¿Qué es una plataforma de funciones?
Infraestructura para la gestión del ciclo de vida de las funciones, que incluye ingeniería, almacenamiento, descubrimiento, supervisión y gobernanza con API para la creación y el servicio.
- Los componentes incluyen herramientas de creación de características para definir transformaciones, sistemas de orquestación que programan canales de cálculo, capas de almacenamiento para características en línea y fuera de línea, API de servicio para acceso en tiempo real y paneles de monitoreo que monitorean la calidad.
- Admite el cálculo de características por lotes para el entrenamiento de modelos, la transmisión de actualizaciones de características para sistemas en tiempo real, el cálculo de características bajo demanda durante la inferencia y el reabastecimiento de características para experimentos históricos.
- Las capacidades avanzadas abarcan la validación de características para garantizar la calidad, las pruebas automatizadas para canales de características, la infraestructura de pruebas A/B para experimentos de características y la integración con plataformas de aprendizaje automático (ML) para flujos de trabajo de desarrollo de modelos fluidos.
Hasta hace dos años, solo las grandes empresas tecnológicas tenían los recursos y la experiencia necesarios para crear productos que dependieran por completo de los sistemas de aprendizaje automático. Piensa en Google gestionando las subastas de anuncios, TikTok recomendando contenido y Uber ajustando dinámicamente los precios. Para impulsar sus aplicaciones más críticas con aprendizaje automático, estos equipos crearon una infraestructura personalizada que satisfacía las necesidades únicas de la implementación de los sistemas de aprendizaje automático.
Con el paso de los años, ha surgido todo un ecosistema de herramientas de MLOps para democratizar el aprendizaje automático en producción. Pero al tener cientos de herramientas diferentes, entender qué hace cada una es ahora un trabajo a tiempo completo. Las plataformas de características y sus equivalentes, los almacenes de características, son una parte popular de ese ecosistema. En pocas palabras, una plataforma de características habilita su infraestructura de datos existente (almacenes de datos, infraestructura de transmisión como Kafka, procesadores de datos como Spark/Flink, etc.) para aplicaciones operativas de ML. Esta publicación explica con más detalle qué son las plataformas de características y qué problemas resuelven.
Dificultad en el desarrollo del aprendizaje automático operativo
Las plataformas de características permiten el aprendizaje automático (ML) operativo, que ocurre cuando una aplicación orientada al cliente utiliza ML de manera autónoma y continua para tomar decisiones que impactan el negocio en tiempo real. Los ejemplos que compartí de Google, TikTok y Uber son todos aplicaciones operativas de ML. Cualquier proyecto de aprendizaje automático consta siempre de cuatro etapas:
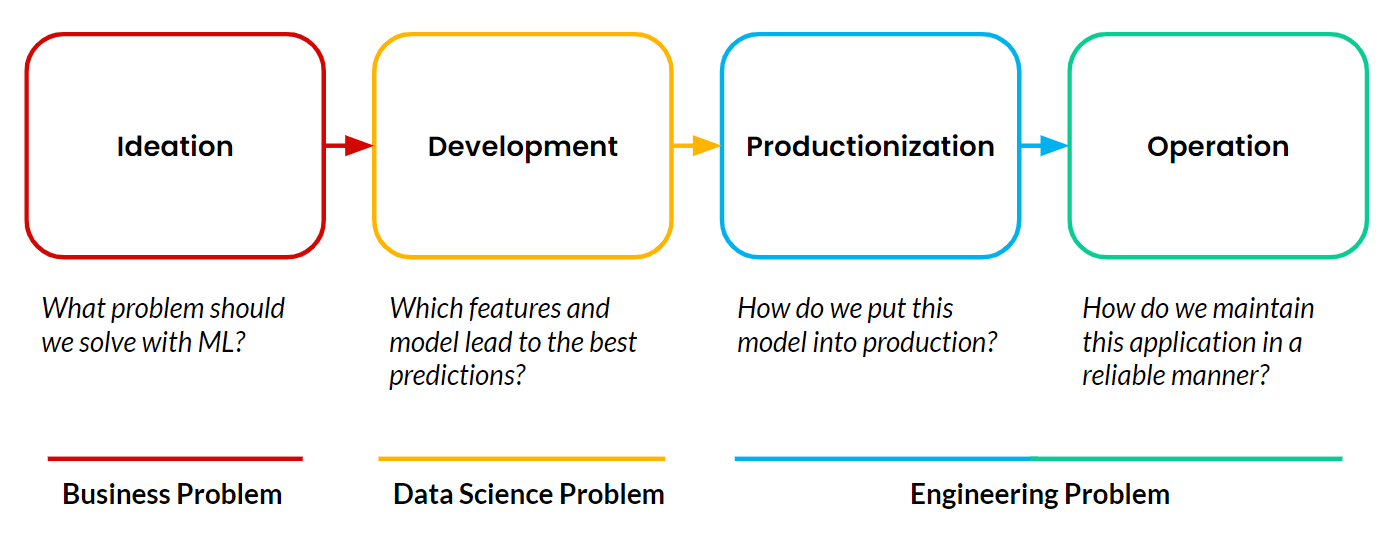
La mayoría de los proyectos nunca pasan de la etapa de desarrollo. La producción y el funcionamiento de las aplicaciones de aprendizaje automático siguen siendo el principal obstáculo para los equipos. Y la parte más difícil de producir y operar ML es gestionar las canalizaciones de datos que necesitan alimentar estas aplicaciones continuamente.
Una plataforma de características resuelve los desafíos de datos que se asocian con la producción y la operación. Crea un camino hacia la producción. Entraremos en el detalle de lo que esto significa, pero primero describamos qué es una característica.
¿Qué es una característica del aprendizaje automático?
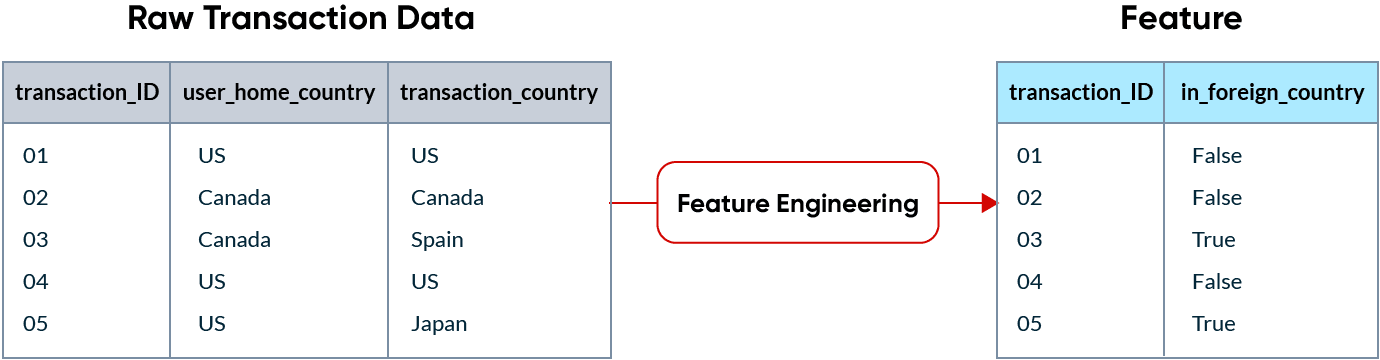
En el aprendizaje automático, una característica es el dato que se utiliza como entrada para que los modelos de ML realicen predicciones. Los datos sin procesar rara vez se encuentran en un formato que sea utilizable por un modelo de ML, por lo que es necesario transformarlos en características. Este proceso se denomina ingeniería de características.
Por ejemplo, si una empresa de tarjetas de crédito está tratando de detectar transacciones fraudulentas, una transacción realizada en un país extranjero podría ser un buen indicador de fraude. Las características terminan siendo columnas en los datos que se envían a un modelo.
Lo que es único del ML es que las características se consumen de dos maneras diferentes:
- Para entrenar un modelo, necesitamos grandes cantidades de datos históricos.
- Para realizar una predicción en tiempo real, solo necesitamos proporcionar las últimas características al modelo, pero debemos proporcionar esa información en milisegundos. Esto también se llama inferencia en línea. En este ejemplo, el modelo solo necesita saber si la transacción actual se realiza en un país extranjero o no, y debe procesar esa información mientras ocurre la transacción.
¿Qué problemas resuelve una plataforma de características?
En la etapa de desarrollo de un proyecto de aprendizaje automático, los científicos de datos realizan grandes cantidades de ingeniería de características para encontrar aquellas que conducen a la mayor precisión de predicción. Una vez que se completa ese proceso, generalmente entregan el proyecto a un colega ingeniero que pondrá esas canalizaciones de ingeniería de características en producción.
Si eres un científico de datos, no quieres preocuparte por cómo se disponen los datos ni cómo se calculan. Sabes qué características quieres y deseas que esas características estén disponibles para que el modelo realice predicciones en tiempo real. Los ingenieros, por su parte, necesitan volver a implementar esas canalizaciones de datos en un entorno de producción, lo que rápidamente se vuelve muy complejo en cuanto hay datos en tiempo real o casi en tiempo real. Para potenciar las aplicaciones operacionales de ML, estas canalizaciones se deben ejecutar de manera continua, no pueden romperse, deben ser extremadamente rápidas y deben escalar con el negocio.
La reimplementación de canalizaciones de datos en un entorno de producción es el principal obstáculo para los proyectos operativos de aprendizaje automático. Volviendo al ejemplo de detección de fraude, las características realistas que implementarán las empresas son:
- La distancia entre la ubicación de origen del usuario y la ubicación donde se realiza la transacción, calculada a medida que la transacción se realiza.
- Si el importe de la transacción actual es más de una desviación estándar superior al promedio histórico en ese establecimiento comercial.
- La cantidad de transacciones de un usuario en los últimos 30 minutos, que se actualizan cada segundo.
Estas canalizaciones de ingeniería de características son difíciles de implementar. No se pueden calcular directamente en un almacén de datos y requieren configurar una infraestructura de transmisión para procesar datos en tiempo real. Una plataforma de características resuelve los desafíos de ingeniería que supone poner estas características en producción y, al hacerlo, facilita el camino hacia la producción. En concreto, una plataforma de características:
- Orquesta y ejecuta continuamente canales de datos para calcular características y ponerlas a disposición para el entrenamiento fuera de línea y la inferencia en línea.
- Gestiona las características como código, lo que permite a los equipos realizar revisiones de código, control de versiones e integrar cambios de características en canalizaciones de CI/CD.
- Crea una biblioteca de características al estandarizar las definiciones de características y permitir que los científicos de datos compartan y descubran características entre equipos.
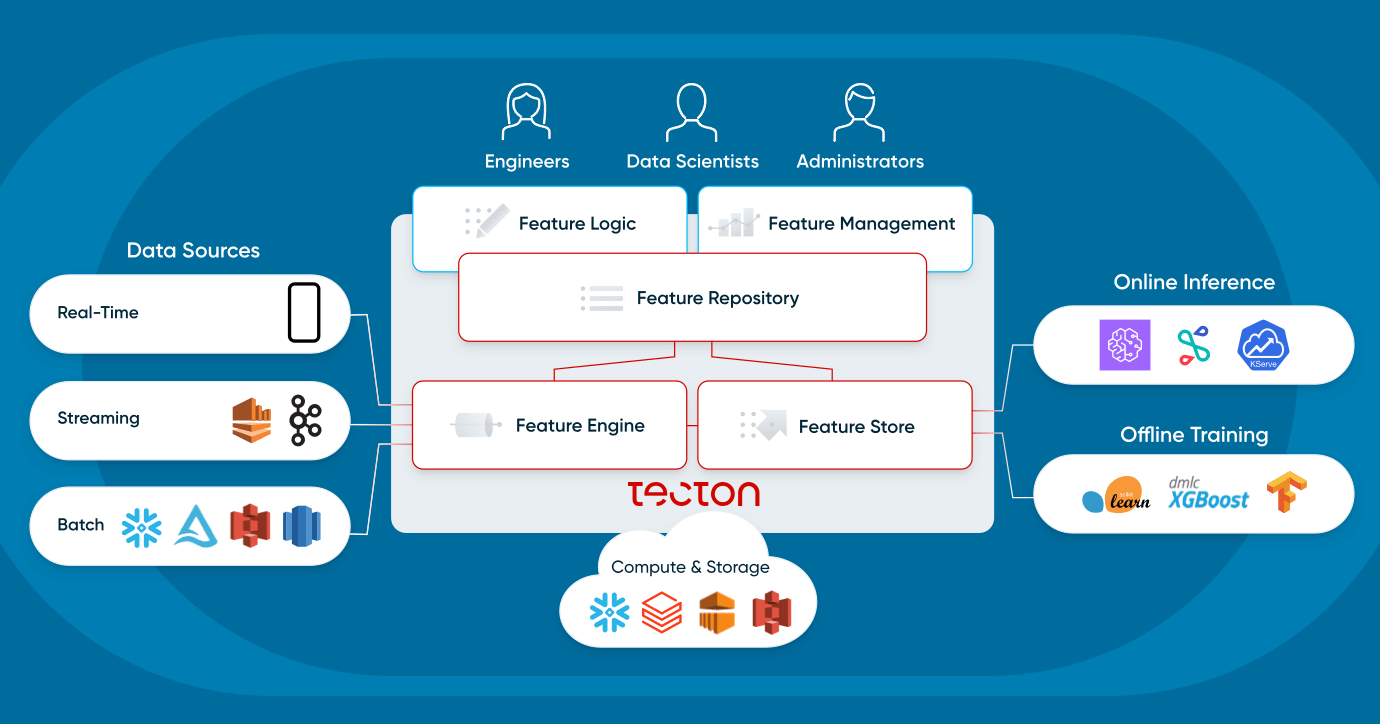
Profundicemos en cómo interactúan los usuarios con una plataforma de características y cuáles son sus componentes.
La guía de IA agéntica para la empresa

¿Qué es una plataforma de características?
Una plataforma de características es un sistema que orquesta la infraestructura de datos existente para transformar, almacenar y servir datos de manera continua para aplicaciones de aprendizaje automático operativo.
Hay dos formas principales en las que los usuarios interactúan con una plataforma de características:
- Creación y descubrimiento de características
- Los usuarios definen características nuevas como código en archivos Python con un marco declarativo. Las definiciones de características se gestionan en un repositorio git.
- Los usuarios descubren las características existentes que definieron los otros equipos.
- Recuperación de características
- Durante el entrenamiento, los usuarios pueden acceder a la plataforma de características desde una notebook para obtener todos los datos históricos que necesitan para entrenar un modelo. Esto se puede hacer con una llamada como get_historical_features(fraud_model). La plataforma de características maneja la complejidad de las funciones de relleno y de realizar uniones puntuales correctas, y el marco de datos resultante lo puede ingerir cualquier herramienta de entrenamiento de modelos, como XGBoost, Scikit-Learn, etc.
- Para el tiempo de inferencia, la plataforma de características expone un endpoint REST al que puede acceder una aplicación en vivo. Devuelve el último vector de características para un ID de entidad dado en milisegundos que el modelo utilizará para realizar una predicción.
Las plataformas de características no reemplazan la infraestructura existente. En cambio, la habilitan para aplicaciones de aprendizaje automático operativo:se conectan a (1) fuentes de datos por lotes, como lagos y almacenes de datos, y (2) fuentes de transmisión, como Kafka. Utilizan (3) la infraestructura informática existente, como un almacén de datos o Spark, y (4) la infraestructura de almacenamiento existente, como S3, DynamoDB o Redis. Una plataforma moderna de características se conecta de manera flexible a la infraestructura de datos existente de una organización.
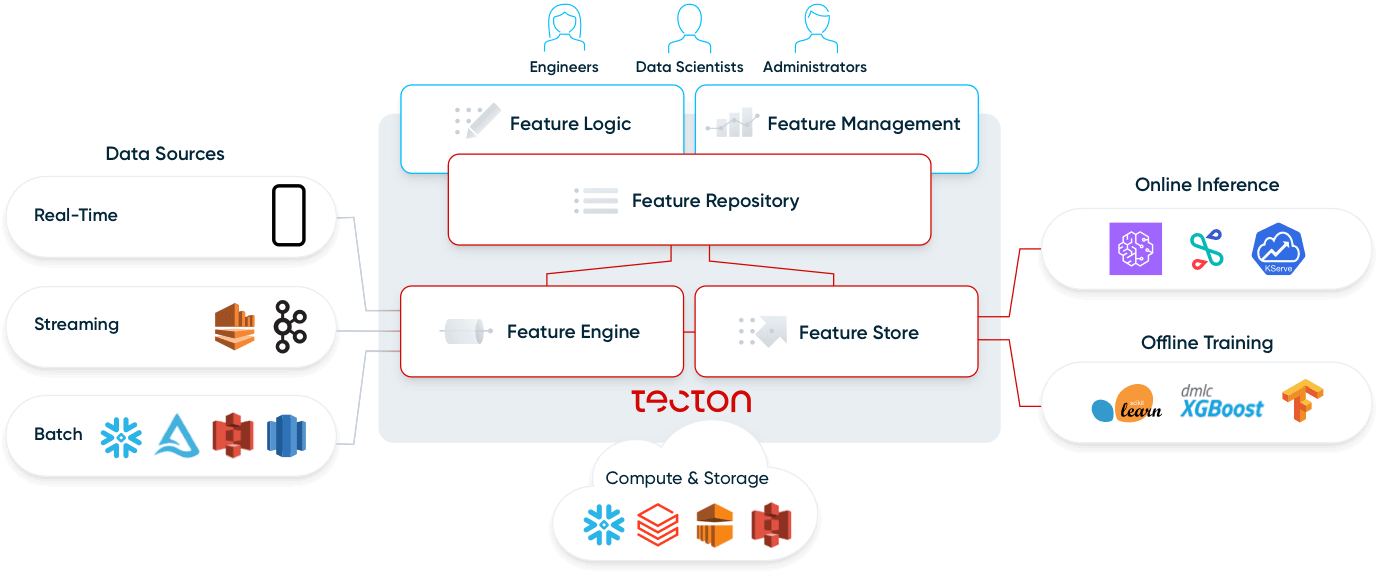
Vamos a analizar más a fondo los cuatro componentes de una plataforma de características: repositorio de características, canalizaciones de características, almacén de características y monitorización.
Repositorio de características
Muchos científicos de datos realizan su ingeniería de características en notebooks. Son interactivos, fáciles de usar y conducen a ciclos de desarrollo rápidos. El problema aparece cuando esas características deben incorporarse a la producción; es imposible integrarlas en los procesos de CI/CD y disponer de los controles que utilizamos con el software tradicional.
Los equipos que despliegan aplicaciones operativas de ML con éxito gestionan sus características como activos de código. Esto brinda todos los beneficios de DevOps. Permite a los equipos realizar revisiones de código, rastrear linaje e integrarse en canalizaciones de CI/CD, lo que da como resultado que los equipos envíen cambios de manera más rápida y confiable. Un síntoma común de los equipos que no gestionan las características como código es que a menudo no pueden iterar más allá de la primera versión de un modelo.
En una plataforma de características, los usuarios definen las características como código mediante una interfaz declarativa que contiene tres elementos:
- Configuración sobre la frecuencia con la que se debe calcular la característica.
- Metadatos, como el nombre y la descripción de la característica, para permitir el uso compartido y la capacidad de descubrimiento.
- Lógica de transformación, definida en SQL o Python.
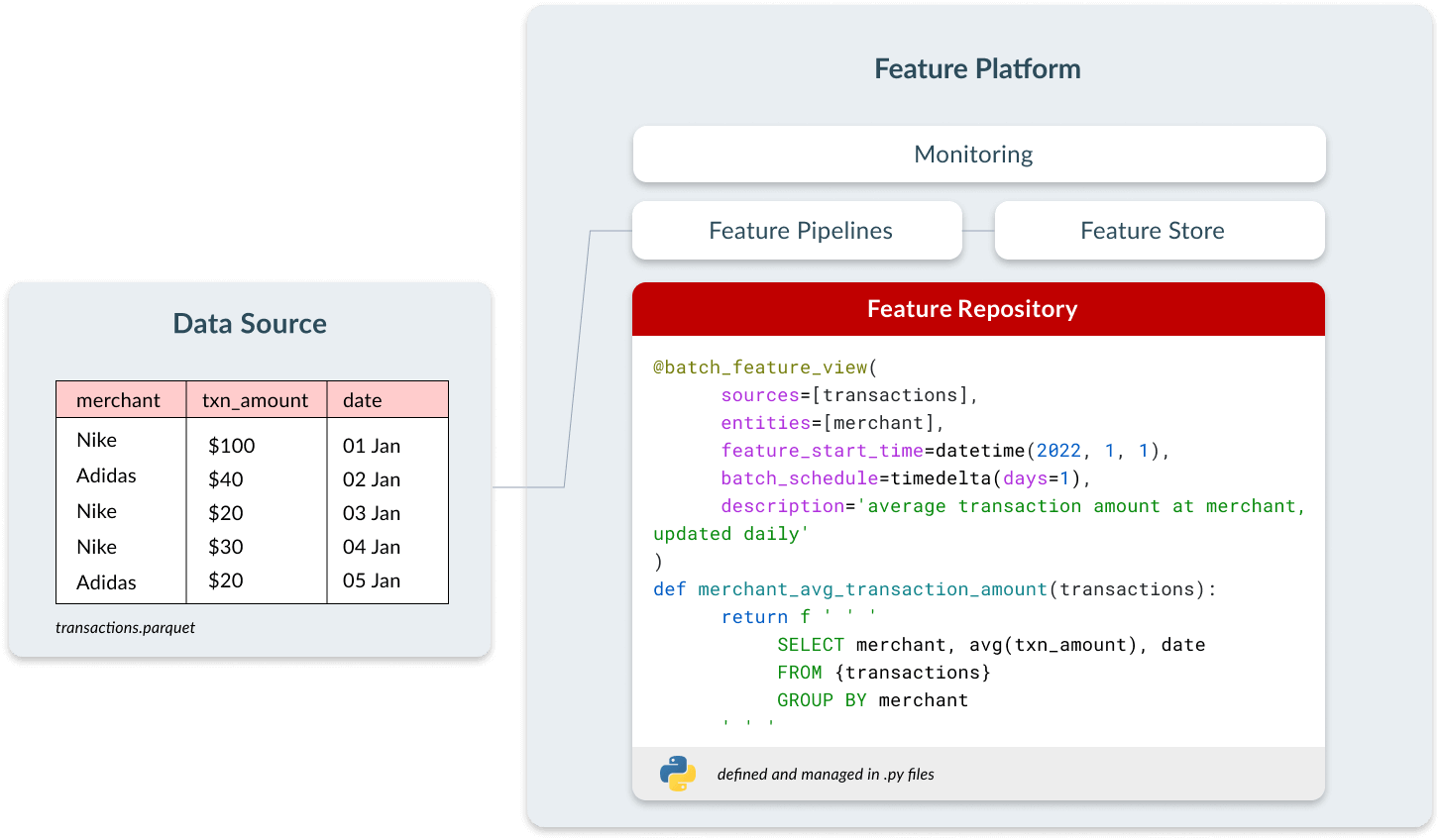
Estas características están disponibles de forma centralizada para que todos los equipos las descubran y utilicen en sus propios modelos. Esto ahorra tiempo de desarrollo, crea consistencia entre equipos y ahorra costos de procesamiento, ya que no es necesario calcular las características varias veces para casos de uso diferentes.
Pipelines de características
Las aplicaciones de aprendizaje automático operativas requieren un procesamiento continuo de datos nuevos para que los modelos puedan realizar predicciones mediante una visión actualizada del mundo. Una vez que un usuario ha definido la característica en el repositorio, la plataforma de características procesará automáticamente las canalizaciones de datos para computar esa característica.
Existen tres tipos de transformaciones de datos que debe admitir una plataforma de características:
| Transformación | Definición | Fuente de datos | Ejemplo |
|---|---|---|---|
| Lote | Transformaciones que se aplican únicamente a datos en reposo | Almacén de datos, lago de datos, base de datos | Importe medio de transacciones por comerciante, actualizado diariamente |
| Streaming | Transformaciones que se aplican a las fuentes de transmisión | Kafka, Kinesis, PubSub, Flink | Cantidad de transacciones de un usuario en los últimos 30 minutos, que se actualizan cada segundo |
| Bajo demanda | Transformaciones que se utilizan para producir características basadas en datos que solo están disponibles en el momento de la predicción. Estas características no se pueden calcular previamente. | Aplicación orientada al usuario, API a servicios RPC, datos en memoria | ¿El monto de la transacción actual es más de dos desviaciones estándar mayor que el monto promedio de la transacción del usuario, calculado al momento de la transacción? |
Estas transformaciones se ejecutan en motores de procesamiento de datos (Spark, Snowflake, Python) a los que está conectada la plataforma de características. La plataforma de características pasa el código de transformación definido por el usuario 1:1 al motor de procesamiento de datos subyacente. Esto significa que la plataforma de características no debe tener su propio dialecto SQL personalizado ni el DSL Python personalizado. Esto simplifica tanto la experiencia de incorporación a la plataforma de características como la experiencia de depuración.
Las transformaciones por lotes son fáciles de ejecutar: se pueden ejecutar a través de una consulta SQL en un almacén de datos o al ejecutar un trabajo de Spark. Sin embargo, las aplicaciones de ML operativas son las que más se benefician de la información nueva a la que solo se puede acceder mediante transmisiones y transformaciones bajo demanda. En el ejemplo de detección de fraudes, las características que permitirán al modelo realizar la mejor predicción contendrán información sobre la transacción actual, como el importe, el comerciante y la ubicación, o información sobre las transacciones que se realizaron en los últimos minutos.
Todos los equipos con los que hablamos coinciden en que tener acceso a datos nuevos mejoraría el rendimiento de la mayoría de sus modelos. La mayoría de las organizaciones siguen utilizando transformaciones por lotes únicamente porque gestionar las transmisiones y las transformaciones bajo demanda es complejo. Una plataforma de características abstrae esa complejidad, lo que permite que un usuario defina la lógica de transformación y seleccione si se debe ejecutar como una transformación por lotes, en transmisión o bajo demanda.
Al iterar en nuevas características en la fase de desarrollo, es necesario rellenar datos para generar conjuntos de datos de entrenamiento. Por ejemplo, hoy podríamos desarrollar una nueva función merchant_fraud_rate, que deberá rellenarse durante toda la ventana de tiempo en la que queremos entrenar el modelo. Las plataformas de características ejecutan estas transformaciones automáticamente al definir nuevas características, lo que permite ciclos de iteración rápidos en el proceso de desarrollo.

Feature Store
Las tiendas de características se volvieron cada vez más populares desde que presentamos el concepto por primera vez con Uber Michelangelo en 2017. Tienen dos funciones: almacenar y ofrecer características de manera coherente en entornos de entrenamiento sin conexión y de inferencia en línea.
Cuando las características no se almacenan de manera consistente en ambos entornos, las características en las que se entrena el modelo pueden tener diferencias sutiles con respecto a las que utiliza para la inferencia en línea. Este fenómeno se denomina sesgo de entrenamiento-servicio y puede descarrilar el rendimiento de un modelo de forma silenciosa y catastrófica, lo que resulta extremadamente difícil de depurar. Al tener datos consistentes en ambos entornos, un almacén de características resuelve este problema.
Para el entrenamiento fuera de línea, los almacenes de características deben contener meses o años de datos. Estos se guardan en almacenes de datos o lagos de datos como S3, BigQuery, Snowflake o Redshift. Estas fuentes de datos están optimizadas para la recuperación a gran escala.
Para la inferencia en línea, las aplicaciones deben tener acceso ultrarrápido a pequeñas cantidades de datos. Para permitir búsquedas de baja latencia, estos datos se guardan en un almacén en línea como DynamoDB, Redis o Cassandra. Solo se guardan en el almacenamiento en línea los valores más recientes de cada entidad.

Para recuperar datos sin conexión, comúnmente se accede a los valores de las características a través de un SDK compatible con notebooks. Para la inferencia en línea, un almacén de características entrega un vector único de características que contiene los datos más actualizados. Si bien la cantidad de datos en cada una de estas solicitudes es pequeña, un almacén de características debe ser capaz de escalar miles de solicitudes por segundo. Estas respuestas se sirven en milisegundos para aplicaciones activas a través de un endpoint REST. Los almacenes de características de alto rendimiento deben proporcionar acuerdos de nivel de servicio (SLA) sobre la disponibilidad y latencia.

Monitoreo
Cuando algo falla en un sistema operativo de ML, normalmente es un problema de datos. Debido a que las plataformas de características gestionan el proceso desde los datos sin procesar hasta los modelos, están en una posición única para detectar los problemas de datos. Hay dos tipos de monitorización que las plataformas de características admiten:
Monitoreo de calidad de datos
Las plataformas de características pueden rastrear la distribución y calidad de los datos entrantes. ¿Hay cambios significativos en la distribución de los datos desde la última vez que entrenamos el modelo? ¿De repente estamos viendo más valores que faltan? ¿Esto afecta el rendimiento del modelo?
Monitorización operativa
Al ejecutar sistemas de producción, también es importante monitorizar las métricas operativas. Las plataformas de características rastrean la estabilidad de las características para detectar si los datos no se actualizan a la velocidad esperada, junto con otras métricas relacionadas con el almacenamiento de características (disponibilidad, capacidad, utilización) y métricas relacionadas con el servicio de características (rendimiento, latencia, consultas por segundo, tasas de error). Una plataforma de características también supervisa que las canalizaciones de características ejecuten trabajos según lo esperado, detecta cuándo los trabajos no tienen éxito y resuelve los problemas automáticamente.
Las plataformas de características ponen estas métricas a disposición de la infraestructura de monitorización existente. Las aplicaciones operativas de ML deben supervisarse como cualquier otra aplicación de producción, que se gestionan con las herramientas de observabilidad existentes.
Reuniendo todo
Parte de la magia de una plataforma de características es que permite a los equipos de ML producir características nuevas con rapidez. Pero la explosión del valor se produce cuando la plataforma de características la utilizan varios equipos y potencia múltiples casos de uso.

Una plataforma de características permite a los ingenieros de datos dar soporte a un mayor número de científicos de datos de lo que podrían hacerlo de otro modo. Hablamos con muchos equipos que necesitaban dos ingenieros de datos para apoyar a un científico de datos sin una plataforma de características. Una plataforma de funciones les permitió superar esa proporción. Una vez que una plataforma de características se adopta ampliamente, los científicos de datos pueden agregar fácilmente características que ya se están calculando en sus modelos. Vimos cómo se repite el mismo patrón: los equipos tardan unos meses en implementar completamente su primer caso de uso, unas semanas para el segundo caso de uso y solo unos días para implementar nuevos casos de uso o iterar sobre los existentes después de eso.
Cuándo (y cuándo no) adoptar una plataforma de características
Empecé este artículo describiendo lo difícil que es mantenerse al día con todo el ecosistema de herramientas MLOPS que surgieron en los últimos años. La realidad es que debes mantener tu stack lo más simple posible y solo adoptar herramientas cuando sean realmente necesarias.
Vemos que los equipos encuentran valor en una plataforma de características cuando:
- Viví el proceso de traspaso entre científicos de datos e ingenieros de datos, así como las dificultades asociadas a la reimplementación de los flujos de datos para la producción.
- Están implementando aplicaciones de aprendizaje automático operativo que deben cumplir con SLA estrictos, alcanzar la escala y no fallar en producción.
- Tener varios equipos que quieran tener definiciones de características estandarizadas y reutilizar características entre modelos.
Los equipos deberán evitar adoptar una plataforma de características cuando:
- Se encuentren en las fases de ideación o desarrollo y no estén listos para enviarse a producción.
- Contar con un solo equipo que trabaje únicamente con datos por lotes.
Cómo empezar
Hay algunas opciones para empezar:
- Tecton es una plataforma de características gestionadas. Incluye todos los componentes descritos anteriormente, y nuestros clientes eligen Tecton porque necesitan SLAs de producción y capacidades empresariales, sin la necesidad de gestionar una solución ellos mismos. Los equipos de ML que van desde startups tecnológicas hasta varias empresas Fortune 500 utilizan Tecton.
- Feast es la tienda de características de código abierto más popular. Es una gran opción si ya tienes canalizaciones de transformación para calcular tus características y si quieres almacenarlas y servirlas en producción. Con el tiempo, Feast seguirá sumando características y capacidades de supervisión que la convertirán en una plataforma completa.
Escribí esta entrada de blog para ofrecer una definición común de plataformas de características tal y como ahora se consolidan como un componente central de la pila para aplicaciones de aprendizaje automático operativo.
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.