¿Qué es el flujo de datos?
Movimiento y transformación de datos desde el origen hasta el destino a través de canales de transmisión, flujos de trabajo por lotes, procesamiento de eventos en tiempo real y ETL orquestado.
- Los patrones incluyen extracción-transformación-carga (ETL) para procesamiento por lotes, extracción-carga-transformación (ELT) que aprovecha el cómputo del sistema de destino, arquitecturas de streaming para procesamiento continuo y arquitecturas lambda que combinan procesamiento por lotes y en tiempo real.
- La orquestación gestiona las dependencias de las tareas, programa la ejecución, gestiona errores, habilita el procesamiento paralelo, proporciona paneles de supervisión y mantiene el estado en sistemas distribuidos, coordinando flujos de trabajo complejos de varias etapas.
- Las técnicas de optimización abarcan el procesamiento incremental, evitando el recálculo completo, el particionamiento para el paralelismo, el almacenamiento en caché de resultados intermedios, la inserción de predicados para minimizar el movimiento de datos y la asignación adaptativa de recursos según las características de la carga de trabajo.
¿Qué es el flujo de datos?
El flujo de datos describe el movimiento de datos a través de la arquitectura de un sistema, de un proceso o componente a otro. Describe cómo se introducen, procesan, almacenan y se generan los datos dentro de un sistema informático, aplicación o red. El flujo de datos tiene un impacto directo en la eficiencia, la fiabilidad y la seguridad de cualquier sistema informático, por lo que es crucial que un sistema esté correctamente configurado para optimizar sus resultados.
Hay varios componentes clave que definen cómo se mueven y procesan los datos dentro de un sistema de flujo de datos:
- Fuente de datos. El flujo de datos comienza con la ingesta de datos de una fuente determinada, que puede incluir tanto datos estructurados como no estructurados, fuentes con scripts o entradas de clientes. Estas fuentes inician el flujo de datos y ponen en movimiento el sistema de flujo de datos.
- Transformación de datos. Una vez que los datos se han incorporado al sistema, pueden someterse a una transformación para convertirlos en una estructura o formato utilizable para el análisis o la ciencia de datos. La transformación de datos se produce de acuerdo con las reglas de transformación de datos, que definen cómo deben manejarse o modificarse los datos en todo el sistema. Esto ayuda a garantizar que los datos estén en el formato correcto para los procesos y resultados de su negocio.
- Sumidero de datos. Una vez que los datos se ingestaron y transformaron, el destino final de los datos procesados es el sumidero de datos. Este es el punto final en un sistema de datos, donde los datos se usan sin transferirse más en el flujo de datos. Esto puede incluir una base de datos, lakehouse, informes o archivos de registro donde se registran los datos para auditoría o análisis.
- Rutas de flujo de datos. Los diagramas de flujo de datos definen las rutas o canales por los que viajan los datos entre las fuentes, los procesos y los destinos. Estas rutas pueden incluir conexiones de red físicas o rutas lógicas, como llamadas API, y también cuentan con protocolos y canales para una transmisión de datos segura y eficiente.
Ejemplos de flujo de datos
Según cómo tu organización gestione tu canal de datos, existen algunas formas comunes de manejar el flujo de datos. Un proceso de extracción, transformación y carga (ETL) organiza, prepara y centraliza datos de varias fuentes para hacerlos accesibles y utilizables para análisis, informes y toma de decisiones operativas. Al gestionar el flujo de datos desde los sistemas de origen hasta una base de datos o un almacén de datos de destino, la ETL permite la integración y coherencia de los datos, lo cual es esencial para generar información fiable y respaldar estrategias basadas en datos.
- Análisis en tiempo real. Este flujo de datos puede procesar una cantidad infinita de registros de la fuente original y manejar un flujo continuo de datos entrantes. Esto brinda a los usuarios el análisis e información de forma instantánea, que pueden ser útiles para las aplicaciones donde las respuestas oportunas son esenciales, como el monitoreo, el seguimiento, las recomendaciones y cualquier acción automatizada.
- Canalizaciones de datos operativos. Las canalizaciones de datos operativos están diseñadas para manejar datos transaccionales y operativos críticos para las funciones diarias y continuas de una organización. Estas canalizaciones capturan datos de diversas fuentes, como interacciones con clientes, transacciones financieras, movimientos de inventario y lecturas de sensores, y garantizan que estos datos se procesen, actualicen y estén disponibles en todos los sistemas, casi en tiempo real o con baja latencia. El propósito de las canalizaciones de datos operativos es mantener las aplicaciones y bases de datos sincronizadas con el fin de asegurar que las operaciones empresariales puedan funcionar sin problemas y que todos los sistemas reflejen el estado más reciente de los datos.
- Procesamiento por lotes. El procesamiento por lotes en el flujo de datos se refiere al manejo de grandes volúmenes de datos a intervalos programados o después de recopilar datos suficientes para procesarlos de una vez. A diferencia del procesamiento en tiempo real, el procesamiento por lotes no necesita resultados instantáneos, ya que se centra en la eficiencia, la escalabilidad y la precisión del procesamiento al agregar los datos antes de procesarlos. El procesamiento por lotes se suele utilizar para tareas como la elaboración de informes, el análisis histórico y las transformaciones de datos a gran escala, donde no es esencial obtener información inmediata.
Herramientas y tecnologías para el flujo de datos
Un flujo de trabajo ETL es un ejemplo común de flujo de datos. En el procesamiento ETL, los datos se ingieren desde los sistemas fuente y se escriben en un área de preparación. Se transforman según los requisitos para garantizar la calidad de los datos, eliminar los registros duplicados y señalar los datos faltantes, y luego, se escriben en un sistema de destino, como un almacén de datos o un lago de datos.
Los sistemas sólidos de la ETL en tu organización pueden ayudar a optimizar la arquitectura de tus datos en cuanto a rendimiento, latencia, costo y eficiencia operativa. De este modo, obtienes acceso a datos de alta calidad y oportunos que te permiten tomar decisiones precisas.
Dada la gran cantidad y variedad de datos críticos generados por las empresas, comprender el flujo de datos es esencial para una buena ingeniería de datos. Mientras que muchas empresas deben elegir entre el procesamiento por lotes y la transmisión en tiempo real para gestionar sus datos, Databricks ofrece una única API, tanto para los datos por lotes como para la transmisión de datos. Las herramientas como Delta Live Tables ayudan a los usuarios a optimizar el costo en un extremo y la latencia o el rendimiento en el otro extremo al cambiar los modos de procesamiento con facilidad. Esto puede ayudar a los usuarios a preparar sus soluciones para el futuro, ya que les permite migrar fácilmente a la transmisión de datos a medida que evolucionan las necesidades empresariales.
La guía de IA agéntica para la empresa

Creación de diagramas de flujo de datos
Una de las formas en que las organizaciones ilustran el flujo de datos a través del sistema es mediante la creación de un diagrama de flujo de datos (DFD). Se trata de una representación gráfica que muestra cómo se recopila, procesa, almacena y utiliza la información, lo que establece el flujo direccional de datos entre las diferentes partes del sistema. El tipo de flujo de datos que necesites crear depende de la complejidad de tu arquitectura de datos, ya que puede ser tan simple como una visión general del flujo de datos o un DFD multinivel más profundo que describe cómo se manejan los datos en diferentes etapas del ciclo de vida.
Los DFD han evolucionado con el tiempo y, en la actualidad, Delta Live Tables utiliza grafos acíclicos dirigidos (DAG) para representar la secuencia de transformaciones de datos y las dependencias entre tablas o vistas dentro de un proceso. Cada transformación o tabla es un nodo, y los bordes entre los nodos definen el flujo de datos y las dependencias. Esto asegura que las operaciones se ejecuten en el orden correcto y en un bucle cerrado direccionalmente.
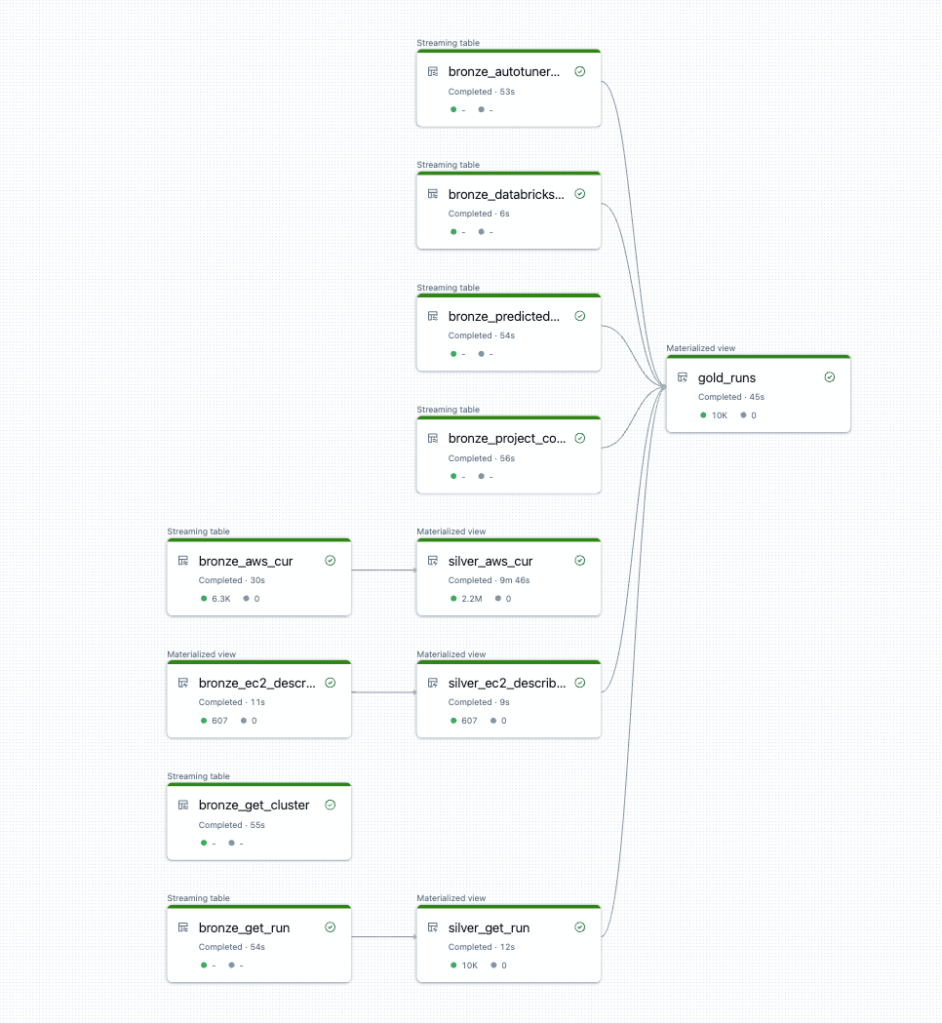
Los DAG ofrecen claridad visual para comprender las relaciones entre las tareas y también pueden ayudar a identificar y gestionar errores o fallas en el sistema de flujo de datos. Delta Live Tables garantiza que el DAG se gestione de manera eficiente, al programar y optimizar las operaciones como la carga de datos, las transformaciones y las actualizaciones, y así mantener la coherencia y el rendimiento.
Mejores prácticas para la gestión del flujo de datos
Se deben seguir algunas prácticas recomendadas para garantizar que el flujo de datos sea óptimo, eficiente y seguro:
- Optimiza el proceso de datos. Esto implica optimizar el flujo de datos para eliminar cuellos de botella, reducir la redundancia y permitir el procesamiento en tiempo real. Revisar y perfeccionar periódicamente los flujos de trabajo garantiza que los datos fluyan por el sistema sin complejidades innecesarias, lo que reduce el consumo de recursos y mejora la escalabilidad.
- Asegura un flujo de información fluido. Para lograr un flujo de información fluido, es importante minimizar los silos de datos y priorizar la interoperabilidad entre sistemas. Al implementar pipelines ETL estrictos, las organizaciones pueden aprovechar datos consistentes entre diversas aplicaciones, departamentos y usos. Esto también implica crear procesos fiables de respaldo y recuperación para proteger contra fallos o cortes del sistema.
- Consideraciones de seguridad. Por supuesto que es primordial garantizar la seguridad de tus datos en su flujo. Todos los datos, especialmente la información sensible o de identificación personal, deben cifrarse mientras se transfieren o almacenan. Limitar el acceso a los datos puede ayudar a reducir el riesgo de exposición no autorizada de datos, y realizar auditorías de seguridad y evaluaciones de vulnerabilidades con regularidad puede identificar posibles puntos débiles, lo que permite tomar medidas proactivas para asegurar el flujo de datos de extremo a extremo.
- Monitoreo del rendimiento. El uso de herramientas de análisis para realizar un seguimiento de métricas como la latencia, las velocidades de transferencia de datos y las tasas de error puede identificar áreas donde el flujo de datos puede demorarse o tener problemas. La configuración de alertas y paneles automatizados garantiza que los equipos estén informados inmediatamente de cualquier problema, lo que permite una resolución rápida y una interrupción mínima. Las evaluaciones periódicas de desempeño también pueden aportar información útil y asegurar un proceso de gestión sólido, seguro y eficiente.
Ventajas de un flujo de datos eficiente
Un flujo de datos eficiente puede marcar una diferencia sustancial en los resultados de tu organización. Al optimizar el flujo de datos rápido y sin interrupciones entre sistemas y departamentos, puedes agilizar los flujos de trabajo, mejorar la productividad y reducir el tiempo necesario para procesar la información.
Para obtener más información sobre cómo Databricks puede ayudar a tu organización a lograr un flujo de datos óptimo, revisa algunas de nuestras arquitecturas de referencia de lakehouse. Además, obtén más información sobre nuestra arquitectura de medallón, que es un patrón de diseño de datos que se utiliza para organizar lógicamente los datos en un lakehouse.
Si deseas obtener más información sobre cómo Delta Live Tables puede preparar a tu organización para manejar datos tanto por lotes como en tiempo real, comunícate con un representante de Databricks.
Lo fundamental es que un flujo de datos eficiente puede ayudar a tu organización a tomar decisiones informadas que respondan a desafíos operativos o de clientes. Cuando tienes acceso inmediato a los datos, puedes tomar decisiones en tiempo real con la información más actualizada. Y con flujos de datos eficientes, puedes asegurarte de que la información es consistente y fiable.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.