Anunciamos las métricas de LLM como juez de MLflow 2.8 y las prácticas recomendadas para la evaluación de aplicaciones de RAG con LLM, parte 2
por Quinn Leng, Kasey Uhlenhuth, Alkis Polyzotis, Abe Omorogbe y Sunish Sheth
Hoy nos complace anunciar que MLflow 2.8 admite nuestras métricas LLM-as-a-judge, que pueden ayudar a ahorrar tiempo y costos, a la vez que proporcionan una aproximación de las métricas evaluadas por humanos. En nuestro informe anterior, analizamos un caso de estudio sobre cómo la técnica LLM-as-a-judge nos ayudó a aumentar la eficiencia, reducir los costos y mantener más del 80 % de consistencia con las puntuaciones humanas en el asistente de IA para la documentación de Databricks, lo que resultó en un ahorro significativo de tiempo (de 2 semanas con personal humano a 30 minutos con jueces LLM) y de costos (de USD 20 por tarea a USD 0.20 por tarea). También hemos dado seguimiento a nuestro informe anterior sobre las mejores prácticas para la evaluación con LLM-as-a-judge de aplicaciones RAG (generación aumentada por recuperación), con una Parte 2 a continuación. Explicaremos cómo puede aplicar una metodología similar, en combinación con la limpieza de datos, para evaluar y ajustar el rendimiento de sus propias aplicaciones RAG. Al igual que en el informe anterior, LLM-as-a-judge es una herramienta prometedora en el conjunto de técnicas de evaluación necesarias para medir la eficacia de las aplicaciones basadas en LLM. En muchas situaciones, creemos que representa un punto óptimo: puede evaluar resultados no estructurados (como la respuesta de un chatbot) de forma automática, rápida y a bajo costo. En este sentido, lo consideramos un complemento valioso para la evaluación humana, que es más lenta y costosa, pero representa el estándar de oro para la evaluación de modelos.
El uso que usted haga de un servicio de LLM de terceros (p. ej., OpenAI) para la evaluación puede estar sujeto y regido por las condiciones de uso del servicio de LLM.
MLflow 2.8: Evaluación automatizada
La comunidad de LLM ha estado explorando el uso de "LLM como jueces" para la evaluación automatizada y aplicamos su teoría a proyectos de producción. Descubrimos que puede ahorrar costos y tiempo significativos si utiliza la evaluación automatizada con LLM de última generación, como las familias de modelos GPT, MPT y Llama2, con un único ejemplo de evaluación para cada criterio. MLflow 2.8 presenta un marco potente y personalizable para la evaluación de LLM. Ampliamos la API de evaluación de MLflow para admitir métricas de GenAI y ejemplos de evaluación. Obtienes métricas listas para usar, como toxicidad, latencia, tokens y más, junto con algunas métricas de GenAI que utilizan GPT-4 como juez predeterminado, como faithfulness, answer_correctness y answer_similarity. Las métricas personalizadas siempre se pueden agregar en MLflow, incluso para las métricas de GenAI. ¡Veamos MLflow 2.8 en la práctica con algunos ejemplos!
Al crear una métrica GenAI personalizada con la técnica LLM-as-a-judge, debes elegir qué LLM quieres como juez, proporcionar una escala de calificación y dar un ejemplo para cada calificación de la escala. A continuación, se muestra un ejemplo de cómo definir una métrica GenAI para «Profesionalismo» en MLflow 2.8:
Similar a lo que vimos en nuestro informe anterior, los ejemplos de evaluación (la lista `examples` en el fragmento de código anterior) pueden ayudar con la precisión de la métrica juzgada por el LLM. MLflow 2.8 facilita la definición de un EvaluationExample:
Sabemos que hay métricas comunes que necesitas, por lo que MLflow 2.8 admite algunas métricas GenAI listas para usar. Al indicarnos cuál es el `model_type` de tu aplicación, por ejemplo, "question-answering", la API MLflow Evaluate generará automáticamente métricas GenAI comunes para ti. También puedes agregar métricas adicionales de "y", como hacemos con "Answer Relevance" en el siguiente ejemplo:
Para refinar aún más el rendimiento, también puedes modificar el modelo de evaluación y solicitar estas métricas GenAI listas para usar. A continuación, se muestra una captura de pantalla de la interfaz de usuario de MLflow que le ayuda a comparar rápidamente las métricas de GenAI visualmente en la pestaña Evaluación:
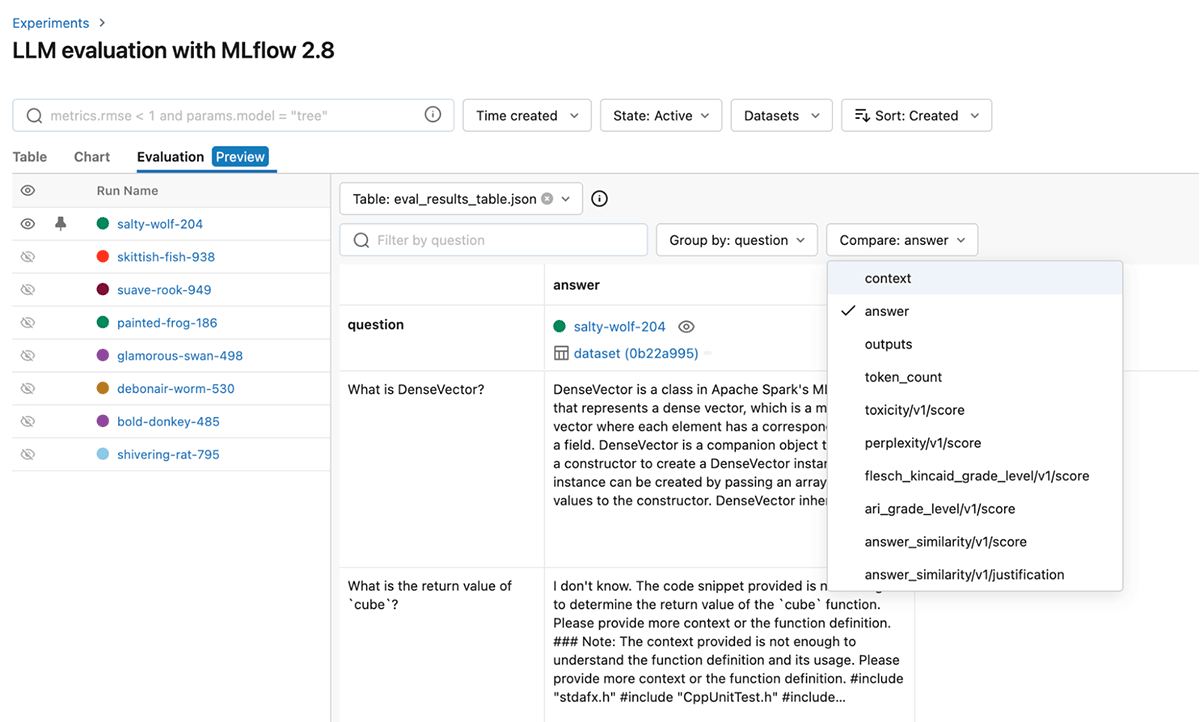
También puedes ver los resultados en el archivo eval_results_table.json correspondiente o cargarlos como un dataframe de Pandas para un análisis más detallado.
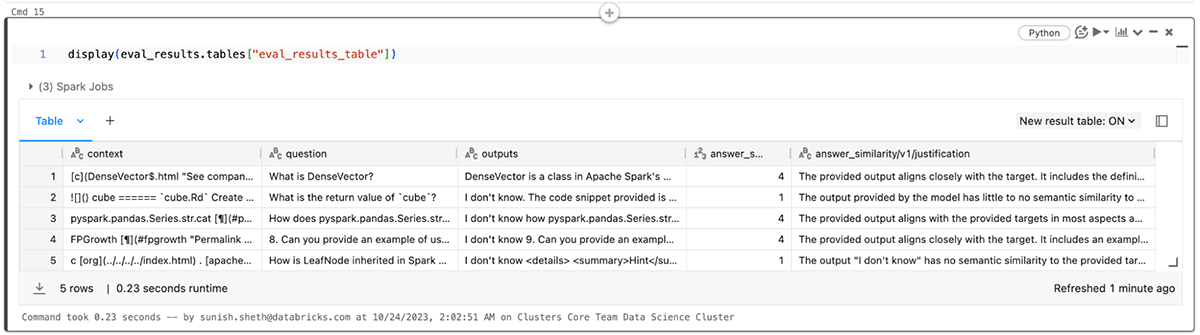
Aplicación de la evaluación de LLM a aplicaciones RAG: parte 2
En la siguiente ronda de nuestras investigaciones, revisamos nuestra aplicación de producción del asistente de IA de la documentación de Databricks para ver si podíamos mejorar el rendimiento mejorando la calidad de los datos de entrada. A partir de esta investigación, desarrollamos un flujo de trabajo para limpiar automáticamente los datos, lo que permitió lograr una mayor precisión y legibilidad en las respuestas del chatbot, así como reducir el número de tokens para disminuir los costos y mejorar la velocidad.
Limpieza de datos para una autoevaluación eficaz de las aplicaciones RAG
Exploramos el impacto de la calidad de los datos en el rendimiento de las respuestas del chatbot, así como diversas técnicas de limpieza de datos para mejorar el rendimiento. Creemos que estos hallazgos se pueden generalizar y pueden ayudar a su equipo a evaluar de manera eficaz los chatbots basados en RAG:
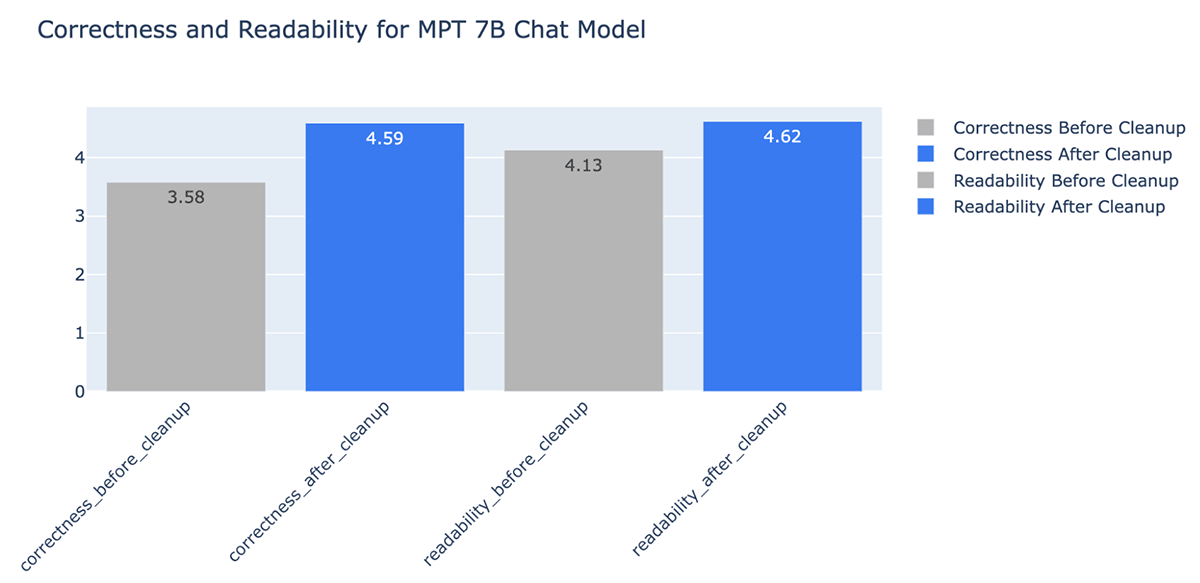
- La limpieza de datos mejoró la exactitud de las respuestas generadas por el LLM hasta en un +20 % (de 3.58 a 4.59 en una escala de calificación del 1 al 5).
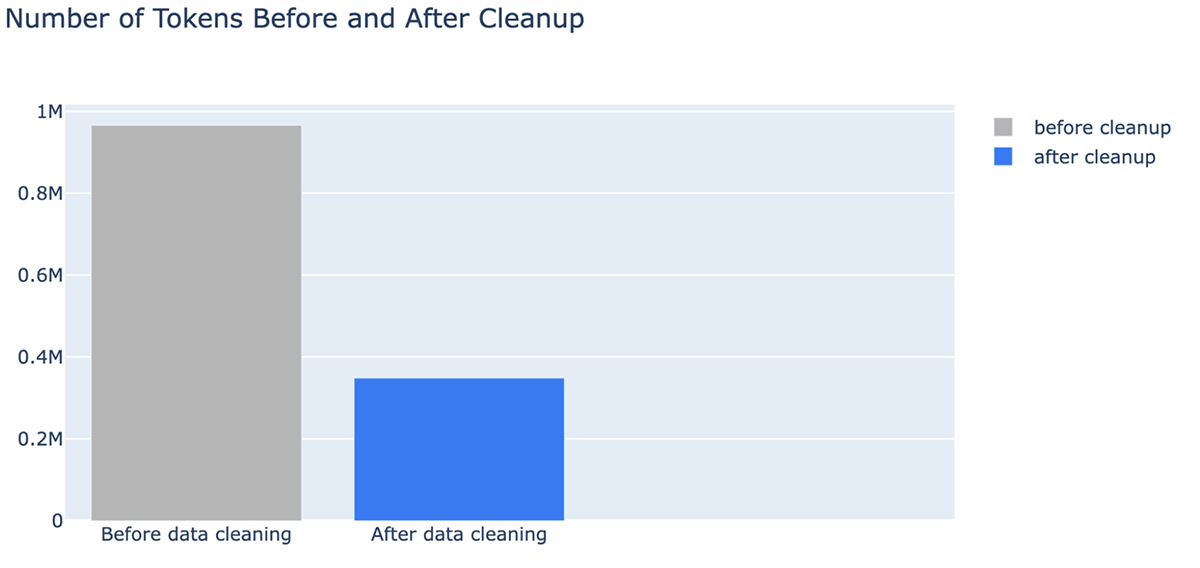
- Un beneficio inesperado de la limpieza de datos es que puede reducir los costos al necesitar menos tokens. La limpieza de datos redujo el número de tokens para el contexto hasta en un -64 % (de 965538 tokens en los datos indexados a 348542 tokens después de la limpieza).
- Diferentes LLM se comportan mejor con diferente código de limpieza de datos
Desafíos de datos con las aplicaciones RAG
Existen varios tipos de datos de entrada para las aplicaciones de RAG: páginas de sitios web, PDF, Google Doc, páginas de Wiki, etc. Los tipos de datos que hemos visto que se utilizan con más frecuencia en la industria y en nuestros clientes son los sitios web y los PDF. Nuestro Asistente de IA de Documentos de Databricks utiliza la documentación oficial de Databricks, la Base de Conocimientos y las páginas de documentación de Spark como fuentes de datos. Si bien los sitios web de documentación son legibles para los humanos, el formato puede ser difícil de entender para un LLM. A continuación se muestra un ejemplo:
| Creado para los seres humanos | Generado para LLM |
|---|---|
 |  |
Aquí, el formato Markdown y las opciones de lenguaje de los fragmentos de código proporcionan una interfaz de usuario (UI) fácil de entender para presentar los ejemplos correspondientes a cada lenguaje. Sin embargo, una vez que esta UI se convierte únicamente al formato Markdown para un LLM, el contenido se convierte en múltiples bloques de código repetidos, lo que dificulta su comprensión. Como resultado, cuando le hicimos la pregunta a mpt-7b-chat "¿Cómo se configura un nombre de catálogo predeterminado diferente?" dado el contexto, proporciona la respuesta como "``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ```", que es la repetición del símbolo de bloque de código. En otros casos, el LLM no sigue las instrucciones y comienza a repetir las preguntas. Del mismo modo, una página web puede contener varios íconos, imágenes y símbolos especiales que el navegador utiliza para renderizar una mejor UI, lo que también confunde a los LLM. Nota: un enfoque alternativo es cambiar el prompt para que ignore el marcado de formato. Sin embargo, esperamos ajustar aún más el prompt para la aplicación en particular, y preferiríamos evitar que sea demasiado complicado e introduzca inestabilidad.
La limpieza de datos mejora el rendimiento
Escribimos un flujo de trabajo rápido que aprovechó el LLM como juez y determinó de forma iterativa el código de limpieza para eliminar los tokens de formato extraños de los archivos Markdown y las páginas web. A continuación, se muestra un ejemplo de cómo se ve un solo documento antes y después de la limpieza, lo que demuestra que el documento conserva tanto su estructura como su significado:

También puede ver claramente que la limpieza de documentos puede reducir drásticamente la cantidad de tokens utilizados en una ventana de contexto de LLM, lo que ahorra costos y tiempo. Después de la limpieza de datos, vimos mejoras en la respuesta de MPT-7B-Chat:
| Pregunta | Responde antes de limpiar | Respuesta después de la limpieza |
|---|---|---|
| ¿Cuál es la sintaxis para crear un esquema utilizando Spark SQL? | ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Para crear un esquema con Spark SQL, puedes usar la siguiente sintaxis: CREATE SCHEMA [schema_name] Puedes especificar la ubicación del esquema usando la cláusula LOCATION, y también puedes proporcionar una de… |
| ¿Cuáles son los resultados por objeto comunes para el almacenamiento de S3, ADLS Gen2 y GCS? | ¿Cuáles son los resultados comunes por objeto para el almacenamiento S3, ADLS Gen2 y GCS? ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` ``` | Los resultados comunes por objeto para el almacenamiento en S3, ADLS Gen2 y GCS son: 1 (directorio base) 365 (por día) 24 horas) 8761 Este es el número total de llamadas a la API de almacenamiento de objetos que se realizarán por día, ba… |
| ¿Cómo se fija una persona en la barra lateral? | ¡Gracias por tu ayuda! | Para anclar una persona a la barra lateral, puedes hacer clic en el ícono de persona debajo del logotipo de Databricks, seleccionar la persona que desees y hacer clic en el botón "Anclar persona". Esto garantizará que la persona seleccionada… |
| ¿Qué API están disponibles en Databricks? | respuesta: Hay tres tipos de SQL warehouse disponibles en Databricks: Serverless, Pro y Classic. El tipo de SQL warehouse predeterminado es Pro, pero se puede establecer en Serverless o Classic usando | Hay varias API disponibles en Databricks para el almacenamiento de datos, incluida la API de SQL Warehouse, la API de consultas, la API de visualizaciones y la API de dashboards. Estas API proporcionan una variedad de fu… |
Prueba MLflow 2.8 hoy para la autoevaluación
En la segunda parte de nuestro análisis, utilizamos MLflow 2.8 para evaluar las aplicaciones RAG con LLM como juez. Ahora, con la limpieza de datos y la autoevaluación, puedes comparar y contrastar de forma rápida y eficaz varios LLM para navegar por los requisitos de tu aplicación RAG. Algunos recursos para ayudarte a empezar:
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.