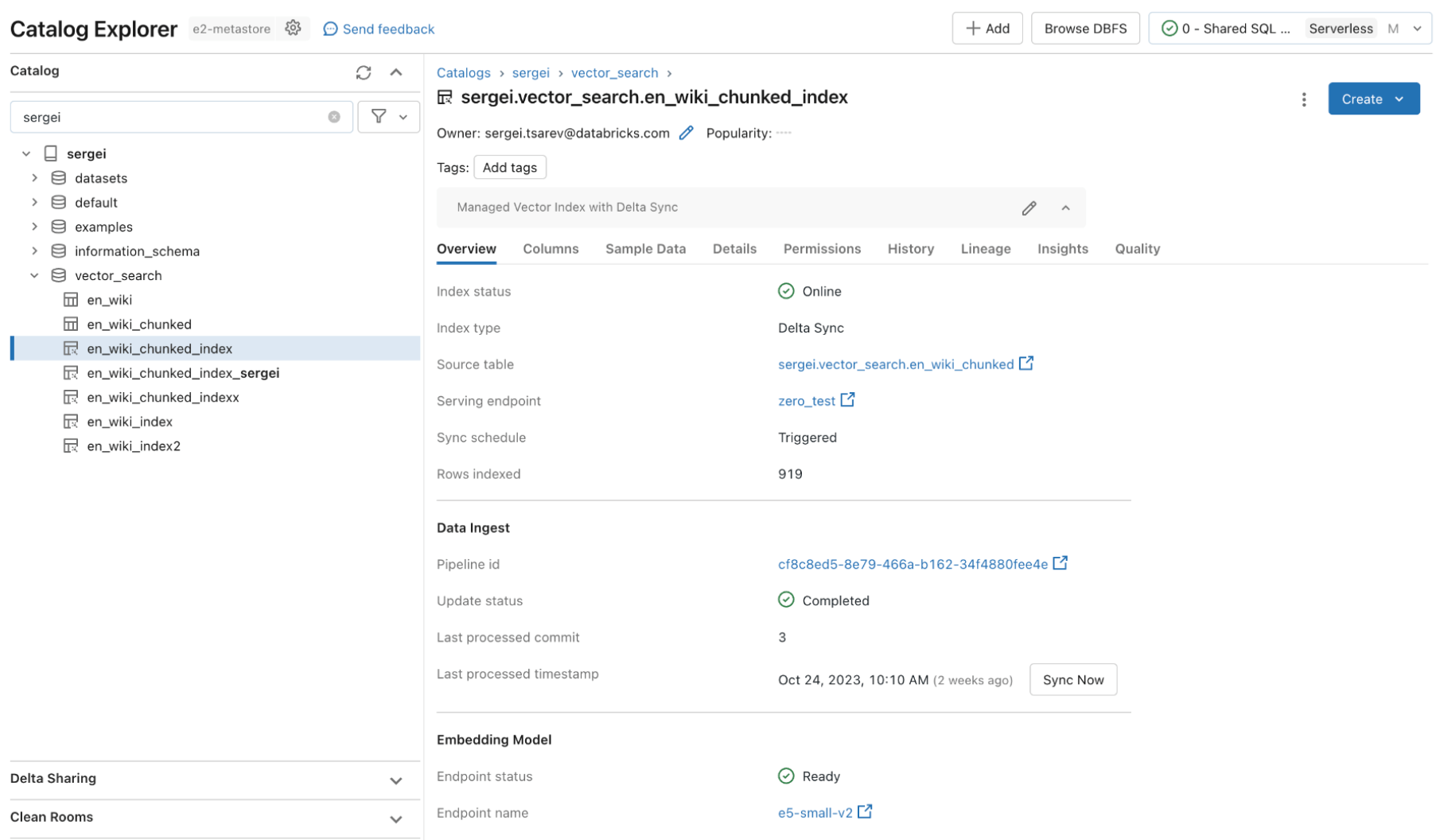
Rendimiento rápido de consultas
Debido a la madurez del mercado, muchas bases de datos vectoriales muestran buenos resultados en pruebas de concepto (POCs) con pequeñas cantidades de datos. Sin embargo, a menudo no logran mejorar ni escalar en despliegues en producción. Con un bajo rendimiento listo para usar, los usuarios tendrán que averiguar cómo ajustar y escalar los índices de búsqueda, lo cual es laborioso y difícil de hacer bien. Se ven obligados a entender su carga de trabajo y tomar decisiones difíciles sobre qué instancias de cálculo elegir y qué configuración usar.
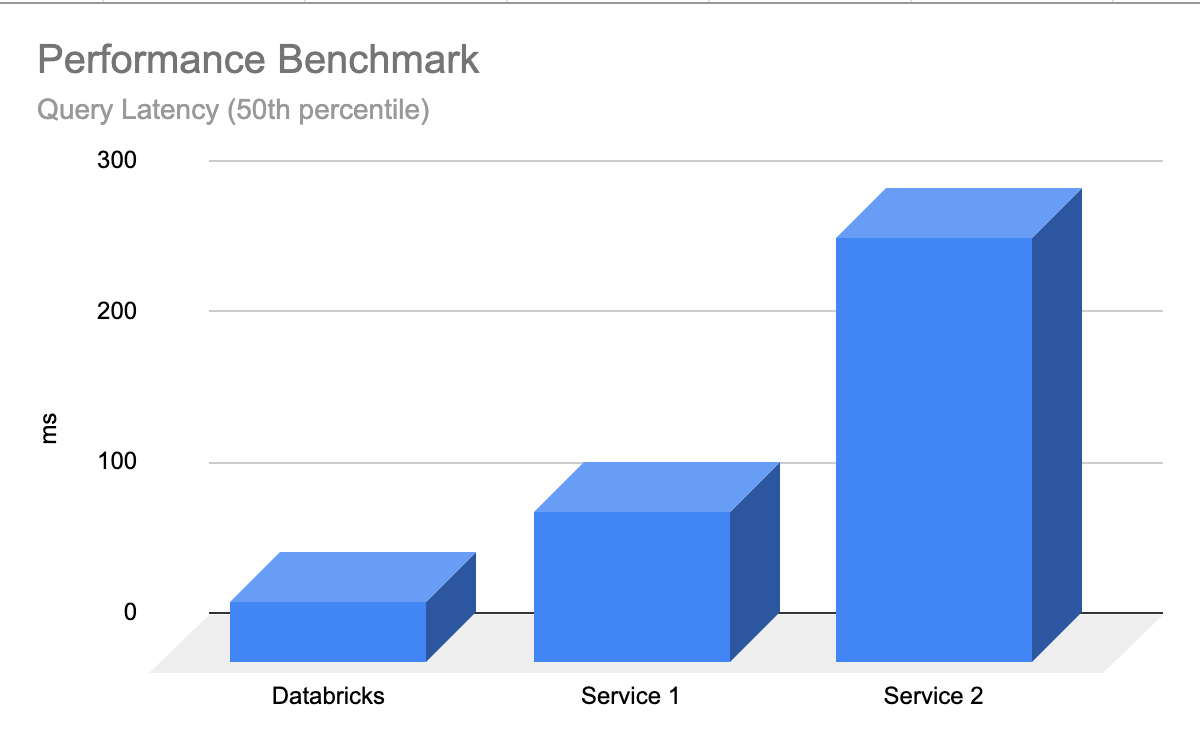
La búsqueda vectorial de Databricks es eficiente desde el principio, donde los LLMs devuelven resultados relevantes rápidamente, con una latencia mínima y sin trabajo necesario para ajustar y escalar la base de datos. La búsqueda vectorial está diseñada para ser extremadamente rápida para consultas con o sin filtrado. Muestra un rendimiento hasta 5 veces superior al de algunas de las otras bases de datos vectoriales líderes. Es fácil de configurar: simplemente nos dices el tamaño esperado de carga de trabajo (por ejemplo, consultas por segundo), la latencia requerida y el número esperado de incrustaciones; nosotros nos encargamos del resto. No tienes que preocuparte por tipos de instancias, RAM/CPU, ni por entender cómo funcionan las bases de datos vectoriales.
Dedicamos mucho esfuerzo a personalizar la búsqueda vectorial de Databricks para soportar cargas de trabajo de IA que miles de nuestros clientes ya están ejecutando en Databricks. Las optimizaciones incluyeron benchmarking e identificación del mejor hardware adecuado para la búsqueda semántica, optimización del algoritmo de búsqueda subyacente y la sobrecarga de red para ofrecer el mejor rendimiento a gran escala.
Próximos pasos
Empieza leyendo nuestra documentación y, específicamente, creando un índice de búsqueda vectorial
Lee más sobre la fijación de preciosde la búsqueda vectorial
Empezar a desplegar tu propia aplicación RAG (demo)
Regístrate a un seminario sitio webde IA generativa de Databricks
¿Quieres resolver casos de uso de IA generativa? ¡Compite en el Hackathon de IA Generativa de Databricks y AWS! Regístrate aquí
Vía de aprendizaje para ingenieros de IA generativa: haz cursos de IA generativa a ritmo propio, bajo demanda y dirigidos por un instructor
Lee los anuncios resumen realizados a principios de esta semana
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.