LLM en el lakehouse: un avance gigante para el sector público
por Tim Lortz, Parth Vakil y Lisa Sion

En los últimos meses, el interés en los Modelos de Lenguaje Grandes (LLM) por parte de las agencias del sector público se ha disparado, ya que los LLM están cambiando fundamentalmente las expectativas que la gente tiene en sus interacciones con las computadoras y los datos. Desde el punto de vista de Databricks, prácticamente todos los clientes y prospectos del sector público con los que interactuamos sienten el mandato de incorporar los LLM a su misión. Constantemente recibimos preguntas sobre qué son los LLM (como Dolly de Databricks), para qué se pueden usar y cómo Databricks Lakehouse dará soporte a las aplicaciones relacionadas con los LLM. En esta publicación, abordaremos estas preguntas en el contexto de las necesidades, oportunidades y limitaciones únicas de las organizaciones del sector público. También nos centraremos en los beneficios de crear, tener y curar su propio LLM frente a la adopción de una tecnología que requiere el intercambio de datos con terceros, como ChatGPT.
¿Qué son los LLM?
Los LLM actuales representan la última versión de una serie de innovaciones en el procesamiento del lenguaje natural, que comenzaron aproximadamente en 2017 con el auge de la arquitectura del modelo transformer. Estos modelos basados en transformers han poseído durante mucho tiempo capacidades asombrosas para comprender el lenguaje humano lo suficientemente bien como para realizar tareas como identificar sentimientos, extraer nombres de personas, lugares y cosas, y traducir documentos de un idioma a otro. También han sido capaces de generar texto interesante a partir de un prompt, con diversos grados de calidad y precisión. Más recientemente, los investigadores y desarrolladores han descubierto que los modelos de lenguaje muy grandes, "preentrenados" en fuentes de texto muy grandes y diversas, pueden ser "ajustados" para seguir una variedad de instrucciones de un humano para generar información útil.
Anteriormente, la mejor práctica era entrenar modelos separados para cada tarea relacionada con el lenguaje. El proceso de entrenamiento de modelos requería recursos: datos curados, capacidad de cómputo (generalmente, una o más GPU) y conocimientos avanzados en ciencia de datos y desarrollo de software. Si bien dichos modelos pueden ser muy precisos, existen claras limitaciones de recursos, tanto en términos de computación como de esfuerzo humano, al ampliar su uso. Con el rápido ascenso de ChatGPT al estrellato, ahora vemos que un único LLM, con la cantidad adecuada de contexto y el prompt correcto, se puede usar para realizar muchas tareas diferentes, a veces con mayor precisión que un modelo más especializado. Y la capacidad de los LLM para generar texto nuevo ("IA generativa") es fascinante y extremadamente útil.
¿Para qué se pueden usar los LLM en el sector público?
Las organizaciones del sector privado han informado de increíbles beneficios de los LLM, como la generación y migración de código, la categorización y respuesta automatizada a los comentarios de los clientes, los chatbots de los centros de llamadas, la generación de informes y mucho más. Como microcosmos de muchas industrias diferentes, las agencias del sector público tienen las mismas oportunidades con los LLM, además de otras necesidades únicas. Los casos de uso comunes del sector público incluyen:
- Asistencia para el cumplimiento normativo. Con su capacidad para interpretar y procesar texto, un LLM puede ayudar a determinar los requisitos de cumplimiento mediante el análisis de documentos normativos, textos legales y jurisprudencia pertinente. Puede ayudar a las agencias gubernamentales y a las empresas a comprender las implicaciones de las regulaciones y garantizar el cumplimiento de la ley.
- Asistente de capacitación y educación. Amplíe y acelere el aprendizaje de los estudiantes actuando como instructor virtual, respondiendo preguntas, explicando conceptos complejos, recuperando partes relevantes de las grabaciones de las clases o recomendando ofertas del catálogo de cursos.
- Resumir y responder preguntas de documentos técnicos. Quizás el caso de uso más ubicuo relacionado con los LLM en el sector público es extraer conocimiento de miles o millones de documentos, incluidos PDF y correos electrónicos, en un formato que permita encontrar rápidamente contenido relevante basado en criterios de búsqueda y, luego, usar el contenido relevante para generar resúmenes o informes.
- Inteligencia de fuentes abiertas. Los LLM pueden mejorar en gran medida el análisis de la Inteligencia de Fuentes Abiertas (OSINT) por parte de la Comunidad de Inteligencia al procesar y analizar grandes cantidades de información multilingüe disponible públicamente. Los LLM pueden extraer entidades clave, relaciones, opiniones y comprensión contextual de diversas fuentes, como redes sociales, artículos de noticias e informes, para luego resumir y organizar esta información de manera eficiente, lo que ayuda a los analistas a comprender y extraer información de valor rápidamente de grandes volúmenes de datos de OSINT.
- Modernización de las bases de código heredado. Las agencias gubernamentales continúan migrando las cargas de trabajo de datos fuera de los mainframes, los almacenes de datos locales y el software de análisis propietario. Al poner asistentes de codificación en manos de desarrolladores y analistas para que sugieran código sobre la marcha, o al entrenar LLM personalizados para gestionar la conversión de código en masa, el ritmo de la migración puede acelerarse mientras los trabajadores del conocimiento adquieren con facilidad las habilidades de software relevantes.
- Recursos humanos. Como el empleador más grande de la nación, el gobierno federal enfrenta desafíos únicos en la contratación y para garantizar la satisfacción de los empleados. Aprovechar los LLM en el campo de RR. HH. puede ayudar a abordar estos desafíos mediante la automatización de la selección de currículums, la correspondencia de candidatos con las descripciones de los puestos y el análisis de los comentarios de los empleados para mejorar los procesos de contratación y aumentar el compromiso de la fuerza laboral. Además, los LLM pueden ayudar a garantizar el cumplimiento de las políticas de RR. HH., apoyar las iniciativas de diversidad e inclusión y proporcionar recomendaciones personalizadas de incorporación y desarrollo profesional.
¿Cómo apoyará Databricks las necesidades de las organizaciones del sector público en un mundo impulsado por los LLM?
Aunque ciertamente son potentes, los LLM también introducen un nuevo conjunto de desafíos que se ven amplificados por algunas de las limitaciones operativas propias de las organizaciones del sector público. Analicemos algunas de ellas y alineémoslas con las capacidades de Databricks Lakehouse:
Desafío n.º 1: Soberanía y gobernanza de datos
¿El desafío?
La mayoría de las organizaciones del sector público tienen estrictos controles normativos sobre sus datos. Estos controles existen para la privacidad, la seguridad y la necesidad de mantener la confidencialidad en algunos casos. Incluso la sencilla tarea de hacer una o varias preguntas a un LLM podría revelar información confidencial. Además, la mayoría de las agencias federales necesitarán ajustar los LLM para satisfacer sus requisitos particulares. Por estas razones, es lógico suponer que las agencias del sector público verán limitado su uso de modelos públicos. Es probable que requieran que los modelos se ajusten en un entorno que garantice su confidencialidad y seguridad, y que las interacciones con los modelos a través de diversos métodos de consulta (prompting) también sean confidenciales.
La solución de Databricks
La plataforma Lakehouse de Databricks tiene las herramientas necesarias para desarrollar e implementar aplicaciones de LLM de extremo a extremo. (Hablaremos de eso más adelante). Además, Databricks posee las certificaciones necesarias para procesar datos para la gran mayoría de las organizaciones del sector público de EE. UU. Databricks es un socio confiable y capaz para las organizaciones que buscan aprovechar todo el poder de los LLM sin los riesgos que conlleva el uso de LLM patentados como servicio, como ChatGPT o Bard.
Más allá de Databricks, la industria está viendo cada vez más evidencia de que los LLM de código abierto, si se usan de forma adecuada, pueden ofrecer resultados que se acercan a la paridad con los principales LLM propietarios. La evidencia es más sólida en los casos de uso en los que los LLM propietarios deben comprender instrucciones o contextos con matices para los que no han sido entrenados previamente. En estos casos, a los LLM de código abierto se les pueden dar instrucciones o se los puede ajustar con datos específicos de la organización para ofrecer resultados asombrosos. En esta arquitectura de soluciones, las organizaciones pueden lograr resultados de primer nivel con cantidades modestas de tiempo de computación y desarrollo, sin que los datos salgan de los límites aprobados. Para las organizaciones del sector público, esto representa una ventaja significativa que no se puede pasar por alto.
La creencia de Databricks en el poder de los LLM de código abierto se refuerza con el lanzamiento de Dolly 2.0, el primer LLM de código abierto que sigue instrucciones, ajustado con un conjunto de datos de instrucciones generado por humanos y con licencia para la investigación y el uso comercial. Al lanzamiento de Dolly le ha seguido una ola de otros LLM de código abierto muy capaces, algunos de los cuales tienen un rendimiento muy impresionante. Databricks se esfuerza por ofrecer a las organizaciones del sector público una plataforma para crear aplicaciones con el LLM de su elección, ya sea de código abierto o comercial, y estamos entusiasmados por lo que está por venir.

Desafío n.º 2: Complejidad arquitectónica
¿El desafío?
La modernización del patrimonio de datos sigue siendo una de las principales prioridades para la mayoría de los líderes técnicos del sector público. Atrás quedaron los días de los data warehouses on-premise, que suelen ser reemplazados por un data warehouse o un lakehouse en la nube. Las organizaciones que aún no han migrado a la nube, o que optaron por un almacén de datos en la nube, ahora se enfrentan a otro punto de inflexión: ¿cómo adoptar los LLM en una arquitectura que no los admite? Dado el inmenso potencial de los LLM para impactar las misiones de las agencias y a los servidores públicos que las cumplen, es fundamental establecer una arquitectura preparada para el futuro. Presentamos el lakehouse.
La solución de Databricks
Databricks ha sido desde hace mucho tiempo un entorno capaz para las cargas de trabajo de machine learning (ML) e inteligencia artificial (IA). Los clientes han estado usando LLM de nivel de producción y sus predecesores en Databricks durante años, aprovechando características como:
- Cómputo escalable para el preprocesamiento de datos no estructurados como texto, imágenes y audio
- Acceso al conjunto completo de bibliotecas de ML/AI de código abierto
- Un entorno de desarrollo de notebooks nativo de primera clase, con excelente soporte para la integración de IDE también
- Capacidades de gobernanza de datos a través de Unity Catalog que garantizan los controles de acceso adecuados a
- Datos estructurados (bases de datos y tablas)
- Datos no estructurados (archivos, imágenes, documentos)
- Modelos (LLM o de otro tipo)
- Opciones de computación en GPU para el entrenamiento y las predicciones de modelos de ML, ahora un prerrequisito para trabajar con LLM basados en transformers
- Gestión del ciclo de vida de modelos de extremo a extremo con MLflow y Unity Catalog. Los modelos se tratan como ciudadanos de primera clase, con linaje a sus datos de origen y eventos de entrenamiento, y se pueden implementar en modo por lotes o en tiempo real.
- Capacidades de servicio de modelos, que se vuelven cada vez más críticas a medida que las organizaciones ajustan, alojan e implementan sus propios LLM.
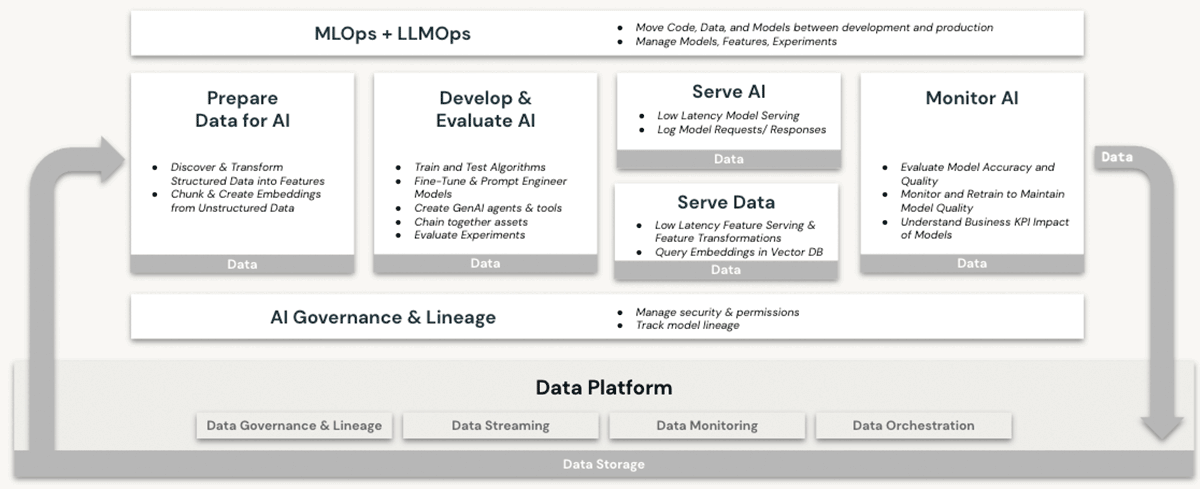
Ninguna de estas características se ofrece en un data warehouse, ni siquiera en la nube. Para usar los LLM junto con un data warehouse, una organización necesitaría adquirir otros servicios de software para todos los aspectos de los procesos de entrenamiento e implementación de modelos, y enviar datos de ida y vuelta entre estos servicios. Solo la arquitectura Lakehouse de Databricks ofrece la simplicidad arquitectónica de realizar todas las operaciones de LLM en una única plataforma, lo que permite aprovechar al máximo los beneficios explicados anteriormente en nuestro análisis sobre la soberanía de los datos.
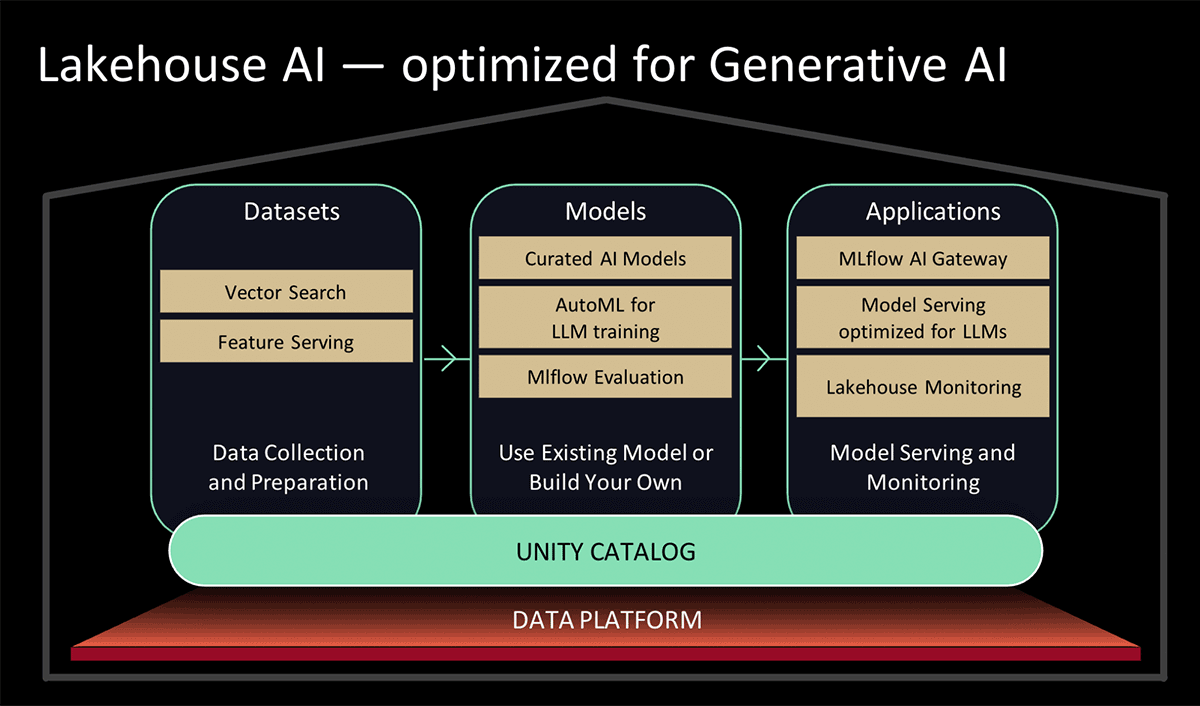
En el Data and AI Summit 2023, Databricks presentó Lakehouse AI, que agrega varias características nuevas e importantes relacionadas con los LLM que simplifican significativamente la arquitectura para LLMOps, entre las que se incluyen:
- AI Search para indexación. Una base de datos de vectores alojada en Databricks ayuda a los equipos a indexar rápidamente los datos de sus organizaciones como vectores de embedding y a realizar búsquedas de similitud de vectores de baja latencia en implementaciones en tiempo real.
- Monitoreo de Lakehouse El primer servicio unificado de monitoreo de datos e IA que permite a los usuarios hacer un seguimiento simultáneo de la calidad tanto de sus datos como de sus activos de IA.
- Funciones de AI. Los analistas e ingenieros de datos ahora pueden usar LLM y otros modelos de machine learning en una consulta SQL interactiva o una canalización de ETL de SQL/Spark.
- Gobernanza unificada de datos e IA. Mejoras en el Unity Catalog para proporcionar una gobernanza integral y un seguimiento del linaje de los activos de datos e IA en una única experiencia unificada.
- MLflow AI Gateway. El MLflow AI Gateway, que forma parte de MLflow 2.5, es una puerta de enlace de API a nivel de espacio de trabajo que permite a las organizaciones crear y compartir rutas, que luego se pueden configurar con varios límites de velocidad, almacenamiento en caché, atribución de costos, etc., para gestionar los costos y el uso.
- MLflow 2.4. Esta versión ofrece un conjunto completo de herramientas de LLMOps para la evaluación de modelos.
Desafío n.º 3: Brecha de habilidades
¿El desafío?
Las agencias gubernamentales han luchado con una persistente "fuga de cerebros" en los últimos años, particularmente en roles que se superponen con las tendencias tecnológicas en auge, como la ciberseguridad, la computación en la nube y el ML/AI. El intenso enfoque actual en los LLM está impulsando aún más la demanda de profesionales con talento en ML/AI. Inevitablemente, el atractivo y los beneficios que conlleva el empleo en las grandes empresas tecnológicas y el ecosistema de las startups exacerbarán la escasez de talento en el sector público. Los líderes gubernamentales necesitan acceso a plataformas y alianzas que los ayuden a adoptar fácilmente los LLM y a empoderar a sus empleados para que se vuelvan autosuficientes con ellos.
La solución de Databricks
Databricks está implementando funciones que simplifican y amplían las capacidades existentes para trabajar con los LLM en la plataforma lakehouse. Estas incluyen:
- Patrones simplificados para usar LLM preentrenados de Hugging Face para tareas de inferencia en canalizaciones de datos, o para realizar su ajuste fino y obtener un mejor rendimiento con sus propios datos en Databricks.
- Simplificando el proceso y mejorando el rendimiento de la carga de datos desde Apache Spark a Hugging Face para trabajos de entrenamiento de modelos o de ajuste fino.
- Aceleradores de soluciones de LLM específicos de la industria, que muestran patrones de implementación repetibles para obtener resultados rápidos, como el análisis del servicio al cliente y el descubrimiento de productos.
- El lanzamiento de MLflow 2.3, que incluye compatibilidad nativa con LLM, en particular:
- Tres tipos de modelos completamente nuevos: Hugging Face Transformers, funciones de OpenAI y LangChain.
- Mejora significativa de la velocidad de descarga y carga de modelos desde y hacia los servicios en la nube mediante la descarga y carga multiparte para los archivos de modelo.
- Una función integrada de Databricks SQL que permite a los usuarios acceder a los LLM directamente desde SQL. Esta función puede evitar los largos y complejos procesos de desarrollo de modelos de lenguaje al permitir que los analistas simplemente elaboren prompts de LLM eficaces.
- Como se anunció en el Data & AI Summit 2023,
- Incorporaciones al servicio de AutoML basado en la IU de Databricks que ajustarán con precisión los LLM para la clasificación de texto, así como los modelos de embedding; y
- Modelos seleccionados, respaldados por un Model Serving optimizado para un alto rendimiento. En lugar de pasar tiempo investigando los mejores modelos de IA generativa de código abierto para su caso de uso, puede confiar en los modelos seleccionados por expertos de Databricks para casos de uso comunes.
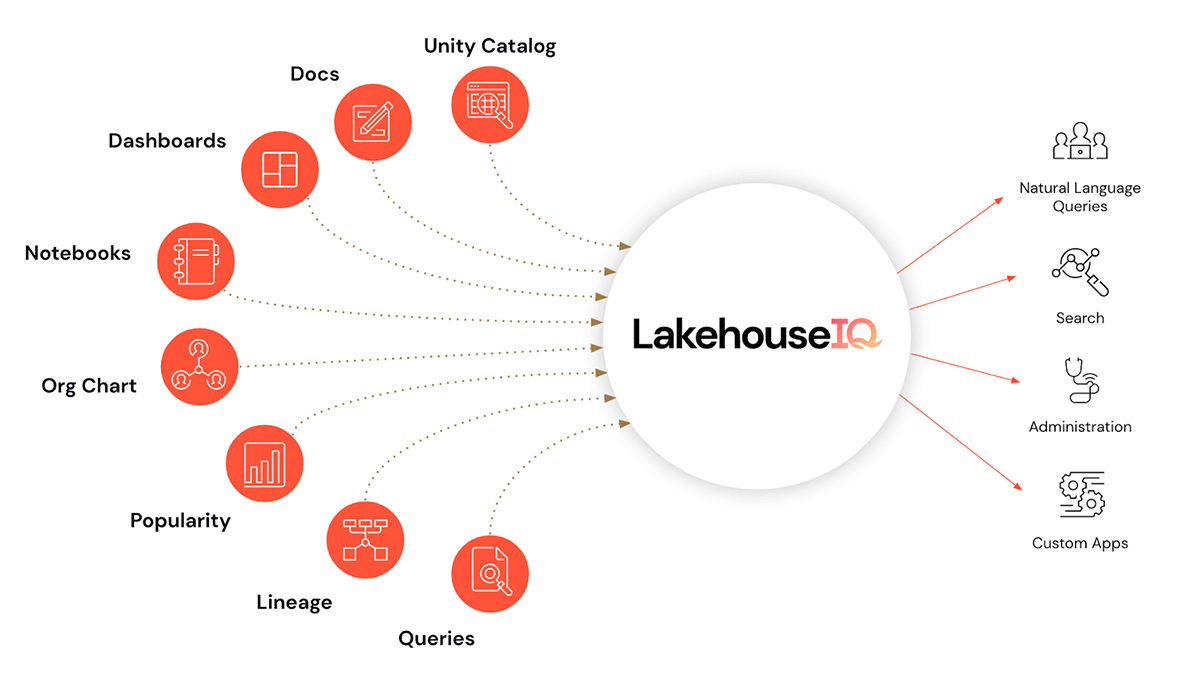
- Y quizás la cereza del pastel, LakehouseIQ, un motor de conocimiento que aprende los matices únicos de su negocio y sus datos para potenciar el acceso a ellos en lenguaje natural para una amplia gama de casos de uso.
Además de facilitar el uso de los LLM en Databricks, también presentamos programas de capacitación y habilitación de LLM para ayudar a las organizaciones a ampliar su dominio de los LLM. Estos se ofrecen a un nivel accesible para los usuarios del sector público de Databricks.
- Asociación con EdX para ofrecer cursos en línea dirigidos por expertos que se centran específicamente en la creación y el uso de modelos de lenguaje en aplicaciones modernas
Conclusiones y próximos pasos
Abundan las oportunidades para aprovechar los LLM y acelerar los casos de uso del sector público. Un valor inmenso permanece oculto en los datos heredados, esperando a ser descubierto y aplicado a los problemas actuales. Descubra cómo Databricks puede ayudarlo a adoptar los LLM para su misión participando en nuestro webinar Modelos de lenguaje grandes en el sector público el 2 de agosto al mediodía, EDT. Además, consulte los registros para las vistas previas de características que figuran en el anuncio de Lakehouse AI y vea para cuáles califica su organización.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.