Creación de productos de datos confiables y de alta calidad con Databricks
por Amr Ali, Bernhard Walter, Fran Medina Castro, Glenn Wiebe, Karthik Subbarao, Lexy Kassan, Magnus Pierre y Pawarit Laosunthara
Introducción
Las organizaciones que aspiran a ser impulsadas por datos e IA a menudo necesitan proporcionar a sus equipos internos productos de datos confiables y de alta calidad. La creación de dichos productos de datos garantiza que las organizaciones establezcan estándares y una base confiable de la verdad empresarial para sus objetivos de datos e IA. Un enfoque para priorizar la calidad y la usabilidad es a través del uso del paradigma de malla de datos (data mesh) para democratizar la propiedad y la gestión de los activos de datos. Nuestras publicaciones de blog (Parte 1, Parte 2) ofrecen orientación sobre cómo los clientes pueden aprovechar Databricks en su empresa para abordar los pilares fundamentales de la malla de datos, uno de los cuales es "datos como producto".
Aunque la idea de tratar los datos como productos puede haber ganado popularidad con la aparición de la malla de datos, hemos observado que la aplicación del pensamiento de producto resuena incluso con los clientes que no han optado por adoptar la malla de datos. Independientemente de la estructura organizacional o la arquitectura de datos, la toma de decisiones basada en datos sigue siendo un principio rector universal. La calidad y la usabilidad de los datos son primordiales para garantizar que estas decisiones se tomen con información válida. Este blog describirá algunas de nuestras recomendaciones para crear productos de datos listos para la empresa, tanto en general como específicamente con Databricks.
Los productos de datos, en última instancia, generan valor cuando los usuarios y las aplicaciones tienen los datos correctos en el momento adecuado, con la calidad correcta y en el formato correcto. Si bien este valor se ha materializado tradicionalmente en forma de operaciones más eficientes a través de menores costos, procesos más rápidos y riesgos mitigados, los productos de datos modernos también pueden allanar el camino para nuevas ofertas de valor y oportunidades de intercambio de datos dentro de la industria de una organización o su ecosistema de socios.
Productos de Datos
Si bien los productos de datos se pueden definir de diversas maneras, generalmente se alinean con la definición que se encuentra en Data Jujitsu: The Art of Turning Data into Product de DJ Patil: "Para empezar, ..., una buena definición de un producto de datos es un producto que facilita un objetivo final a través del uso de datos". Como tales, los productos de datos no se limitan a datos tabulares; también pueden ser modelos de ML, paneles, etc. Para aplicar este pensamiento de producto a los datos, se recomienda encarecidamente que cada producto de datos tenga un propietario del producto de datos.
{kind=link}
Los propietarios de productos de datos gestionan el desarrollo y supervisan el uso y el rendimiento de sus productos de datos. Para ello, deben comprender el negocio subyacente y ser capaces de traducir los requisitos de los consumidores de datos en un diseño para un producto de datos de alta calidad y fácil de usar. Junto con otros en la organización, cierran la brecha entre los colegas de negocios y los técnicos, como los ingenieros de datos. El propietario del producto de datos es responsable de garantizar que los productos de su cartera se alineen con los estándares organizacionales en cuanto a características de confiabilidad.
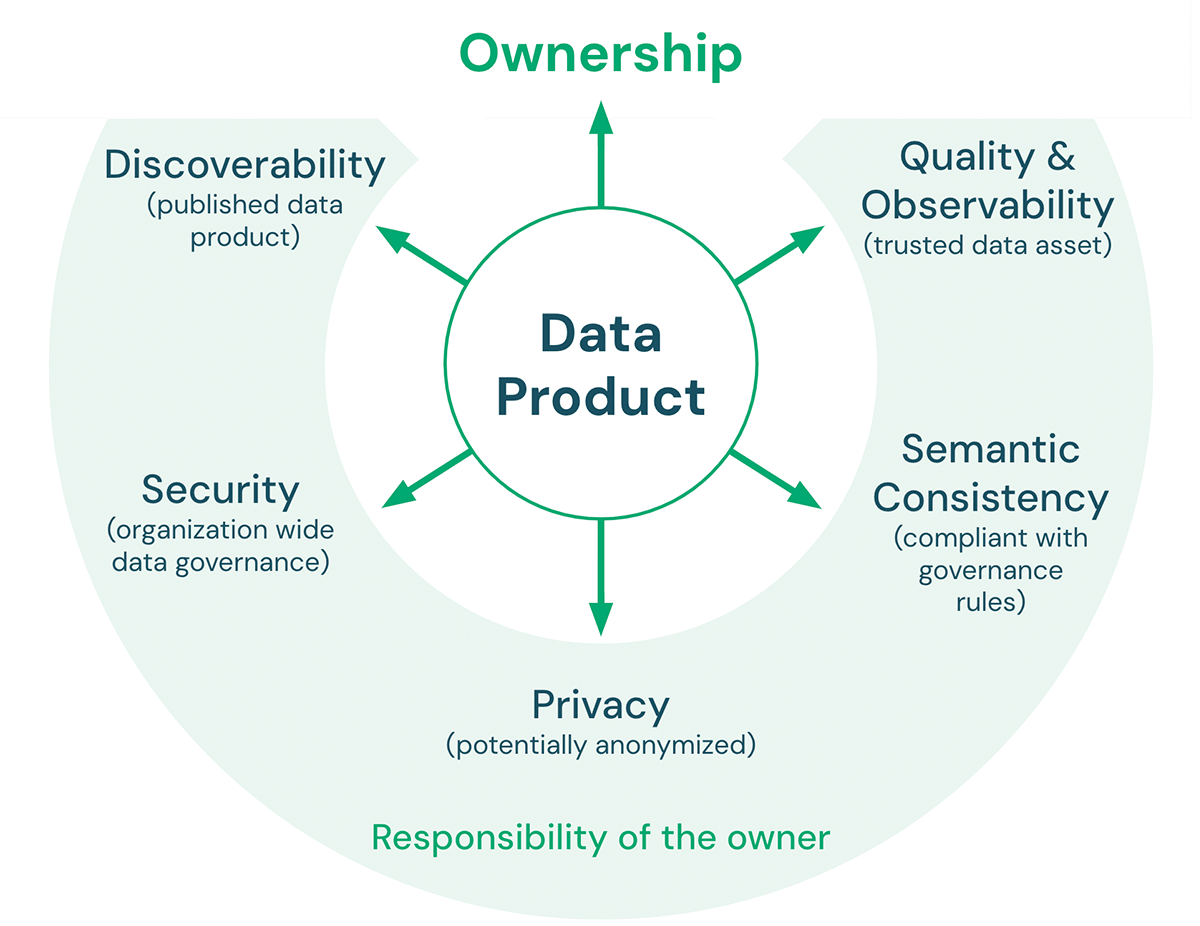
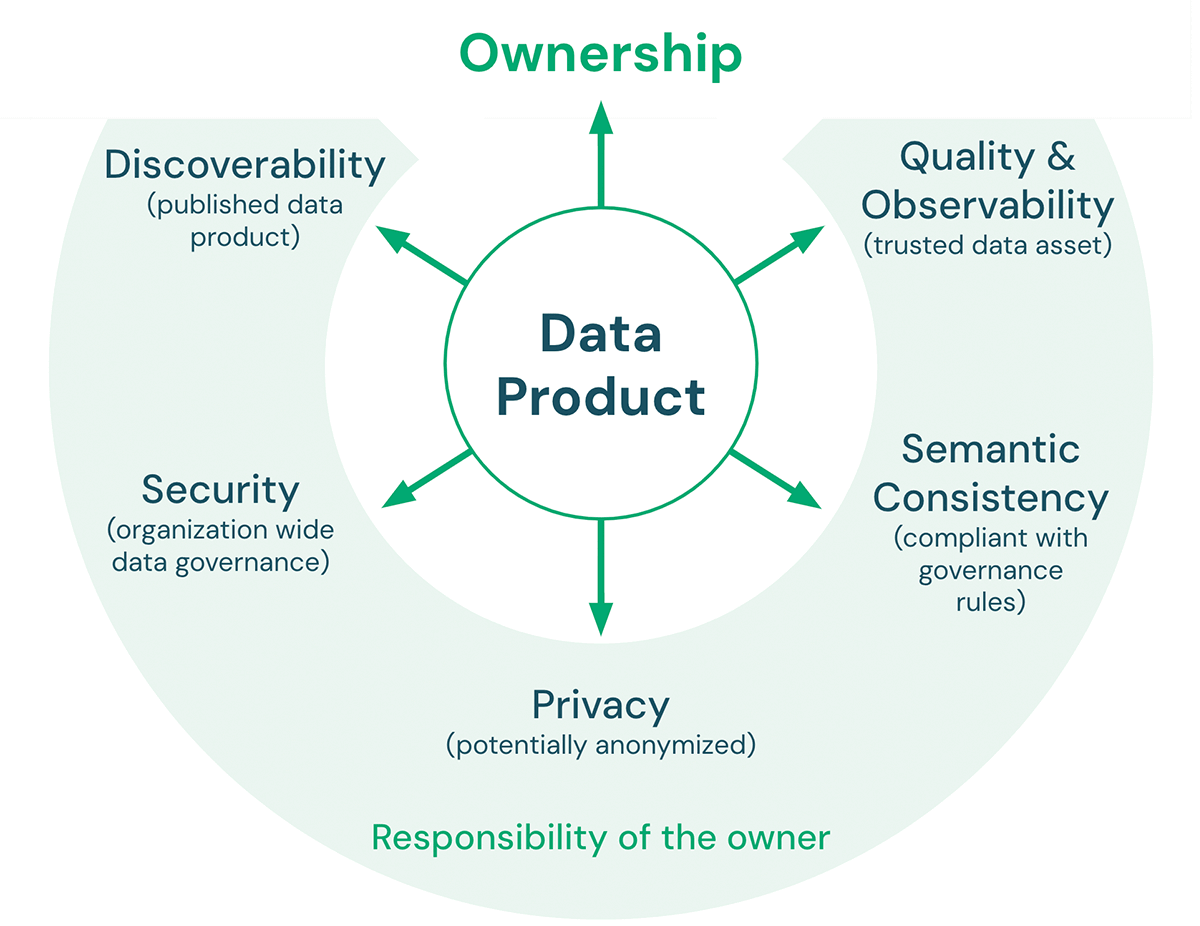
Hay cinco características clave que debe cumplir un producto de datos:
- Calidad y Observabilidad: La calidad de los datos incluye precisión, consistencia, confiabilidad, puntualidad, así como claridad en la documentación. Las métricas de calidad definidas sobre el producto de datos se pueden monitorear y exponer para garantizar que la calidad de los datos esperada se mantenga con el tiempo. El objetivo general es hacer del producto de datos una fuente confiable para los consumidores de datos.
- Consistencia semántica: El objetivo de una arquitectura lakehouse es facilitar el trabajo con los datos. Por lo tanto, los productos de datos que están destinados a ser utilizados juntos deben ser semánticamente consistentes. En otras palabras, deben seguir las reglas de gobernanza acordadas y tener definiciones compartidas de terminología para que los consumidores puedan combinar estos productos de datos de manera significativa y correcta.
- Privacidad: La privacidad se refiere a la confidencialidad y seguridad de la información, en relación con cómo se recopilan, comparten y utilizan los datos. La privacidad de los datos suele regirse por normativas y leyes (por ejemplo, GDPR, CCPA). El cumplimiento de las normas de privacidad de datos puede incluir temas como la anonimización, el cifrado, la residencia de datos, el etiquetado de datos (por ejemplo, PII), la limitación del almacenamiento a entornos específicos y la minimización del acceso a un pequeño número de empleados.
- Seguridad: Además de contar con una plataforma de datos aprobada por seguridad de la información, los propietarios de productos de datos aún deben definir, por ejemplo, los permisos de acceso (quién puede acceder a los datos, con qué socios se pueden compartir los datos, etc.) y las políticas de uso aceptable para sus productos de datos.
- Descubribilidad: Los productos de datos deben publicarse de manera que todos en la organización puedan encontrarlos. Esto puede incluir lugares como un catálogo de datos central o un mercado de datos interno. Los propietarios de productos de datos deben incluir activos con el producto publicado que faciliten la comprensión de los datos y cómo combinarlos con otros productos de datos (por ejemplo, cuadernos de ejemplo, paneles, etc.).
Ciclo de vida del producto de datos
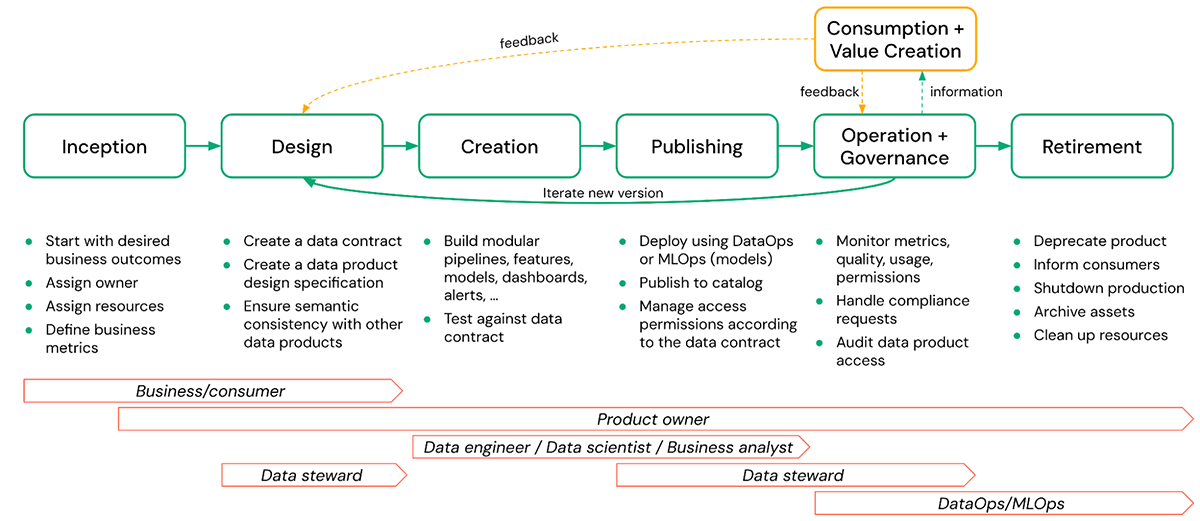
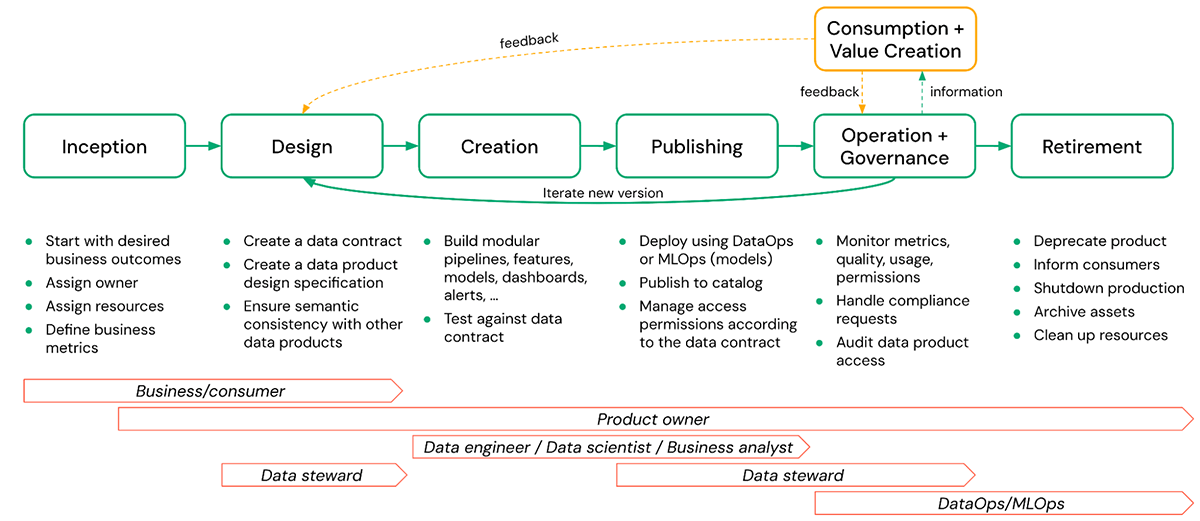
Un ciclo de vida típico de un producto de datos consta de las siguientes fases:
- Incepción: Aquí es donde se define el valor comercial de un producto de datos deseado y se asigna un propietario. También se deben definir las métricas de rendimiento y calidad para fines de monitoreo.
- Diseño: En esta fase, se crean detalles concretos como la especificación de diseño y los contratos de datos, asegurando la consistencia con otros productos de datos.
- Creación: La creación del producto de datos real puede incluir esquemas, tablas, vistas, modelos, archivos arbitrarios (volúmenes), paneles, etc., junto con los pipelines que los crean. Esta fase también incluye la prueba del producto de datos resultante frente al contrato de datos definido.
- Publicación: La creación y publicación de un producto de datos a menudo se tratan como lo mismo, pero son bastante diferentes. Esta fase incluye actividades como la implementación de modelos, la publicación de un esquema en un catálogo compartido, la gestión de los permisos de acceso según el contrato de datos, etc. La publicación debe implicar la gestión de versiones para los cambios en los productos de datos publicados.
- Operación y Gobernanza: Las operaciones implican actividades continuas como el monitoreo de la calidad, los permisos y las métricas de uso. La parte de gobernanza incluye el manejo de solicitudes relacionadas con el cumplimiento y la auditoría del acceso al producto de datos, etc.
- Consumo y Creación de Valor: El producto de datos se utiliza en el negocio para resolver una variedad de problemas. Los consumidores pueden proporcionar comentarios al propietario del producto de datos basándose en su experiencia al usar el producto y recomendar mejoras que podrían facilitar una mayor creación de valor en el futuro.
- Retirada: Puede haber varias razones para retirar un producto de datos, como la falta de uso, que el producto de datos ya no cumpla con las normativas, etc. En cualquier caso, el producto de datos debe retirarse elegantemente. Esto significa desaprobar el producto, informar a los consumidores, archivar activos y limpiar recursos. Aquí, la visibilidad del uso posterior a menudo será importante y se facilitará significativamente si el linaje se captura automáticamente.
{kind=link}
En la figura anterior, el propietario del producto de datos es responsable de todas las fases, desde la concepción hasta la retirada de un producto de datos. Sin embargo, la responsabilidad de las tareas individuales puede compartirse con otras partes interesadas, como administradores de datos, ingenieros de datos, etc.
Mejores prácticas para la implementación de productos de datos
La implementación de productos de datos de alta calidad con Databricks requiere un enfoque reflexivo más allá de la simple ejecución técnica. Comience por establecer una propiedad clara, con propietarios de productos de datos dedicados que comprendan tanto las necesidades del negocio como los requisitos técnicos. Defina contratos de datos completos por adelantado que incluyan métricas de calidad, definiciones de esquemas, políticas de uso y parámetros de seguridad para garantizar la alineación entre productores y consumidores.
Al crear pipelines, utilice Delta Live Tables (DLT) con controles de calidad implementados directamente en su código, aprovechando las expectativas y restricciones integradas para validar los datos en cada etapa. Implemente un enfoque de desarrollo por etapas con entornos de desarrollo, prueba y producción separados para garantizar la calidad antes de la publicación. Automatice el monitoreo utilizando Lakehouse Monitoring, configurando alertas para los umbrales de métricas de calidad para detectar problemas de manera temprana.
Documenta extensamente dentro de Unity Catalog, utilizando tanto especificaciones técnicas como contexto de negocio para ayudar a los usuarios a comprender y utilizar correctamente tus productos de datos. Para una gestión eficiente, estandariza las convenciones de nomenclatura y los metadatos en todos los productos de datos para mejorar la descubribilidad y la interoperabilidad. Finalmente, implementa un ciclo de retroalimentación formal con los consumidores para mejorar continuamente tus productos de datos basándote en los patrones de uso reales y las necesidades de los usuarios.
La Plataforma de Inteligencia de Datos de Databricks puede ser aprovechada para varias de las actividades involucradas en el ciclo de vida del producto de datos:
- Pipelines ETL - Delta Live Tables (DLT) puede emplearse para construir pipelines de datos robustos y controlados por calidad. Auto Loader y las tablas de streaming pueden usarse para cargar datos incrementalmente en la capa Bronze para pipelines DLT o consultas de Databricks SQL.
- Gestión - Unity Catalog de Databricks es rico en funcionalidades y está diseñado para permitir una gestión simple y unificada en toda la empresa. Catalog Explorer puede usarse para el descubrimiento de datos y los mecanismos de control de acceso facilitan la publicación de los productos de datos a los consumidores previstos. El linaje y las Tablas del Sistema se rastrean automáticamente y son vitales para la gestión operativa.
- Monitorización - Lakehouse Monitoring proporciona una solución única y unificada para monitorizar la calidad de los activos de datos e IA. Un enfoque proactivo de este tipo es necesario para cumplir los términos del contrato de datos.
Para algunas de las actividades del ciclo de vida del producto de datos, como el diseño del producto de datos y el contrato de datos, Databricks no tiene actualmente funcionalidades para dar soporte. Estos procesos deben realizarse fuera de la Plataforma Databricks y los resultados luego documentarse en Unity Catalog una vez que el producto de datos haya sido publicado.
Contratos de Datos
Un contrato de datos es una forma formal de alinear los dominios e implementar una gestión federada. El productor de datos debe proporcionarlo; sin embargo, debe diseñarse pensando en el consumidor. El contrato debe estar redactado de manera que sea consumible por todo tipo de usuarios.
Un contrato de datos típico tiene los siguientes atributos:
- Descripción de los datos (nombre, descripción, sistemas de origen, selección de atributos, …)
- Esquema de datos (tablas, columnas, información de anonimización y cifrado, filtros, máscaras, …) y formatos de datos (datos semiestructurados y no estructurados)
- Políticas de uso (etiquetas, PII, directrices, residencia de datos, …)
- Calidad de los datos (comprobaciones de calidad aplicadas y restricciones, métricas de calidad, …)
- Seguridad (quién tiene permitido usar el producto de datos)
- SLAs de datos (última actualización, fechas de caducidad, tiempo de retención, …)
- Responsabilidades (propietario, mantenedor, contacto de escalada, proceso de cambio, …)
Además, se pueden proporcionar activos de soporte como notebooks, dashboards, etc., para ayudar al consumidor a comprender y analizar el producto de datos, facilitando así una adopción más sencilla.
Equipo de Gobernanza de Datos
Un equipo de gobernanza de datos en una empresa suele estar compuesto por representantes de diferentes grupos, como propietarios de negocio, expertos en cumplimiento y seguridad, y profesionales de datos. Este equipo debe actuar como Centro de Excelencia (CoE) para temas de cumplimiento y seguridad de datos y dar soporte al propietario del producto de datos, que es el responsable del producto de datos. Juegan un papel crucial en la redacción del contrato de datos al extender las políticas de uso e influir en la decisión de quién tiene permitido usar el producto de datos. Para organizaciones grandes, un equipo así puede ayudar a dirigir y estandarizar el proceso de redacción del contrato de datos en alineación con funciones globales como una oficina de gestión de datos.
Publicación y Certificación
A pesar de los contratos de datos establecidos, la gestión de los productos de datos sigue siendo un tema amplio, que abarca aspectos como los controles de acceso, la clasificación de Información Personalmente Identificable (PII) y diversas políticas de uso, todo lo cual puede diferir entre organizaciones. Sin embargo, una tendencia constante que hemos observado se refiere a la publicación de productos de datos. A medida que los consumidores encuentran un número creciente de conjuntos de datos, a menudo requieren garantías de que los datos están curados, estandarizados y aprobados oficialmente para su uso. Por ejemplo, un caso de uso de informes o gestión de datos maestros dentro de una organización grande podría requerir un alto grado de consistencia semántica e interoperabilidad entre diversos activos de datos de la empresa.
Aquí es donde el concepto de 'certificación' de productos de datos puede ser valioso para ciertos productos de datos. En este proceso, los productores de datos pueden primero proponer una especificación de contrato de datos, generalmente sujeta a revisión por un administrador o equipo de gobernanza de datos. Tras la aprobación, se pueden ejecutar procesos de Integración Continua/Despliegue Continuo (CI/CD) para desplegar pipelines de producción que escriben físicamente datos en las cuentas de almacenamiento en la nube del cliente. Estos datos pueden luego publicarse y descubrirse fácilmente a través de tablas, vistas o incluso volúmenes para datos no tabulares de Unity Catalog. En este contexto, Unity Catalog admite el uso de etiquetas, así como markdown, para indicar el estado de certificación y los detalles de un producto de datos.
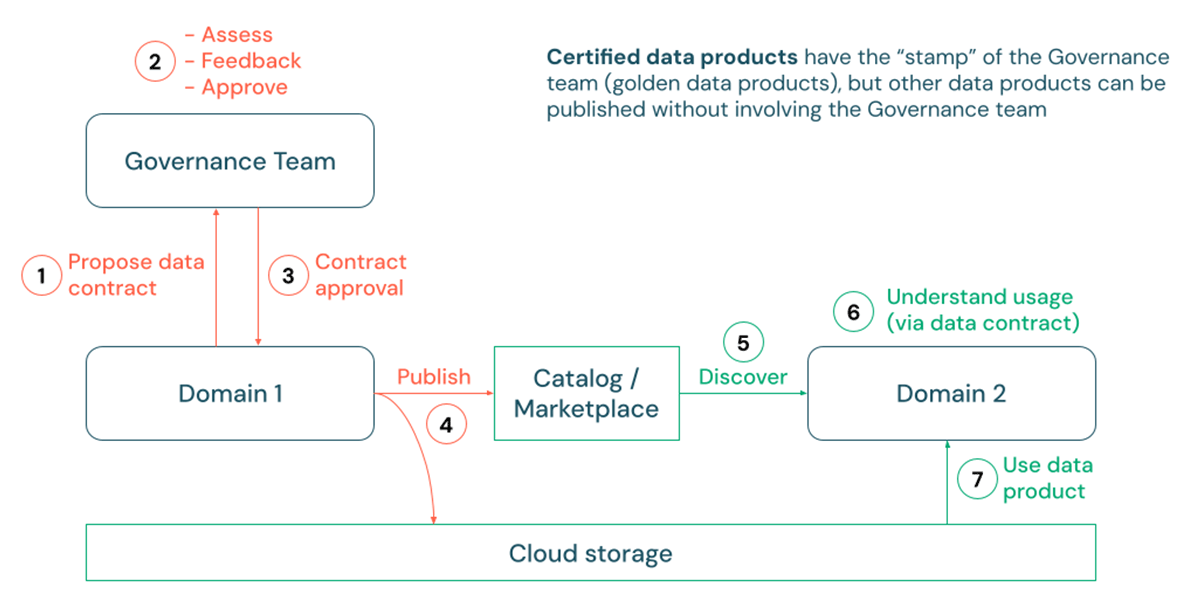
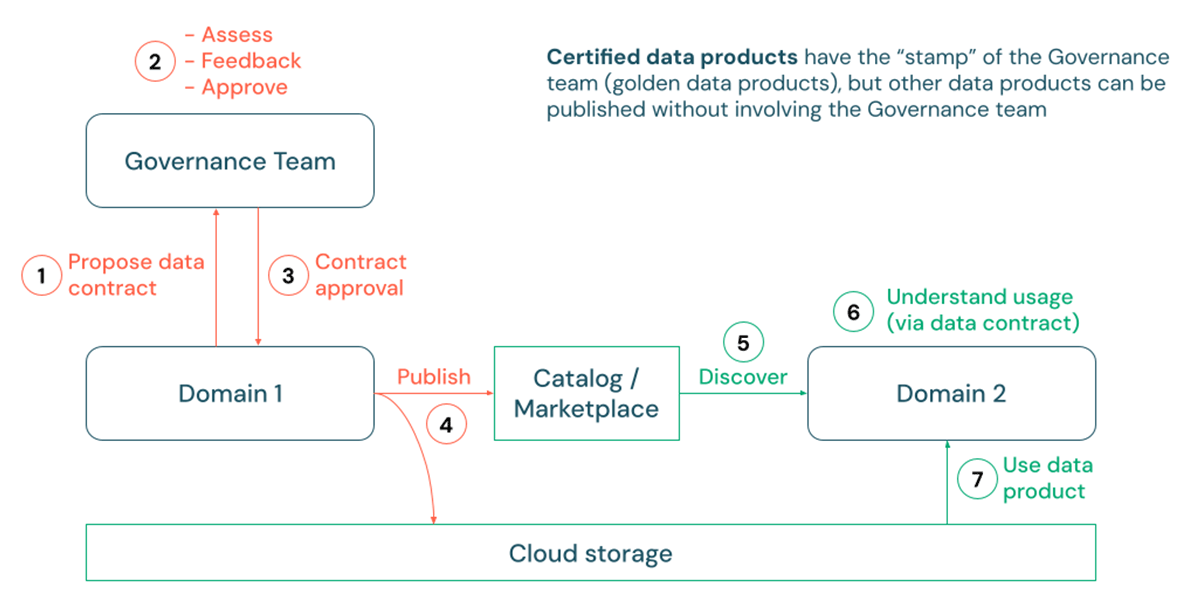{kind=link}
Algunos clientes incluso pueden optar por promocionar sus productos de datos certificados publicando una lista privada correspondiente en el Databricks Marketplace con guías completas y ejemplos de uso. Además, las API REST de Databricks y las integraciones con soluciones de catálogo empresariales como Alation, Atlan y Collibra también facilitan el descubrimiento de productos de datos certificados a través de múltiples canales, incluso aquellos fuera de Databricks.
Casos de Uso e Historias de Éxito
Automoción: Plataforma de Inteligencia Vehicular de Rivian
Rivian, el fabricante de vehículos eléctricos, utiliza Databricks para procesar datos de sensores IoT de más de 25.000 vehículos en circulación, cada uno generando terabytes de datos al día. Su equipo de sistemas avanzados de asistencia al conductor (ADAS) utiliza esta plataforma para analizar datos telemétricos, incluida información sobre cabeceo, balanceo, velocidad, suspensión y actividad de airbags, lo que ayuda a Rivian a comprender el rendimiento del vehículo y los patrones de conducción. Al aprovechar la Plataforma Lakehouse de Databricks, han logrado un aumento del 30%-50% en el rendimiento de ejecución, lo que se traduce en información más rápida y una mayor precisión del modelo. Este enfoque basado en datos permite a Rivian implementar mantenimiento predictivo, optimizar la fiabilidad de los componentes y mejorar continuamente la experiencia de conducción del cliente.
Salud: Personalización de Recetas de Walgreens
Walgreens, una de las cadenas de farmacias más grandes de Estados Unidos, transformó su experiencia de paciente utilizando Databricks para procesar datos de recetas a gran escala. Con más de 825 millones de recetas dispensadas anualmente en casi 9.000 ubicaciones, Walgreens construyó su plataforma de Información, Datos y Conocimientos (IDI) sobre Databricks para procesar 40.000 eventos de datos por segundo. Esto ha optimizado su cadena de suministro al ajustar los niveles de inventario para ahorrar millones de dólares y ha aumentado la productividad de los farmacéuticos en un 20%. La plataforma permite a los farmacéuticos brindar una mejor atención con perfiles de pacientes robustos que incluyen alertas de interacciones farmacológicas, cambios en los perfiles de medicamentos y otra información crítica para una gestión de recetas más segura.
Manufactura: Analítica Potenciada por IA de Mahindra
Mahindra & Mahindra Limited, un conglomerado manufacturero global, ha implementado soluciones de IA a nivel empresarial utilizando Databricks para mejorar las operaciones en su negocio. Su bot GenAI para analistas financieros ha llevado a una reducción del 70% en el tiempo dedicado a tareas rutinarias, permitiendo a los equipos centrarse en iniciativas estratégicas de mayor valor. La empresa está aprovechando la Plataforma de Inteligencia de Datos de Databricks para múltiples casos de uso, incluido un chatbot de Voz del Cliente construido con el LLM de código abierto DBRX de Databricks que integra datos internos a través de Delta Lake y datos externos de sitios web y redes sociales. Este enfoque integral está ayudando a Mahindra a impulsar el crecimiento, mejorar las experiencias del cliente y optimizar la eficiencia operativa.
Telecomunicaciones: Arquitectura de Data Mesh de T-Mobile
T-Mobile ha implementado con éxito una arquitectura de data mesh utilizando Databricks para democratizar el acceso a los datos manteniendo la seguridad y la gobernanza. El gigante de las telecomunicaciones integró su lakehouse en un Data Mesh utilizando Unity Catalog y Delta Sharing, permitiendo a los equipos de toda la empresa acceder y utilizar datos manteniendo un modelo de seguridad racional y fácil de entender. Este enfoque ha permitido a los equipos de dominio crear y gestionar sus propios productos de datos, garantizando al mismo tiempo una gobernanza coherente, acelerando las iniciativas de análisis en toda la organización y mejorando la toma de decisiones basada en datos.
Tendencias Futuras en Productos de Datos
El futuro de los productos de datos está siendo moldeado por varias tendencias emergentes que impactarán cómo las organizaciones aprovechan plataformas como Databricks. Los productos de datos en tiempo real están ganando protagonismo a medida que las empresas requieren insights cada vez más actuales, con arquitecturas de streaming convirtiéndose en el estándar para productos de datos operativos críticos. También estamos viendo el auge de la creación de productos de datos de autoservicio, con expertos de dominio empresarial utilizando interfaces low-code/no-code para definir y construir productos de datos manteniendo las salvaguardas de gobernanza.
Los productos de datos enriquecidos con IA que incorporan automáticamente características y insights de machine learning son cada vez más comunes, difuminando la línea entre los activos de datos tradicionales y los de IA. Las arquitecturas de data mesh están madurando, con organizaciones implementando gobernanza computacional federada que equilibra los estándares centrales con la autonomía del dominio. Están surgiendo productos de datos interorganizacionales que abarcan de forma segura los límites empresariales, con data clean rooms y computación que preserva la privacidad permitiendo nuevos insights colaborativos.
Los contratos de datos están evolucionando para incluir garantías de calidad más sofisticadas, controles de privacidad y derechos de uso, convirtiéndose en especificaciones ejecutables en lugar de documentación estática. La analítica embebida dentro de aplicaciones operativas está creciendo, con productos de datos diseñados específicamente para potenciar insights dentro de la aplicación en lugar de entornos analíticos separados. Finalmente, las métricas de sostenibilidad se están incorporando a los productos de datos, rastreando el impacto ambiental junto con los KPIs de negocio tradicionales para apoyar la presentación de informes ESG e iniciativas verdes.
Conclusión
Formular productos de datos y contratos de datos puede convertirse en ejercicios intrincados dentro de un entorno empresarial grande. Dada la aparición de nuevas tecnologías para interactuar con los datos, junto con los requisitos empresariales y regulatorios modernos, las especificaciones para productos y contratos de datos evolucionan continuamente. Hoy en día, Databricks Marketplace y Unity Catalog sirven como componentes centrales para la experiencia de descubrimiento y onboarding de datos para los consumidores de datos. Para los productores de datos, Unity Catalog ofrece funcionalidades esenciales de gobernanza empresarial, incluyendo linaje, auditoría y controles de acceso.
A medida que los productos de datos se extienden más allá de simples tablas o dashboards para abarcar modelos de IA, flujos y más, los clientes pueden beneficiarse de una experiencia de gobernanza unificada y coherente en Databricks para todos los perfiles de usuario principales.
Los aspectos clave de los productos de datos empresariales destacados en este blog pueden servir como principios rectores al abordar el tema. Para obtener más información sobre cómo construir productos de datos de alta calidad utilizando la Plataforma de Inteligencia de Datos de Databricks, póngase en contacto con su representante de Databricks.
Preguntas Frecuentes
¿Cuál es la diferencia entre un producto de datos y un conjunto de datos normal?
Un producto de datos va más allá de simplemente proporcionar datos; está diseñado teniendo en cuenta las necesidades específicas del usuario, incluye garantías de calidad, documentación y elementos de soporte. A diferencia de un conjunto de datos normal, un producto de datos tiene una propiedad clara, SLAs definidos y se gestiona activamente a lo largo de su ciclo de vida para garantizar que continúa satisfaciendo las necesidades del consumidor.
¿Quién debe poseer los productos de datos en nuestra organización?
Los productos de datos deben ser propiedad de personas que comprendan tanto el dominio empresarial como los aspectos técnicos de los datos. Estos propietarios de productos de datos son responsables de la calidad, la usabilidad y la alineación con los objetivos empresariales. Dependiendo de su estructura organizativa, pueden residir dentro de los dominios empresariales (en un enfoque de data mesh) o dentro de un equipo de datos central.
¿Cómo medimos el éxito de nuestros productos de datos?
Las métricas de éxito deben incluir tanto aspectos técnicos (calidad, disponibilidad, rendimiento) como medidas de impacto empresarial. Rastree los patrones de uso, la satisfacción del usuario, el tiempo hasta la obtención de insights para los consumidores y los resultados empresariales directos habilitados por el producto de datos. Establezca métricas de referencia antes de la implementaci�ón y mida las mejoras a lo largo del tiempo.
¿Qué papel juega Unity Catalog en la gestión de productos de datos?
Unity Catalog sirve como base para la gobernanza de productos de datos al proporcionar gestión centralizada de metadatos, controles de acceso, seguimiento de linaje y capacidades de descubrimiento. Le permite implementar contratos de datos a través de características como etiquetado, comentarios y definiciones de esquemas, al tiempo que proporciona auditabilidad y controles de cumplimiento necesarios para los productos de datos empresariales.
¿Cómo manejamos los cambios en los productos de datos publicados?
Implemente procesos formales de versionado y gestión de cambios para los productos de datos. Comunique los cambios a los consumidores con antelación, mantenga la compatibilidad retroactiva siempre que sea posible y proporcione rutas de migración para cambios disruptivos. Utilice las características de Unity Catalog para rastrear versiones y gestionar la transición entre ellas.
¿Podemos crear productos de datos sin adoptar una arquitectura de data mesh completa?
Absolutamente. Si bien el data mesh enfatiza la propiedad del dominio de los productos de datos, puede aplicar el pensamiento de producto a sus activos de datos independientemente de su estructura organizativa. Céntrese en las necesidades del usuario, la calidad y la usabilidad de sus datos e implemente una propiedad y gobernanza claras: estos principios crean valor incluso sin una implementación completa de data mesh.
¿Cómo garantizamos que nuestros productos de datos cumplan con las regulaciones en evolución?
Incorpore el cumplimiento en el ciclo de vida de su producto de datos, con revisiones periódicas por parte de su equipo de gobernanza. Implemente controles basados en metadatos en Unity Catalog para aplicar políticas automáticamente y utilice las características de linaje para comprender el impacto de los cambios regulatorios en sus productos de datos. Documente los requisitos de cumplimiento en sus contratos de datos y supervise el cumplimiento a través de registros de auditoría.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.