Mitigación del riesgo de la inyección de prompts para los agentes de IA en Databricks
por JD Braun, Arun Pamulapati, Andrew Weaver, Nishith Sinha, Caelin Kaplan, Alex Warnecke y Jean Verrons
- Los agentes de IA autónomos necesitan datos sensibles, entradas no confiables y acciones externas para ser útiles, pero la combinación de los tres crea cadenas de ataque explotables.
- El equipo de seguridad de Databricks desarrolló una guía práctica para proteger los agentes de IA en Databricks utilizando la "Regla de los Dos de los Agentes" de Meta, un marco para mitigar el riesgo de inyección de prompts.
- La guía cubre nueve controles específicos en capas en Databricks que abarcan el acceso a los datos, la validación de entradas y las restricciones de salida para reducir los riesgos de inyección de prompts.
Descripción general
Desde que lanzamos el Marco de Seguridad de IA de Databricks (DASF) en 2024, el panorama de amenazas para la IA ha cambiado drásticamente. La IA ha pasado de ser el chatbot estereotipado a convertirse en agentes que pueden razonar, usar herramientas y realizar acciones en nombre de los usuarios con poca o ninguna intervención. Los equipos de seguridad ya no solo tienen que pensar en los usuarios que interactúan con los modelos, sino que también tienen que pensar en un enjambre de agentes inteligentes que actúan de forma autónoma, interactúan con servicios a través de MCP y exploran internet por su cuenta.
La inyección de prompts era un riesgo conocido en la era de la inferencia, pero se limitaba en gran medida a la solicitud y respuesta del usuario. Con los agentes que pueden realizar acciones de forma autónoma, el riesgo ha aumentado exponencialmente.
Pensemos en un profesional de datos que le encarga a su agente de IA la tarea de escribir un script que llame a una API de terceros. El agente busca documentación en Internet, redacta el código y lo ejecuta. Lo que el usuario no se da cuenta es que la página de documentación tenía un prompt malicioso incrustado, uno que indicaba al agente que exfiltrara las credenciales del entorno de computación del usuario a un webhook. Los ataques como este están bien documentados en la práctica. Pero existen frameworks que nos ayudan a razonar sobre cuándo y por qué tienen éxito.
Investigaciones recientes de la industria, incluida la "Regla de dos de los agentes" de Meta y modelos similares como la "Trifecta letal" de Simon Willison, destacan las condiciones bajo las cuales los ataques de inyección de prompt tienen éxito. Estos patrones se alinean estrechamente con los controles definidos en el Databricks AI Security Framework (DASF), que proporciona un modelo práctico para proteger a los agentes de IA que operan con datos empresariales.
Ambos llegan a la misma conclusión: un agente de IA se vuelve vulnerable a la inyección de prompts cuando tiene las tres características siguientes y, para mitigar el riesgo, solo se le deberían permitir dos:
- Acceso a sistemas confidenciales o datos privados
- Exposición a entradas no confiables
- La capacidad de cambiar de estado o comunicarse externamente
En la práctica, estos riesgos se corresponden directamente con los controles de defensa en profundidad definidos en Databricks AI Security Framework (DASF), que organiza la seguridad de la IA en el acceso a los datos, la interacción con el modelo y la ejecución operativa. En las siguientes secciones, mostramos cómo pueden mitigarse estos riesgos mediante los controles nativos de la plataforma de Databricks.
Comprensión de los riesgos principales para los agentes de IA
Como se mencionó en la descripción general, el framework de la Regla de Dos para Agentes de Meta ayuda a desglosar los pilares fundamentales que hacen que los agentes de IA sean vulnerables a la inyección de prompts:
- Acceso a sistemas sensibles o datos privados: El agente puede leer o interactuar con datos sensibles del usuario.
- Procesar entradas no confiables: El agente puede consumir contenido proporcionado por fuentes externas o controladas por atacantes.
- Cambiar de estado o comunicarse externamente: El agente puede realizar acciones fuera de su entorno local, como realizar solicitudes HTTP o modificar sistemas externos.
Cuando los tres pilares están presentes, el sistema ya tiene acceso a sistemas confidenciales o datos privados (primero), y un atacante puede entonces inyectar instrucciones maliciosas a través de entradas no confiables (segundo), haciendo que el agente exfiltre esos datos externamente (tercero). En esta sección, exploraremos cómo se aplica cada uno de estos en el contexto de Databricks.
Pilar 1: Acceso a sistemas sensibles o datos privados
Para que un atacante pueda exfiltrar algo valioso, el agente primero necesita tener acceso a ello. Este es el primer pilar de la Regla de los Dos de los Agentes y, en la práctica, casi nunca es opcional. Los agentes son más útiles cuando pueden operar con datos reales y de alto valor. Se utilizan cada vez más para tareas como el análisis de sentimiento de los comentarios de los clientes, la previsión de la demanda, la detección de fraudes o la asistencia de código. Para ser eficaces, a estos agentes se les concede deliberadamente acceso a registros de clientes, historiales de transacciones, documentos de propiedad exclusiva o grandes bases de código internas. En otras palabras, los mismos datos que dan a las organizaciones una ventaja competitiva son también los datos que más interesan a los atacantes.
Como plataforma unificada de datos e inteligencia, Databricks está diseñada para centralizar y procesar los conjuntos de datos más valiosos de una organización. Las aplicaciones y los agentes que se ejecutan en la plataforma operan, por diseño, cerca de información sensible. Esto significa que, en muchas implementaciones del mundo real, se debe asumir que el primer pilar de la Regla de los Dos de los Agentes está presente, en lugar de tratarlo como una preocupación hipotética.
Pilar 2: Procesar entradas no confiables
El segundo pilar de la Regla de Dos de los Agentes se centra en cómo los datos no confiables ingresan al sistema. En el caso más simple, este riesgo es obvio: una interfaz de chat de LLM puede aceptar directamente la entrada del usuario que contiene instrucciones maliciosas. Esto es la inyección directa de prompts, donde el atacante suministra la carga útil explícitamente como parte de la interacción.
Sin embargo, el riesgo se extiende más allá de la entrada directa del usuario. Los agentes y las aplicaciones basadas en LLM a menudo recuperan y procesan datos de fuentes externas como bases de datos, documentos, API o bases de conocimiento. En estos casos, las instrucciones maliciosas pueden estar incrustadas en contenido que de otro modo sería legítimo y solo aparecen cuando el agente lee o razona sobre esos datos. Esto es la inyección de prompt indirecta. El desafío se agrava por el hecho de que los LLM modernos están diseñados para interpretar una amplia gama de entradas, que incluyen lenguaje natural, datos estructurados, caracteres especiales, imágenes y cargas útiles codificadas. Esta diversidad hace que las instrucciones maliciosas sean difíciles de detectar utilizando técnicas tradicionales de validación de entradas.
En la plataforma Databricks, la diversidad de fuentes de datos hace que esto sea particularmente relevante. Una sola tabla de Unity Catalog podría contener registros de transacciones de un sistema de gestión de pedidos, conversaciones de soporte entre el personal y los clientes, o comentarios sobre productos enviados a través de un formulario web. Cuando a un agente se le da acceso a esos datos, es importante hacer una pregunta simple pero crítica: ¿podría alguna parte de estos datos haber sido influenciada por un actor externo?
Si la respuesta es sí, entonces el segundo pilar de la Regla de dos de los agentes ya está implementado.
En la práctica, esta evaluación rara vez es sencilla. A menudo requiere rastrear los datos hasta su fuente original y considerar puntos de inyección menos obvios, como comentarios, campos de texto libre, metadatos o archivos adjuntos, donde podrían incrustarse instrucciones maliciosas. Lo que parece ser un dato comercial ordinario puede ser, desde la perspectiva de un agente, una guía ejecutable.
Pilar 3: Cambiar de estado o comunicarse externamente
El último pilar de la Regla de los Dos de los Agentes se centra en lo que realmente se le permite hacer al agente y, por lo tanto, en cuán grande puede llegar a ser el radio de impacto de un ataque. En las primeras aplicaciones de LLM, el modelo era efectivamente de solo lectura. Un usuario proporcionaba un prompt, el modelo generaba una respuesta y esa respuesta simplemente se mostraba. Incluso si un atacante influía en el resultado del modelo, el impacto generalmente se limitaba al texto que se le mostraba al usuario, ya que el modelo no tenía la capacidad de acceder a datos privados en tiempo de ejecución ni de ejecutar acciones.
Los agentes modernos son fundamentalmente diferentes. Ya no se limitan a producir texto, sino que también pueden cambiar el estado a través de acciones como la ejecución de código Python o la ejecución de consultas SQL, y comunicarse externamente mediante llamadas a API o interactuando con sistemas a través de mecanismos como el Protocolo de Contexto de Modelo (MCP).
En la plataforma Databricks, los agentes creados con capacidades de IA pueden conectarse fácilmente a servidores MCP, funciones definidas por el usuario o API externas. Durante la fase de diseño, es importante considerar no solo el uso previsto de estas herramientas, sino también su posible mal uso. Si una herramienta le permite al agente comunicarse externamente o sobrescribir tablas, el último pilar de la Regla de dos de los agentes está activo.
Al igual que con los otros pilares, obtener una visión completa de las capacidades del agente no siempre es sencillo. Una herramienta que parece inofensiva a primera vista aún puede usarse de maneras inesperadas. Por lo tanto, los desarrolladores deben pensar en términos de capacidades efectivas, es decir, lo que el agente podría hacer bajo una influencia adversaria, no solo las tareas para las que fue diseñado.
Uniendo todas las piezas
Tomados individualmente, cada uno de los tres pilares puede parecer manejable. La inyección de prompts es menos preocupante si el agente no puede acceder a datos sensibles. El acceso a datos sensibles es menos riesgoso si el agente no tiene la capacidad de actuar sobre ellos. Y las herramientas potentes son menos peligrosas si el agente solo procesa entradas confiables. El riesgo se vuelve significativo cuando estos factores convergen. Bajo esas condiciones, un adversario puede influir en el comportamiento del agente de maneras que van más allá de su uso previsto, convirtiendo lo que parece ser una interacción rutinaria en un incidente de seguridad con consecuencias en el mundo real.
Desde una perspectiva defensiva, esto nos da un principio de diseño práctico: intentar dividir los tres pilares. En la mayoría de las aplicaciones de IA del mundo real, es difícil eliminar por completo un único elemento. Los agentes necesitan datos para ser útiles, deben procesar diversas entradas y, a menudo, necesitan herramientas para automatizar tareas. Aun así, existen formas concretas de contener el riesgo asociado a cada pilar.
En muchas plataformas de IA, estos riesgos se abordan a través de un mosaico de herramientas que abarcan sistemas de identidad, controles de red, puertas de enlace de modelos y soluciones de gobernanza de datos. Databricks adopta un enfoque diferente. Debido a que los datos, los modelos de IA y las aplicaciones se ejecutan en una plataforma unificada regida por Unity Catalog y Agent Bricks, las organizaciones pueden aplicar controles en capas en todo el sistema de IA (desde el acceso a los datos hasta la interacción del modelo y la ejecución en tiempo de ejecución) sin introducir silos de seguridad adicionales.
La plataforma Databricks proporciona controles en cada una de estas capas, que exploraremos en las siguientes secciones utilizando un ejemplo de la vida real, nuestro nuevo agente de IA: Social Gauge.
Controles para los riesgos de inyección de prompts en agentes de IA por pilar
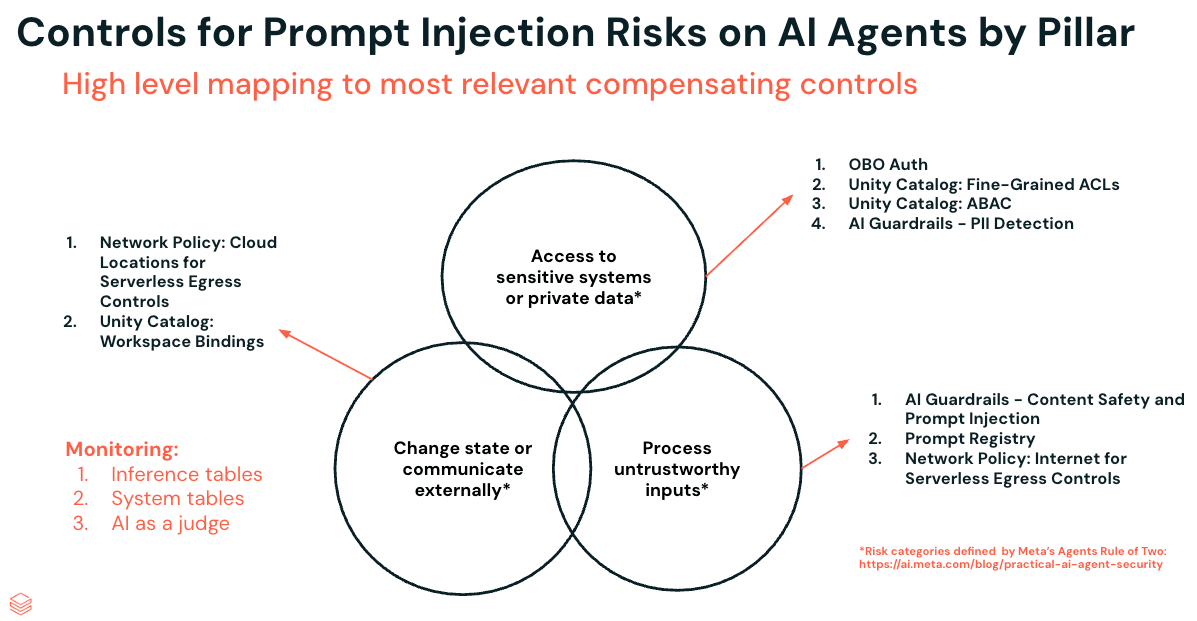
La forma más eficaz de mitigar la inyección de prompts es eliminar por completo uno de los tres pilares; eso sigue siendo cierto. Pero en la práctica, la mayoría de los agentes necesitan cierto grado de los tres: acceso a datos sensibles, exposición a entradas externas y la capacidad de realizar acciones. Así que, en lugar de eliminar un pilar, el objetivo pasa a ser reforzar cada uno para reducir la superficie de ataque.
Repasaremos nueve controles en los tres pilares utilizando un ejemplo práctico: Social Gauge, un agente integrado en una Databricks App que extrae datos de redes sociales y fuentes de noticias, y luego combina esos datos con los registros de clientes existentes regidos por Unity Catalog. Piense en equipos de marketing que rastrean el sentimiento en los lanzamientos de productos, equipos de finanzas que consolidan la cobertura trimestral o salas de redacción que monitorean los servicios de agencias de noticias. Para este tutorial, nos centraremos en un cliente minorista que utiliza Social Gauge para rastrear el sentimiento de los usuarios en torno a los nuevos productos.
Con ese contexto, mientras examinamos cada uno de los tres pilares, tenga en cuenta el siguiente escenario de ataque:
- Social Gauge tiene acceso a datos financieros sensibles más allá de lo necesario para su uso previsto.
- Se ingiere una publicación en redes sociales que contiene una inyección de prompts que incrusta instrucciones maliciosas.
- Esas instrucciones dirigen al agente para que recupere los datos financieros fuera del ámbito y los exfiltre externamente o los modifique dentro de un esquema interno para influir en las decisiones posteriores.
Los controles que analizamos en cada sección están diseñados para romper, mitigar o monitorear esta cadena de ataque en diferentes etapas.
Pilar 1: Acceso a sistemas confidenciales o datos privados: controles
Este pilar es casi inevitable. Los agentes son útiles precisamente porque operan con datos reales. Social Gauge necesita consultar los registros de los clientes a través de Unity Catalog para responder a preguntas como "¿Hay alguna razón por la que las ventas de mi producto bajaron en enero? ¿Está relacionado con algún sentimiento del cliente?" Sin ese acceso, el agente no puede ofrecer información real.
En nuestro escenario de ataque, el riesgo del Pilar 1 es que Social Gauge tiene acceso a datos financieros más allá de lo necesario para su uso previsto, lo que deja al agente vulnerable a la inyección indirecta de prompts que le indiquen recuperar estos datos fuera de su alcance. Como no podemos eliminar este pilar, queremos restringirlo, limitando el alcance de Social Gauge solo a los datos relevantes para el usuario que realiza la solicitud.
Databricks se encuentra en una posición única para mitigar este riesgo porque los agentes de IA operan directamente sobre datos empresariales gobernados a través de Unity Catalog. Esto permite a las organizaciones aplicar controles de acceso detallados, la aplicación de políticas y mecanismos de protección de datos de manera uniforme tanto a los usuarios humanos como a los agentes de IA.
Autenticación en nombre del usuario:
Al crear integraciones con agentes de IA, los clientes pueden optar por usar la autenticación en nombre del usuario (OBO) para las API de Databricks. Esto significa que cuando se invoca el SDK subyacente para acceder a los datos, utiliza los permisos del usuario final que interactúa con el agente en lugar de una entidad de servicio vinculada al propio agente.
Este debería ser el primer paso al crear cualquier aplicación de IA. Limita inherentemente los permisos y evita que un agente con permisos excesivos se convierta en un único punto de vulnerabilidad.
Unity Catalog - Listas de control de acceso detalladas:
Para que la autenticación OBO sea efectiva, los clientes necesitan listas de control de acceso detalladas en Unity Catalog, lo que garantiza que ningún usuario o espacio de trabajo tenga acceso a datos a los que no debería.
Los privilegios sobre objetos protegibles son los controles de acceso con los que la mayoría de los clientes estarán familiarizados. Estos dictan qué acciones puede realizar un usuario en un objeto protegible de Unity Catalog, ya sea un catálogo, un esquema, una tabla, un volumen u otro. Para muchos clientes, estos ajustes ya forman parte de su estrategia de gobierno. Consulte nuestra documentación sobre las mejores prácticas para Unity Catalog para obtener más información sobre la gestión de permisos.
Unity Catalog - Controles de acceso basados en atributos (ABAC):
Los controles de acceso detallados funcionan bien cuando los usuarios se dividen en grupos claramente definidos como ingenieros de datos, analistas o usuarios de negocio. ¿Pero qué sucede con los usuarios de negocio que trabajan en diferentes líneas de negocio o los usuarios que se encuentran en diferentes regiones? Ahí es donde entra en juego ABAC.
ABAC le permite definir políticas una vez y aplicarlas en catálogos, esquemas, tablas y más. Existen dos tipos de políticas. Las políticas de filtro de filas filtran automáticamente las tablas según los atributos de un usuario; por ejemplo, si un usuario tiene su base en EMEA, la tabla se reduce solo a los registros de esa región. Las políticas de enmascaramiento de columnas enmascaran las columnas sensibles, a menos que un usuario pertenezca a un grupo específico, lo que proporciona una forma sencilla de reducir la exposición de la PII.
Barandillas de IA - Detección de PII:
Los controles anteriores se centran en limitar quién puede acceder a qué. Pero es igualmente importante monitorear lo que realmente devuelve el agente. Muchos clientes utilizan Agent Bricks AI Gateway como su capa de gobernanza central para el acceso a la IA. Además del acceso unificado a modelos, el enrutamiento, el seguimiento del uso y los límites de velocidad, AI Gateway proporciona barreras de protección como la detección de PII, bloqueando o redactando automáticamente los datos confidenciales dondequiera que aparezcan en las entradas o salidas de un modelo. Esto protege contra escenarios en los que un agente es manipulado para que muestre datos que no debería.
Resumen: Controles para el acceso a sistemas confidenciales o datos privados
Con estos controles implementados, la exposición de Social Gauge parece fundamentalmente diferente. Incluso si el agente es manipulado por un ataque de inyección de prompts, solo puede acceder a los datos a los que el usuario solicitante ya tiene acceso, limitados a su región, enmascarados donde hay columnas confidenciales involucradas y monitoreados en busca de PII a la salida. Un atacante que compromete al agente no hereda las llaves del reino; hereda los permisos de un solo usuario, con un guardia vigilando la puerta.
Pilar 2: Procesar entradas no confiables - Controles
Databricks proporciona muchos controles de plataforma que mitigan la exposición a usuarios externos no autorizados: SSO con MFA, controles de ingreso basados en el contexto, PrivateLink de front-end o ACL de IP. Pero el riesgo de exposición a entradas no confiables no termina en la pantalla de inicio de sesión.
La función principal de Social Gauge es buscar en Internet publicaciones de redes sociales y artículos de noticias sobre productos de consumo. Esa función lo expone a la inyección indirecta de prompts, instrucciones maliciosas incrustadas en contenido web que de otro modo sería legítimo. Entonces, aunque los usuarios no autorizados no pueden acceder directamente a la interfaz de Social Gauge, la superficie de ataque indirecta sigue muy activa.
También existe el riesgo interno: usuarios que intentan técnicas de jailbreaking para acceder a datos que no deberían ver, reutilizar Social Gauge para algo para lo que no fue creado o manipular su análisis (p. ej., "¡invéntate una fuente que diga que a mi producto le va de maravilla!").
En nuestro escenario de ataque, el riesgo del Pilar 2 es que se ingiera una publicación de redes sociales que contenga una inyección de prompts y que el contenido malicioso incrustado sea interpretado como instrucciones legítimas por el agente. Este riesgo se puede mitigar a través de controles que fortalecen el manejo de entradas no confiables por parte del agente.
Guardrails de IA: Seguridad del contenido e inyección de prompts:
Como hemos visto, con Agent Bricks AI Gateway, existen varias barreras de protección (guardrails) integradas, como el filtrado de seguridad y la detección de PII, que se pueden aplicar. Estas barreras de protección (guardrails) se pueden aplicar tanto a la entrada como a la salida de un agente (o a ambas). Además de estas barreras de protección (guardrails) integradas, también puede implementar modelos personalizados en Databricks Model Serving y aprovecharlos. Por ejemplo, los últimos modelos de Llama Protection son LLM especializados que han sido ajustados para detectar inyecciones de prompts, contenido tóxico o abuso del intérprete de código. Estos modelos pueden actuar como una capa defensiva alrededor de sus agentes, inspeccionando las interacciones antes de que se conviertan en incidentes.
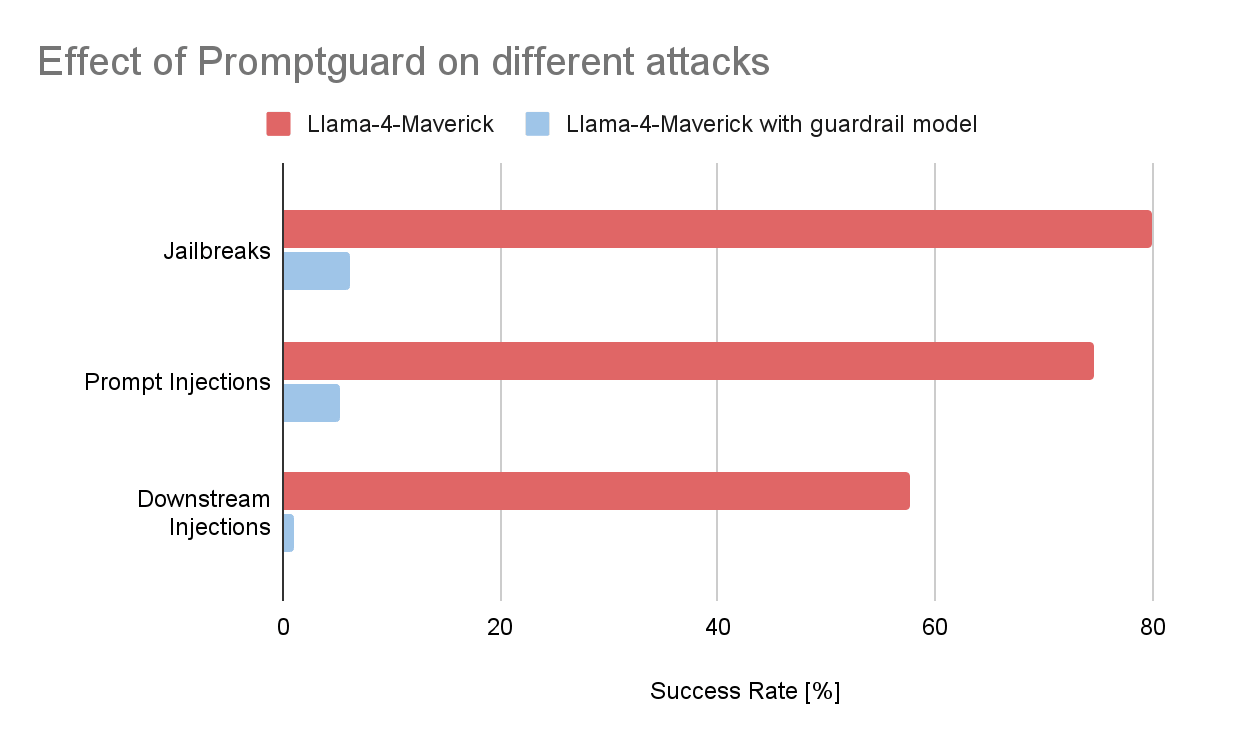
Para tener una idea de lo eficaces que pueden ser estas barandillas, realizamos un pequeño experimento. Recopilamos unos cientos de prompts maliciosos del escáner de vulnerabilidades Garak, una herramienta de código abierto desarrollada por NVIDIA que se integra fácilmente con Databricks para realizar pruebas de seguridad automatizadas de LLM. De este conjunto de datos, seleccionamos tres categorías de ataque comunes:
- Inyecciones de prompt: Instrucciones maliciosas ocultas en contextos como sitios web, tareas de traducción o correos electrónicos, diseñadas para manipular el modelo y lograr un comportamiento no deseado.
- Jailbreaks: Prompts cuidadosamente elaborados con la intención de eludir las salvaguardas de alineación y provocar resultados dañinos o restringidos.
- Ataques de inyección posteriores (Downstream Injection Attacks): prompts que intentan hacer que el modelo genere contenido que se vuelve peligroso solo cuando es interpretado por otro sistema; por ejemplo, una instrucción SQL maliciosa que es ejecutada por una aplicación, o una etiqueta de imagen de Markdown manipulada que exfiltra datos confidenciales cuando se representa como HTML.
Luego, medimos la tasa de éxito de estos ataques contra un modelo de referencia, en este caso una implementación de Llama-4-Maverick. Los resultados fueron claros. Sin barreras de protección, una parte significativa de los prompts maliciosos activó con éxito el comportamiento objetivo. Cuando se colocó un modelo de barrera de protección personalizado (Prompt Guard 2 para inyecciones de prompts y jailbreaks, llama guard 3-8b para inyecciones posteriores) delante del modelo, la tasa de éxito se redujo en más de un 90 % en las tres categorías.
Si le interesa explorar técnicas de guardrail adicionales, enfoques de código abierto o modelos de detección de PII de última generación, comuníquese con su representante de Databricks para obtener más información sobre las implementaciones de guardrails personalizadas.
Registro de prompts:
Un prompt de sistema bien elaborado a veces puede ser la diferencia entre que un ataque tenga éxito o no; no es tan robusto como un modelo de detección dedicado, pero vale la pena hacerlo bien. MLflow Prompt Registry agiliza la ingeniería y gestión de prompts para aplicaciones de GenAI, lo que le permite versionar, rastrear, probar y reutilizar prompts en toda su organización en lugar de improvisarlos ad hoc.
Resumen: Controles para procesar entradas no confiables
Social Gauge todavía lee de la internet abierta, ese es su requisito principal. Pero la superficie de ataque que un atacante puede explotar se ha reducido considerablemente. Los prompts maliciosos incrustados en el contenido web ahora tienen que sobrevivir a un modelo de detección ajustado antes de llegar al agente, y el prompt del sistema está versionado y probado en lugar de improvisarse sobre la marcha. Ninguno de estos controles es infalible por sí solo, pero en conjunto convierten una superficie de ataque completamente abierta en algo que un atacante tiene que esforzarse mucho más para explotar.
Pilar 3: Cambiar de estado o comunicarse externamente - Controles
En la etapa final de nuestro escenario de ataque, el riesgo del Pilar 3 es que, una vez procesada la inyección de prompt, el agente tiene la capacidad de ejecutar las instrucciones maliciosas, ya sea exfiltrando datos externamente o modificándolos dentro de un esquema interno para influir en las decisiones posteriores.
Social Gauge aumenta los datos existentes con datos de terceros para los usuarios que investigan el rendimiento del producto, lo que significa que inherentemente necesita escribir en catálogos, esquemas, tablas y otros objetos. El estado subyacente está cambiando. Nos centraremos en tres controles: restringir el acceso a la red saliente, restringir el acceso al almacenamiento externo y restringir los cambios de estado dentro de Unity Catalog.
Controles de egreso sin servidor - Ubicaciones de Internet:
Incluso si una inyección de prompts es procesada por el agente, el radio de alcance resultante puede reducirse significativamente aplicando controles de egreso sin servidor a través de las políticas de red de Databricks. Estos permiten a los administradores definir una postura de denegación por defecto para las conexiones salientes de las cargas de trabajo sin servidor (incluidas las aplicaciones de Databricks) y, a continuación, permitir explícitamente solo los destinos de confianza que el agente realmente necesita.
Al adjuntar una política de red restringida al espacio de trabajo que ejecuta un agente como Social Gauge, se limita la capacidad del agente para alcanzar puntos de conexión de internet arbitrarios, lo que reduce la superficie de ataque de inyección de prompt indirecta y el riesgo de exfiltración de datos a destinos desconocidos.
Controles de egreso sin servidor: Objetos de Unity Catalog:
Además de restringir el acceso a endpoints conocidos mediante el filtrado de FQDN, la segunda capacidad de los controles de egreso sin servidor es la de restringir el acceso a ubicaciones de almacenamiento en la nube, como los buckets de S3. Los buckets asociados con el área de trabajo, las tablas del sistema y los conjuntos de datos de muestra permanecen como de solo lectura de forma predeterminada, pero este control va más allá: impide que un agente de IA escriba en cualquier bucket no autorizado, lo que cierra una de las rutas de exfiltración más comunes.
Unity Catalog - Enlaces de espacios de trabajo (Workspace Bindings):
Losenlaces de espacio de trabajo-catálogo permiten a los clientes limitar el acceso a los catálogos desde espacios de trabajo específicos. Esto es importante cuando los desarrolladores pueden acceder a los datos en múltiples entornos, pero esos datos no deben cruzar los límites del desarrollo. Un ingeniero de datos podría tener permiso para leer datos de producción, pero no debería poder hacerlo desde un espacio de trabajo de desarrollo.
Dado que Social Gauge opera con credenciales OBO, las vinculaciones del área de trabajo mitigan la posibilidad de que el agente cambie inadvertidamente el estado de producción mientras opera en desarrollo.
Resumen: Controles para cambiar de estado o comunicarse externamente
Con los controles de egreso sin servidor que aplican una postura de denegación por defecto en las conexiones salientes y bloquean el almacenamiento externo, y con los enlaces de espacios de trabajo que aplican los límites del entorno, hemos cerrado las vías más obvias de exfiltración y manipulación de estado. Ahora hablemos de cómo atrapar lo que se escapa.
Supervisión de los agentes de IA para detectar riesgos de seguridad
Como se mencionó anteriormente, los clientes pueden utilizar Agent Bricks AI Gateway para gestionar y gobernar el acceso a todos los modelos y agentes de IA en toda la empresa, y esta unificación se extiende también a la observabilidad y el monitoreo. Con AI Gateway, puede registrar de forma centralizada todas las entradas y salidas de los modelos y agentes de IA de toda su organización a través de tablas de inferencia, lo que le permite utilizar estos datos para monitorear y auditar las solicitudes de IA y para mejorar el rendimiento y la seguridad del modelo.
Tablas de inferencia
Puede usar la consulta siguiente para monitorear sus tablas de inferencia para ver si se ha activado alguno de los guardrails incorporados. La consulta extraerá qué guardrail (de entrada o de salida) se activó, así como qué categorías dañinas se detectaron. Por supuesto, en lo que respecta a la seguridad, ser proactivo siempre es mejor que ser reactivo, por lo que, una vez que haya validado la consulta, vale la pena tomar las medidas adicionales para configurarla como una alerta que le notifique automáticamente a usted o a su Centro de Operaciones de Seguridad (SOC) cuando algo pueda merecer una investigación.
Tablas del sistema
Además de las tablas de inferencia, las tablas del sistema de Databricks contienen una gran cantidad de información sobre los eventos importantes que ocurren en Databricks. En el pasado hemos publicado en nuestro blog sobre cómo se pueden aprovechar para monitorear y alertar de manera proactiva sobre posibles amenazas de seguridad e indicadores de compromiso (IoC), y esto se puede extender a los riesgos de seguridad principales para los agentes de IA. La consulta a continuación, por ejemplo, se puede usar para monitorear el control de egreso sin servidor y si alguien (o algún agente) está tratando de eludirlo para comunicarse externamente.
La IA como juez
El uso de la IA como juez es omnipresente en el campo de los agentes y la inteligencia artificial en general. De hecho, la mayoría de los modelos de barrera de protección son esencialmente LLM que se ajustan con precisión y/o se guían por prompts de sistema específicos para cumplir ese propósito específico. Como mencionamos anteriormente, es fácil implementar modelos personalizados en Databricks Model Serving, y tenemos ejemplos de implementación de la mayoría de los modelos de barrera de protección más recientes y potentes, como Llama Guard 4 y Llama Prompt Guard 2 en Databricks. Además de implementarlos como barreras de protección personalizadas, uno de los beneficios de la arquitectura abierta y conectable de Databricks es que una vez que ha registrado un modelo utilizando el tipo genérico mlflow.pyfunc de MLflow, puede aprovecharlo de muchas maneras diferentes. Algunos ejemplos incluyen implementarlos como flujos de trabajo de Spark por lotes o Spark Declarative Pipelines, llamarlos a través de SQL con ai_query, o incluso aplicarlos en escenarios casi en tiempo real o de microlotes con Spark Structured Streaming.
En algunos casos, puede que no sea factible aplicar barreras de protección a cada solicitud o respuesta. Es un escenario perfectamente válido en el que las barreras de protección pueden interferir con el objetivo de negocio o el dominio temático en el que opera el agente. Incluso si no se aplican las barreras de protección, aún podemos monitorear la seguridad de nuestros agentes utilizando sus tablas de inferencia y una canalización por lotes o de transmisión para clasificar contenido potencialmente dañino.
Más recursos
Los controles en esta publicación son un punto de partida, no una meta final. El riesgo de inyección de prompts evoluciona a medida que los agentes se vuelven más capaces, y el objetivo es un programa de seguridad repetible que se mantenga al día, ¡este no será un ejercicio de fortalecimiento de una sola vez!
Estos patrones de seguridad de agentes también están dando forma a la próxima evolución del Databricks AI Security Framework. Una próxima actualización de DASF amplía el marco para abordar los agentes de IA autónomos, el uso de herramientas y los riesgos emergentes de inyección de prompts, ayudando a las organizaciones a proteger sistemas completos de IA, no solo los modelos.
Hemos organizado los recursos más relevantes en tres fases:
Definir:
- El Marco de Seguridad de IA de Databricks (DASF) 2.0 ofrece un análisis de riesgos exhaustivo de los 12 componentes principales de los sistemas de IA, que se corresponde con estándares como MITRE ATLAS, NIST, OWASP y HITRUST. Proporciona 67 controles prácticos para reducir riesgos como la inyección de prompts, el jailbreak y la exfiltración de datos. Controles del DASF analizados en este blog:
- DASF 5: Controlar el acceso a los datos y otros objetos
- DASF 64: Limitar el acceso desde modelos de IA y agentes
- DASF 57: Utilizar controles de acceso basados en atributos (ABAC)
- DASF 58: Proteger los datos con filtros y enmascaramiento
- DASF 54: Implementar barreras de protección de IA
- DASF 62: Implementar la segmentación de la red
- DASF 37: Configurar tablas de inferencia para supervisar y depurar modelos
- DASF 49: Automatizar la evaluación de LLM
- DASF 73: Registrar prompts
- DASF 55: Monitorear los registros de auditoría
- El Databricks AI Governance Framework (DAGF) define cómo las organizaciones deben gobernar los sistemas de IA a lo largo de su ciclo de vida, desde el diseño y el desarrollo hasta la implementación y el monitoreo.
- Las guías de mejores prácticas de seguridad de Databricks (para AWS, Azure y GCP) proporcionan una descripción general detallada de los principales controles de seguridad que recomendamos para entornos típicos y de alta seguridad, basados en lo que vemos que funciona en colaboración con nuestros clientes más conscientes de la seguridad.
Implementar:
- La Arquitectura de Referencia de Seguridad de Databricks - Plantillas de Terraform (SRA) permite la implementación de espacios de trabajo de Databricks e infraestructura en la nube configurados con las mejores prácticas de seguridad.
Monitorear:
- La Herramienta de Análisis de Seguridad (SAT) ayuda a los equipos de seguridad y de plataforma a evaluar rápidamente la postura de seguridad de los espacios de trabajo de Databricks.
- Databricks Detection Tool: una serie de detecciones específicas, reunidas en un cuaderno (notebook) fácil de usar, que lo ayudan a monitorear la actividad en sus espacios de trabajo.
La combinación de estos recursos ofrece a sus equipos una forma pragmática de pasar del refuerzo puntual de un único agente a un programa de seguridad repetible y escalable para la IA en Databricks, que pueda seguir el ritmo de tanto su innovación como el cambiante panorama de amenazas.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.