TEST - Um Guia Compacto para Ajuste Fino e Construção de LLMs Personalizados
por Team Databricks
Introdução
A IA Generativa (GenAI) tem o potencial de democratizar a IA, transformar todos os setores, apoiar todos os funcionários e engajar todos os clientes. Para ser mais útil, os modelos de GenAI precisam de um profundo entendimento dos dados corporativos de uma organização. Até hoje, as técnicas mais populares para dar aos modelos de GenAI conhecimento sobre sua empresa são engenharia de prompt, geração aumentada por recuperação (RAG), cadeias e agentes. No entanto, essas técnicas atingem limites ao usar modelos gerais não adaptados a domínios e aplicações específicas. Para melhorar os resultados gerados e reduzir custos, os desenvolvedores de aplicações de GenAI devem recorrer à criação de modelos personalizados por meio de ajuste fino (fine-tuning) ou pré-treinamento.
O ajuste fino especializa um modelo de IA existente para um domínio ou tarefa específica, treinando-o adicionalmente em um conjunto menor de dados personalizados. As técnicas incluem ajuste fino supervisionado para seguir instruções ou chat, bem como pré-treinamento contínuo. O pré-treinamento cria um modelo totalmente novo, treinando-o do zero em dados totalmente personalizáveis. Todas essas técnicas permitem que os desenvolvedores criem propriedade intelectual e diferenciação para seu domínio ou aplicação, com o potencial de criar modelos melhores e mais precisos e de usar arquiteturas de modelos menores e de menor custo.
Neste guia para criação de modelos personalizados, abordamos:
- Motivação: Por que e quando você deve criar um modelo de GenAI personalizado?
- Princípios: Quais práticas de alto nível devem guiar sua estratégia e implementação ao criar modelos personalizados?
- Técnicas: Como você pode criar modelos personalizados? Quais técnicas e “armadilhas” você deve ter em mente para preparação de dados, treinamento e avaliação?
Este guia é voltado para profissionais que planejam criar modelos personalizados. Assumimos o entendimento de GenAI e modelos de linguagem grandes (LLMs), incluindo termos como engenharia de prompt, RAG, agentes, ajuste fino (fine-tuning) e pré-treinamento. Para material introdutório, consulte mais sobre IA Generativa e LLMs.
Sobre o Databricks
Databricks fornece ferramentas unificadas para construir, implantar e monitorar soluções de IA e ML — desde a criação de modelos preditivos até os mais recentes GenAI e LLMs. Construído sobre a Plataforma de Inteligência de Dados Databricks, o Databricks permite que as organizações integrem de forma segura e econômica seus dados corporativos no ciclo de vida da IA com qualquer modelo de GenAI. Permitimos que os clientes implantem, governem, consultem e monitorem modelos ajustados ou pré-implantados pelo Databricks, como Meta Llama 3, DBRX ou BGE, ou de outros provedores de modelos como Azure OpenAI GPT-4, Anthropic Claude, AWS Bedrock e AWS SageMaker. Para personalizar modelos com dados corporativos, o Databricks oferece todos os padrões arquitetônicos, desde engenharia de prompt, RAG, ajuste fino e pré-treinamento.
O Databricks oferece recursos de ajuste fino e pré-treinamento de GenAI incomparáveis a qualquer outra plataforma de IA. Em junho de 2024, os clientes do Databricks haviam criado mais de 200.000 modelos de IA personalizados no ano anterior. Além disso, o Databricks possui modelos pré-treinados que podem ser usados diretamente pelos clientes. Em março de 2024, o Databricks lançou o DBRX, um novo LLM de código aberto de alto desempenho que foi pré-treinado do zero, sob uma licença comercialmente viável. Em junho de 2024, Databricks e Shutterstock lançaram outro modelo pré-treinado, Shutterstock ImageAI, Powered by Databricks, um modelo de ponta de texto para imagem.
A infraestrutura e a tecnologia que usamos para construir esses modelos de alto desempenho são as mesmas infraestrutura e tecnologia fornecidas aos nossos clientes. Veja nossas histórias de clientes Databricks para ler sobre sucessos em dados e IA em todos os setores.
Motivação: Por que fazer ajuste fino ou criar LLMs personalizados?
Os clientes geralmente começam a criar modelos de GenAI personalizados quando os modelos existentes têm limitações dolorosas em qualidade, custo ou latência. Os detalhes variam para cada caso de uso, mas exemplos incluem:
- “Preciso de um modelo para gerar a linguagem de consulta especial do meu produto. Posso fazer isso usando APIs de modelo e prompting com poucos exemplos (few-shot prompting), mas é muito lento e caro.”
- “Meu bot RAG funciona bem, mas está usando uma API de modelo grande e poderosa que é muito cara para meu caso de uso de alto volume. Não preciso de um modelo tão geral, então quero fazer o ajuste fino de um modelo pequeno, direcionado e barato.”
- “Não consigo encontrar um modelo de código aberto que seja bom no idioma X, então quero criar um modelo adaptado para entender X.”
Os modelos de GenAI mais famosos são modelos gerais, feitos para fazer (quase) tudo. Embora impressionantes, esses modelos são muito grandes e caros para a maioria dos casos de uso, e eles não sabem nada sobre seus dados proprietários ou sua aplicação. Em todos os exemplos acima, a criação de um modelo personalizado e especializado aumentou a qualidade ou diminuiu o custo e a latência. O modelo personalizado se tornou propriedade intelectual e forneceu uma vantagem competitiva para o produto do cliente.
Uma motivação menos comum, mas mais premente, para criar modelos personalizados vem de preocupações legais ou regulatórias, especialmente em setores mais regulamentados. Alguns clientes querem ou precisam de controle total sobre seus modelos para gerenciar riscos, como acusações de uso ilegal de conteúdo para treinamento de modelos. Ao pré-treinar um modelo totalmente personalizado, você pode saber e provar exatamente como o modelo foi criado.
Então, como você pode começar? Embora a GenAI seja um campo de pesquisa complexo, pode ser simples começar a personalizar modelos de GenAI. Existe um caminho natural do ajuste fino básico ao pré-treinamento complexo, e a plataforma Databricks suporta todo esse fluxo de trabalho. Ao seguir este caminho, você acumulará expertise e dados que alimentarão tipos futuros e mais complexos de personalização de modelos.
Princípios: Quando e Como Você Deve Fazer Ajuste Fino ou Criar Modelos Personalizados?
Quando, por que e como você deve criar modelos personalizados?
Em um nível alto, os sistemas de GenAI podem ser personalizados de duas maneiras:
- IA Composta: Dadas uma ou mais modelos existentes, você pode construir RAG, agentes e outros sistemas de IA compostos em torno desses modelos
- Modelos Personalizados: Você pode personalizar um modelo existente (ajuste fino) ou criar um modelo totalmente novo (pré-treinamento)
Essas duas opções podem ser combinadas, como RAG usando um LLM com ajuste fino. Tais combinações — e a velocidade do desenvolvimento de GenAI — podem tornar o planejamento e a criação de aplicações de GenAI complexos. Para simplificar sua abordagem, recomendamos três princípios orientadores.
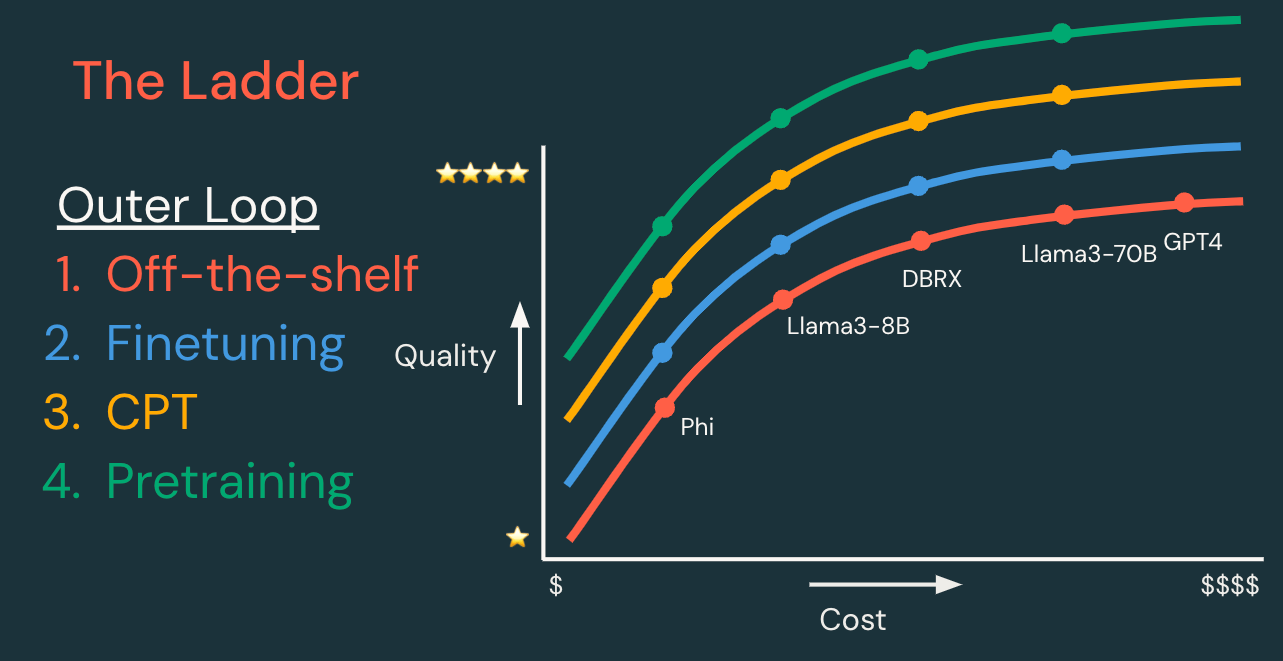
Princípio 1: Comece pequeno e avance gradualmente
Para qualquer aplicação de GenAI, recomendamos que você comece de forma simples e adicione complexidade conforme necessário. Isso pode significar começar com um modelo existente (como as APIs de Modelo de Fundação Databricks) e fazer engenharia de prompt simples. Em seguida, adicione técnicas conforme necessário para melhorar suas métricas de qualidade, custo e velocidade.
A “escada” de técnicas pode ser dividida em loops de desenvolvimento interno e externo, descritos abaixo.
Loop externo: Escada de personalização de modelos | ||||
Cada etapa tem o potencial de criar um modelo de maior qualidade, menor custo e/ou menor latência. | Dados necessários | Tempo de desenvolvimento | Custo de desenvolvimento | |
Modelo existente | Comece com um modelo ou API de modelo existente e itere primeiro no loop interno. | Nenhum, ou dados para RAG | Horas | $ |
Ajuste fino supervisionado | Personalize um modelo para lidar melhor com sua tarefa específica. “Espere consultas como esta e retorne respostas como aquela.” | Centenas a dezenas de milhares de exemplos | Dias | $$ |
Retreinamento contínuo | Personalize um modelo para entender melhor seu domínio. “Aprenda a linguagem deste nicho de domínio de aplicação.” | Milhões a bilhões de tokens | Semanas | $$$ |
Pré-treinamento | Crie um novo modelo para ter controle total, personalização e propriedade. “Aprenda tudo do zero!” | Bilhões a trilhões de tokens | Meses | $$$$$$ |
Loop interno: Técnicas compostas de IA | |
Cada técnica abaixo pode melhorar a qualidade da geração para um determinado modelo. Essas técnicas são listadas em ordem (aproximada) de complexidade, mas podem ser misturadas e combinadas. | |
Engenharia de prompt | Crie prompts específicos para a tarefa para guiar o comportamento do modelo. |
Prompt de poucos exemplos (few-shot prompting) | Forneça dados em prompts para ensinar modelos no momento da inferência. |
RAG | Forneça dados específicos da consulta aos modelos como contexto adicional. |
Agentes | Forneça aos modelos ferramentas chamáveis e/ou fluxo de controle complexo. |
Adotar uma técnica do loop interno é relativamente barato e rápido, em comparação com subir um degrau no loop externo. Portanto, sempre que você subir no loop externo, vale a pena iterar em algumas ou todas as técnicas do loop interno. Essa designação “interna” versus “externa” é o inverso do que você esperaria da arquitetura do sistema — o loop “interno” de IA composta envolve o loop “externo” do seu modelo. Chamamos a personalização do modelo de loop “externo” porque ele é o loop externo em termos de seu fluxo de trabalho, conforme determinado pelos custos relativos dos loops interno e externo.
Princípio 2: Seja orientado por dados
Antes de investir seriamente em qualquer projeto, defina cuidadosamente sua régua de medição de sucesso e siga as práticas populares de desenvolvimento orientado por avaliação.
No nível de sistemas de IA, considere métricas de qualidade, custo e latência.
- Qualidade provavelmente envolverá várias métricas: precisão, feedback do usuário, toxicidade, etc.
- Custos para sistemas em produção geralmente se concentram na inferência do modelo e no fornecimento de dados
- Latência pode significar latência de ponta a ponta, ou tempo para o primeiro token para aplicações mais interativas
Quais números essas métricas devem atingir para declarar sucesso? Quais restrições rígidas você tem nessas métricas para garantir uma boa experiência do usuário, retorno positivo sobre o investimento ou outros requisitos de negócios?Veja esta palestra de nosso cientista-chefe de IA para mais discussões.
No nível do projeto e de negócios, analise o retorno sobre o investimento.
- Custos (investimento) devem ser divididos em duas fases:
- Custos de desenvolvimento podem incluir custos de computação e humanos para preparação de dados, treinamento de modelo e desenvolvimento de sistema
- Custos contínuos podem incluir fornecimento e manutenção de modelos e dados em horas de pessoal
- Impacto nos negócios (retorno)
- Receita ou outros objetivos de negócios e resultados-chave (OKRs) podem variar de economia de tempo humano (para um bot de suporte GenAI) a receita direta (para um produto com tecnologia GenAI)
- Criação de PI, como novos modelos ou dados, pode ser o impacto mais difícil de medir, mas o maior a longo prazo. Todos podem usar as mesmas APIs de provedores de modelos, mas apenas você pode usar seus modelos e dados proprietários.
Seus objetivos orientados por dados informarão suas escolhas sobre personalização de modelos (princípio 1). Por exemplo, se você atingir suas métricas de qualidade, mas exceder seus limites de custo usando uma API de modelo cara, você pode passar a ajustar um modelo menor e mais eficiente, adaptado à sua tarefa específica, para reduzir custos e manter a qualidade. O ajuste fino incorrerá em custos de desenvolvimento extras, mas reduzirá os custos contínuos — e reduzirá o custo geral a longo prazo.
Princípio 3: Mantenha o pragmatismo
Avaliar modelos e sistemas GenAI é desafiador. Técnicas de ajuste fino e pré-treinamento são uma área de pesquisa em alta. O entusiasmo acadêmico e da indústria (e os LLMs) estão gerando muito mais conteúdo do que se pode ler. Essas fontes de confusão tornam desafiador saber quando usar quais técnicas. (“Preciso de LoRA? O que é aprendizado curricular? Qual arquitetura de modelo é melhor?”)
Muitas pessoas novas em GenAI ouviram que você pode jogar montanhas de dados em GenAI e ele aprenderá coisas incríveis. Modere essas expectativas. A quantidade de dados importa, mas a qualidade dos dados, as técnicas de treinamento e a avaliação também importam.
Clientes Databricks podem contar parcialmente com a orientação integrada no Databricks durante sua jornada na escada da personalização de GenAI. Essa orientação varia de APIs simples para modelos gerais ao Agent Bricks Custom Agents para RAG e agentes, a uma interface de usuário e API para ajuste fino e até mesmo a uma API guiada para pré-treinamento.
No entanto, quanto mais você avançar na personalização, mais técnicas e decisões você precisará tomar. Recomendamos que você mantenha o pragmatismo. Técnicas que funcionaram em pesquisa podem não funcionar em aplicações da vida real. Modelos bons para uma tarefa podem ser ruins para outra. As melhores técnicas mudarão com o tempo. Para navegar nessa complexidade, mantenha os princípios 1 e 2 em mente: Defina sua estrela guia e siga-a com base em dados e métricas.
Também recomendamos fazer parceria conosco. Além de sua equipe imediata Databricks, nossa equipe de Serviços Profissionais pode guiá-lo desde provas de conceito iniciais até execuções completas de pré-treinamento. Nossa equipe de Pesquisa Mosaic faz parceria com muitos clientes para execuções de pré-treinamento, dando-lhes acesso a conhecimento e conselhos de ponta.
Técnicas para Construir LLMs Personalizados
Dado que você deseja subir no loop externo de personalização de modelos, como você deve abordar as técnicas introduzidas com o princípio 1? Esta seção discute a avaliação e, em seguida, mergulha nas principais técnicas de personalização.
Nota: Este guia não foca no loop interno de iteração em um modelo fixo. Para mais informações sobre essas técnicas, consulte os cursos Fundamentos de IA Generativa e Engenharia de IA Generativa com Databricks.
Esta seção desenvolve as técnicas de personalização descritas anteriormente no loop externo do princípio 1. Nós as listamos aqui e observamos que sua escolha de técnica será amplamente guiada pelos dados que você tem disponíveis (princípio 2).
Loop externo: Escada de personalização do modelo | ||
Tipo de dado necessário | Orientação de tamanho de dados | |
Modelo existente | NA | Nenhum, ou dados para RAG |
Ajuste fino supervisionado | Dados de consulta-resposta (ou dados “rotulados” de outra forma) | Pelo menos centenas a dezenas de milhares de exemplos |
Pré-treinamento contínuo | Texto “bruto” para predição do próximo token | Milhões a bilhões de tokens, ou 1%+ do conjunto de treinamento original |
Pré-treinamento | Texto “bruto” para predição do próximo token | Bilhões a trilhões de tokens |
Na próxima seção, cobriremos cada técnica com mais detalhes, começando com orientações que permanecem constantes em todas as técnicas.
Dados
Seus dados devem corresponder ao seu caso de uso. Se você está ajustando um modelo para responder de uma certa maneira, então seus dados de treinamento devem demonstrar respostas “boas”. Se você está fazendo pré-treinamento contínuo para entender um domínio específico, seus dados devem representar esse domínio.
Aborde questões legais e de licenciamento desde o início. Ao usar dados públicos, especialmente para pré-treinamento, esteja ciente de que alguns conjuntos de dados públicos são bem curados para evitar complicações legais e alguns conjuntos de dados não são. Ao usar seus próprios dados corporativos, certifique-se de ter certeza da proveniência, especialmente se os dados vieram de clientes ou de modelos GenAI com licenças restritivas.
Colete dados cedo e com frequência. Consultas, respostas e feedback do usuário de seus aplicativos hoje podem se tornar entradas para o ajuste e treinamento do seu modelo GenAI no futuro — mas apenas se você for cuidadoso com isso. Muitos modelos proprietários e de código aberto vêm com restrições de uso, portanto, rastreie a proveniência das respostas geradas cuidadosamente. Para lhe dar flexibilidade futura, evite misturar modelos e dados com licenças incompatíveis e prefira licenças abertas.
Use dados sintéticos com cuidado. Dados sintéticos podem ser úteis, mas dados corporativos genuínos são quase sempre mais valiosos. Dados “reais” podem ser usados para informar LLMs sobre como gerar dados sintéticos, o que você aprenderá mais tarde neste guia. Dados sintéticos ainda são uma área de pesquisa ativa.
Modelos
Esteja ciente de modelos base vs. instrução/chat. A maioria dos principais lançamentos de LLM inclui modelos base (pré-treinados, mas não ajustados) e variantes de seguimento de instrução ou chat (ajustados). Veja nossas recomendações sobre qual tipo usar nas seções seguintes.
Use os modelos sugeridos pelos recursos do Databricks. O Mosaic Research estuda arquiteturas de modelos de ponta, compartilha algumas principais recomendações para modelos GenAI e prioriza esses modelos principais no Databricks Model Training e outros recursos.
Desça para código mais personalizado, se necessário. Se os modelos ou métodos de treinamento padrão não atenderem às suas necessidades, você sempre pode “descer na pilha” e usar código mais personalizado. Os clusters acelerados por GPU da Databricks (computação geral) e o Databricks Model Training (computação especializada em deep learning) suportam código de treinamento arbitrário para GenAI e outros modelos de deep learning.
Identifique modelos que mostram promessa para seu caso de uso. Antes do ajuste, examine se o modelo genérico mostra promessa para sua aplicação. “Promessa” pode ser medida por testes manuais ad hoc usando o AI Playground ou um teste mais rigoroso usando um conjunto de dados de benchmark ou seu conjunto de dados de avaliação personalizado. Os testes podem exigir treinamento em pequena escala. Para ajuste fino, o modelo melhora após o ajuste fino em um pequeno conjunto de 100 exemplos? Para pré-treinamento, o modelo melhora com o pré-treinamento contínuo em um conjunto de dados específico?
Lembre-se de suas restrições. Escolha o tamanho do seu modelo com base em suas restrições de custo e latência no tempo de inferência. Lembre-se também de que construir modelos personalizados é apenas o loop externo; você também pode otimizar custos e latência no loop interno, como roteando solicitações mais simples para modelos menores.
Dica: Seu trabalho em técnicas mais simples não será em vão, pois essas técnicas formam uma sequência. Por exemplo, depois de pré-treinar um modelo, você geralmente faz o ajuste fino supervisionado em seguida.
Avaliação
O Princípio 2 recomenda ser orientado por dados, com métricas. Antes de mergulharmos nos detalhes de como construir modelos personalizados, abordaremos as métricas de avaliação e qualidade que podem guiar seu trabalho.
Assim como na engenharia de software, recomendamos seguir uma pirâmide de testes.
Analogia de teste de software | Velocidade/custo vs. fidelidade | Exemplos |
Testes unitários | Medidas proxy rápidas e baratas | Testes com respostas certas/erradas |
Testes de integração | Testes de velocidade/custo médios | Métricas LLM-como-juiz em conjuntos de dados de benchmark |
Testes de ponta a ponta | Testes lentos, mas realistas | Feedback humano |
Os exemplos na pirâmide de testes acima são escritos genericamente e evitam a questão de testar modelos (o loop externo do princípio 1) vs. sistemas de IA compostos (loop interno). Ao construir um modelo personalizado, você desejará testar tanto o modelo em si quanto os sistemas de IA que o utilizarão. Por exemplo, “métricas LLM-como-juiz” podem ser usadas para testar a capacidade de um modelo de seguir instruções, e elas podem ser usadas para testar as métricas de recuperação e as métricas de resposta a perguntas de um sistema RAG.
Modelos e tarefas específicos vs. gerais
Sua pirâmide de testes será muito diferente ao ajustar um modelo para uma tarefa específica em comparação com o pré-treinamento de um modelo de propósito geral. Ser orientado por dados e métricas significa adaptar sua pirâmide de testes aos casos de uso downstream do seu modelo.
Se você está ajustando um modelo para uma tarefa específica, lembre-se de começar pequeno (princípio 1). Por exemplo, você pode:
- Construir um conjunto de dados “dourado” de consulta-resposta para avaliação. Certifique-se de que ele esteja balanceado entre consultas e tópicos potenciais.
- Usar métricas LLM-como-juiz para escalar a avaliação. Escolha ou personalize métricas para sua tarefa específica.
- Usar avaliação humana ou do usuário como um teste final
À medida que você inicia o pré-treinamento contínuo ou o pré-treinamento completo, suas avaliações podem se tornar mais complexas. Ao planejar sua pirâmide de testes, divida sua avaliação pelas diferentes habilidades que você acredita que seu modelo precisa para que você possa focar nas áreas importantes. Isso pode significar:
- Habilidades como conhecimento geral, lógica ou compreensão de leitura
- Domínios como finanças, direito ou saúde
- Idiomas, incluindo idiomas naturais ou linguagens de programação
- Outras dimensões, do comprimento do contexto às salvaguardas integradas
Dicas:
- Adapte sua avaliação aos seus casos de uso. Por exemplo, se você estiver modificando um modelo para lidar com comprimentos de contexto mais longos, lembre-se de que as métricas de perplexidade de pré-treinamento contínuo não são suficientes. Seu conjunto de dados de avaliação também deve incluir tarefas de contexto longo.
- Teste tanto o aprendizado quanto o esquecimento. Se você estiver fazendo pré-treinamento contínuo para melhorar a compreensão de um modelo sobre um idioma específico (por exemplo, malaio), considere se seus casos de uso exigem que esse modelo mantenha sua compreensão existente de outros idiomas (por exemplo, inglês). Se for o caso, sua avaliação deve testar tanto o malaio quanto o inglês.
- Teste o que seus clientes realmente usarão. Se você estiver pré-treinando um novo modelo (base), provavelmente fará o ajuste fino de instruções para criar a versão do modelo que seus clientes realmente usarão. Sua avaliação final (de ponta a ponta) deve ser no modelo ajustado, não no modelo base.
Exemplos da construção do DBRX
Em maio de 2024, a Databricks lançou o DBRX, um LLM de código aberto de ponta (na época). Seu conjunto de avaliação fornece um bom exemplo de uma pirâmide de testes, que é descrita abaixo.
Analogia de teste de software | Exemplos de métricas da construção do DBRX | |
Testes unitários | 39 benchmarks publicamente disponíveis divididos em seis competências principais: compreensão de linguagem, compreensão de leitura, resolução de problemas simbólicos, conhecimento de mundo, senso comum e programação | |
Testes de integração | Dados de benchmark de conversação multi-turno e de seguimento de instruções | |
Dados de benchmark de seguimento de instruções | ||
Chatbot Arena – gerador baseado para dados de benchmark de preferência humana | ||
Testes de ponta a ponta | Feedback interno e de clientes e testes A/B | Testes iterativos com usuários internos e externos para coletar métricas de testes A/B e anotações humanas |
Red-teaming | Testes de especialistas para gerar saídas indesejáveis (ofensivas, tendenciosas ou inseguras de outra forma) |
Para mais informações sobre métricas de avaliação, recomendamos este curso de Engenharia de IA Generativa. Para ferramentas, recomendamos o Databricks MLflow, que suporta métricas automatizadas (LLM-como-juiz), conjuntos de dados de avaliação e um aplicativo de avaliação humana. A Avaliação de Agente usa as APIs de código aberto do MLflow para avaliação de LLM. Para uma avaliação mais aprofundada para pré-treinamento, podemos trabalhar com você para desenvolver seu plano de avaliação personalizado.
Ajuste fino supervisionado
A primeira técnica para personalização de modelos usada pela maioria dos praticantes é o ajuste fino supervisionado (SFT), no qual um modelo é treinado em dados rotulados para otimizá-lo para uma tarefa ou comportamento específico.
Casos de uso comuns incluem:
- Reconhecimento de entidade nomeada: Ajuste fino de um modelo para reconhecer entidades específicas do domínio
- Conclusão de chat e resposta a perguntas: Ajuste fino de um modelo para responder em um tom específico
- Formatação de saída: Ajuste fino de um modelo para responder com saídas específicas e estruturadas
- Seguimento de instruções: Após o pré-treinamento de um modelo geral, é comum usar o ajuste fino de instruções para ensinar o modelo a responder a instruções e consultas, em vez de simplesmente gerar texto de conclusão
Terminologia: “Ajuste fino” é frequentemente usado para significar “ajuste fino supervisionado”, mas tecnicamente, “ajuste fino” é qualquer adaptação de um modelo existente. O pré-treinamento contínuo e o aprendizado por reforço com feedback humano (RLHF) também são tipos de ajuste fino.
O ajuste fino é, de longe, o tipo mais rápido e barato de personalização de modelos. Por exemplo, para o modelo MPT-7B lançado em maio de 2023, o ajuste fino de instruções custou US$ 46 para processar 9,6 milhões de tokens, enquanto o pré-treinamento custou US$ 250.800 para processar 1 trilhão de tokens.
Dados
Ao preparar seus dados, o conteúdo e a formatação são fundamentais. Uma grande parte do ajuste fino é ensinar ao modelo quais entradas esperar e quais saídas você espera. Como você espera que as consultas dos seus usuários se pareçam, em termos de formato, tom, cobertura de tópicos ou outros aspectos? Seus dados de treinamento devem representar essas expectativas.
Tamanho dos dados é um tópico comum de perguntas e, em última análise, depende do caso de uso. Em alguns casos, vimos bons resultados com ajuste fino em conjuntos de dados pequenos de centenas ou milhares de exemplos, mas algumas aplicações exigem dezenas de milhares ou centenas de milhares de exemplos. Comece pequeno para validar seu plano e, em seguida, escale iterativamente, expandindo seu conjunto de dados de treinamento, se necessário.
Dados sintéticos podem ser úteis para SFT, mais comumente para expandir um conjunto pequeno demais de dados “reais”. Um LLM pode ser instruído a gerar dados sintéticos de SFT semelhantes a exemplos de seus dados reais.
Veja também a documentação sobre preparação de dados para Treinamento de Modelos Databricks.
Modelos
Anteriormente nesta guia, recomendamos usar os modelos suportados pelo Treinamento de Modelos Databricks por padrão e testar modelos quanto ao potencial para seu caso de uso. Um bom exemplo disso veio do MPT. Embora o MPT não tenha sido treinado com o japonês em mente, um teste rápido de ajuste fino com 100 exemplos de prompt-resposta em japonês resultou em um modelo surpreendentemente eficaz para um cliente. Esse teste rápido validou a abordagem e abriu caminho para o ajuste fino em larga escala.
Ao escolher um tamanho de modelo, considere começar com um modelo superdimensionado. Ao ajustar com um pequeno conjunto de dados, um modelo maior tem maior probabilidade de produzir bons resultados do que um modelo menor. Começar com um modelo grande pode informar sobre o potencial em seus dados e caso de uso, e o SFT é relativamente barato. Após ver o potencial, você pode testar com modelos menores e mais dados.
Você pode executar SFT em variantes de base ou de instrução/chat de modelos. Por padrão, recomendamos que você use uma variante de instrução/chat, especialmente se tiver um pequeno conjunto de dados. Se você executou o pré-treinamento contínuo para criar um modelo base personalizado, então você pode executar SFT em seu modelo base personalizado.
Treinamento de Modelos Databricks
O Treinamento de Modelos Databricks fornece interfaces simples (UI e API) para tarefas de ajuste fino supervisionado. Além das dicas sobre dados e modelos já apresentadas nesta guia, considere:
- Tarefa: As tarefas de SFT podem ser especificadas de diferentes maneiras, dependendo do formato de consulta esperado. Observe que recomendamos a formatação de conclusão de chat por padrão, mesmo para tarefas de seguimento de instruções, para se adequar aos padrões comuns.
- Configuração: À medida que você itera, o primeiro hiperparâmetro a otimizar é a taxa de aprendizado. Experimente uma grade de taxas e, em seguida, amplie para uma grade de taxas de aprendizado mais refinadas centradas nas melhores taxas iniciais, semelhante ao ajuste de taxas de aprendizado em algoritmos tradicionais de machine learning (ML). Considere também ajustar a duração do treinamento (épocas ou tokens) com base em gráficos de progresso de aprendizado. Algumas tarefas de fine-tuning exigem poucas épocas e outras se beneficiam de 50+ épocas.
- Avaliação: Especifique um conjunto de dados de avaliação para que o Databricks Model Training compute avaliações iniciais (“testes unitários”). Mesmo um pequeno conjunto de dados de 50 pares de consulta-resposta pode fornecer um sinal, embora conjuntos de dados maiores e mais variados sejam melhores. Use o Databricks MLflow para avaliações mais completas, especialmente porque a perda de avaliação em tempo de treinamento (ou precisão) pode não se correlacionar bem com as avaliações do usuário final.
Mais sobre fine-tuning supervisionado
Recomendamos o Databricks Model Training para um fluxo de trabalho simples e eficiente por padrão. No entanto, se você precisar usar uma arquitetura de modelo não suportada ou precisar de métodos de ajuste mais personalizados, poderá executar código totalmente personalizado em clusters Databricks com aceleração por GPU (computação geral) e no Databricks Model Training.
Este guia não se aprofunda em fine-tuning eficiente em termos de parâmetros (PEFT), uma família de técnicas como adaptação de baixo ranqueamento (LoRA) para tornar o fine-tuning e a inferência mais eficientes. Consulte este blog, este blog ou o Hugging Face PEFT para descrições e exemplos dessas técnicas.
Pré-treinamento contínuo
O fine-tuning supervisionado (SFT) não foi projetado para ensinar um modelo a entender um novo domínio. Para personalizar um modelo para entender um novo idioma, uma indústria específica ou outra área particular, os praticantes podem recorrer ao pré-treinamento contínuo (CPT). O CPT é semelhante ao pré-treinamento, exceto que você pega um modelo pré-treinado existente e, em seguida, *continua* o processo de pré-treinamento usando novos dados. Após o CPT para adaptar-se a um novo domínio, o modelo geralmente é adaptado a tarefas específicas por meio de fine-tuning supervisionado.
Casos de uso comuns incluem:
- Idiomas: Modelos gerais frequentemente viram muitos idiomas naturais em seus dados de treinamento, mas podem ser fracos em todos, exceto nos idiomas principais. O CPT pode aprimorar a compreensão de um modelo sobre um idioma específico.
- Programação: Modelos gerais frequentemente viram pelo menos algumas linguagens de programação em seus dados de treinamento, mas os modelos podem não ser projetados principalmente para codificação ou podem não entender uma linguagem de programação específica bem. O CPT pode ensinar um modelo a codificar em uma linguagem de programação específica.
- Domínios da indústria: Modelos gerais podem não ter conhecimento aprofundado de áreas de tópico específicas, como biologia molecular, direito ambiental ou regulamentações financeiras. O CPT pode aprimorar o conhecimento e a compreensão de um modelo sobre um domínio específico.
Para melhorar o modelo de instrução do meu bot de Q&A RAG, devo usar fine-tuning supervisionado (SFT) ou pré-treinamento contínuo (CPT)?
Ambas as técnicas podem ser aplicáveis, mas depende de quais dados de treinamento você tem e o que deseja melhorar no modelo. Se você deseja ensinar o modelo a responder de uma certa maneira, use SFT — se você tiver dados de consulta-resposta para treinamento. Se o modelo não entende seu domínio ou idioma, use CPT — se você tiver uma quantidade considerável de dados de texto para treinamento. Lembre-se de que, após o CPT, você provavelmente precisará executar o SFT para reensinar o modelo a responder a consultas.
Posso usar SFT ou CPT para ensinar novos conhecimentos e fatos ao meu modelo?
Sim, ambas as técnicas podem transmitir algum conhecimento, mas o CPT é mais aplicável. Independentemente disso, você pode precisar usar RAG para tornar seu sistema de IA robusto, fundamentando as respostas com dados de origem.
Dados
Ao considerar quais dados você precisa para CPT, lembre-se do princípio 2 (“orientado por dados”). O que você deseja melhorar no modelo original? Seus dados devem representar o domínio, idioma, conhecimento, etc. que você deseja instilar no modelo. Para um caso de uso específico, isso provavelmente se traduzirá em executar CPT em seus dados corporativos proprietários relevantes para o caso de uso — seus documentos de base de conhecimento internos, artigos de pesquisa relevantes dos últimos 20 anos, etc. Para um modelo mais geral, nossa orientação para dados se torna mais semelhante à de pré-treinamento , onde você pode selecionar vários conjuntos de dados para representar as diferentes conjuntos de habilidades importantes para o seu caso de uso.
Dica: Esquecer vs. aprender. Ao testar o CPT, lembre-se de que há compensações entre esquecer o conhecimento passado e aprender novo conhecimento. Seu objetivo é mudar o comportamento do modelo para imitar seus dados de treinamento CPT, mas isso pode significar esquecer aspectos dos dados de pré-treinamento originais. Portanto, certifique-se de que tanto seus dados de treinamento CPT quanto sua suíte de avaliação cubram os domínios que você se importa.
Para formato de dados, seus dados serão texto “bruto”. Ou seja, você executará o CPT fazendo previsão do próximo token, assim como no pré-treinamento.
Para tamanho dos dados, o CPT pode abranger desde o ajuste de um modelo com menos tokens até a mudança significativa de um modelo com muitos tokens. “Menos” e “muitos” dependerão do tamanho do modelo, mas uma estimativa razoável são bilhões de tokens para LLMs modernos de tamanho médio. Uma regra geral é que o CPT exigirá pelo menos ~1% do tamanho do conjunto de treinamento original.
Preciso de dados brutos para CPT e dados de prompt-resposta para SFT?
Se você estiver executando CPT seguido por SFT, então sim. No entanto, se você tiver dados para CPT, mas poucos dados para SFT, poderá aumentar seu pequeno conjunto de dados SFT com dados de consulta-resposta usando outros conjuntos de dados SFT ou dados sintéticos.
Dados sintéticos podem ser úteis para CPT, especialmente para destilação, na qual um modelo grande e poderoso é usado para gerar dados para treinar um modelo menor. A destilação pode ajudar a criar modelos menores, mais rápidos e mais baratos e pode complementar seus dados não sintéticos específicos para seus casos de uso.
Veja também a documentação sobre preparação de dados para Databricks Model Training.
Modelos
Assim como para SFT, recomendamos usar os modelos suportados pelo Databricks Model Training por padrão e testar os modelos quanto ao potencial para seu caso de uso.
Nossas recomendações sobre o ajuste de um modelo base versus uma variante de instrução/chat, e sobre a execução de SFT após CPT, estão interligadas. O caminho mais comum, e nossa recomendação padrão, é executar CPT em um modelo base, seguido por SFT para ajuste de instrução ou chat. No entanto, existem nuances:
- Variante base vs. instrução/chat: É mais comum executar CPT no modelo base. Executar CPT em um grande conjunto de dados em uma variante de instrução ou chat pode fazer com que esse modelo perca parte da capacidade de seguir instruções ou de chat.
- SFT após CPT: Se você executar CPT em uma grande quantidade de dados, provavelmente o seguirá com SFT. No entanto, se você executar CPT em um modelo de seguir instruções ou chat usando uma pequena quantidade de dados, pode não precisar de SFT depois. Vimos alguns clientes fazerem isso e, em seguida, usarem o modelo resultante diretamente em suas aplicações.
Databricks Model Training
O Treinamento de Modelos Databricks oferece interfaces simples (UI e API) para CPT. As dicas para SFT mencionadas anteriormente neste guia se aplicam principalmente ao CPT também. Convenientemente, o recurso de Treinamento de Modelos pode ser usado para executar tanto CPT quanto SFT.
Sua pirâmide de testes da discussão anterior sobre avaliação precisará de testes mais robustos e gerais, pois o CPT pode alterar o modelo de forma mais fundamental do que o SFT. À medida que você escala o CPT, sua pirâmide de testes pode começar a se parecer mais com um conjunto de testes de pré-treinamento.
Mais sobre CPT
À medida que suas cargas de trabalho de CPT se tornam mais personalizadas e maiores, você também pode querer explorar a pilha de pré-treinamento discutida abaixo.
CPT é útil para testar dados para pré-treinamento. Se seus dados de CPT cobrem um novo domínio (como uma nova linguagem de programação), então mostrar sucesso com CPT indica que os dados podem ser úteis como parte de um conjunto de dados de pré-treinamento.
Pré-treinamento
Digamos que seu aplicativo GenAI progrediu através do pré-treinamento contínuo e você acredita que pré-treinar um modelo totalmente personalizado é o próximo passo necessário para melhorar seu aplicativo. Esta seção descreve o processo e as melhores práticas em um nível alto, mas na prática, você deve passar pelo processo de pré-treinamento com sua equipe Databricks.
Você deveria pular direto para o pré-treinamento?
Não. Mesmo que restrições regulatórias ou outras exijam que você crie um novo modelo que você possua totalmente, é melhor prototipar nas etapas inferiores da escada de personalização primeiro. Isso permite que você reduza o risco de execuções de pré-treinamento mais caras e complexas.
Quais são as etapas para o pré-treinamento?
A realidade é que o pré-treinamento é um processo iterativo e adaptativo, mas as etapas gerais e comuns no pré-treinamento incluem:
- Prossiga primeiro com o ajuste fino e o pré-treinamento contínuo. Faça sua devida diligência!
- Prepare conjuntos de dados. Isso acontece durante a etapa 1, na qual o CPT ajuda você a testar a utilidade de certos conjuntos de dados.
- Pré-treine um modelo base que possa fazer completação de texto. Isso envolve monitorar o treinamento, ajustar a execução ao longo do caminho e técnicas adaptativas como aprendizado curricular para ajustar a mistura de dados.
- Execute o ajuste fino de instruções ou chat para criar uma variante de instrução/chat.
- Possivelmente use técnicas como aprendizado por reforço com feedback humano (RLHF) para ajustar ainda mais o modelo.
- Durante cada etapa acima, avalie seus modelos ao longo do caminho.
Este breve resumo procedural enfatiza a devida diligência e avaliação devido ao custo relativamente alto do pré-treinamento completo. Lembre-se do exemplo citado anteriormente do modelo MPT-7B, para o qual o pré-treinamento custou 5452 vezes mais do que o ajuste fino de instruções.
Dados
Sua escolha e tratamento de dados desempenharão um papel importante na determinação do sucesso de suas execuções de pré-treinamento.
Quais dados?
Sua mistura de dados deve ser escolhida cuidadosamente para representar seu aplicativo de destino.
- Assim como as avaliações precisam ser divididas pelas habilidades que você deseja que seu modelo tenha, considere o que cada conjunto de dados que você traz para o pré-treinamento ensinará ao modelo. Você pode testar o impacto desses conjuntos de dados antecipadamente usando pré-treinamento contínuo.
- Poucos modelos de alto desempenho vêm com detalhes publicados sobre suas misturas de dados. Alguns modelos mais antigos têm listas publicadas (por exemplo, MPT, LLaMA, OLMo). Veja também esta discussão sobre mistura de dados.
- Você provavelmente misturará conjuntos de dados públicos e proprietários. Conjuntos de dados públicos devidamente verificados podem satisfazer algumas de suas necessidades de treinamento, como ensinar capacidade de linguagem, conhecimento geral e algumas habilidades específicas. Conjuntos de dados proprietários dão aos seus modelos uma vantagem competitiva indisponível para qualquer outra pessoa.
Quantidade de dados e qualidade importam, mas em momentos diferentes. É comum começar o pré-treinamento com “todos os dados” com controles de qualidade mais flexíveis. Inicialmente, mais tokens se traduzem em mais aprendizado de capacidade básica de linguagem. No entanto, mais tarde, durante o pré-treinamento, é comum mudar a mistura de dados para um conjunto menor e de maior qualidade. “Alta qualidade” não tem uma definição acadêmica, mas intuitivamente significa curadoria usando técnicas de bom senso. Veja o seguinte para mais informações sobre preparação de dados.
Quanta quantidade de dados?
- Seu tamanho de dados deve ser escolhido com o tamanho e a arquitetura do modelo em mente.
- A regra de ouro “Chinchilla” é a mais famosa: # tokens = 20 * # parâmetros. Para reduzir os custos de inferência, recomendamos que você treine um modelo menor com mais dados para atingir qualidade de geração semelhante, de acordo com os resultados deste artigo LLaMA.
- Arquiteturas de mistura de especialistas (MoEs) podem mudar esse cálculo, geralmente exigindo menos dados para um determinado tamanho de modelo. Para MoEs, use o número de parâmetros ativos (não o total de parâmetros) para fazer este cálculo.
- Tenha em mente que algumas tarefas são mais difíceis do que outras. Por exemplo, modelos de 7 bilhões de parâmetros geralmente exigem pelo menos 2 trilhões de tokens de dados de treinamento para lidar com o benchmark de codificação HumanEval.
Como os dados devem ser preparados?
- Download e análise: Geralmente, você precisa adquirir os dados por conta própria. Poucos provedores oferecem dados em escala de internet pré-baixados, e os requisitos regulatórios podem variar por cliente.
- Limpeza: Embora o pré-treinamento possa aproveitar grandes quantidades de dados de baixa qualidade, vale a pena melhorar a qualidade dos dados. Por exemplo, este artigo RefinedWeb estima que cerca de 11% do Common Crawl é útil. A limpeza de dados para pré-treinamento é um tópico grande e complexo, com muita pesquisa ativa. Veja este artigo para uma excelente pesquisa sobre etapas comuns, incluindo:
- Filtragem de idioma para reduzir o texto aos idiomas primários de interesse
- Filtragem heurística para remover texto de boilerplate, documentos excessivamente curtos ou longos, texto não natural, etc.
- Filtragem de qualidade para identificar texto com maior probabilidade de ter sido escrito ou revisado por humanos
- Filtragem de domínio para identificar texto sobre os domínios de interesse
- Desduplicação de conteúdo dentro ou entre conjuntos de dados
- Filtragem de conteúdo tóxico e explícito com base na origem ou no texto
- Observe que todas essas técnicas vêm com ressalvas. Para cada uma, a rigorosidade do filtro deve ser ajustada para trocar precisão e recall. Para algumas, o filtro pode ser equivocado: a duplicação pode indicar que o texto é mais válido ou importante, e um modelo que nunca viu conteúdo tóxico pode não reconhecer a toxicidade e, portanto, repetir facilmente as entradas tóxicas do usuário.
- Como mencionado, o pré-treinamento inicial pode usar mais dados com controles de qualidade mais flexíveis, enquanto o pré-treinamento posterior pode se concentrar em subconjuntos de dados mais cuidadosamente limpos.
- Pré-computação: Pré-tokenizar e concatenar dados para otimizar seu formato para pré-treinamento pode melhorar a eficiência.
O processamento de dados é o forte original da Databricks. Faça uso do seguinte:
- Workflows para definir trabalhos e orquestração, com Apache Spark™ e otimizações Delta para processamento em escala
- Delta Lake como seu formato de armazenamento de dados
- Unity Catalog para gerenciamento de dados
- Cadernos, integração com IDE e Databricks SQL para desenvolvimento e exploração de dados
- Monitoramento do Lakehouse para monitoramento de longo prazo de pipelines e fontes de dados
Modelos
Embora os pesquisadores naturalmente divulguem novas arquiteturas de modelos como grandes avanços, há uma razão pela qual a arquitetura Transformer ainda domina, apesar de ter sido criada em 2017 — ela funciona muito bem. Da mesma forma, geralmente recomendamos aderir a escolhas arquitetônicas comprovadas, como:
- Use mecanismos de atenção padrão, como atenção quadrática ou FlashAttention-2, em vez de métodos menos testados da pesquisa
- Considere arquiteturas de mistura de especialistas (MoEs) para treinamento e inferência mais eficientes, bem como aritmética de menor precisão
- Treine seu transformer usando predição do próximo token
A Databricks suporta pré-treinamento em arquiteturas arbitrárias, mas fornecemos configurações de pré-treinamento mais simples para as principais arquiteturas recomendadas por meio do Databricks Model Training, que fornece versões gerenciadas e otimizadas de ferramentas como Mosaic LLM Foundry e Mosaic Diffusion. Essa ferramenta pode simplificar escolhas, fornecendo padrões padrão e bem testados. Por exemplo, em julho de 2024, o LLM Foundry recomenda o FlashAttention-2 como um mecanismo de atenção padrão e suporta arquiteturas MoEs como o DBRX. Para sua aplicação específica, podemos aconselhar sobre detalhes da arquitetura.
Quanto ao tamanho do modelo, lembre-se de começar pequeno (princípio 1). Treinar um modelo de 7B parâmetros custa cerca de 10x menos do que um modelo de 70B, e isso pode informar suas escolhas de modelagem para quando você escalar. Além disso, considere as restrições de latência e custo do seu caso de uso como limites para o tamanho potencial do modelo.
Pilha de treinamento e infraestrutura
Com seus dados e escolhas de modelagem preparados, você pode estar pronto para o pré-treinamento. Esta pode ser a etapa mais cara que você realiza com GenAI, daí a preparação cuidadosa nas etapas anteriores. Durante esta etapa, é crucial usar ferramentas robustas e consultores especializados para garantir que o pré-treinamento ocorra sem problemas.
As execuções de pré-treinamento incluem muitos desafios. A plataforma Databricks lida com muitos desses desafios automaticamente para o usuário.
Desafio | Databricks |
Carregamento de dados: Você pode precisar carregar trilhões de tokens. | O Databricks oferece tempos rápidos de inicialização e recuperação. |
Escalabilidade e otimização: Você pode precisar escalar de dezenas a milhares de GPUs. Existem muitas técnicas para otimizar o desempenho do treinamento. | O Databricks oferece escalabilidade perfeita via paralelismo de dados e FSDP, e uma biblioteca de otimizações compostas. Ele atinge a utilização de FLOPS de modelo de ponta (MFU). |
Recuperação de falhas: Você pode esperar ~1 falha de infraestrutura a cada 1000 dias de GPU na maioria das nuvens. Os trabalhos de pré-treinamento podem apresentar picos de perda ou divergência. | O Databricks detecta falhas automaticamente e realiza reinícios rápidos. A pilha de treinamento também reduz picos de perda. |
Determinismo: O carregamento e treinamento de dados distribuídos tornam o determinismo difícil, mas é valioso para recuperação e reprodutibilidade. | Os algoritmos de carregamento e treinamento de dados do Databricks tornam o pré-treinamento muito mais reproduzível. |
A pilha do Databricks Training abrange desde hardware até gerenciamento de carga de trabalho. A tabela a seguir lista as principais peças para aprender primeiro.
Estágio | Componente Databricks | Detalhes |
Carregamento de dados | Fornece streaming rápido e reproduzível de dados de treinamento de armazenamento em nuvem, incluindo inicializações e reinícios rápidos. | |
Treinamento | Fornece melhores práticas e técnicas compostas para treinamento distribuído e eficiente. | |
Configuração do fluxo de trabalho | Permite a definição simples de fluxos de trabalho, incluindo preparação de dados, treinamento, ajuste fino e avaliação. A Databricks pode fornecer configurações padrão para ajudar você a começar o pré-treinamento de arquiteturas comuns. | |
Rastreamento de experimentos | Rastreia a avaliação e outras métricas durante as execuções de pré-treinamento. O Databricks também suporta Weights & Biases. |
Seu caso de uso pode seguir os caminhos bem trilhados definidos como "receitas" de configuração pelo LLM Foundry, caso em que seu fluxo de trabalho pode ser muito orientado por configuração. Ou, se você precisar de arquiteturas ou código mais personalizados, pode se concentrar em partes de nível inferior da pilha, como MCLI, trabalhando mais diretamente com a infraestrutura do Databricks.
Computação e custos
Antes de pré-treinar um modelo, é importante estimar os custos. O custo de computação de pré-treinamento geralmente é simples de estimar, pois se resume à estimativa de horas de GPU, com base no tamanho dos dados e do modelo. Sua equipe Databricks pode fornecer estimativas precisas, mas para qualquer provedor, certifique-se de entender dois cálculos chave:
FLOPS = 6 x parâmetros x tokens
Esta regra prática diz que a computação (e o custo) aumentará linearmente com o tamanho do modelo e com o tamanho dos dados. Observe que "parâmetros" se traduzirá em "parâmetros ativos" para arquiteturas esparsas como MoEs.
Utilização de FLOPS do modelo (MFU) = utilização média de GPU na prática
O MFU nunca é 100% na prática, e muitas vezes está bem abaixo. Diferentes modelos e tipos de dados podem atingir diferentes MFUs. A pilha Databricks é otimizada para atingir MFU de alto desempenho.
E quanto às épocas?
Treinar por N épocas custará N vezes mais do que 1 época. No entanto, para pré-treinamento, é comum usar uma única época, embora você possa repetir alguns dados chave de alta qualidade em seu treinamento. Isso é diferente das muitas épocas usadas em aprendizado profundo mais tradicional. Veja este artigo para mais informações.
Além dos custos de computação de pré-treinamento, também faça estimativas para:
- Custos de dados, incluindo compra, curadoria e rotulagem
- Custos de inferência
Durante o pré-treinamento
Depois de iniciar o pré-treinamento, ele pode "simplesmente funcionar" no Databricks, mas ainda é importante monitorar o treinamento e saber como depurar ou melhorar o aprendizado. Sua equipe Databricks pode ajudá-lo a monitorar e depurar problemas.
Monitoramento envolve duas áreas principais:
- Infraestrutura: Databricks Training lida com a maioria dos problemas de infraestrutura para você. Por exemplo, ele fará checkpoint e retomará automaticamente o treinamento quando GPUs, rede ou outra infraestrutura falharem. É valioso monitorar a utilização, especialmente ao usar configurações não padrão.
- Progresso de aprendizado: Perda e outras métricas em dados de treinamento e avaliação devem ser monitoradas para verificar problemas de configuração e dados. Os sintomas mais comuns a serem observados são picos de perda e divergência. No Databricks Training, recomendamos registrar nos Experimentos do MLflow por padrão para monitoramento ao vivo e revisão post hoc.
Depuração mais frequentemente requer ajustes em:
- Configurações: Se suas configurações estiverem mal definidas, esses problemas geralmente aparecem no início do treinamento. A taxa de aprendizado é a configuração mais comum que requer ajustes.
- Dados: Por exemplo, um problema comum de treinamento é ver picos de perda devido a datasets embaralhados incorretamente. O Databricks Training simplifica o embaralhamento através da biblioteca Mosaic Streaming, mas o embaralhamento tem um custo, então o Streaming suporta diferentes configurações de embaralhamento para suportar trade-offs de qualidade-custo. Se você vir picos de perda, é possível que a configuração de embaralhamento mais forte no Streaming evite os picos. Por exemplo, se seus dados vierem de diferentes buckets (domínios, idiomas, etc.) e não forem devidamente embaralhados, você terá mais chances de ver picos de perda.
Aprendizado curricular: O pré-treinamento geralmente não é executado em um único dataset homogêneo. O modelo final pode ser frequentemente melhorado variando a mistura de dados durante o processo de treinamento, e a técnica mais comum para isso é o aprendizado curricular, no qual datasets de maior qualidade e mais direcionados são enfatizados na mistura de dados posteriormente durante o treinamento. As misturas de dados podem ser especificadas antecipadamente, ou a mistura de dados pode ser ajustada manualmente para fortalecer o modelo em certas áreas.
Após o pré-treinamento
Após o pré-treinamento, pode haver etapas adicionais para preparar um modelo para aplicações finais, como:
- Aprendizado curricular adicional ou pré-treinamento contínuo para ajustar o modelo
- Ajuste fino supervisionado, como para seguir instruções ou chat
- Aprendizado por reforço a partir de feedback humano (RLHF), uma técnica avançada para ajustar um modelo para corresponder às preferências humanas. Isso pode ser muito poderoso, mas complexo de acertar, e não é necessário para todas as aplicações. Para muitas aplicações, o ajuste fino supervisionado ou os mecanismos de proteção podem ser suficientes.
- Iterar sobre o acima, com base em avaliações de usuários finais do modelo ou aplicação
O Futuro
O ritmo do desenvolvimento de GenAI não está diminuindo. GPUs e outros hardwares especializados ficarão mais rápidos e baratos. Pilhas de software melhorarão. Novas arquiteturas de modelos e técnicas de treinamento passarão da pesquisa para a prática. O que você pode fazer para se preparar?
Com o Databricks, você poderá aproveitar muitos desenvolvimentos por padrão. O Databricks Model Training, Model Serving e outros recursos continuarão a adicionar suporte para os modelos mais recentes. Novas técnicas de treinamento e inferência serão integradas internamente. Para cargas de trabalho maiores e mais complexas, o Databricks suportará personalização completa, e as cargas de trabalho mais avançadas serão feitas em conjunto com a equipe de Pesquisa do Mosaic.
Em sua organização, concentre-se em suportar cargas de trabalho flexíveis e personalizáveis agora e no futuro:
- Desenvolva sua infraestrutura de IA. Configure a governança de API de modelos através de um gateway de IA. Configure processos de segurança usando um framework de segurança de IA. Padronize e unifique a governança de dados e IA sob o Unity Catalog. Desenvolva o loop interno usando o Agent Framework e o loop externo usando o Model Training. Desenvolva sua prática de MLOps, incluindo Model Serving robusto e Monitoramento.
- Desenvolva sua expertise em IA. Trabalhe com sua equipe Databricks para desenvolver um centro de excelência (CoE) em IA. Aproveite o Databricks Training para guiar equipes em trilhas de aprendizado adaptadas às suas funções.
- Desenvolva sua propriedade intelectual. Essa PI incluirá não apenas modelos personalizados, mas, mais importante, seus dados empresariais. Colete dados de aplicações e usuários atuais, rastreie a proveniência e tome cuidado com regulamentações e licenças. Esses dados alimentarão toda a sua personalização de GenAI — tanto RAG no loop interno quanto ajuste fino e pré-treinamento no loop externo.
Recursos
Cursos
- Faça o tutorial auto-guiado Get Started With Generative AI e ganhe um certificado Databricks
- Fundamentos de IA Generativa (Databricks Academy)
- Engenharia de IA Generativa com Databricks (Treinamento com instrutor e Databricks Academy)
- Consulte o Databricks Training e a Databricks Academy para novos cursos
Leitura
- The Big Book of Generative AI para uma coleção de posts de blog aprofundando diferentes aspectos do desenvolvimento de modelos e sistemas de IA generativa
- Um Guia Compacto para Geração Aumentada por Recuperação (RAG) para um mergulho profundo na construção de aplicações de IA generativa usando LLMs que foram aumentados com dados corporativos
- Posts do blog Mosaic Research
- The Big Book of MLOps: Second Edition para um mergulho profundo em MLOps com Databricks, incluindo LLMOps
- Página Databricks para uma visão geral do produto, detalhes sobre recursos e links para muitos recursos
- Documentação Databricks para GenAI para AWS, Azure e GCP
Palestras do Data + AI Summit 2024
- Personalizando Seus Modelos: RAG, Ajuste Fino e Pré-treinamento
- Nas Trincheiras com DBRX: Construindo um Modelo Open-Source de Ponta
Sobre a Databricks
A Databricks é a empresa de dados e IA. Mais de 10.000 organizações no mundo todo — incluindo Block, Comcast, Condé Nast, Rivian, Shell e 70% das empresas da Fortune 500 — confiam na Plataforma de Inteligência de Dados da Databricks para assumir o controle de seus dados e usá-los com IA. A Databricks tem sede em São Francisco, com escritórios em todo o mundo, e foi fundada pelos criadores originais do Lakehouse, Apache SparkTM, Delta Lake e MLflow. Para saber mais, siga a Databricks no LinkedIn, X e Facebook.
Entre em contato para uma demonstração personalizada:
databricks.com/contact
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.