Cumplimiento moderno de BSA/AML en Databricks
Cómo Databricks Data Intelligence Platform unifica sistemas de AML aislados, puntuación de riesgo de ML y una flota de agentes de AI en un único flujo de trabajo gobernado: desde la alerta hasta el SAR presentado.
por Kateryna Savchyn , Pavithra Rao, Mimi Park y Emerson Bayuk
- ¿Qué es? Una experiencia unificada y aumentada con agentes de AI y machine learning para analistas y líderes de AML, creada sobre Databricks Data Intelligence Platform.
- ¿Qué problema resuelve? Consolida los sistemas aislados que consumen la mayor parte del tiempo de los analistas durante una investigación de AML, aumenta la detección basada en reglas con una puntuación de riesgo impulsada por ML y acelera la creación de informes SAR de horas a minutos, todo bajo un único entorno gobernado.
- ¿Qué resultados pueden esperar los equipos de AML? Un procesamiento de casos de 8 a 10 veces más rápido, una reducción del 75% en falsos positivos y entre 50 y 150 millones de dólares en ahorros de costos anuales para instituciones medianas y grandes.
La función de prevención del lavado de dinero (AML) en los servicios financieros se ha organizado históricamente en torno a dos responsabilidades: resolver las alertas de posibles actividades de lavado de dinero y documentar la resolución de cada caso, lo que incluye la presentación de informes de actividad sospechosa (SAR) cuando se justifique, todo ello manteniendo la eficacia del programa y la auditabilidad del proceso. Ese modelo está ahora bajo presión. Las cambiantes tipologías de los delitos financieros, las expectativas regulatorias de explicabilidad en tiempo real y la madurez de la IA generativa están redefiniendo cómo es una práctica moderna de AML. Cada vez se espera más de los líderes de AML que dirijan el tiempo de los analistas hacia una verdadera inteligencia sobre delitos financieros, en lugar de hacia la recopilación de datos, el triaje de falsos positivos y la redacción de informes que hoy dominan las cargas de trabajo.
La limitación rara vez es el talento o la intención. Es el lastre estructural que imponen a cada alerta los sistemas fragmentados, la puntuación opaca de los proveedores y la recopilación manual de pruebas. Hasta que se elimine ese lastre, los programas de AML, por muy bien financiados que estén, seguirán atrapados en el modo de resolución de tareas pendientes.
Por qué las operaciones de AML se enfrentan a una barrera de productividad
El ciclo típico de investigación de AML hoy en día es manual y propenso a errores. Los analistas dedican entre tres y seis horas por caso a extraer y correlacionar datos en 10 o más sistemas aislados, que incluyen: Know Your Customer (KYC), monitoreo de transacciones, detección de sanciones, gestión de casos, medios adversos, beneficiario final, CRM interno, registros de sucursales y bases de conocimientos regulatorios, todo ello unido en hojas de cálculo y plantillas de Word. La mayor parte de ese tiempo se dedica a falsos positivos: PwC estima que entre el 90 y el 95 por ciento de todas las alertas generadas por los sistemas de monitoreo de transacciones no requieren acción, aunque cada una consume el mismo esfuerzo de investigación que un positivo real porque nada conecta las pruebas de forma automática. El monitoreo basado en reglas de primera generación se ve cada vez más superado por las técnicas modernas de fraude impulsadas por AI.
Este lastre se manifiesta en cuatro aspectos:
- Más de 10 sistemas aislados. Los analistas son la capa de integración de facto. Cada alerta requiere volver a autenticarse en múltiples portales de proveedores, copiar valores en un documento de trabajo y conciliar los identificadores a mano.
- Alta tasa de falsos positivos. Las reglas y modelos de detección que no se actualizan continuamente frente a las cambiantes tipologías de delitos financieros pueden desalinearse con los patrones de actividad reales, generando alertas sobre transacciones que finalmente resultan ser legítimas. Aun así, cada alerta consume las mismas 3 a 6 horas de esfuerzo de investigación, independientemente del resultado.
- Documentación manual de casos. Cada caso requiere una resolución por escrito (escalación, desestimación como falso positivo o presentación de un SAR) documentada y archivada para la auditoría regulatoria. Los analistas redactan estos informes a mano desde cero, citando las mismas regulaciones y estructurando los mismos paquetes de pruebas caso tras caso. Los datos de la encuesta del Bank Policy Institute sitúan el esfuerzo de los bancos para la presentación de SAR por sí sola en aproximadamente 21.4 horas por presentación, más de diez veces la estimación de la propia Ley de Reducción de Trámites de FinCEN.
- Puntuación opaca de los proveedores. Las plataformas de AML empaquetadas suelen exponer umbrales de escenarios para su ajuste, pero los artefactos del modelo subyacente, la ingeniería de características y la frecuencia de reentrenamiento a menudo residen en el entorno del proveedor, lo que dificulta que las instituciones cumplan con los estándares de gestión de riesgos de modelos (por ejemplo, SR 11-7) y respondan rápidamente cuando los reguladores preguntan cómo se produjo una puntuación específica.
El efecto acumulativo es una acumulación de tareas pendientes que crece más rápido de lo que el personal puede resolver. En la Encuesta de AML de PwC EMEA de 2024, el 44% de las instituciones financieras citan el aumento de las regulaciones sobre delitos financieros como el factor más urgente que complica las operaciones de cumplimiento, y las tipologías de la próxima década (pagos en tiempo real, finanzas embebidas, puentes cripto-fiat, identidad sintética a escala) solo ampliarán la brecha.
La solución: Databricks Data Intelligence Platform
Para pasar de la resolución de tareas pendientes a la investigación, los equipos de AML necesitan una plataforma que no solo almacene alertas, sino que razone sobre ellas, y que lo haga bajo el esquema de gobernanza que un regulador espera ver. Databricks Data Intelligence Platform reúne el monitoreo de transacciones, KYC, la detección de sanciones, el conocimiento regulatorio y los agentes de AI bajo la gobernanza de Unity Catalog, con un linaje completo desde la transacción sin procesar hasta el SAR presentado. Cada componente es modular en lugar de todo o nada: las instituciones pueden adoptar todo el conjunto de extremo a extremo o integrar piezas individuales en los flujos de trabajo existentes, lo que es especialmente útil para los equipos que acaban de empezar a modernizarse. Seis capacidades distinguen este enfoque de las soluciones de AML tradicionales:
1. Una capa de datos de cumplimiento unificada gobernada por Unity Catalog
Unity Catalog consolida más de 10 sistemas aislados en un único lakehouse gobernado. La banca central, los flujos de monitoreo de transacciones, los perfiles de KYC, las coincidencias de sanciones, el historial de casos y la biblioteca de documentos de políticas de AML de la institución se ingieren a través de Lakeflow Connect en una arquitectura de medallas Bronze → Silver → Gold, con calidad de datos aplicada por Delta, enmascaramiento de columnas para la PII de los clientes y seguridad a nivel de fila vinculada al equipo y al rol. Cada artefacto descendente, la puntuación de riesgo, la cadena de pruebas del agente y el informe SAR, se rastrea mediante linaje hasta su fila de origen y su marca de tiempo de ingesta. Cuando el examinador pregunta qué activó la alerta, qué pruebas respaldaron la presentación o cómo manejó la institución casos estructuralmente similares, la respuesta es una consulta reproducible en lugar del recuerdo de un analista. La gobernanza, el linaje y la aplicación de la calidad son propiedades de la plataforma, no una capa superpuesta.
2. ML de extremo a extremo para detección y puntuación de riesgos
Los motores de reglas estáticas se complementan, no se reemplazan. Databricks Data Intelligence Platform brinda a los equipos de ciencia de datos y delitos financieros la base para desarrollar, entrenar y servir modelos de ML de última generación adaptados al propio historial de transacciones, base de clientes y perfil de riesgo de la institución, alimentando señales más ricas tanto en la cola de alertas como en el contexto de la investigación. Los modelos se registran en MLflow con alias de campeón/retador (champion/challenger) y un seguimiento completo de los experimentos; Model Serving expone el modelo activo; Lakehouse Monitoring observa la desviación y el rendimiento en producción; y las tablas de inferencia capturan los comentarios de los analistas que alimentan el reentrenamiento del retador. A medida que los retadores demuestran ser superiores, los equipos los promueven a través de la gestión del ciclo de vida de MLflow. Cada alerta puede mostrar una explicación de las reglas de negocio y las señales de ML que la activaron, de modo que el analista abre un caso sabiendo de antemano por qué llegó a la cola. El resultado es una reducción del 75% en los falsos positivos que llegan a la cola de los analistas, sin necesidad de reemplazar por completo el motor de reglas de monitoreo de transacciones subyacente.
3. Una flota de agentes de AI especializados que trabajan en conjunto
El núcleo de la modernización es un asistente de chat multiagente que orquesta una flota de subagentes especializados durante una investigación, desarrollado sobre Agent Bricks. En lugar de iniciar sesión en múltiples sistemas para correlacionar datos manualmente, el analista trabaja desde una única página de investigación que muestra notas de diligencia pasadas, notas del caso, presentaciones anteriores de SAR, patrones de transacciones y relaciones de entidades en una sola vista. La flota de agentes analiza toda la red de datos disponibles y devuelve una recomendación informada sobre cómo manejar el caso, con el ser humano firmemente en el proceso para la decisión final: escalar a un equipo de especialistas, desestimar como falso positivo o proceder a la presentación de un SAR. El efecto de extremo a extremo: una investigación que antes requería de tres a seis horas de trabajo manual se reduce a minutos de revisión asistida por agentes.

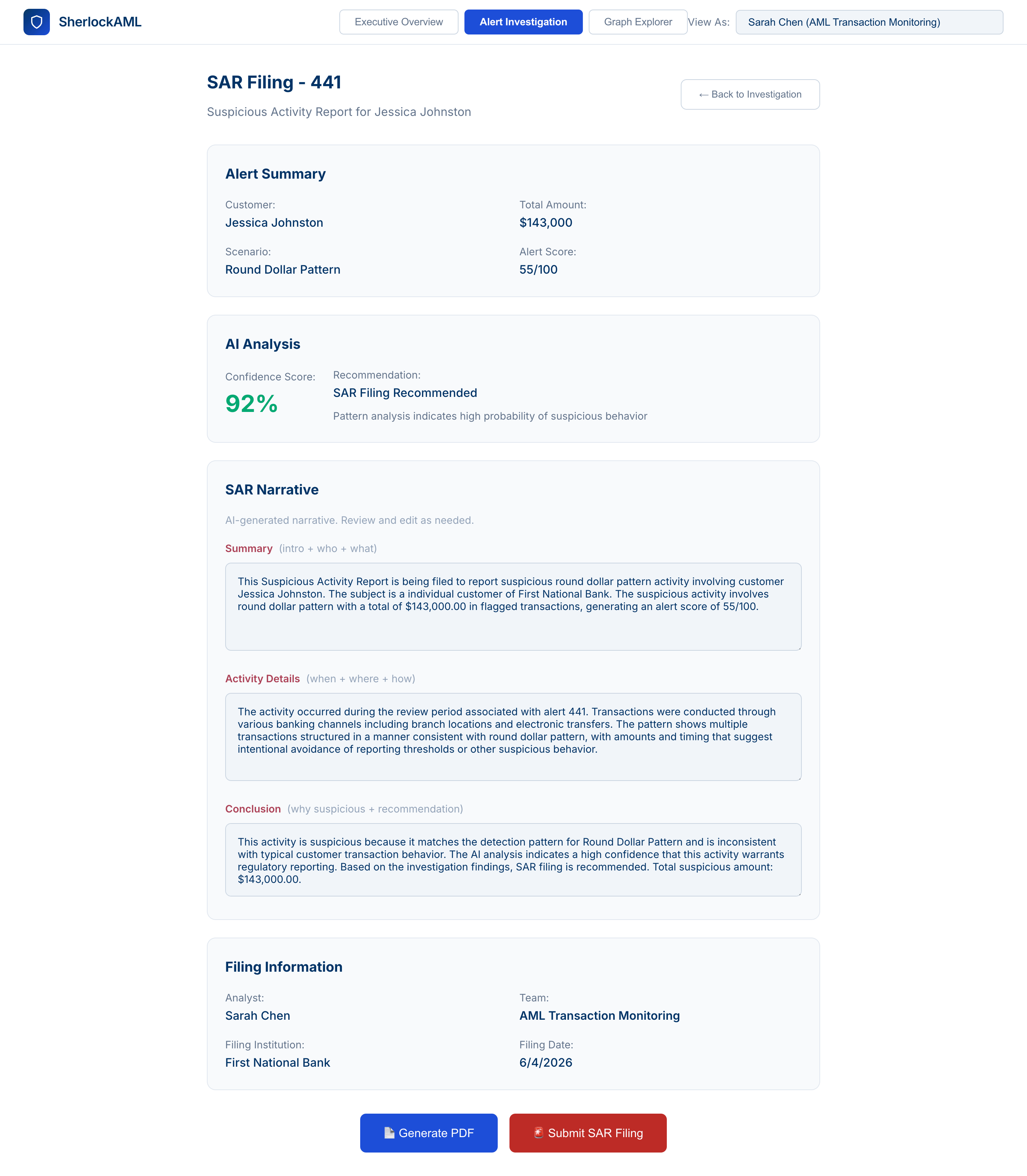
4. Generación de SAR asistida por AI, de horas a minutos
Cuando el analista procede a la presentación de SAR, la misma flota de agentes completa automáticamente los metadatos contextuales recopilados durante la investigación y redacta un resumen y una narrativa personalizados para el informe. El analista verifica los datos, personaliza y genera el PDF; la AI estructura el documento para cumplir con las especificaciones de formato requeridas por la institución antes de su envío. Los informes presentados se envían al backend con un registro totalmente rastreable desde una perspectiva de auditabilidad. La creación de informes SAR, que tradicionalmente tomaba horas, se completa en minutos. Además, esto cierra el ciclo automáticamente y muestra de inmediato la presentación como contexto y evidencia adicionales para los casos que el resto del equipo de AML está analizando activamente en paralelo.
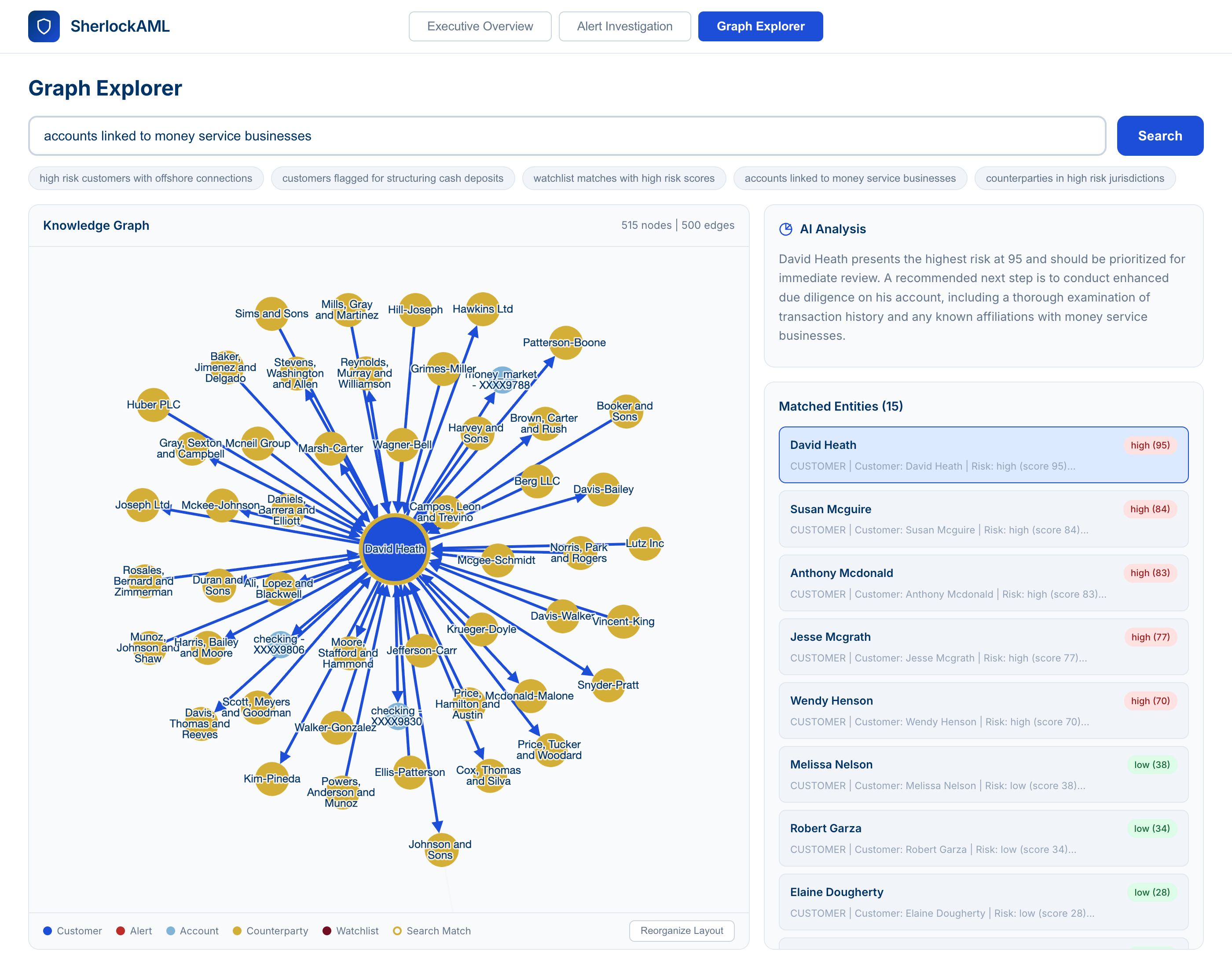
5. Visualización de grafos para la detección de patrones de red
Una capa de grafos, que se muestra a través de visualizaciones interactivas en el entorno de trabajo del analista, permite al analista pasar de la página de investigación a una vista de grafo completa, hacer preguntas en lenguaje natural al propio grafo o saltar a cualquier entidad individual para explorar las relaciones con las contrapartes. Esto revela los patrones de red ocultos que los sistemas basados en reglas no detectan: empresas fantasma, estructuras de estratificación y flujos circulares de fondos.
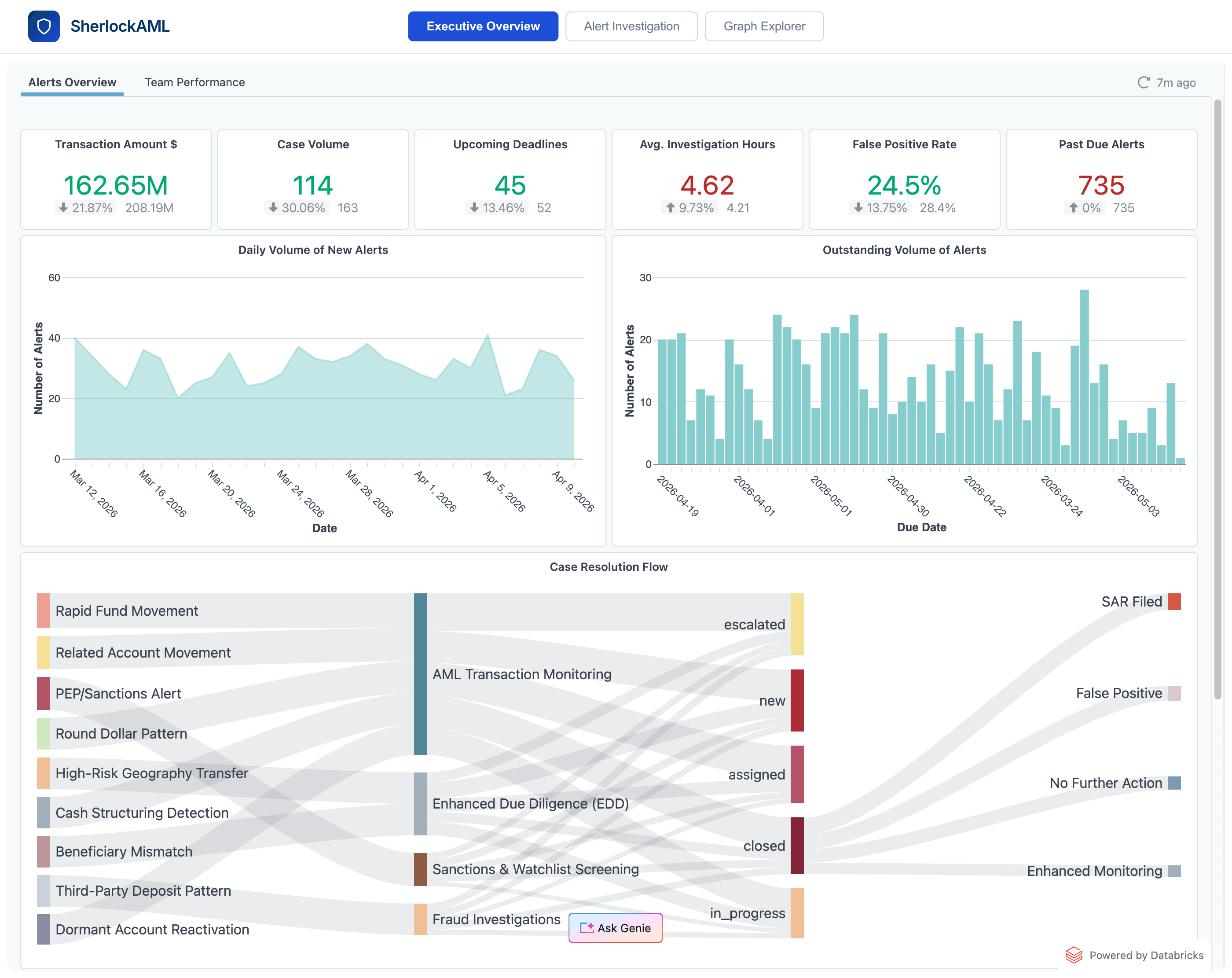
6. Informes ejecutivos con interfaz de lenguaje natural
Los líderes de AML acceden a una vista ejecutiva que muestra KPIs de volumen de casos, horas dedicadas y alertas vencidas; líneas de tendencia para la detección y el envejecimiento; una visualización del flujo del proceso desde la detección hasta la resolución, pasando por la asignación del equipo; y desgloses por escenario y criticidad. Una vista de Rendimiento del equipo profundiza en el rendimiento de incidentes, la presión de las fechas de vencimiento y el tiempo promedio de resolución por tipo de detección y equipo, lo que facilita la identificación de cuellos de botella en el proceso y oportunidades para reorganizar el equipo a fin de cumplir con los plazos críticos. El chat en lenguaje natural sobre los mismos datos gobernados permite realizar análisis profundos de autoservicio sobre las tendencias sin tener que esperar a un equipo de analítica: Genie permite a los líderes de AML preguntar: "¿Qué relaciones de asesores han activado la mayor cantidad de alertas de estructuración en el último trimestre y cuál es la tasa de falsos positivos por equipo?" y recibir una respuesta lista para auditoría en segundos.
Conclusión: Un nuevo estándar para el liderazgo en AML
Los equipos de AML ya no tienen que elegir entre la productividad de los analistas y la capacidad de defensa regulatoria. Una plataforma de inteligencia de datos gobernada, donde las alertas, la evidencia, los agentes y las pistas de auditoría coexisten en el mismo entorno con seguimiento de linaje, ofrece ambas cosas. La postura tradicional de "más analistas, más proveedores, más hojas de cálculo" ya no es competitiva frente a las instituciones que han unificado sus datos de cumplimiento y permiten que los agentes de AI se encarguen de la carga de investigación de múltiples fuentes. Este cambio no es una aspiración futura; es una decisión operativa disponible hoy mismo.
Breve descripción de la arquitectura
La solución se compone de cinco capacidades disponibles en la plataforma de inteligencia de datos de Databricks:
- Ingesta y gobernanza. Lakeflow Connect lleva los datos bancarios principales, los flujos de monitoreo de transacciones, los perfiles KYC, las coincidencias de sanciones, el historial de casos y los documentos de políticas a un medallón Bronze → Silver → Gold en Delta, con Unity Catalog aplicando enmascaramiento de columnas, seguridad a nivel de fila y linaje de extremo a extremo.
- Puntuación. Los modelos de detección, adaptados al historial de transacciones y al perfil de riesgo de la propia institución, se entrenan y sirven a través de MLflow con alias de campeón/retador; Model Serving expone el modelo activo; Lakehouse Monitoring supervisa la desviación; y las tablas de inferencia capturan los comentarios de los analistas que alimentan el reentrenamiento del modelo retador.
- Razonamiento. Un asistente multiagente creado sobre Agent Bricks orquesta agentes de Genie para consultas estructuradas, asistentes de conocimiento RAG respaldados por Vector Search sobre la biblioteca de regulaciones y políticas de la institución, agentes externos expuestos a través del MCP Marketplace y una capa de grafos que resuelve entidades y revela estructuras ocultas de contrapartes.
- Estado operativo. Databricks Lakebase, una base de datos Postgres administrada y totalmente integrada con el lakehouse, sirve como backend operativo para los agentes y las aplicaciones. El estado del caso, las notas del analista, el historial de conversaciones del agente, los borradores de SAR y el estado del flujo de trabajo se conservan en Lakebase con lecturas y escrituras de baja latencia, al tiempo que se mantienen sincronizados con las tablas de Delta bajo la misma gobernanza, linaje y controles de acceso de Unity Catalog que se aplican a los datos analíticos.
- Experiencia del analista y del ejecutivo. Databricks Apps ofrece el entorno de trabajo de investigación del analista, la vista ejecutiva, el explorador de grafos y la superficie de envío de SAR, leyendo y escribiendo el estado operativo a través de Lakebase con total trazabilidad de auditoría en los informes presentados.
Implementación modular
Las cinco capas se pueden implementar de forma independiente o como una pila completa. Un banco que ya cuente con su propio motor de monitoreo de transacciones puede adoptar solo las capas de puntuación o razonamiento para agregar puntuación de riesgo de ML e investigación aumentada por AI sobre las alertas existentes; un banco con una gestión de casos madura pero con datos fragmentados puede comenzar con la capa de ingesta y gobernanza para consolidar las fuentes primero. Dado que cada componente comparte la misma plataforma de inteligencia de datos y la gobernanza de Unity Catalog, las implementaciones parciales se acumulan hacia la arquitectura completa sin necesidad de cambiar de plataforma.
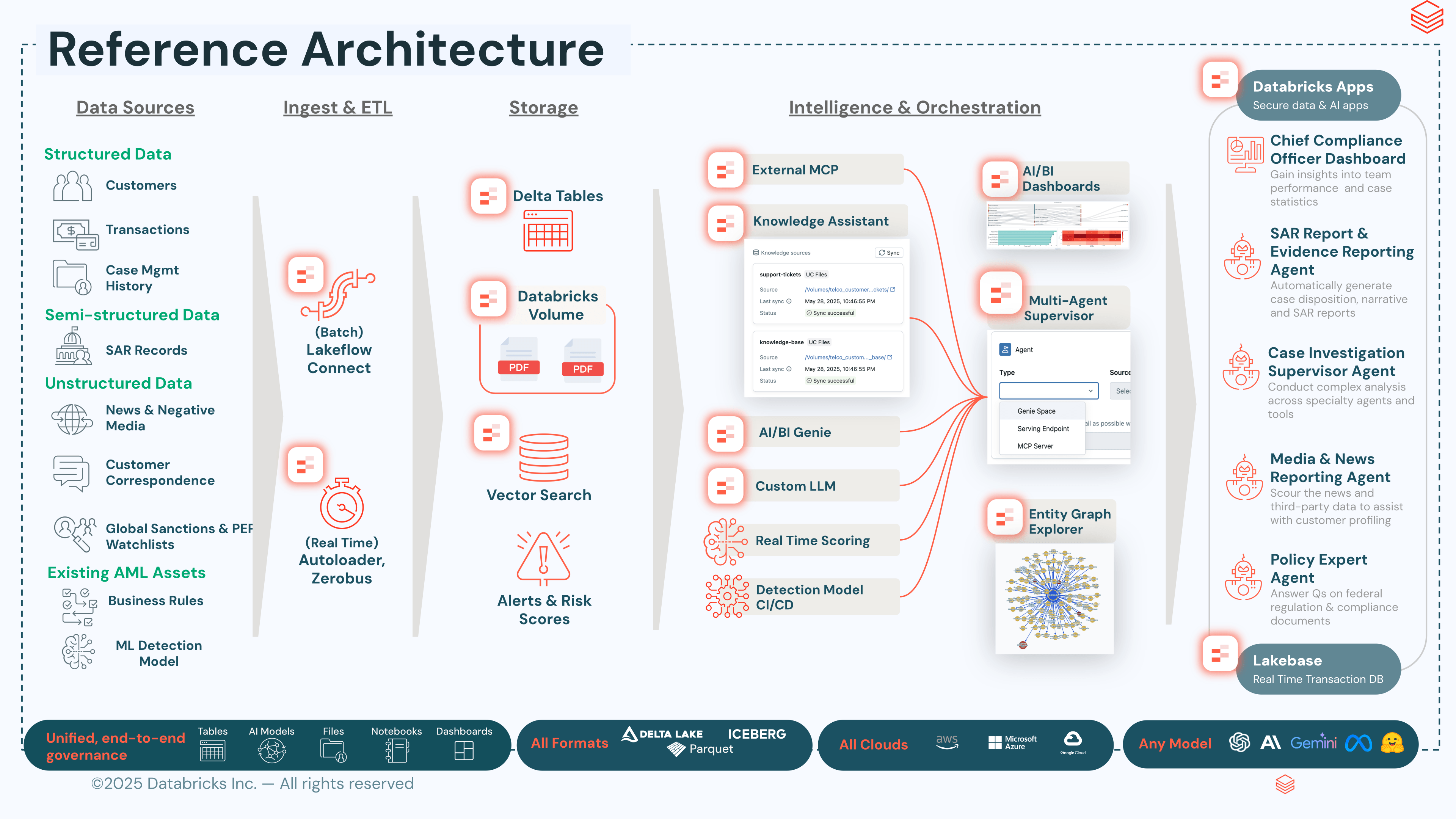
Implementación modular
Las cinco capas se pueden implementar de forma independiente o como una pila completa. Un banco que ya cuente con su propio motor de monitoreo de transacciones puede adoptar solo las capas de puntuación o razonamiento para agregar puntuación de riesgo de ML e investigación aumentada por AI sobre las alertas existentes; un banco con una gestión de casos madura pero con datos fragmentados puede comenzar con la capa de ingesta y gobernanza para consolidar las fuentes primero. Dado que cada componente comparte la misma plataforma de inteligencia de datos y la gobernanza de Unity Catalog, las implementaciones parciales se acumulan hacia la arquitectura completa sin necesidad de cambiar de plataforma.
Véalo en acción
▸ Implemente la solución en su espacio de trabajo
▸ Hable con nosotros: ¡Póngase en contacto con el equipo de su cuenta de Databricks para integrar esto con su flujo de trabajo de AML existente hoy mismo!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.