Mejores prácticas para la gestión de costos en Databricks
por Tomasz Bacewicz y Greg Wood
Este blog forma parte de nuestra serie Admin Essentials, en la que nos centraremos en temas importantes para quienes administran y mantienen entornos de Databricks. Mantente atento a blogs adicionales sobre otros temas, y consulta nuestros blogs anteriores sobre las mejores prácticas de administración de espacios de trabajo (Workspace) y administración (Admin).
Una de las principales ventajas de usar una plataforma en la nube es su flexibilidad. La Plataforma Databricks Lakehouse proporciona a los usuarios un acceso fácil a cómputo escalable horizontalmente y casi instantáneo. Sin embargo, con esta facilidad para crear recursos de cómputo surge el riesgo de que los costos en la nube se disparen cuando no se gestionan y no se establecen salvaguardas. Como administradores, siempre buscamos lograr el equilibrio perfecto entre evitar costos exorbitantes de infraestructura y, al mismo tiempo, permitir que los usuarios trabajen sin fricciones innecesarias. En este blog, analizaremos las herramientas de administración de Databricks para encontrar este equilibrio y controlar los costos sin limitar la productividad del usuario.
¿Qué es una DBU?
Antes de entrar en los controles de costos disponibles en la plataforma Databricks, es importante comprender primero la base de costos de ejecución de una carga de trabajo. Una Unidad Databricks (DBU) es la unidad subyacente de consumo dentro de la plataforma. Con la excepción de un SQL Warehouse, la cantidad de DBUs consumidas se basa en el número de nodos y la potencia computacional de los tipos de instancia de VM subyacentes que forman parte del clúster respectivo (dado que los SQL Warehouses son esencialmente un grupo de clústeres, la tasa de DBU es la suma de las tasas de DBU de los clústeres que componen el endpoint). En el nivel más alto, cada nube tendrá tasas de DBU ligeramente diferentes para clústeres similares (ya que los tipos de nodo varían entre las nubes), pero el sitio web de Databricks tiene calculadoras de DBU para cada proveedor de nube compatible (AWS | Azure | GCP).
Para convertir el uso de DBU a montos en dólares, necesitarás la tasa de DBU del clúster, así como el tipo de carga de trabajo que generó la DBU respectiva (por ejemplo, Trabajo Automatizado, Cómputo de Propósito General, Delta Live Tables, Cómputo SQL, Cómputo Serverless) y el nivel del plan de suscripción (Estándar y Premium para Azure y GCP; Estándar, Premium y Enterprise para AWS). Por ejemplo, un espacio de trabajo Databricks Enterprise tiene una tasa de lista de DBU de Trabajos de 20 centavos/DBU en AWS. Con un tipo de instancia que se ejecuta a 3 DBU/hora, un clúster de trabajos de 4 nodos se facturaría a $2.40 ($0.2 * 3 * 4) durante una hora. Las calculadoras de DBU se pueden usar para calcular los cargos totales y los precios de lista se resumen en una matriz específica de la nube que incluye SKU y nivel (AWS | Azure | GCP).
Dado que los costos se calculan a través del uso de recursos de cómputo, y más específicamente clústeres, es vital administrar los espacios de trabajo de Databricks a través de políticas de clúster. La siguiente sección discutirá cómo los diferentes atributos de las políticas de clúster pueden restringir el consumo de DBU y administrar de manera efectiva los costos de la plataforma. Las secciones posteriores también revisarán algunos de los costos subyacentes de la nube a considerar, así como cómo monitorear el uso y la facturación de Databricks.
Administración de costos a través de políticas de clúster
¿Qué son las políticas de clúster?
Una política de clúster permite a un administrador controlar el conjunto de configuraciones que están disponibles al crear un nuevo clúster, y estas políticas se pueden asignar a usuarios individuales o grupos de usuarios. Por defecto, todos los usuarios tienen el derecho "permitir la creación de clústeres sin restricciones" dentro de un espacio de trabajo. Este permiso rara vez debe usarse, ya que permite al usuario crear clústeres sin ninguna restricción fuera de las políticas asignadas, lo que podría generar costos inmanejables y descontrolados.
Dentro de una política, un administrador puede restringir cada configuración a través de un valor fijo inmutable, un rango de valores más permisivo y regex, o un valor predeterminado completamente abierto. Las políticas limitan efectivamente la cantidad de DBUs que puede consumir un solo clúster a través de restricciones en todo, desde configuraciones más granulares como tipos de instancia de VM hasta atributos "sintéticos" de nivel superior como el máximo de DBUs permitidas por hora o los tipos de carga de trabajo del clúster.
Aunque a primera vista pueda parecer que los clústeres más restrictivos conducen a costos más bajos, este no siempre es el caso. Las políticas muy restrictivas conducen a clústeres que no pueden finalizar tareas a tiempo, lo que genera mayores costos por trabajos de larga duración. Por lo tanto, es imperativo adoptar un enfoque basado en casos de uso al formular políticas de clúster, brindando a los equipos la cantidad correcta de potencia de cómputo para sus cargas de trabajo. Para ayudar con esto, Databricks proporciona características de rendimiento como tiempos de ejecución de Apache Spark optimizados y, lo más notable, el motor Photon, lo que genera ahorros de costos a través de un tiempo de procesamiento más rápido. Discutiremos las políticas para tiempos de ejecución en una sección posterior, pero primero comencemos con las políticas que administran la escala horizontal.
Límites de recuento de nodos, escalado automático y terminación automática
Una preocupación común con respecto a los costos de cómputo son los clústeres infrautilizados o inactivos. Databricks proporciona funciones de escalado automático y terminación automática para aliviar estas preocupaciones de forma dinámica y sin intervención directa del usuario. Estas funciones se pueden aplicar a través de políticas sin obstaculizar los recursos computacionales disponibles para el usuario.
Límites de recuento de nodos y escalado automático
Las políticas pueden exigir que la función de escalado automático del clúster esté habilitada con un número mínimo de nodos trabajadores. Por ejemplo, una política como la siguiente garantizará que se utilice el escalado automático y permitirá que un usuario tenga un clúster con hasta 10 nodos trabajadores, pero solo cuando sean necesarios:
Dado que el tipo de aplicación es "rango" en el recuento máximo de trabajadores, se puede cambiar a un valor inferior a 10 durante la creación. Sin embargo, el recuento mínimo de trabajadores se establece por "fijo" a un valor de uno, de modo que el clúster siempre se reducirá a un solo trabajador cuando esté infrautilizado, lo que garantiza ahorros de costos en cómputo. Un campo adicional que se muestra aquí es "defaultValue", que, como su nombre indica, establece un valor predeterminado para la cantidad máxima de trabajadores en la página de configuración del clúster. Esto es útil para reducir el número máximo de trabajadores dentro de un clúster de forma predeterminada, de modo que el creador deba ser deliberado al permitir que un clúster escale hasta 10 nodos.
Comprender los casos de uso al crear y asignar políticas es vital en cuanto a los límites en el recuento de nodos y si se debe aplicar el escalado automático. Por ejemplo, aplicar el escalado automático funciona bien para:
- Clústeres de cómputo de propósito general compartidos: un equipo puede compartir un clúster para análisis ad hoc y trabajos experimentales o cargas de trabajo de machine learning.
- Trabajos por lotes de larga duración con complejidad variable: los trabajos pueden aprovechar el escalado automático para que el clúster escale al grado de recursos necesarios.
Tenga en cuenta que los trabajos que utilizan escalado automático no deben tener plazos de tiempo, ya que escalar el clúster puede retrasar la finalización debido al tiempo de inicio del nodo. Para ayudar a aliviar esto, utilice un pool de instancias siempre que sea posible.
Las cargas de trabajo de streaming estándar no se han podido beneficiar históricamente de la escalabilidad automática; simplemente se escalaban al número máximo de nodos y permanecían allí durante la ejecución del trabajo. Una opción más preparada para producción para los equipos que trabajan en este tipo de cargas de trabajo es aprovechar Delta Live Tables y la escalabilidad automática mejorada (las cargas de trabajo de DLT se pueden aplicar con la política "cluster_type" que se analiza más adelante en este blog). A pesar de que DLT se desarrolló pensando en las cargas de trabajo de streaming, es igualmente aplicable para pipelines por lotes al aprovechar la opción Trigger.AvailableNow, que permite actualizaciones incrementales de las tablas de destino.
Otra configuración común de las políticas de dimensionamiento de clústeres es la política de nodo único. Los clústeres de nodo único pueden ser útiles para usuarios nuevos que exploran la plataforma, equipos de ciencia de datos que utilizan bibliotecas de ML no distribuidas, así como para usuarios que necesitan realizar análisis exploratorios de datos ligeros. Tal como se describe en el ejemplo de política de clúster de nodo único, las políticas se pueden restringir para aprovechar un grupo de instancias específico. En consecuencia, el equipo asignado a esta política tendrá un límite en la cantidad de clústeres de nodo único que pueden crear según la configuración de capacidad máxima del grupo.
Autoterminación
Otro atributo que se puede establecer al crear un clúster dentro de la plataforma Databricks es el tiempo de autoterminación, que apaga un clúster después de un período de inactividad establecido. Los períodos de inactividad se definen por la falta de cualquier tipo de actividad en el clúster, como trabajos de Spark, Structured Streaming o llamadas JDBC. Las actividades que no se consideran actividades en el clúster son la creación de una conexión SSH al clúster y la ejecución de comandos bash.
La ventana de autoterminación más común es una hora. Como ejemplo, aquí está la política establecida en una ventana fija de una hora:
En este ejemplo, el atributo "hidden" también se agrega a este control, lo que oculta el widget de la página de configuración del clúster del usuario. Este atributo solo es aplicable a clústeres de propósito general, ya que los clústeres de trabajos y DLT se apagarán automáticamente cuando se completen todas las tareas asignadas.
Tiempos de ejecución de clústeres y Photon
Los tiempos de ejecución de Databricks son una parte importante de la optimización del rendimiento en Databricks; los clientes a menudo ven un beneficio automático al cambiar a un clúster que ejecuta un tiempo de ejecución más nuevo sin muchos otros cambios en su configuración. Para un administrador que crea políticas de clúster, educar a los creadores de clústeres sobre los efectos de ejecutar un tiempo de ejecución más nuevo es valioso para ahorrar costos. A medida que los usuarios pasan a tiempos de ejecución más nuevos, los tiempos de ejecución antiguos pueden eliminarse gradualmente y restringirse a través de políticas. Como ejemplo rápido, aquí está el atributo "spark_version" que restringe a los usuarios a solo los tiempos de ejecución de DB de la versión 11.0 o 11.1.
Sin embargo, esta política podría ser más flexible al permitir otras versiones, tiempos de ejecución de ML, tiempos de ejecución de Photon o tiempos de ejecución de GPU expandiendo la lista de permitidos o usando expresiones regulares.
La otra característica de tiempo de ejecución a considerar al optimizar el rendimiento para reducir costos es el uso de nuestro motor Photon vectorizado. Photon acelerará inteligentemente partes de una carga de trabajo a través de un motor Spark vectorizado con el que los clientes ven un aumento de 3x a 8x en el rendimiento. El aumento masivo en el rendimiento conduce a trabajos más rápidos y, en consecuencia, a costos totales más bajos.
Tipos de instancias en la nube e instancias spot
Durante la creación del clúster, se pueden seleccionar tipos de instancias de VM tanto para el nodo controlador como para los nodos trabajadores por separado. Cada tipo de instancia disponible tiene una tasa de DBU calculada diferente y se puede encontrar en las páginas de estimación de precios de Databricks para cada nube respectiva (AWS, Azure, GCP). Por ejemplo, en AWS, el tipo de instancia m4.large con dos núcleos y 8 GB de memoria consume 0.4 DBU por hora, mientras que un tipo de instancia m4.16xlarge con 64 núcleos y 256 GB de memoria consume 12 DBU por hora en modo de cómputo de propósito general. Con una gama tan amplia de uso de DBU entre los recursos de cómputo, es crucial restringir este atributo a través de una política.
Los tipos de instancias en la nube se pueden controlar de manera más conveniente mediante el tipo "allowlist" o, de lo contrario, el tipo "fixed" para permitir el uso de un solo tipo de instancia. El siguiente ejemplo muestra el atributo "node_type_id", que establece una política sobre los tipos de nodos trabajadores disponibles para el usuario, mientras que "driver_node_type_id" establece una política sobre el tipo de nodo controlador.
Como administrador que crea estas políticas, es importante tener una idea del tipo de cargas de trabajo que ejecuta cada equipo y asignar las políticas adecuadas de manera apropiada. Las cargas de trabajo con pequeñas cantidades de datos solo deberían requerir tipos de instancias con menos memoria, mientras que el entrenamiento de modelos de aprendizaje profundo se beneficiaría más de clústeres de GPU, que generalmente consumen más DBU. En última instancia, restringir los tipos de instancias puede ser un acto de equilibrio. Cuando un equipo tiene que ejecutar cargas de trabajo que requieren más recursos de los disponibles debido a restricciones de políticas, el trabajo puede tardar más en finalizar y, en consecuencia, aumentar los costos. Existen algunas mejores prácticas a seguir al configurar un clúster para una carga de trabajo definida. Por ejemplo, se recomienda escalar verticalmente (usar tipos de instancias más potentes) en lugar de escalar horizontalmente (agregar más nodos) para cargas de trabajo complejas que consisten en muchas transformaciones amplias que requieren barajado de datos. Dicho esto, a los equipos con menos experiencia se les deben asignar políticas restringidas a tipos de instancias más pequeños, ya que las VM innecesariamente potentes no proporcionarán muchos beneficios para cargas de trabajo más comunes y menos complejas.
Una capacidad de ahorro de costos relativamente nueva de la plataforma Databricks es la capacidad de usar VM habilitadas para AWS Graviton, que se basan en la arquitectura del conjunto de instrucciones Arm64. Según estudios proporcionados por AWS, además de los benchmarks realizados con Databricks usando Photon, estas instancias habilitadas para Graviton tienen algunas de las mejores relaciones precio-rendimiento disponibles en el conjunto de tipos de instancias EC2 de AWS.
Instancias Spot
Databricks proporciona otra configuración que puede ahorrar costos específicamente en los costos de cómputo de VM subyacentes con instancias spot (la opción disponible a través de Databricks en GCP utiliza instancias preemptibles que son similares a las instancias spot). Las instancias spot son VM de repuesto ofrecidas por el proveedor de la nube subyacente que se ponen a subasta en un mercado en vivo. Estas instancias pueden permitir grandes descuentos, ofreciendo a veces reducciones de hasta el 90% en los costos de cómputo de las instancias. La desventaja de las instancias spot es que pueden ser retiradas por el proveedor de la nube subyacente en cualquier momento con un corto período de aviso (2 minutos para AWS, 30 segundos para Azure y GCP).
Si usa AWS, se puede definir una política de clúster que incluya el uso de instancias spot de la siguiente manera:
En Azure:
En estos ejemplos, solo un nodo (específicamente el nodo controlador) puede ser una instancia bajo demanda mientras que todos los demás nodos dentro del clúster serán instancias spot durante la creación inicial del clúster. Como la opción de fallback está habilitada aquí, se solicitará una instancia bajo demanda para reemplazar una instancia spot que haya sido solicitada de vuelta al proveedor de la nube. Aunque las políticas en GCP no pueden forzar actualmente el atributo "first_on_demand", los nodos preemptibles aún se pueden forzar de la siguiente manera:
Por defecto, solo el nodo controlador usará una instancia bajo demanda al inicio del clúster cuando se habiliten las instancias preemptibles.
Cuando ejecutas procesos tolerantes a fallos, como cargas de trabajo experimentales o consultas ad-hoc donde la fiabilidad y la duración de la carga de trabajo no son prioritarias, las instancias spot pueden ser una forma sencilla de reducir los costes de las instancias. Por lo tanto, las instancias spot son las más adecuadas para entornos de desarrollo y staging.
Las tasas de interrupción y los precios de las instancias spot pueden variar entre los tamaños de camiseta y las regiones de la nube. Por lo tanto, la planificación de configuraciones de clúster óptimas puede ser asistida por herramientas de los respectivos proveedores de nube, como el AWS Spot Instance Advisor, el Historial y precios de Azure Spot en el portal de cuentas de Azure, o la Calculadora de precios de Google Cloud.
Ten en cuenta que Azure tiene una palanca adicional en el control de costes: las instancias reservadas pueden ser utilizadas por Databricks, proporcionando otro descuento (potencialmente elevado) sin añadir inestabilidad.
Etiquetado de clústeres
La capacidad de observar los recursos que está utilizando un equipo se habilita mediante el etiquetado de clústeres. Estas etiquetas se propagan hasta el nivel del proveedor de nube para que el uso y los costes puedan atribuirse tanto desde la plataforma Databricks como desde los costes de la nube subyacente. Sin embargo, sin una política de clúster, un usuario que crea un clúster no está obligado a asignar ninguna etiqueta. Por lo tanto, cuando un administrador crea una política para un equipo que solicita acceso a la plataforma Databricks, es vital que la política incluya una aplicación de etiquetas de clúster específica para el equipo al que se asignará la política.
Aquí tienes un ejemplo de creación de una política con una etiqueta de centro de costes personalizada aplicada:
Una vez asignada una etiqueta para identificar al equipo que utiliza el clúster, los administradores pueden analizar los registros de uso para vincular los DBU y los costes generados al equipo que utiliza el clúster. Estas etiquetas también se propagarán al nivel de uso de la VM para que los costes de las instancias del proveedor de nube también puedan atribuirse al equipo o centro de costes. Las opciones de monitorización de registros de uso en general se discuten en una sección más adelante.
Una distinción importante con respecto a las etiquetas de clúster al utilizar un grupo de clústeres es que solo las etiquetas del grupo de clústeres (y no las etiquetas del clúster) se propagan a las instancias de VM subyacentes. La creación de grupos de clústeres no está restringida por las políticas de clúster y, por lo tanto, un administrador debe crear grupos de clústeres con las etiquetas apropiadas antes de asignar permisos de uso a un equipo. El equipo puede entonces tener acceso a través de políticas para adjuntarse al grupo respectivo al crear sus clústeres. Esto garantiza que las etiquetas asociadas con el equipo que utiliza el grupo se propaguen al nivel de instancia de VM para la facturación.
Atributos virtuales de la política
Además de la configuración que se ve en la página de configuración del clúster, también hay atributos "virtuales" que pueden ser restringidos por las políticas. Específicamente, los dos atributos disponibles en esta categoría son "dbus_per_hour" y "cluster_type".
Con el atributo "dbus_per_hour", los creadores de clústeres pueden tener cierta flexibilidad en la configuración siempre que el uso de DBU caiga por debajo de la restricción establecida en la política. Este atributo en sí mismo no restringe los costes atribuidos a las instancias de VM subyacentes directamente como los atributos anteriores discutidos (aunque las tasas de DBU a menudo están correlacionadas con las tasas de instancias de VM). Aquí tienes un ejemplo de una definición de política que restringe al usuario a crear clústeres que utilizan menos de 10 DBU por hora:
El otro atributo virtual disponible es "cluster_type", que se puede aprovechar para restringir a los usuarios de los diferentes tipos de clústeres. Los tipos que son permitidos a través de este atributo son "all-purpose", "job" y "dlt", siendo este último una referencia a Delta Live Tables. Aquí tienes un ejemplo de uso de esta política:
Las restricciones de tipo de clúster son especialmente valiosas cuando se trabaja con equipos distintos involucrados en el ciclo de vida de desarrollo y despliegue. Un equipo que trabaja en el desarrollo de una nueva canalización ETL o de machine learning típicamente requeriría acceso a un clúster de propósito general, mientras que los equipos de ingeniería de despliegue utilizarían clústeres de trabajos o Delta Live Tables (DLT). Estas políticas pueden reforzar las mejores prácticas asegurando que se utiliza el tipo de clúster correcto para cada etapa específica del ciclo de vida de desarrollo y despliegue.
Una mala práctica común es el despliegue de cargas de trabajo automatizadas compartiendo un clúster de propósito general. A primera vista, esto puede parecer la opción más barata, ya que el consumo se puede vincular a un solo clúster. Sin embargo, este tipo de configuración conduce a la contención de recursos, lo que prolonga el tiempo que el clúster tiene que estar en ejecución, aumentando los costes de cómputo. En su lugar, el uso de clústeres de trabajos que están aislados para ejecutar un trabajo a la vez reduce la duración del cómputo necesaria para finalizar un conjunto de trabajos. Esto conduce a un menor uso de DBU de Databricks, así como a menores costes de instancias de nube subyacentes. Un mejor rendimiento junto con las tasas de coste más bajas por DBU que ofrecen los clústeres de trabajos conducen a un ahorro de costes drástico. Hemos visto clientes que han ahorrado decenas de miles de dólares simplemente moviendo solo el diez por ciento de sus cargas de trabajo de clústeres de propósito general a clústeres de trabajos. La reutilización de clústeres de trabajos puede ser aprovechada para asegurar la finalización oportuna de un conjunto de trabajos eliminando el tiempo de inicio del clúster entre cada tarea.
Para formular políticas que permitan a los equipos crear clústeres para la carga de trabajo correcta, hay algunas mejores prácticas a seguir. Algunos patrones de políticas restrictivas típicas son clústeres de un solo nodo, clústeres solo para trabajos o clústeres de propósito general con escalado automático para que los equipos los compartan. Ejemplos de políticas completas se pueden encontrar aquí.
Costes del proveedor de nube
Desde la perspectiva del consumo de Databricks (DBU), todos los costes se pueden atribuir a los recursos de cómputo utilizados. Sin embargo, también se deben considerar los costes atribuidos a la red y al almacenamiento de la nube subyacente.
Almacenamiento
La ventaja de usar una plataforma como Databricks es que funciona sin problemas con almacenamiento en la nube relativamente económico como ADLS Gen2 en Azure, S3 en AWS o GCS en GCP. Esto es especialmente ventajoso cuando se utiliza el formato Delta Lake, ya que proporciona gobernanza de datos para una capa de almacenamiento que de otro modo sería difícil de gestionar, así como optimizaciones de rendimiento cuando se utiliza junto con Databricks.
Una mala optimización común, en lo que respecta al almacenamiento, es no utilizar la gestión del ciclo de vida siempre que sea posible; en un caso reciente, observamos un bucket S3 de un cliente que era de ~2.5PB, de los cuales solo unos 800TB eran datos reales. Los 1.7PB restantes eran datos versionados que no proporcionaban ningún valor. Aunque eliminar objetos antiguos del almacenamiento de tu nube es una práctica recomendada general, es importante alinear esto con tu ciclo de Delta Vacuum. Si el ciclo de vida de tu almacenamiento elimina los objetos antes de que puedan ser aspirados por Delta, tus tablas pueden romperse; asegúrate de probar cualquier política de ciclo de vida en datos no productivos antes de implementarlas de forma más generalizada. Una política de ejemplo podría ser así:
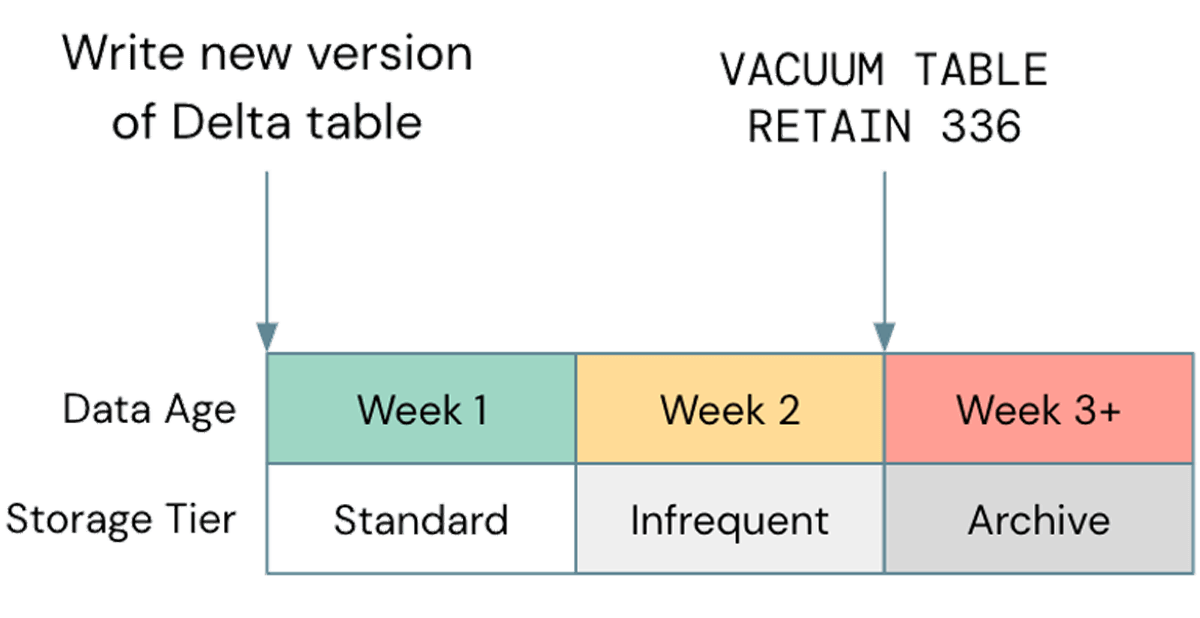
Ten en cuenta que los niveles de almacenamiento no estándar, como Glacier en S3 o Archive en ADLS, no son compatibles con Databricks, así que asegúrate de hacer Vacuum antes de que se utilicen esos niveles.
Redes
Los datos utilizados dentro de la plataforma Databricks pueden provenir de una variedad de fuentes diferentes, desde almacenes de datos hasta sistemas de streaming como Kafka. Sin embargo, el mayor consumidor de ancho de banda son las escrituras en capas de almacenamiento como S3 o ADLS. Para reducir los costes de red, los espacios de trabajo de Databricks deben desplegarse con el objetivo de minimizar la cantidad de datos que se transfieren entre regiones y zonas de disponibilidad. Esto incluye desplegar en la misma región que la mayoría de tus datos siempre que sea posible, y puede incluir el lanzamiento de espacios de trabajo regionales si es necesario.
Al usar una VPC administrada por el cliente para un espacio de trabajo de Databricks en AWS, los costos de red se pueden reducir aprovechando los Puntos de conexión de VPC, que permiten la conectividad entre la VPC y los servicios de AWS sin una Puerta de enlace a Internet ni un Dispositivo NAT. El uso de puntos de conexión reduce los costos incurridos por el tráfico de red y también hace que la conexión sea más segura. Los puntos de conexión de puerta de enlace específicamente se pueden usar para conectarse a S3 y DynamoDB, mientras que los puntos de conexión de interfaz se pueden usar de manera similar para reducir el costo de las instancias de cómputo que se conectan al plano de control de Databricks. Estos puntos de conexión están disponibles siempre que el espacio de trabajo utilice Conectividad segura de clúster.
De manera similar en Azure, se pueden configurar Private Link o Puntos de conexión de servicio para que Databricks se comunique con servicios como ADLS para reducir los costos de NAT. En GCP, se puede aprovechar el Acceso privado a Google (PGA) para que el tráfico entre Google Cloud Storage (GCS) y Google Container Registry (GCR) utilice la red interna de Google en lugar de Internet público, lo que también evita el uso de un dispositivo NAT.
Cómputo sin servidor
Para cargas de trabajo de análisis, una opción a considerar es usar un SQL Warehouse con la opción Sin servidor habilitada. Con SQL Sin servidor, la plataforma Databricks administra un grupo de instancias de cómputo que están listas para asignarse a un usuario cada vez que se inicia una carga de trabajo. Por lo tanto, los costos de las instancias subyacentes son administrados completamente por Databricks en lugar de tener dos cargos separados (es decir, el costo de cómputo de DBU y el costo de cómputo de la nube subyacente).
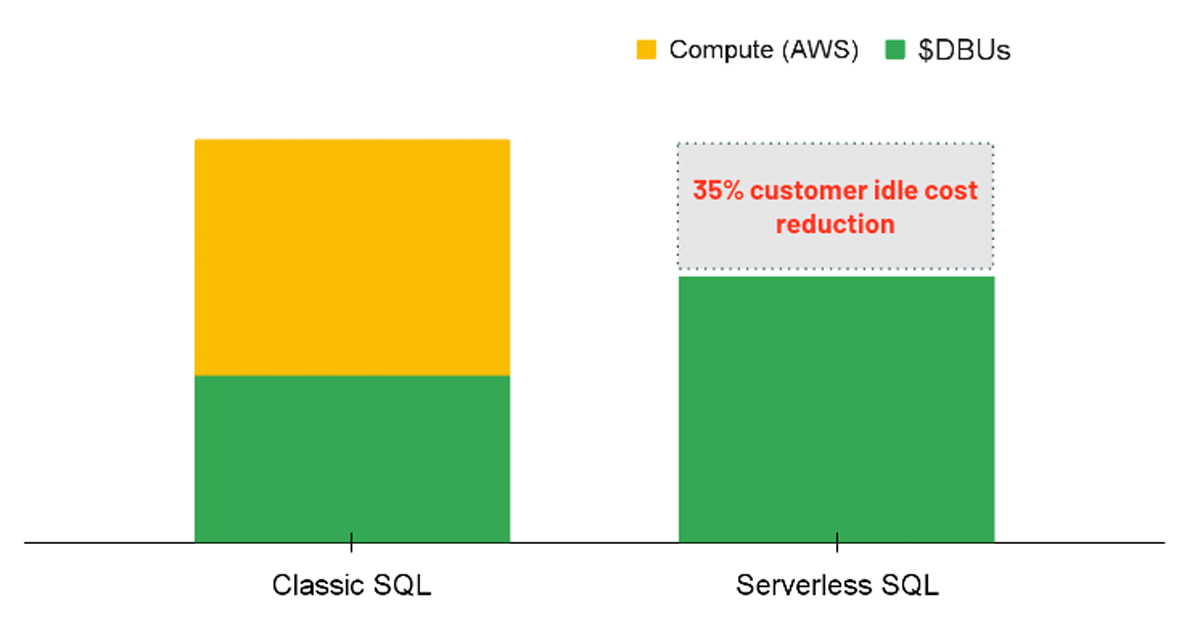
Sin servidor genera una ventaja de costo al proporcionar recursos de cómputo instantáneos cuando se ejecuta una consulta, lo que reduce los costos inactivos de clústeres infrautilizados. En el mismo sentido, sin servidor permite un escalado automático más preciso para que las cargas de trabajo se puedan completar de manera eficiente, lo que ahorra costos al mejorar el rendimiento. Aunque la opción sin servidor aún no se puede aplicar directamente a través de una política, los administradores pueden habilitar la opción para todos los usuarios con permisos de creación de SQL Warehouse.
Monitoreo de uso
Además de controlar los costos a través de políticas de clúster y configuraciones de implementación de espacios de trabajo, es igualmente importante que los administradores tengan la capacidad de monitorear los costos. Databricks proporciona algunas opciones para hacerlo con capacidades para automatizar notificaciones y alertas basadas en análisis de uso. Específicamente, los administradores pueden usar la consola de cuenta de Databricks para una vista general rápida del uso, analizar los registros de uso para una vista más detallada y usar nuestra nueva API de presupuestos para recibir notificaciones activas cuando se superan los presupuestos.
Uso de la consola de cuenta
Con la arquitectura Databricks Enterprise 2.0, la consola de cuenta incluye una página de uso que brinda a los administradores la capacidad de ver el uso por DBU o monto en dólares visualmente. El gráfico puede mostrar el consumo con una vista agregada, agrupada por espacio de trabajo o agrupada por SKU. Al agrupar por SKU, el uso se muestra por clústeres de trabajos, clústeres de propósito general o cómputo SQL, como ejemplos. Si el gráfico se segmenta por espacio de trabajo, habrá un grupo que muestre los nueve espacios de trabajo principales por consumo de DBU, y la última agrupación será una suma combinada de todos los demás espacios de trabajo. Para comprender los detalles más granulares de cada espacio de trabajo individualmente, hay una tabla en la parte inferior de la página que enumera cada espacio de trabajo por separado junto con las cantidades de DBU/USD por SKU. Esta página es muy adecuada para que los administradores obtengan una vista completa del uso y los costos en todos los espacios de trabajo de una cuenta.
Como Databricks es un servicio de primera clase en la plataforma Azure, la herramienta Azure Cost Management se puede utilizar para monitorear el uso de Databricks (junto con todos los demás servicios en Azure). A diferencia de la Consola de Cuenta para implementaciones de Databricks en AWS y GCP, las capacidades de monitoreo de Azure proporcionan datos hasta el nivel de granularidad de etiquetas. Las etiquetas personalizadas en Azure se pueden crear no solo a nivel de clúster, sino también a nivel de espacio de trabajo. Estas etiquetas se mostrarán como grupos y filtros al analizar los datos de uso. Dentro de estos informes, el uso generado por el cómputo de Databricks se mostrará junto con el uso de la instancia subyacente de manera conveniente dentro de la misma vista. Los registros también se pueden entregar a un contenedor de almacenamiento según un horario y utilizarse para un análisis y alertas más automatizados, como se explica en la siguiente sección.
Los administradores tienen la opción de descargar los registros de uso manualmente desde la página de uso de la consola de cuenta o con la API de Cuenta. Sin embargo, un proceso más eficiente para analizar estos registros de uso es configurar la entrega automatizada de registros al almacenamiento en la nube (AWS, GCP). Esto da como resultado un archivo CSV diario que contiene el uso de cada espacio de trabajo en un esquema granular.
Una vez configurada la entrega de registros de uso en cualquiera de las tres nubes, una práctica recomendada común es crear un pipeline de datos dentro de Databricks que ingiera estos datos diariamente y los guarde en una tabla Delta utilizando un flujo de trabajo programado. Estos datos se pueden utilizar para análisis de uso o para activar alertas que notifiquen a los administradores o líderes de equipo responsables del gasto del centro de costos cuando el consumo alcance un umbral establecido.
API de presupuestos
Una próxima función para facilitar la presupuestación de los costos de cómputo de Databricks es el nuevo punto final de presupuesto (actualmente en vista previa privada) dentro de la API de Cuenta. Esto permitirá que cualquier persona que use un espacio de trabajo de Databricks reciba notificaciones una vez que se alcance un umbral de presupuesto en cualquier marco de tiempo personalizado filtrado por espacio de trabajo, SKU o etiqueta de clúster. Por lo tanto, se puede configurar un presupuesto para cualquier espacio de trabajo, centro de costos o equipo a través de esta API.
Resumen
Aunque la Plataforma Databricks Lakehouse abarca muchos casos de uso y perfiles de usuario, nuestro objetivo es proporcionar un conjunto unificado de herramientas para ayudar a los administradores a equilibrar el control de costos con la experiencia del usuario. En este blog, presentamos varias estrategias para abordar este equilibrio:
- Use Políticas de clúster para controlar qué usuarios pueden crear clústeres, así como el tamaño y el alcance de esos clústeres
- Diseñe su entorno para minimizar los costos que no son de DBU generados por los espacios de trabajo de Databricks, como los costos de almacenamiento y red
- Utilice herramientas de monitoreo para asegurarse de que sus expectativas de costos se cumplan y de que tenga prácticas efectivas implementadas
Consulte nuestros otros blogs enfocados en administradores vinculados en este artículo, y esté atento a blogs adicionales que llegarán pronto. ¡También asegúrese de probar nuevas funciones como Private Link (AWS | Azure) y Presupuestos!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.