Datos estructurados vs. datos no estructurados
- Los datos estructurados se organizan en esquemas predefinidos: almacenados en tablas con formatos fijos, los datos estructurados permiten consultas SQL rápidas, admiten herramientas de inteligencia empresarial y sirven para análisis tradicionales como la generación de informes y el pronóstico, pero los cambios de esquema pueden ser un desafío.
- Los datos no estructurados representan entre el 80 % y el 90 % de los datos empresariales y requieren herramientas avanzadas para extraer información de los data lakes o las arquitecturas de lakehouse.
- Las empresas modernas necesitan enfoques híbridos que combinen ambos tipos de datos: las arquitecturas de lakehouse unifican la gestión de datos estructurados y no estructurados, ofreciendo la apertura de los data lakes con la confiabilidad de los data warehouses, a la vez que proporcionan una gobernanza unificada en todos los tipos de datos.
Los datos estructurados y no estructurados son activos clave para las organizaciones modernas, pero son fundamentalmente diferentes. Las organizaciones deben comprender estas diferencias y gestionar cada tipo de manera eficaz para aprovechar todo su valor. Esta guía examina las implicaciones prácticas, los casos de uso del mundo real y las consideraciones estratégicas para elegir el tipo de datos correcto. También abarca herramientas para los requisitos empresariales comunes y va más allá de las comparaciones genéricas para ofrecer marcos de toma de decisiones procesables.
Datos estructurados: características y aplicaciones
Rasgos principales de los datos estructurados
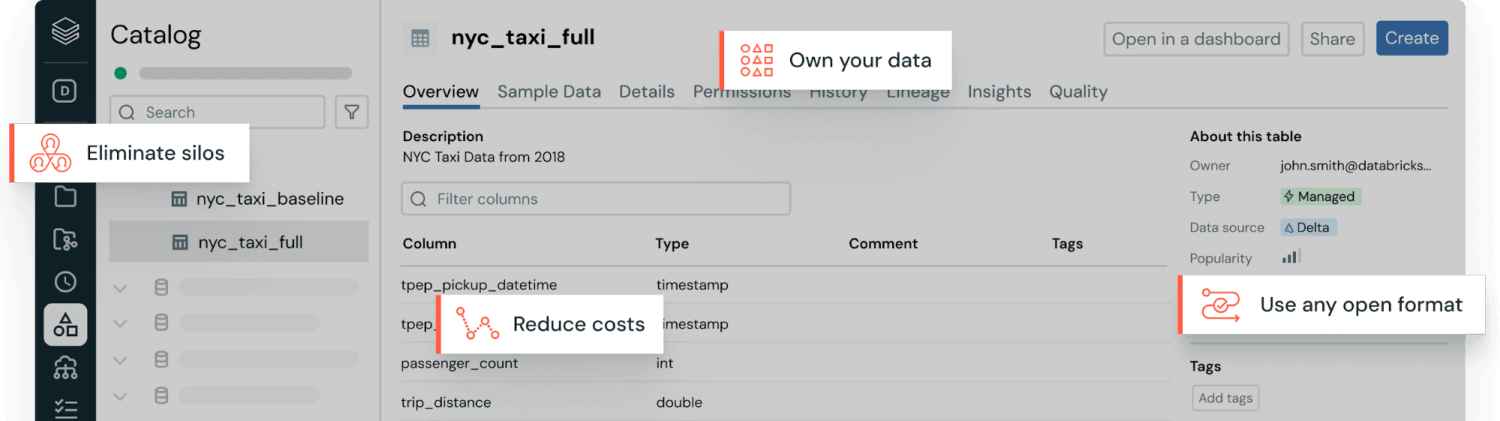
Los datos estructurados son información organizada dentro de un modelo de datos relacional predefinido, lo que significa que los datos se disponen en tablas con esquemas fijos. Este modelo especifica la estructura (filas y columnas), los tipos de datos y las relaciones entre tablas antes de que se almacene cualquier dato para permitir una búsqueda y un análisis eficientes. Algunos ejemplos comunes de datos estructurados son las transacciones financieras, los archivos de Excel, los registros de gestión de relaciones con los clientes (CRM), los niveles de inventario, los pedidos de ventas, los sistemas de reservas y las lecturas de sensores.
Por lo general, los datos estructurados se alojan en almacenes de datos. Estos están optimizados para consultas rápidas y confiables a través del Lenguaje de consulta estructurado (SQL), que se utiliza para cargas de trabajo de datos estructurados.
El formato estandarizado también hace que los datos estructurados sean muy accesibles. Los usuarios empresariales pueden explorarlos, analizarlos y generar informes sobre ellos fácilmente con herramientas conocidas de inteligencia empresarial (BI) y análisis para generar información sin necesidad de tener conocimientos técnicos avanzados.
Análisis y valor comercial de los datos estructurados
Los datos estructurados aportan un valor empresarial significativo porque su formato coherente y filtrable permite el análisis de datos con un preprocesamiento mínimo, lo que permite a las organizaciones realizar cálculos, crear modelos y comparar tendencias de forma eficiente. Los datos estructurados sirven como la columna vertebral de la analítica empresarial, ofreciendo consultas rápidas, alta integridad de datos y resultados fiables en los que las organizaciones pueden confiar para la planificación diaria y estratégica. Esto incluye la inteligencia empresarial (BI) tradicional, como los informes de rutina, las previsiones, el seguimiento de los KPI y los dashboards interactivos que ayudan a las organizaciones a supervisar el rendimiento y a tomar decisiones para optimizar las operaciones.
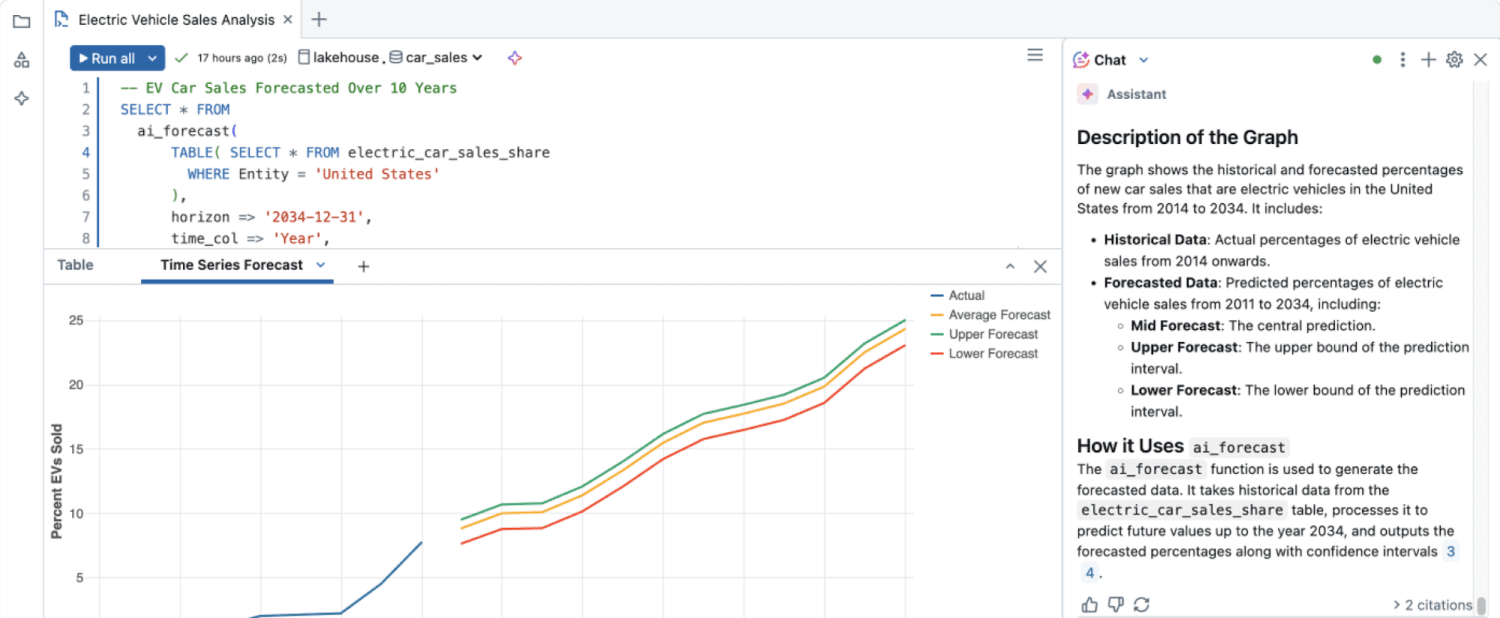
Los datos estructurados también son muy eficaces para los modelos de machine learning (ML) y los sistemas automatizados que generan información avanzada, como los resúmenes generados por la IA y la evaluación del sentimiento de los clientes.
Consideraciones sobre el almacenamiento y la escalabilidad de los datos estructurados
Una ventaja importante de los conjuntos de datos estructurados es la alta eficiencia de almacenamiento mediante la compresión columnar. Como los valores de una misma columna suelen ser similares, las bases de datos columnares permiten una compresión y lectura eficientes de los datos, lo que se traduce en un ahorro de almacenamiento significativo y análisis más rápidos.
Sin embargo, los cambios de esquema en los datos estructurados pueden ser un desafío. Dado que los ecosistemas de bases de datos están muy conectados y tienen muchas dependencias, los cambios como agregar, modificar o eliminar campos pueden provocar la pérdida de datos, el tiempo de inactividad de las aplicaciones y fallas en cascada en otras partes del sistema si no se gestionan adecuadamente. Las organizaciones deben planificar cuidadosamente las migraciones para evitar interrupciones.
Datos no estructurados: rasgos, desafíos y oportunidades
Características y fuentes de los datos no estructurados
Los datos no estructurados son información en su formato nativo. A diferencia de los datos estructurados que se organizan en filas y columnas, los datos no estructurados carecen de una estructura predefinida, lo que dificulta su búsqueda y análisis.
Los datos en su forma no estructurada pueden ser generados por máquinas —como los datos de GPS, los archivos de registro y otra información de telemetría— o generados por humanos. Algunos ejemplos de datos no estructurados generados por humanos son las publicaciones en redes sociales, los archivos de audio, los archivos de video, los correos electrónicos, los archivos multimedia y los documentos de texto.
Los datos no estructurados representan entre el 80 % y el 90 % del crecimiento de los datos empresariales. Este tipo de datos puede ofrecer información valiosa en áreas como las tendencias del mercado, el sentimiento del cliente y los problemas operativos, pero extraer esa información puede ser un desafío en comparación con el trabajo con datos estructurados.
Desafíos y soluciones del análisis de datos no estructurados
La información de los datos no estructurados en gran medida no se aprovechaba hasta la creación de análisis de datos avanzados, como los algoritmos de ML, el procesamiento del lenguaje natural (NLP) y el análisis de opiniones, que pueden extraer automáticamente el significado de grandes volúmenes de datos no estructurados.
Por lo general, las organizaciones necesitan científicos de datos para gestionar, procesar y extraer patrones significativos de los datos no estructurados mediante técnicas avanzadas. Los data lakes se utilizan comúnmente para consolidar datos no estructurados en su formato nativo y sin procesar, lo que proporciona un almacenamiento flexible para grandes volúmenes. Los data lakes permiten que los datos sin procesar se transformen en datos estructurados que están listos para el análisis de SQL, la ciencia de datos y el machine learning con baja latencia. Los data lakes también pueden retener datos sin procesar de forma indefinida a bajo costo para su uso futuro en ML y análisis.
Sin embargo, los data lakes pueden degenerar fácilmente en "pantanos de datos" con problemas de fiabilidad, rendimiento y gobernanza. Los data lakes tradicionales por sí solos no son suficientes para satisfacer las necesidades de las empresas que buscan innovar, razón por la cual las empresas suelen operar en arquitecturas complejas, con datos aislados en diferentes sistemas de almacenamiento en toda la empresa.
El almacenamiento de lakehouse unifica el manejo de datos estructurados y no estructurados para abordar los desafíos que plantean los data lakes. Los lakehouses implementan estructuras y funciones de gestión similares a las de un data warehouse directamente en el almacenamiento de datos de bajo costo de un data lake, combinando la apertura de los data lakes con las funciones de gestión y fiabilidad de los data warehouses. Esta estructura garantiza que las empresas puedan aprovechar varios tipos de datos para proyectos de ciencia de datos, ML y análisis de negocios.
Cómo obtener valor empresarial de los datos no estructurados
Los datos no estructurados contienen información valiosa que las técnicas analíticas tradicionales no pueden interpretar fácilmente. Las capacidades de machine learning permiten procesar el contenido no estructurado a escala, identificando patrones, temas, sentimientos y anomalías que de otro modo permanecerían ocultos. Mediante el uso de técnicas como el NLP y la visión por computadora, las organizaciones pueden transformar los datos cualitativos en información procesable que se utiliza para la toma de decisiones.
Por ejemplo, para mejorar el servicio al cliente, las organizaciones pueden usar la IA para analizar una variedad de fuentes, entre las que se incluyen reseñas de productos, transcripciones de centros de llamadas, menciones en redes sociales y conversaciones de chatbots. Los patrones identificados pueden usarse para revelar oportunidades para resolver problemas, aumentar la eficiencia e impulsar la innovación para mejorar la experiencia del cliente.
Diferencias clave entre los datos estructurados y los no estructurados, y el marco de decisión
Comprender las diferencias entre los datos estructurados y los no estructurados es esencial para diseñar arquitecturas de datos eficaces y elegir los métodos analíticos adecuados. Cada tipo presenta fortalezas y desafíos únicos que deben tenerse en cuenta en la estrategia de datos de una organización.
Dimensiones de comparación críticas
- Formato de datos: Los datos estructurados se organizan en un formato fijo y predefinido. Cada registro utiliza el mismo conjunto de campos y tipos de datos para que todo sea coherente. Los datos no estructurados se almacenan en su forma nativa sin procesar y sin una estructura uniforme, lo que los hace más flexibles pero más difíciles de organizar y analizar.
- Herramientas de análisis: los datos estructurados se pueden consultar fácilmente mediante SQL e integrarse en herramientas estándar de inteligencia empresarial. Los datos no estructurados requieren métodos de análisis más avanzados, como ML, NLP y visión por computadora. Estos suelen ser gestionados por científicos de datos o analistas especializados.
- Almacenamiento: los datos estructurados encajan de forma natural en los data warehouses, que están optimizados para las consultas relacionales y el rendimiento. Los datos no estructurados se adaptan mejor a los data lakes, que permiten a las organizaciones almacenar datos sin procesar a escala, o a las arquitecturas de lakehouse híbridas.
- Tiempo de procesamiento: Debido a que los datos estructurados ya están organizados, a menudo se pueden analizar de inmediato con una preparación mínima. Por lo general, los datos no estructurados necesitan un preprocesamiento significativo (como limpieza, tokenización, etiquetado y extracción de características) antes de que se pueda generar información valiosa.
- Accesibilidad para el usuario: los datos estructurados son accesibles para una amplia gama de usuarios, incluidos los analistas de negocios y los responsables de la toma de decisiones, que pueden explorarlos a través de dashboards y herramientas de generación de informes. Los datos no estructurados generalmente requieren la experiencia de científicos de datos o ingenieros para convertirlos en formatos utilizables y capturar información procesable.
Datos semiestructurados y enfoques modernos
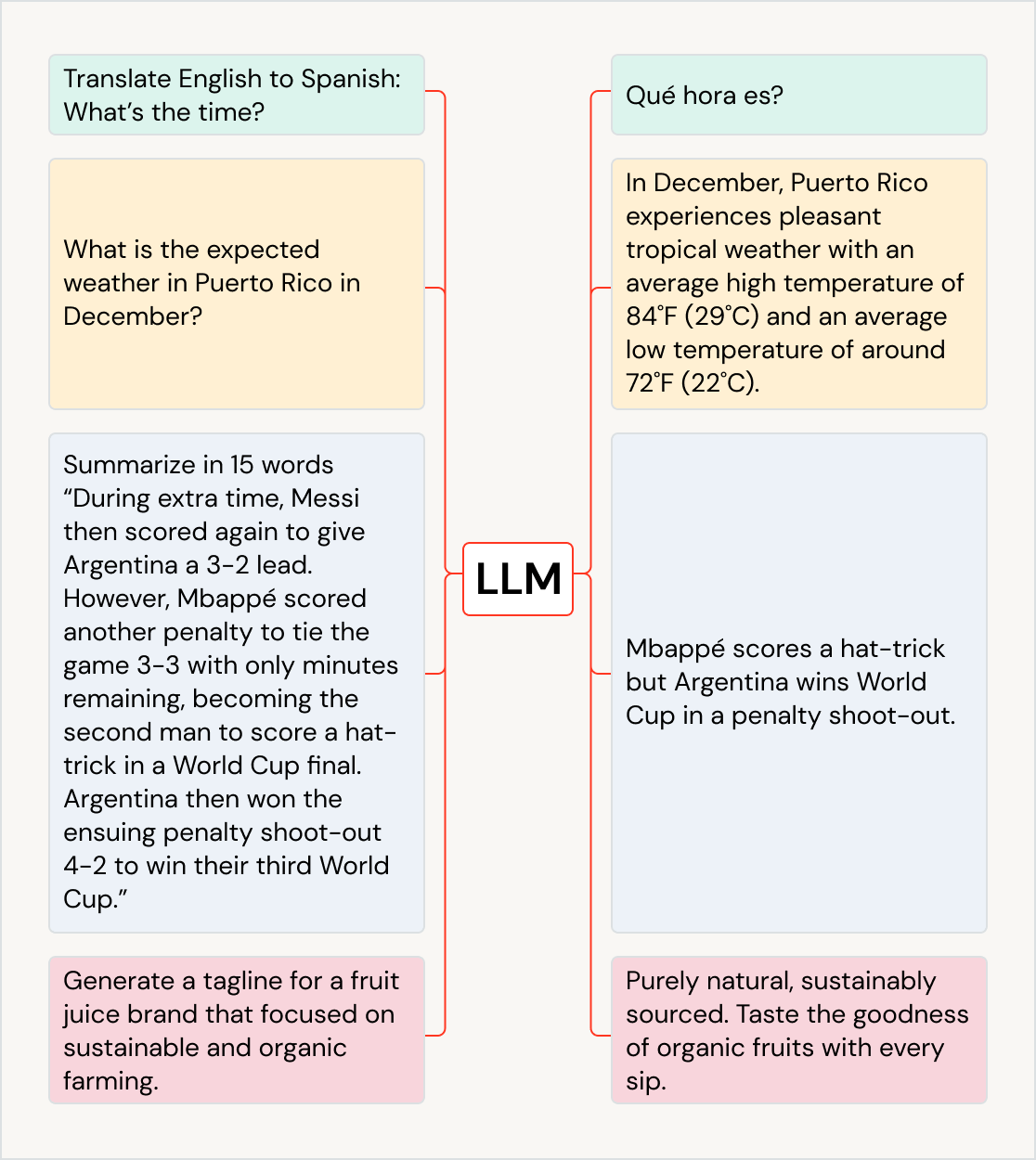
El punto medio híbrido
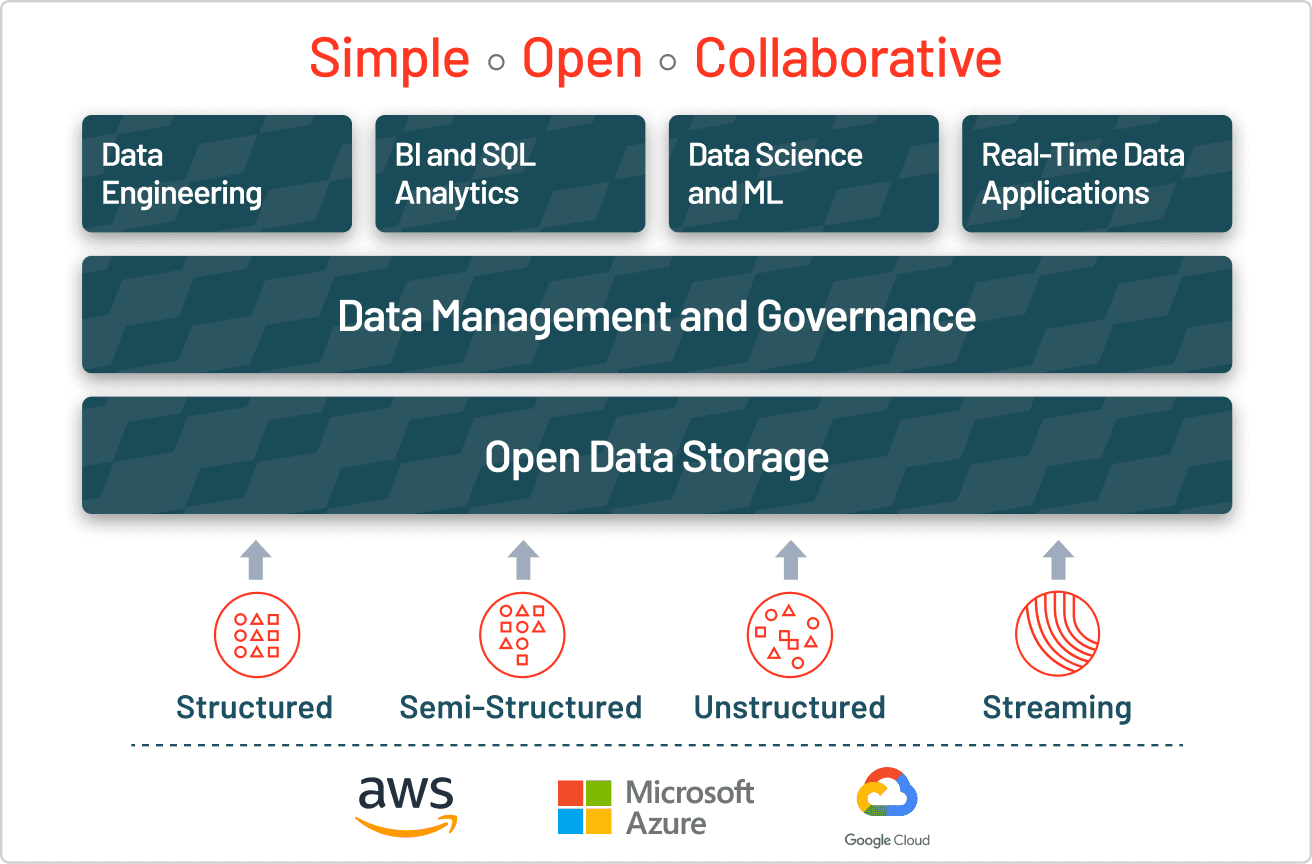
Los datos estructurados y no estructurados no son los únicos formatos que las organizaciones deben gestionar. Los datos semiestructurados cierran la brecha entre los dos, utilizando etiquetas de metadatos para añadir algo de organización, al tiempo que permiten campos flexibles y en evolución. Algunos ejemplos comunes son los archivos JSON, XML y CSV. Las organizaciones suelen utilizar bases de datos NoSQL y sistemas de archivos modernos para gestionar este tipo de datos, ya que admiten esquemas flexibles y se adaptan más fácilmente a los formatos de datos cambiantes.
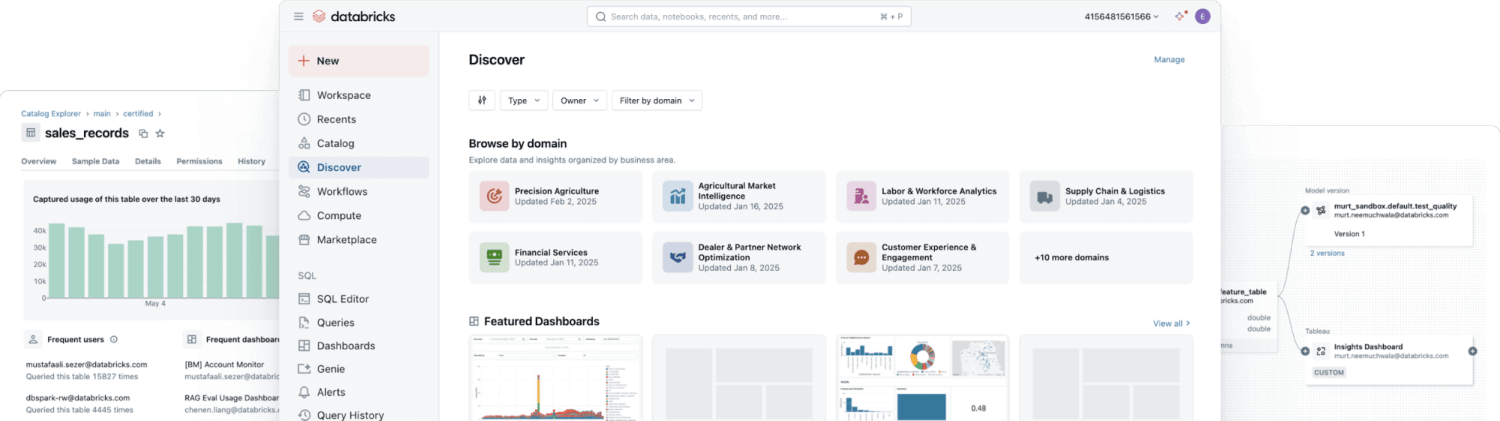
La mayoría de las empresas necesitan todo tipo de datos, por lo que están adoptando estrategias de almacenamiento híbridas que combinan las fortalezas de diferentes enfoques de datos. La arquitectura de lakehouse moderna elimina la necesidad de elegir entre data lakes y data warehouses al combinar sus capacidades en una única plataforma. El Unity Catalog de Databricks ofrece una gobernanza unificada y abierta para todos los datos estructurados, los datos no estructurados, las métricas de negocio y los modelos de IA en cualquier nube. Esto permite a las organizaciones gobernar, descubrir, supervisar y compartir datos, todo en un solo lugar, lo que agiliza el cumplimiento y permite obtener información más rápidamente.
Conclusión
La estrategia de datos no es una solución universal. Comprender en qué se diferencian los datos estructurados, no estructurados y semiestructurados es esencial para construir una gestión de datos eficaz. Las organizaciones necesitan la experiencia para hacer coincidir los tipos de datos con sus necesidades analíticas específicas y los requisitos del negocio. Al alinear las elecciones de datos con sus casos de uso únicos, las empresas pueden obtener información más profunda, mejorar la toma de decisiones y maximizar el impacto de sus inversiones en datos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.