Tuberías de datos de streaming de baja latencia con Delta Live Tables y Apache Kafka
por Frank Munz
Delta Live Tables (DLT) es el primer framework de ETL que utiliza un enfoque declarativo simple para crear pipelines de datos confiables y administra completamente la infraestructura subyacente a escala para datos por lotes y datos de streaming. Muchos casos de uso requieren información procesable derivada de datos casi en tiempo real. Delta Live Tables permite pipelines de datos de streaming de baja latencia para admitir dichos casos de uso con bajas latencias, ingiriendo datos directamente desde buses de eventos como Apache Kafka, AWS Kinesis, Confluent Cloud, Amazon MSK o Azure Event Hubs.
Este artículo te guiará a través del uso de DLT con Apache Kafka, proporcionando el código Python necesario para ingerir flujos. Se explicará la arquitectura del sistema recomendada y se explorarán las configuraciones de DLT relacionadas que vale la pena considerar a lo largo del camino.
Plataformas de streaming
Los buses de eventos o buses de mensajes desacoplan los productores de mensajes de los consumidores. Un caso de uso de streaming popular es la recopilación de datos de clics de usuarios que navegan por un sitio web, donde cada interacción del usuario se almacena como un evento en Apache Kafka. El flujo de eventos de Kafka se utiliza luego para análisis de datos de streaming en tiempo real. Múltiples consumidores de mensajes pueden leer los mismos datos de Kafka y utilizarlos para aprender sobre los intereses de la audiencia, las tasas de conversión y las razones de rebote. Los datos de eventos de streaming en tiempo real de las interacciones del usuario a menudo también deben correlacionarse con las compras reales almacenadas en una base de datos de facturación.
Apache Kafka
Apache Kafka es un popular bus de eventos de código abierto. Kafka utiliza el concepto de un tema (topic), un registro distribuido de eventos solo para añadir (append-only) donde los mensajes se almacenan en búfer durante un cierto período de tiempo. Aunque los mensajes en Kafka no se eliminan una vez que se consumen, tampoco se almacenan indefinidamente. La retención de mensajes para Kafka se puede configurar por tema y tiene un valor predeterminado de 7 días. Los mensajes expirados se eliminarán eventualmente.
Este artículo se centra en Apache Kafka; sin embargo, los conceptos discutidos también se aplican a muchos otros buses de eventos o sistemas de mensajería.
Pipelines de datos de streaming
En un pipeline de flujo de datos, Delta Live Tables y sus dependencias se pueden declarar con una declaración estándar de SQL Create Table As Select (CTAS) y la palabra clave DLT "live".
Al desarrollar DLT con Python, se utiliza el decorador @dlt.table para crear una Delta Live Table. Para garantizar la calidad de los datos en un pipeline, DLT utiliza Expectations, que son cláusulas de restricciones SQL simples que definen el comportamiento del pipeline con registros inválidos.
Dado que las cargas de trabajo de streaming a menudo vienen con volúmenes de datos impredecibles, Databricks emplea escalado automático mejorado para pipelines de flujo de datos para minimizar la latencia general de extremo a extremo y al mismo tiempo reducir costos al apagar la infraestructura innecesaria.
Delta Live Tables se recalcula completamente, en el orden correcto, exactamente una vez para cada ejecución del pipeline.
En contraste, las Delta Live Tables de streaming son stateful, se calculan incrementalmente y solo procesan los datos que se han agregado desde la última ejecución del pipeline. Si la consulta que define una tabla en vivo de streaming cambia, los nuevos datos se procesarán según la nueva consulta, pero los datos existentes no se recalcularán. Las tablas en vivo de streaming siempre utilizan una fuente de streaming y solo funcionan sobre flujos solo para añadir (append-only), como Kafka, Kinesis o Auto Loader. Las DLT de streaming se basan en Spark Structured Streaming.
Puedes encadenar múltiples pipelines de streaming, por ejemplo, cargas de trabajo con volúmenes de datos muy grandes y requisitos de baja latencia.
Ingesta directa desde motores de streaming
Delta Live Tables escritas en Python pueden ingerir datos directamente desde un bus de eventos como Kafka utilizando Spark Structured Streaming. Puedes establecer un período de retención corto para el tema de Kafka para evitar problemas de cumplimiento, reducir costos y luego beneficiarte del almacenamiento económico, elástico y gobernable que proporciona Delta.
Como primer paso en el pipeline, recomendamos ingerir los datos tal como están en una tabla de bronce (raw) y evitar transformaciones complejas que podrían descartar datos importantes. Como cualquier Delta Table, la tabla de bronce conservará el historial y permitirá realizar tareas de cumplimiento de GDPR y otras.
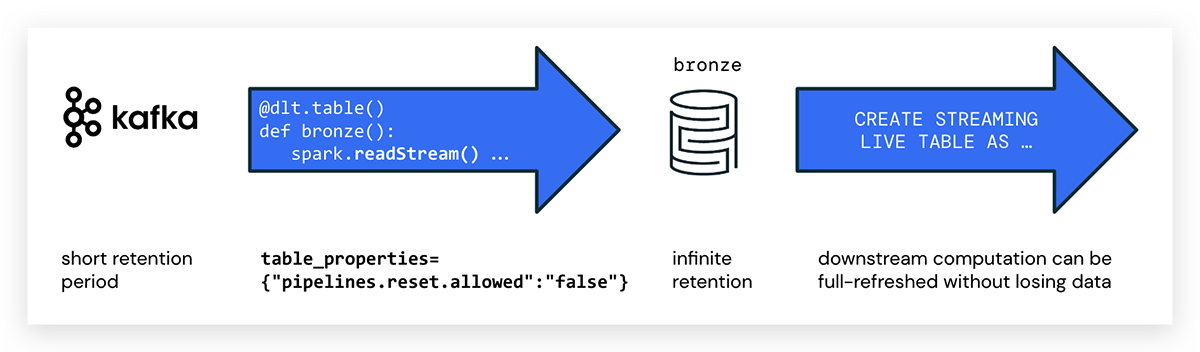
Al escribir pipelines DLT en Python, utilizas la anotación @dlt.table para crear una tabla DLT. No hay un atributo especial para marcar DLT de streaming en Python; simplemente usa spark.readStream() para acceder al flujo. El código de ejemplo para crear una tabla DLT con el nombre kafka_bronze que consume datos de un tema de Kafka es el siguiente:
pipelines.reset.allowed
Ten en cuenta que los buses de eventos suelen expirar los mensajes después de un cierto período de tiempo, mientras que Delta está diseñado para una retención infinita.
Esto podría llevar a que los datos de origen en Kafka ya se hayan eliminado al ejecutar una actualización completa para un pipeline DLT. En este caso, no todos los datos históricos podrían ser rellenados desde la plataforma de mensajería, y los datos faltarían en las tablas DLT. Para evitar la pérdida de datos, utiliza la siguiente propiedad de tabla DLT:
pipelines.reset.allowed=false
Establecer pipelines.reset.allowed en false evita las actualizaciones de la tabla, pero no evita las escrituras incrementales en las tablas ni que fluyan nuevos datos hacia la tabla.
Checkpointing
Si eres un desarrollador experimentado de Spark Structured Streaming, notarás la ausencia de checkpointing en el código anterior. En Spark Structured Streaming, el checkpointing es necesario para persistir la información de progreso sobre qué datos se han procesado correctamente y, en caso de fallo, estos metadatos se utilizan para reiniciar una consulta fallida exactamente donde se quedó.
Mientras que los checkpoints son necesarios para la recuperación de fallos con garantías de exactamente una vez (exactly-once) en Spark Structured Streaming, DLT maneja el estado automáticamente sin ninguna configuración manual o checkpointing explícito requerido.
Mezcla de SQL y Python para un Pipeline DLT
Un pipeline DLT puede consistir en múltiples notebooks, pero se requiere que un notebook DLT esté escrito completamente en SQL o Python (a diferencia de otros notebooks de Databricks donde puedes tener celdas de diferentes lenguajes en un solo notebook).
Ahora, si prefieres SQL, puedes codificar la ingesta de datos desde Apache Kafka en un notebook en Python y luego implementar la lógica de transformación de tus pipelines de datos en otro notebook en SQL.
Mapeo de esquemas
Al leer datos de una plataforma de mensajería, el flujo de datos es opaco y se debe proporcionar un esquema.
El siguiente ejemplo de Python muestra la definición del esquema de eventos de un rastreador de actividad física (fitness tracker) y cómo la parte del valor del mensaje de Kafka se mapea a ese esquema.
Beneficios
Leer datos de streaming en DLT directamente desde un broker de mensajes minimiza la complejidad arquitectónica y proporciona una menor latencia de extremo a extremo, ya que los datos se transmiten directamente desde el broker de mensajes y no hay pasos intermedios involucrados.
Ingesta de streaming con un intermediario de almacén de objetos en la nube
Para algunos casos de uso específicos, es posible que desee descargar datos de Apache Kafka, por ejemplo, utilizando un conector de Kafka, y almacenar sus datos de streaming en un intermediario de objetos en la nube. En un espacio de trabajo de Databricks, el almacén de objetos específico del proveedor de la nube se puede mapear a través del sistema de archivos de Databricks (DBFS) como una carpeta independiente de la nube. Una vez que los datos se descargan, Databricks Auto Loader puede ingerir los archivos.
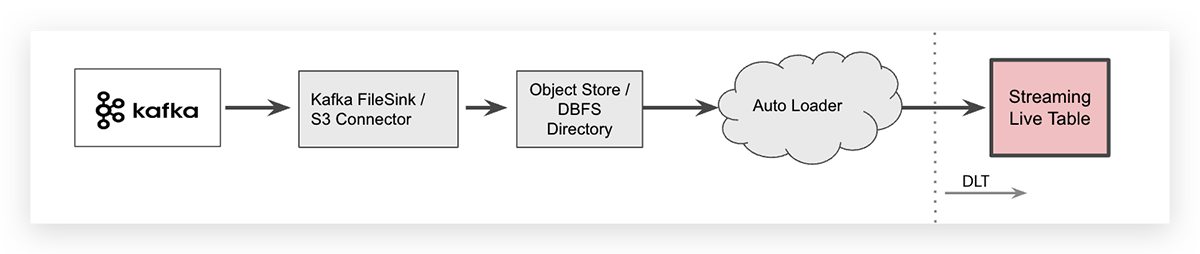
Auto Loader puede ingerir datos con una sola línea de código SQL. La sintaxis para ingerir archivos JSON en una tabla DLT se muestra a continuación (está dividida en dos líneas para facilitar la lectura).
Tenga en cuenta que Auto Loader en sí mismo es una fuente de datos de streaming y todos los archivos recién llegados se procesarán exactamente una vez, de ahí la palabra clave de streaming para la tabla raw que indica que los datos se ingieren incrementalmente a esa tabla.
Dado que la descarga de datos de streaming a un almacén de objetos en la nube introduce un paso adicional en la arquitectura de su sistema, también aumentará la latencia de extremo a extremo y creará costos de almacenamiento adicionales. Tenga en cuenta que el conector de Kafka que escribe datos de eventos en el almacén de objetos en la nube debe administrarse, lo que aumenta la complejidad operativa.
Por lo tanto, Databricks recomienda como mejor práctica acceder directamente a los datos del bus de eventos desde DLT utilizando Spark Structured Streaming como se describe anteriormente.
Otros buses de eventos o sistemas de mensajería
Este artículo se centra en Apache Kafka; sin embargo, los conceptos discutidos también se aplican a otros buses de eventos o sistemas de mensajería. DLT admite cualquier fuente de datos que Databricks Runtime admita directamente.
Amazon Kinesis
En Kinesis, escribe mensajes en un flujo sin servidor totalmente administrado. Al igual que Kafka, Kinesis no almacena mensajes de forma permanente. La retención predeterminada de mensajes en Kinesis es de un día.
Al usar Amazon Kinesis, reemplace format("kafka") con format("kinesis") en el código Python para la ingesta de streaming anterior y agregue configuraciones específicas de Amazon Kinesis con option(). Para obtener más información, consulte la sección sobre Integración de Kinesis en la documentación de Spark Structured Streaming.
Azure Event Hubs
Para la configuración de Azure Event Hubs, consulte la documentación oficial de Microsoft y el artículo Recetas de Delta Live Tables: Consumo desde Azure Event Hubs.
Resumen
DLT es mucho más que la "T" en ETL. Con DLT, puede ingerir fácilmente desde fuentes de streaming y batch, limpiar y transformar datos en la Plataforma Databricks Lakehouse en cualquier nube con calidad de datos garantizada.
Los datos de Apache Kafka pueden ser ingeridos conectándose directamente a un broker de Kafka desde un notebook DLT en Python. La pérdida de datos puede evitarse para una actualización completa del pipeline, incluso cuando los datos de origen en la capa de streaming de Kafka han expirado.
Empezar
Si es cliente de Databricks, simplemente siga la guía para empezar. Lea las notas de la versión para obtener más información sobre lo que se incluye en esta versión GA. Si no es un cliente de Databricks existente, regístrese para una prueba gratuita y puede ver nuestros precios detallados de DLT aquí.
Únase a la conversación en la Comunidad Databricks, donde compañeros obsesionados con los datos están charlando sobre los anuncios y actualizaciones de Data + AI Summit 2022. Aprenda. Conéctese.
Por último, pero no menos importante, disfrute de la sesión Profundice en la ingeniería de datos de la cumbre. En esa sesión, le guiaré a través del código de otro ejemplo de datos de streaming con un flujo de Twitter en vivo, Auto Loader, Delta Live Tables en SQL y análisis de sentimientos de Hugging Face.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.