¿Qué es LLMOps?
Prácticas y herramientas para desarrollar, implementar y gestionar LLM en producción, abordando el ajuste fino, la ingeniería rápida, la evaluación y la gobernanza de la IA.
- Aborda flujos de trabajo específicos de LLM, incluyendo la selección de modelos básicos, estrategias de ajuste fino (ajuste fino completo, PEFT, LoRA), ingeniería rápida, pipelines de generación aumentada por recuperación (RAG) y orquestación de conjuntos multimodelo.
- Implementa marcos de evaluación que miden el rendimiento del modelo mediante métricas (perplejidad, BLEU, ROUGE, retroalimentación humana), pruebas A/B, trabajo en equipo rojo para seguridad, detección de sesgos y optimización rápida mediante experimentación sistemática.
- Supervisa las implementaciones de producción, rastreando la latencia de inferencia, los costos de consumo de tokens, la desviación de la calidad de salida, las puntuaciones de toxicidad y la satisfacción del usuario, a la vez que gestiona el control de versiones del modelo, las capacidades de reversión y el cumplimiento de las políticas de gobernanza de IA.

¿Qué es LLMOps?
Las operaciones de modelos de lenguaje grande (LLMOps) abarcan las prácticas, técnicas y herramientas que se usan para la gestión operativa de modelos de lenguaje grande en entornos de producción.
Los últimos avances en LLM, destacados por lanzamientos como GPT de OpenAI, Bard de Google y Dolly de Databricks, están impulsando un crecimiento significativo en las empresas que desarrollan e implementan LLM. Eso condujo a la necesidad de construir mejores prácticas sobre cómo operacionalizar estos modelos. LLMOps permite el despliegue, monitoreo y mantenimiento eficientes de modelos de lenguaje grande. LLMOps, al igual que las operaciones tradicionales de aprendizaje automático (MLOps), requieren la colaboración de científicos de datos, ingenieros de DevOps y profesionales de TI. Puedes aprender a construir tu propio LLM con nosotros aquí.
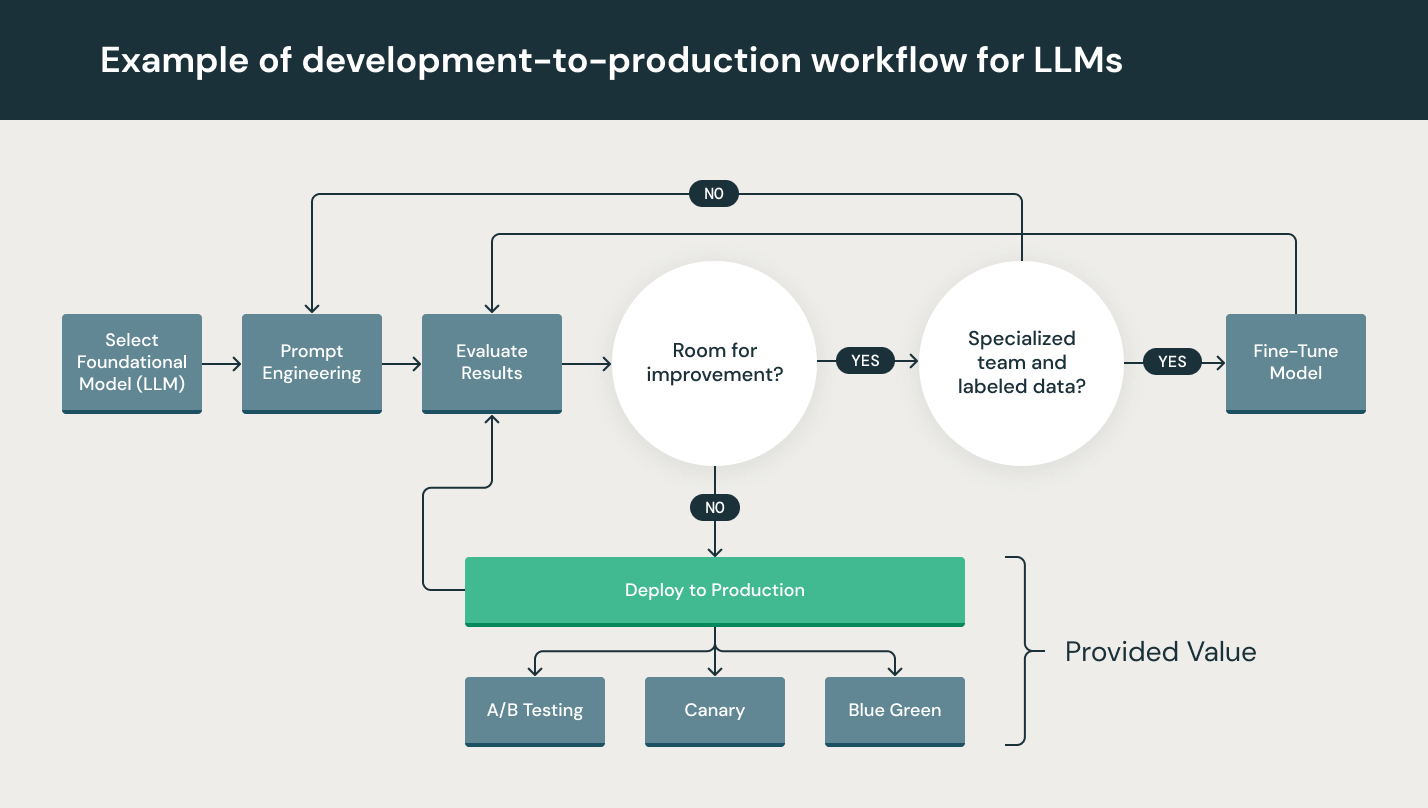
Los modelos de lenguaje grande (LLM) son una nueva clase de modelos de procesamiento de lenguaje natural (PLN) que superaron con creces los avances anteriores en una variedad de tareas, desde la respuesta abierta a preguntas hasta la síntesis y el seguimiento de instrucciones casi arbitrarias. Los requisitos operativos de MLOps suelen aplicarse también a LLMOps, pero existen desafíos en el entrenamiento y el despliegue de LLM que requieren un enfoque único para LLMOps.

¿Cómo se diferencia LLMOps de MLOps?
Con el propósito de ajustar las prácticas de MLOps, debemos considerar cómo cambian los flujos de trabajo y requisitos de aprendizaje automático (ML) con los LLM. Entre las consideraciones clave se incluyen las siguientes:
- Recursos de cómputo: el entrenamiento y el ajuste preciso de modelos de lenguaje grande generalmente implica realizar órdenes de magnitud más cálculos en grandes conjuntos de datos. Para acelerar este proceso, se usa hardware especializado, como GPU, que permite realizar operaciones paralelas con datos mucho más rápido. Tener acceso a estos recursos de cómputo especializados se vuelve esencial tanto para el entrenamiento como para el despliegue de modelos de lenguaje grande. El costo de la inferencia también puede hacer que las técnicas de compresión y destilación de modelos sean importantes.
- Aprendizaje por transferencia: a diferencia de muchos modelos tradicionales de ML que se crean o entrenan desde cero, muchos modelos de lenguaje grande parten de un modelo básico y se ajustan con nuevos datos para mejorar el rendimiento en un dominio más específico. El ajuste preciso permite un rendimiento de última generación para aplicaciones específicas empleando menos datos y menos recursos de cálculo.
- Retroalimentación humana: Una de las principales mejoras en el entrenamiento de modelos de lenguaje grandes se ha logrado gracias al aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF). De forma más general, dado que las tareas de los LLM suelen ser muy abiertas, la retroalimentación humana de los usuarios finales de tu aplicación suele ser fundamental para evaluar el rendimiento de los LLM. La integración de este bucle de retroalimentación en sus procesos de LLMOps simplifica la evaluación y proporciona datos para el futuro ajuste de su LLM.
- Ajuste de hiperparámetros: en el ML clásico, el ajuste de hiperparámetros a menudo se centra en mejorar la precisión u otras métricas. Para los LLM, el ajuste también es importante para reducir los costos y los requisitos de potencia de cómputo del entrenamiento y la inferencia. Por ejemplo, ajustar el tamaño de los lotes y las tasas de aprendizaje puede cambiar significativamente la velocidad y el costo del entrenamiento. Así, tanto los modelos clásicos de ML como los LLM se benefician del seguimiento y la optimización del proceso de ajuste, pero con diferentes énfasis.
- Métricas de rendimiento: los modelos tradicionales de ML tienen métricas de rendimiento muy claramente definidas, tales como la exactitud, el AUC, el puntaje F1, etc. Estas métricas son bastante sencillas de calcular. Sin embargo, cuando se trata de evaluar LLM (modelos de lenguaje grande), se aplica un conjunto completamente diferente de métricas y puntuaciones estándar, como Bilingual Evaluation Understudy (BLEU) y Recall-Oriented Understudy for Gisting Evaluation (ROUGE), que requieren una consideración adicional al implementarlas.
- Ingeniería de prompts: Los modelos que siguen instrucciones pueden aceptar prompts complejos o conjuntos de instrucciones. La ingeniería de estas plantillas de prompts es fundamental para obtener respuestas precisas y fiables de los LLMs. La ingeniería de prompts puede reducir el riesgo de alucinaciones en los modelos y el hackeo de prompts, incluyendo la inyección de prompts, la filtración de datos confidenciales y el jailbreaking.
- Construcción de cadenas o pipelines de LLM: los pipelines de LLM, creados con herramientas como LangChain o LlamaIndex, encadenan múltiples llamadas a LLM o llamadas a sistemas externos, como bases de datos vectoriales o búsquedas web. Estos pipelines permiten que los LLM se utilicen para tareas complejas como preguntas y respuestas de bases de conocimiento, o para responder preguntas de los usuarios basadas en un conjunto de documentos. El desarrollo de aplicaciones LLM a menudo se enfoca en construir estos pipelines, en lugar de construir nuevos LLM.
¿Por qué necesitamos LLMOps?
Aunque los LLM son particularmente fáciles de usar en la creación de prototipos, su uso en un producto comercial sigue presentando desafíos. El ciclo de vida del desarrollo de LLM consta de muchos componentes complejos como la ingesta de datos, la preparación de datos, la ingeniería de indicaciones, el ajuste fino del modelo, la implementación del modelo, el monitoreo del modelo y mucho más. También requiere colaboración y entregas entre equipos, desde ingeniería de datos hasta ciencia de datos e ingeniería de ML. Requiere un rigor operativo estricto para mantener todos estos procesos sincronizados y trabajando juntos. LLMOps abarca la experimentación, iteración, implementación y mejora continua del ciclo de vida de desarrollo de LLM.
¿Cuáles son los beneficios de LLMOps?
Los principales beneficios de LLMOps son la eficiencia, la escalabilidad y la reducción de riesgos.
- Eficiencia: LLMOps permite a los equipos de datos lograr un desarrollo más rápido de modelos y pipelines, ofrecer modelos de mayor calidad e implementar en producción con mayor rapidez.
- Escalabilidad: LLMOps también permite una vasta escalabilidad y gestión donde miles de modelos pueden ser supervisados, controlados, administrados y monitoreados para integración continua, entrega continua y despliegue continuo. Específicamente, LLMOps proporciona reproducibilidad de los pipelines de LLM, lo que permite una colaboración más estrechamente acoplada entre equipos de datos, y reduce conflictos con DevOps y TI, y acelera la velocidad de lanzamiento.
- Reducción de riesgos: los LLM suelen necesitar un escrutinio regulatorio, y LLMOps permite una mayor transparencia y una respuesta más rápida a este tipo de solicitudes, además de garantizar un mayor cumplimiento con las políticas de una organización o sector.
La guía de IA agéntica para la empresa

¿Cuáles son los componentes de LLMOps?
El alcance de LLMOps en proyectos de aprendizaje automático puede ser tan enfocado o amplio como lo requiera el proyecto. En ciertos casos, LLMOps puede abarcar todo, desde la preparación de datos hasta la producción de canalizaciones, mientras que otros proyectos pueden requerir únicamente la implementación del proceso de despliegue del modelo. La mayoría de las empresas aplican los principios de LLMOps en los siguientes ámbitos:
- Análisis exploratorio de datos (EDA)
- Preparación de datos e ingeniería de indicaciones
- Ajuste preciso del modelo
- Revisión y gobernanza de modelos
- Inferencia y servicio de modelos
- Monitoreo de modelos con feedback humano
¿Cuáles son las mejores prácticas para LLMOps?
Las mejores prácticas para LLMOps pueden delinearse por la etapa en la que se están aplicando los principios de LLMOps.
- Análisis exploratorio de datos (EDA): explora, comparte y prepara iterativamente los datos para el ciclo de vida del aprendizaje automático, al crear conjuntos de datos, tablas y visualizaciones reproducibles, editables y compartibles.
- Preparación de datos e ingeniería de indicaciones: transforma, agrega y deduplica datos iterativamente, y haz que los datos sean visibles y compartibles entre los equipos de datos. Desarrolla indicaciones de forma iterativa para consultas estructuradas y confiables a los LLM.
- Ajuste preciso del modelo: usa bibliotecas de código abierto populares, como Hugging Face Transformers, DeepSpeed, PyTorch, TensorFlow y JAX, para perfeccionar y mejorar el rendimiento del modelo.
- Revisión y gobierno del modelo: realiza un seguimiento del linaje y las versiones del modelo y del pipeline, y administra esos artefactos y transiciones a lo largo de tu ciclo de vida. Descubre, comparte y colabora en modelos de ML con la ayuda de una plataforma MLOps de código abierto como MLflow.
- Inferencia y servicio de modelos: administre la frecuencia de actualización del modelo, los tiempos de solicitud de inferencia y especificaciones de producción similares en pruebas y control de calidad. Utiliza herramientas de CI/CD como repositorios y orquestadores (tomando prestados los principios de DevOps) para automatizar el pipeline de preproducción. Habilitar los endpoints del modelo de API REST, con aceleración por GPU.
- Monitoreo de modelos con feedback humano: crea procesos de monitoreo de modelos y datos con alertas tanto para la desviación de modelos como para el comportamiento malicioso de los usuarios.
¿Qué es una plataforma de LLMOps?
Una plataforma LLMOps proporciona a científicos de datos e ingenieros de software un entorno colaborativo que facilita la exploración iterativa de datos, capacidades de trabajo conjunto en tiempo real para el seguimiento de experimentos, la ingeniería de indicaciones y la gestión de modelos y pipelines, así como la transición, el despliegue y el monitoreo controlado de modelos para LLM. LLMOps automatiza los aspectos operativos, de sincronización y de supervisión del ciclo de vida del aprendizaje automático.
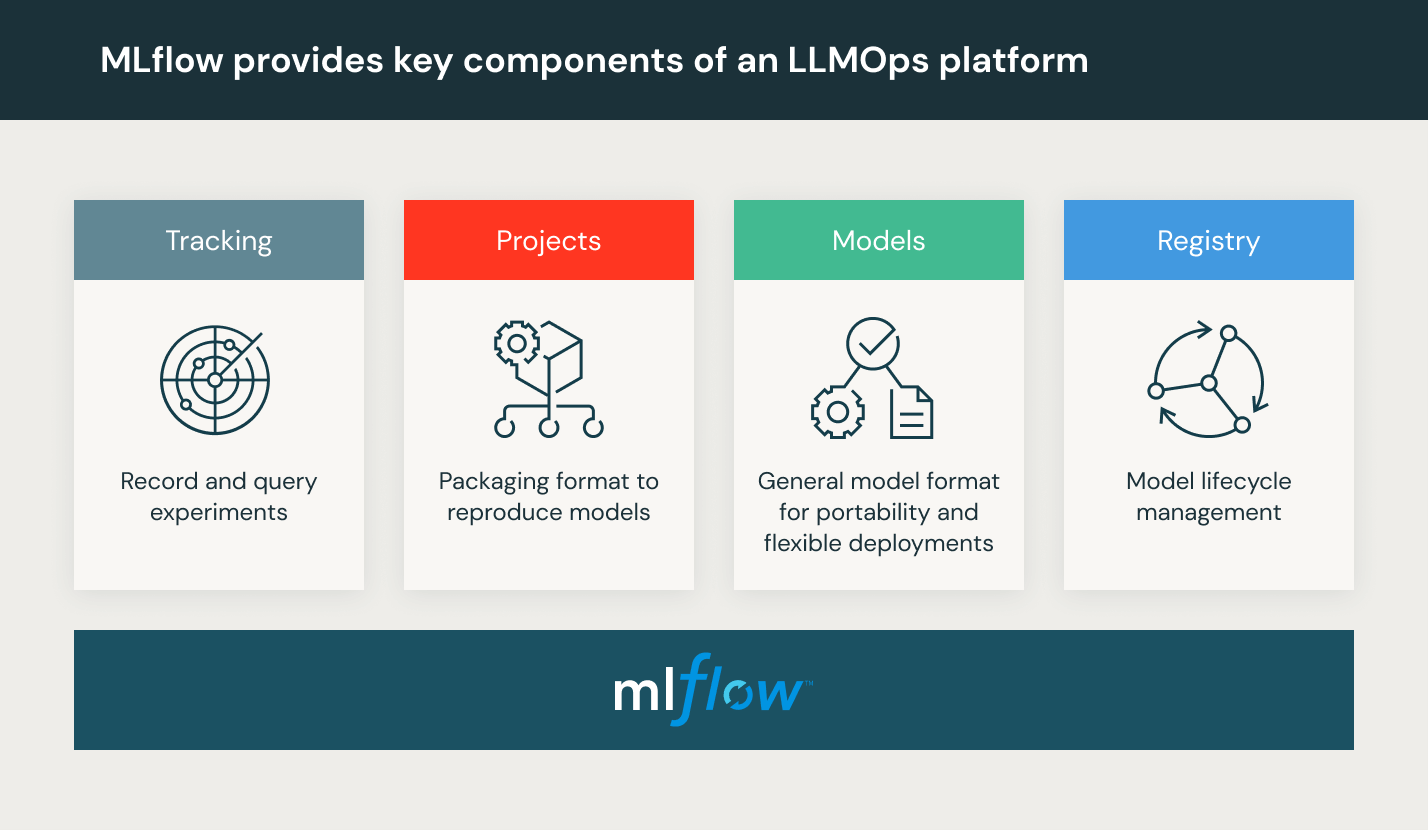
Databricks proporciona un entorno totalmente administrado que incluye MLflow, la plataforma MLOps abierta líder en el mundo. Prueba Databricks Machine Learning
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.