¿Qué es un MMM y por qué es importante para los profesionales del marketing?

El MMM (Marketing or Media Mix Modeling) es una metodología basada en datos que permite a las empresas identificar y medir el impacto de sus campañas de marketing en múltiples canales. El propósito del MMM es ayudar a las empresas a tomar decisiones informadas sobre sus estrategias de publicidad y marketing. Al analizar datos de varios canales, como la televisión, las redes sociales, el marketing por correo electrónico y más, el MMM puede determinar qué canales contribuyen más a las ventas y a otros resultados comerciales. Al incluir eventos e indicadores externos, quienes toman las decisiones pueden comprender mejor el impacto de los factores externos (como los días festivos, las condiciones económicas o el clima) y evitar valorar en exceso de forma accidental el impacto del gasto publicitario por sí solo.
Con el MMM, las empresas pueden identificar qué canales de marketing generan la mayor interacción, ventas o ingresos. Esta información se puede utilizar para optimizar los presupuestos de marketing y asignar recursos a los canales que sean más eficaces. Por ejemplo, supongamos que una empresa ha estado ejecutando campañas de marketing en diferentes canales, como redes sociales, marketing por correo electrónico, anuncios de televisión, etc. Sin embargo, el equipo de marketing no está seguro de qué canal ofrece el mayor ROI. Aquí es donde el MMM resulta útil. Al analizar los datos agregados de todos estos canales, un modelo potente puede ayudar a la empresa a identificar las campañas que generan más ingresos, así como los canales que ofrecen el retorno de la inversión publicitaria más eficiente, lo que les permite optimizar sus estrategias publicitarias de manera eficaz. Esto permite a la empresa optimizar sus esfuerzos de marketing y asignar su presupuesto en la dirección correcta.
Durante años, el MMM ha sido una herramienta muy potente y se ha considerado un elemento transformador, que ofrece a las empresas inteligentes la ventaja que necesitan para mantenerse por delante de la competencia. Al aprovechar el poder de la toma de decisiones basada en datos, el MMM permite a las empresas realizar inversiones inteligentes en sus estrategias de marketing, garantizando que cada dólar se gaste en el lugar correcto, en el momento adecuado y de la manera correcta. Esto se traduce en resultados convincentes, desde una mayor interacción con el cliente y un aumento de las ventas, hasta un alto retorno de la inversión.
La evolución del MMM
El MMM existe desde hace décadas y siempre ha sido una herramienta potente para medir la eficacia de las campañas de marketing. El modelo puede tener en cuenta varios factores, como la estacionalidad, la actividad de la competencia y las tendencias macroeconómicas, para ofrecer una visión holística del impacto general de las actividades de marketing. Sin embargo, en los últimos años, el MMM se ha visto un poco eclipsado por la MTA (Multi-Touch Attribution), que ofrece un enfoque de atribución más granular al realizar el seguimiento de usuarios individuales a través de múltiples puntos de contacto. Con la MTA, los profesionales del marketing pueden ver qué puntos de contacto específicos generan conversiones para los usuarios individuales y asignar el presupuesto en consecuencia. Este nivel de granularidad ha convertido a la MTA en una opción popular para muchos profesionales del marketing, especialmente en el ámbito del marketing digital.
Pero con las nuevas normativas de privacidad, como el GDPR (General Data Protection Regulation) y la CCPA (California Consumer Privacy Act), el seguimiento basado en cookies en el que se apoya la MTA se está volviendo más difícil. Esto significa que el MMM, que utiliza datos agregados en lugar de datos a nivel de usuario, está cobrando un nuevo impulso para destacar.
Por lo tanto, es posible que se pregunte qué herramienta elegir para medir la eficacia del marketing. Al elegir entre ambas, hay varios factores a considerar a la hora de seleccionar el MMM. Una opción a considerar es elegir el MMM cuando algunos o todos sus datos ya están agregados previamente. Otro factor es si sus esfuerzos de marketing involucran canales tanto online como offline. Esto es cada vez más importante en la era digital actual, donde las líneas entre el marketing online y offline a menudo se difuminan. Por último, si dispone de información externa que sea relevante para sus esfuerzos de marketing, como los resultados de pruebas geográficas, el MMM puede ayudarle a incorporar estos datos a su modelo.
Ventajas del MMM
En primer lugar, el análisis basado en el MMM puede incorporar el impacto de los canales offline, como la televisión, la prensa escrita, la radio o la publicidad OOH (Out-Of-Home), que no se pueden rastrear con cookies. Algunas técnicas de modelado más avanzadas incluso tienen la capacidad de incorporar el efecto embudo, que describe cómo funcionan juntos varios canales, así como los efectos multiplicativos que explican el impacto sinérgico de estos canales. Además, puede proporcionar información sobre el impacto a más largo plazo de las actividades de marketing, algo que la MTA podría pasar por alto. El MMM se considera más escalable y se puede utilizar para medir el impacto de las actividades de marketing en grandes regiones geográficas o incluso en países enteros.
Además, el MMM puede ayudar a las empresas a cumplir con las normativas de privacidad al utilizar datos agregados en lugar de datos de usuarios individuales. Esto significa que las empresas aún pueden medir la eficacia de sus actividades de marketing sin comprometer la privacidad del usuario.
En esta publicación de blog, exploraremos las características clave del MMM y cómo la plataforma Databricks Lakehouse puede ayudar a las empresas a crear una solución de MMM moderna, robusta y escalable.
Cómo superar los desafíos comunes
El MMM es implementado por una variedad de empresas, desde firmas de consultoría hasta anunciantes y proveedores de software. A medida que las empresas siguen buscando formas de optimizar su gasto en marketing, el MMM se ha convertido en un método cada vez más popular para medir el ROI. Sin embargo, crear una solución de MMM escalable y robusta puede ser una tarea difícil. En esta sección analizamos algunos de los desafíos comunes a los que se enfrentan las empresas al crear una solución escalable. En esta sección analizamos algunos de los desafíos comunes.
Uno de los desafíos más importantes a la hora de crear una solución de MMM son las fuentes de datos ascendentes. El equipo de ciencia de datos y aprendizaje automático necesita unificar los flujos de datos de diferentes fuentes para los datos de MMM, incluidos datos de terceros como los datos econométricos, que carecen de métodos de recopilación estandarizados. Además, las fuentes de datos suelen estar dispersas en varios lugares, como bases de datos heredadas, Hive, archivos planos sftp y otras fuentes, lo que dificulta la obtención de los datos necesarios. Además, los datos deben actualizarse manualmente cada mes, lo que puede ser una tarea tediosa y lenta.
Otro obstáculo para lograr resultados de MMM precisos es la falta de datos. Por ejemplo, es común que falte la ingesta de datos económicos y de medios tradicionales u offline, lo que puede dificultar sustancialmente la precisión de los resultados. Este desafío puede ser especialmente pronunciado para las empresas que tienen presencia en varios países, donde las normativas pueden imponer restricciones a la recopilación y el intercambio de datos. En la era moderna de la AI, la solución de MMM, al ser una forma de modelo de aprendizaje automático, no está exenta de los desafíos y riesgos asociados con el campo emergente de la AI. El seguimiento del linaje de las fuentes de datos hasta los modelos, desde la ingesta hasta el panel de control de información, puede ser un obstáculo importante para los enfoques tradicionales, lo que dificulta mantener la transparencia y la responsabilidad.
Además, la existencia de silos de equipos puede dificultar la creación de una solución de MMM escalable. La creación de modelos a menudo ocurre en entornos segregados, lo que genera barreras entre los equipos tanto horizontalmente, abarcando dominios funcionales técnicos y comerciales, como verticalmente, a través de niveles organizacionales, marcas, categorías y unidades de negocio. La ausencia de métodos de control de versiones para los modelos, el código y los datos puede provocar inconsistencias e imprecisiones dentro de la solución de MMM. Además, el código heredado y poco manejable puede hacer que la solución sea difícil de mantener y actualizar, lo que requiere importantes esfuerzos de refactorización. Además, a menudo se producen procesos manuales y el análisis se realiza normalmente como una actividad única cada pocos meses, que las personas o los equipos pequeños deben repetir en lugar de formar parte de un pipeline de DSML más automatizado, repetible y confiable.
Por último, la publicación de datos y el intercambio de información a menudo se retrasan y requieren una integración independiente. Esto puede dificultar que las partes interesadas tomen decisiones informadas rápidamente, lo que provoca un mayor retraso en la toma de decisiones, la pérdida de oportunidades y una baja agilidad para reaccionar en un entorno económico cada vez más rápido y dinámico, especialmente cuando los competidores se mueven a la velocidad de la luz. Muchas soluciones de MMM existentes también carecen de la flexibilidad y la protección de la privacidad necesarias para colaborar de manera eficaz con clientes y socios.
Como resultado, las empresas deben adoptar un enfoque integral y meticuloso para implementar el MMM en la era de la AI, teniendo en cuenta los desafíos y riesgos únicos asociados con la tecnología DSML.
Cree su MMM escalable y flexible con Databricks Lakehouse
Diagrama de referencia
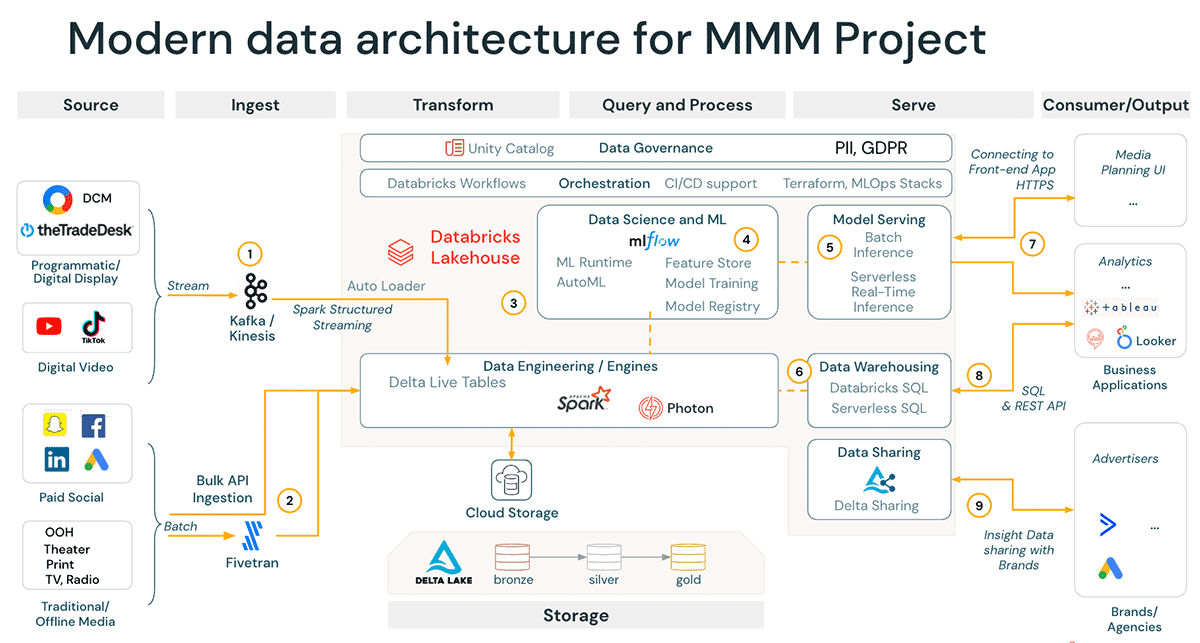
Databricks Lakehouse está diseñado para proporcionar a las empresas una plataforma unificada para crear soluciones de MMM modernizadas que sean tanto escalables como flexibles.
Una de las ventajas más importantes de Databricks Lakehouse es su capacidad para unificar diversas fuentes de datos de origen. Esto significa que la plataforma puede reunir diferentes fuentes de datos que son esenciales para el MMM, como los datos econométricos offline, los datos de campañas de medios y los datos de CRM, y unificarlos en una única fuente de verdad. Esto resulta especialmente útil en el mundo actual impulsado por los datos, donde las empresas tienen que gestionar grandes volúmenes de datos procedentes de distintas fuentes.
Otra ventaja clave de Databricks Lakehouse que beneficia enormemente al MMM es la capacidad de agilizar los pipelines de datos. Tras la ingesta de datos, el proceso de MMM requiere transformar varios canales de marketing y analizar su impacto en los KPI, lo que implica gestionar una amplia variedad de datos de diversas fuentes. El Lakehouse puede automatizar la ingesta, el procesamiento y la transformación de datos, lo que reduce el tiempo y el esfuerzo necesarios para administrar los pipelines de datos manualmente. Esto garantiza que los datos se entreguen de forma incremental, con una supervisión exhaustiva de la calidad de los datos.
Además, el Lakehouse ofrece un sistema de seguimiento de linaje que garantiza establecer el linaje de todos sus activos de datos (no solo de los datos en sí, sino también del código, los artefactos del modelo y las iteraciones de trabajos), lo cual es una ventaja significativa de Databricks Lakehouse. Proporciona total transparencia y trazabilidad del uso de los datos, lo que permite a las empresas tomar decisiones basadas en datos con total confianza. Esto es especialmente importante en el contexto del MMM, donde la precisión y la confiabilidad de los datos son fundamentales para comprender el impacto de los canales de marketing en las ventas y optimizar la asignación del presupuesto de marketing.

Pasando a la fase de modelado, uno de los diferenciadores clave de Databricks Lakehouse son sus potentes capacidades de DSML, que son especialmente evidentes en su ML Runtime de primer nivel y sus herramientas de MLOps. Una tarea crucial para el modelado de MMM es la configuración previa exhaustiva y la transformación de variables, que requieren un gran número de iteraciones. MLflow permite a los profesionales del marketing realizar un seguimiento de la derivación y transformación de sus variables independientes (features) y su uso en los modelos. Además, el Feature Store de Databricks fomenta las mejores prácticas en la ingeniería de características, proporcionando al equipo de DSML las herramientas y la infraestructura necesarias para crear, descubrir y reutilizar características. Esto agiliza el proceso de modelado y mejora la precisión de las predicciones para los resultados comerciales. Estas capacidades permiten a los profesionales del marketing aprovechar al máximo el potencial de sus datos de manera fluida, impulsando decisiones de marketing más informadas y eficaces.
A estas alturas, debería ser evidente que Databricks aporta enormes mejoras de eficiencia al equipo de MMM. Con Databricks, incluso los científicos de datos que trabajan en un solo nodo pueden distribuir el ajuste y el entrenamiento, ejecutar múltiples escenarios y configuraciones simultáneamente en todo el clúster, y crear modelos independientes en paralelo para distintas marcas, categorías y regiones geográficas; consulte la demostración a continuación:
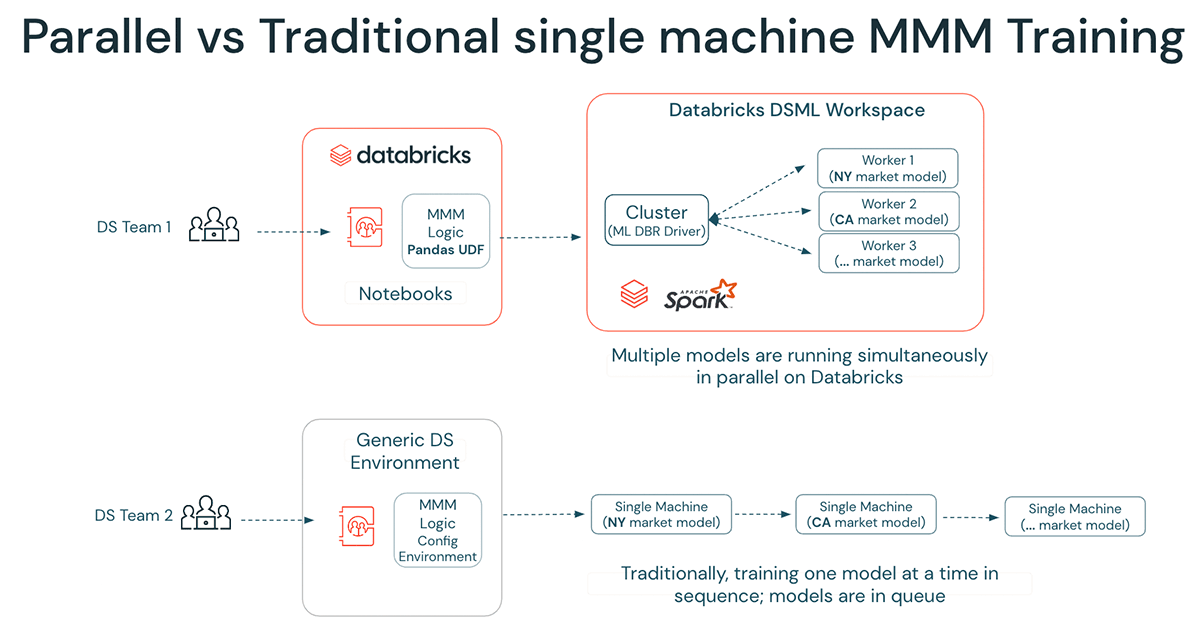
El ML Runtime es un entorno de ML totalmente administrado, seguro y colaborativo que potencia directamente la productividad del equipo de DS sin necesidad de que arranquen, creen o mantengan su propio entorno de DS. Además, fomenta un flujo de trabajo colaborativo al facilitar el intercambio de tareas, lo que evita que los diferentes equipos adopten enfoques inconsistentes. Una solución consiste en desarrollar mecanismos para completar los datos faltantes, como el abastecimiento desde un marketplace o el almacenamiento de datos obtenidos de fuentes como Dun & Bradstreet, S&P, Edgar, datos meteorológicos y estudios de mercado en una ubicación bien organizada en el Lakehouse. Este enfoque puede evitar que los equipos reinventen la rueda en lo que respecta a datos y código, lo que en última instancia ahorra tiempo y recursos. Sin embargo, es fundamental reconocer que esta falta de reutilización y el hecho de reinventar la rueda también se aplica al código y al resto del pipeline, por lo que es necesario trasladar el MMM a silos de equipo para aumentar la eficiencia y minimizar las discrepancias.
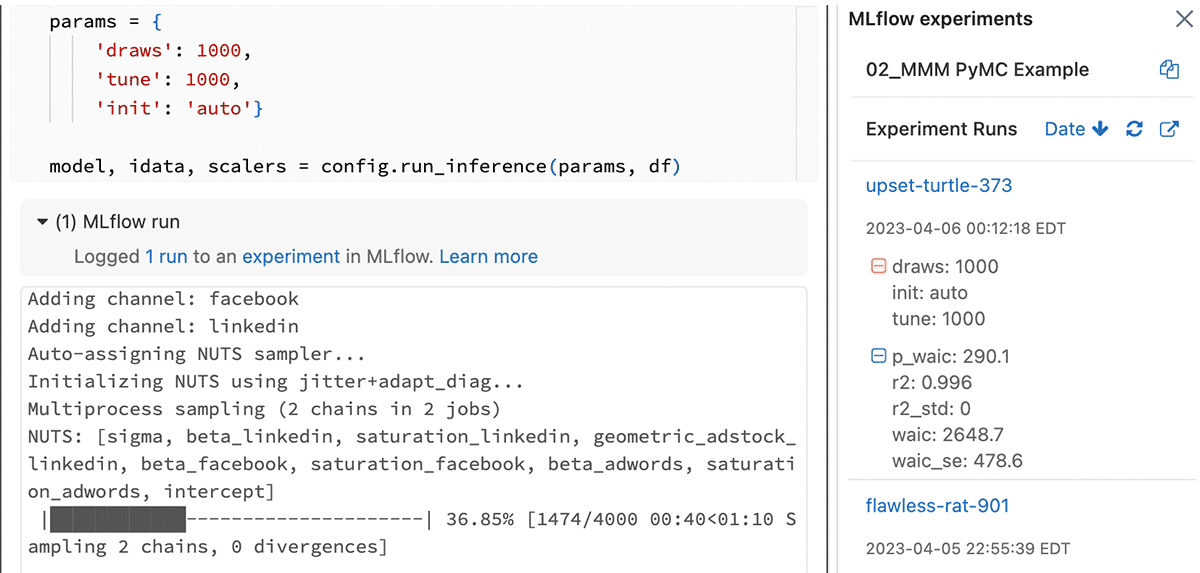
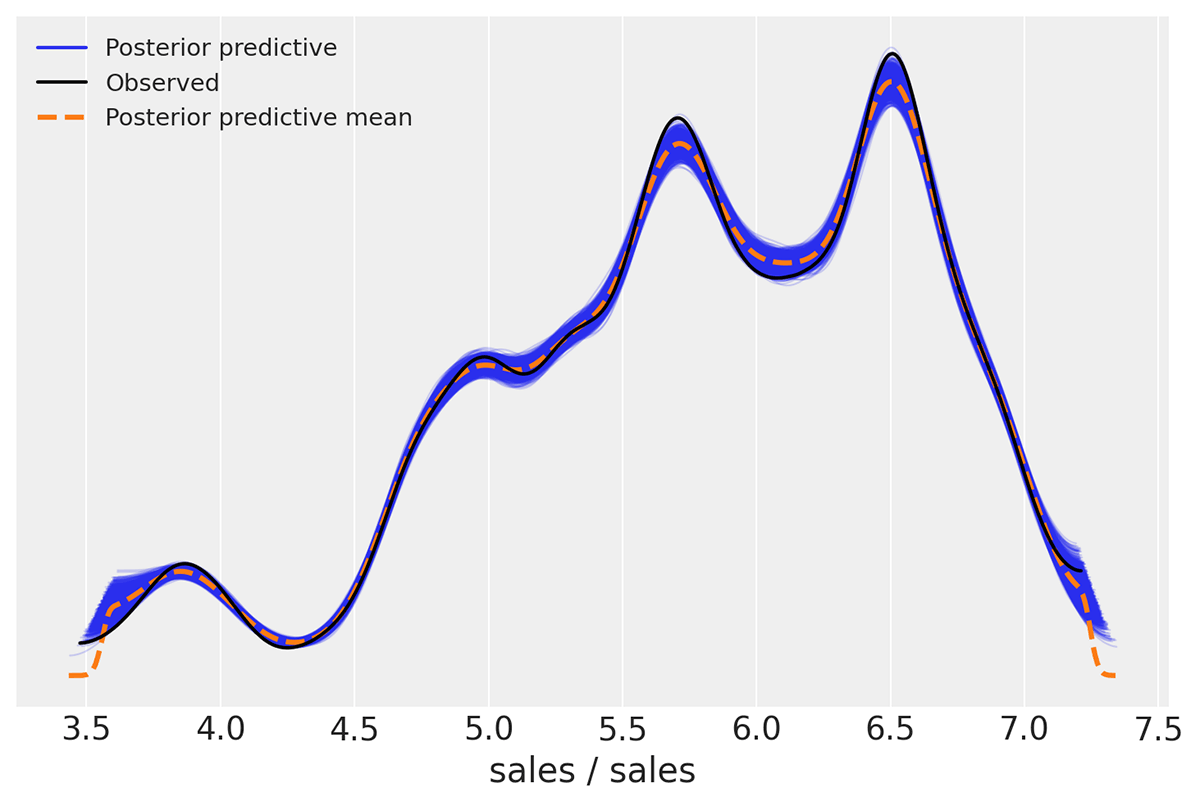
La naturaleza de código abierto de Lakehouse proporciona el entorno ideal para ejecutar todas las bibliotecas de código abierto populares para MMM, como PyMC en Python y Robyn en R. Esta característica permite a los usuarios crear soluciones que se adapten a sus necesidades específicas y evitar la dependencia de un solo proveedor.
Por último, pero no menos importante, DBSQL con integración de BI y el marketplace de Databricks permiten al equipo de MMM publicar la información relevante del modelo con facilidad, lo que reduce el tiempo necesario para llevar los nuevos proyectos de modelado desde la recopilación de datos hasta las conclusiones prácticas para los ejecutivos de MMM. Al consolidar y estandarizar toda la actividad de datos e IA, el Lakehouse se convierte en el mejor lugar para crear no solo una solución de MMM, sino también cualquier otra solución de datos e IA en la que el equipo trabaje hoy y en el futuro.
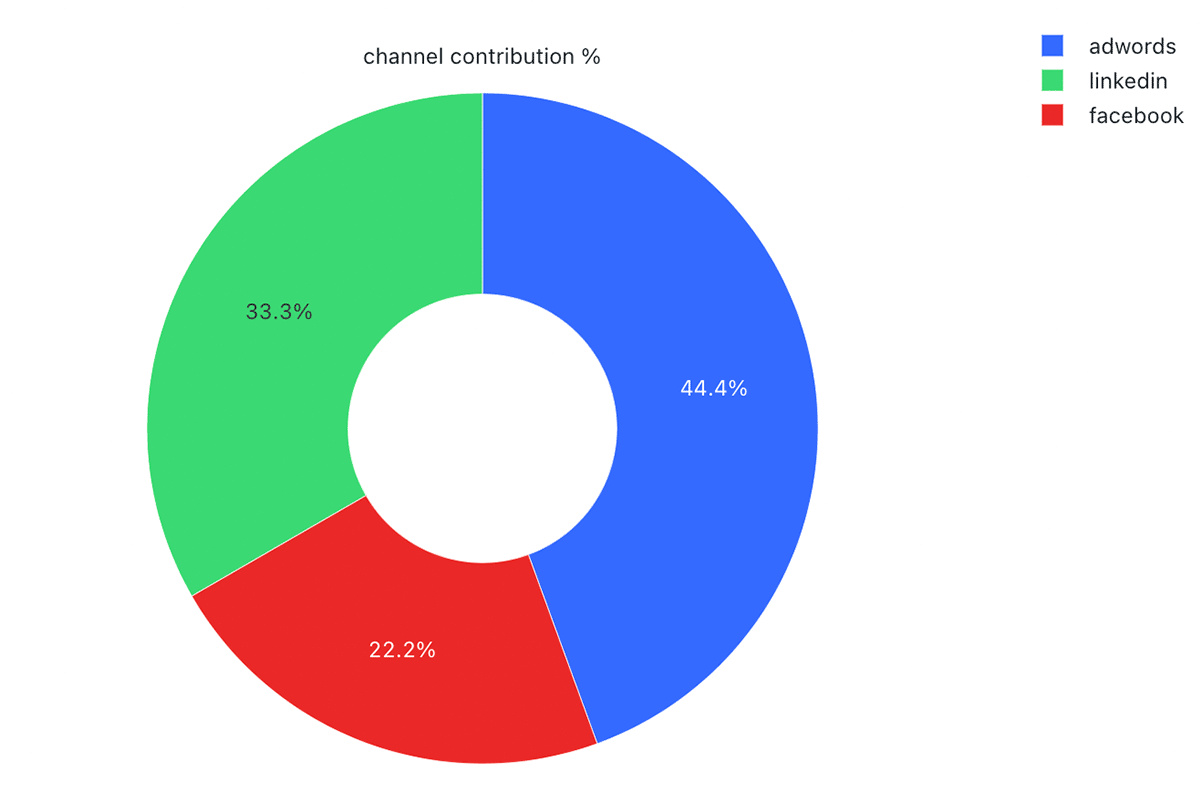
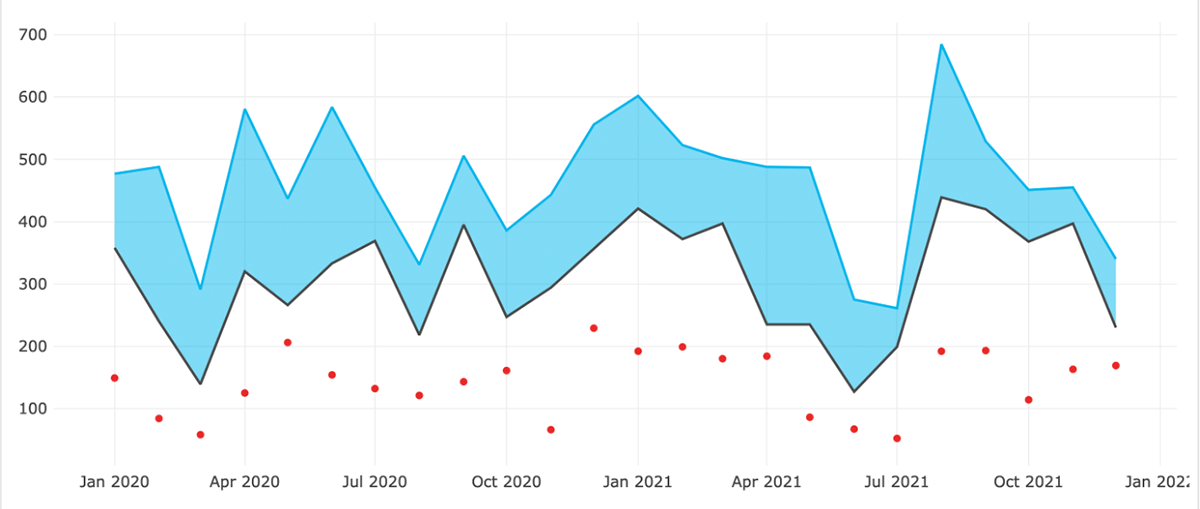
Descubra cómo Databricks para Lakehouse puede ayudarle a optimizar las campañas de marketing en múltiples canales con MMM. Acceda al acelerador de soluciones.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.