Aprendizaje supervisado vs. no supervisado: Comprender las diferencias y capacidades de cada enfoque de ML
- El aprendizaje supervisado y no supervisado cumplen propósitos diferentes: el aprendizaje supervisado utiliza datos etiquetados para hacer predicciones y clasificaciones precisas, mientras que el aprendizaje no supervisado encuentra patrones ocultos en datos brutos sin etiquetar, lo que hace que cada uno sea más adecuado para diferentes objetivos comerciales.
- El ML moderno combina ambos enfoques: técnicas como el aprendizaje semi-supervisado y auto-supervisado combinan las fortalezas de cada paradigma.
- El verdadero desafío es construir sistemas: el ML empresarial exitoso depende de la orquestación de ambos enfoques dentro de canalizaciones de datos confiables, una gobernanza sólida y una evaluación continua a lo largo del ciclo de vida del modelo.
Los sistemas de aprendizaje automático aprenden de los datos para hacer predicciones, clasificar información o descubrir patrones que serían difíciles de identificar manualmente para los humanos.
¿Qué es el aprendizaje supervisado?
En el aprendizaje supervisado, los modelos se entrenan utilizando datos etiquetados, donde cada entrada se empareja con una salida conocida. El modelo aprende comparando sus predicciones con estas respuestas correctas y reduciendo iterativamente el error.
En el núcleo de este proceso se encuentran los modelos de aprendizaje automático que aprenden relaciones explícitas entre características y resultados. La presencia de datos etiquetados proporciona una guía clara, lo que hace que el aprendizaje supervisado sea adecuado para problemas donde la precisión, la trazabilidad y la repetibilidad son esenciales.
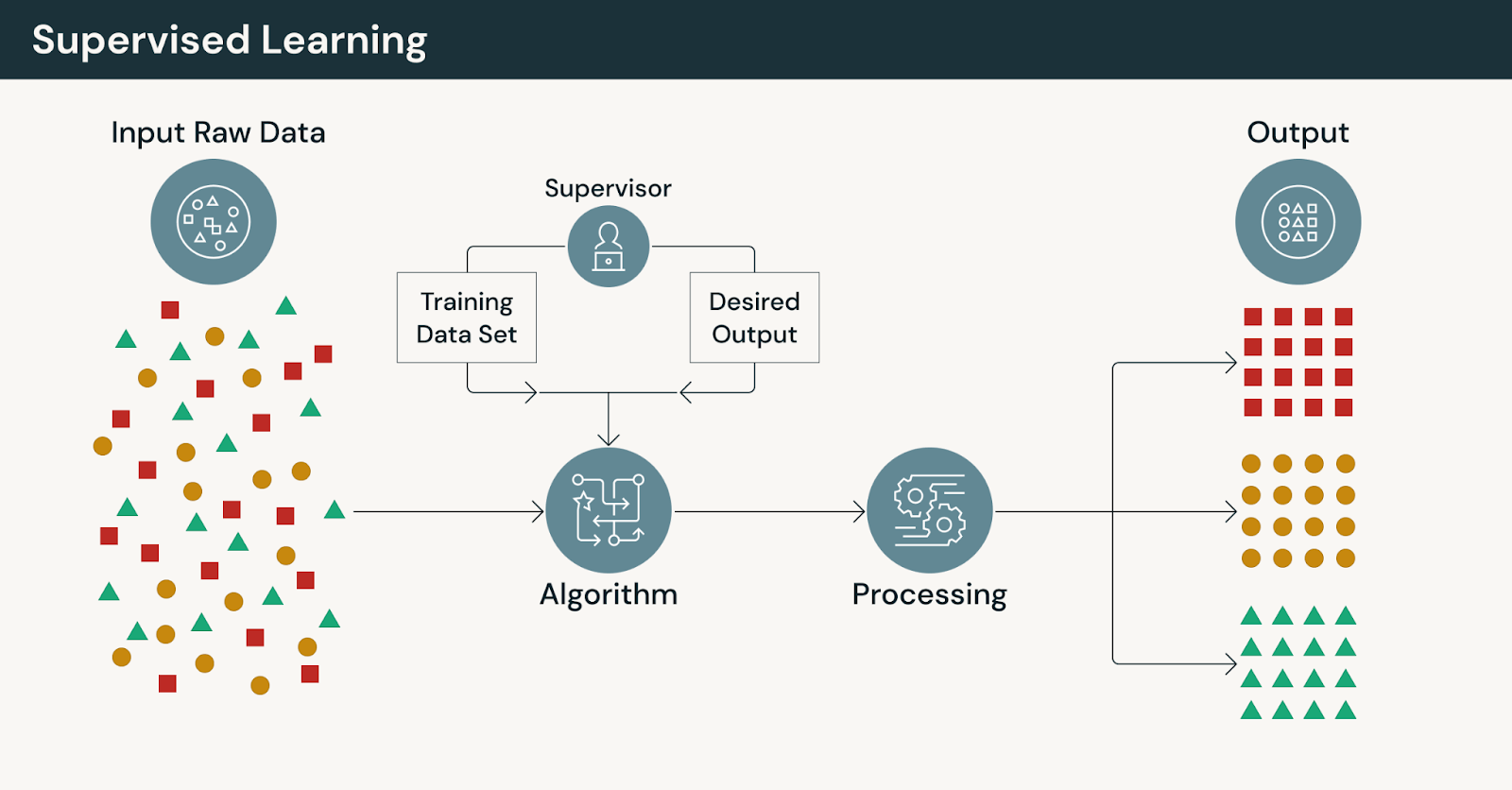
¿Cómo funciona el aprendizaje supervisado?
Un flujo de trabajo típico de aprendizaje supervisado incluye:
- Recopilar datos históricos de entrenamiento con resultados conocidos
- Preparar y validar conjuntos de datos de entrenamiento etiquetados
- Ingeniería de características que capturan señales relevantes
- Entrenar y evaluar modelos contra la verdad fundamental
- Desplegar modelos y rastrear el rendimiento a lo largo del tiempo
Este flujo de trabajo depende de la disponibilidad y calidad de las etiquetas, una limitación que a menudo se vuelve más pronunciada a medida que aumenta el volumen de datos.
Tipos de aprendizaje supervisado
Los problemas de aprendizaje supervisado generalmente se dividen en dos categorías:
- Clasificación: Asignar datos de entrada a clases predefinidas, como correo no deseado frente a correo electrónico legítimo o sentimiento positivo frente a negativo.
- Regresión: Predecir valores continuos, como pronósticos de demanda, precios o puntuaciones de riesgo. Las empresas de transporte utilizan modelos de regresión para predecir los tiempos de vuelo basándose en el rendimiento histórico de las rutas, los patrones estacionales y los factores operativos, lo que ayuda a optimizar la programación y a establecer expectativas precisas para los clientes.
En ambos casos, el rendimiento del modelo se puede medir directamente contra los resultados conocidos, lo que simplifica la evaluación y la rendición de cuentas.
Aplicaciones comunes de aprendizaje supervisado
El aprendizaje automático supervisado se utiliza comúnmente para:
- Filtrado de correo electrónico y moderación de contenido
- Análisis de sentimiento en comentarios de clientes
- Pronóstico y análisis predictivo
- Clasificación de imágenes y documentos
Muchas aplicaciones de procesamiento del lenguaje natural se basan en el ajuste fino supervisado para adaptar modelos de propósito general a tareas, políticas o vocabularios específicos del dominio.
Aprendizaje supervisado en diversas industrias
Las aplicaciones de aprendizaje supervisado abarcan prácticamente todos los sectores, y algunos casos de uso se han convertido en la base de la infraestructura digital moderna.
Ciberseguridad: Los sistemas de detección de spam analizan miles de millones de correos electrónicos al día, utilizando modelos supervisados entrenados con ejemplos etiquetados de mensajes legítimos y maliciosos. La detección moderna de spam va más allá de la simple coincidencia de palabras clave, incorporando la reputación del remitente, la estructura del mensaje, el análisis de archivos adjuntos y los patrones de comportamiento.
Salud y ciencias de la vida: El aprendizaje supervisado implica entrenar modelos predictivos con datos biomédicos y genómicos etiquetados para identificar patrones asociados con variantes relacionadas con enfermedades y objetivos terapéuticos. Al aplicar estos modelos dentro de una plataforma de análisis escalable, los investigadores pueden cuantificar las relaciones entre las características genéticas y los resultados clínicos, lo que permite una predicción más precisa de los objetivos de los fármacos y acelera el descubrimiento basado en hipótesis.
Servicios financieros: El aprendizaje supervisado se utilizó para entrenar modelos de detección de riesgos y fraudes con datos históricos de transacciones etiquetados, lo que permitió al sistema distinguir entre actividad legítima y sospechosa. Al aprender de resultados conocidos, como casos de fraude confirmados o comportamientos de clientes validados, los modelos mejoraron la precisión de la detección en tiempo real y redujeron los falsos positivos. Desplegados dentro de una plataforma de datos escalable, estos modelos supervisados respaldaron una toma de decisiones más rápida y una gestión de riesgos financieros más resiliente.
Retail y bienes de consumo: Utilizando datos históricos de ventas, precios y promociones etiquetados, se entrenaron modelos predictivos para pronosticar la demanda y optimizar las decisiones de inventario a escala. Al aprender de resultados conocidos, como patrones previos de movimiento de productos y demanda regional, el sistema mejoró la precisión de los pronósticos en miles de ubicaciones. Esto permitió una reposición más precisa, redujo las roturas de stock y una mayor alineación entre las operaciones de la cadena de suministro y la demanda del cliente.
Experiencias del cliente: Se entrenaron modelos predictivos con datos unificados y etiquetados de interacciones y perfiles de clientes para aprender patrones que ayudan a segmentar audiencias y predecir comportamientos de clientes. Estos modelos supervisados permitieron obtener información más precisa sobre los clientes, lo que respaldó estrategias de marketing dirigidas y personalización. Esto dio como resultado una entrega más rápida de información procesable que mejora la participación y la experiencia del cliente en todos los canales.
Medios y entretenimiento: Se utilizaron datos etiquetados de jugabilidad, participación y comportamiento para entrenar modelos predictivos que identifican patrones en la actividad de los jugadores y la interacción con el contenido. Al aprender de resultados conocidos, como señales de abandono, comportamientos dentro del juego y tendencias de la comunidad, el sistema permitió pronósticos más precisos y una optimización de contenido más rápida. Esto respaldó mejores experiencias para los jugadores, mejores decisiones operativas en vivo y desarrollo basado en datos en un ecosistema de juegos global.
Cada aplicación comparte un requisito común: datos de entrenamiento etiquetados confiables que representan con precisión el espacio del problema y un monitoreo continuo para detectar cuándo el rendimiento del modelo se degrada.
¿Qué es el aprendizaje no supervisado?
En lugar de aprender de ejemplos etiquetados, el aprendizaje automático no supervisado analiza datos no etiquetados para identificar patrones, estructuras o relaciones sin objetivos predefinidos.
Esto hace que el aprendizaje no supervisado sea especialmente valioso al principio de los proyectos de ML, cuando los equipos aún no saben qué preguntas hacer, o cuando etiquetar datos es poco práctico o prohibitivamente costoso.
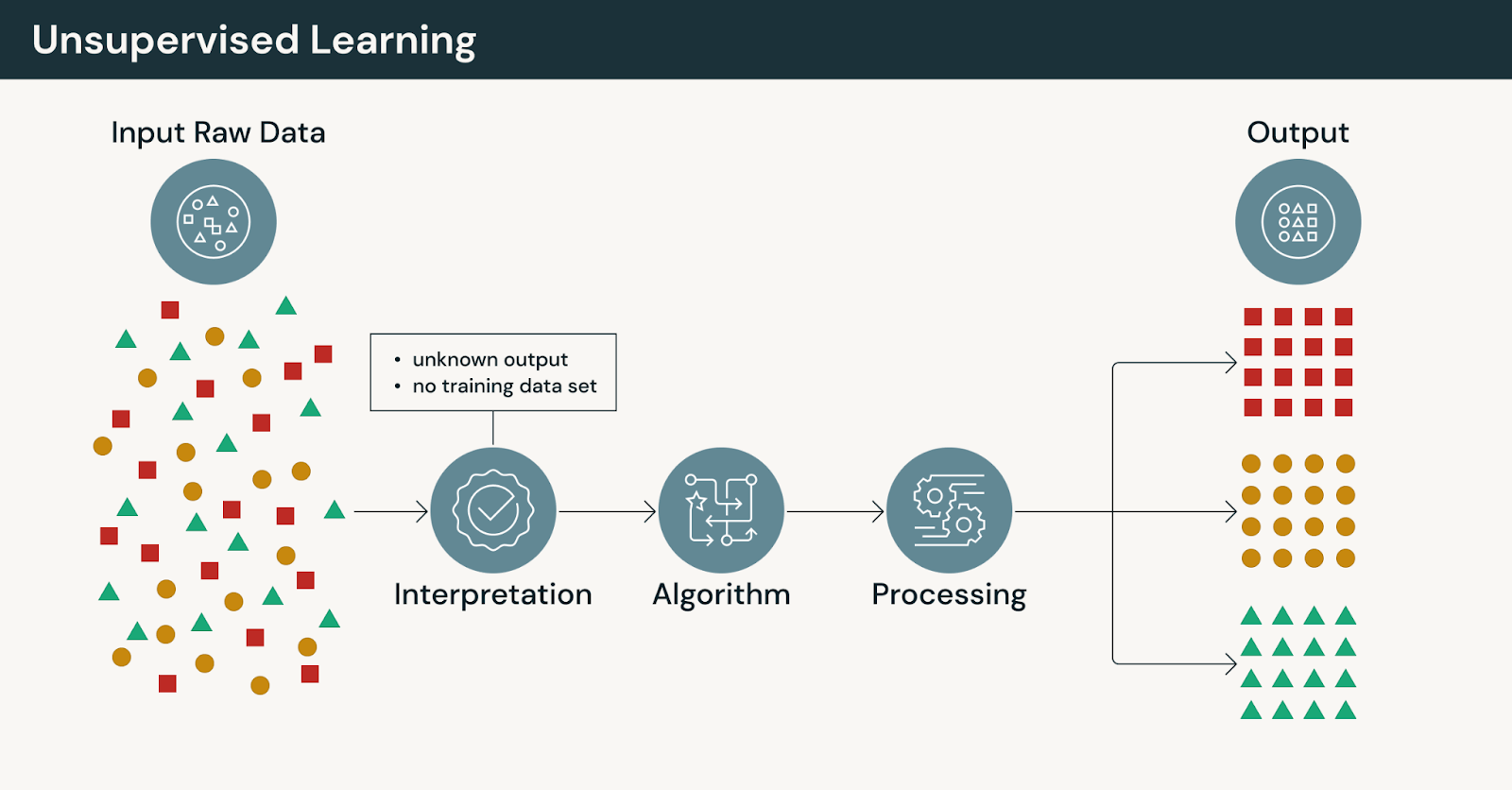
¿Cómo funciona el aprendizaje no supervisado?
En el aprendizaje no supervisado:
- Los modelos operan sin etiquetas explícitas proporcionadas por humanos
- Los algoritmos agrupan, comprimen u organizan datos según la similitud
- Las salidas requieren interpretación y validación por parte de expertos del dominio
Dado que no hay respuestas correctas, el aprendizaje no supervisado enfatiza la exploración en lugar de la predicción.
Tipos de aprendizaje no supervisado
Las técnicas comunes de aprendizaje no supervisado incluyen:
- Clustering: Agrupar puntos de datos similares para revelar la estructura
- Reducción de dimensionalidad: Simplificar conjuntos de datos complejos para el análisis
- Aprendizaje de reglas de asociación: Identificar relaciones entre variables
Muchos de estos métodos se basan en algoritmos de clustering para descubrir patrones que no se definieron explícitamente de antemano.
Aplicaciones comunes de aprendizaje no supervisado
El aprendizaje automático no supervisado se utiliza ampliamente para:
- Estrategias de segmentación de clientes en marketing y personalización, utilizando clustering para agrupar datos similares por comportamiento, preferencias y valor en lugar de categorías predeterminadas
- Sistemas de detección de anomalías para prevención de fraudes y monitoreo operativo
- Análisis exploratorio de datos y descubrimiento de patrones de comportamiento
- Búsqueda y agrupación de similitudes a gran escala
- Análisis de la cesta de la compra y sistemas de recomendación de productos, donde algoritmos como el algoritmo Apriori descubren patrones de compra y asociaciones de productos sin que se les indique qué artículos deben estar relacionados
A medida que las organizaciones acumulan más datos brutos, el aprendizaje no supervisado ofrece una forma de extraer valor sin esperar esfuerzos exhaustivos de etiquetado.
Diferencias clave entre aprendizaje supervisado y no supervisado
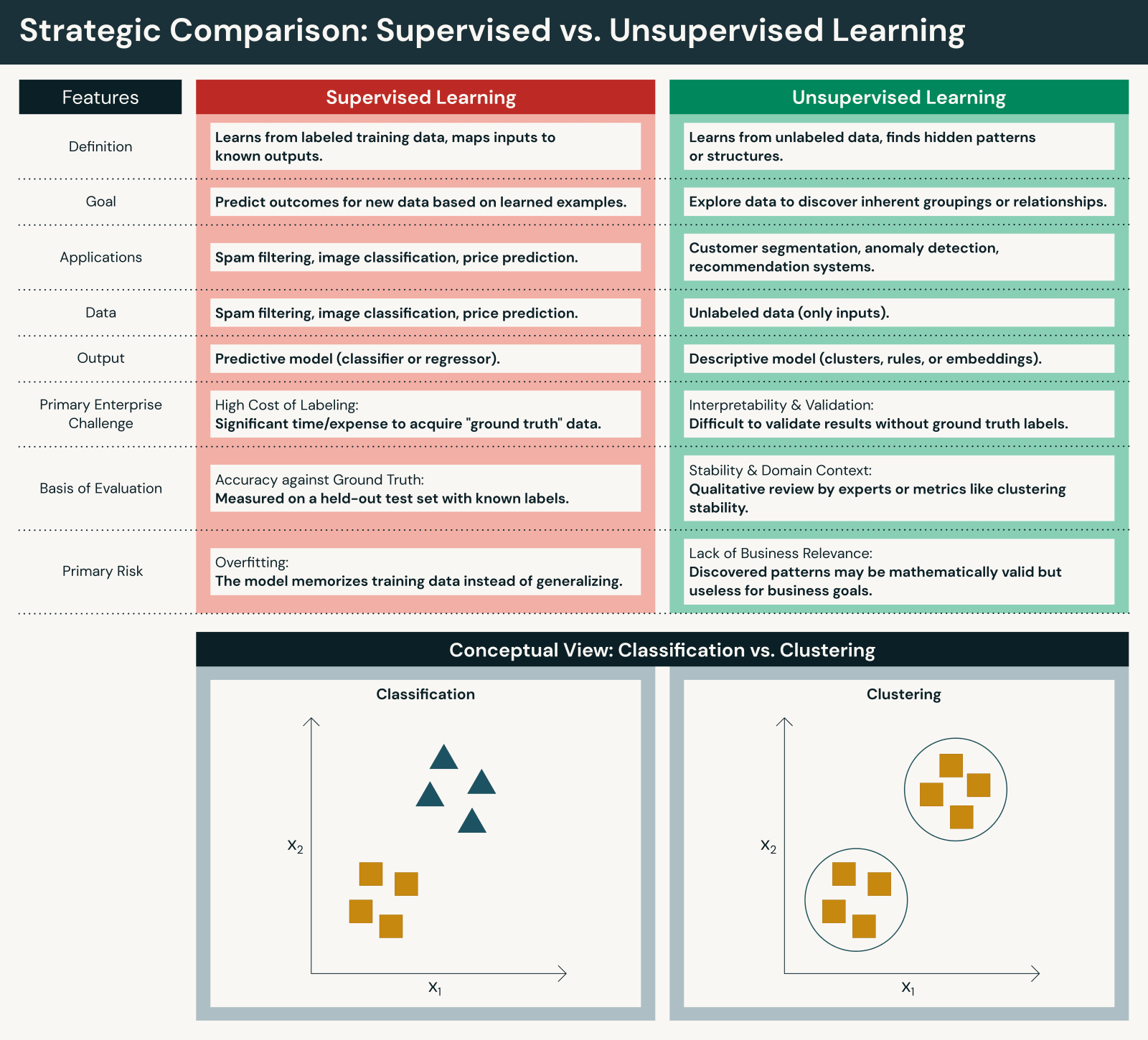
Aunque ambos enfoques son fundamentales, difieren en aspectos importantes:
Datos y esfuerzo humano
- El aprendizaje supervisado requiere conjuntos de datos etiquetados, a menudo creados mediante anotación manual o revisión de expertos. Si bien el aprendizaje automático supervisado requiere una intervención humana significativa para el etiquetado, esta intervención humana garantiza que la precisión se alinee con los objetivos comerciales.
- El aprendizaje no supervisado funciona directamente con datos brutos, lo que reduce la preparación inicial pero aumenta el esfuerzo de interpretación. El aprendizaje automático no supervisado reduce la intervención humana durante el entrenamiento, pero requiere intervención humana para interpretar los resultados.
Objetivos
- El aprendizaje supervisado se centra en la predicción y clasificación frente a resultados conocidos para predecir resultados con precisión.
- El aprendizaje no supervisado se centra en el descubrimiento y la generación de información para descubrir patrones en los datos.
Evaluación y transparencia
- Los modelos supervisados se pueden evaluar utilizando métricas de rendimiento claras frente a respuestas correctas (precisión, recall, F1, RMSE, etc.).
- Los modelos de aprendizaje no supervisado requieren evaluación indirecta y contexto de dominio para evaluar su utilidad (puntuaciones de silueta, método del codo, validación de expertos de dominio, etc.).
Escalabilidad
- El aprendizaje supervisado a menudo escala más lentamente debido a las restricciones de etiquetado.
- El aprendizaje no supervisado escala de forma natural con el volumen de datos, pero puede producir resultados más ruidosos.
En entornos empresariales, estas diferencias clave impulsan a los equipos hacia enfoques híbridos en lugar de opciones exclusivas.
La guía de IA agéntica para la empresa

Aprendizaje semisupervisado y autosupervisado
Los sistemas modernos de ML combinan cada vez más paradigmas:
El aprendizaje semisupervisado combina un pequeño conjunto de datos etiquetados con un grupo mucho más grande de datos no etiquetados, lo que reduce los costos de etiquetado y al mismo tiempo mantiene la precisión predictiva.
El aprendizaje autosupervisado va más allá al permitir que los modelos generen sus propias señales de entrenamiento a partir de datos brutos. Este enfoque sustenta muchos modelos fundacionales modernos y ha convertido el aprendizaje supervisado en un rol de refinamiento en lugar de un punto de partida.
Estas técnicas permiten a las organizaciones:
- Aprovechar los activos de datos existentes a escala
- Adaptarse más rápidamente a nuevas distribuciones de datos
- Reducir la dependencia del etiquetado manual
Vale la pena señalar que el aprendizaje supervisado y no supervisado no representan el panorama completo del machine learning. El aprendizaje por refuerzo es un tercer paradigma importante en el que los agentes aprenden comportamientos óptimos a través de interacciones de prueba y error con entornos, recibiendo recompensas o penalizaciones por sus acciones. Si bien el aprendizaje por refuerzo cae fuera del espectro supervisado vs. no supervisado, los sistemas modernos combinan cada vez más los tres enfoques según los requisitos de la tarea.
Cuándo usar aprendizaje supervisado vs. no supervisado
En la práctica, la elección correcta depende de los datos, los objetivos y las restricciones operativas.
Evalúa tus datos
- ¿Tienes etiquetas fiables hoy?
- ¿Puedes mantener la calidad del etiquetado a medida que crecen los datos?
- ¿Con qué frecuencia cambian tus datos?
Define tu objetivo
- ¿Predecir resultados? El aprendizaje supervisado es adecuado.
- ¿Explorar estructuras desconocidas? El aprendizaje no supervisado es a menudo el punto de entrada correcto.
Planifica todo el ciclo de vida
Independientemente del enfoque, los sistemas exitosos dependen de pipelines de ingeniería de datos fiables que muevan los datos desde la ingesta hasta el entrenamiento y la producción de manera consistente.
Muchos equipos comienzan con la exploración no supervisada y luego introducen el aprendizaje supervisado una vez que los objetivos y las métricas están bien definidos.
Por qué la gobernanza unificada de datos e IA es fundamental para una estrategia empresarial de ML
A medida que los sistemas de ML escalan, las empresas deben gestionar el acceso, el linaje, el cumplimiento y la rendición de cuentas.
Aquí es donde la gobernanza de datos unificada se vuelve fundamental. Gobernar los datos y los modelos de manera consistente en todos los flujos de trabajo garantiza que la información sea confiable y que los sistemas sigan siendo auditables a medida que evolucionan.
Abordando preguntas comunes
¿Es la regresión lineal supervisada o no supervisada?
La regresión lineal es un aprendizaje supervisado porque requiere valores de salida etiquetados.
¿Cuál es la principal diferencia entre el aprendizaje supervisado y no supervisado?
El aprendizaje supervisado predice resultados conocidos utilizando datos etiquetados. El aprendizaje no supervisado descubre patrones en datos no etiquetados.
Lo que necesitas saber de cara al futuro
Varias tendencias están remodelando el ML empresarial:
- El aprendizaje autosupervisado domina el entrenamiento de modelos fundacionales.
- El aprendizaje supervisado sirve cada vez más como una capa de precisión.
- La agrupación y las incrustaciones se están convirtiendo en capacidades empresariales centrales.
- La evaluación y la gobernanza están cobrando importancia a medida que se expande el uso de datos no etiquetados.
Estos cambios refuerzan la necesidad de pensar en sistemas, no en silos.
Desafíos y limitaciones
Tanto el aprendizaje supervisado como el no supervisado desempeñan funciones esenciales en el ML empresarial, pero cada uno tiene compensaciones que los equipos deben planificar con anticipación.
Desafíos del aprendizaje supervisado
Los requisitos de datos son a menudo la mayor limitación. Crear conjuntos de datos etiquetados puede ser lento y costoso, especialmente cuando el etiquetado requiere experiencia en el dominio. En muchos casos, la precisión del modelo está directamente ligada a la calidad de las etiquetas, lo que convierte las anotaciones inconsistentes o sesgadas en un riesgo grave.
Los modelos supervisados también se enfrentan a riesgos de sobreajuste. Cuando los modelos aprenden los datos de entrenamiento demasiado de cerca, pueden funcionar bien en la evaluación pero fallar en generalizar a datos nuevos o no vistos. Las mitigaciones comunes incluyen la validación cruzada, las técnicas de regularización y la expansión de los conjuntos de datos de entrenamiento para reflejar mejor la variabilidad del mundo real.
Las preocupaciones sobre la escalabilidad surgen a medida que crecen los volúmenes de datos. El etiquetado con intervención humana no escala linealmente, y los procesos manuales pueden convertirse en cuellos de botella para proyectos grandes o de rápido movimiento. Sin una planificación cuidadosa, los flujos de trabajo supervisados pueden tener dificultades para seguir el ritmo de las demandas empresariales.
Desafíos del aprendizaje no supervisado
El aprendizaje no supervisado introduce un conjunto diferente de problemas, comenzando por la dificultad de interpretación. Los clústeres o patrones pueden no tener un significado obvio sin contexto de dominio, y la estructura descubierta no siempre se alinea con los objetivos comerciales. Extraer valor a menudo requiere una estrecha colaboración entre científicos de datos y expertos en la materia.
La complejidad de la validación es otro desafío. Sin etiquetas de verdad fundamental, puede ser difícil evaluar objetivamente la calidad del modelo. Los equipos a menudo recurren a métricas proxy, alineación comercial o evaluación comparativa entre múltiples algoritmos para generar confianza en los resultados.
Finalmente, la selección del algoritmo requiere experimentación. Los resultados pueden variar significativamente según las opciones de parámetros, las medidas de distancia o los pasos de preprocesamiento, lo que hace que la iteración sea inevitable.
Mejores prácticas de machine learning
En ambos enfoques, varias prácticas mejoran consistentemente los resultados:
- Asegurar datos de entrada de alta calidad, incluido el manejo adecuado de valores faltantes y valores atípicos
- Comenzar con una definición clara del problema antes de seleccionar un enfoque
- Implementar controles de calidad de datos y procesos de validación desde el principio
- Utilizar métricas de evaluación apropiadas para cada paradigma
- Comenzar con análisis exploratorios de datos antes de comprometerse con flujos de trabajo de producción
Las soluciones de ingeniería de datos fiables proporcionan la base para aplicar estas prácticas de manera consistente, ayudando a los equipos a pasar de la experimentación a la producción con mayor confianza.
Lo que necesitas saber en 2026
Varios cambios ya están remodelando la práctica empresarial de ML.
1. El preentrenamiento autosupervisado ahora sustenta la mayoría de los modelos fundacionales modernos
La mayoría de los modelos de vanguardia, incluidos los modelos de lenguaje grandes, los sistemas de visión por computadora y las arquitecturas multimodales, ahora se entrenan principalmente utilizando aprendizaje autosupervisado. En lugar de depender de conjuntos de datos etiquetados por humanos, estos modelos generan sus propias señales de entrenamiento a partir de datos brutos, como predecir el siguiente token en una secuencia o reconstruir porciones enmascaradas de una entrada.
Este cambio refleja una realidad práctica: las empresas poseen grandes cantidades de datos no etiquetados, pero el etiquetado a escala es costoso y lento. El aprendizaje autosupervisado permite a las organizaciones extraer valor de los activos de datos existentes mientras construyen representaciones que luego se pueden adaptar a tareas específicas.
2. El ajuste fino supervisado se ha trasladado a un rol de refinamiento
El aprendizaje supervisado no ha desaparecido, pero su rol ha cambiado. En lugar de servir como el mecanismo de entrenamiento principal, el ajuste fino supervisado se utiliza cada vez más para refinar, alinear y validar modelos para objetivos comerciales bien definidos.
Este enfoque permite a los equipos centrar los esfuerzos de etiquetado donde la precisión es más importante, como los requisitos reglamentarios, las restricciones de seguridad o la precisión específica del dominio, al tiempo que evitan el etiquetado innecesario en etapas anteriores del pipeline.
3. Las incrustaciones son ahora capacidades empresariales centrales
Las incrustaciones se han convertido en infraestructura empresarial central. Los modelos fundacionales generan cada vez más incrustaciones vectoriales que capturan el significado semántico en texto, imágenes, audio y datos estructurados. Estas incrustaciones potencian la búsqueda de similitud, la recuperación, la personalización, la detección de anomalías y los sistemas de recomendaci�ón a escala.
La agrupación y otros métodos basados en similitudes son importantes, pero son aplicaciones posteriores de las incrustaciones en lugar de paradigmas similares. El cambio estratégico no es hacia la agrupación en sí, sino hacia arquitecturas centradas en incrustaciones que permiten la búsqueda, recuperación y razonamiento unificados en los datos empresariales.
A medida que las organizaciones operacionalizan la IA, las incrustaciones se convierten en el tejido conectivo entre el preentrenamiento autosupervisado, el ajuste fino supervisado y las aplicaciones posteriores. Proporcionan una capa representacional común que admite flujos de trabajo tanto de exploración como de precisión dentro de plataformas de datos modernas y unificadas.
Construye sistemas, no lados
El aprendizaje supervisado y no supervisado resuelven problemas diferentes, y los sistemas modernos de ML necesitan ambos. El aprendizaje automático supervisado destaca cuando tienes datos etiquetados y necesitas predicciones o clasificaciones precisas y fiables. El aprendizaje automático no supervisado prospera cuando el objetivo es el descubrimiento, ayudando a los equipos a descubrir patrones y conocimientos en datos brutos sin resultados predefinidos. Cuando los datos etiquetados son limitados, los enfoques de aprendizaje semi supervisado cierran la brecha combinando ambos paradigmas.
El verdadero desafío no es elegir entre aprendizaje supervisado vs no supervisado, sino construir sistemas que puedan combinar enfoques, evolucionar con el tiempo y operar de manera fiable en producción. Los equipos eficaces comienzan evaluando la disponibilidad de sus datos, aclarando si su objetivo principal es la predicción o la exploración, y evaluando los recursos necesarios para cada enfoque.
Las estrategias de aprendizaje automático rara vez son estáticas. La exploración no supervisada a menudo informa el desarrollo posterior de modelos supervisados, mientras que el ajuste fino supervisado aporta precisión y validación a los sistemas construidos sobre representaciones más amplias. Con el tiempo, los conocimientos deben fluir hacia la inteligencia empresarial y análisis donde puedan informar decisiones e impulsar resultados.
Para profundizar, explora estos recursos:
- Una guía compacta para el ajuste fino y preentrenamiento de LLMs — Aprende técnicas para ajustar y preentrenar tu LLM
Obtén la guía - El gran libro de la IA generativa — Mejores prácticas para construir aplicaciones GenAI de calidad de producción
Descargar - El gran libro de casos de uso de aprendizaje automático — Obtén todo lo que necesitas para poner el aprendizaje automático a trabajar
Leer ahora
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.