Crear aplicaciones de RAG de alta calidad con Databricks
Un nuevo conjunto de herramientas para llevar las aplicaciones de IA generativa a producción
por Patrick Wendell y Hanlin Tang
La generación aumentada por recuperación (RAG) ha surgido rápidamente como una forma poderosa de incorporar datos propietarios y en tiempo real en las aplicaciones de modelos de lenguaje grandes (LLM). Hoy nos complace lanzar un conjunto de herramientas de RAG para ayudar a los usuarios de Databricks a crear aplicaciones de LLM de alta calidad y listas para producción utilizando sus datos empresariales.
Los LLM supusieron un gran avance en la capacidad de prototipar rápidamente nuevas aplicaciones. Pero después de trabajar con miles de empresas que desarrollan aplicaciones RAG, hemos descubierto que su mayor desafío es llevar estas aplicaciones a una calidad de producción. Para cumplir con el estándar de calidad que se requiere para las aplicaciones orientadas al cliente, el resultado de la IA debe ser preciso, actual, consciente del contexto de su empresa y seguro.
Para lograr una alta calidad con las aplicaciones de RAG, los desarrolladores necesitan herramientas completas para comprender la calidad de sus datos y los resultados del modelo, junto con una plataforma subyacente que les permita combinar y optimizar todos los aspectos del proceso de RAG. RAG implica muchos componentes, como la preparación de datos, los modelos de recuperación, los modelos de lenguaje (ya sea SaaS o de código abierto), los pipelines de clasificación y posprocesamiento, la ingeniería de prompts y el entrenamiento de modelos con datos empresariales personalizados. Databricks siempre se ha centrado en combinar sus datos con las técnicas de ML más avanzadas. Con el lanzamiento de hoy, ampliamos esa filosofía para permitir que los clientes aprovechen sus datos en la creación de aplicaciones de IA de alta calidad.
El lanzamiento de hoy incluye la vista previa pública de:
- Un servicio de búsqueda vectorial para potenciar la búsqueda semántica en las tablas existentes de su lakehouse.
- Un servicio en línea de características y funciones para que el contexto estructurado esté disponible para las aplicaciones de RAG.
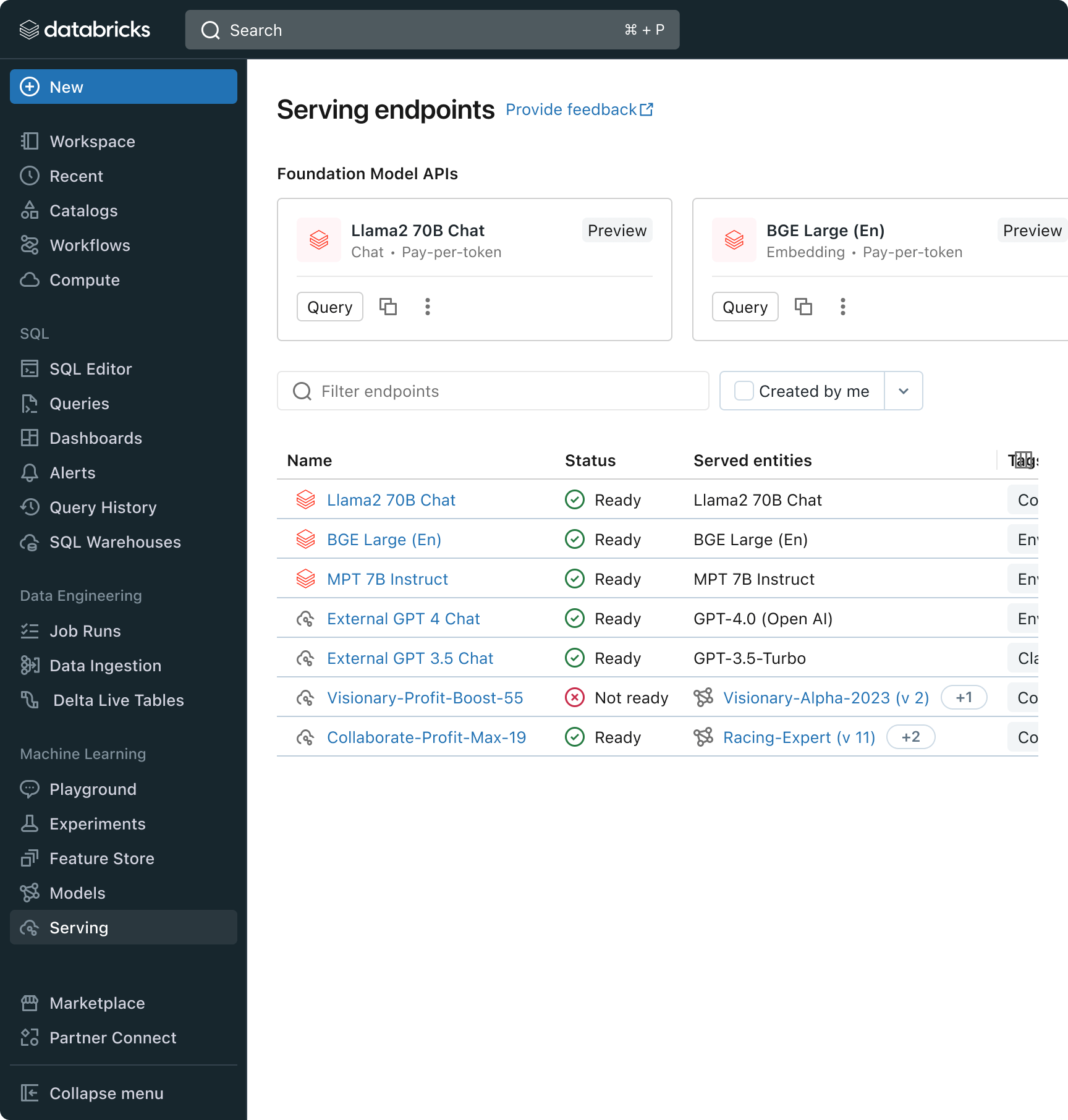
- Modelos fundacionales totalmente gestionados que proporcionan LLM base de pago por token.
- Una interfaz flexible de monitoreo de calidad para observar el rendimiento en producción de las aplicaciones RAG.
- Un conjunto de herramientas de desarrollo de LLM para comparar y evaluar varios LLM.
Estas funciones están diseñadas para abordar los tres desafíos principales que hemos visto en la creación de aplicaciones RAG de producción:
Desafío n.º 1: Entrega de datos en tiempo real para tu aplicación RAG
Las aplicaciones de RAG combinan sus datos estructurados y no estructurados más recientes para producir las respuestas más personalizadas y de la más alta calidad. Sin embargo, mantener una infraestructura de servicio de datos en línea puede ser muy difícil y, tradicionalmente, las empresas han tenido que unir varios sistemas y mantener complejas canalizaciones de datos para cargarlos desde lagos de datos centrales a capas de servicio personalizadas. Proteger los conjuntos de datos importantes también es muy difícil cuando las copias se distribuyen en diferentes pilas de infraestructura.
Con este lanzamiento, Databricks admite de forma nativa el servicio y la indexación de tus datos para la recuperación en línea. Para los datos no estructurados (texto, imágenes y video), la Búsqueda Vectorial indexará y servirá automáticamente los datos de las tablas Delta, haciéndolos accesibles a través de la búsqueda de similitud semántica para las aplicaciones RAG. Internamente, AI Search gestiona las fallas, se encarga de los reintentos y optimiza los tamaños de los lotes para brindarte el mejor rendimiento, capacidad de procesamiento y costo. Para los datos estructurados, Servicio de Características y Funciones proporciona consultas a escala de milisegundos de datos contextuales, como datos de usuario o de cuenta, que las empresas suelen querer insertar en los prompts para personalizarlos según la información del usuario.
Unity Catalog realiza un seguimiento automático del linaje entre las copias sin conexión y en línea de los conjuntos de datos servidos, lo que facilita mucho la depuración de los problemas de calidad de los datos. También aplica de manera consistente la configuración de los controles de acceso entre los conjuntos de datos en línea y fuera de línea, lo que significa que las empresas pueden auditar y controlar mejor quién ve la información confidencial y propietaria.
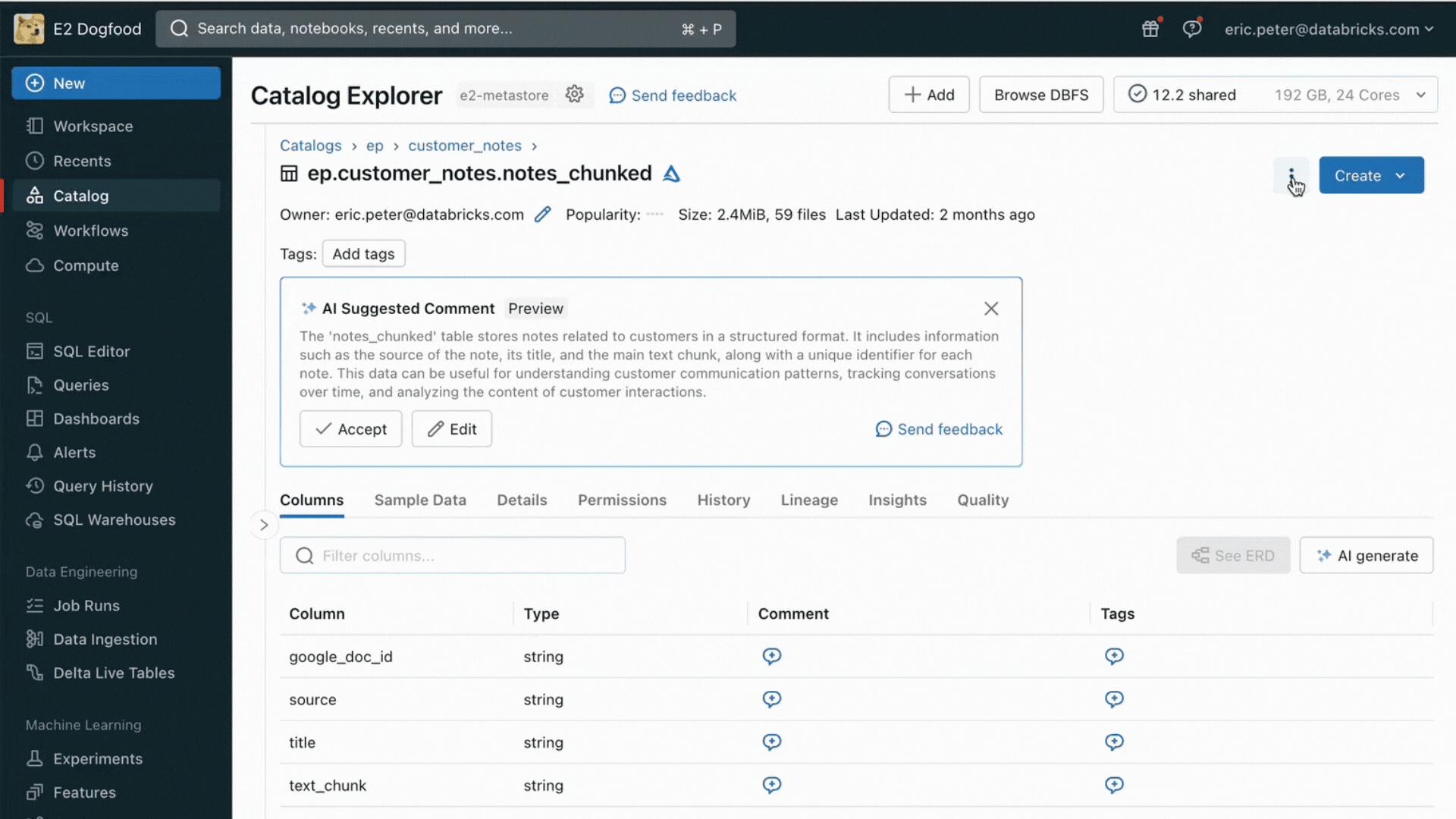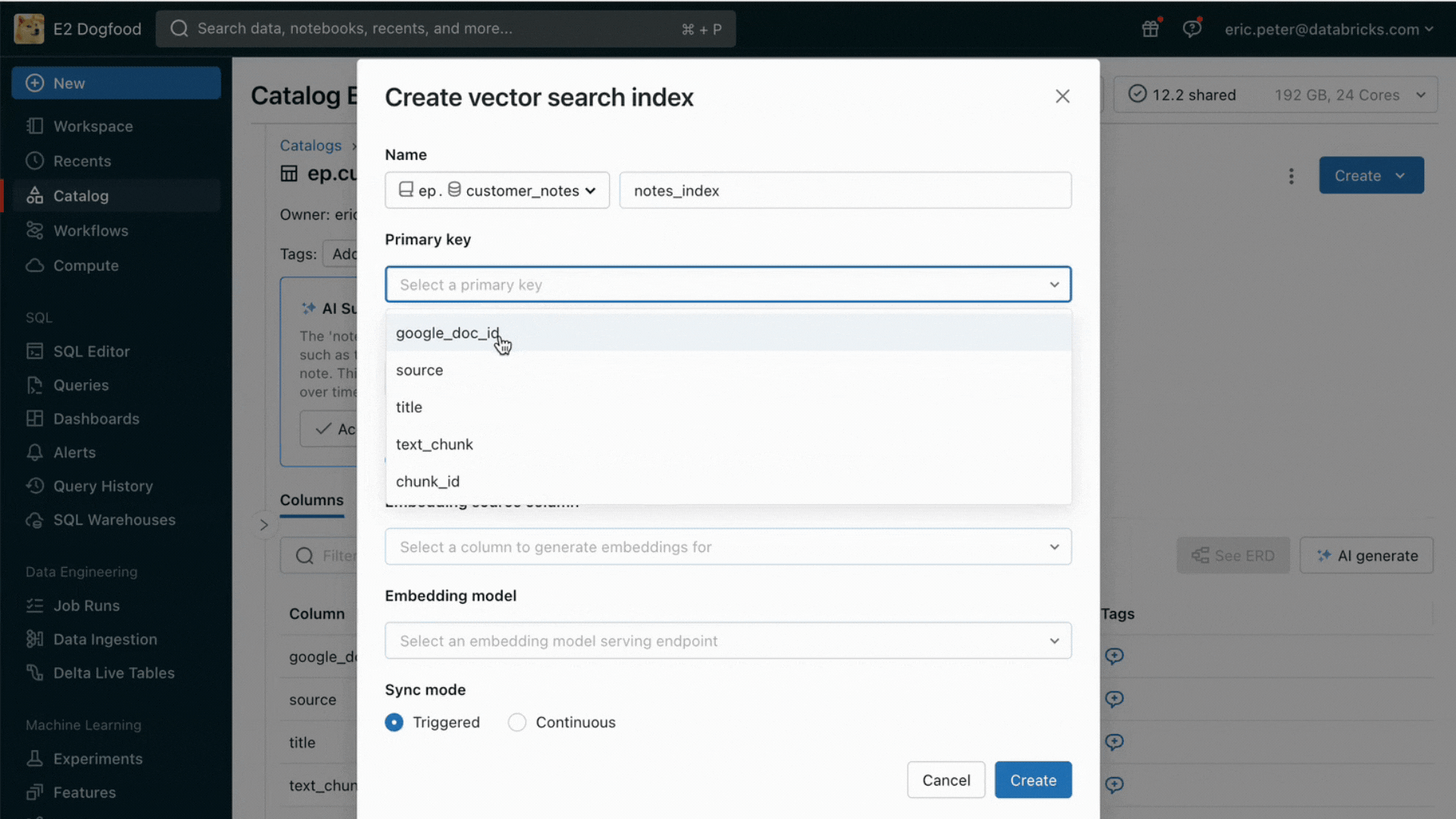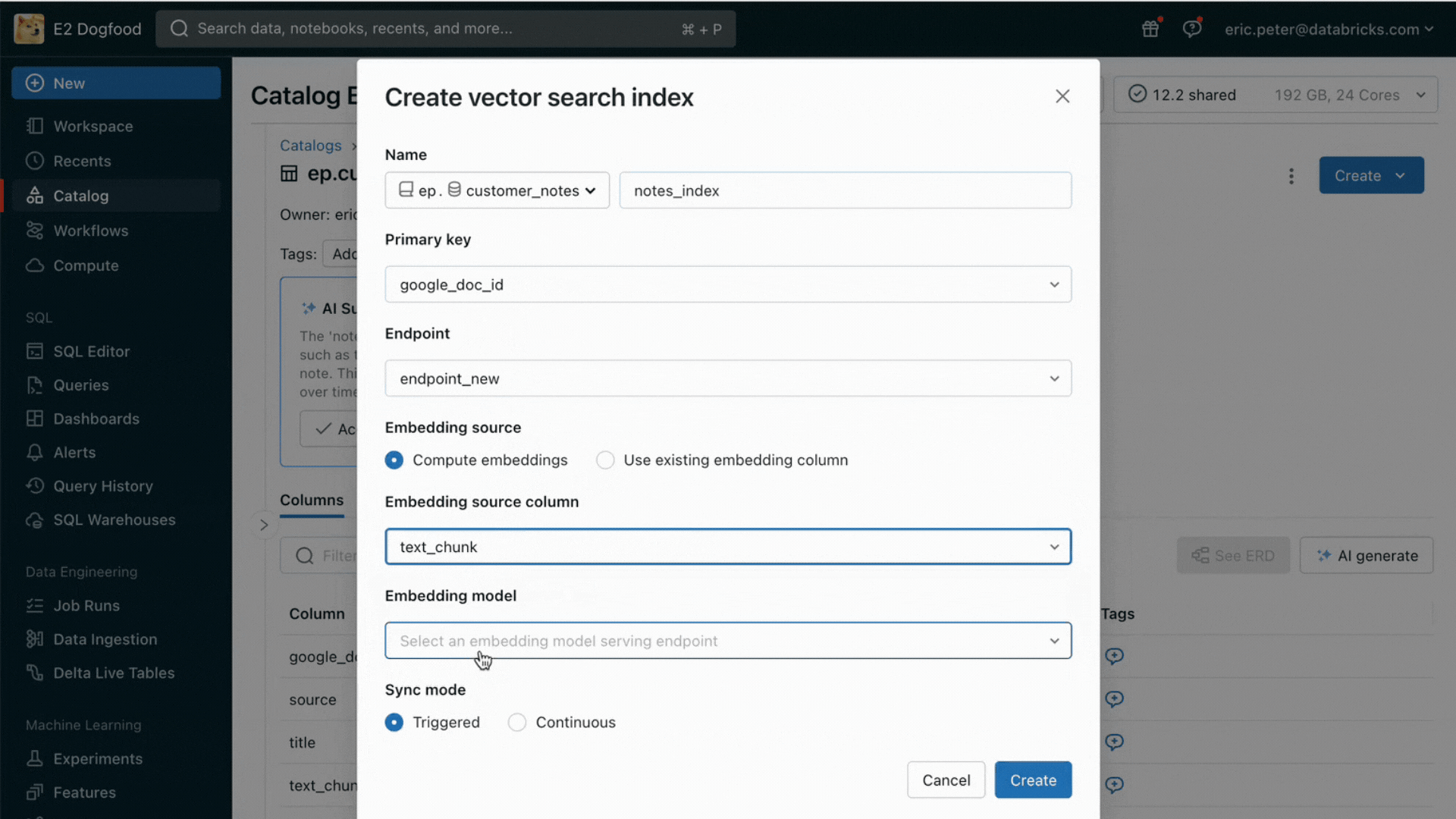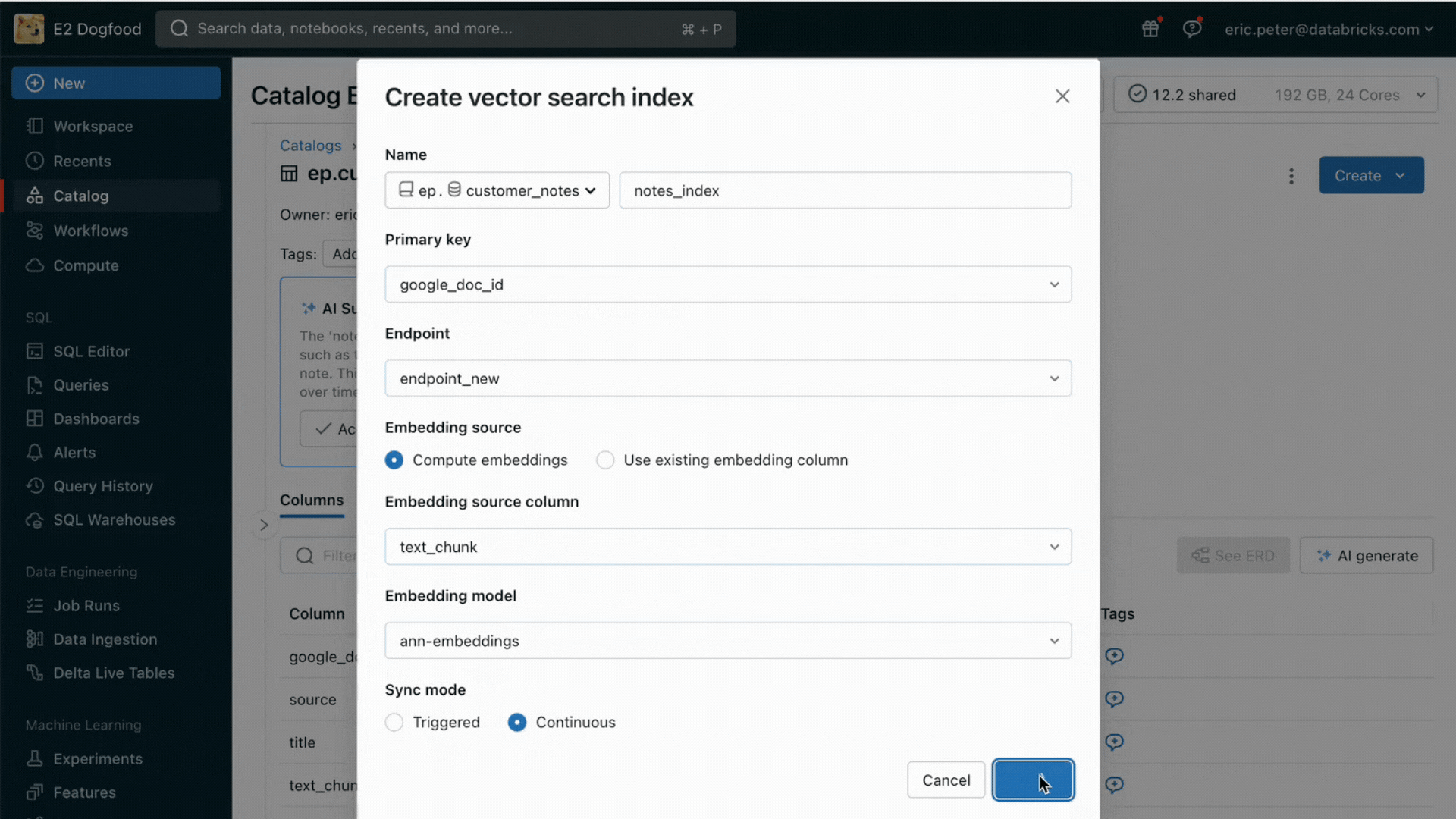
Desafío n.º 2: comparación, ajuste y servicio de modelos fundacionales
Un factor determinante de la calidad en una aplicación RAG es la elección del modelo LLM base. Comparar modelos puede ser difícil porque los modelos varían en varias dimensiones, como la capacidad de razonamiento, la propensión a alucinar, el tamaño de la ventana de contexto y el costo de servicio. Algunos modelos también se pueden ajustar para aplicaciones específicas, lo que puede mejorar aún más el rendimiento y potencialmente reducir los costos. Con el lanzamiento de nuevos modelos casi todas las semanas, comparar las permutaciones del modelo base para encontrar la mejor opción para una aplicación en particular puede ser extremadamente engorroso. Para complicar aún más las cosas, los proveedores de modelos a menudo tienen API dispares, lo que dificulta mucho la comparación rápida o la preparación para el futuro de las aplicaciones RAG.
Con este lanzamiento, Databricks ahora ofrece un entorno unificado para el desarrollo y la evaluación de LLM, que proporciona un conjunto coherente de herramientas para todas las familias de modelos en una plataforma independiente de la nube. Los usuarios de Databricks pueden acceder a modelos líderes de Azure OpenAI Service, AWS Bedrock y Anthropic, modelos de código abierto como Llama 2 y MPT, o modelos de clientes totalmente personalizados y ajustados. El nuevo AI Playground interactivo permite chatear fácilmente con estos modelos, mientras que nuestra cadena de herramientas integrada con MLflow permite realizar comparaciones detalladas mediante el seguimiento de métricas clave como la toxicidad, la latencia y el recuento de tokens. La comparación de modelos en paralelo en Playground o MLflow permite a los clientes identificar el mejor modelo candidato para cada caso de uso, e incluso admite la evaluación del componente de recuperación.
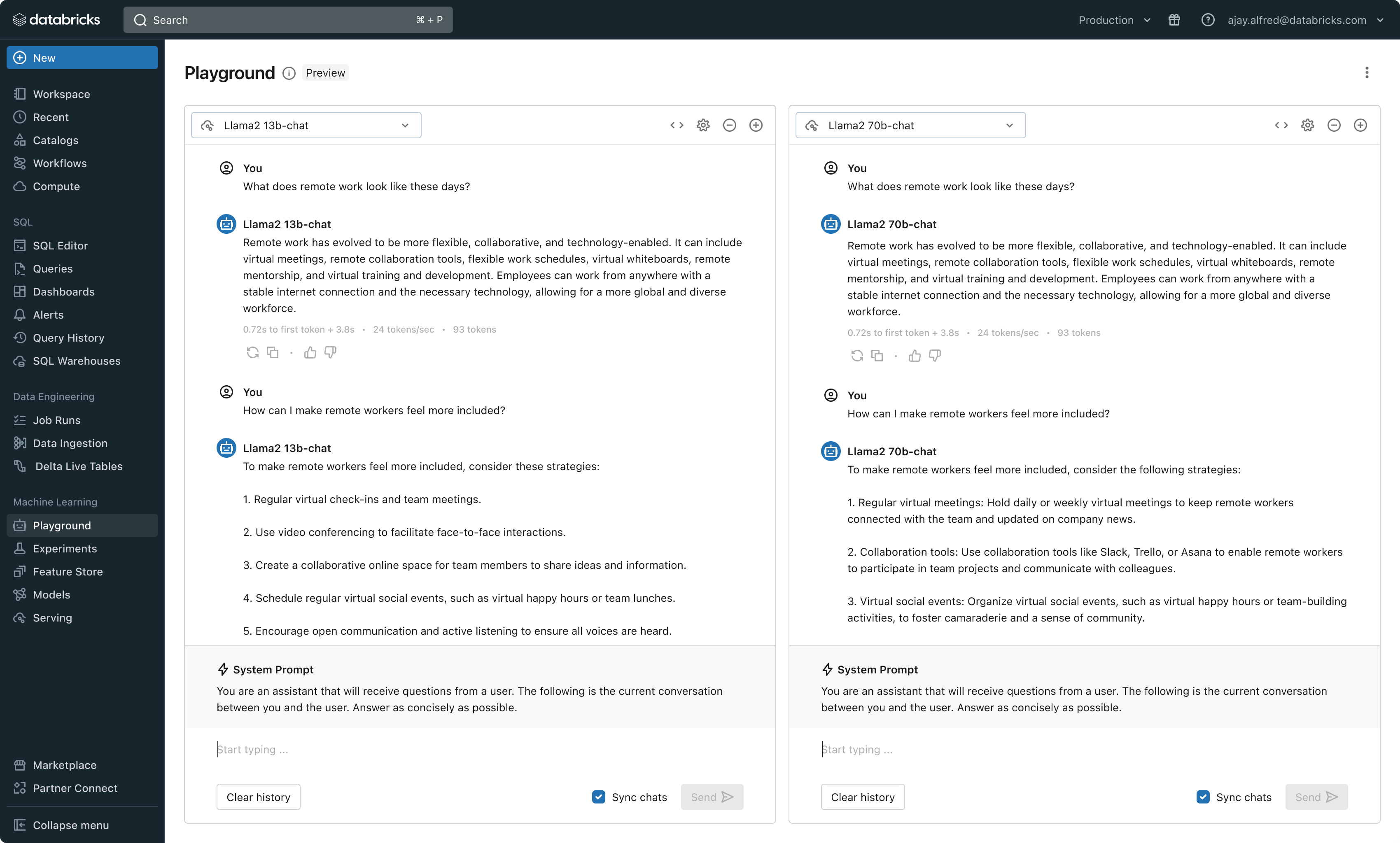
Databricks también está lanzando las API de modelos fundacionales, un conjunto totalmente administrado de modelos LLM que incluye las populares familias de modelos Llama y MPT. Las API de modelos fundacionales se pueden usar con un modelo de pago por token, lo que reduce drásticamente el costo y aumenta la flexibilidad. Como las API de modelos fundacionales se sirven desde la infraestructura de Databricks, los datos confidenciales no necesitan transitar a servicios de terceros.
En la práctica, lograr una alta calidad a menudo significa mezclar y combinar modelos base según los requisitos específicos de cada aplicación. La arquitectura de Model Serving de Databricks ahora ofrece una interfaz unificada para desplegar, gobernar y consultar cualquier tipo de LLM, ya sea un modelo totalmente personalizado, un modelo gestionado por Databricks o un modelo fundacional de terceros. Esta flexibilidad permite a los clientes elegir el modelo adecuado para la tarea adecuada y prepararse para los futuros avances en el conjunto de modelos disponibles.
Desafío n.º 3: garantizar la calidad y la seguridad en la producción
Una vez que se implementa una aplicación de LLM, puede ser difícil saber qué tan bien está funcionando. A diferencia del software tradicional, las aplicaciones basadas en el lenguaje no tienen una única respuesta correcta ni condiciones de “error” obvias. Esto significa que comprender la calidad (¿qué tan bien está funcionando?) o qué constituye un resultado anómalo, inseguro o tóxico (¿es seguro?) no es trivial. En Databricks, hemos visto que muchos clientes dudan en lanzar aplicaciones de RAG porque no están seguros de si la calidad observada en un pequeño prototipo interno se traducirá a su base de usuarios a escala.
Incluida en esta versión, Lakehouse Monitoring proporciona una solución de monitoreo de calidad totalmente administrada para aplicaciones de RAG. Lakehouse Monitoring puede escanear automáticamente los resultados de la aplicación para detectar contenido tóxico, alucinado o de algún otro modo inseguro. Luego, estos datos pueden alimentar paneles, alertas u otras canalizaciones de datos descendentes para tomar acciones posteriores. Como el monitoreo está integrado con el linaje de los conjuntos de datos y modelos, los desarrolladores pueden diagnosticar rápidamente errores relacionados con, p. ej., canalizaciones de datos obsoletas o modelos cuyo comportamiento ha cambiado inesperadamente.
El monitoreo no se trata solo de la seguridad, sino también de la calidad. Lakehouse Monitoring puede incorporar conceptos a nivel de aplicación, como los comentarios de los usuarios al estilo de “pulgar hacia arriba/pulgar hacia abajo”, o incluso métricas derivadas como la “tasa de aceptación del usuario” (la frecuencia con la que un usuario final acepta las recomendaciones generadas por la IA). Según nuestra experiencia, medir las métricas de usuario de extremo a extremo refuerza sustancialmente la confianza de las empresas en que las aplicaciones RAG funcionan bien en el entorno real. Los pipelines de monitoreo también son totalmente administrados por Databricks, por lo que los desarrolladores pueden dedicar tiempo a sus aplicaciones en lugar de administrar la infraestructura de observabilidad.
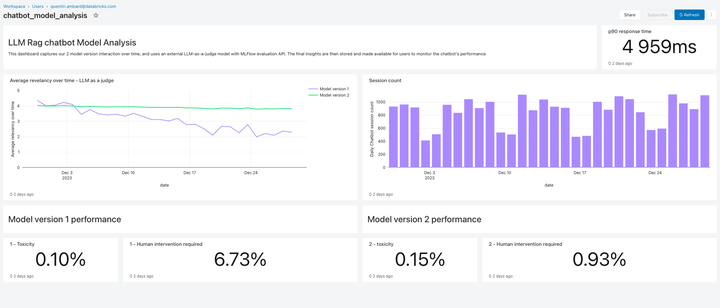
Las funciones de monitoreo de esta versión son solo el comienzo. ¡Pronto habrá mucho más!
Próximos pasos
Tenemos blogs detallados durante esta semana y la próxima que explican en detalle las mejores prácticas de implementación. Así que vuelve a nuestro blog de Databricks, explora nuestros productos a través de la nueva demostración de RAG, mira el webinar on-demand sobre IA generativa de Databricks, capacítate en IA generativa con nuestra ruta de aprendizaje para ingenieros de IA generativa y mira una rápida demostración en video del conjunto de herramientas de RAG en acción:
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.