Del conocimiento tribal a las respuestas instantáneas: creando Reffy en Databricks
- Por qué encontrar la referencia de cliente adecuada en el momento adecuado fue un desafío persistente en las ventas y el marketing de Databricks.
- Cómo creamos Reffy, una aplicación agéntica de pila completa que usa RAG, AI Search, AI Functions y Lakebase, para que más de 2400 historias de clientes se puedan buscar al instante.
- Desde su lanzamiento en diciembre de 2025, más de 1800 empleados de Databricks han ejecutado más de 7500 consultas en Reffy.
Encontrar la historia de cliente adecuada en el momento oportuno es sorprendentemente más difícil de lo que debería ser. Para mejorar la productividad de los empleados, creamos Reffy, una aplicación que permite a los usuarios descubrir y analizar más de 2400 referencias de clientes de Databricks, ofreciendo respuestas personalizadas, análisis cruzados de historias, citas y mucho más. En sus primeros dos meses, más de 1800 personas de ventas y marketing de Databricks han ejecutado más de 7500 consultas en Reffy. Eso se traduce en una narrativa más relevante y coherente, una ejecución de campañas más rápida y la confianza de que las pruebas de los clientes se utilizan a gran escala. Al hacer que estas historias fueran fáciles de encontrar y asimilar, resolvimos el problema del conocimiento tribal en torno a las referencias de clientes y liberamos el valioso trabajo de tantas personas que las han recopilado a lo largo de los años.
En este artículo, analizaremos la motivación detrás de Reffy, la solución completa de Databricks, su impacto en nuestra organización y cómo planeamos escalarla aún más internamente.
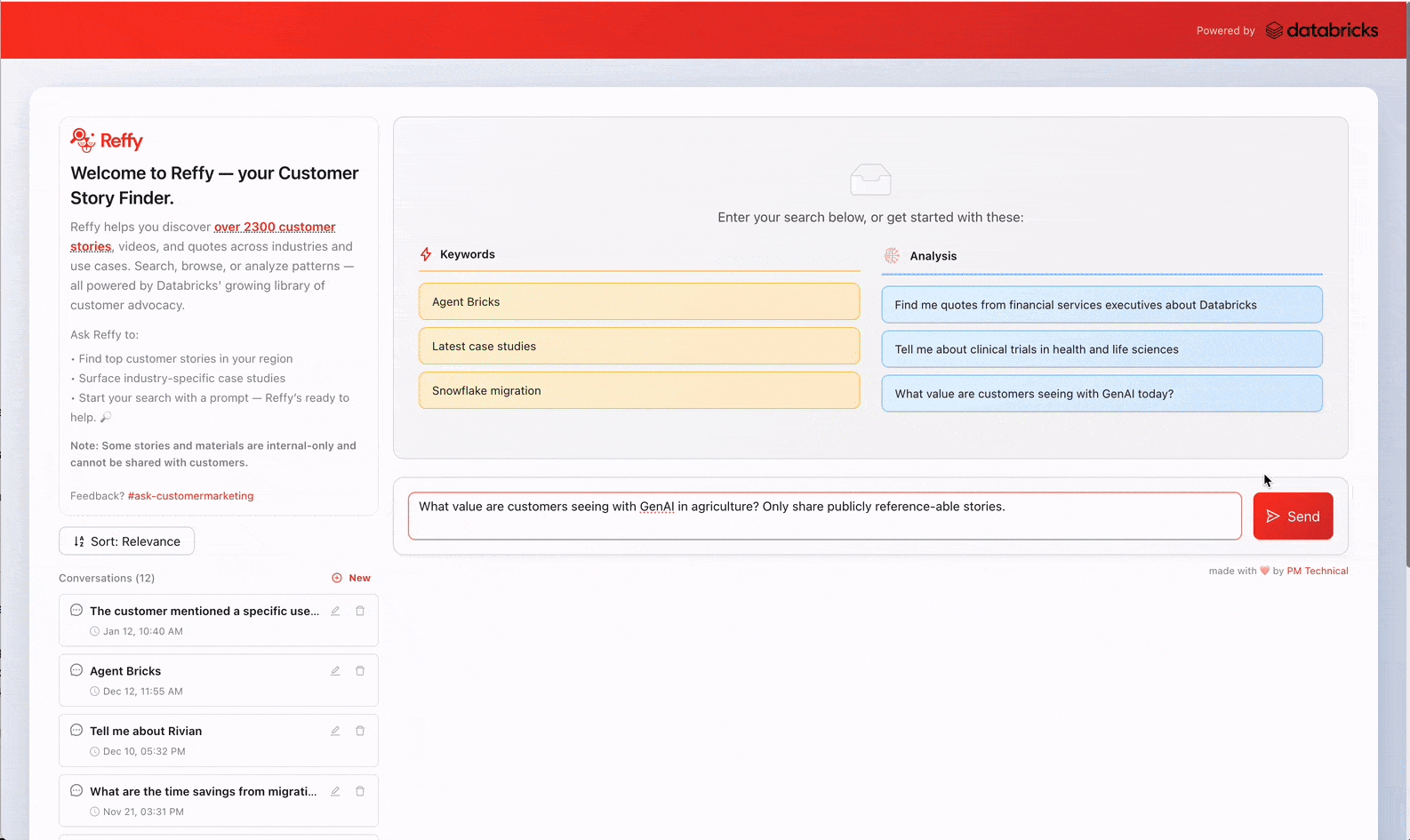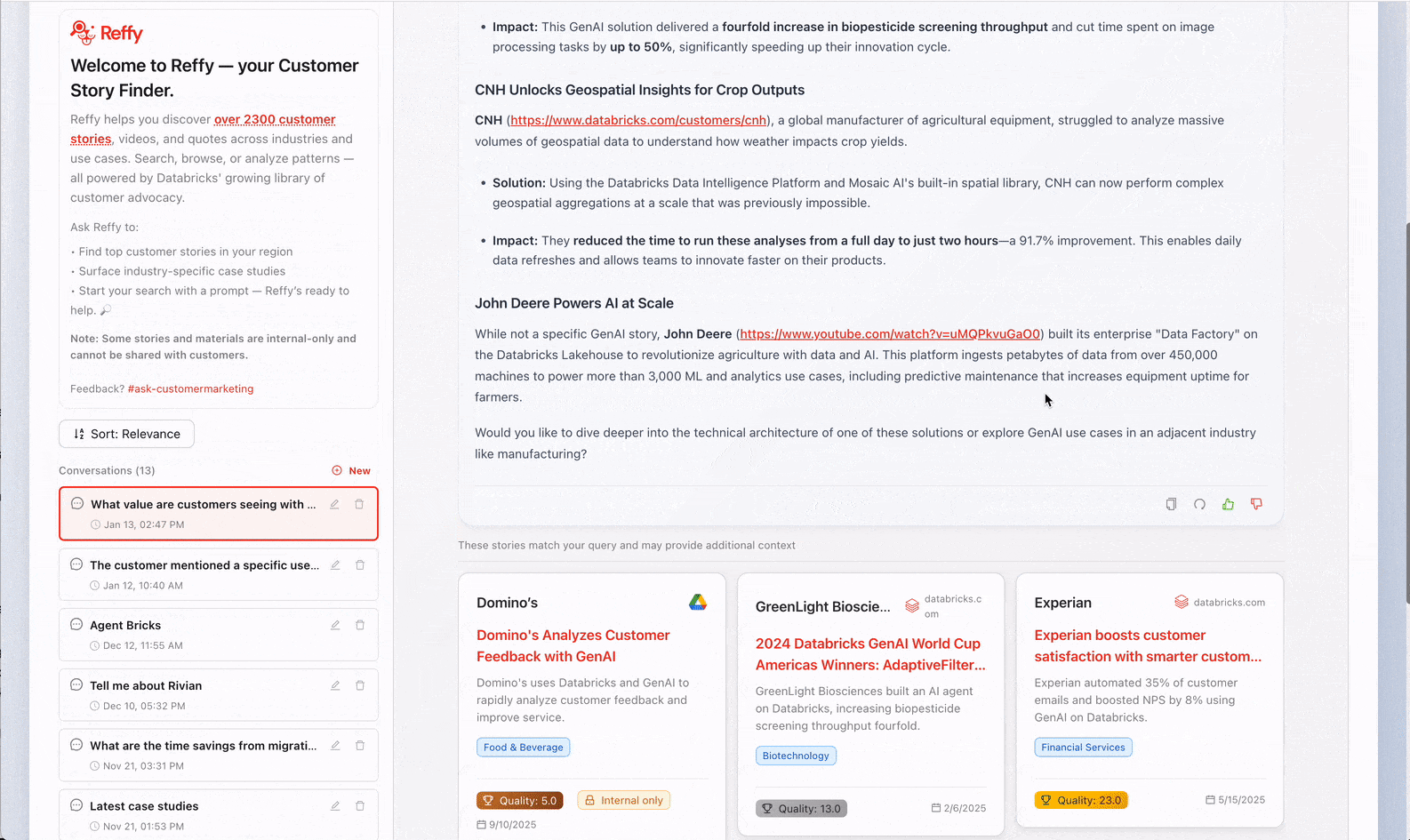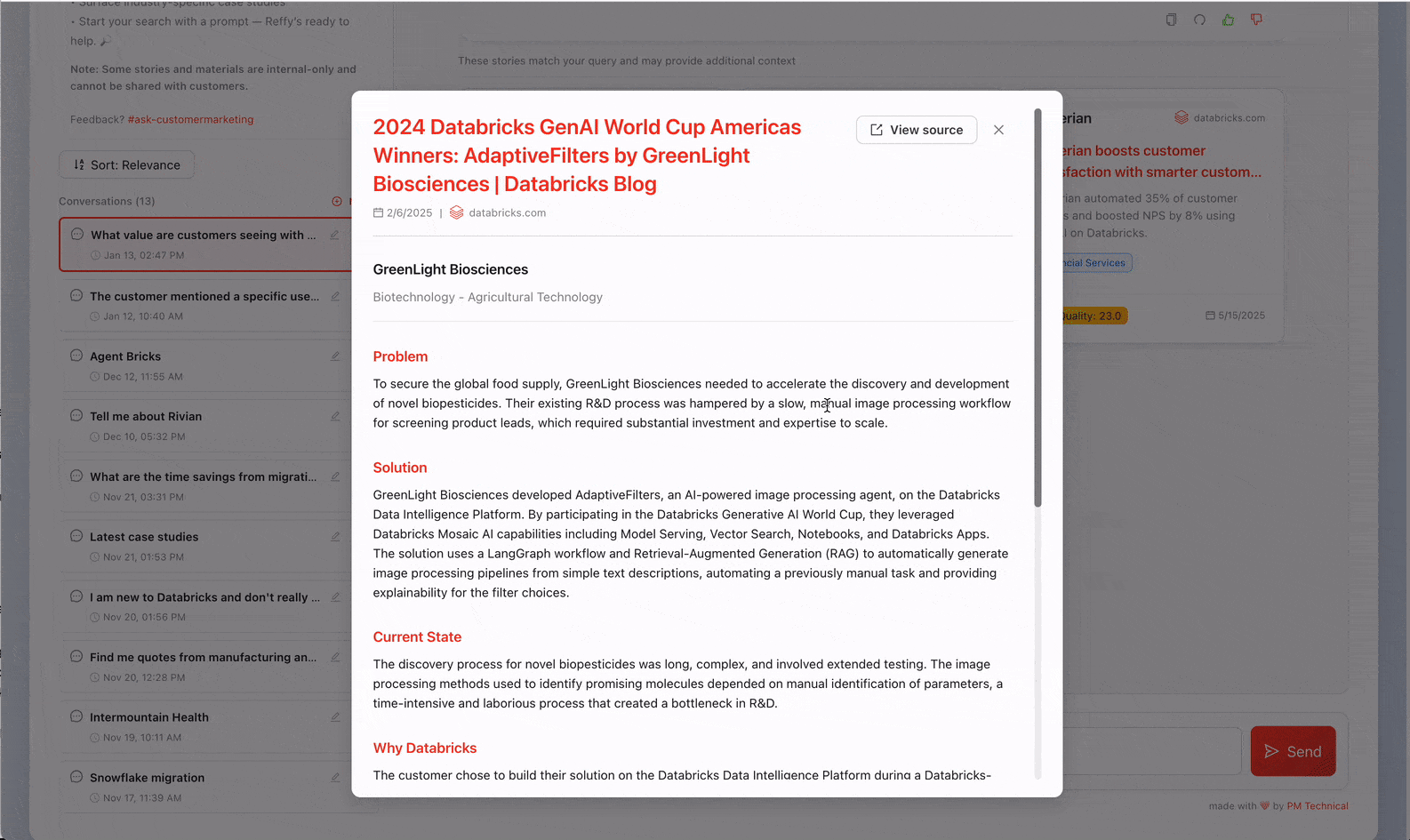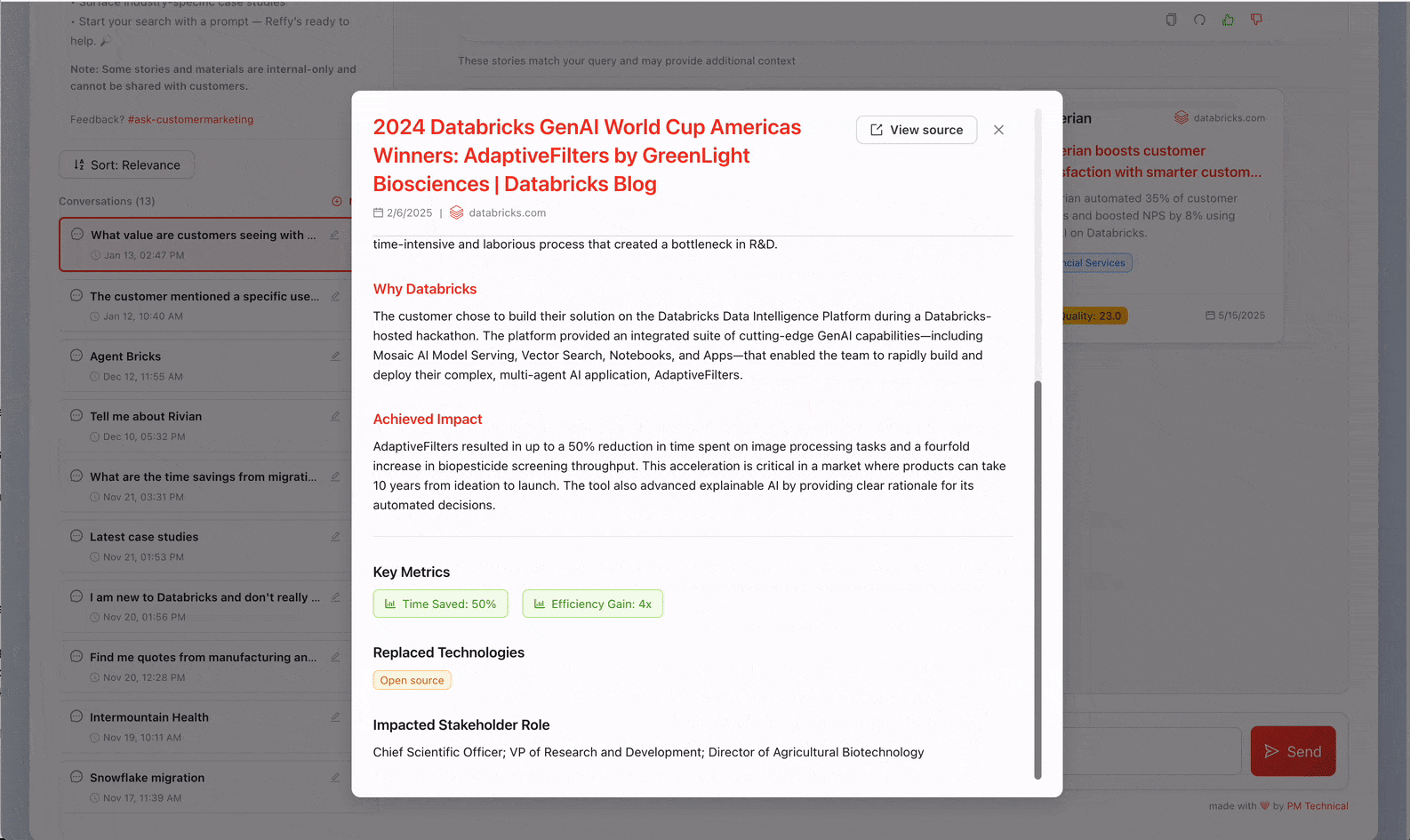
El desafío de democratizar el conocimiento tribal
"¿Quién más ha hecho esto?" es una pregunta que todo vendedor escucha. A un cliente potencial le intriga tu propuesta, pero antes de avanzar, quiere una prueba: un cliente similar que ya haya recorrido este camino. Debería ser fácil de responder.
Para nuestro equipo de marketing, las historias de clientes son un insumo fundamental para casi todas las acciones: campañas, lanzamientos de productos, publicidad, relaciones públicas, reuniones informativas con analistas y comunicaciones ejecutivas. Cuando esas historias no son fáciles de encontrar o evaluar, los problemas reales se agravan: las referencias de alto valor se usan en exceso, se pasan por alto los casos de uso o las industrias más recientes y la eficacia del marketing se ve limitada por el conocimiento tribal.
Databricks tiene miles de charlas en YouTube, casos de estudio en databricks.com, diapositivas internas, artículos de LinkedIn, publicaciones en Medium. En algún lugar se encuentra la referencia perfecta: una empresa de servicios financieros en Canadá que realiza detección de fraude en tiempo real, un minorista que reemplazó un almacén de datos heredado, un fabricante que escala la GenAI. ¿Pero encontrarla? Ahí es donde todo se complica. Las historias se encuentran en una docena de plataformas sin una búsqueda unificada, y cuando encuentras algo, no puedes saber de inmediato si es sólido: ¿tiene resultados comerciales creíbles o solo afirmaciones vagas?
Así que la gente hace lo que suele hacer: le envían un mensaje al equipo de marketing por Slack, buscan en carpetas que apenas recuerdan o preguntan por ahí hasta que alguien encuentra algo útil. A veces encuentran oro. La mayoría de las veces, se conforman con algo "suficientemente bueno" o se rinden por completo, sin saber si la historia perfecta siempre estuvo ahí.
Claramente, necesitábamos una mejor manera para que ventas y marketing descubrieran las historias de clientes más relevantes.
Reffy: una solución full-stack en Databricks
Para resolver este problema, consolidamos todas las historias en una única tabla, las categorizamos y luego usamos un agente basado en RAG para potenciar la búsqueda, todo ello a través de una aplicación de Databricks con un diseño atractivo. La arquitectura abarca toda la plataforma de Databricks: Lakeflow Jobs orquesta nuestros pipelines de ETL, Unity Catalog gobierna nuestros datos, AI Search potencia la recuperación, Model Serving aloja nuestro agente, Lakebase gestiona las lecturas y escrituras en tiempo real y Databricks Apps proporciona el frontend. Profundicemos en los detalles.
Fuentes de datos & ETL
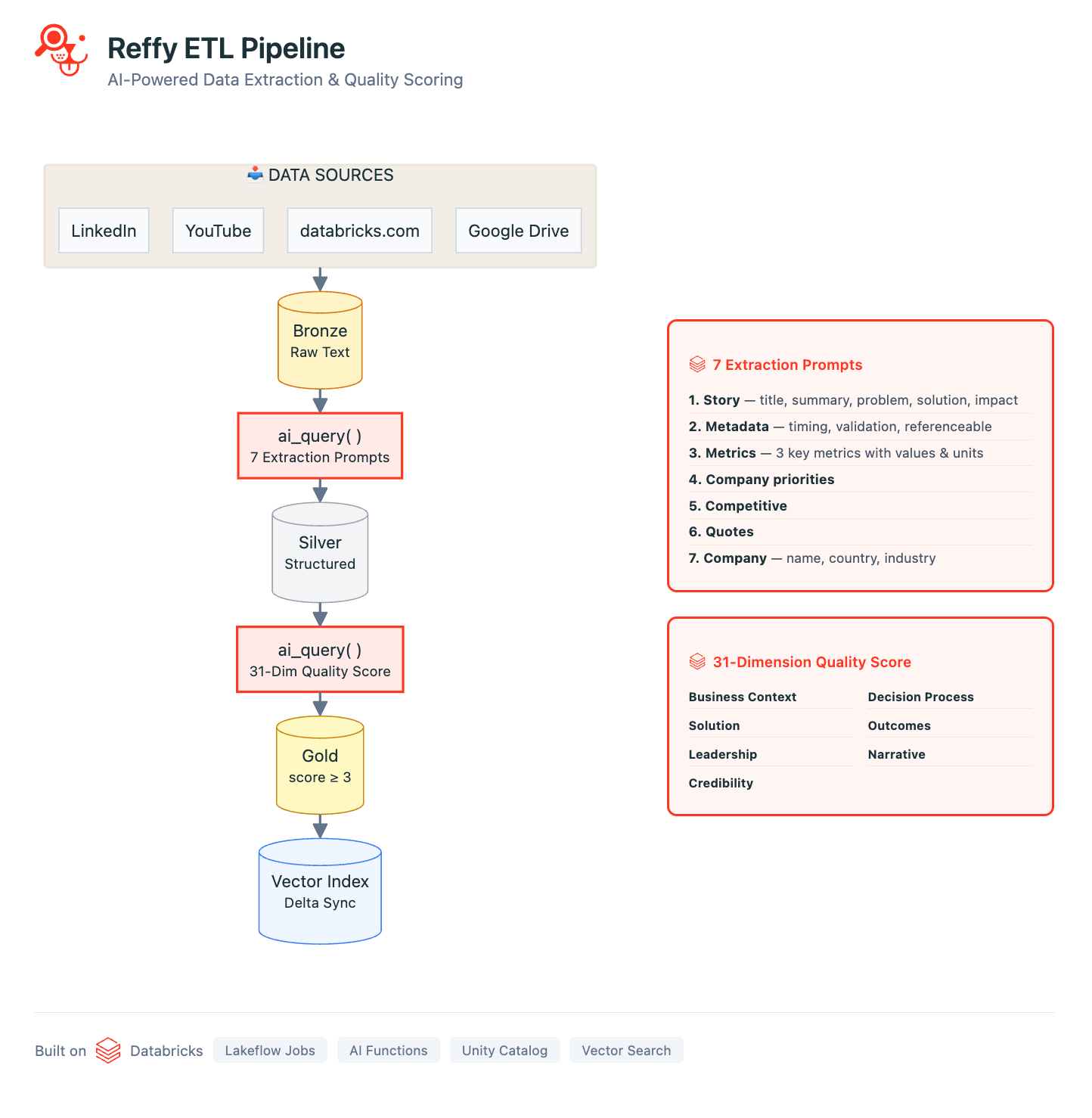
Nuestro pipeline se define en una serie de Databricks Notebooks orquestados con Lakeflow Jobs. El pipeline comienza recopilando el texto de las historias de todas nuestras fuentes de datos: usamos bibliotecas estándar de webscraping de Python para recopilar transcripciones de YouTube, artículos de LinkedIn/Medium y todas las historias públicas de clientes en databricks.com. Usando scripts de Google Apps, también consolidamos el texto de cientos de diapositivas y documentos internos de Google en una sola Google Sheet. Todas estas fuentes se procesan con metadatos básicos y se guardan en una tabla 'Bronze' de Delta Lake en Unity Catalog (UC).
Ahora tenemos todas nuestras historias en un solo lugar, pero todavía no tenemos ninguna perspectiva sobre su calidad. Para remediar esto, clasificamos el texto aplicando un riguroso sistema de puntuación de 31 puntos (desarrollado por nuestro equipo de Valor) a cada historia a través de AI Functions. Le pedimos a Gemini 2.5 que evalúe la calidad general de la historia mediante la identificación del desafío de negocio, la solución, la credibilidad del resultado y por qué Databricks estaba en una posición única para ofrecer valor. Juzgar historias como esta también nos permite filtrar las de menor calidad de Reffy. El prompt también extrae metadatos clave como el país y la industria, los productos utilizados, la competencia y las citas, y etiqueta las historias en función de si se pueden compartir públicamente o si son solo para uso interno. Este conjunto de datos enriquecido se guarda en una tabla "Silver" en UC.
Los pasos finales del ETL incluyen el filtrado de las historias con baja puntuación y la creación de una nueva columna de 'resumen' que concatena los componentes esenciales de la historia. La idea es simple: sincronizamos esta tabla 'Gold' con un índice de Databricks AI Search, donde la columna de resumen contiene toda la información esencial que un LLM necesitar�ía para hacer coincidir las historias de los clientes con las consultas.
IA agéntica
Usando el marco de DSPy, definimos un agente de llamada de herramientas que puede buscar las referencias de clientes más relevantes con búsqueda semántica y de palabras clave híbrida. ¡Nos encanta DSPy! Los agentes creados con él son fáciles de probar de forma iterativa en un notebook de Databricks sin tener que volver a implementarlos en un punto de conexión de Model Serving cada vez, lo que da como resultado un ciclo de desarrollo más rápido. La sintaxis es muy intuitiva en comparación con otros marcos populares, e incluye excelentes componentes de optimización de prompts. Si aún no lo has hecho, definitivamente echa un vistazo a DSPy.
Estructuramos nuestro agente de historias de clientes para facilitar una búsqueda por palabras clave pura y ultrarrápida y una respuesta de formato largo de un LLM con razonamiento según la entrada del usuario: si haces una pregunta, obtendrás una respuesta bien pensada con fuentes, pero si solo ingresas algunas palabras clave, Reffy devolverá los mejores resultados en menos de dos segundos. También usamos el re-ranker de Databricks para AI Search para mejorar los resultados de RAG.
Para garantizar una respuesta equilibrada y profesional, usamos el siguiente prompt del sistema:
El agente se registra en MLflow y se implementa en Databricks Model Serving usando nuestro Agent Framework. Como la mayor parte del procesamiento se realiza del lado del proveedor del modelo, podemos optar por desplegar en una instancia de CPU pequeña, ahorrando en costos de infraestructura en comparación con las GPU.
La Databricks App
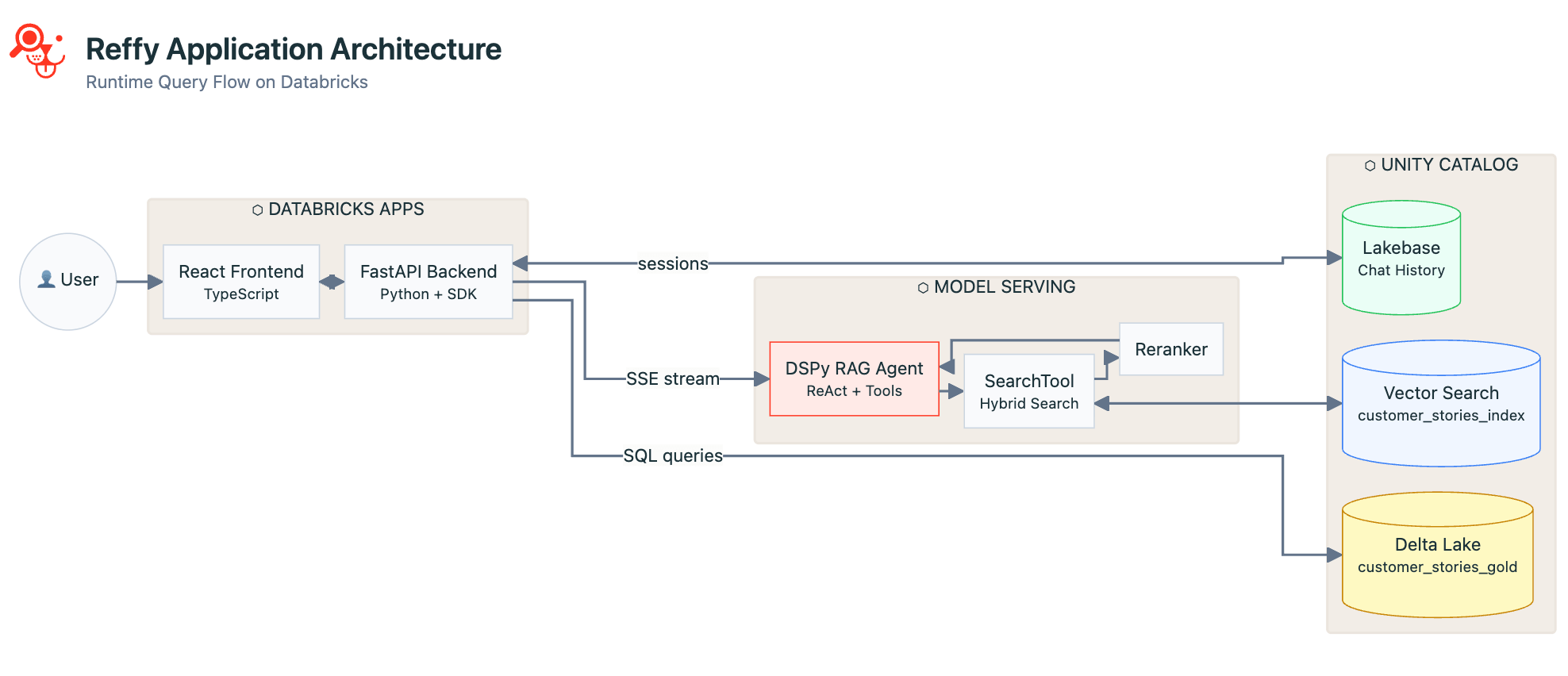
Ahora que tenemos los datos limpios e indexados y que el agente funciona bien, es hora de crear una aplicación para unirlo todo y hacerlo accesible a los usuarios no técnicos. Elegimos un frontend de React con un backend de Python FastAPI. React es atractivo y rápido en el navegador y admite la salida de streaming desde nuestro punto de conexión de Model Serving. FastAPI nos permite aprovechar todas las ventajas del SDK de Python de Databricks en nuestra aplicación, a saber:
- Autenticación unificada: sin cambios de código al autenticarse localmente durante el desarrollo en comparación con la implementación en las aplicaciones de Databricks. Las aplicaciones tienen las mismas variables de entorno que la autenticación local, por lo que el código funciona sin problemas.
- Amplia cobertura de API: podemos llamar a Model Serving, ejecutar consultas SQL o cualquier otra cosa que necesitemos desde un workspace de Databricks, todo a través de un único SDK.
Reffy es principalmente una aplicación de chat, por lo que usamos Lakebase para conservar todo el historial de conversaciones, los registros y las identidades de los usuarios para lecturas y escrituras rápidas, control de calidad y un seguimiento atento cuando los usuarios regresan o inician nuevas conversaciones.
Supervisión y métricas continuas
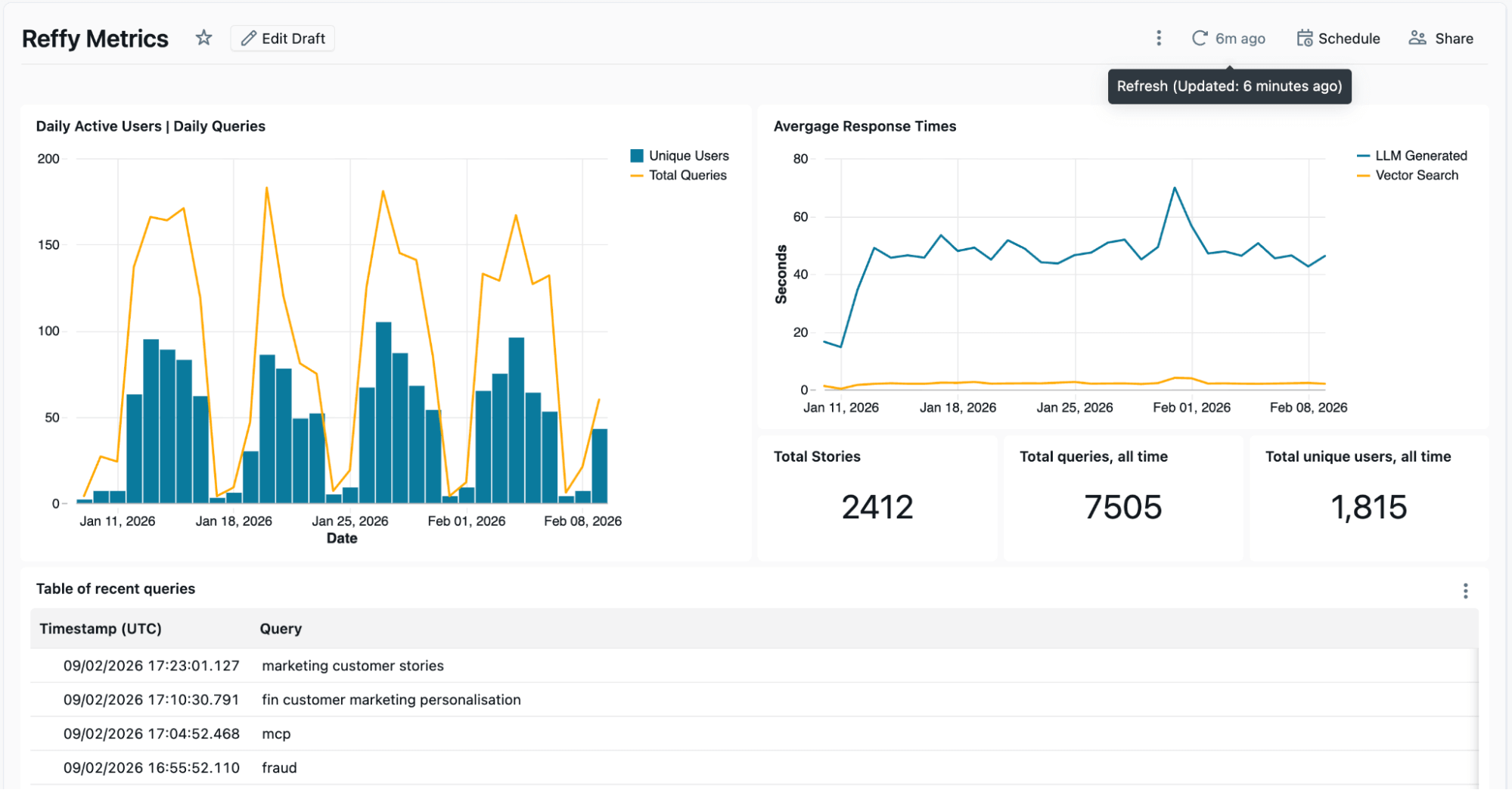
Los registros de Lakebase se procesan en un trabajo de Lakeflow independiente para mostrar métricas clave, como los usuarios activos diarios y los tiempos de respuesta promedio, en un panel de control de AI/BI. Este panel de control también nos muestra las entradas y respuestas recientes, y vamos un paso más allá al aplicar otra función de IA para resumir las entradas y respuestas en temas recientes y análisis de carencias. Queremos entender qué historias de clientes son populares y dónde podemos tener carencias, y los registros que recopilamos de Reffy nos ayudan a hacer precisamente eso. Por ejemplo, descubrimos que los usuarios estaban especialmente interesados en encontrar historias sobre Agent Bricks y Lakebase, dos de los productos más nuevos de Databricks.
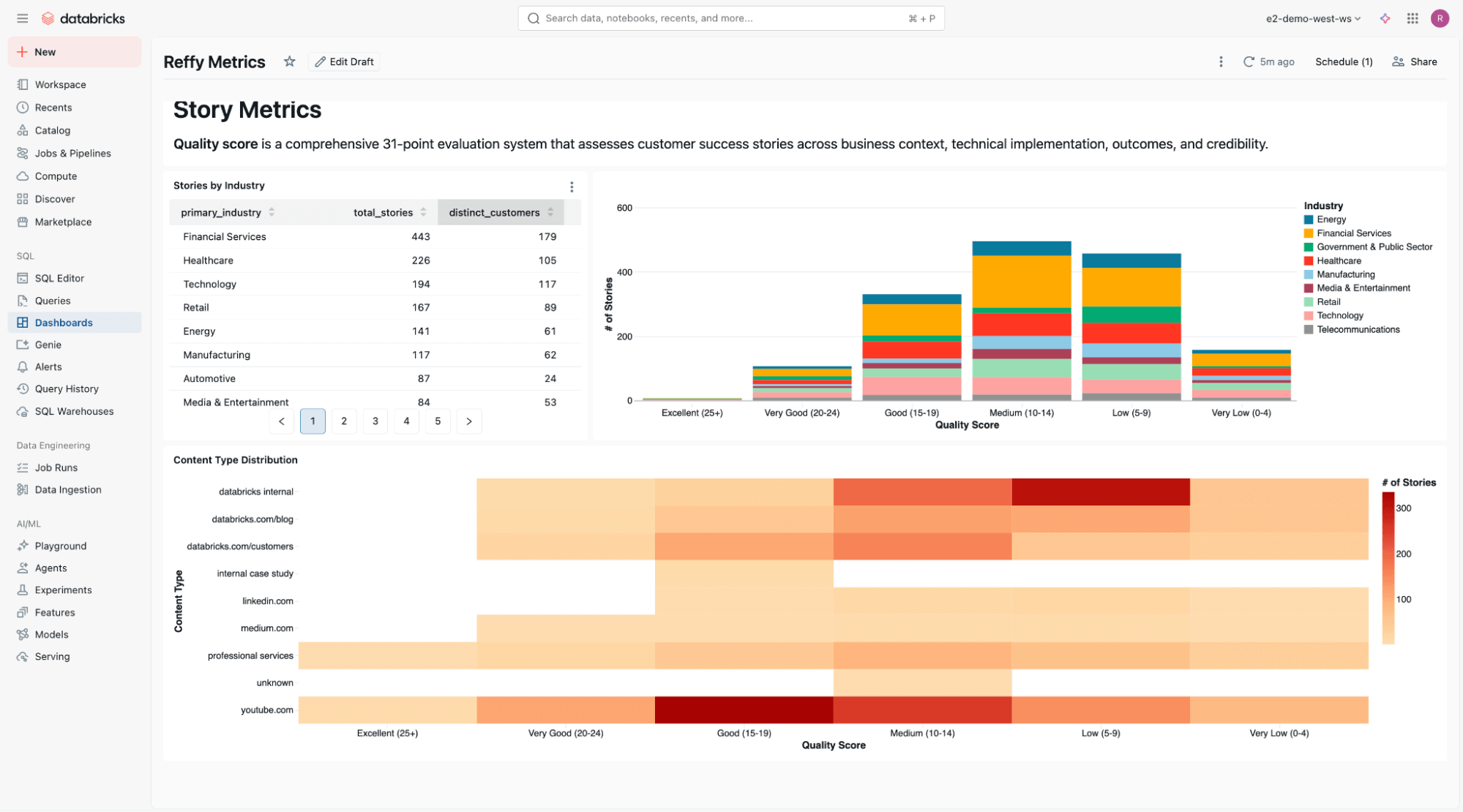
En la parte inferior del dashboard, incluimos un análisis estático de la calidad de la historia en todas las industrias y tipos de contenido.
Una nota sobre la configuración del desarrollo
La mayor parte del desarrollo del proyecto se lleva a cabo en Cursor, y, como se mencionó anteriormente, la autenticación unificada entre la CLI de Databricks y el SDK simplifica las cosas. Iniciamos sesión una vez a través de la CLI, y todas nuestras compilaciones locales de Reffy que usan el SDK se autentican. Cuando queremos probar en Databricks Apps, usamos la CLI para sincronizar el código más reciente con nuestro Workspace y luego implementar la aplicación. Databricks Apps comprueba las mismas variables de entorno para la autenticación que hemos establecido localmente, por lo que nuestras llamadas a Model Serving y SQL Warehouses que se basan en el SDK ¡simplemente funcionan! Nuestro devloop iterativo se convierte en:
- Inicia sesión en Workspace a través de la CLI
- Crear código en Cursor
- Probar localmente
- Sincronizar el código con el workspace y desplegar la aplicación
- Probar en Databricks Apps
Finalmente, para garantizar una CI/CD y una portabilidad adecuadas, utilizamos Databricks Asset Bundles para vincular todo el código y los recursos utilizados por Reffy en un solo paquete. Este paquete se implementa a través de GitHub Actions en nuestro Workspace de producción de destino.
Lo que aprendimos
Varios equipos de Databricks ya habían resuelto partes de este problema de forma independiente, gravitando de forma natural hacia el trabajo más emocionante: la capa de IA. Sin embargo, la ingeniería de datos sigue siendo fundamental, y hacer bien el ETL, puntuar la calidad de las historias y estructurar los datos para una recuperación eficaz resultó ser tan crucial como el propio agente.
La colaboración fue igualmente esencial. Las historias de los clientes llegan a casi todos los rincones de la organización: Ventas, Marketing, Ingeniería de campo y Relaciones Públicas, todos juegan un papel importante. La creación de alianzas sólidas con estos grupos dio forma tanto al producto como a los datos que lo impulsan.
¿Qué sigue?
Si bien la interfaz de la aplicación ofrece un valor inmediato, el verdadero poder surgirá al conectar Reffy con otras soluciones en Databricks. Planeamos proporcionar esa conectividad a través de una API y un servidor MCP, lo que permitirá a los equipos acceder a la inteligencia de clientes directamente en sus flujos de trabajo y herramientas existentes.
Con Databricks y Lakebase, también podemos entender cómo miles de usuarios interactúan con Reffy a lo largo del tiempo. Estos conocimientos nos permitirán perfeccionar continuamente la herramienta y dar forma de manera reflexiva a las historias que se agreguen a este ecosistema en crecimiento.
Para los equipos de Databricks que hoy tienen dificultades con el descubrimiento de referencias de clientes, Reffy ofrece un ejemplo concreto de lo que es posible cuando estas capacidades se unen. Para empezar a crear su propia aplicación agéntica en Databricks, obtenga más información sobre las aplicaciones de Databricks, nuestra guía de RAG, Lakebase y Agent Bricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.