Arquitetando um Armazém de Dados de Alta Concorrência e Baixa Latência no Databricks que Escala
Desbloqueie desempenho econômico em escala: insights práticos para construir um moderno armazém de dados no Databricks
por Ben Dunmire, Dan Lueck e Jen Lim
- Unifique o armazenamento de dados, análises e IA com o Databricks - a IA cuida das otimizações para melhor preço/desempenho.
- Ajuste a arquitetura à sua escala, desempenho e metas de custo para maximizar o impacto.
- Forneça armazenamento de dados em nível de produção, com subsegundos, que cresce com o seu negócio.
Implementando Análises de Nível de Produção em um Armazém de Dados Databricks
Armazenamento de dados de alta concorrência e baixa latência é essencial para organizações onde os dados impulsionam decisões de negócios críticas. Isso significa suportar centenas de usuários simultâneos, fornecer desempenho rápido de consultas para análises interativas e permitir insights em tempo real para tomadas de decisões rápidas e informadas. Um armazém de dados em nível de produção é mais do que um sistema de suporte -é um catalisador para o crescimento e a inovação.
A Databricks foi pioneira na arquitetura de lakehouse para unificar dados, análises e cargas de trabalho de IA—eliminando a duplicação de dados dispendiosa e integrações de sistemas complexos. Com otimizações de desempenho autônomas integradas, o lakehouse oferece competitivo preço/desempenho enquanto simplifica as operações. Como um lakehouse aberto, também garante acesso rápido e seguro a dados críticos através do Databricks SQL, alimentando ferramentas de BI, análises e IA com segurança unificada e governança que se estendem por todo o ecossistema. A interoperabilidade aberta é essencial, pois a maioria dos usuários interage com o armazém por meio dessas ferramentas externas. A plataforma escala sem esforço—não apenas com dados e usuários, mas também com a crescente diversidade de ferramentas em que suas equipes confiam—e oferece poderosas capacidades integradas como Databricks AI/BI, Databricks e mais, mantendo a flexibilidade e interoperabilidade com seu ecossistema existente.
Este blog fornece um guia abrangente para organizações em qualquer estágio de sua jornada de arquitetura de lakehouse - desde o design inicial até a implementação intermediária e otimização contínua - sobre como maximizar o desempenho de alta concorrência e baixa latência com a Plataforma de Inteligência de Dados Databricks. Vamos explorar:
- Componentes arquitetônicos principais de um armazém de dados e seu impacto coletivo no desempenho da plataforma.
- Um framework estruturado de ajuste de desempenho para orientar a otimização desses elementos arquitetônicos.
- Melhores práticas, estratégias de monitoramento e metodologias de ajuste para garantir desempenho sustentado em escala.
- Um estudo de caso do mundo real demonstrando como esses princípios funcionam juntos na prática.
Considerações Arquitetônicas Chave
Embora muitos princípios fundamentais dos tradicionais armazéns de dados ainda se apliquem - como modelagem de dados sólida, robusta gestão de dados e qualidade de dados incorporada - projetar um moderno lakehouse para análises de produção requer uma abordagem mais holística. Central para isso é um framework unificado de governança, e o Unity Catalog (AWS | Azure | GCP) desempenha um papel crítico em sua entrega. Ao padronizar controles de acesso, rastreamento de linhagem e auditabilidade em todos os dados e ativos de IA, o Unity Catalog garante uma governança consistente em escala - algo cada vez mais essencial à medida que as organizações crescem em volume de dados, concorrência de usuários e complexidade da plataforma.
Um design eficaz requer:
- Adoção das melhores práticas arquitetônicas comprovadas
- Uma compreensão das compensações entre componentes interconectados
- Objetivos claros para concorrência, latência e escala com base nos requisitos de negócios
Em um lakehouse, os resultados de desempenho são influenciados pelas escolhas arquitetônicas feitas no início da fase de design. Essas decisões de design deliberadas destacam como os lakehouses modernos representam uma mudança fundamental em relação aos armazéns de dados legados em cinco eixos críticos:

Com essas considerações arquitetônicas em mente, vamos explorar um framework prático para implementar um armazém de dados de nível de produção que pode cumprir a promessa de alta concorrência e baixa latência em escala.
Descrição Técnica da Solução
O seguinte framework destila as melhores práticas e princípios arquitetônicos desenvolvidos através de engajamentos no mundo real com clientes corporativos. Se você está construindo um novo armazém de dados, migrando de uma plataforma legada ou ajustando um lakehouse existente, essas diretrizes ajudarão a acelerar o tempo de produção, ao mesmo tempo que fornecem resultados escaláveis, eficientes e de baixo custo.
Comece com uma Avaliação Orientada por Caso de Uso
Antes de implementar, recomendamos uma avaliação rápida de uma carga de trabalho crítica - geralmente seu painel mais lento ou pipeline mais intensivo em recursos. Essa abordagem ajuda você a identificar lacunas de desempenho e priorizar áreas para otimização.
Faça as seguintes perguntas para estruturar sua análise:
- Quais métricas de desempenho são mais importantes (por exemplo, latência de consulta, taxa de transferência, concorrência) e como elas se comparam às expectativas do negócio?
- Quem usa essa carga de trabalho, quando e com que frequência?
- Os custos de computação são proporcionais ao valor do negócio da carga de trabalho?
Essa avaliação cria uma base para melhorias direcionadas e ajuda a alinhar seus esforços de otimização com o impacto nos negócios.
Framework de Implementação
O framework abaixo descreve uma abordagem passo a passo para implementar ou modernizar seu armazém no Databricks:
- Avalie o Estado Atual e Priorize Seus Objetivos
- Avalie e compare a arquitetura existente em relação a desempenho, custo e metas de escalabilidade.
- Defina os requisitos de negócios (e tecnologia) para simultaneidade, latência, escala, custo, SLAs e outros fatores para que os objetivos não continuem mudando.
- Identifique lacunas que impactam mais o negócio e priorize a remediação com base no valor e na complexidade (seja projetando algo novo, em meio à migração ou em produção).
- Defina a Arquitetura e Governança do Armazém
- Projete segmentação lógica: Determine quais equipes ou casos de uso compartilharão ou exigirão Armazéns SQL dedicados.
- Dimensione corretamente o seu armazém de instâncias, aplique tags e defina padrões (por exemplo, configurações de cache, timeouts, etc.).
- Entenda e planeje configurações detalhadas como cache padrão, tempos de espera do armazém, tempos de espera do JDBC de ferramentas de BI e parâmetros de configuração SQL (AWS | Azure | GPC).
- Estabeleça um modelo de governança para armazéns que abrange o administrador (AWS | Azure | GCP) e as funções e responsabilidades do usuário final (AWS | Azure | GCP).
- Invista em treinamento e forneça modelos de implementação para garantir a consistência entre as equipes.
- Ative a Observabilidade
- Habilite a observabilidade e monitoramento para o uso do armazém SQL para detectar anomalias, descobrir cargas de trabalho ineficientes e otimizar a utilização de recursos.
- Ative a funcionalidade pronta para uso (AWS | Azure | GCP) ao lado de telemetria personalizada e automatize alertas/remediações quando possível.
- Aprenda a aproveitar tabelas de sistema, monitoramento de armazém e perfis de consulta para identificar problemas como derramamento, embaralhamento ou enfileiramento.
- Integre dados de custo e metadados de linhagem (por exemplo, contexto da ferramenta BI via tabelas de histórico de consultas) para correlacionar desempenho e gastos.
- Implementar Otimizações e Melhores Práticas
- Aproveite os insights da observabilidade para alinhar o desempenho da carga de trabalho com os requisitos de negócios e tecnologia.
- Implemente recursos de IA para eficiência de custo, layout e computação.
- Codifique os aprendizados em modelos reutilizáveis, documentação e listas de verificação para escalar as melhores práticas entre as equipes.
- Otimize incrementalmente usando uma matriz de esforço (complexidade, cronograma, expertise) vs. impacto (desempenho, custo, sobrecarga de manutenção) para priorizar.
Nas seções abaixo, vamos percorrer cada estágio deste framework para entender como um design e execução cuidadosos permitem alta concorrência, baixa latência e desempenho de custo alinhado aos negócios no Databricks.
Avalie o Estado Atual e Priorize Seus Objetivos
Antes de mergulhar nas melhores práticas e técnicas de ajuste, é essencial entender as alavancas fundamentais que moldam o desempenho do lakehouse - como dimensionamento de computação, layout de dados e modelagem de dados. Estas são as áreas que as equipes podem influenciar diretamente para atender aos objetivos de alta concorrência, baixa latência e escalabilidade.

O quadro de pontuação abaixo fornece uma matriz simples para avaliar a maturidade em cada alavanca e identificar onde focar seus esforços. Para usá-lo, avalie cada alavanca em três dimensões: o quão bem ela atende às necessidades de negócios, o quão alinhada está com as melhores práticas, o nível de capacidade técnica que sua equipe tem nessa área e governança. Aplique uma classificação Vermelho-Amarelo-Verde (RAG) a cada interseção para visualizar rapidamente pontos fortes (verde), áreas para melhoria (âmbar) e lacunas críticas (vermelho). As melhores práticas e técnicas de avaliação mais adiante neste blog informarão a classificação - use essa direcionalidade em combinação com uma avaliação de maturidade mais granular. Este exercício pode orientar discussões entre equipes, revelar gargalos ocultos e ajudar a priorizar onde investir - seja em treinamento, mudanças de arquitetura ou automação.
Com os componentes que impulsionam o desempenho do lakehouse e um framework para implementá-los definidos, o que vem a seguir? A combinação de melhores práticas (o que fazer), técnicas de ajuste (como fazer) e métodos de avaliação (quando fazer) fornece as ações a serem tomadas para alcançar seus objetivos de desempenho.
O foco será nas melhores práticas específicas e técnicas de configuração granulares para alguns componentes críticos que trabalham harmoniosamente para operar um armazém de dados de alto desempenho.
Defina a Arquitetura e Governança do Armazém
Computação (Databricks SQL Warehouse)
Embora a computação seja frequentemente vista como a principal alavanca de desempenho, as decisões de dimensionamento de computação devem sempre ser consideradas juntamente com o design de layout de dados e modelagem/consulta, pois esses impactam diretamente a computação necessária para alcançar o desempenho requerido.
O dimensionamento correto dos armazéns SQL é crítico para o escalonamento com custo efetivo. Não há uma bola de cristal para um dimensionamento preciso antecipadamente, mas estas são algumas heurísticas chave a seguir para organizar e dimensionar o cálculo do armazém SQL.
- Habilite Armazéns SQL Serverless: Eles oferecem computação instantânea, autoescalabilidade elástica e são totalmente gerenciados, simplificando as operações para todos os tipos de usos, incluindo cargas de trabalho de BI/análise irregulares e intermitentes. Databricks gerencia totalmente a infraestrutura, com o custo dessa infraestrutura incluído, oferecendo o potencial para reduções de TCO.
- Entenda as Cargas de Trabalho e os Usuários: Segmentar usuários (humanos/automatizados) e seus padrões de consulta (BI interativo, ad hoc, relatórios agendados) para usar diferentes armazéns dimensionados por contexto de aplicação, um agrupamento lógico por propósito, equipe, função, etc. Implemente uma arquitetura multi-armazém, por esses segmentos, para ter um controle de dimensionamento mais refinado e a capacidade de monitorar independentemente. Garanta que as tags para atribuição de custos sejam aplicadas. Entre em contato com o seu contato de conta Databricks para acessar os próximos recursos destinados a prevenir vizinhos barulhentos.
- Dimensionamento e Escalabilidade Iterativa: Não pense demais no tamanho inicial do armazém ou nas configurações mínimas/máximas do cluster. Ajustes baseados no monitoramento do desempenho da carga de trabalho real, usando mecanismos na próxima seção, são muito mais eficazes do que suposições iniciais. Os volumes de dados e o número de usuários não estimam com precisão a computação necessária. Os tipos de consultas, padrões e simultaneidade da carga de consulta são melhores métricas, e há um benefício automatizado do Gerenciamento Inteligente de Carga de Trabalho (IWM) (AWS | Azure | GCP).
- Entenda Quando Redimensionar vs. Escalar: Aumente o tamanho do armazém ("tamanho de camiseta") quando precisar acomodar consultas pesadas e complexas, como grandes agregações e junções de várias tabelas, que requerem alta memória - monitore a frequência de derramamentos de disco e utilização de memória. Aumente o número de clusters para autoescala ao lidar com uso simultâneo em rajadas e quando você vê filas persistentes como resultado de muitas consultas esperando para serem executadas, não algumas consultas intensivas pendentes.
- Equilibre Disponibilidade e Custo: Configure as configurações de auto-parada. O rápido início frio do Serverless torna a auto-parada uma economia de custo significativa para períodos ociosos.
Layout de Dados Físicos (Arquivo) no Lakehouse
Consultas rápidas começam com a omissão de dados, onde o mecanismo de consulta lê apenas arquivos relevantes usando metadados e estatísticas para a poda eficiente de arquivos. A organização física dos seus dados impacta diretamente essa poda, tornando a otimização do layout do arquivo crítica para um desempenho de alta concorrência e baixa latência.
A evolução das técnicas de layout de dados no Databricks oferece várias abordagens para a organização ideal de arquivos:
Para novas tabelas, a Databricks recomenda por padrão tabelas gerenciadas com Agrupamento Líquido Automático (AWS | Azure | GCP) e Otimização Preditiva (AWS | Azure | GCP). O Agrupamento Líquido Automático organiza inteligentemente os dados com base em padrões de consulta, e você pode especificar colunas de agrupamento iniciais como dicas para habilitá-lo em um único comando. A Otimização Preditiva lida automaticamente com trabalhos de manutenção como OPTIMIZE, VACUUM e ANALYZE.
Para implantações existentes usando tabelas externas, considere migrar para tabelas gerenciadas para aproveitar totalmente esses recursos alimentados por IA, priorizando primeiramente as tabelas de alta leitura e sensíveis à latência. O Databricks fornece uma solução automatizada (AWS | Azure | GCP) com o ALTER TABLE...SET MANAGED comando para simplificar o processo de migração. Além disso, o Databricks suporta tabelas Iceberg gerenciadas como parte de sua estratégia de formato de tabela aberta.
Modelagem / Consulta de Dados
A modelagem é onde os requisitos de negócios encontram a estrutura de dados. Sempre comece entendendo seus padrões de consumo finais, depois modele para essas necessidades de negócios usando a metodologia preferida de sua organização - Kimball, Inmon, Data Vault ou abordagens desnormalizadas. A arquitetura lakehouse no Databricks suporta todas elas.
Unity Catalog estende suas funcionalidades além da observabilidade e descoberta com linhagem, chaves primárias (PKs), restrições e capacidades de evolução de esquema. Eles fornecem dicas cruciais para o otimizador de consultas do Databricks, permitindo planos de consulta mais eficientes e melhorando o desempenho da consulta. Por exemplo, declarar PKs e chaves estrangeiras com RELY permite que o otimizador elimine junções redundantes, impactando diretamente a velocidade. O robusto suporte do Unity Catalog para evolução de esquema também garante agilidade à medida que seus modelos de dados se adaptam ao longo do tempo. Unity Catalog fornece um modelo padrão de governança baseado em SQL ANSI.
Recursos relevantes adicionais incluem Técnicas de Modelagem de Armazenamento de Dados e uma série de três partes sobre Armazenamento de Dados Dimensional (Parte 1, Parte 2 e Parte 3).
Ative a Observabilidade
Ativar o monitoramento e a tomada de decisões de ajuste destaca perfeitamente a interconexão dos componentes do armazém de dados entre computação, layout físico de arquivos, eficiência de consultas e mais.
- Comece estabelecendo observabilidade por meio de painéis e aplicativos.
- Defina padrões aprendidos para identificar e diagnosticar gargalos de desempenho e, em seguida, corrigi-los.
- Construa iterativamente a automação através de alertas e ações corretivas agenticas.
- Compile tendências comuns que causam gargalos e incorpore-as nas melhores práticas de desenvolvimento, verificações de revisão de código e modelos.
O monitoramento contínuo é essencial para um alto desempenho sustentado e consistente e eficiência de custo em produção. Compreender padrões padrão permite refinar as decisões de ajuste à medida que o uso evolui.
Monitore e Ajuste: Use a aba de Monitoramento integrada de cada armazém (AWS | Azure | GCP) para insights em tempo real sobre consultas simultâneas de pico, utilização e outras estatísticas-chave. Isso fornece uma referência rápida para observação, mas deve ser complementado com outras técnicas para gerar alertas e ações.
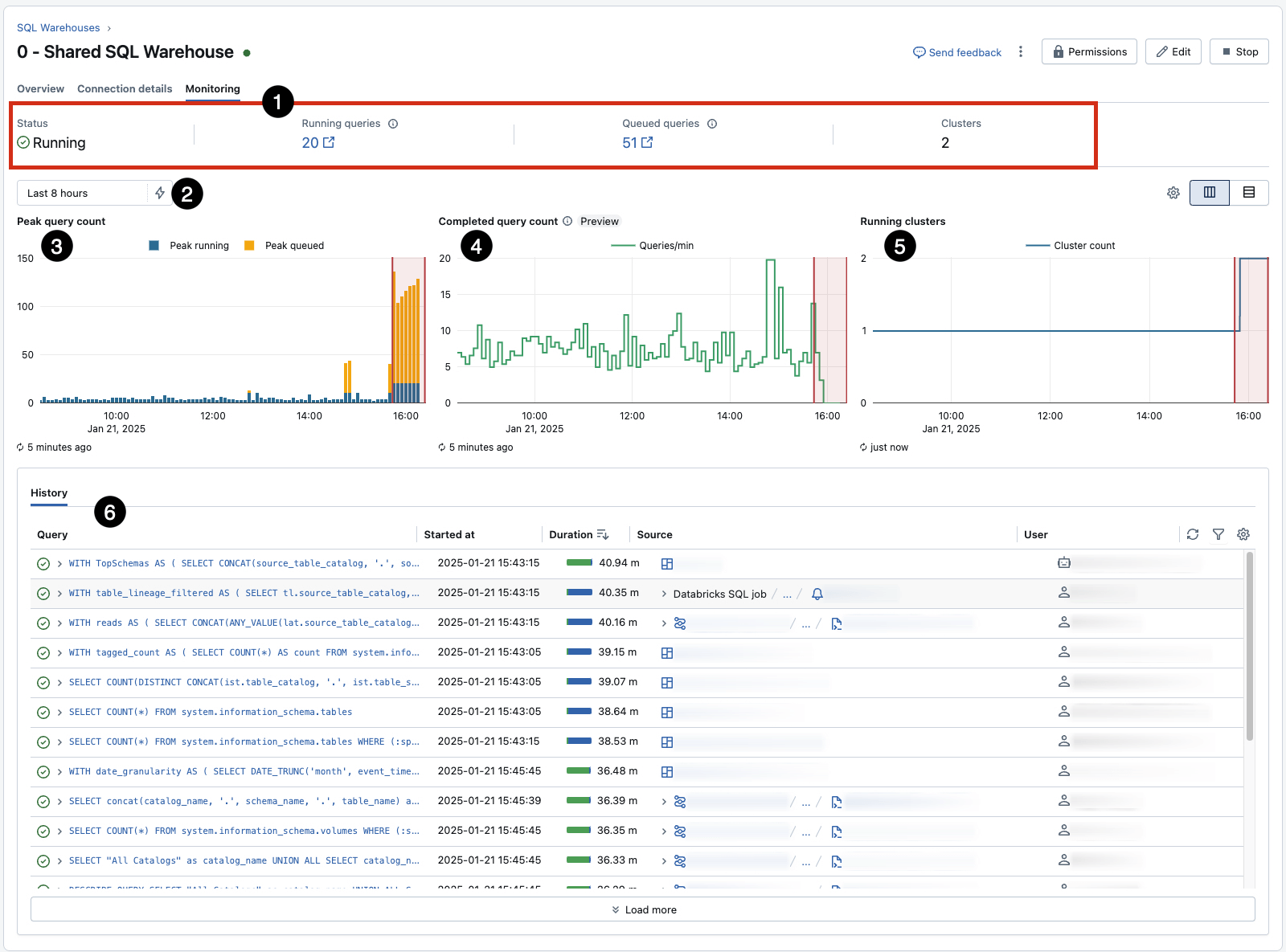
- Preste atenção especial ao 3, que revela filas devido a limites de concorrência para um determinado armazém (e pode ser influenciado pelo redimensionamento) e 5, que mostra eventos de escalonamento automático em resposta à fila. 6 registra o histórico de consultas, um ótimo ponto de partida para identificar e investigar cargas de trabalho longas e ineficientes.
Aproveite as tabelas do sistema: Suporta monitoramento mais granular e personalizado. Com o tempo, desenvolva painéis personalizados e alertas, mas aproveite as ofertas preparadas:
- O Painel de Monitoramento de Armazém SQL Granular fornece uma visão abrangente das decisões de escalonamento informadas, entendendo quem e o que impulsiona os custos.
- O DBSQL Workflow Advisor fornece uma visão geral do escalonamento, desempenho de consulta para identificar gargalos e atribuição de custos.
- Introduza alertas SQL personalizados (AWS | Azure | GCP) para notificações integradas aprendidas a partir dos eventos de monitoramento acima.
Para clientes interessados em atribuição de custos e observabilidade além do simples SQL Warehouse, este blog dedicado, Do Caos ao Controle: Uma Jornada de Maturidade de Custos com Databricks, sobre a jornada de maturidade de custos, é um recurso valioso.
Utilize Perfis de Consulta: A ferramenta Perfil de Consulta (AWS | Azure | GCP) é o seu principal diagnóstico para problemas de desempenho de consultas individuais. Ela fornece planos de execução detalhados e ajuda a identificar gargalos que afetam a computação necessária.
 |
|

Algumas sugestões de ponto de partida do que procurar no perfil de consulta:
- Verifique se ocorre poda. Se deveria haver poda (AWS | Azure | GCP) (ou seja, reduzindo a leitura de dados do armazenamento usando metadados/estatísticas das tabelas), o que você esperaria se aplicasse predicados ou junções, mas não está ocorrendo, então analise a estratégia de layout de arquivo. Idealmente, os arquivos/partições lidos devem ser baixos e os arquivos podados devem ser altos.
- Uma quantidade significativa de tempo de relógio gasto em "Agendamento" (maior que alguns segundos) sugere enfileiramento.
- Se a duração da 'Busca de resultados pelo cliente' levar a maior parte do tempo, indica um possível problema de rede entre a ferramenta/aplicação externa e o armazém SQL.
- Bytes lidos do cache variarão dependendo dos padrões de uso, pois os usuários que executam consultas usando as mesmas tabelas no mesmo armazém naturalmente aproveitarão os dados em cache em vez de reescanear arquivos.
- O DAG (Grafo Direcionado Acíclico–AWS | Azure | GCP) permite que você identifique etapas pelo tempo que levaram, memória utilizada e linhas lidas. Isso pode ajudar a identificar problemas de desempenho para consultas altamente complexas.
- Para detectar o problema de arquivo pequeno (onde os arquivos de dados são significativamente menores que o tamanho ideal, causando processamento ineficiente), idealmente, o tamanho médio do arquivo deve estar entre 128MB e 1GB, dependendo do tamanho da tabela:
- A maior parte do plano de consulta gasto na varredura da(s) tabela(s) de origem.
- Execute
DESCRIBE DETAIL [Nome da Tabela]. Para encontrar o tamanho médio do arquivo, divida osizeInBytespelonumFiles. Ou, no perfil de consulta, use [Bytes lidos] / [Arquivos lidos].
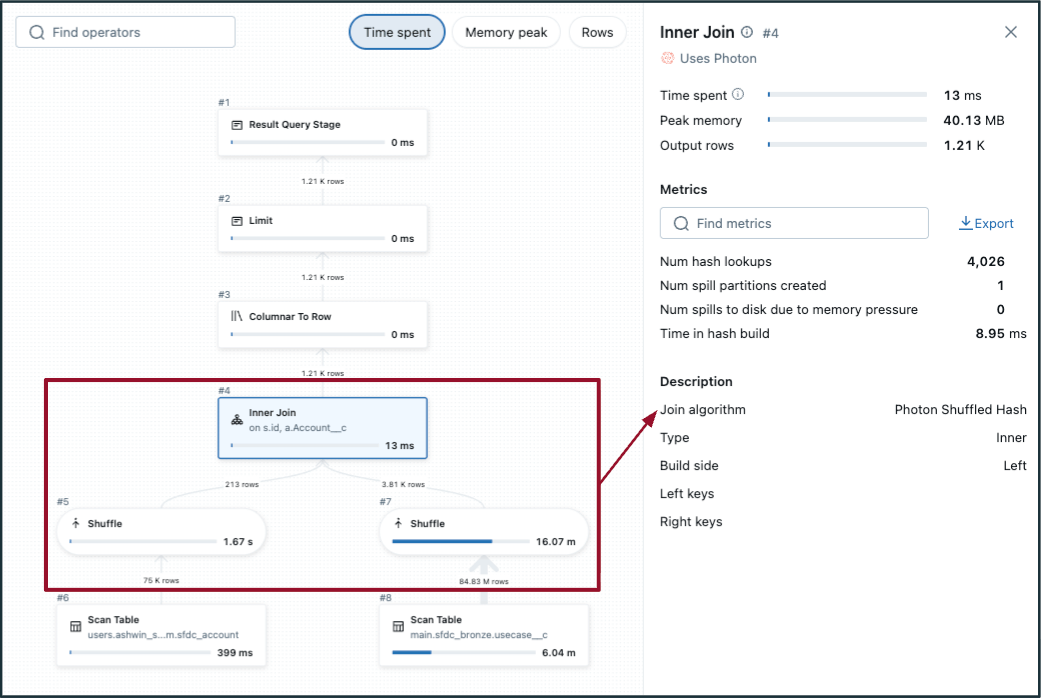
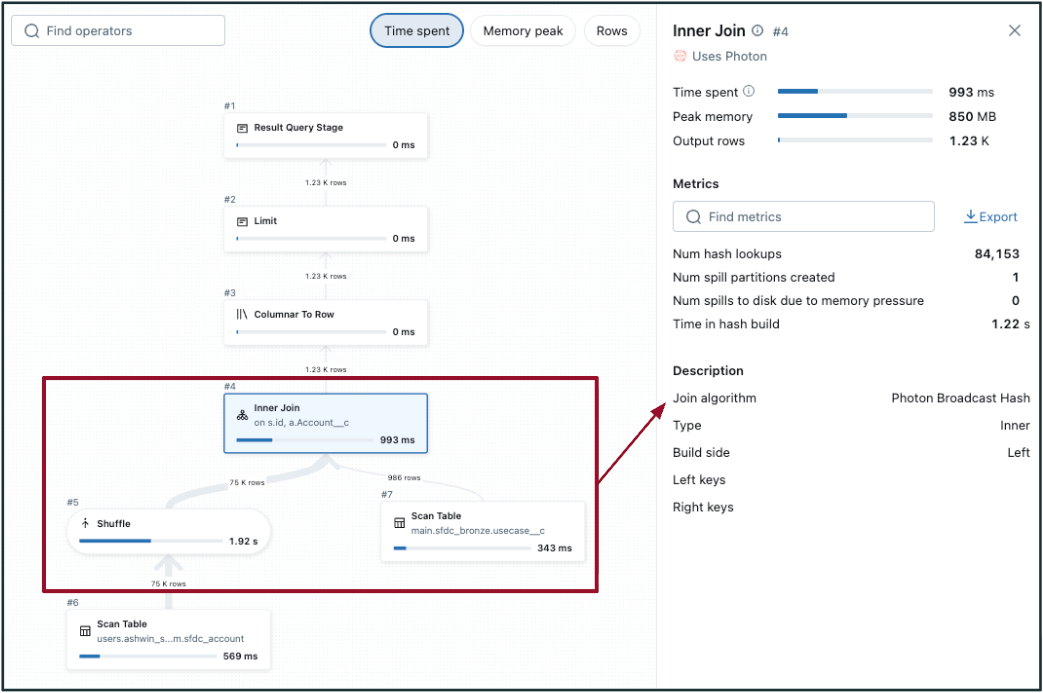
- Para detectar uma junção de hash de embaralhamento potencialmente ineficiente:
- Escolha a etapa de junção no DAG e verifique o "Algoritmo de junção".
- Sem/pouca poda de arquivo.
- No DAG, o embaralhamento ocorre em ambas as tabelas (em qualquer lado da junção, como na imagem à esquerda). Se uma das tabelas for pequena o suficiente, considere transmitir para realizar uma junção de hash de transmissão em vez disso (mostrado na imagem à direita).
- A execução de consulta adaptativa (AQE) tem como padrão <=30 MB de tamanho de dados para junções de transmissão - geralmente, tabelas com tamanho de dados inferior a 200 MB são bons candidatos para avaliação de transmissão. 1 GB é o limite máximo.
- Sempre garanta que os filtros estão sendo aplicados para reduzir os conjuntos de dados de origem.
 |  |
Implementar Otimizações e Melhores Práticas
Problemas de Desempenho: Os 4 S's + Enfileiramento
Seja configurando a computação para uma nova carga de trabalho ou otimizando, é necessário entender os problemas de desempenho mais comuns. Estes se encaixam em um apelido comum, "Os 4 S's", com um quinto (enfileiramento) adicionado:
Para reduzir a latência de consulta em seu armazém SQL, determine se o spill, queuing e/ou shuffle (skew e pequenos arquivos serão abordados mais tarde) são o principal gargalo de desempenho. Este guia abrangente fornece mais detalhes. Após identificar a causa raiz, aplique as diretrizes abaixo para ajustar o tamanho do armazém SQL de acordo e medir o impacto.
- Derramamento de Disco (da memória para o disco): O derramamento ocorre quando um armazém SQL fica sem memória e grava resultados temporários no disco, significativamente mais lento do que o processamento em memória. Em um Perfil de Consulta, quaisquer quantidades contra "spill (bytes)" ou "tempo de spill" indicam que isso está ocorrendo.
Para mitigar derramamentos, aumente o tamanho da camiseta do armazém SQL para fornecer mais memória. O uso de memória de consulta também pode ser reduzido por meio de técnicas de otimização de consulta, como filtragem precoce, redução de skew e simplificação de junções. Melhorar o layout do arquivo - usando arquivos de tamanho apropriado ou aplicando o Agrupamento Líquido - pode limitar ainda mais a quantidade de dados escaneados e embaralhados durante a execução.
Consulta auxiliar em tabelas do sistema que pode ser convertida em um Alerta SQL ou Painel AI/BI
- Enfileiramento de Consultas: Se a tela de Monitoramento do Armazém SQL mostra enfileiramento persistente (onde as consultas em pico enfileiradas são >10) que não se resolve imediatamente com um evento de autoescala, aumente o valor máximo de escala para o seu armazém. O enfileiramento adiciona diretamente latência, pois as consultas aguardam recursos disponíveis.
Consulta auxiliar em tabelas do sistema que pode ser convertida em um Alerta SQL ou Painel AI/BI
- Alta Paralelização/Baixo Embaralhamento: Para consultas que podem ser divididas em muitas tarefas independentes - como filtros ou agregações em grandes conjuntos de dados - e mostram baixo embaralhamento nos Perfis de Consulta, aumentar o tamanho da camiseta do armazém SQL pode melhorar a taxa de transferência e reduzir o enfileiramento. Um shuffle baixo indica movimento mínimo de dados entre os nós, o que permite uma execução paralela mais eficiente.
- Transformações estreitas (por exemplo, consultas pontuais, consultas agregadas) geralmente se beneficiam de mais escalabilidade para o manuseio de consultas simultâneas. Transformações amplas (junções complexas com agregação) geralmente se beneficiam mais de tamanhos de armazém maiores versus escalabilidade.
- Alto Shuffle: Por outro lado, quando o shuffle é alto, grandes quantidades de dados são trocadas entre os nós durante a execução da consulta - muitas vezes devido a junções, agregações ou dados mal organizados. Isso pode ser um gargalo de desempenho significativo. Nos Perfis de Consulta, um alto embaralhamento é indicado por grandes valores em "bytes escritos no embaralhamento", "bytes lidos no embaralhamento" ou longas durações em estágios relacionados ao embaralhamento. Se essas métricas estiverem consistentemente elevadas, otimizar a consulta ou melhorar o layout físico dos dados, em vez de simplesmente aumentar a computação, é o melhor.
Consulta auxiliar em tabelas do sistema que pode ser convertida em um Alerta SQL ou Painel AI/BI
Adotando uma Visão de Monitoramento Macro
Embora essas análises e regras ajudem a entender como as consultas impactam o armazém no nível micro, as decisões de dimensionamento são feitas no nível macro. Geralmente, comece ativando as capacidades de monitoramento na seção anterior (e personalizando-as) para identificar o que está acontecendo e, em seguida, estabeleça medidas de limite para derramamento, inclinação, enfileiramento, etc., para servir como indicadores de quando é necessário redimensionar. Avalie esses limites para gerar uma pontuação de impacto pela frequência com que os limites são atingidos ou a porcentagem de tempo que os limites são excedidos durante a operação regular. Para compartilhar algumas medidas de exemplo (defina estas usando seus requisitos de negócios específicos e SLAs):
- Porcentagem de tempo cada dia que as consultas enfileiradas no pico > 10
- Consultas que estão entre os 5% mais altos de embaralhamento por um período prolongado ou consistentemente entre os 5% mais altos de embaralhamento durante o uso de pico
- Períodos em que pelo menos 20% das consultas derramam para o disco ou consultas que derramam para o disco em mais de 25% de suas execuções
É necessário fundamentar isso no reconhecimento de que existem compensações a considerar, não uma única receita a seguir ou uma solução única para todos os armazéns de dados. Se a latência da fila não for uma preocupação, potencialmente para consultas noturnas que atualizam, então não ajuste para ultra-baixa concorrência e reconheça a eficiência de custo com maior latência. Este blog fornece um guia sobre as melhores práticas e metodologias para diagnosticar e ajustar seu armazém de dados com base em suas necessidades de implementação únicas.
Otimizando o Layout de Dados Físicos (Arquivo) no Lakehouse
Abaixo estão várias melhores práticas para gerenciar e otimizar arquivos de dados físicos armazenados em seu lakehouse. Use essas técnicas e técnicas de monitoramento para diagnosticar e resolver problemas que afetam suas cargas de trabalho analíticas do armazém de dados.
- Ajuste a omissão de dados de uma tabela (AWS | Azure | GCP) se necessário. As tabelas Delta armazenam min/max e outras estatísticas de metadados para as primeiras 32 colunas por padrão. Aumentar esse número pode aumentar os tempos de execução da operação DML, mas pode diminuir o tempo de execução da consulta se as colunas adicionais forem filtradas nas consultas.
- Para identificar se você tem o problema de arquivos pequenos, revise as propriedades da tabela (numFiles, sizeInBytes, clusteringColumns, partitionColumns) e use a Otimização Preditiva com Agrupamento Líquido ou garanta que você execute rotinas de compactação OPTIMIZE em cima de dados devidamente organizados.
- Embora a recomendação seja habilitar o Auto Liquid Clustering e aproveitar a Otimização Preditiva para remover o ajuste manual, é útil entender as melhores práticas subjacentes e estar capacitado para ajustar manualmente em instâncias selecionadas. Abaixo estão regras úteis para selecionar colunas de agrupamento:
- Comece com uma única coluna, a que é mais naturalmente usada como predicado (e usando as sugestões abaixo), a menos que haja alguns candidatos óbvios. Muitas vezes, apenas tabelas enormes se beneficiam de >1 chave de cluster.
- Priorizar colunas para uso prioriza a otimização de leituras sobre gravações. Eles devem ser 1) usados como predicados de filtro, 2) usados em operações GROUP BY ou JOIN e 3) colunas MERGE.
- Geralmente, deve ter alta cardinalidade (mas não única). Evite valores sem sentido como strings UUID, a menos que você precise de consultas rápidas nessas colunas.
- Não reduza a cardinalidade (por exemplo, converta de timestamp para data) como você faria ao definir uma coluna de partição.
- Não use duas colunas relacionadas (por exemplo, timestamp e datestamp)—sempre escolha a que tem a maior cardinalidade.
- A ordem das chaves na sintaxe CREATE TABLE não importa. O agrupamento multidimensional é usado.
Juntando Tudo: Uma Abordagem Sistemática
Este blog se concentra nas três primeiras alavancas arquitetônicas. Outros componentes críticos de implementação contribuem para a arquitetura de um armazém de dados de alta concorrência, escalável e de baixa latência, incluindo ETL/ELT, infraestrutura, DevOps e Governança. Uma perspectiva adicional do produto sobre a implementação de um lakehouse pode ser encontrada aqui, e uma série de melhores práticas está disponível no Guia Completo para Otimizar Cargas de Trabalho Databricks, Spark e Delta Lake.
Os componentes fundamentais do seu armazém de dados - computação, layout de dados e modelagem/consulta - são altamente interdependentes. Abordar o desempenho de forma eficaz requer um processo iterativo: monitoramento contínuo, otimização e garantia de que novas cargas de trabalho aderem a um projeto otimizado. E evolua esse projeto à medida que as melhores práticas de tecnologia mudam e seus requisitos de negócios mudam. Você quer as ferramentas e o conhecimento para ajustar seu armazém para atender às suas exigências precisas de concorrência, latência e escalabilidade. Robusta governança, transparência, monitoramento e segurança habilitam este framework arquitetônico central. Estes não são considerações separadas, mas a base para oferecer experiências de armazém de dados de primeira classe no Databricks.
Agora, vamos explorar um exemplo recente de cliente em que o framework e as melhores práticas fundamentais, alavancas de ajuste e monitoramento, foram aplicados na prática, e uma organização melhorou significativamente o desempenho e a eficiência de seu armazém de dados.
Cenários e Compromissos do Mundo Real
Otimização da Plataforma de Marketing por Email
Contexto de Negócios
Uma plataforma de marketing por e-mail fornece aos varejistas de comércio eletrônico ferramentas para criar jornadas personalizadas para os clientes com base em dados ricos do cliente. O aplicativo permite aos usuários orquestrar campanhas de e-mail para públicos-alvo, ajudando os clientes a elaborar estratégias de segmentação e acompanhar o desempenho. As análises em tempo real são críticas para o seu negócio - os clientes esperam visibilidade imediata em métricas de desempenho de campanha como taxas de cliques, rejeições e dados de engajamento.
Desafio Inicial
A plataforma estava enfrentando problemas de desempenho e custo com sua infraestrutura de análise. Eles estavam executando um grande armazém SQL Serverless com escalonamento automático de 1-5 clusters e até precisaram atualizar para XL durante os períodos de pico de relatórios. Sua arquitetura dependia de:
- Dados de streaming em tempo real de uma fila de mensagens para o Delta Lake via streaming estruturado contínuo
- Um trabalho noturno para consolidar registros transmitidos em uma tabela histórica
- Uniões em tempo de consulta entre a tabela histórica e os dados de streaming
- Agregações complexas e lógica de deduplicação executada no momento da consulta
Essa abordagem significava que cada atualização do painel do cliente exigia processamento intensivo, levando a custos mais altos e tempos de resposta mais lentos.
Ao monitorar o armazém SQL, houve enfileiramento significativo (colunas amarelas), com períodos de uso intermitentes, onde o escalonamento automático foi devidamente acionado, mas não conseguiu acompanhar as cargas de trabalho:

Para diagnosticar a causa da fila, identificamos algumas consultas de longa duração e as consultas mais frequentemente executadas usando o histórico de consultas (AWS | Azure | GCP) e tabelas do sistema para determinar se a fila era simplesmente devido a um alto volume de consultas relativamente básicas e estreitas ou se a otimização era necessária para melhorar as consultas de baixo desempenho.
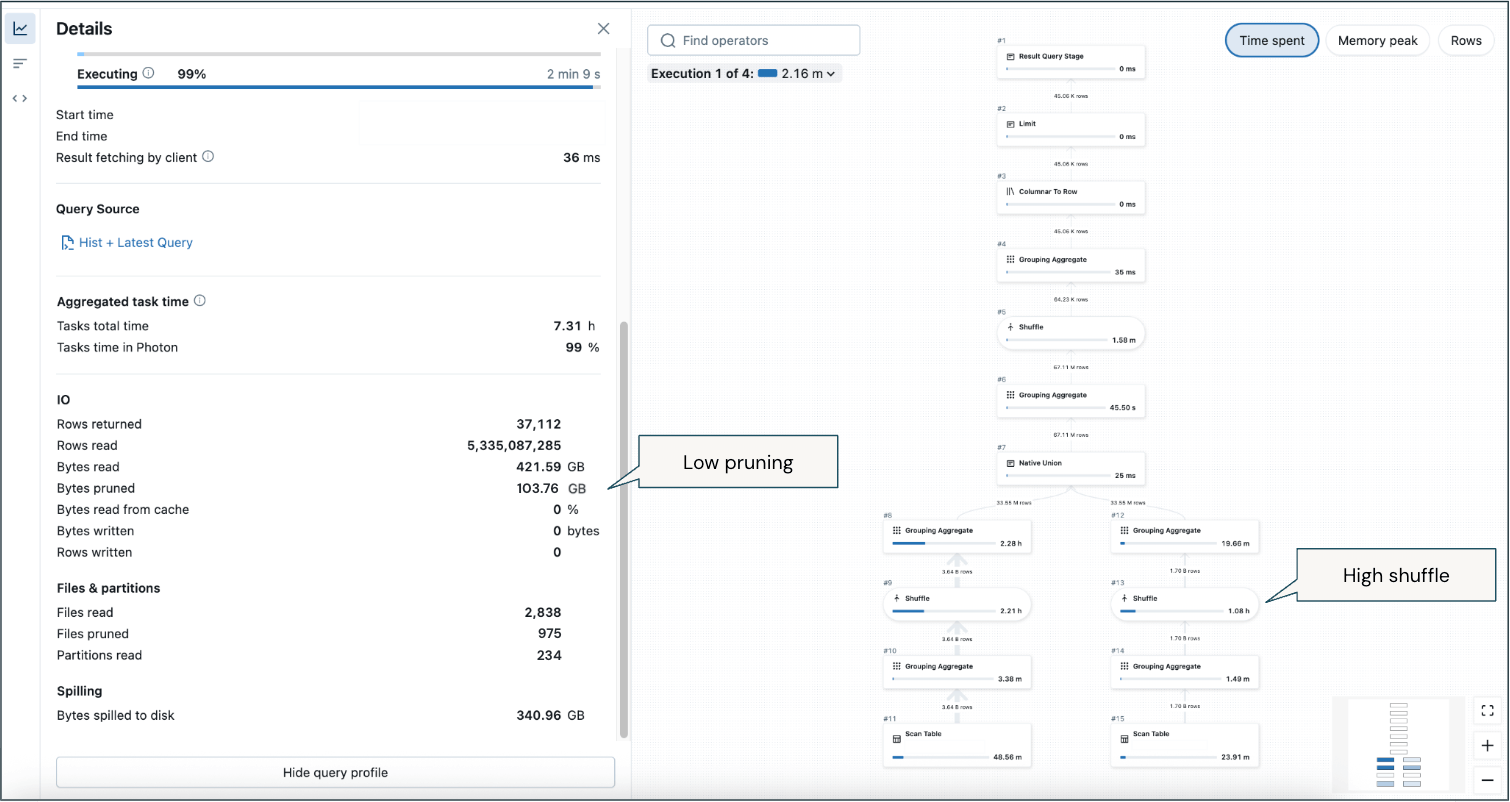
Alguns pontos críticos deste exemplo de perfil de uma consulta de longa duração:
- Baixa poda (apesar de um filtro significativo no período de tempo para retornar as 2 semanas mais recentes) significa que uma quantidade considerável de dados está sendo escaneada.
- Alto embaralhamento - haverá inerentemente embaralhamento devido a agregações analíticas, mas é a maioria do uso de memória em dados históricos e recentes.
- Derrame para o disco em algumas instâncias.
Esses aprendizados a partir da observação de consultas críticas levaram a ações de otimização em computação, layout de dados e técnicas de consulta.
Abordagem de Otimização
Trabalhando com um Arquiteto de Soluções de Entrega da Databricks, a plataforma implementou várias otimizações-chave:
- Aumento da frequência de fusão: Mudou de fusões noturnas para fusões horárias, reduzindo significativamente o volume de dados de streaming que precisavam ser processados no momento da consulta.
- Implementar Visualizações Materializadas: Converta a tabela de agregação em uma visualização materializada que se atualiza incrementalmente a cada hora, pré-computando a lógica de agregação complexa durante a atualização para que o processamento no momento da consulta seja limitado apenas aos dados da hora mais recente.
- Organização moderna de dados: Mudou da partição estilo Hive para o agrupamento líquido automático, que seleciona inteligentemente as colunas de agrupamento ótimas com base nos padrões de consulta e se adapta ao longo do tempo.
Resultados
Após um processo de descoberta e implementação de seis semanas, a plataforma viu melhorias imediatas e notáveis assim que foi implantada:
- Redução dos custos de infraestrutura: Reduzido de um grande armazém sem servidor com escalonamento automático para um pequeno armazém sem servidor sem escalonamento automático.
- Melhoria do desempenho da consulta: Menor latência para painéis de usuário final, melhorando a experiência do cliente.
- Operações simplificadas: Eliminou a sobrecarga operacional de frequentes reclamações de desempenho do usuário final e casos de suporte.
Um exemplo de um perfil de consulta após a otimização:
- Como o layout do arquivo foi otimizado, mais poda de arquivo ocorreu para reduzir a quantidade de dados/arquivos que precisavam ser lidos.
- Sem derramamento para o disco.
- Ainda ocorre embaralhamento por causa das agregações analíticas, mas a quantidade de embaralhamento é significativamente reduzida devido à poda mais eficiente e elementos pré-agregados que não precisam ser calculados em tempo de execução.

Esta transformação demonstra como a aplicação de melhores práticas de modelagem de dados, aproveitando a computação serverless e utilizando recursos avançados do Databricks como visualizações materializadas e agrupamento líquido podem melhorar dramaticamente tanto o desempenho quanto a eficiência de custos.
Principais Conclusões
- Foque seus requisitos na concorrência, latência e escala do armazém de dados. Em seguida, use as melhores práticas, capacidades de observabilidade e técnicas de ajuste para atender a esses requisitos.
- Concentre-se em dimensionar corretamente a computação, implementar práticas sólidas de layout de dados (significativamente auxiliadas pela IA) e abordar modelos de dados e consultas como prioridade.
- O melhor armazém de dados é um lakehouse do Databricks - aproveite abordagens inovadoras que levam a novos recursos, casadas com princípios fundamentais de armazém de dados.
- Atenda às necessidades tradicionais de armazenamento de dados sem sacrificar a IA/ML (você está capitalizando com o Databricks).
- Não dimensione e ajuste cegamente; aproveite a observabilidade integrada para monitorar, otimizar e automatizar ações de economia de custos.
- Adote o Databricks SQL Serverless para um desempenho de preço ótimo e suporte aos padrões de uso variáveis típicos de cargas de trabalho de BI e análise.
Próximos Passos e Recursos Adicionais
Alcançar um data warehouse de alta concorrência e baixa latência que escala não acontece seguindo uma receita padrão. Existem compensações a considerar, e muitos componentes trabalham juntos. Se você está consolidando sua estratégia de data warehousing, em progresso com uma implementação e lutando para entrar em operação, ou otimizando sua pegada atual, considere as melhores práticas e o framework descritos neste blog para abordá-lo de forma holística. Entre em contato se você precisar de ajuda ou quiser discutir como a Databricks pode atender todas as suas necessidades de armazenamento de dados.
Databricks Arquitetos de Soluções de Entrega (DSAs) aceleram as iniciativas de Dados e IA em organizações. Eles fornecem liderança arquitetônica, otimizam plataformas para custo e desempenho, melhoram a experiência do desenvolvedor e impulsionam a execução bem-sucedida do projeto. Os DSAs preenchem a lacuna entre a implantação inicial e as soluções de produção, trabalhando de perto com várias equipes, incluindo engenharia de dados, líderes técnicos, executivos e outros stakeholders para garantir soluções personalizadas e um tempo de valor mais rápido. Para se beneficiar de um plano de execução personalizado, orientação estratégica e suporte durante sua jornada de dados e IA com um DSA, entre em contato com sua Equipe de Contas Databricks.
(This blog post has been translated using AI-powered tools) Original Post
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.