La nueva forma de crear pipelines en Databricks: Presentamos el IDE para ingeniería de datos
Una nueva experiencia de desarrollador creada específicamente para la creación de Lakeflow Spark Declarative Pipelines
por Adriana Ispas, Lennart Kats, Camiel Steenstra y Monica Alvarez Vicente
- Las Spark Declarative Pipelines ahora tienen una experiencia de desarrollador IDE dedicada en el Databricks Workspace.
- El nuevo IDE mejora la productividad y la depuración con funciones como gráficos de dependencias, vistas previas e información de ejecución.
- El IDE admite tanto la incorporación rápida como los casos de uso avanzados, como la integración con Git, CI/CD y observabilidad.
En el Data + AI Summit de este año, presentamos el IDE para Ingeniería de Datos: una nueva experiencia de desarrollador diseñada específicamente para crear pipelines de datos directamente en el Workspace de Databricks. Como la nueva experiencia de desarrollo predeterminada, el IDE refleja nuestro enfoque decidido para la ingeniería de datos: declarativo por defecto, modular en estructura, integrado con Git y asistido por IA.
En resumen, el IDE para Ingeniería de Datos es todo lo que necesitas para crear y probar pipelines de datos, todo en un solo lugar.
Con esta nueva experiencia de desarrollo disponible en Vista Previa Pública, nos gustaría usar este blog para explicar por qué los pipelines declarativos se benefician de una experiencia de IDE dedicada y destacar las características clave que hacen que el desarrollo de pipelines sea más rápido, organizado y fácil de depurar.
La ingeniería de datos declarativa obtiene una experiencia de desarrollador dedicada
Los pipelines declarativos simplifican la ingeniería de datos al permitirte declarar lo que quieres lograr en lugar de escribir instrucciones detalladas paso a paso sobre cómo construirlo. Aunque la programación declarativa es un enfoque extremadamente potente para construir pipelines de datos, trabajar con múltiples conjuntos de datos y gestionar el ciclo de vida completo del desarrollo puede volverse difícil de manejar sin herramientas dedicadas.
Por eso, creamos una experiencia IDE completa para pipelines declarativos directamente en el Workspace de Databricks. Disponible como un nuevo editor para Lakeflow Spark Declarative Pipelines, te permite declarar conjuntos de datos y restricciones de calidad en archivos, organizarlos en carpetas y ver las conexiones a través de un grafo de dependencias generado automáticamente que se muestra junto a tu código. El editor evalúa tus archivos para determinar el plan de ejecución más eficiente y te permite iterar rápidamente al volver a ejecutar archivos individuales, un conjunto de conjuntos de datos modificados o todo el pipeline.
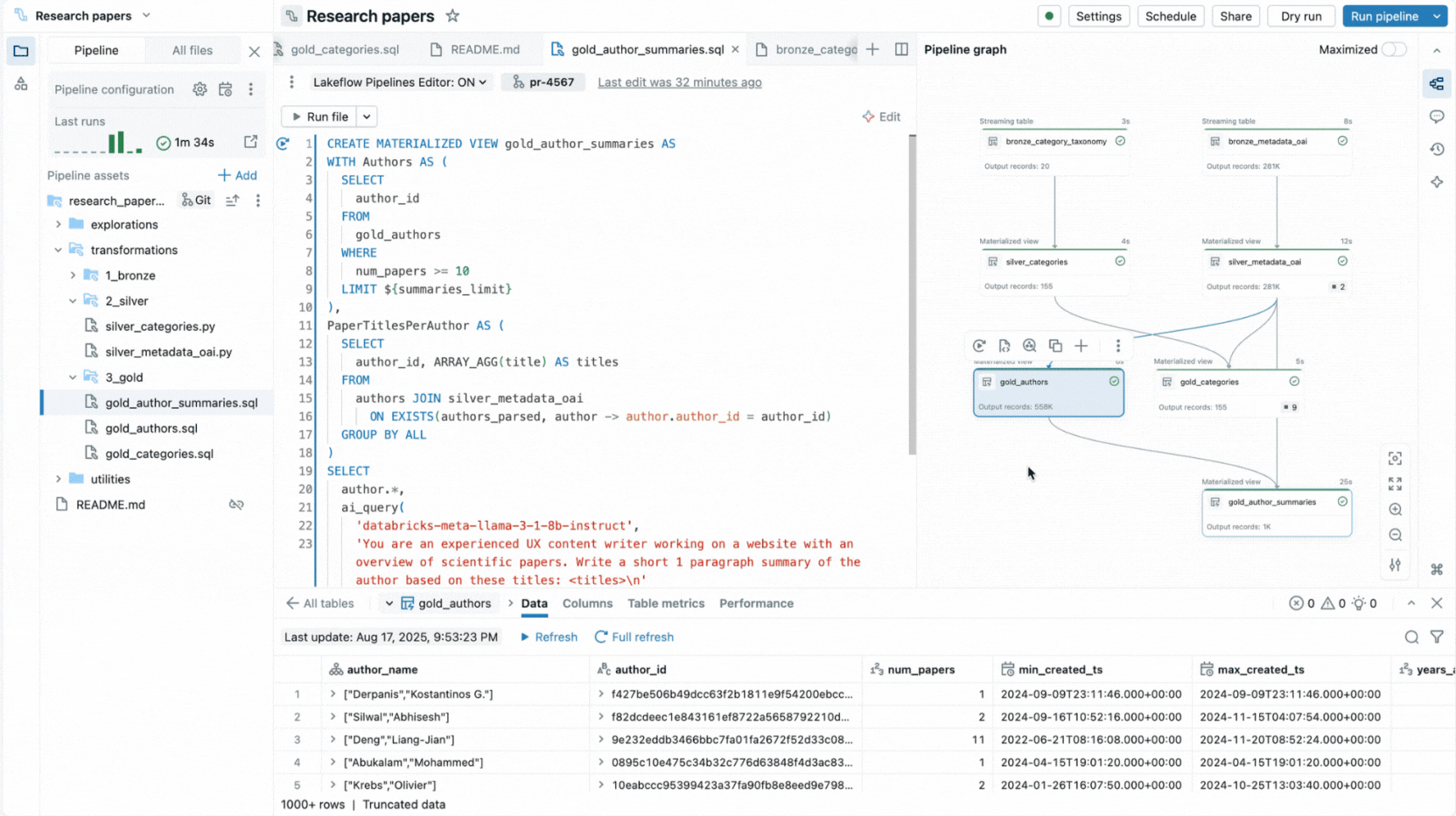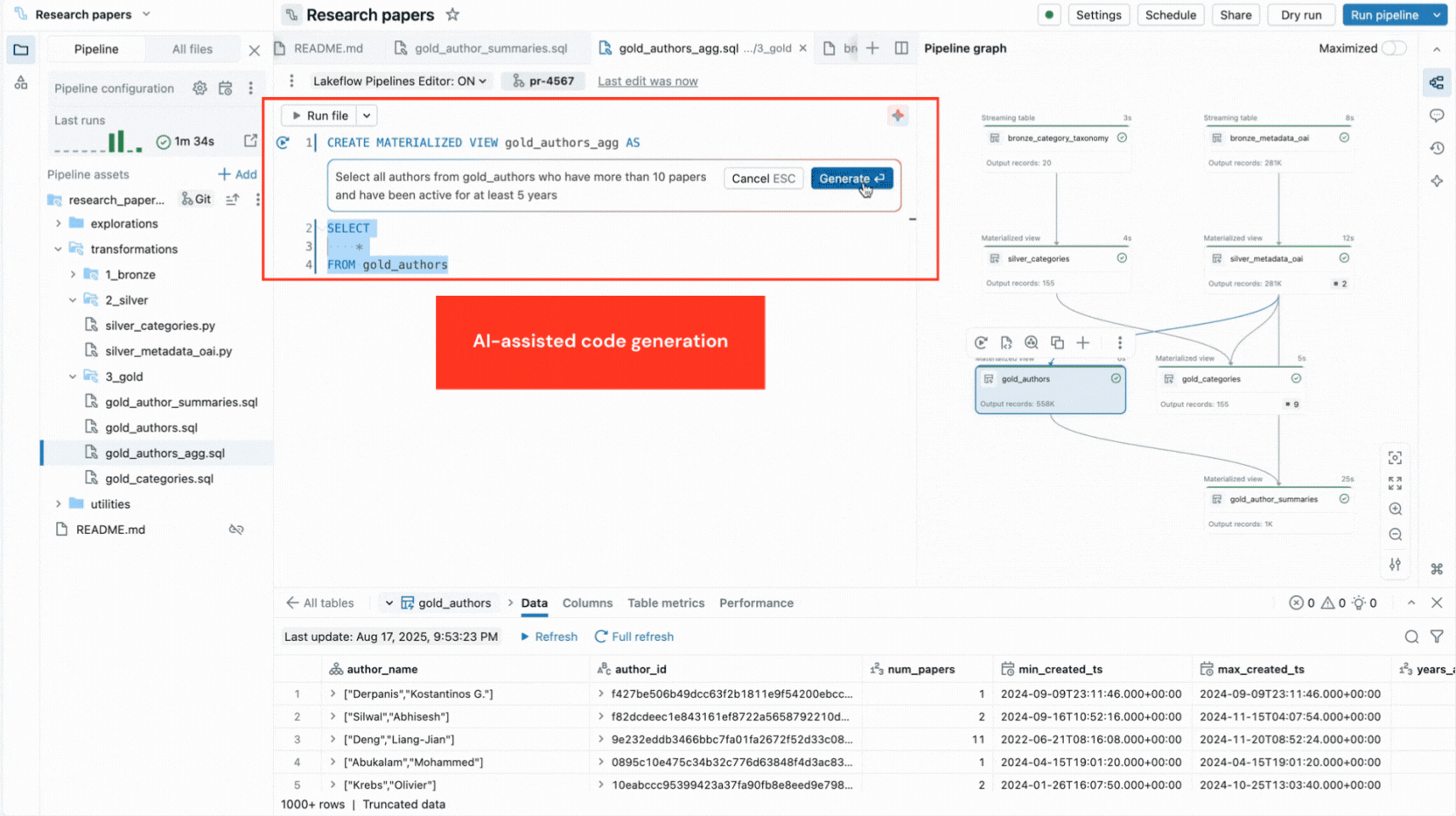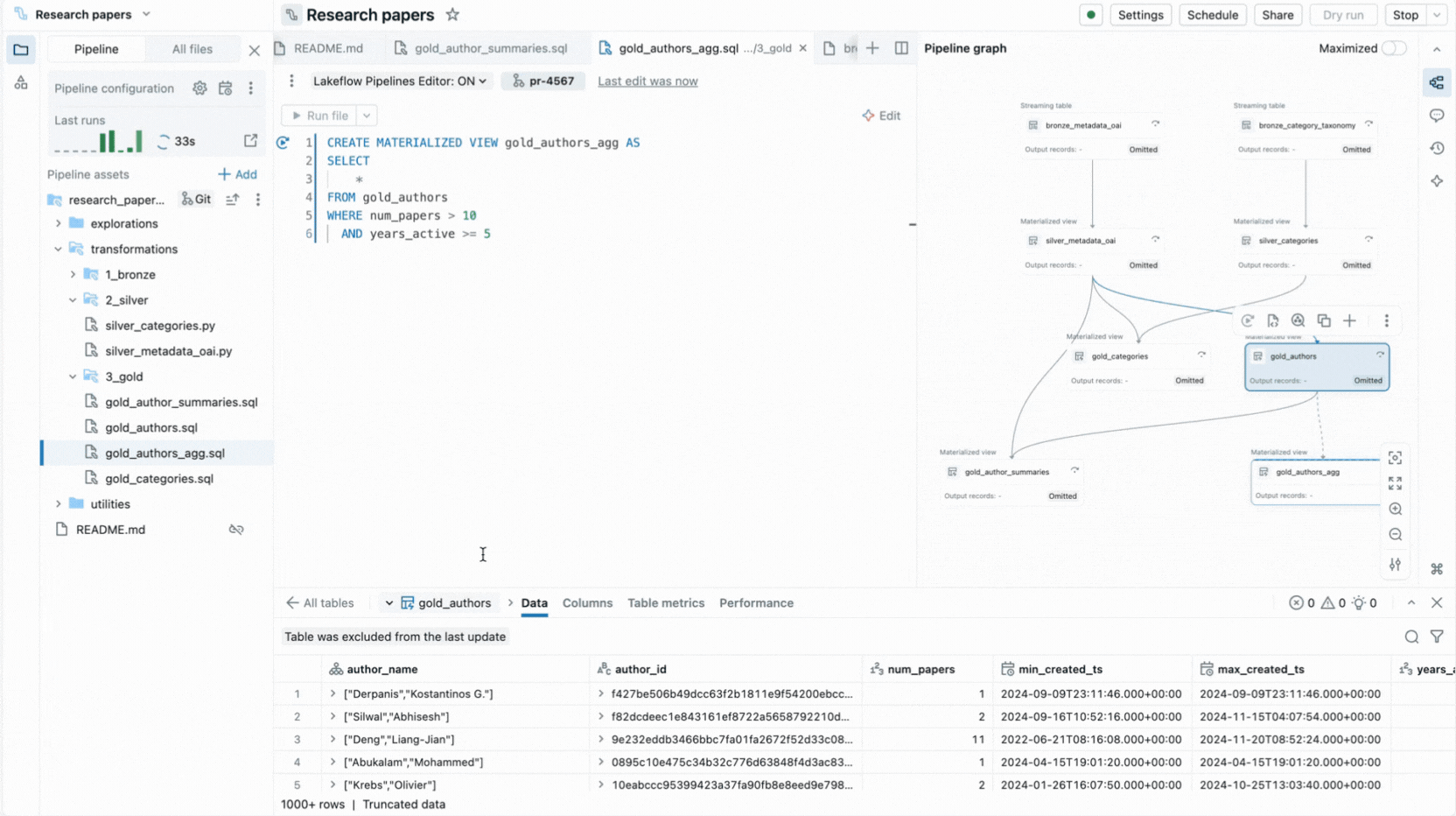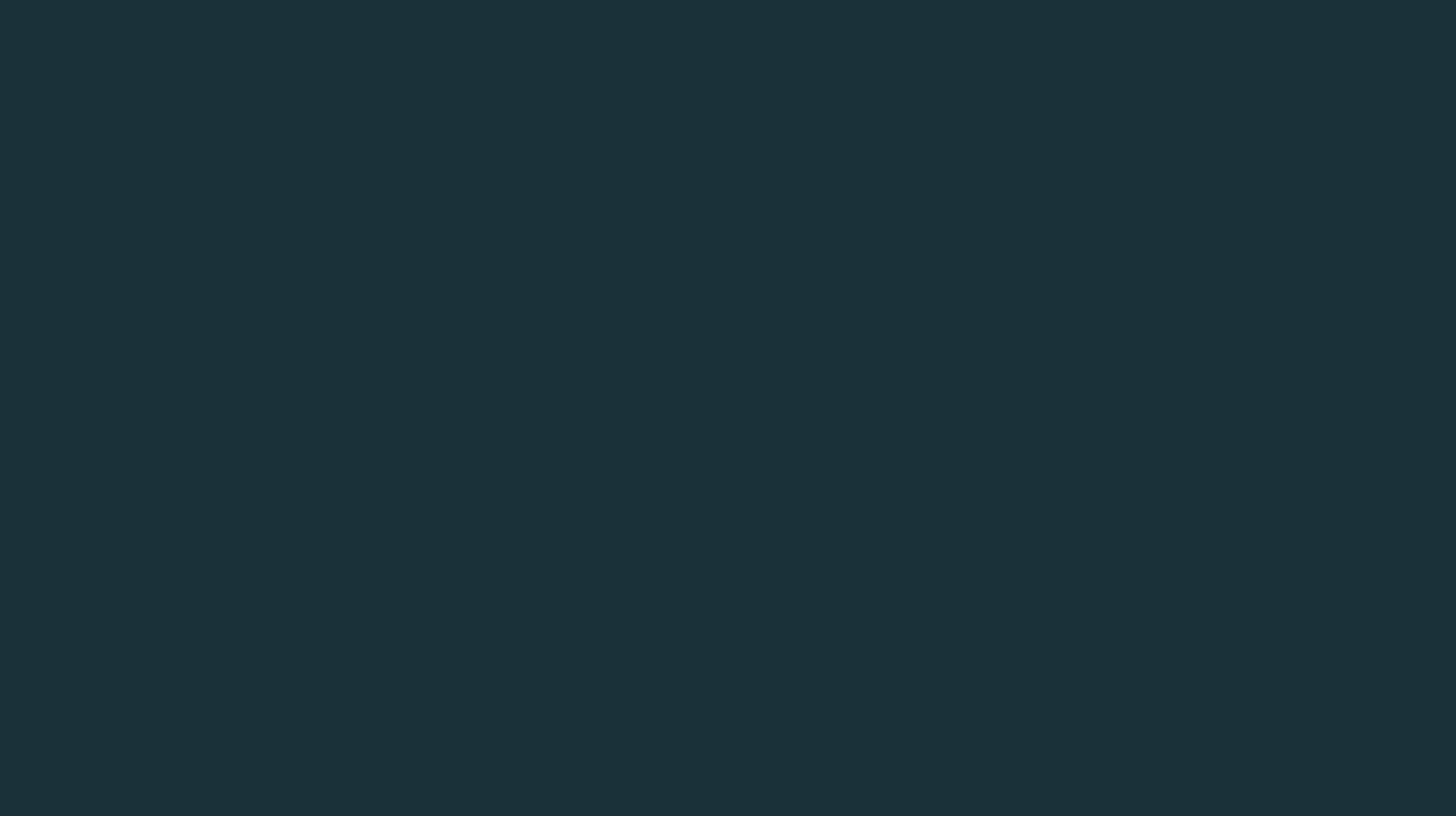
El editor también muestra información de ejecución, proporciona vistas previas de datos integradas e incluye herramientas de depuración para ayudarte a ajustar tu código. También se integra con el control de versiones y la ejecución programada con Lakeflow Jobs. Por lo tanto, puedes realizar todas las tareas relacionadas con tu pipeline desde una única interfaz.
Al consolidar todas estas capacidades en una única interfaz similar a un IDE, el editor permite las prácticas y la productividad que los ingenieros de datos esperan de un IDE moderno, al tiempo que se mantiene fiel al paradigma declarativo.
El video incrustado a continuación muestra estas características en acción, con más detalles cubiertos en las siguientes secciones.
"El nuevo editor lo reúne todo en un solo lugar: código, grafo del pipeline, resultados, configuración y solución de problemas. No más malabarismos con pestañas del navegador o pérdida de contexto. El desarrollo se siente más enfocado y eficiente. Puedo ver directamente el impacto de cada cambio de código. Un clic me lleva a la línea de error exacta, lo que acelera la depuración. Todo está conectado: código a datos; código a tablas; tablas al código. Cambiar entre pipelines es fácil, y características como las carpetas de utilidad autoconfiguradas eliminan la complejidad. Esto se siente como debería ser el desarrollo de pipelines."—Chris Sharratt, Ingeniero de Datos, Rolls-Royce
"En mi opinión, el nuevo Editor de Pipelines es una gran mejora. Me resulta mucho más fácil gestionar estructuras de carpetas complejas y cambiar entre archivos gracias a la experiencia de pestañas múltiples. La vista DAG integrada realmente me ayuda a mantenerme al tanto de pipelines intrincados, y el manejo de errores mejorado cambia las reglas del juego: me ayuda a identificar problemas rápidamente y agiliza mi flujo de trabajo de desarrollo."—Matt Adams, Desarrollador Senior de Plataformas de Datos, PacificSource Health Plans
Facilidad para empezar
Diseñamos el editor para que incluso los usuarios nuevos en el paradigma declarativo puedan crear rápidamente su primer pipeline.
- Configuración guiada permite a los usuarios nuevos comenzar con código de ejemplo, mientras que los usuarios existentes pueden configurar configuraciones avanzadas, como pipelines con CI/CD integrado a través de Databricks Asset Bundles.
- Estructuras de carpetas sugeridas proporcionan un punto de partida para organizar activos sin imponer convenciones rígidas, por lo que los equipos también pueden implementar sus propios patrones organizativos establecidos. Por ejemplo, puedes agrupar transformaciones en carpetas para cada etapa de Medallion, con un conjunto de datos por archivo.
- Configuraciones predeterminadas permiten a los usuarios escribir y ejecutar su primer código sin una gran sobrecarga de configuración inicial, y ajustar la configuración más tarde, una vez que se define su carga de trabajo de extremo a extremo.
Estas características ayudan a los usuarios a ser productivos rápidamente y a transicionar su trabajo a pipelines listos para producción.
Eficiencia en el bucle de desarrollo interno
Construir pipelines es un proceso iterativo. El editor agiliza este proceso con características que simplifican la creación y hacen que sea más rápido probar y refinar la lógica:
- Generación de código y plantillas de código impulsadas por IA aceleran las definiciones de conjuntos de datos y las restricciones de calidad de datos, y eliminan pasos repetitivos.
- Ejecución selectiva te permite ejecutar una sola tabla, todas las tablas en un archivo o todo el pipeline.
- Grafo de pipeline interactivo proporciona una visión general de las dependencias de los conjuntos de datos y ofrece acciones rápidas como vistas previas de datos, repeticiones, navegación al código o adición de nuevos conjuntos de datos con código boilerplate generado automáticamente.
- Vistas previas de datos integradas te permiten inspeccionar los datos de la tabla sin salir del editor.
- Errores contextuales aparecen junto al código relevante, con sugerencias de corrección del Asistente de Databricks.
- Paneles de información de ejecución muestran métricas de conjuntos de datos, expectativas, rendimiento de consultas, con acceso a perfiles de consulta para la optimización del rendimiento.
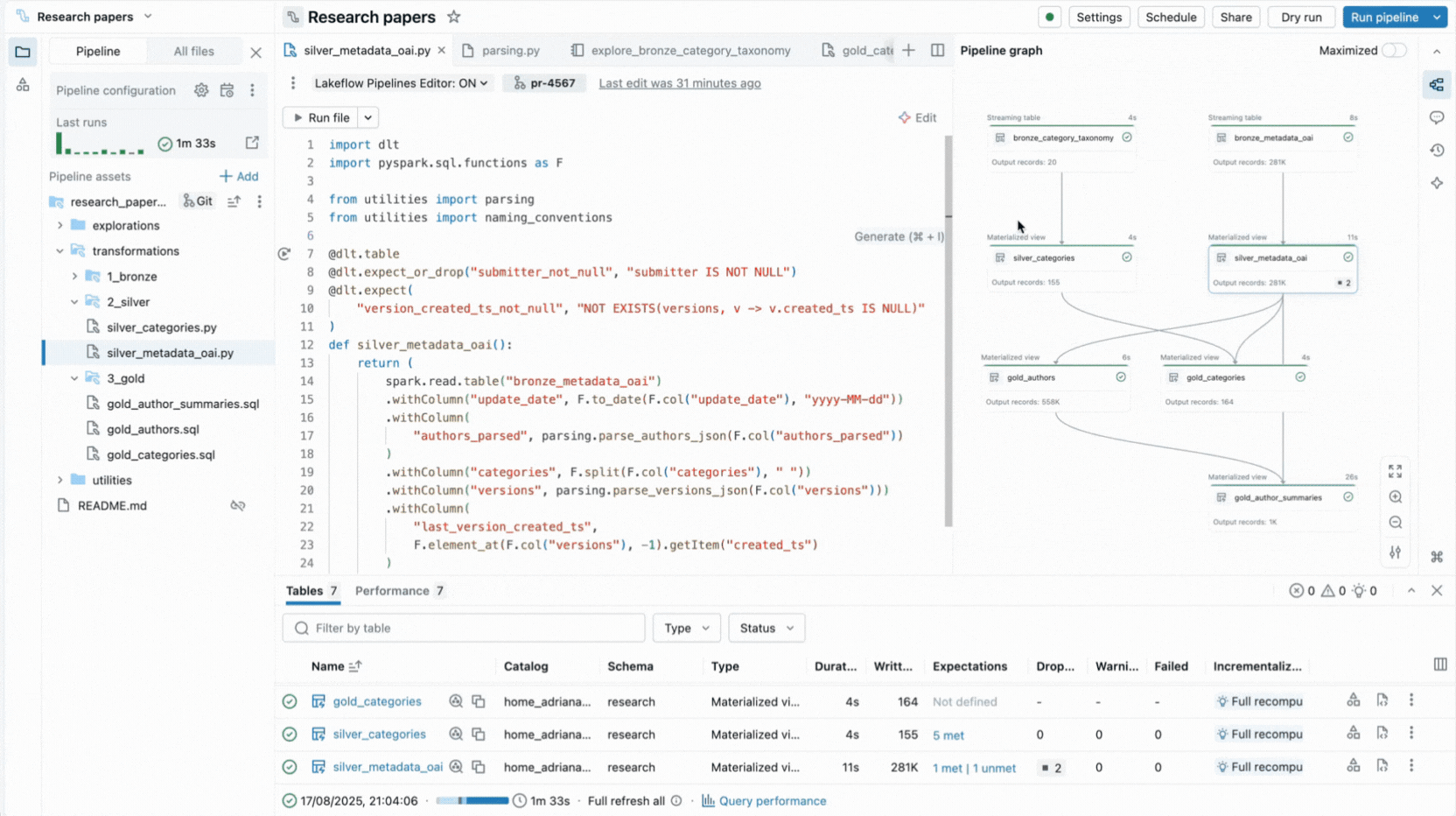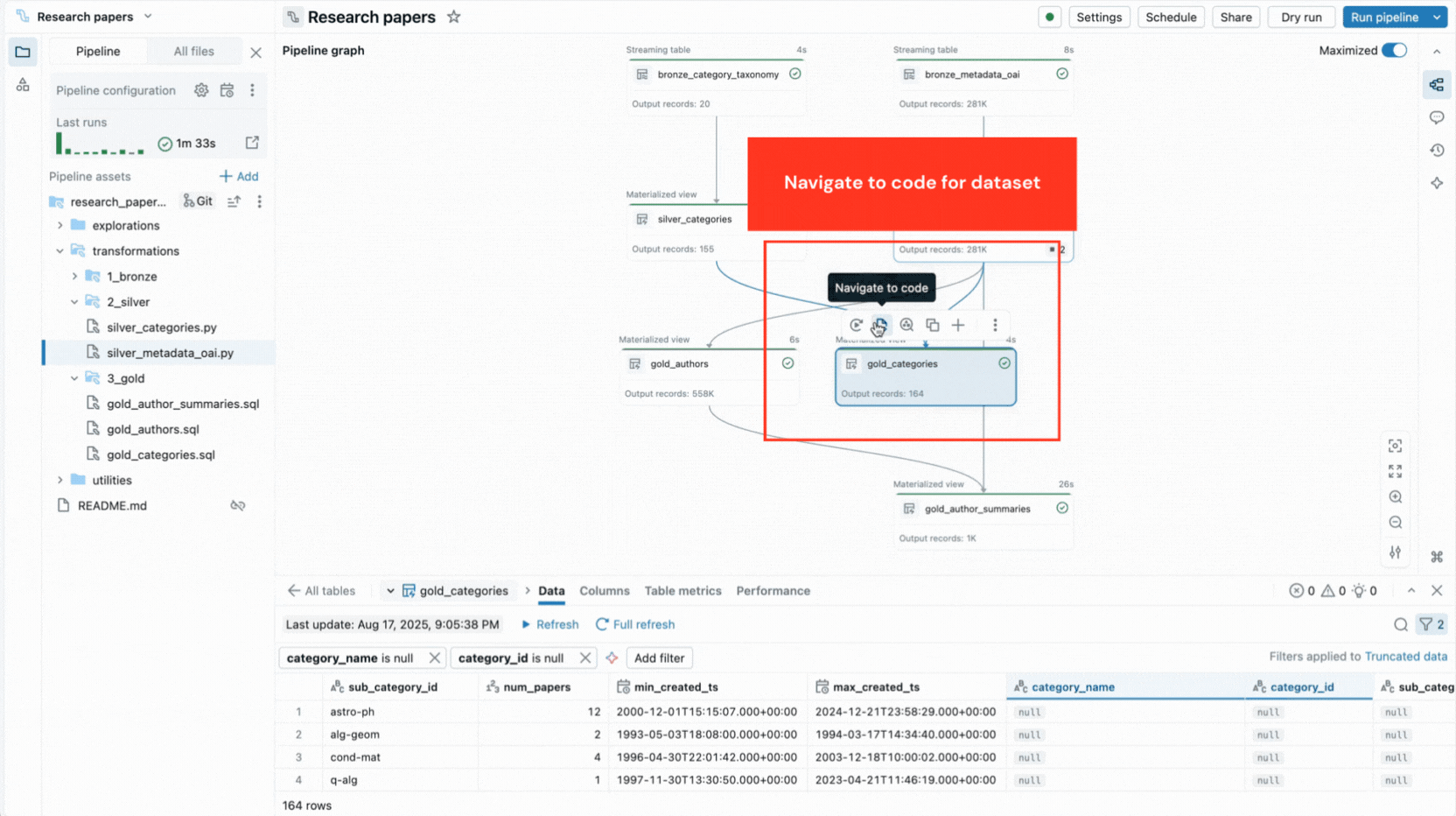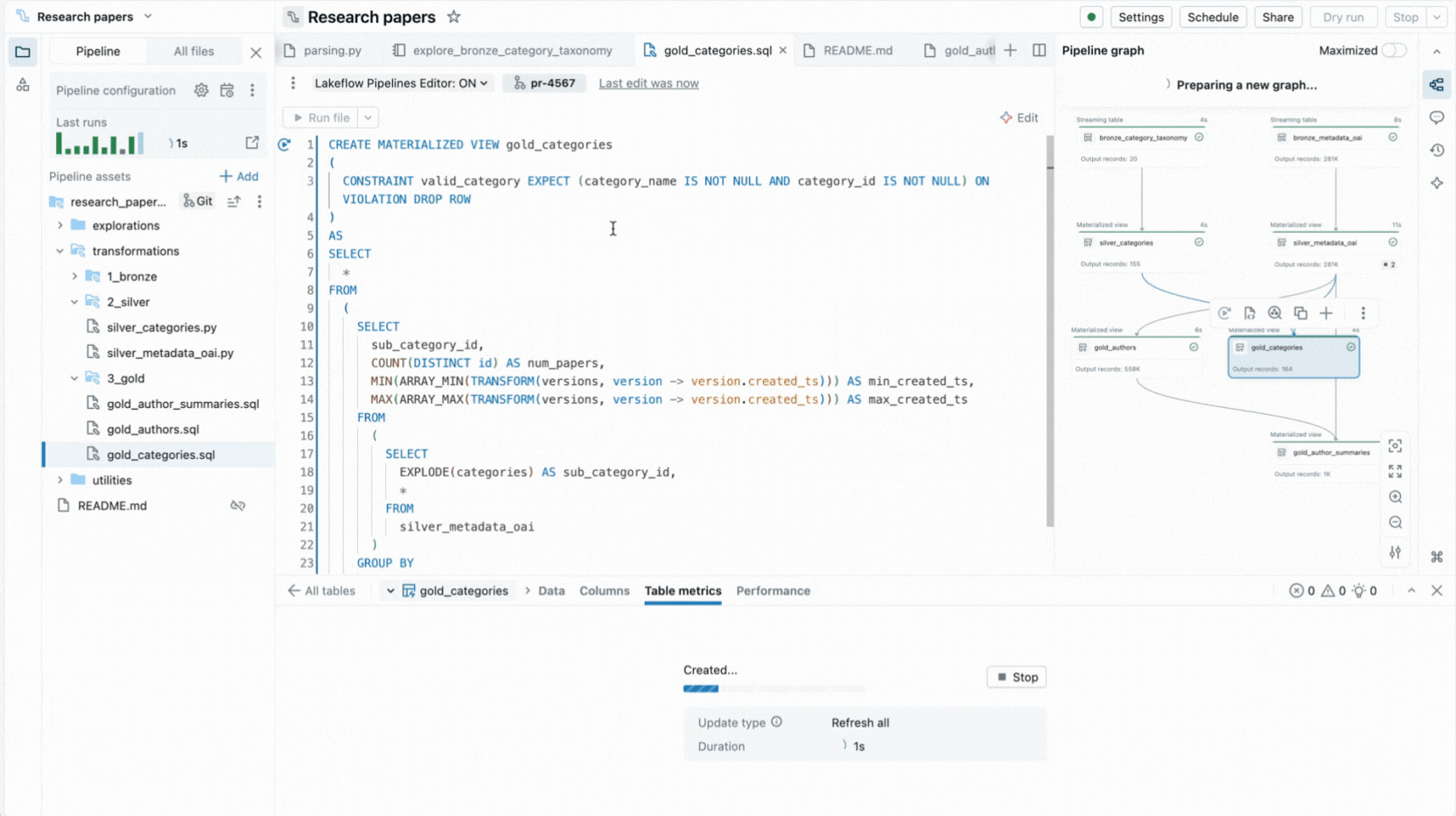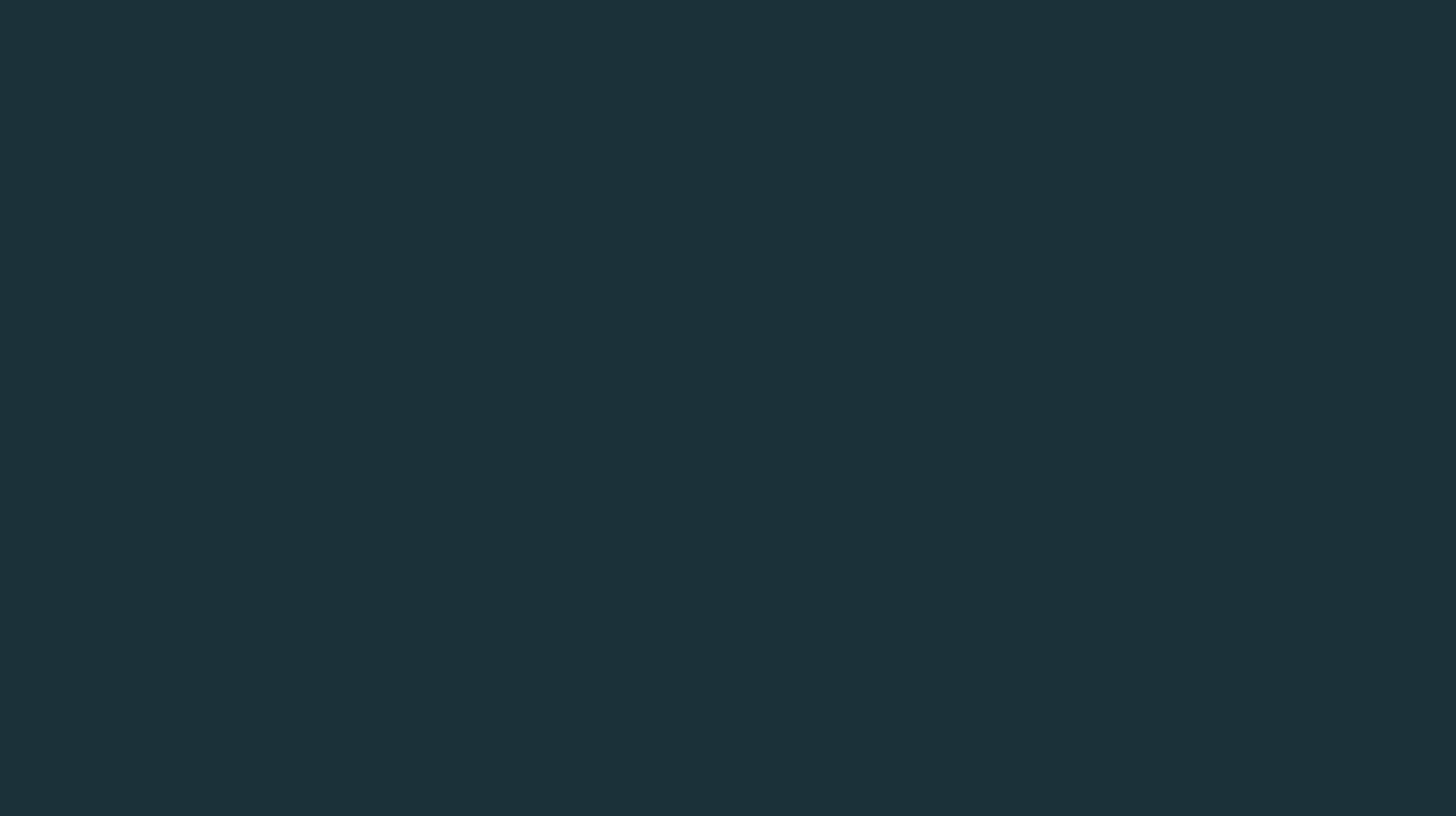
Estas capacidades reducen el cambio de contexto y mantienen a los desarrolladores enfocados en construir la lógica del pipeline.
Una única interfaz para todas las tareas
El desarrollo de pipelines implica más que escribir código. La nueva experiencia de desarrollador reúne todas las tareas relacionadas en una única interfaz, desde la modularización del código para su mantenibilidad hasta la configuración de la automatización y la observabilidad:
- Organiza código adyacente, como notebooks exploratorios o módulos Python reutilizables, en carpetas dedicadas, edita archivos en varias pestañas y ejecútalos por separado de la lógica del pipeline. Esto mantiene el código relacionado descubrible y tu pipeline ordenado.
- Control de versiones integrado a través de carpetas Git permite un trabajo seguro y aislado, revisiones de código y solicitudes de extracción a repositorios compartidos.
- CI/CD con soporte de Databricks Asset Bundles para pipelines conecta el desarrollo del bucle interno con la implementación. Los administradores de datos pueden forzar pruebas y automatizar la promoción a producción utilizando plantillas y archivos de configuración, todo ello sin añadir complejidad al flujo de trabajo de un profesional de datos.
- Automatización y observabilidad integradas permiten la ejecución programada de pipelines y proporcionan acceso rápido a ejecuciones pasadas para monitoreo y solución de problemas.
Al unificar estas capacidades, el editor agiliza tanto el desarrollo diario como las operaciones de pipeline a largo plazo.
Consulta el video a continuación para obtener más detalles sobre todas estas características en acción.
¿Qué sigue?
No nos detenemos aquí. Aquí tienes un adelanto de lo que estamos explorando actualmente:
- Soporte nativo para pruebas de datos en Lakeflow Spark Declarative Pipelines y ejecutores de pruebas en el editor
- Generación de pruebas asistida por IA para acelerar la validación
- Experiencia de agente para Lakeflow Spark Declarative Pipelines.
Haznos saber qué más te gustaría ver: tus comentarios impulsan lo que construimos.
Empieza hoy mismo con la nueva experiencia de desarrollador
El IDE para ingeniería de datos está disponible en todas las nubes. Para habilitarlo, abre un archivo asociado con un pipeline existente, haz clic en el banner 'Lakeflow Pipelines Editor: OFF' y actívalo. También puedes habilitarlo durante la creación del pipeline con un interruptor similar, o desde la página de Configuración del Usuario.
Obtén más información utilizando estos recursos:
- Consulta la documentación.
- Mira la charla Authoring Data Pipelines With the New Editor en el Data + AI Summit 2025.
- Consulta Lakeflow in Production: CI/CD, Testing and Monitoring at Scale en el Data + AI Summit 2025.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.