De Legacy a Lakehouse: Cómo Mazda Aceleró GenAI para Operaciones de Servicio Técnico
Cómo un equipo ágil construyó un asistente GenAI gobernado utilizando RAG, Unity Catalog y Búsqueda Vectorial
por Tim Marx (Mazda), Foon Hoe Campbell-Wong (Mazda), Jiayi Wu, Arthur Dooner y Olivia Zhang
- Cómo Mazda utilizó Databricks Lakehouse para unificar el historial de servicio, diagnósticos y documentos como base para GenAI
- Cómo el equipo diseñó el asistente GenAI, incluyendo la recuperación de los documentos correctos y la lógica de compartición entre la interfaz de usuario y el agente
- Cómo Mazda pasó de pruebas GenAI ad hoc a evaluaciones y casos de prueba repetibles utilizando MLflow
Las organizaciones de servicio automotriz están bajo presión. El volumen de llamadas sigue aumentando, los vehículos eléctricos introducen una nueva complejidad de diagnóstico y los coches conectados generan más datos de los que los agentes de la línea de atención pueden procesar de manera realista. Cada año de modelo trae consigo cientos de documentos de información de servicio (SI), cada uno con procedimientos y condiciones únicas. Cuando algo cambia, los agentes de la línea de atención necesitan tiempo para asimilarlo antes de poder guiar con confianza a los técnicos a través de problemas desconocidos. Ese retraso importa cuando un cliente está esperando.
Mazda ya contaba con los ingredientes brutos para resolver esto: un creciente lakehouse de garantía, retiradas, códigos de diagnóstico, historial de servicio y del vehículo, así como una biblioteca en constante actualización de documentos de servicio. El desafío era reunir estos activos de una manera que mejorara la capacidad de los agentes para hacer su trabajo con precisión, consistencia y confianza.
Ahí es donde entró Databricks. El equipo de ciencia de datos de Mazda actuó con rapidez y aprendió haciendo, pasando del inicio a un concepto funcional en aproximadamente ocho semanas. No hubo una fase de planificación larga. El equipo construyó, probó, rompió cosas y ajustó sobre la marcha, entregando un piloto que tuvo un impacto y valor reales para Mazda.
Punto de partida: un equipo ágil con grandes ambiciones
Este proyecto fue una de las primeras iniciativas de GenAI de extremo a extremo de Mazda, construida completamente sobre su nueva plataforma de datos en la nube. El equipo era pequeño —dos científicos de datos iterando rápidamente— y las herramientas eran tempranas. Había que construir pipelines de datos. Los documentos debían extraerse y transformarse en índices de búsqueda vectorial. Los experimentos vivían en notebooks aislados, y el éxito dependía más de la memoria que de la trazabilidad.
Para un equipo tan ágil, la sobrecarga de infraestructura tenía que ser mínima. Ese fue un factor importante en la elección de Databricks. La plataforma permitió la agilidad: sin gestionar bases de datos vectoriales, sin configurar frameworks de cómputo distribuidos, sin orquestación a medida, sin servicios de pegamento para unirlo todo. El enfoque está en construir valor, no en infraestructura.
Construyendo el piloto
Al principio del piloto, el equipo se centró en un diseño de Generación Aumentada por Recuperación (RAG), con el objetivo principal de conectar un LLM con nuestro corpus personalizado. Pronto, Mazda notó que los probadores a menudo querían que los agentes tuvieran una imagen completa del vehículo primero: su historial de servicio, retiradas pendientes, escalaciones previas de la línea de atención, estado de la garantía.
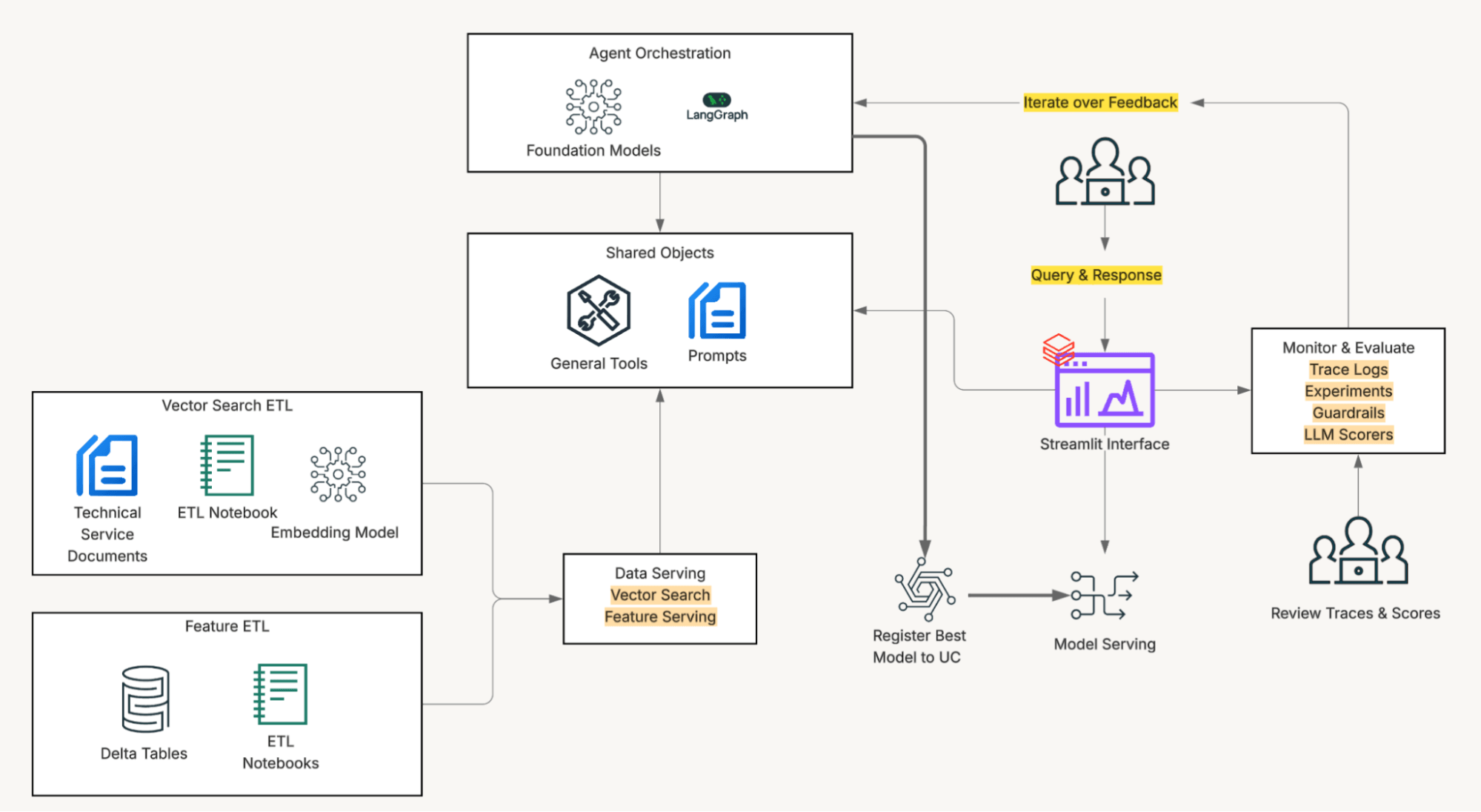
Esa observación dio forma a una elección arquitectónica deliberada: el frontend y el agente comparten código y herramientas. El acceso a los datos del vehículo, la transformación y la lógica de prompting se implementan una vez y se utilizan de forma idéntica tanto por la interfaz de Streamlit como por el endpoint del agente desplegado.
Cuando un agente de servicio introduce un VIN al inicio de una sesión, el frontend precarga el contexto completo del vehículo (historial de reparaciones, escalaciones de la línea de atención, datos de garantía, estado de retirada) y lo inyecta en el prompt del sistema antes de enviar el primer mensaje. Esto elimina las llamadas a herramientas y proporciona interactividad inmediata.
Por otro lado, si el agente de IA se invoca sin ese contexto precargado, utilizará el mismo conjunto de herramientas con el que interactúan los usuarios. La salida es estructuralmente idéntica de cualquier manera, y el prompt del sistema maneja ambos caminos explícitamente: usar el contexto inyectado si está presente, llamar a herramientas si no. Un prompt, dos modos de ejecución, sin deriva de comportamiento entre superficies.
Unity Catalog
La solución está impulsada por el Databricks Lakehouse. Unity Catalog proporciona acceso gobernado a los datos que los agentes de servicio utilizan a diario, y donde los embeddings, la búsqueda vectorial, las llamadas a herramientas SQL y la entrega de modelos se ejecutan en el mismo entorno, simplificando el desarrollo y eliminando la fricción de integración. Mazda utilizó LLMs a través de la API de modelos fundacionales (pago por token) y el modelo de embeddings a través del endpoint de búsqueda vectorial gestionado.
Todo vive dentro de Unity Catalog: documentos SI, tablas Delta con historial de vehículos y códigos de diagnóstico, índices de búsqueda vectorial, transformaciones de datos y modelos. La gobernanza unificada significa la capacidad de aislar el acceso a subconjuntos específicos de datos, realizar cambios sobre la marcha y observar el impacto de inmediato. Luego, Databricks Apps lo une todo con un frontend de Streamlit que los equipos de servicio pueden usar sin necesidad de nueva formación o herramientas.
Filtrado preciso del corpus, habilitado por Unity Catalog Functions
Una búsqueda vectorial ingenua en todo el corpus devuelve resultados que son semánticamente plausibles pero no necesariamente aplicables al vehículo que tiene delante el técnico. Conseguir una recuperación correcta significó resolver un problema de alcance antes de resolver un problema de relevancia.
El equipo implementó el filtrado a través de funciones definidas por el usuario de Unity Catalog. Antes de que se ejecute cualquier búsqueda vectorial, el sistema llama a una función de UC que mapea el VIN (o el código de diagnóstico de problemas) al subconjunto de documentos aplicables para ese vehículo, restringiendo la coincidencia semántica solo a los documentos que aplican.
Alojar esta lógica como una función de Unity Catalog en lugar de código de aplicación significó que las reglas de aplicabilidad viven junto a los datos que rigen, son accesibles tanto para el agente como para cualquier otra aplicación downstream, y pueden actualizarse independientemente del ciclo de implementación del agente.
De pruebas ad hoc a desarrollo impulsado por pruebas
Mazda probó la aplicación con 10 agentes de servicio testers. Al principio del piloto, la iteración se basaba en la retroalimentación: los testers informaban de problemas, el equipo ajustaba los prompts o la configuración de recuperación y evaluaba el resultado de forma informal. Eso funcionó para el desarrollo inicial, pero no escaló a medida que el sistema se volvía más complejo.
El framework de evaluación GenAI nativo de MLflow 3 cambió el flujo de trabajo del equipo. MLFlow 3 proporciona una forma integral de crear conjuntos de datos de evaluación y una variedad de puntuadores LLM y deterministas. Para pruebas rápidas, los borradores de conjuntos de datos de evaluación se definen en YAML antes de promocionarlos a un conjunto de datos de evaluación estándar. Cuando los testers detectaban una brecha, el equipo la añadía al conjunto de datos de evaluación y consideraba que pasar esas pruebas era el criterio de aceptación para cualquier corrección. Cuando se añadían nuevas características y fuentes de datos, se escribían nuevos casos de evaluación antes de que se aceptara la integración.
El resultado fue un cambio de "parece mejor" a "es mejor, y aquí están las pruebas". Los rastros de experimentos capturaron prompts, estrategias de recuperación, recuentos de tokens y métricas de calidad de respuesta para que los cambios pudieran compararse objetivamente en lugar de por memoria.
Capacidad multilingüe
El rápido éxito inicial planteó la pregunta de si la misma arquitectura podría servir a otras localidades. Después de experimentar con modelos de embeddings multilingües, el equipo se dio cuenta de que el LLM puede traducir los prompts del usuario y la respuesta final, sin hacer modificaciones a la arquitectura y herramientas principales. Eso tiene implicaciones para los planes más amplios de Mazda de expandir la aplicación a otros mercados.
Gobernanza
Alinear los permisos entre Apps, clusters, warehouses, endpoints y agentes tuvo una curva de aprendizaje, pero una vez estandarizado, creó un patrón de gobernanza reutilizable que es seguro y aplicable a futuras aplicaciones GenAI. El patrón que funcionó: enrutar todo el acceso a través del principal de servicio del endpoint de entrega, y definir concesiones a nivel de catálogo y esquema para grupos de control de acceso basado en roles. Una vez establecido, se volvió reutilizable: incorporar un nuevo modelo o fuente de datos significaba otorgar acceso al mismo principal de servicio contra el mismo esquema, no renegociar la estructura de permisos. Combinado con conectividad privada para el tráfico de IA, esto le da a Mazda un camino controlado y seguro entre las aplicaciones y los datos gobernados.
La asociación con el equipo de ingeniería de campo de Databricks permitió a Mazda avanzar más rápido, guiado por las mejores prácticas y previniendo obstáculos.
Impacto y próximos pasos
Mazda ahora tiene una base repetible para aplicaciones GenAI que combinan datos estructurados y no estructurados, todo dentro del lakehouse: índices de búsqueda vectorial, entrega de modelos, evaluaciones, observabilidad, gobernanza a nivel de catálogo y entrega frontend a través de una aplicación web. Tener estas capacidades en una sola plataforma eliminó la necesidad de unir múltiples servicios, lo que aceleró el desarrollo muchas veces.
Dos científicos de datos que comenzaron con notebooks aislados ahora ejecutan aplicaciones y experimentos de IA con trazabilidad completa en Databricks. El equipo está expandiendo el enfoque a flujos de trabajo de diagnóstico adicionales y explorando cómo los agentes generativos pueden apoyar a los técnicos, ingenieros de campo y soporte al cliente.
Este cambio no es solo técnico. Mueve a Mazda de la generación de informes descriptivos a aplicaciones inteligentes y generativas construidas directamente sobre datos empresariales gobernados.
Conclusión
No necesitas un equipo grande ni una práctica de MLOps madura para crear aplicaciones GenAI significativas. Mazda tenía dos científicos de datos, plazos ajustados y mucho que aprender. Databricks como Plataforma realizó más del trabajo pesado de lo esperado, y Databricks nos ayudó a lanzar algo real, rápidamente.
En su esencia, el proyecto es una expresión de omotenashi — el principio rector de Mazda de hospitalidad de todo corazón. Brindar a los agentes de servicio técnico de Mazda mejores herramientas les ayuda a cuidar mejor a sus clientes. Y ahora, con esta base establecida, el equipo apenas está comenzando.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.