Toma de Decisiones en Tiempo Real para Agentes de IA: Por qué Primero Necesitas una Capa de Contexto del Cliente
Una perspectiva de Snowplow sobre "The New Martech Stack for the AI Age" de Scott Brinker
por Alex Dean
- Scott Brinker publicó recientemente un informe de investigación con Databricks, The New Martech “Stack” for the AI Age, que describió un cambio de 3 a 5 años de arquitecturas rígidas a un lienzo componible y fluido para la arquitectura de marketing.
- Alex Dean, cofundador y CEO de Snowplow, comparte su perspectiva sobre cómo la capa de contexto del cliente captura datos de comportamiento en tiempo real que los agentes de IA utilizan para tomar decisiones en el momento.
- El bucle de retroalimentación del agente convierte el marketing en un volante de inercia: recopila y unifica el comportamiento humano y de IA en tiempo real, actívalo para la toma de decisiones, y luego cierra el bucle para que los agentes aprendan y mejoren continuamente en función de los resultados.
El nuevo informe de Scott Brinker con Databricks articula algo que he estado observando tomar forma durante años: el "stack" de martech, la familiar disposición de Tetris de cajas, está comenzando a disolverse. Lo que está surgiendo en su lugar es lo que Scott llama un lienzo componible: una arquitectura fluida y centrada en los datos donde los agentes de IA y el software personalizado operan sobre datos compartidos en lugar de luchar a través de canalizaciones de integración.
Al leerlo, me encontré asintiendo más de una vez. No porque sea una tesis fácil de hacer (en realidad, es un replanteamiento bastante radical de cómo las empresas piensan sobre la tecnología de marketing), sino porque describe una dirección arquitectónica a la que en Snowplow nos comprometimos hace mucho tiempo, a menudo antes de que existiera un vocabulario compartido para ello.
Quería compartir algunas reacciones: dónde resuena fuertemente el informe, cómo creemos que Snowplow encaja en la arquitectura que describe y una dimensión que agregaría al modelo que creo que se vuelve más importante a medida que los agentes de IA asumen un papel más importante en las interacciones con los clientes.
La plataforma de datos es ahora el centro de gravedad para la toma de decisiones en tiempo real
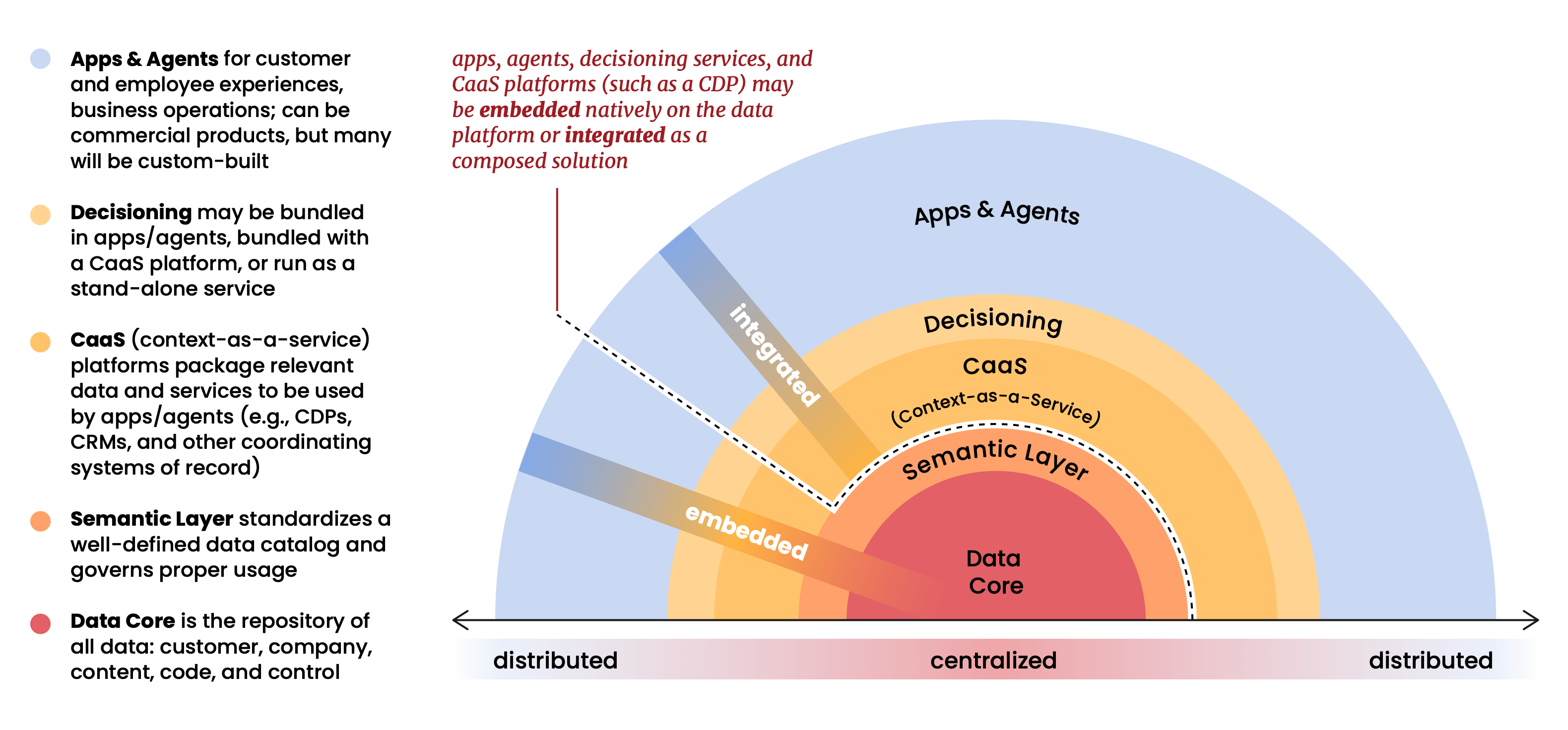
El argumento estructural central del informe es que la plataforma de datos (Databricks, Snowflake, BigQuery, etc.) se ha convertido en el centro gravitacional de todo el stack de martech. Las aplicaciones, los agentes y los análisis ya no se asientan sobre los datos; operan dentro de ellos. La plataforma de datos ya no es un repositorio en la parte inferior del stack. Es el stack.
Esta es una visión que hemos tenido en Snowplow durante mucho tiempo, y es una que dio forma a muchas de las primeras decisiones sobre cómo construimos nuestro producto. Cuando estábamos armando Snowplow en 2012, el modelo predominante era acumular datos de clientes dentro de los sistemas de los proveedores y proporcionar acceso administrado a ellos. Tomamos la posición opuesta: sus datos pertenecen a su infraestructura, gobernados por sus reglas, consultables por cualquier herramienta que elija. En ese momento, se sintió como una postura arquitectónica de principios, tal vez incluso un poco contraria. Como deja claro este informe, ahora es la única arquitectura que tiene sentido a escala.
¿Qué es la Capa de Contexto del Cliente? Y por qué la toma de decisiones en tiempo real depende de ella
¿Qué es la capa de contexto del cliente? La capa de contexto del cliente es la infraestructura de comportamiento en tiempo real que se encuentra entre su base de datos y sus sistemas orientados al cliente. Está conectada directamente a las experiencias digitales para que los agentes de IA puedan comprender lo que un cliente está haciendo en este momento, además de su historial completo.
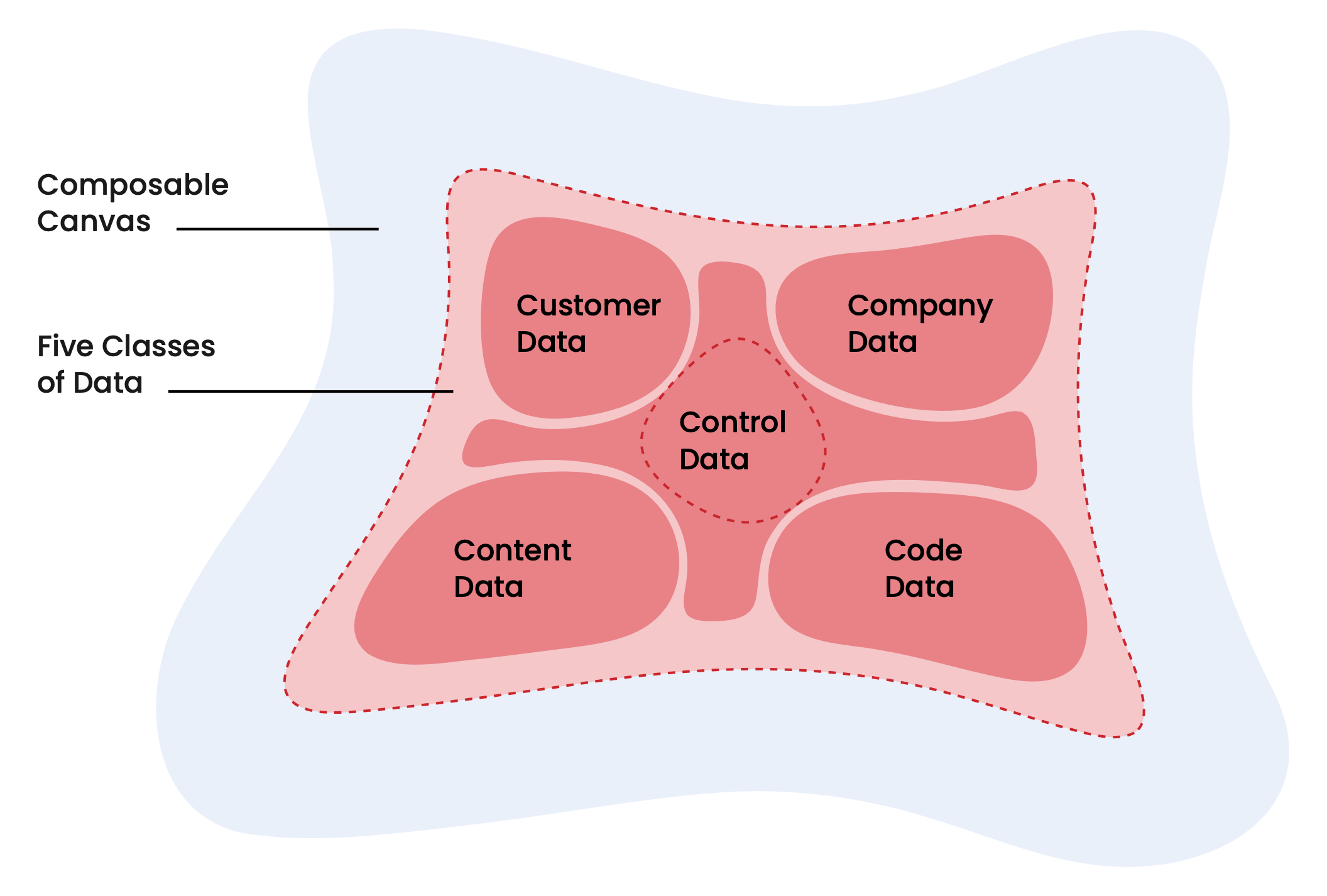
El informe describe cinco clases de datos que convergen en la base unificada: datos del cliente, datos de la empresa, datos de contenido, datos de código y datos de control. Datos del cliente: "perfiles individuales y de cuentas, historiales de transacciones, señales de comportamiento (visitas web, uso del producto)" se encuentra en el centro de todo.
Aquí es donde opera Snowplow. Pero me gustaría ampliar un poco el encuadre más allá de lo que hace el informe.
Hay una diferencia significativa entre registros de clientes y contexto del cliente. Los CRM y CDP han gestionado bien lo primero durante mucho tiempo: quién es el cliente, qué acuerdos tiene, a qué segmentos pertenece. Lo que ha sido consistentemente más difícil de servir es lo último, es decir: ¿qué está haciendo, en este momento, y qué le dice ese comportamiento sobre su intención?
Los flujos de eventos de comportamiento, el registro continuo y granular de cómo los clientes interactúan con su producto, su sitio web, su aplicación, son la señal en tiempo real más rica disponible para cualquier agente de IA que intente tomar una decisión. Y son notoriamente difíciles de hacer bien. Los eventos deben estructurarse en el punto de recopilación, validarse contra un esquema y enriquecerse antes de llegar a la base de datos. Si los datos de comportamiento que ingresan a su plataforma unificada son ruidosos, inconsistentes o están mal modelados, los agentes de IA que operan sobre ellos agravarán esos errores a escala.
Snowplow es la capa de contexto del cliente. Nos ubicamos entre el momento en que un cliente hace algo (un clic, un evento de producto, una búsqueda, un desplazamiento) y la plataforma de datos que necesita actuar sobre ello. Nuestro trabajo es garantizar que los datos de comportamiento estén estructurados, bien gobernados y semánticamente coherentes desde el momento en que se crean.
Y el contexto sin identidad es ruido. Un flujo de comportamiento enriquecido solo es tan útil como su capacidad para vincularlo a un individuo conocido y resuelto a través de puntos de contacto, dispositivos y sesiones, incluidas las transiciones entre estados anónimos y autenticados. Las Identidades de Snowplow realizan este trabajo en la capa de recopilación, antes de que los datos lleguen a la plataforma. El resultado no es solo un flujo de eventos. Es una imagen resuelta y continua del viaje de cada cliente sobre la que su plataforma de datos, sus analistas y sus agentes de IA pueden operar con confianza.
La componibilidad siempre fue la arquitectura, no la característica
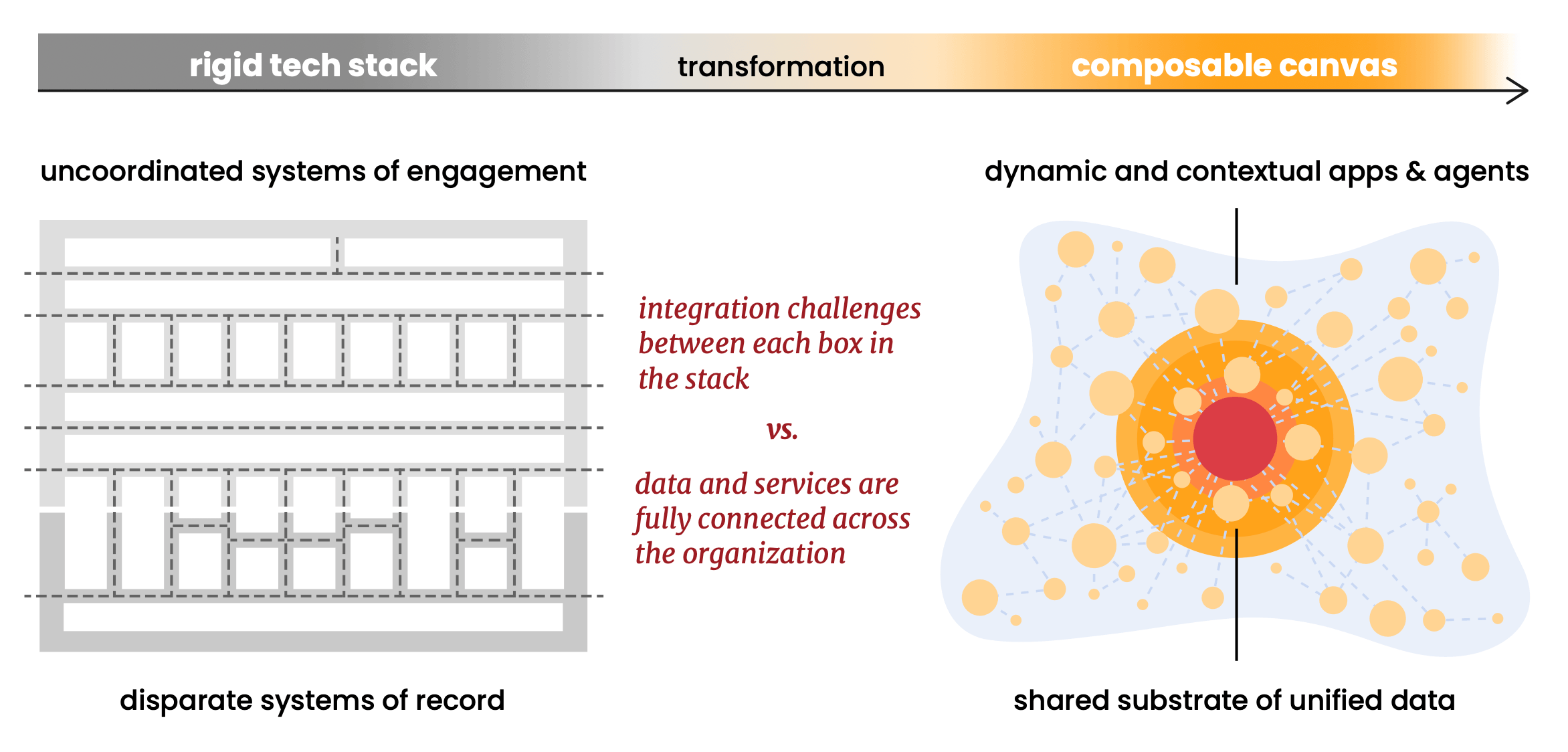
El argumento de componibilidad del informe es uno de sus puntos más fuertes. Aboga por formatos de datos abiertos (Linux Foundation Delta Lake, Apache Iceberg), protocolos abiertos (MCP para agentes) y estándares abiertos como precondición para un lienzo genuinamente componible. El principio: estandarizar la base para poder diversificar todo lo que se ejecuta sobre ella.
Creemos profundamente en esto, y construimos Snowplow sobre él desde el principio. Creemos en los estándares de código abierto. Nuestras estructuras de datos se ejecutan de forma nativa en Apache Iceberg y Linux Foundation Delta Lake. Nos ejecutamos dentro de su cuenta en la nube (referenciada como hiperscaladores en la pieza de Scott: AWS, GCP o Azure), lo que significa que sus datos de comportamiento nunca abandonan su entorno. No hay un almacén de datos propietario de Snowplow que se convierta en una dependencia o un riesgo de migración. Cuando desea reemplazar o extender cualquier parte del stack, los datos de comportamiento ya están donde deben estar: en su plataforma, en formatos abiertos, listos para componer.
El informe señala que los "CDP componibles invierten" el modelo tradicional al llevar las capacidades de CDP a los datos en lugar de extraer datos al CDP. Snowplow estaba haciendo esto antes de que la categoría tuviera un nombre, porque para nosotros, la componibilidad nunca fue una característica que agregamos. Fue el principio fundamental sobre el que se construyó el producto.
La capa semántica comienza antes de la plataforma
Una de las ideas más importantes que desarrolla el informe es el papel de la capa semántica, específicamente lo que llama "el guardián de la coherencia". Este es el vocabulario compartido que hace que los datos sean significativos y consistentes en todos los agentes y aplicaciones que los tocan. Qué significa "cliente" en todos los equipos. Cómo se calcula la "conversión". Qué constituye un "cliente potencial calificado".
Desde nuestro punto de vista, agregaría una observación práctica: la mayoría de estas preguntas deben responderse antes de que los datos ingresen a la plataforma, no después. Los datos de comportamiento en particular son notablemente fáciles de recopilar mal. Los eventos llegan con nombres inconsistentes, propiedades faltantes, esquemas indefinidos. Para cuando los datos llegan a la plataforma, ya son incoherentes. Puede construir una capa semántica sobre datos malos, pero está encubriendo un problema estructural en lugar de resolverlo.
El registro de esquemas de Snowplow y la validación de eventos a través de nuestro Event Studio imponen la coherencia semántica en el punto de recopilación. Rechazamos o marcamos los eventos que no se ajustan a las estructuras definidas antes de que lleguen a la plataforma de datos. En el lienzo componible que describe el informe, donde docenas de agentes y aplicaciones extraen datos de comportamiento de la misma fuente, la calidad de esos datos en el origen es lo que determina si se puede confiar en cualquier cosa construida sobre ellos.
El Bucle de Retroalimentación Agéntica: Cómo se cierra realmente la toma de decisiones en tiempo real
El informe hace un punto que creo que merece aún más énfasis: los agentes de IA son "ávidos de contexto". No solo necesitan registros de clientes; necesitan comprender lo que está sucediendo en el momento, es decir, las señales de comportamiento que indican intención, urgencia y oportunidad.
Agregaría algo al modelo que Scott ha presentado aquí. El informe presenta los datos fluyendo hacia los agentes, una base de la que los agentes extraen para tomar decisiones. Lo que no desarrolla completamente es el bucle que ocurre después de que el agente actúa, y por qué cerrar ese bucle es cada vez más el problema de datos estratégicamente más importante en martech. Esto es algo en lo que pensamos mucho en Snowplow, y es central en cómo opera realmente el lienzo componible en la práctica.
El bucle tiene cuatro etapas:
- La etapa de Recopilación captura eventos de comportamiento tanto de interacciones humanas como impulsadas por IA como datos estructurados y validados por esquema que fluyen continuamente a la plataforma de datos. Pero la definición de "datos de comportamiento" necesita expandirse para incluir una segunda clase de actividad que la mayoría de las arquitecturas aún no están capturando bien. Esta segunda clase tiene dos caras distintas. La primera son las Analíticas de Agentes de IA: cuando un cliente interactúa con un agente conversacional, recibe una recomendación personalizada o tiene un recorrido moldeado por un sistema de toma de decisiones automatizado, esas interacciones impulsadas por agentes son en sí mismas eventos que deben recopilarse con el mismo rigor que cualquier comportamiento humano. La segunda son las Analíticas Agénticas: agentes de IA que investigan en nombre de un usuario. Cuando una IA está navegando por las páginas de su producto, leyendo su documentación o comparando opciones como proxy de un cliente, ese tráfico es intención, solo que expresado a través de un actor no humano. Tratarlo como ruido de bot a filtrar significa descartar una señal que le dice algo real sobre lo que un cliente está evaluando. Snowplow distingue y captura ambos como eventos de comportamiento estructurados, separados de la interacción humana directa pero igualmente significativos para comprender la intención e informar la toma de decisiones.
- La etapa de Resolución y Enriquecimiento transforma flujos de eventos brutos en una imagen coherente del cliente a través de la resolución de identidad, uniendo sesiones, dispositivos y puntos de contacto a un individuo conocido. Aquí es donde el flujo de comportamiento se convierte en una imagen coherente: no "un usuario visitó tres páginas", sino "esta cuenta, actualmente en etapa avanzada de evaluación, ha tenido tres ejecutivos investigando precios en las últimas 48 horas".
- La etapa de Servicio entrega contexto de comportamiento enriquecido en dos modos simultáneos: en tiempo real para personalización en sesión, y combinado en tiempo real más histórico para la toma de decisiones de agentes de IA. Para la personalización en sesión, es en tiempo real: la plataforma de datos expone señales de comportamiento lo suficientemente rápido como para que la experiencia que se está renderizando a este cliente ahora mismo refleje lo que ha estado haciendo en esta sesión. Para la toma de decisiones de agentes de IA, es tanto en tiempo real como histórico: un agente que coordina la siguiente mejor acción para una cuenta se basa en el flujo de comportamiento en vivo y el registro histórico completo del cliente. La pregunta no es solo "¿qué está haciendo este cliente?", sino "¿qué significa este comportamiento, dado todo lo que sabemos sobre clientes como ellos?"
- La etapa de Aprendizaje cierra el bucle de retroalimentación al dirigir los resultados de cada decisión del agente de vuelta a la base de datos como eventos de comportamiento de primera clase. El resultado de cada decisión del agente, cada experiencia personalizada, cada acción automatizada es en sí mismo un evento de comportamiento. ¿Se añadió el producto recomendado al carrito? ¿Se abrió el correo electrónico personalizado? ¿La intervención en sesión cambió la trayectoria de la sesión? ¿La sesión de investigación del agente de IA finalmente se convirtió? Estos resultados deben fluir de regreso a la misma base de datos que impulsó la decisión original. Sin esta retroalimentación, los agentes de IA operan con datos históricos que se vuelven más obsoletos cada día. Con ella, el sistema se vuelve genuinamente auto-mejora.
Aquí es donde las Analíticas de Agentes de IA y las Analíticas Agénticas completan el ciclo. Ha recopilado eventos de comportamiento de agentes de IA como datos de primera clase; ahora puede analizarlos con el mismo rigor que aplicaría al comportamiento humano. ¿Qué agentes están rindiendo? ¿Qué modelos de toma de decisiones se están degradando? ¿Dónde se está convirtiendo el tráfico de investigación generado por IA y dónde está cayendo? Estas preguntas solo pueden responderse si la recopilación fue correcta desde el principio. Las analíticas de Agentes de IA y Agénticas no son una capa de informes que se añade más tarde. Son una consecuencia de cómo recopiló los datos en primer lugar.
Este es el bucle de retroalimentación que es único para hacer bien la infraestructura de datos de comportamiento. No es una tubería. Es un volante de inercia.
De analíticas a toma de decisiones: las herramientas adecuadas para la toma de decisiones en tiempo real
Algo que el informe sugiere y que creo que merece más espacio, especialmente para los líderes de marketing y datos que piensan en lo que la IA realmente requiere de su pila tecnológica: el cambio de usar datos de comportamiento para analíticas a usarlos para toma de decisiones es un cambio arquitectónico significativo, no simplemente una expansión de casos de uso.
Las analíticas miran hacia atrás. Recopila eventos, los modela y consulta los resultados. La latencia de minutos u horas es aceptable. Los datos informan a un humano que toma una decisión.
La toma de decisiones mira hacia adelante y es en tiempo real. Un agente de IA necesita contexto de comportamiento en milisegundos para determinar qué experiencia servir a este cliente, en esta sesión, ahora mismo. Los requisitos de infraestructura son diferentes. Los requisitos de calidad de datos son más altos porque los errores no aparecen como una anomalía en un panel que alguien detecta la próxima semana; aparecen como una mala experiencia del cliente entregada instantáneamente, a escala.
Desafortunadamente, la mayoría de las tuberías de datos fuerzan una compensación. Algunas optimizan la velocidad, pero hacen que pierda la profundidad histórica. Y otras optimizan la riqueza, pero hacen que pierda el margen de latencia que necesita la toma de decisiones en tiempo real.
El lienzo componible exige ambos al mismo tiempo, sobre los mismos datos. Ese es un problema de infraestructura más difícil de lo que parece, y vale la pena resolverlo en la base en lugar de intentar parchearlo más tarde cuando un agente está tomando decisiones a velocidad de milisegundos y se da cuenta de que su contexto histórico está en una tienda separada.
Sobre grafos de contexto y datos de comportamiento
El informe introduce un concepto que me pareció genuinamente interesante: el grafo de contexto — un registro vivo de rastros de decisiones que captura no solo qué sucedió sino por qué se permitió que sucediera. Racional de decisión, concesiones de excepciones, cadenas de aprobación. El tipo de memoria institucional que actualmente vive en hilos de Slack y en la cabeza de las personas.
Argumentaría que los flujos de eventos de comportamiento son la materia prima natural para los grafos de contexto en el lado del cliente. Cada acción del agente que involucra a un cliente (una recomendación realizada, un segmento activado, un mensaje enviado) debe ser rastreable hasta las señales de comportamiento que la provocaron. El modelo de eventos de Snowplow está estructurado para capturar precisamente esta causalidad: qué señal se activó, qué datos se observaron, qué umbral se cruzó.
A medida que los grafos de contexto maduren como un patrón arquitectónico, la capa de datos de comportamiento será fundamental para ellos. El "qué sucedió" y el "por qué sucedió" están codificados en el flujo de eventos, si lo recopila correctamente desde el principio.
Cómo construir una base de toma de decisiones en tiempo real que escale
Para cualquier organización que esté construyendo hacia el lienzo componible que describe el informe, hacer bien la infraestructura de datos de comportamiento es la primera inversión de mayor apalancamiento: no porque sea la más emocionante, sino porque todo lo demás se ejecuta sobre ella.
Eso significa hacer bien cuatro cosas desde el principio:
- Recopilación estructurada con validación de esquemas integrada desde el primer día
- Resolución de identidad en la capa de recopilación, no adaptada posteriormente
- Una tubería construida para la toma de decisiones en tiempo real y análisis históricos sobre los mismos datos
- La disciplina de recopilar los resultados de las interacciones de los agentes de IA como eventos de comportamiento de primera clase, para que el bucle de retroalimentación se cierre desde el principio
La arquitectura componible también significa que las decisiones de proveedores que tome hoy deben ser reversibles. Si su tubería de datos de comportamiento escribe en formatos abiertos en su propia infraestructura en la nube, conserva la opcionalidad. Si escribe en un almacén propietario, ha creado una dependencia que limitará cada decisión futura sobre la pila tecnológica.
La 3ª Edad ya está aquí para quienes invirtieron temprano
El informe enmarca la Tercera Edad de Martech como un horizonte de 3-5 años. Para los clientes de Snowplow que ya han realizado las inversiones arquitectónicas descritas aquí, es decir: plataformas de datos como núcleo operativo, datos de comportamiento alimentando agentes en tiempo real, el bucle completo de retroalimentación de toma de decisiones a analíticas funcionando sobre una base componible, este no es un estado futuro. Ya es así como operan hoy.
Eso no es una afirmación sobre Snowplow específicamente. Es evidencia de que la arquitectura es factible ahora, para las organizaciones dispuestas a priorizarla. El lienzo componible no está esperando nueva tecnología. Está esperando decisiones arquitectónicas y la convicción para tomarlas.
El informe de Scott es una articulación clara y generosa de cuáles deberían ser esas decisiones. Nos complace ver que esta conversación se desarrolla con este nivel de profundidad, ¡y nos complace ser parte de ella!

Lea el informe de investigación completo de Scott Brinker aquí: El Nuevo "Stack" de Martech para la Era de la IA
Seminario web en vivo con Scott Brinker, CMO de Samsara y VP de Marketing Data Science de HP sobre cómo está evolucionando Martech para la IA: Regístrese para el seminario web
Si desea profundizar en cómo debe ser la base de datos para las analíticas agénticas, el equipo de Snowplow lo ha cubierto en detalle aquí: ¿Qué son las Analíticas Agénticas? Una Guía para Líderes de Datos
Preguntas frecuentes:
¿En qué se diferencia la toma de decisiones en tiempo real del procesamiento por lotes? El procesamiento por lotes recopila y analiza datos en intervalos programados, a menudo horas después de que ocurre una interacción. La toma de decisiones en tiempo real procesa señales de comportamiento en el momento en que se generan y activa una acción dentro de la misma sesión, a menudo en milisegundos. Los requisitos de infraestructura, los estándares de calidad de los datos y las tolerancias de latencia son fundamentalmente diferentes entre los dos enfoques.
¿Por qué los agentes de IA necesitan una capa de contexto del cliente? Los agentes de IA que toman decisiones en sesión requieren un contexto de comportamiento que refleje lo que un cliente está haciendo en este momento, no lo que hizo ayer. La capa de contexto del cliente proporciona flujos de eventos de comportamiento estructurados y resueltos por identidad a los que los agentes de IA pueden consultar en tiempo real. Sin ella, los agentes operan con datos obsoletos que degradan la calidad de las decisiones a escala.
¿Cuál es la diferencia entre los registros de clientes y el contexto del cliente? Los registros de clientes describen quién es un cliente: su perfil, historial de compras, estado de la cuenta y pertenencia a segmentos. El contexto del cliente describe lo que está haciendo en el momento actual: qué páginas ha visitado, qué ha buscado, cuánto tiempo ha interactuado y qué señala ese comportamiento sobre su intención. La toma de decisiones en tiempo real requiere ambos, pero la mayoría de las pilas de datos son mejores en lo primero que en lo segundo.
¿Cuáles son las cuatro etapas del bucle de retroalimentación del agente? El bucle de retroalimentación del agente atraviesa cuatro etapas: (1) Recopilar: capturar eventos de comportamiento de interacciones humanas y de IA como datos estructurados; (2) Resolver y enriquecer: vincular eventos a una identidad conocida y construir una imagen coherente del cliente; (3) Servir: entregar contexto enriquecido a los agentes de IA y sistemas de personalización en tiempo real; (4) Aprender: retroalimentar los resultados de cada decisión del agente a la base de datos para que el sistema mejore continuamente.
¿Qué infraestructura de datos se requiere para la toma de decisiones en tiempo real? La toma de decisiones en tiempo real requiere cuatro capacidades fundamentales: recopilación de eventos estructurados con validación de esquemas en el punto de captura; resolución de identidad en la capa de recopilación en lugar de adaptarla posteriormente; una canalización de datos capaz de servir contexto tanto en tiempo real como histórico simultáneamente; y la disciplina de tratar las salidas de las interacciones de los agentes de IA como eventos de comportamiento de primera clase que retroalimentan el sistema.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.