Un Open Lakehouse en Tiempo Real con Redpanda y Databricks
Las inversiones de Redpanda en la integración de principios fundamentales con Iceberg y Unity Catalog crean una arquitectura sostenible para ofrecer agilidad de flujo a tabla y potenciar un lakehouse abierto en tiempo real.
por Matt Schumpert y Jason Reid
- Convierte tus flujos de Kafka en tablas Iceberg completamente gobernadas y gestionadas por Unity Catalog en un solo paso, ofreciendo análisis de lakehouse en tiempo real sin conectores pesados ni trabajos de ETL personalizados.
- Ejecuta ingestas de Apache Iceberg™ de baja latencia (sub-10 ms) y alto rendimiento en el mismo clúster de Redpanda con Iceberg Topics que manejan el empaquetado de parquet, commits exactos y optimizaciones predictivas de Unity, reduciendo drásticamente los costos y el esfuerzo operativo.
- Despliega en cualquier lugar (SaaS, BYOC o autogestionado) y construye sobre estándares abiertos con las API de Kafka, Iceberg V2 y REST Catalog; las configuraciones declarativas simples te brindan partición personalizada, evolución de esquemas y DLQ integradas de fábrica.
Todo lakehouse debe ser 'alimentado por streaming'
El concepto de 'lakehouse abierto' iniciado por Databricks hace años se ha materializado de forma más amplia a través del reciente auge de Apache Iceberg™, impulsado por las inversiones de los principales proveedores en integración de frameworks, herramientas, soporte de catálogos e interoperabilidad de datos, comprometiéndose con Iceberg como sustrato común para un lakehouse abierto. Avances como la capacidad de exponer tablas de Delta Lake al creciente ecosistema de Iceberg a través de UniForm, el soporte de Unity Catalog para funciones avanzadas como la optimización predictiva y Iceberg REST con tablas administradas de Iceberg, y la reciente unificación de la capa de datos Delta/Iceberg en Iceberg V3 significan que las organizaciones ahora pueden adoptar una estrategia de datos 'orientada a Iceberg' con confianza, y sin comprometer el uso de los ricos conjuntos de características de productos maduros de lakehouse como Databricks.
Uno de los jugadores clave que faltaba en esta historia de acceso ubicuo a datos residentes en la nube a través de la lengua franca de Iceberg eran los streams, concretamente los temas de Kafka. Hoy en día, cualquier dato estructurado en reposo se puede cargar de forma nativa o 'decorar' como Iceberg. Por el contrario, los datos de alto valor en movimiento que fluyen a través de una plataforma de streaming que potencia aplicaciones en tiempo real todavía necesitan ser 'ETLed' al lakehouse de destino a través de un trabajo de integración de datos punto a punto, por stream, o ejecutando una costosa connector infraestructura en su propio clúster. Ambos enfoques utilizan un pesado consumidor de Kafka, ejerciendo presión sobre sus pipelines de entrega de datos en tiempo real, y crean un componente de infraestructura intermediario para escalar, administrar y observar con habilidades especializadas de Kafka. Ambos enfoques equivalen a insertar un peaje muy caro entre sus entornos de datos en tiempo real y analíticos, uno que realmente no necesita existir.
A medida que el uso de almacenes de objetos en la nube para respaldar streams ha madurado (Redpanda lideró esa carga hace varios años) y a medida que los formatos de tabla abiertos han cobrado protagonismo en los lakehouses, esta unión de stream a tabla es conveniente y está 'destinada a ser'. Databricks y Redpanda ofrecen dos plataformas de datos de clase mundial que hacen que este enfoque brille intensamente y llame la atención. Juntos, crean un sustrato de datos que abarca la toma de decisiones en tiempo real, el análisis y la IA que es difícil de superar. En la práctica, este enfoque fusiona streams con tablas con la facilidad de un indicador de configuración. Actúa como una presa multicámara, enrutando streams seleccionables a un lago de datos unificado bajo demanda, entregando insights actualizados y desbloqueando la misma inclusión arbitraria de datos dentro de nuevos pipelines de análisis que la arquitectura del lakehouse nos brindó para las tablas, y ahora a través de la apertura ampliada que proporciona el ecosistema Iceberg.
Fusionar sin problemas la infraestructura de datos en tiempo real y analítica para hacer de un 'lakehouse alimentado por streaming' un asunto de un solo clic no solo desbloquea un valor masivo, sino que también resuelve un problema de ingeniería difícil que exige un enfoque reflexivo para abordar adecuadamente en el caso general. Como esperamos ilustrar a continuación, no tomamos atajos para apresurar esta capacidad al mercado. Trabajando con docenas de socios de diseño (y Databricks) durante más de un año, extendimos la base de código única de Redpanda de una manera que preserva las opciones de implementación preferidas de nuestros clientes (incluyendo BYOC en múltiples nubes), mantiene la compatibilidad total con Kafka (sin dejar cargas de trabajo atrás) y evita la duplicación de artefactos y pasos para los usuarios siempre que sea posible. Esperamos que esta visión completa se refleje a medida que presentamos los principios rectores para construir Redpanda Iceberg Topics, que ahora están disponibles con Databricks Unity Catalog en AWS y GCP!
Ejecute su plataforma de stream-a-lakehouse en cualquier lugar
Nuestro primer principio fue mantener la elección y encontrar a los usuarios donde están. Redpanda ya tiene ofertas maduras multicloud SaaS, BYOC y autoadministradas, opciones de red soberana privada como BYOVPC, y en general nunca obliga a sus clientes a cambiar de nube, red, almacenes de objetos, IdP, o cualquier otra cosa que pudiera dificultar la adopción o impedir que los propietarios de plataformas posicionen su implementación de plataforma de streaming (incluyendo tanto planos de datos como de control), donde tenga más sentido para ellos. Independientemente de esa elección, los usuarios obtienen todas las características de la plataforma y una experiencia de usuario consistente tanto para desarrolladores como para administradores. Esta estrategia de producto de plataforma única es lo que nos permite anunciar que Iceberg Topics para Databricks están disponibles de forma general en las nubes AWS, GCP y Azure hoy, y que las organizaciones pueden implementar con la confianza de saber que si y cuando cambien de nube o de nuevos factores de forma, estarán implementando el mismo producto con el mismo motor subyacente, compatibilidad con Kafka, modelo de seguridad, características de rendimiento y herramientas de gestión. Esta amplitud de flexibilidad y consistencia contrasta marcadamente con otras opciones en el mercado.
Unity Catalog, conoce la plataforma de streaming más unificada
En segundo lugar, estábamos firmes en construir esto como un solo sistema, y uno que realmente se sienta así. Simplemente no se pueden fusionar dos conceptos bien uniendo dos arquitecturas de software completamente diferentes. Se pueden disimular algunas cosas con una capa de SaaS, pero las arquitecturas hinchadas se filtran en los modelos de precios, el rendimiento y el TCO como mínimo, y en los peores casos en la experiencia del usuario. Hemos hecho todo lo posible para evitar eso.
Para los desarrolladores, la sensación de un sistema único significa un ciclo de vida CRUD único y una experiencia de usuario (UX) coherente para los temas como tablas, y para las cosas que necesitan para funcionar (es decir, esquemas). Con Iceberg Topics, nunca copias entradas ni configuraciones, ni las creas dos veces usando una interfaz de usuario separada. Gestionas una entidad como la fuente de verdad tanto para los datos como para el esquema, utilizando siempre las mismas herramientas. Para nosotros, eso significa que gestionas (CRUD) a través de las herramientas que ya utilizas: cualquier herramienta del ecosistema Kafka, nuestra CLI rpk, las APIs REST de Cloud o cualquier herramienta de automatización de despliegue de Redpanda como nuestras CRs de K8s o el proveedor de Terraform. Para los esquemas, es nuestro Registro de Esquemas integrado con su API estándar ampliamente aceptado, que define el esquema de la tabla Iceberg implícitamente, o explícitamente, como prefieras. Todo está impulsado por la configuración y es amigable con DevOps. Y con las nuevas tablas Managed Iceberg de Unity Catalog, todos tus streams son descubribles a través de las herramientas de Databricks como tablas Iceberg y Delta Lake por defecto.
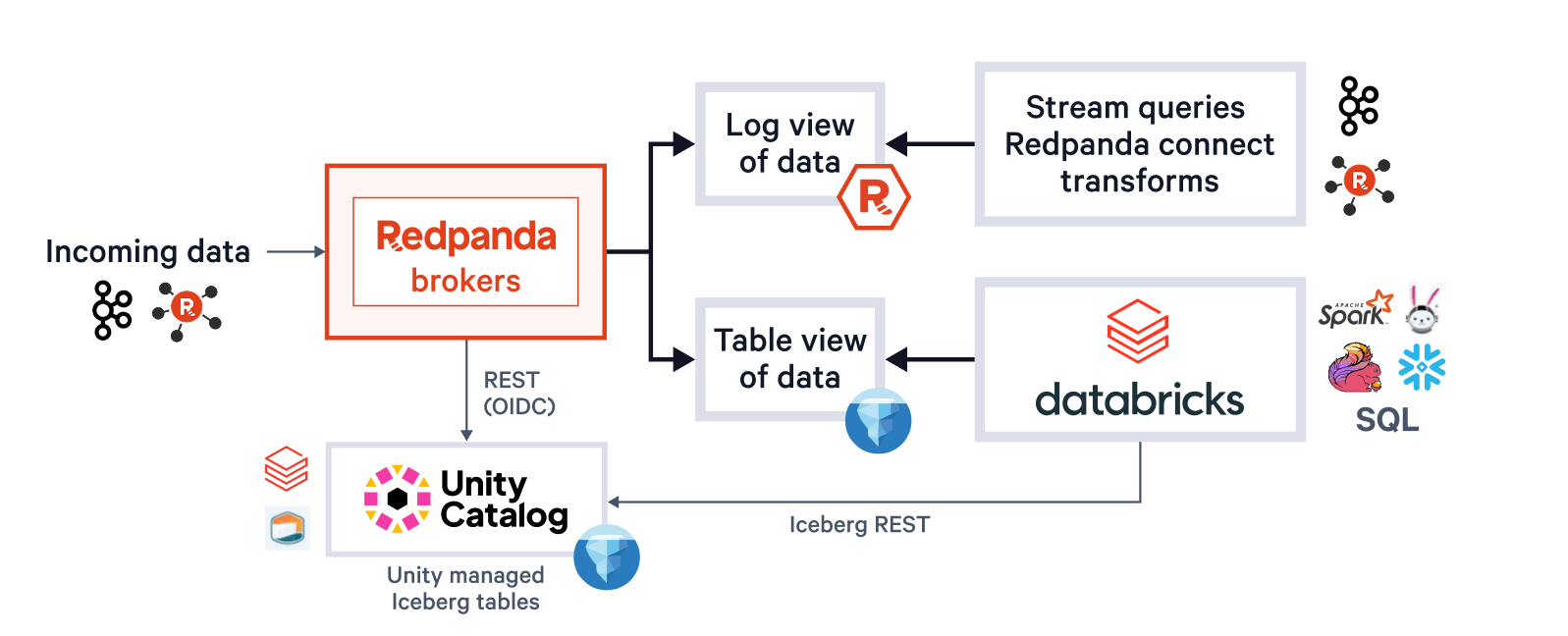
Un sistema único también concierne al operador de la plataforma, que no debería tener que preocuparse por gestionar múltiples buckets o catálogos, ajustar tamaños de archivos Parquet, temas que se retrasan respecto a los streams cuando los clústeres tienen recursos limitados, o fallos de nodos que comprometen la entrega exactamente una vez. Con Redpanda Iceberg Topics, todo esto se autogestiona. Los operadores se benefician de escrituras de parquet agrupadas dinámicamente y commits transaccionales de Iceberg que se ajustan a tus SLAs de llegada de datos, monitorización automática de retrasos que genera backpressure en el productor de Kafka cuando es necesario, y entrega exactamente una vez a través del etiquetado de snapshots de Iceberg (evitando huecos o duplicados después de fallos de infraestructura).
Redpanda gestiona todos tus datos en un único bucket/contenedor, utiliza un único catálogo de Iceberg en Unity Catalog (que Redpanda monitoriza para una recuperación elegante), y hace que las tablas sean fácilmente descubribles al mostrar el endpoint REST de Iceberg de Unity Catalog directamente en la UI de Redpanda Cloud. Y ahora, con Unity Catalog Managed Iceberg Tables, las operaciones de mantenimiento de tablas como la compactación, la expiración de datos y la optimización predictiva están integradas y se ejecutan automáticamente por Unity Catalog en segundo plano, mientras que Redpanda se encarga de las operaciones de mantenimiento mínimas apropiadas para su función (actualmente limpieza de snapshots de Iceberg y creación/eliminación de tablas). Los administradores de Databricks pueden entonces asegurar y gobernar estas tablas utilizando todos los privilegios normales de Unity Catalog. privilegios.
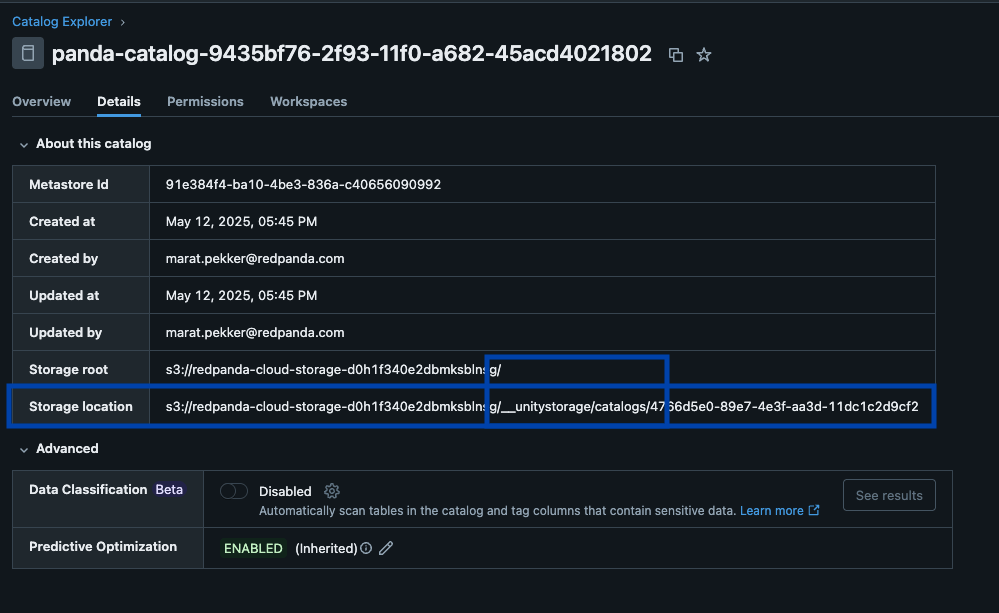
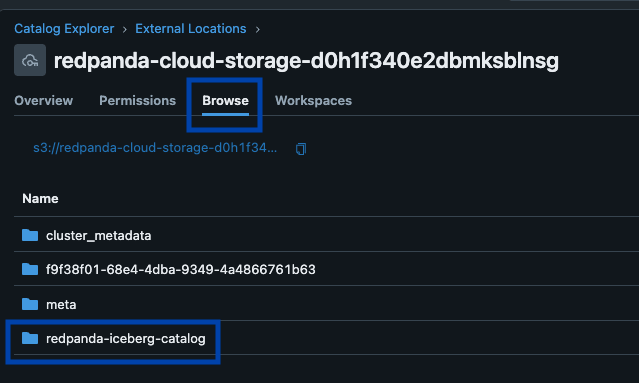
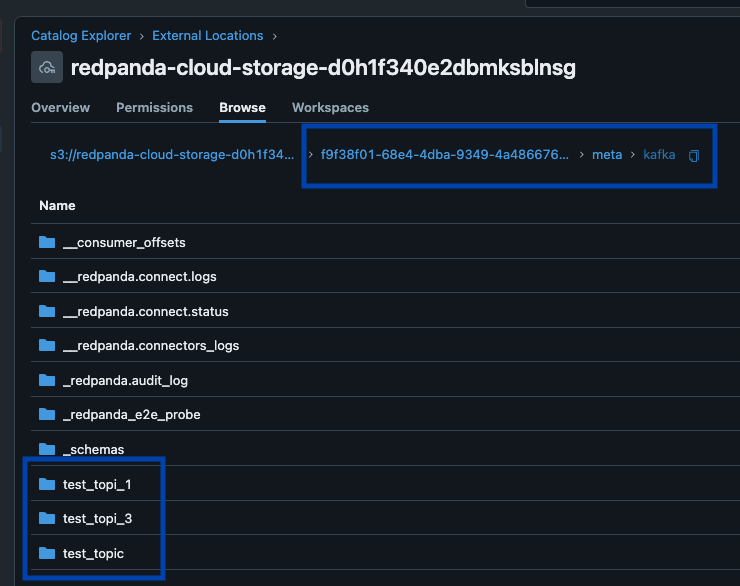
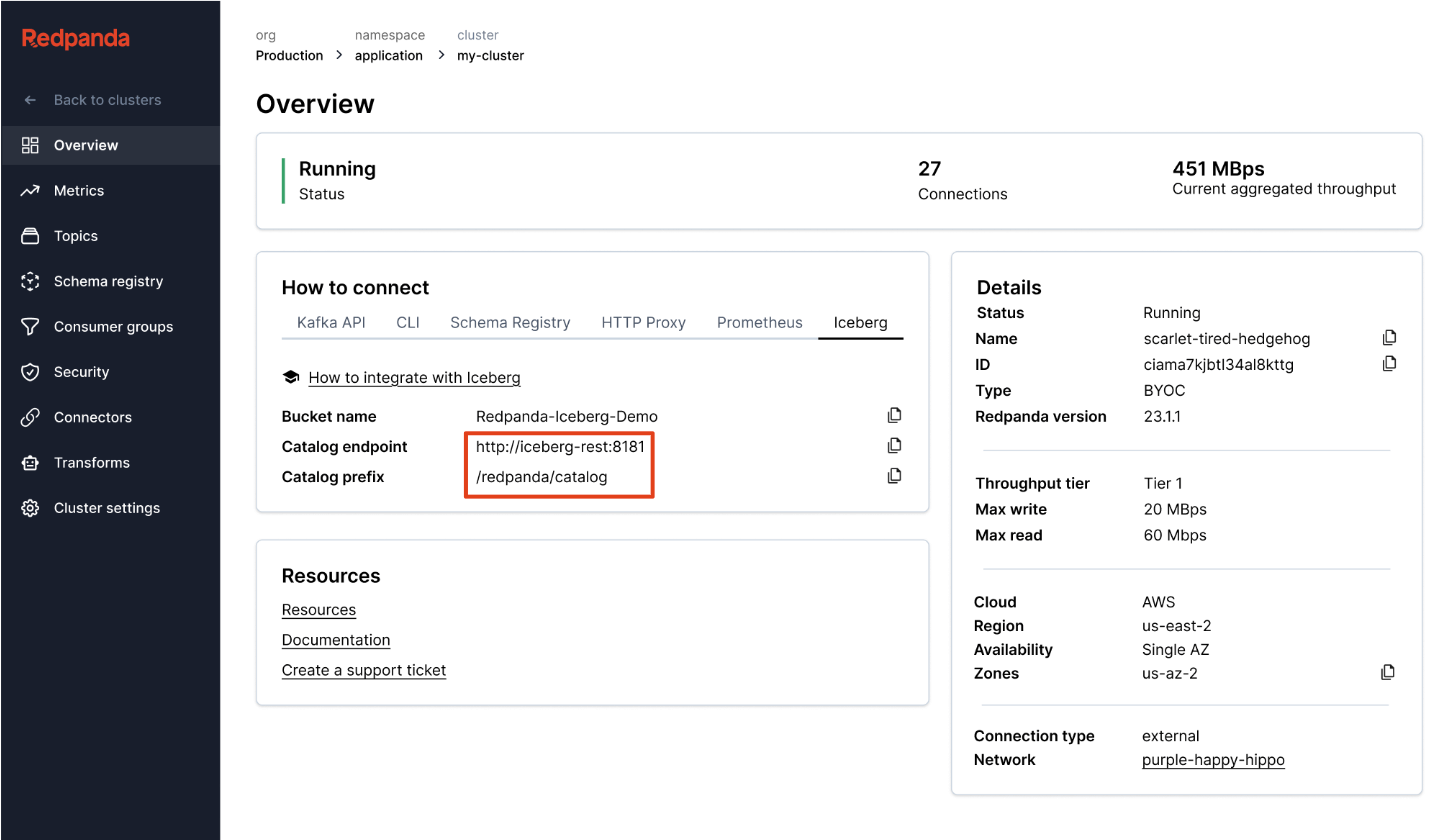
Un clúster para gobernarlos a todos
Lo más importante es que, gracias a nuestro motor de streaming multimodal R1 que utiliza una arquitectura de hilo por núcleo y agrupa funciones como el caché de escritura y el equilibrio de datos y cargas de trabajo multinivel, los administradores pueden ejecutar esta ingesta de Iceberg de alto rendimiento en el mismo clúster, y con los mismos temas que potencian las cargas de trabajo Kafka de baja latencia existentes con SLAs inferiores a 10 ms. Utilizando operaciones asíncronas y en pipeline ancladas a los mismos núcleos de CPU que manejan las solicitudes de Producción/Consumo, manejamos ambas cargas de trabajo con la máxima eficiencia en un solo proceso. Lo más importante es que Iceberg Topics puede aprovechar todo el conjunto de semánticas de Kafka, incluidas las transacciones de Kafka y los temas compactados, donde la capa de Iceberg solo recibe registros de transacciones confirmadas. Esta combinación de una arquitectura fundamentalmente eficiente que resuelve los problemas difíciles de semánticas sofisticadas rinde enormes dividendos al reducir tus costos operativos porque, bueno, un clúster para gobernarlos a todos. Sin productos adicionales. Sin clústeres separados. Sin supervisar pipelines. Despliega en cualquier lugar. Mantén la calma y sigue adelante, administradores de plataformas de streaming.
Hazlo simple
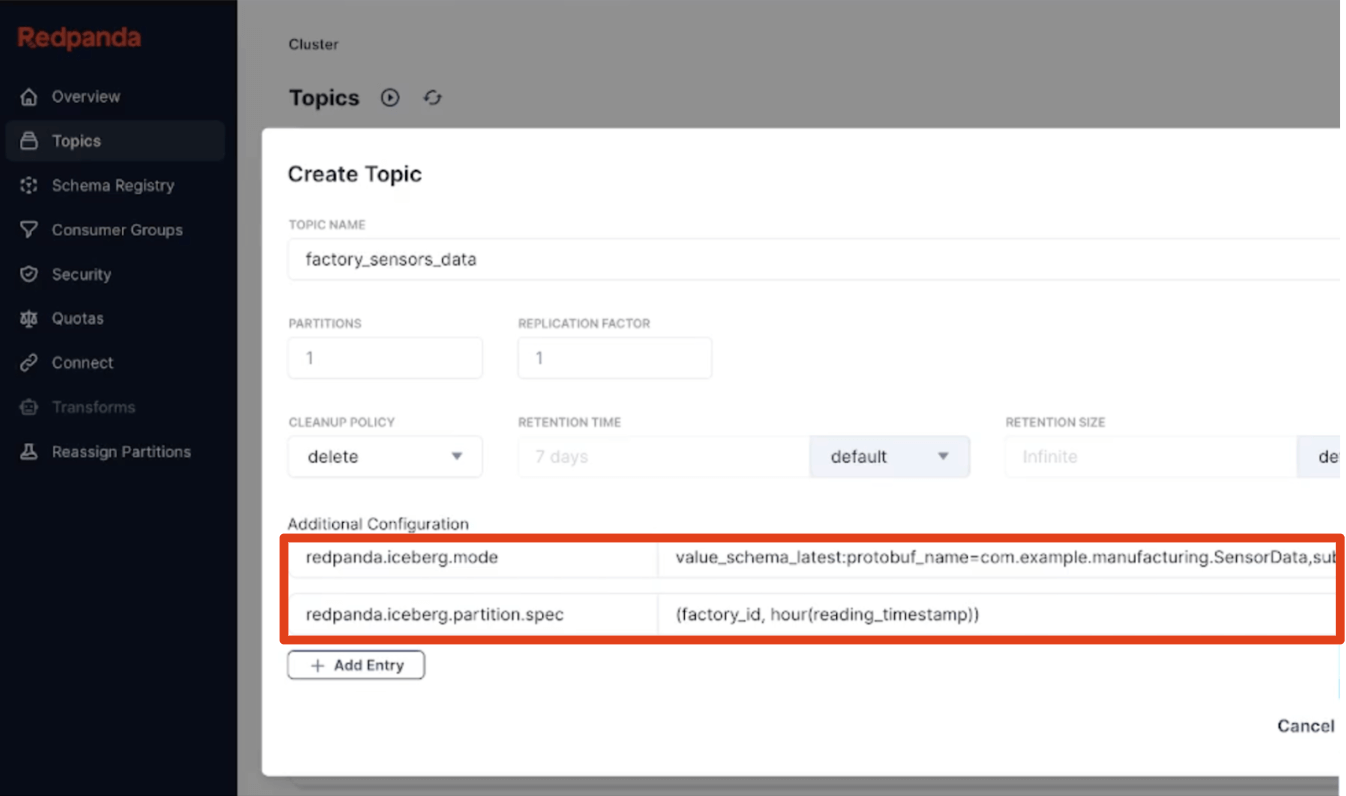
Nuestro tercer principio fue tomar decisiones predeterminadas sobre los comportamientos predeterminados, permitiendo a los usuarios aprender el sistema gradualmente con la configuración manos libres más inteligente posible que funciona para la mayoría de los casos de uso. Esto significa particionamiento de tablas por hora incorporado (completamente separado de los esquemas de partición de temas de Kafka), colas de mensajes fallidos siempre activas para capturar cualquier dato no válido, y convenciones simples y canónicas como 'última versión' o 'TopicNameStrategy' para la inferencia de esquemas facilitan la adopción. También incorporamos metadatos de Kafka como particiones de mensajes, offsets y claves como una estructura Iceberg, para que los desarrolladores tengan toda la procedencia para validar rápidamente la corrección de sus pipelines de streaming en Iceberg SQL.

Lo simple debe ser simple, por supuesto, pero lo sofisticado también debe ser sencillo. Así que definir particionamiento jerárquico personalizado con el conjunto completo de transformaciones de partición de Iceberg o extraer un tipo de mensaje Protobuf específico de un tema para que sea el esquema de su tabla Iceberg son, nuevamente, solo propiedades de tema declarativas de una sola línea. Los esquemas pueden evolucionar con gracia ya que Redpanda aplica evolución de tablas en el lugar. Y si lo necesita, ejecute una SMT simple en su idioma favorito que expanda mensajes complejos de un tema sin procesar a tablas de hechos Iceberg más simples utilizando Transformaciones de Datos integradas impulsadas por WebAssembly. El objetivo final es aterrizar datos listos para análisis en una sola pasada. ¡Boom, hola capa Bronce.
El telón de fondo de toda esta innovación es, por supuesto, el proyecto y las especificaciones de Apache Iceberg en rápida evolución, y el compromiso de Redpanda en general con los estándares abiertos. Ese compromiso comenzó con su soporte temprano para el protocolo Kafka, el registro de esquemas y las API de proxy HTTP, e incluso otros detalles como la configuración estándar de temas que permite a las organizaciones migrar sin problemas todo un conjunto de aplicaciones Kafka sin cambios. En el ámbito de Iceberg, Redpanda se ha destacado como un pionero comprometido en la comunidad, implementando un cliente C++ completo de Iceberg desde cero (algo no disponible de código abierto). Este cliente admite la especificación completa de tablas Iceberg V2, todas las reglas de evolución de esquemas y transformaciones de partición. En el lado del catálogo de Iceberg, Redpanda envía un catálogo basado en archivos y habla REST de Iceberg para operaciones como crear, confirmar, actualizar y eliminar en catálogos remotos como Unity Catalog, y admite la autenticación OIDC, manejando sus credenciales de Unity Catalog de manera juiciosa como un secreto que se cifra de forma transparente en el administrador de secretos de su proveedor de nube. Redpanda también ha trabajado en estrecha colaboración con Databricks y otros líderes de Iceberg para explorar cómo se puede extender la especificación para admitir datos de transmisión semiestructurados a través del tipo Variant, y para hacer que la gestión de RBAC de tablas sea más fluida sincronizando políticas entre las dos plataformas. Esta estandarización y la implementación constante según la especificación también significan una mínima dependencia del proveedor. Las organizaciones siempre son libres de reemplazar cualquier pieza del sistema si encuentran una mejor opción: la plataforma de transmisión, el catálogo de Iceberg o el lakehouse que consulta/procesa las tablas.
Si ha llegado hasta aquí, esperamos sinceramente que haya tenido una idea del riguroso enfoque de Redpanda para esta oportunidad de mercado candente, una que surge de una sólida cultura de ingeniería y pasión por construir productos sólidos. Como tecnólogos de corazón con sólidas trayectorias, y con nuestro enfoque en el factor de forma BYOC en particular, Redpanda y Databricks están perfectamente alineados para ofrecer dos plataformas de primer nivel que actúan y se sienten como una, y una que, para usted, resuelve bien el problema de la transmisión a la tabla.
Pruebe los temas de Iceberg con Unity Catalog utilizando la oferta única de Redpanda Bring-Your-Own-Cloud hoy mismo. O, comience con una prueba gratuita de nuestra versión autogestionada, Redpanda Enterprise!: https://cloud.redpanda.com/try-enterprise.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.