Guía prescriptiva para implementar un modelo de Data Vault en la plataforma Lakehouse de Databricks
por Soham Bhatt, Tanveer Shaikh y Glenn Wiebe
Existen muchos modelos de datos diferentes que puede utilizar al diseñar un sistema analítico, como los modelos de dominio específicos del sector y las metodologías Kimball, Inmon y Data Vault. En función de sus requisitos específicos, puede utilizar estas diferentes técnicas de modelado al diseñar un lakehouse. Todos tienen sus puntos fuertes, y cada uno puede ser una buena opción en diferentes casos de uso.
En última instancia, un modelo de datos no es más que un constructo que define diferentes tablas con relaciones uno a uno, uno a muchos y muchos a muchos definidas. Las plataformas de datos deben proporcionar las mejores prácticas para la fisicalización del modelo de datos, a fin de ayudar a facilitar la recuperación de la información y a mejorar el rendimiento.
En un artículo anterior, cubrimos Cinco pasos simples para implementar un esquema de estrella en Databricks con Delta Lake. En este artículo, explicaremos qué es un Data Vault, cómo implementarlo dentro de la capa Bronce/Plata/Oro y cómo obtener el mejor rendimiento del Data Vault con la plataforma Lakehouse de Databricks.
Modelado de Data Vault, definido
El objetivo del modelado de Data Vault es adaptarse a los requisitos de negocio que cambian rápidamente y respaldar el desarrollo más rápido y ágil de los data warehouses por diseño. Un Data Vault se adapta bien a la metodología lakehouse, ya que el modelo de datos es fácilmente extensible y granular con su diseño de hub, link y satellite, por lo que los cambios de diseño y de ETL se implementan fácilmente.
Entendamos algunos bloques de construcción para un Data Vault. En general, un modelo de Data Vault tiene tres tipos de entidades:
- Hubs — Un Hub representa una entidad de negocio principal, como clientes, productos, pedidos, etc. Los analistas usarán las claves naturales o de negocio para obtener información sobre un Hub. La clave principal de las tablas Hub generalmente se deriva de una combinación del ID del concepto de negocio, la fecha de carga y otra información de metadatos.
- Enlaces: los enlaces representan la relación entre los concentradores. Solo tiene las claves de unión. Es como una tabla de hechos sin hechos en el modelo dimensional. Sin atributos, solo claves de unión.
- Satélites: las tablas satélite tienen los atributos de las entidades en el Hub o los Links. Tienen información descriptiva sobre las entidades de negocio principales. Son similares a una versión normalizada de una tabla de dimensiones. Por ejemplo, un hub de clientes puede tener muchas tablas satélite, como atributos geográficos del cliente, puntaje de crédito del cliente, niveles de lealtad del cliente, etc.
Una de las mayores ventajas de usar la metodología Data Vault es que los trabajos ETL existentes necesitan mucha menos refactorización cuando el modelo de datos cambia. Data Vault es un estilo de modelado "optimizado para escritura", admite enfoques de desarrollo ágiles y es ideal para el enfoque de data lakes y lakehouse.
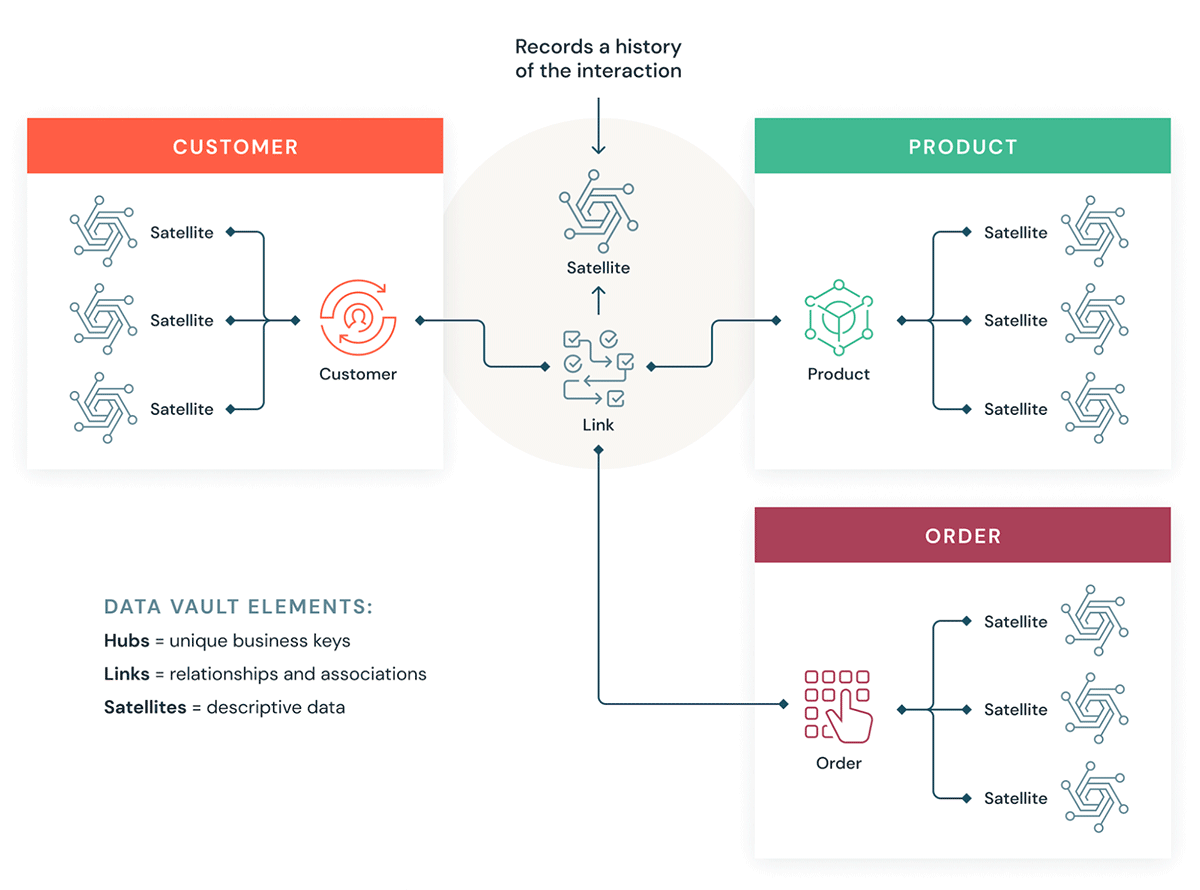
Cómo se adapta Data Vault a un Lakehouse
Veamos cómo algunos de nuestros clientes utilizan el modelado de Data Vault en una arquitectura Lakehouse de Databricks:
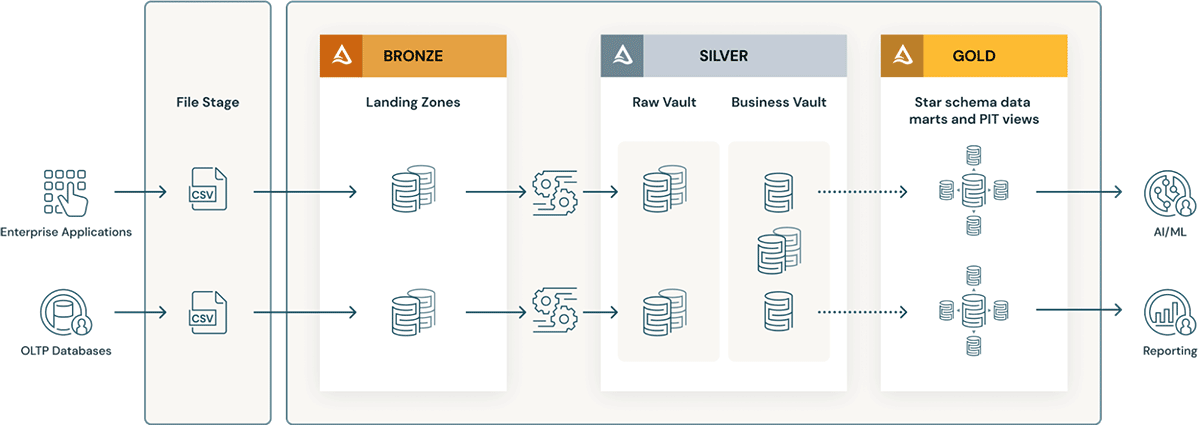
Consideraciones para implementar un modelo de Data Vault en Databricks Lakehouse
- El modelado de Data Vault recomienda usar un hash de las claves de negocio como claves primarias. Databricks admite las funciones hash, md5 y SHA de forma nativa para admitir las claves de negocio.
- Las capas de Data Vault tienen el concepto de una zona de aterrizaje (y, a veces, una zona de preparación). Ambas capas físicas encajan naturalmente en la capa Bronze del data lakehouse. Si los datos de la landing zone llegan en formatos como Avro, CSV, Parquet, XML y JSON, se convierten en tablas con formato Delta en la zona de staging para que la ETL posterior pueda tener un alto rendimiento.
- El Raw Vault se crea a partir de la zona de aterrizaje (landing) o de preparación (staging). Los datos se modelan como Hubs, Links y tablas satélite en el Raw Data Vault. Normalmente, no se aplican reglas ETL "de negocio" adicionales al cargar el Raw Data Vault.
- Todas las reglas de negocio de ETL, las reglas de calidad de los datos y las reglas de limpieza y adecuación se aplican entre Raw Vault y Business Vault. Las tablas de Business Vault se pueden organizar por dominios de datos, que sirven como un "repositorio central" empresarial de datos depurados y estandarizados. Los responsables de los datos y los expertos en la materia son responsables de la gobernanza, la calidad de los datos y las reglas de negocio en torno a sus áreas de Business Vault.
- Las tablas auxiliares de consulta, como las tablas de punto en el tiempo (PIT) y las tablas puente, se crean para la capa de presentación sobre la bóveda de negocios. Las tablas PIT mejorarán el rendimiento de las consultas, ya que algunos Satélites y Hubs se unen previamente y proporcionan algunas condiciones WHERE con un filtrado de "punto en el tiempo". Las tablas puente unen previamente hubs o entidades para proporcionar vistas aplanadas de tipo "tabla dimensional" para las entidades. Delta Live Tables son exactamente como las vistas materializadas y se pueden usar para crear tablas de punto en el tiempo, así como tablas puente en la capa Gold/de presentación sobre la bóveda de datos de negocios.
- A medida que los procesos de negocio cambian y se adaptan, el modelo Data Vault puede extenderse fácilmente sin una refactorización masiva como los modelos dimensionales. Se pueden agregar fácilmente hubs adicionales (áreas temáticas) a los links (tablas de unión puras) y satélites adicionales (p. ej., segmentaciones de clientes) se pueden agregar a un Hub (cliente) con cambios mínimos.
- Además, cargar un Data Warehouse de modelo dimensional en la capa Gold se vuelve más fácil por las siguientes razones:
- Los Hubs facilitan la gestión de claves (las claves naturales de los hubs pueden convertirse en claves sustitutas mediante columnas de identidad).
- Los satélites facilitan la carga de dimensiones porque contienen todos los atributos.
- Los links hacen que la carga de las tablas de hechos sea bastante sencilla porque contienen todas las relaciones.
Consejos para obtener el mejor rendimiento de un modelo de Data Vault en Databricks Lakehouse
- Use tablas con formato Delta para las tablas de Raw Vault, Business Vault y la capa Gold.
- Asegúrate de usar índices OPTIMIZE y Z-order en todas las claves de unión de Hubs, Links y Satélites.
- No particione en exceso las tablas, especialmente las tablas de satélites más pequeñas. Use la indexación con filtro de Bloom en las columnas de fecha, las columnas de indicador actual y las columnas de predicado sobre las que se suele filtrar para garantizar el mejor rendimiento, especialmente si necesita crear índices adicionales además del orden Z.
- Delta Live Tables (vistas materializadas) facilita enormemente la creación y la administración de tablas PIT.
- Reduzca el
optimize.maxFileSizea un número más bajo, como 32-64 MB, frente al valor predeterminado de 1 GB. Al crear archivos más pequeños, puede beneficiarse del descarte de archivos y minimizar la E/S para recuperar los datos que necesita para la unión. - El modelo Data Vault tiene comparativamente más joins, por lo que se recomienda usar la última versión de DBR, que garantiza que la función Adaptive Query Execution esté activada de forma predeterminada para que se utilice automáticamente la mejor estrategia de join. Use sugerencias de join solo si es necesario. (para un ajuste de rendimiento avanzado).
Obtenga más información sobre el modelado de Data Vault en Data Vault Alliance.
Comience a construir su Data Vault en el Lakehouse
Prueba Databricks gratis durante 14 días.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.