MemEx: Um bloco de rascunho programável para agentes de LLM
Em 1945, Vannevar Bush imaginou uma máquina do tamanho de uma escrivaninha que ampliaria a memória de um cientista ao armazenar cada documento, anotação e linha de pensamento para recuperação sob demanda. Ele a chamou de MemEx. Bush estava resolvendo um problema humano: mentes sobrecarregadas por informações que não conseguiam manter ao alcance das mãos. Oito décadas depois, os agentes de LLM estão enfrentando uma barreira notavelmente semelhante.
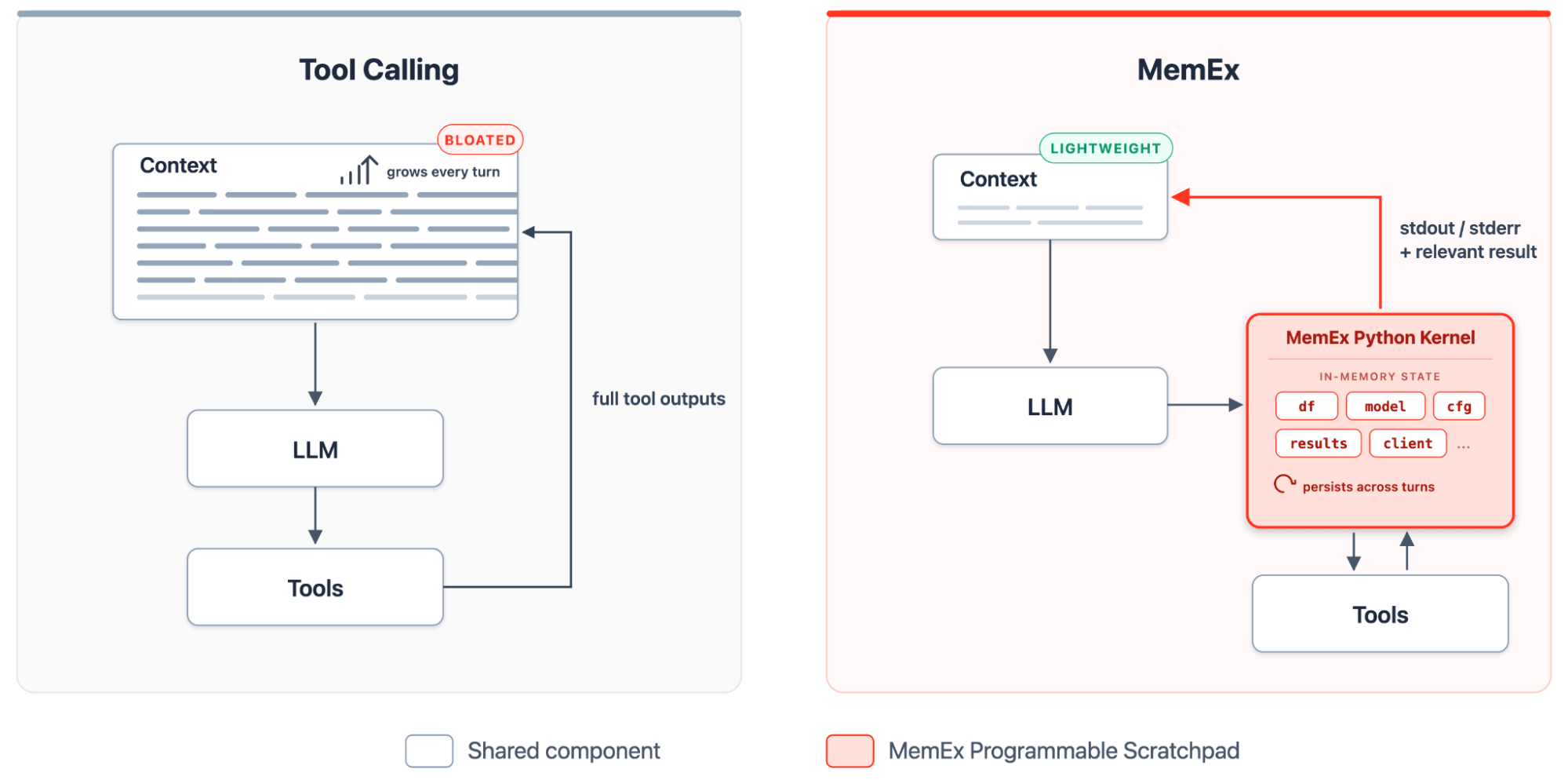
No paradigma atual de Agentic Tool Calling, a janela de contexto é o único substrato persistente sobre o qual o modelo pode operar. É um espaço compartilhado que carrega o prompt do sistema, a consulta do usuário, o raciocínio do modelo, as chamadas de ferramentas e as saídas brutas das ferramentas. As saídas das ferramentas são as piores vilãs: uma única consulta SQL pode retornar milhões de linhas e, nos harnesses atuais, essas linhas são carregadas em cada turno subsequente, mesmo que apenas uma célula fosse importante. O agente não tem como fatiar, resumir ou armazenar o resultado antes que ele inunde a janela.
Enfrentamos essa barreira constantemente na Databricks. Nossos agentes de produção, do Genie ao Agent Bricks, encontram as mesmas limitações de contexto em algum momento. O Genie oferece um exemplo claro: uma única consulta pesquisa todo o espaço de trabalho de um cliente, chamando muitas ferramentas para extrair dados de tabelas, índices vetoriais e dashboards. Para resolver isso, criamos nosso próprio MemEx e o validamos em vários agentes internos e de produção.
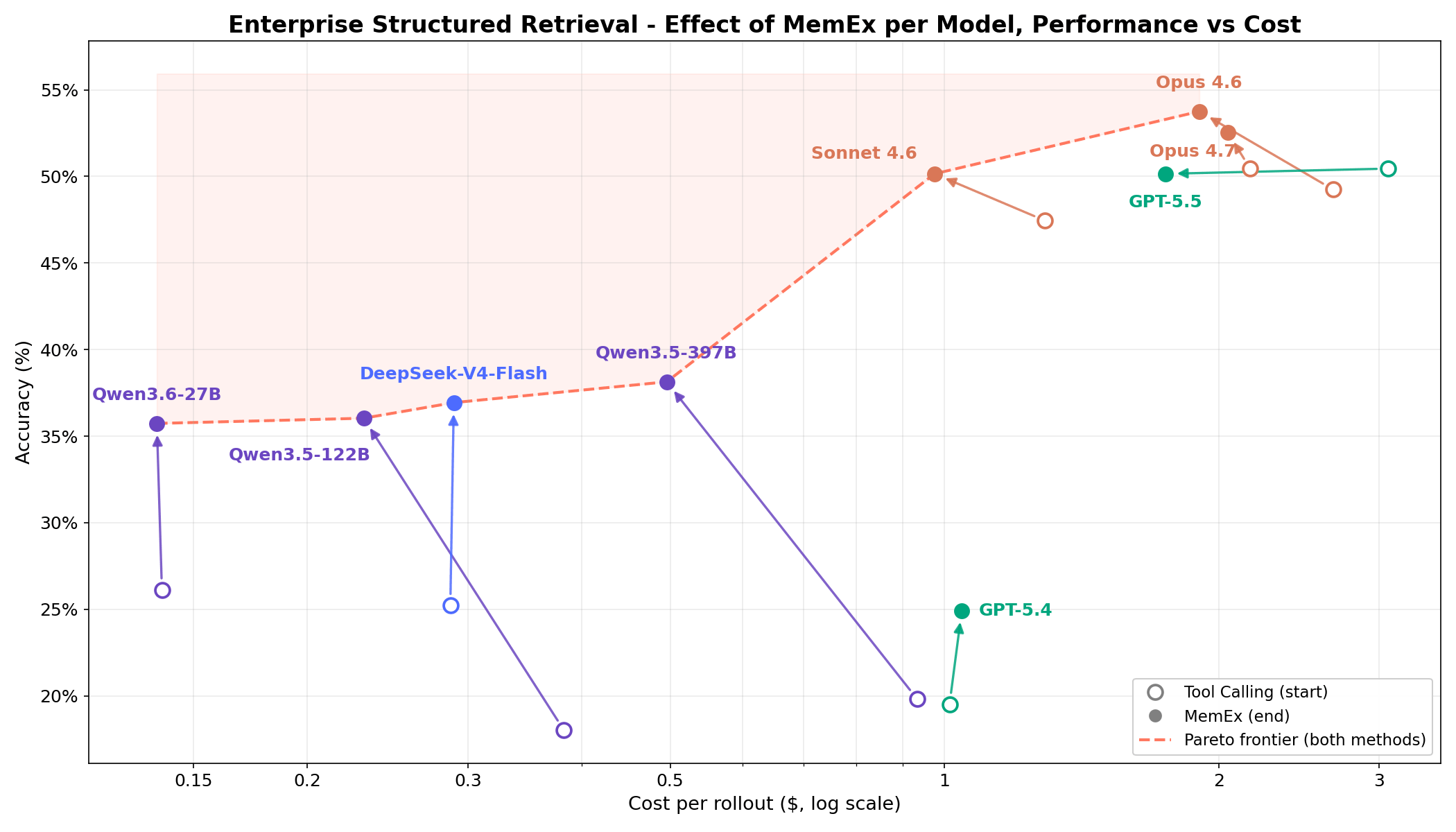
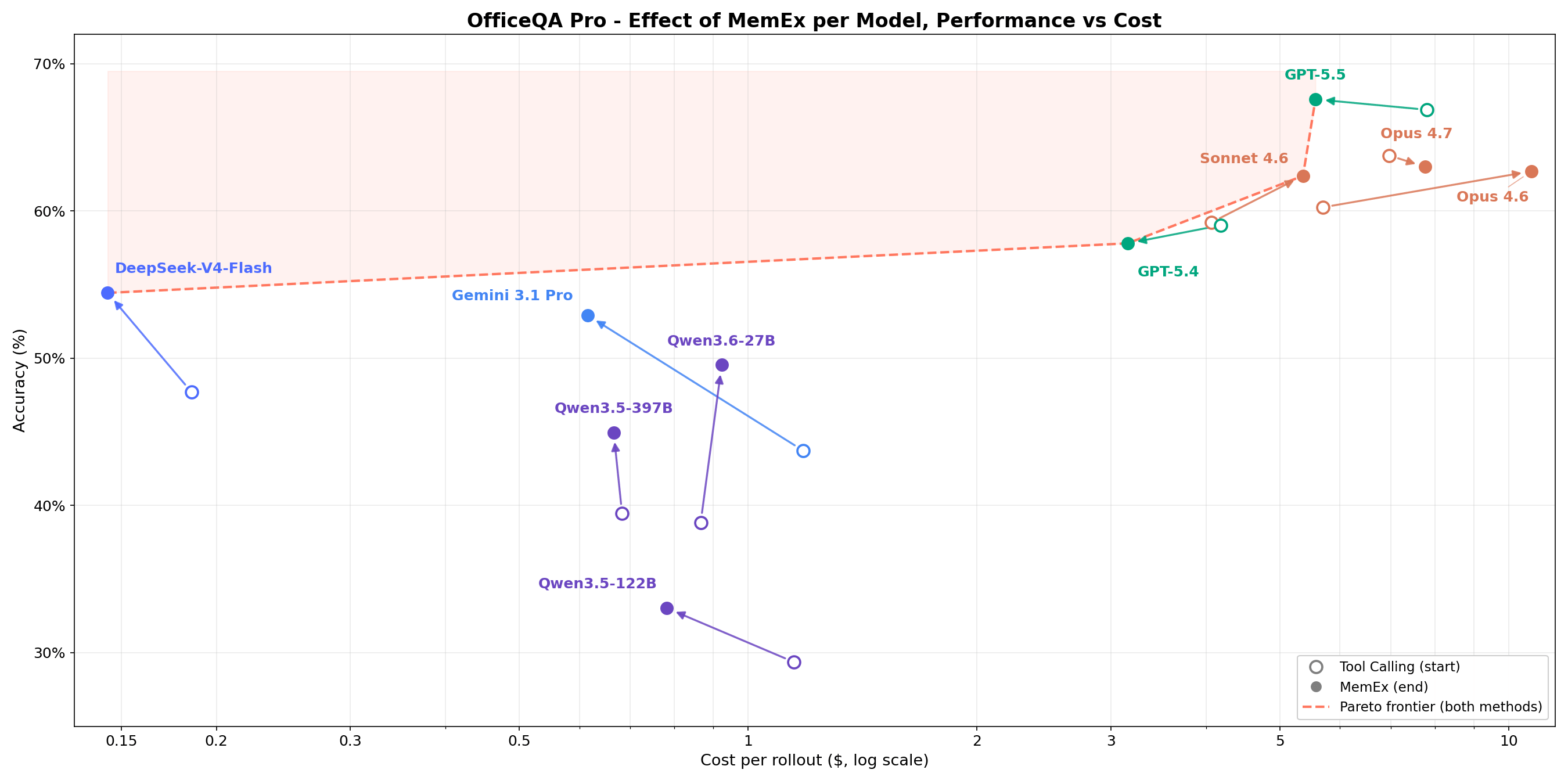
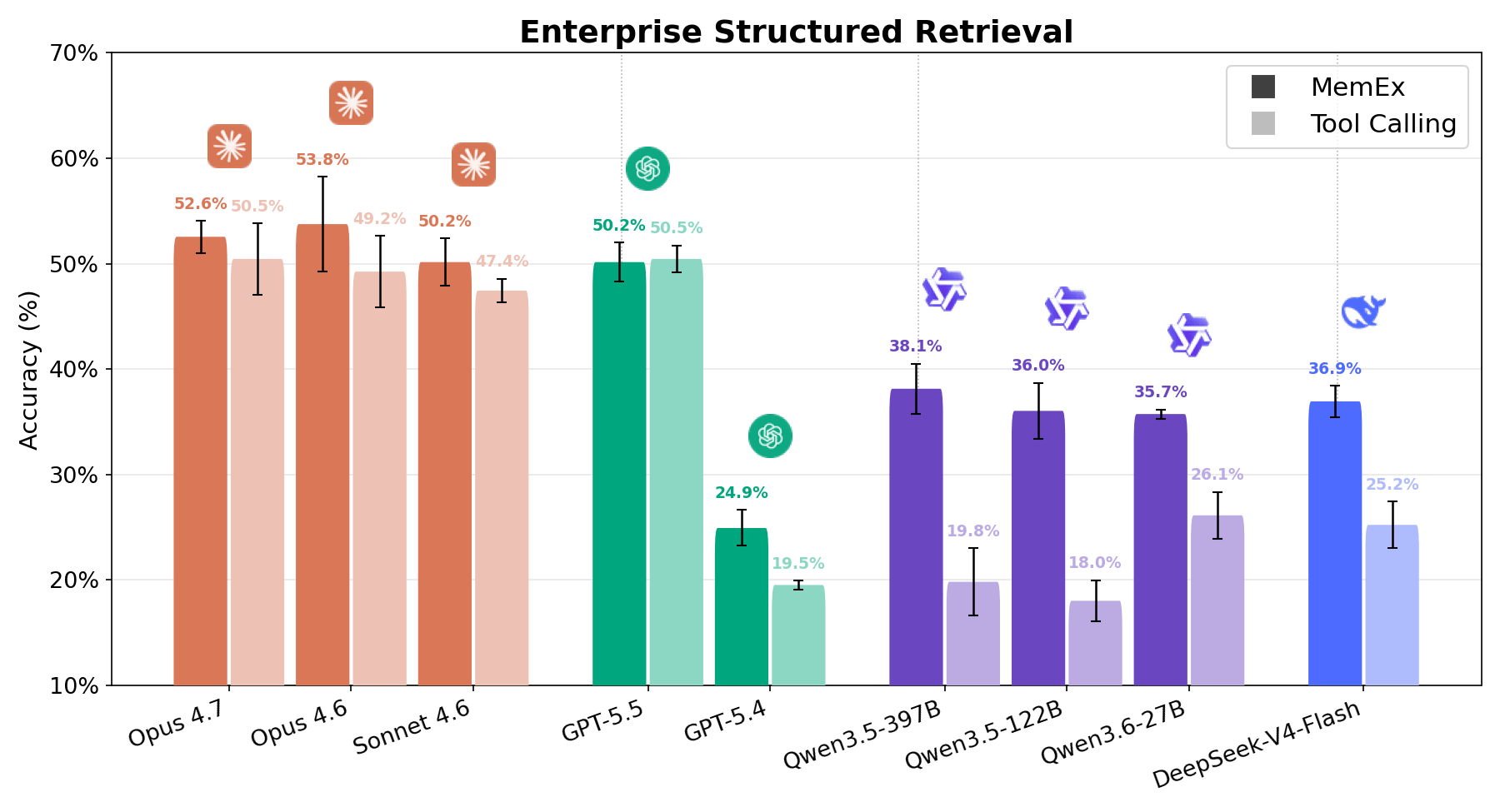
Em tarefas complexas de recuperação estruturada empresarial, a Figura 1 mostra que o MemEx expande a fronteira de custo-benefício (custo vs. precisão) para cada modelo. Modelos de fronteira como Opus 4.6 e Sonnet 4.6 ganham de 2 a 5 pontos percentuais com um custo de tokens de 25% a 30% menor. Modelos de pesos abertos como Qwen3.5-122B (18% → 36%) e Qwen3.5-397B (20% → 38%) quase dobram sua precisão com um custo de tokens de 40% a 50% menor. Como o MemEx pode operar sobre entradas arbitrariamente longas, ele também viabiliza duas outras aplicações: a auditoria de trajetórias de agentes, incluindo as do próprio MemEx, que normalmente não caberiam em uma única janela de contexto, e o raciocínio paralelo em várias trajetórias.
Como o MemEx funciona
{kind=link}
O MemEx oferece ao LLM um rascunho programável: um kernel Python tipado que armazena as saídas das ferramentas, as transforma com código e materializa apenas as instruções de impressão (print) como tokens no contexto. Dentro desse ambiente, a execução (rollout) se torna um programa Python autoextensível. Durante cada turno, o agente cria um novo bloco, o kernel mantém o estado ativo e o próximo bloco se baseia no anterior. As ferramentas são expostas como funções Python tipadas com parâmetros tipados e valores de retorno tipados. As saídas das ferramentas chegam como objetos Python no escopo do MemEx, onde persistem entre os turnos. O agente os compõe com código, define funções auxiliares quando um padrão se repete e gera subagentes como chamadas de função assíncronas no mesmo escopo.
O MemEx faz parte da família de código como ação (code-as-action) introduzida pelo CodeAct (Wang et al., 2024), com variantes de produção no Programmatic Tool Calling da Anthropic e no Cloudflare Code Mode. O MemEx se destaca por se integrar a uma estrutura de agentes existente no estilo ReAct (Yao et al., 2022), com escopo persistente, primitivas de subagentes e retornos tipados integrados. Juntos, eles liberam recursos que faltam ao paradigma de chamada de ferramentas JSON/XML:
- Tratamento de entradas arbitrariamente grandes: Documentos, conjuntos de dados e outros objetos grandes podem ser mantidos no escopo do Python como variáveis.
- Retorno de objetos tipados: As saídas das ferramentas são objetos Python tipados mantidos na memória, não strings que o modelo precisa materializar ou analisar novamente (re-parse) a cada turno.
- Composição de chamadas de ferramentas: A saída de uma chamada flui diretamente para os argumentos da próxima chamada em uma única linha de código. As saídas intermediárias não precisam ser materializadas no contexto do agente.
- Fatiamento de saídas de ferramentas: As saídas podem ser pré-processadas, filtradas ou resumidas no código antes que o modelo as veja.
- Geração de subagentes assíncronos: Os agentes podem gerar subagentes programaticamente que são executados junto com o agente pai e agregar seus resultados sem a necessidade de uma viagem de ida e volta (round-trip) pelo modelo principal.
Exemplo de agente de LLM com MemEx
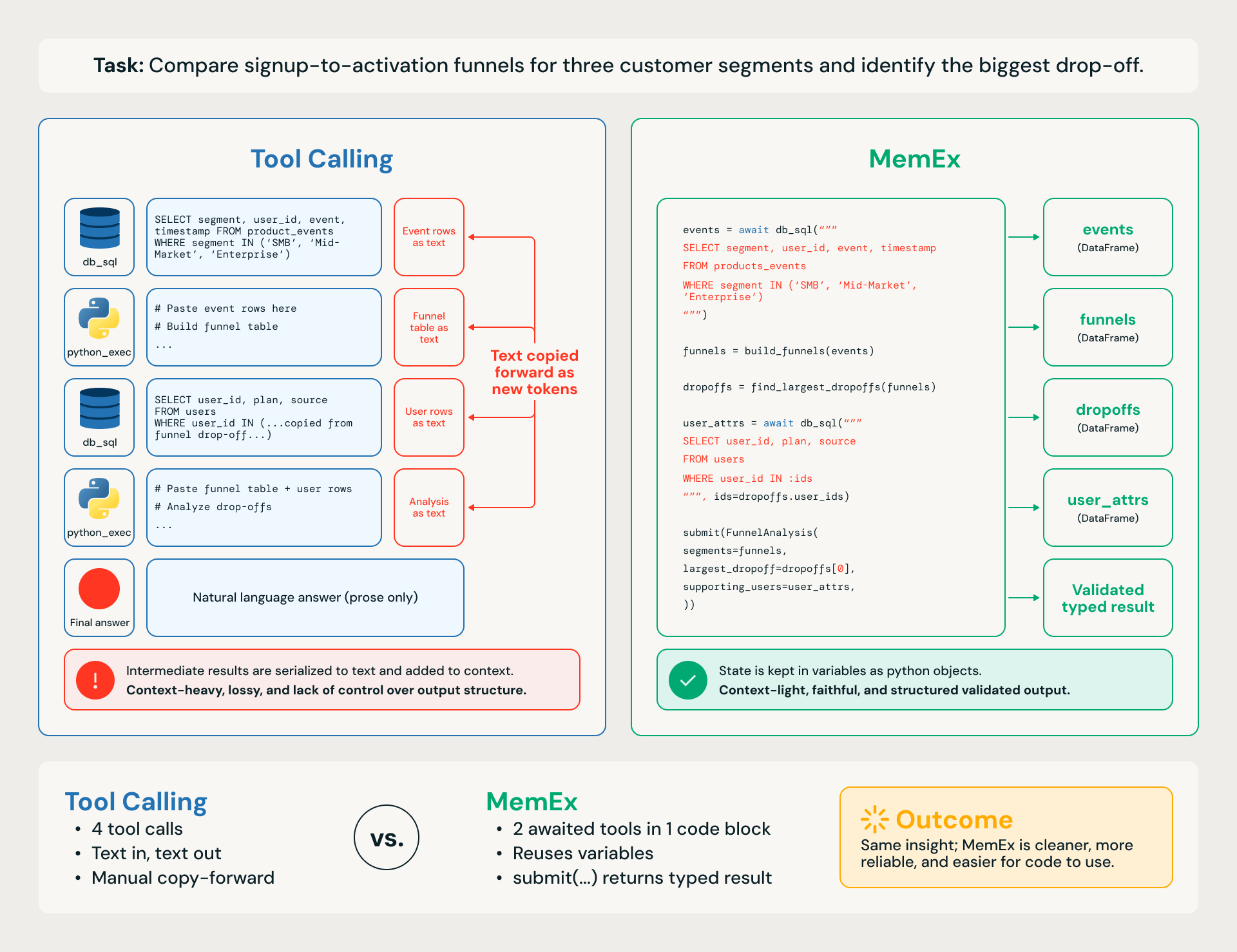
Considere uma tarefa empresarial concreta, como comparar funis de inscrição para ativação (signup-to-activation) de três segmentos de clientes e identificar a maior queda (Figura 1). O fluxo de trabalho tem quatro etapas:
- recuperar eventos de inscrição e ativação do data warehouse
- fazer o join deles por usuário
- calcular as taxas de conversão por segmento em cada etapa
- classificar as quedas entre os segmentos.
Um agente de Tool Calling equipado com python_exec funciona uma etapa de cada vez. Cada consulta SQL e cada computação programática é uma chamada de ferramenta separada, com DataFrames intermediários serializados em texto e colados novamente nos turnos subsequentes. O rastreamento (trace) consome muitos tokens, o que o torna sujeito a perdas, lento, caro e propenso a pequenos erros em cascata na tarefa downstream.
Um agente MemEx escreve o mesmo fluxo de trabalho como um único bloco de código: as consultas retornam DataFrames nativos no escopo, as funções auxiliares os compõem e a resposta final retorna como um objeto validado tipado via submit(). Mesmo pensamento, espaço de ação diferente.
Para tarefas que se decompõem em subproblemas, o agente pode gerar subagentes de dentro de um bloco. Ao gerar subagentes, o agente pai pode passar acesso compartilhado a qualquer objeto. Os subagentes são executados de forma adiantada (eagerly) em paralelo com o pai e podem retornar resultados ao agente principal após a conclusão. Por exemplo:
A decomposição recursiva se torna outra expressão no mesmo programa Python.
O MemEx é desenvolvido com base no aroll, a estrutura de rollouts de agentes da Databricks. O aroll já potencializa sistemas de produção como o Genie, o Supervisor Agent do Agent Bricks e esforços de pesquisa como o KARL. O MemEx se conecta ao mesmo loop de agente e ferramentas que o aroll já usa para Tool Calling.
Como o MemEx se comporta em tarefas de agentes empresariais?
Realizamos avaliações diretas (head-to-head) em 9 modelos de fronteira, onde comparamos chamadas de ferramentas estruturadas paralelas (Tool Calling) vs. blocos de código Python (MemEx). Sem ajuste de prompt (prompt tuning), sem adaptação por tarefa. Comparamos dois formatos de trabalho de agentes empresariais: leitura fundamentada em um grande corpus de texto (OfficeQA) e recuperação estruturada em um grande espaço de trabalho de diversos dados relacionais (Enterprise Structured Retrieval).
Em ambas as tarefas, o Agente MemEx é melhor e mais barato do que o Agente de Chamada de Ferramentas!
{kind=link}
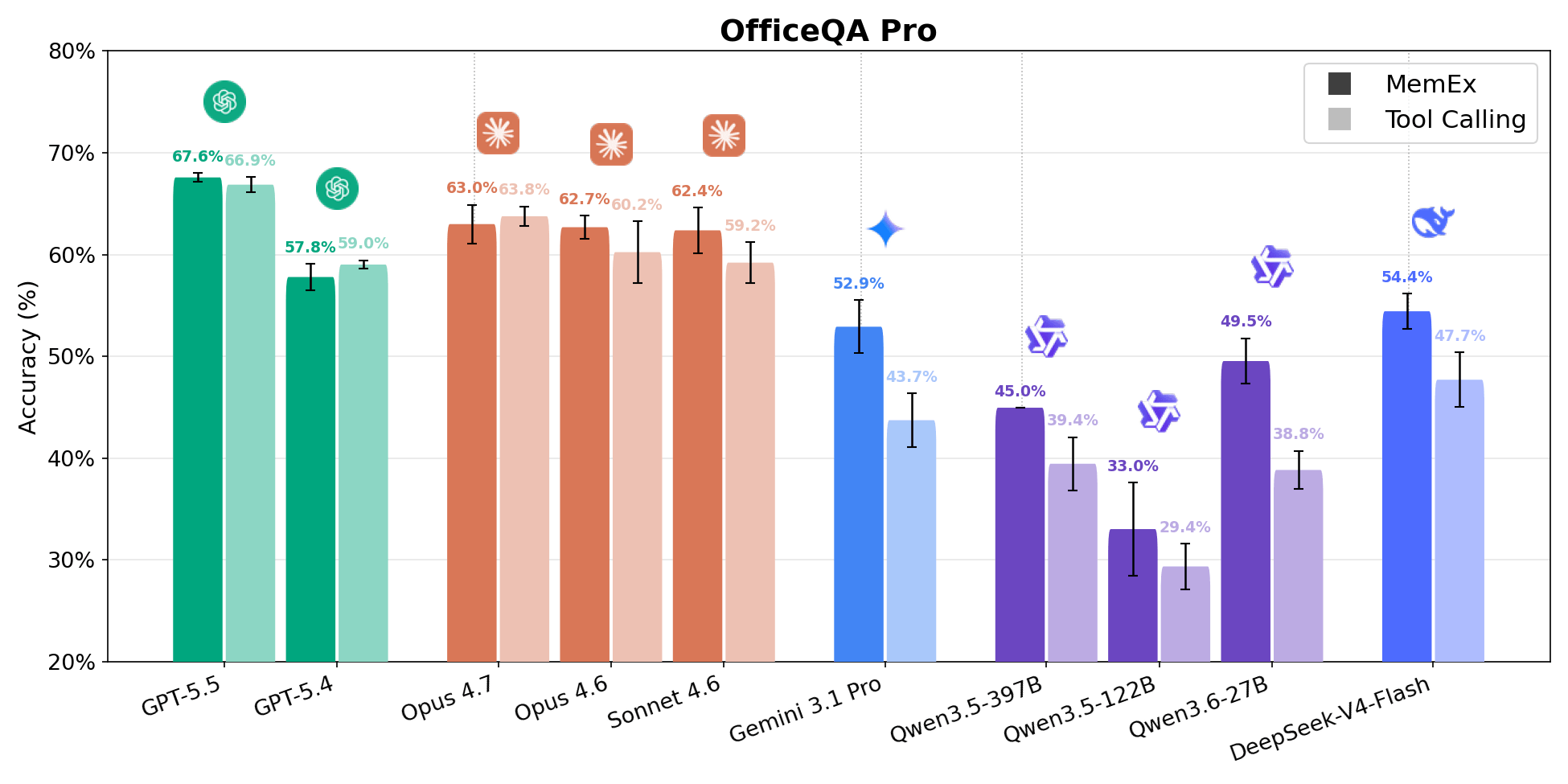
O OfficeQA Pro solicita que o agente responda a perguntas de raciocínio fundamentado sobre o corpus de Boletins do Tesouro dos EUA, cerca de 89.000 páginas que abrangem de 1939 até o presente. Uma pergunta típica exige a localização de evidências em vários documentos, a navegação em tabelas com hierarquias aninhadas e células mescladas, e a execução de cálculos nos dados recuperados. As respostas são avaliadas por correspondência estrita. Quatro dos cinco pontos na fronteira de Pareto de custo versus precisão são configurações do MemEx. O Gemini 3.1 Pro MemEx é o ponto mais barato da fronteira, a US$ 0,62 por execução (52,9% de precisão), e o Sonnet 4.6 MemEx se aproxima da precisão do GPT-5.5 com Chamada de Ferramentas a aproximadamente 70% do custo. Em nove modelos, o MemEx empata ou vence em todos eles. O grupo intermediário é o que mais se move, com o Qwen 3.6 27B e o Gemini 3.1 Pro ganhando cerca de 10 pontos percentuais.
{kind=link}
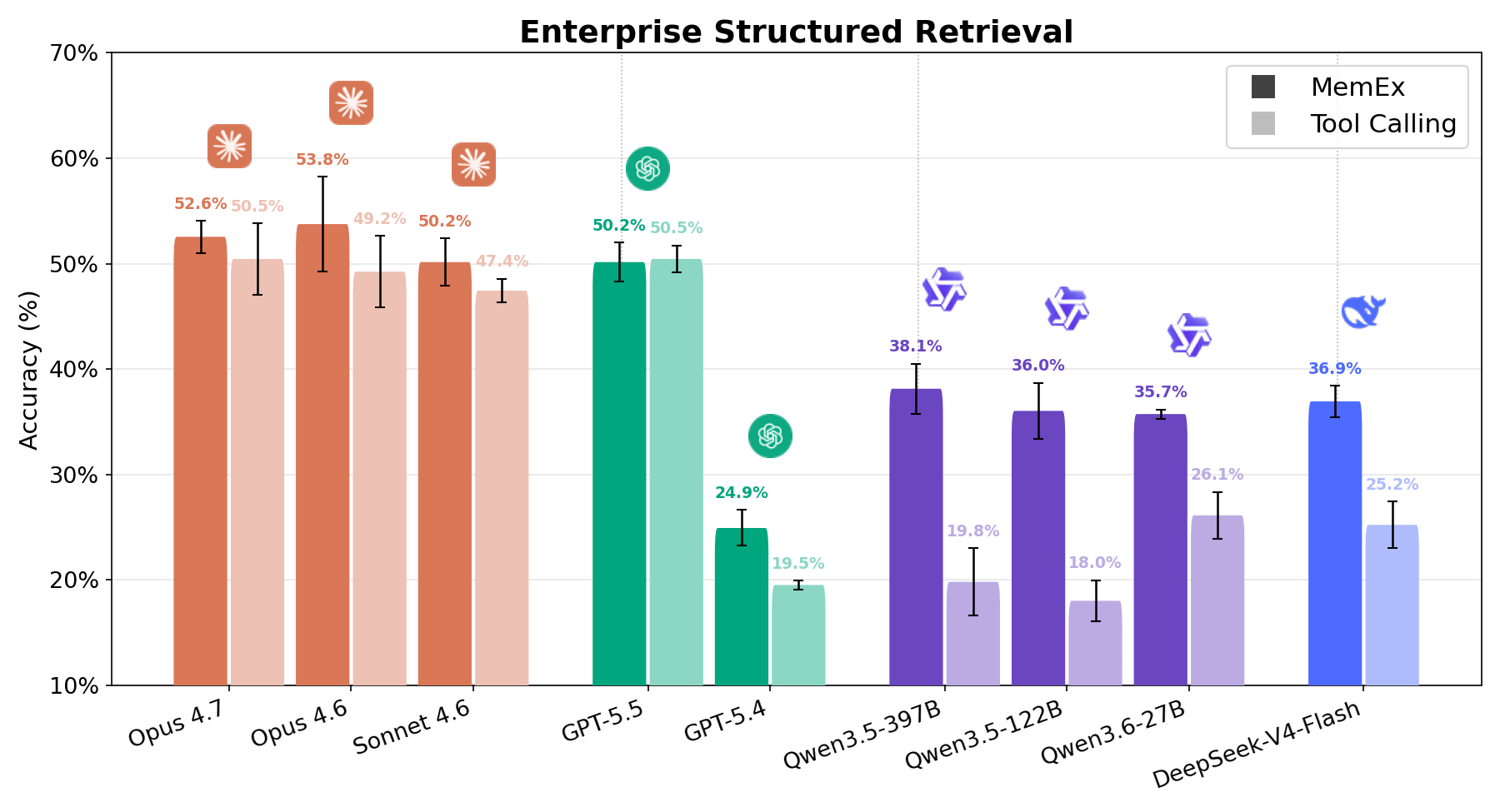
O Enterprise Structured Retrieval solicita que o agente responda a perguntas em linguagem natural sobre dados relacionais corporativos. O agente recebe ferramentas relacionadas à descoberta de esquema e à execução de consultas SQL, e deve usá-las para realizar a tarefa de análise de dados solicitada pelo usuário, geralmente com poucas informações sobre onde encontrar as informações relevantes no workspace diversificado. As respostas do agente são avaliadas em relação às respostas de ground truth usando validação de dados determinística e LLM como juiz. Como visto nas Figuras 1 e 6, todos os modelos apresentam forte ganho com o MemEx, exceto o GPT 5.5, que apresenta desempenho equivalente. Em termos de custo, o cenário é igualmente promissor. O Qwen 122B cai de 56 para 28 chamadas de ferramentas por execução, enquanto dobra sua pontuação; o Sonnet cai de 28 para 17; o Opus de 33 para 21.1 Isso resulta em reduzir o custo pela metade na maioria dos modelos. O padrão reflete o OfficeQA Pro: quanto mais difícil a tarefa, mais os objetos nativos e o estado persistente mostram seu valor.
Cada comparação foi executada sem prompt tuning, sem adaptação por tarefa e sem ajustes específicos do modelo. O loop do agente, os prompts do sistema e as ferramentas são idênticos em ambos os ambientes de teste. A única diferença é o espaço de ação: chamadas de ferramentas estruturadas em JSON/XML versus blocos de código Python do MemEx.
MemEx Operando em Trajetórias de Agentes
As trajetórias de agentes são, por si só, objetos volumosos. No paradigma de Chamada de Ferramentas, analisar trajetórias geralmente exige achatá-las em texto, o que gera perdas e consome muito contexto, tornando inviável analisar várias de uma vez. As trajetórias podem até abranger várias janelas de contexto, com compressão entre elas; como um LLM pode analisar um rastro que, por definição, não cabe em seu contexto? Mas uma trajetória é apenas mais um objeto Python, então o MemEx pode carregá-la diretamente no escopo e raciocinar sobre ela. Apresentamos duas aplicações: primeiro, um agente de auditoria baseado em MemEx que analisa as trajetórias do Qwen 3.6-27B no OfficeQA-Pro para explicar por que o MemEx supera a Chamada de Ferramentas; segundo, o escalonamento em tempo de teste no OfficeQA-Pro, com um agente MemEx que supera um agente equivalente de Chamada de Ferramentas.
O MemEx audita o MemEx: Análise de Trajetórias de Agentes
Para analisar por que a mudança para o MemEx resultou em um aumento de desempenho para modelos de código aberto, como o Qwen 3.6-27B, recorremos ao próprio MemEx para explicar. Em particular, instanciamos um agente de auditoria que recebe uma pergunta do OfficeQA, sua resposta de ground truth e seis trajetórias de solução (3 de um agente MemEx e 3 de um agente de Chamada de Ferramentas) diretamente em seu escopo Python, e solicita a um agente Sonnet 4.6 baseado em MemEx que classifique cada trajetória incorreta ao longo de uma taxonomia de quatro eixos de modos de falha.
| Eixo de Falha | Definição | Erros do MemEx | Erros de Chamada de Ferramentas |
|---|---|---|---|
Source Selection | O modelo foca no documento ou tabela incorreta | 32 | 45 |
Interpretation | O modelo recupera os dados corretos, mas extrai o significado errado | 28 | 38 |
Search Strategy | O modelo para cedo demais ou passa da resposta | 6 | 15 |
Execution | Bugs na computação intermediária ou na formatação da saída final | 3 | 6 |
Total | - | 69 | 104 |
Nossa análise se concentra em 66 perguntas do OfficeQA Pro em que nem todas as seis tentativas foram corretas ou incorretas, gerando 173 trajetórias. Os quatro eixos se dividem em dois grandes grupos:
- Erros de fundamentação (~83%): Casos em que o modelo recupera um valor preliminar em vez de um valor revisado, interpreta incorretamente terminologias ambíguas (por exemplo, variância amostral vs. populacional, ou precisão de arredondamento para "centésimos") ou extrai a coluna incorreta de uma tabela válida.
- Erros de Estratégia de Busca e Execução: Erro no planejamento da sequência de recuperação ou falha ao integrar corretamente os dados recuperados nos cálculos finais.
Para erros de Estratégia de Busca e Execução, o MemEx mostra que o agente MemEx teve uma redução de 2x nos erros em comparação com a Chamada de Ferramentas. Isso ocorre porque, no MemEx, a recuperação pode ser armazenada diretamente em variáveis Python, permitindo que o modelo evite copiar valores da saída de uma ferramenta para a próxima chamada de ferramenta, além de possibilitar que várias chamadas de ferramentas sejam processadas em lote em um único turno. A Chamada de Ferramentas não possui esse atalho e precisa sempre transcrever valores entre as chamadas, o que às vezes gera falhas. Por exemplo, em uma trajetória, um valor de 3.501 de um documento recuperado foi digitado incorretamente na chamada seguinte como 3531.
Pensamento Paralelo de Agentes com o MemEx
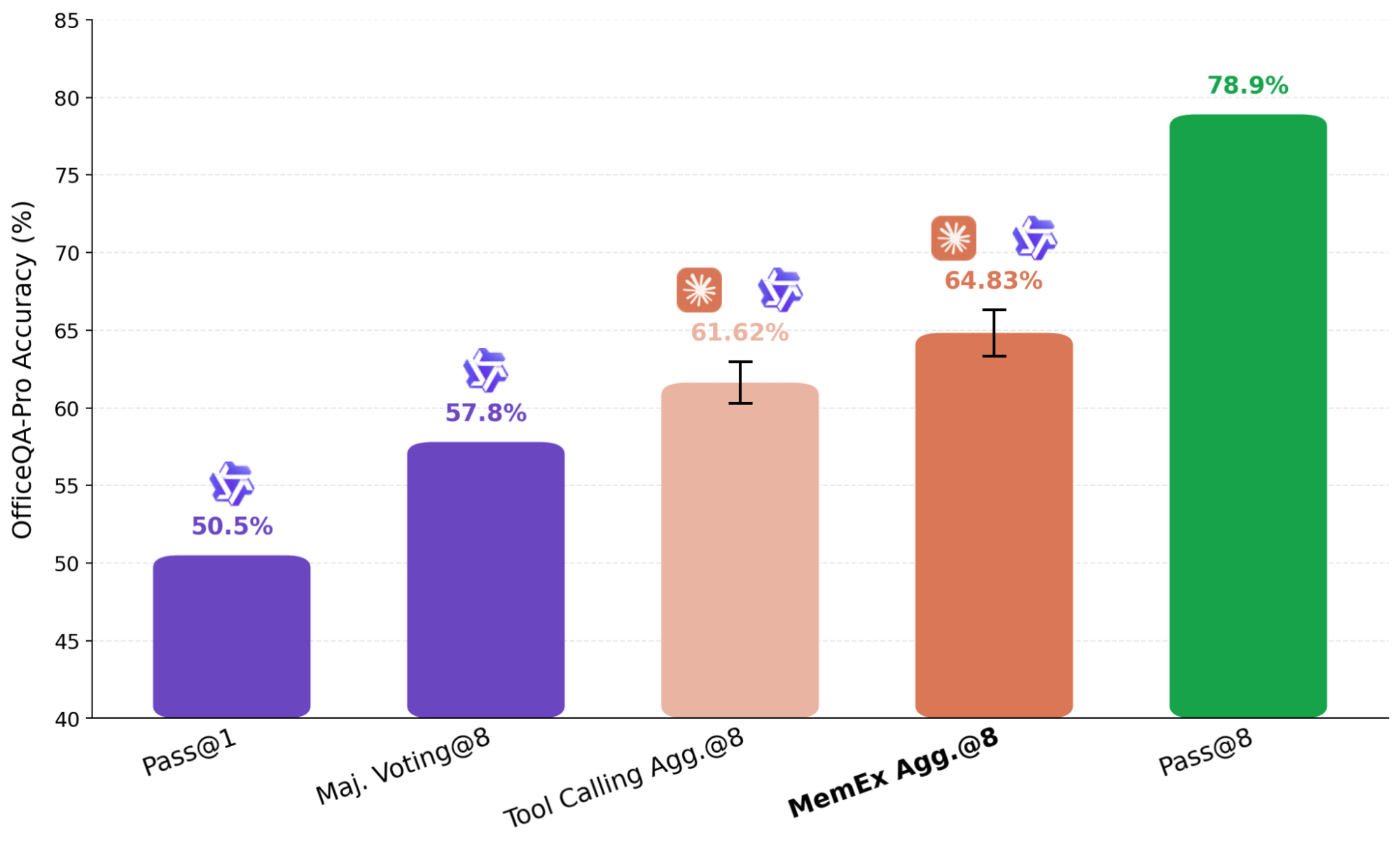
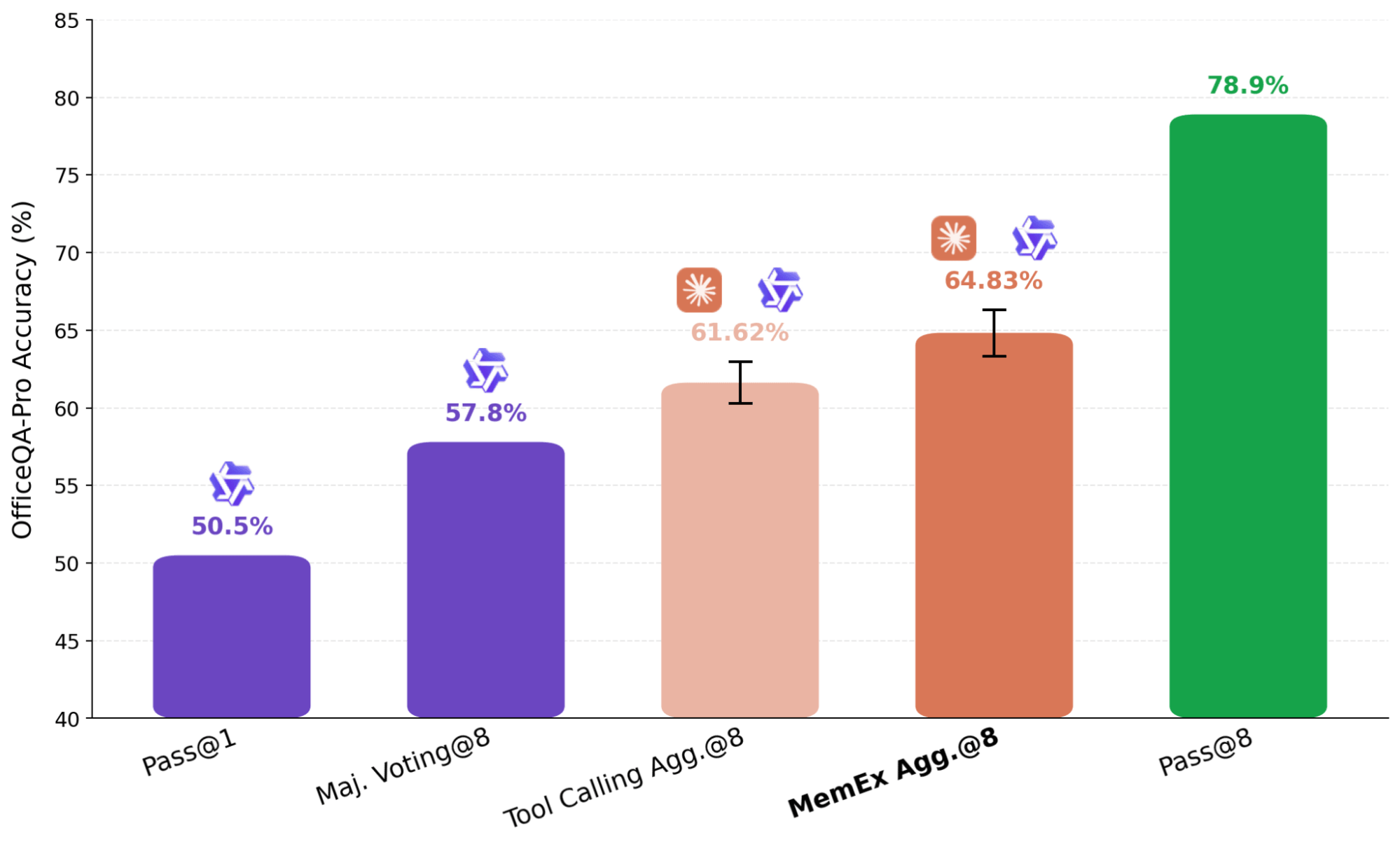
Uma abordagem comum para escalonar a computação em tempo de teste é o pensamento paralelo, no qual várias execuções independentes de uma tarefa são agregadas em uma resposta final. No pensamento paralelo de agentes, como a abordagem usada no KARL, resumos das tentativas independentes são passados para um agente agregador. Essa etapa de sumarização gera perdas, mas é inevitável na configuração padrão, pois colocar várias trajetórias completas na janela de contexto de um modelo é inviável. Com o MemEx, podemos carregar essas trajetórias como variáveis de escopo, contornando completamente a representação com perdas.
{kind=link}
No resultado mostrado na Figura 7, usamos o Claude Sonnet 4.6 como um agregador sobre oito trajetórias do Qwen-3.6-27B geradas de forma independente. Para garantir que o agregador não esteja simplesmente resolvendo o problema novamente por conta própria, removemos suas ferramentas de busca de arquivos, restringindo-o à verificação e seleção. O agente baseado em MemEx, que recebe as trajetórias completas como entrada, supera o agente equivalente de Tool Calling que recebe apenas seus resumos. Em um dos casos, o agregador de trajetórias detectou um erro de duplicação em um boletim anterior ao ler as saídas brutas das ferramentas a partir das trajetórias de entrada; o agregador de Tool Calling não conseguiu verificar a alegação de dados duplicados devido à sua entrada estar limitada aos resumos, recorrendo à votação por maioria na fonte corrompida.
Arquitetura do MemEx
Os agentes de Tool Calling emitem uma ou mais chamadas de ferramentas estruturadas por turno (JSON ou XML), cada uma em conformidade com um esquema de ferramenta predefinido, no loop de ação-observação introduzido pelo ReAct (Yao et al., 2022). O CodeAct (Wang et al., 2024) substituiu esse formato por um kernel Python persistente: o agente emite código Python arbitrário, e as variáveis e definições de função são mantidas entre os turnos. Variantes de produção do mesmo paradigma incluem o Programmatic Tool Calling (PTC) da Anthropic e o Cloudflare Code Mode; o PTC também mantém o estado entre as requisições reutilizando o mesmo contêiner, enquanto o Code Mode não faz isso. O MemEx estende esse paradigma com quatro adições adicionais:
- Integração direta de ferramentas (drop-in) com preservação dos esquemas de parâmetros.
- Escopo Python ativo no início do rollout.
submit()tipado para retornos estruturados.spawn_agent()não bloqueante para subagentes paralelos, generalizando os Modelos de Linguagem Recursivos (Zhang et al., 2025).
A implementação baseia-se em três escolhas de design:
Código como ação, em um REPL persistente
A ação do agente é um bloco de código Python arbitrário, executado em um namespace que persiste entre os turnos. Ferramentas, objetos de escopo e resultados anteriores vivem todos nesse namespace. O agente lê as observações (stdout, valores de retorno, erros) e, em seguida, escreve mais código. O mesmo loop de observação-ação que executa o Tool Calling executa o MemEx; apenas o espaço de ação muda.
Substituição direta (drop-in) para Tool Calling
As ferramentas de Tool Calling existentes são autoinjetadas como funções Python, incluindo esquemas de parâmetros e metadados de tipo de retorno. Mudar um agente existente de Tool Calling para o MemEx é apenas uma alteração de configuração.
Execução agnóstica ao backend
O mesmo código de agente é executado em três backends, escolhidos no momento da configuração:
- Em processo (in-process) para rápida iteração durante a pesquisa.
- Subprocesso para isolamento durante a avaliação.
- Pool para geração em lote de alto rendimento (dados de treinamento, rollouts em larga escala).
Para implantações em produção, o kernel pode ser substituído por um sandbox hospedado, como o Managed Agents da Anthropic. O mesmo código de agente, com isolamento de sistema de arquivos, controles de saída de rede e limites de recursos gerenciados pelo host.
O que vem a seguir?
O MemEx está chegando às mãos do seu agente. Estamos fazendo o lançamento dele nos agentes nativos da Databricks e no Agent Bricks: se você desenvolve com agentes da Databricks hoje, em breve poderá usar o MemEx.
Estamos realizando o pós-treinamento dos nossos modelos para o espaço de ação do MemEx. O próprio MemEx é o substrato: ele gera dados sintéticos, executa verificadores agênticos e alimenta o loop de treinamento.
Autores: Ashutosh Baheti, Shubham Toshniwal, Arnav Singhvi, Krista Opsahl-Ong, Sean Kulinski, Sam Havens, Jonathan Li, Marco Cusumano-Towner, Jonathan Chang, Wen Sun, Alexander Trott, Jonathan Frankle, Xing Chen, Matei Zaharia
1 No MemEx, as chamadas de ferramentas são blocos de código Python que podem ter análise de dados ou outras ferramentas chamadas como funções assíncronas (async).
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.