Creación de un copiloto de riesgo regulatorio con Databricks Agent Bricks (Parte 1: Extracción de información)
Aprenda a transformar las cartas de rechazo no estructuradas de la FDA en información procesable con las funciones de AI de Databricks y Agent Bricks.
por Guanyu Chen y Diego Malaver
- Analice PDF complejos: a diferencia de los enfoques tradicionales que requieren equipos y miles de líneas de código, simplemente utilice la función ai_parse_document() para analizar de forma fiable texto e imágenes de documentos PDF complejos como las Cartas de respuesta completa (CRL) de la FDA.
- Extraiga información de forma colaborativa: descubra cómo utilizar los Agent Bricks de extracción de información para permitir que los expertos en negocios y los ingenieros de IA definan, prueben y perfeccionen de forma colaborativa la extracción de datos estructurados en tiempo real.
- Ponga en producción con SQL: implementación con un solo clic de su agente perfeccionado como un endpoint sin servidor y utilice la función ai_query() para crear una canalización escalable y lista para producción para procesar nuevos documentos directamente en su Lakehouse.
En julio de 2025, la FDA de EE. UU. publicó un lote inicial de más de 200 cartas de respuesta completa (CRL), cartas de decisión que explican por qué las solicitudes de medicamentos y productos biológicos no fueron aprobadas en una primera revisión, lo que marca un cambio importante en la transparencia. Por primera vez, los patrocinadores, los médicos y los equipos de datos pueden analizar la industria a través del propio lenguaje de la agencia sobre las deficiencias en los ámbitos clínico, de CMC, de seguridad, de etiquetado y de bioequivalencia, a través de PDF de la FDA centralizados, descargables y de acceso abierto.
A medida que la FDA continúa publicando nuevas CRL, la capacidad de generar rápidamente información valiosa a partir de estos y otros datos no estructurados, y agregarla a su inteligencia/datos internos, se convierte en una importante ventaja competitiva. Las organizaciones que pueden aprovechar eficazmente esta información valiosa de datos no estructurados, en forma de PDF, documentos, imágenes y más, pueden reducir el riesgo de sus propias presentaciones, identificar los escollos más comunes y, en última instancia, acelerar su llegada al mercado. El desafío es que estos datos, como muchos otros datos regulatorios, están bloqueados en PDF, que son notoriamente difíciles de procesar a gran escala.
Este es precisamente el tipo de desafío para el que se creó Databricks. Este blog demuestra cómo usar las últimas herramientas de AI de Databricks para acelerar la extracción de información clave atrapada en archivos PDF, convirtiendo estas cartas críticas en una fuente de inteligencia procesable.
Qué se necesita para tener éxito con la AI
Dada la profundidad técnica requerida, los ingenieros suelen liderar el desarrollo de forma aislada, lo que crea una gran brecha entre la construcción de la AI y los requisitos del negocio. Para cuando un experto en la materia (SME) ve el resultado, a menudo no es lo que necesitaba. El ciclo de retroalimentación es demasiado lento y el proyecto pierde impulso.
Durante las fases iniciales de prueba, es crucial establecer una base de referencia. En muchos casos, los enfoques alternativos requieren perder meses sin datos de referencia, dependiendo en su lugar de la observación subjetiva y las “sensaciones”. Esta falta de evidencia empírica frena el progreso. Por el contrario, las herramientas de Databricks proporcionan funciones de evaluación listas para usar y permiten a los clientes hacer hincapié en la calidad de inmediato, mediante un marco iterativo para obtener confianza matemática en la extracción. El éxito de la AI requiere un nuevo enfoque basado en una iteración rápida y colaborativa.
Databricks proporciona una plataforma unificada donde los expertos en la materia (SME) del negocio y los ingenieros de IA pueden trabajar juntos en tiempo real para crear, probar e implementar agentes con calidad de producción. Este marco se basa en tres principios clave:
- Alineación empresarial y técnica estrecha: los expertos en la materia y los líderes técnicos colaboran en la misma UI para obtener comentarios al instante, lo que reemplaza las lentas cadenas de correo electrónico.
- Evaluación de la verdad fundamental: las etiquetas de "verdad fundamental" definidas por el negocio se integran directamente en el flujo de trabajo para la puntuación formal.
- Un enfoque de plataforma completa: no se trata de un sandbox o una solución puntual; está totalmente integrada con pipelines automatizados, evaluación LLM-as-a-Judge, rendimiento de GPU fiable para producción y gobernanza de extremo a extremo de Unity Catalog.
Este enfoque de plataforma unificada es lo que convierte un prototipo en un sistema de AI confiable y listo para la producción. Repasemos los cuatro pasos para construirlo.
Del PDF a la producción: una guía de cuatro pasos
Crear un sistema de IA con calidad de producción sobre datos no estructurados requiere algo más que un buen modelo; requiere un flujo de trabajo fluido, iterativo y colaborativo. El Agent Brick de extracción de información, combinado con las funciones de IA integradas de Databricks, facilita el análisis de documentos, la extracción de información clave y la puesta en funcionamiento de todo el proceso. Este enfoque permite a los equipos avanzar más rápido y ofrecer resultados de mayor calidad. A continuación, desglosamos los cuatro pasos clave para la creación.
Paso 1: Análisis de PDF no estructurados a texto con ai_parse_document()
El primer obstáculo es obtener texto limpio de los PDF. Los CRL pueden tener diseños complejos con encabezados, pies de página, tablas y gráficos, distribuidos en varias páginas y columnas. Una simple extracción de texto a menudo fallará y producirá un resultado impreciso e inutilizable.
A diferencia de las frágiles soluciones puntuales que tienen dificultades con el formato, ai_parse_document() aprovecha la IA multimodal de última generación para comprender la estructura de los documentos, extrayendo con precisión el texto en orden de lectura, conservando las jerarquías irregulares de las tablas y generando pies de foto para las figuras.
Adem�ás, Databricks ofrece una ventaja en inteligencia de documentos al escalar de forma fiable para gestionar volúmenes de nivel empresarial de PDF complejos a un costo de 3 a 5 veces menor que el de los principales competidores. Los equipos no tienen que preocuparse por los límites de tamaño de los archivos, y el OCR y VLM subyacentes garantizan un análisis preciso de los “PDF problemáticos” históricos que contienen figuras densas e irregulares y otras estructuras complejas.
Lo que antes requería que numerosos científicos de datos configuraran y mantuvieran pilas de análisis personalizadas de múltiples proveedores, ahora se puede lograr con una única función nativa de SQL, lo que permite a los equipos procesar millones de documentos en paralelo sin los modos de falla que afectan a los analizadores menos escalables.
Para empezar, primero apunte un volumen de UC a su almacenamiento en la nube que contiene sus PDF. En nuestro ejemplo, apuntaremos la función SQL a los PDF de CRL administrados por un volumen:
Este único comando procesa todos sus PDF y crea una tabla estructurada con el contenido analizado y el texto combinado, dejándolo listo para el siguiente paso.
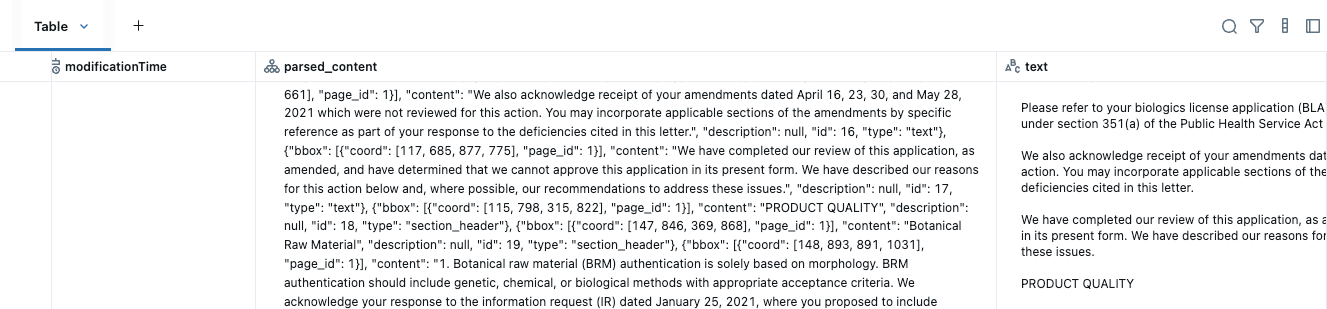
Tenga en cuenta que no fue necesario configurar ninguna infraestructura, red o llamada externa a LLM o GPU: Databricks aloja las GPU y el backend del modelo, lo que permite un rendimiento confiable y escalable sin configuración adicional. A diferencia de las plataformas que cobran tarifas de licencia, Databricks utiliza un modelo de precios basado en el cómputo, lo que significa que solo paga por los recursos que utiliza. Esto permite potentes optimizaciones de costos a través de la paralelización y la personalización a nivel de función en sus pipelines de producción.
Paso 2: Extracción de información iterativa con Agent Bricks
Una vez que tenga el texto, el siguiente objetivo es extraer campos específicos y estructurados. Por ejemplo: ¿Cuál fue la deficiencia? ¿Cuál fue el ID de la NDA? ¿Cuál fue la cita de rechazo? Aquí es donde los ingenieros de AI y los SME del negocio necesitan colaborar estrechamente. El SME sabe qué buscar y puede trabajar con el ingeniero para indicarle rápidamente al modelo cómo encontrarlo.
Agent Bricks: Extracción de información proporciona una UI colaborativa en tiempo real para este flujo de trabajo exacto.
Como se muestra a continuación, la interfaz permite que un líder técnico y un experto en la materia (SME) del negocio trabajen juntos:
- El experto en la materia (SME) del negocio proporciona los campos específicos que se deben extraer (p. ej.,
deficiency_summary_paragraphs, NDA_ID, FDA_Rejection_Citing). - El agente de extracción de información traducirá estos requisitos en prompts eficaces; estas pautas editables se encuentran en el panel derecho.
- Tanto el líder técnico como el SME del negocio pueden ver inmediatamente la salida JSON en el panel central y validar si el modelo está extrayendo correctamente la información del documento de la izquierda. A partir de aquí, cualquiera de los dos puede reformular un prompt para garantizar extracciones precisas.
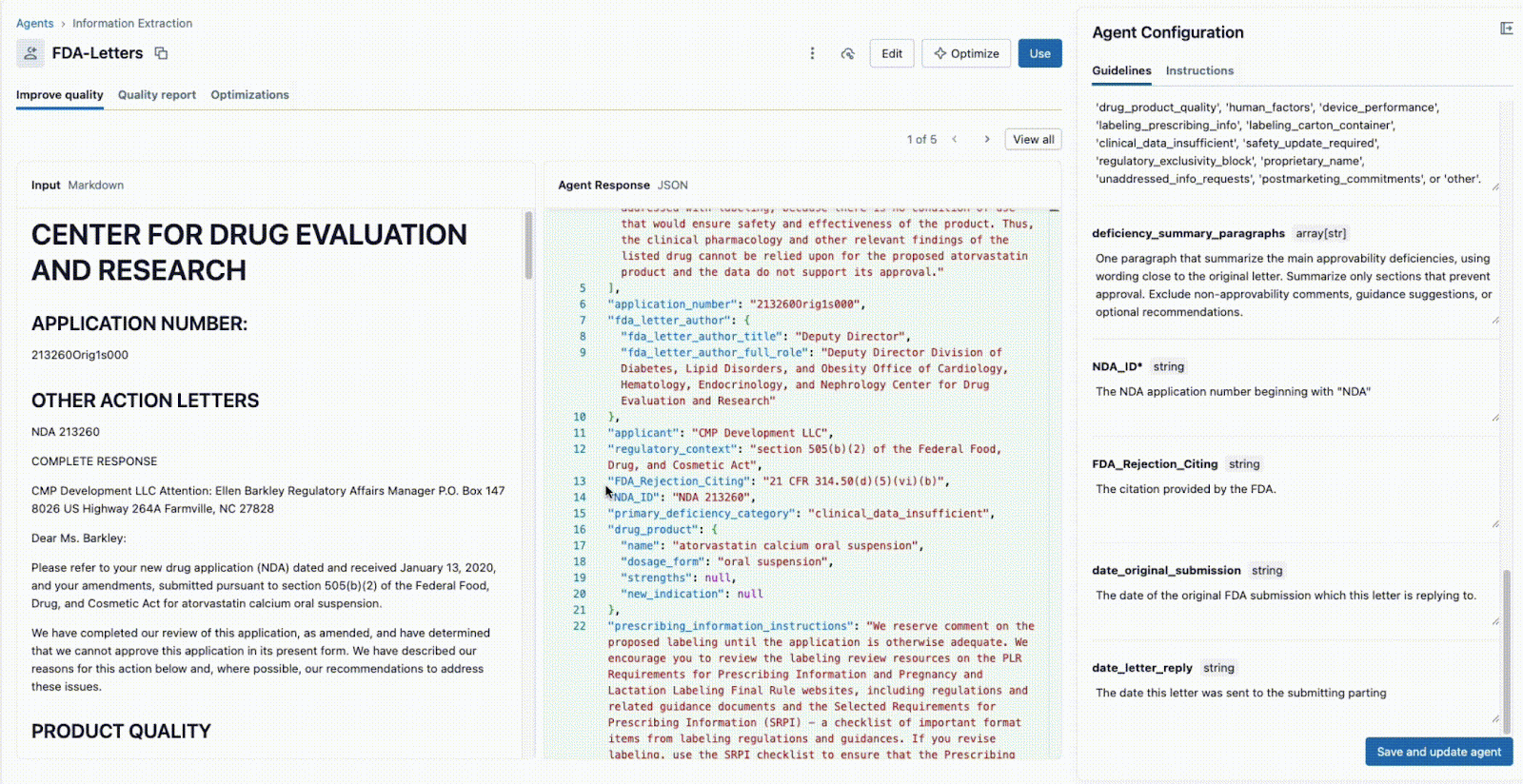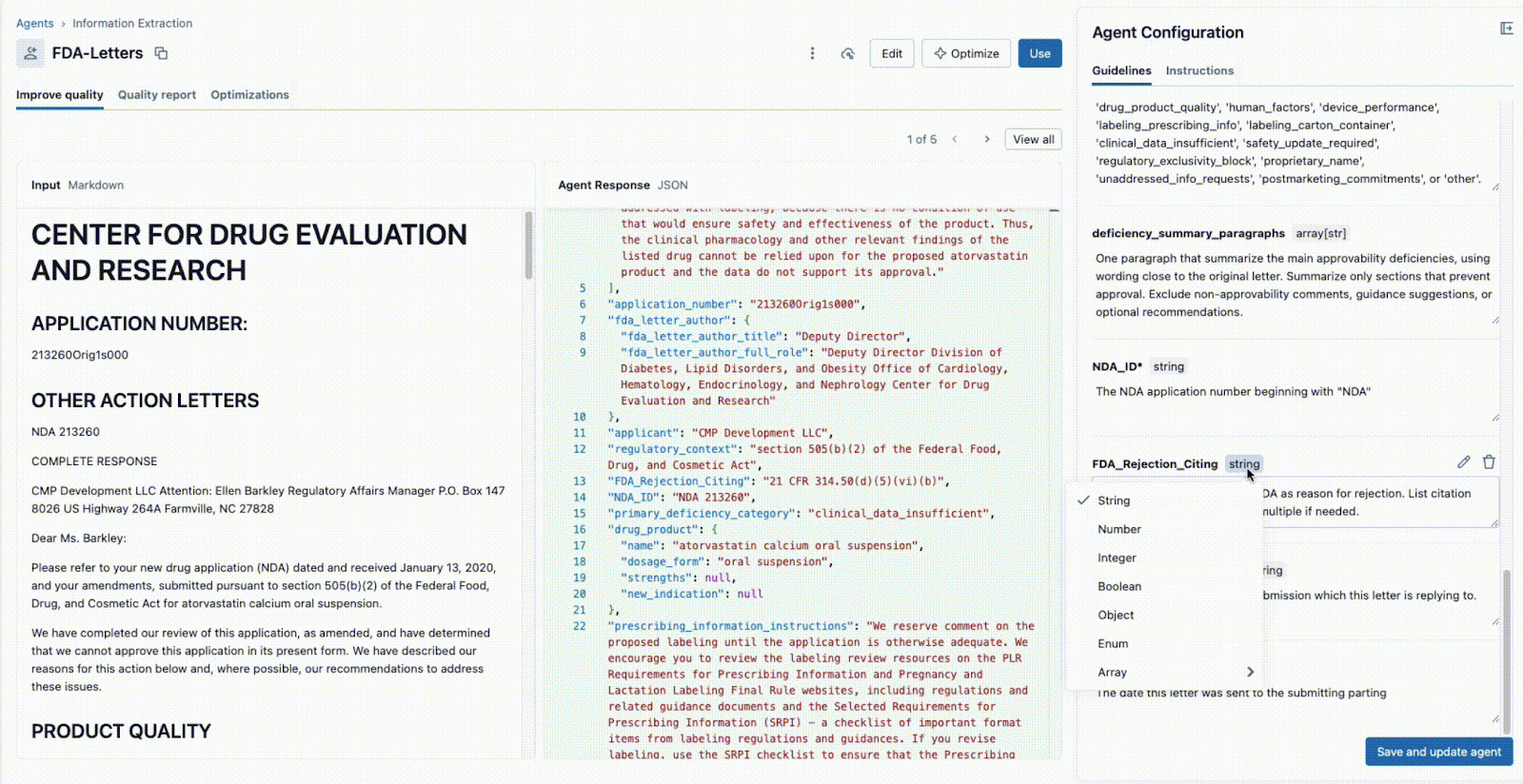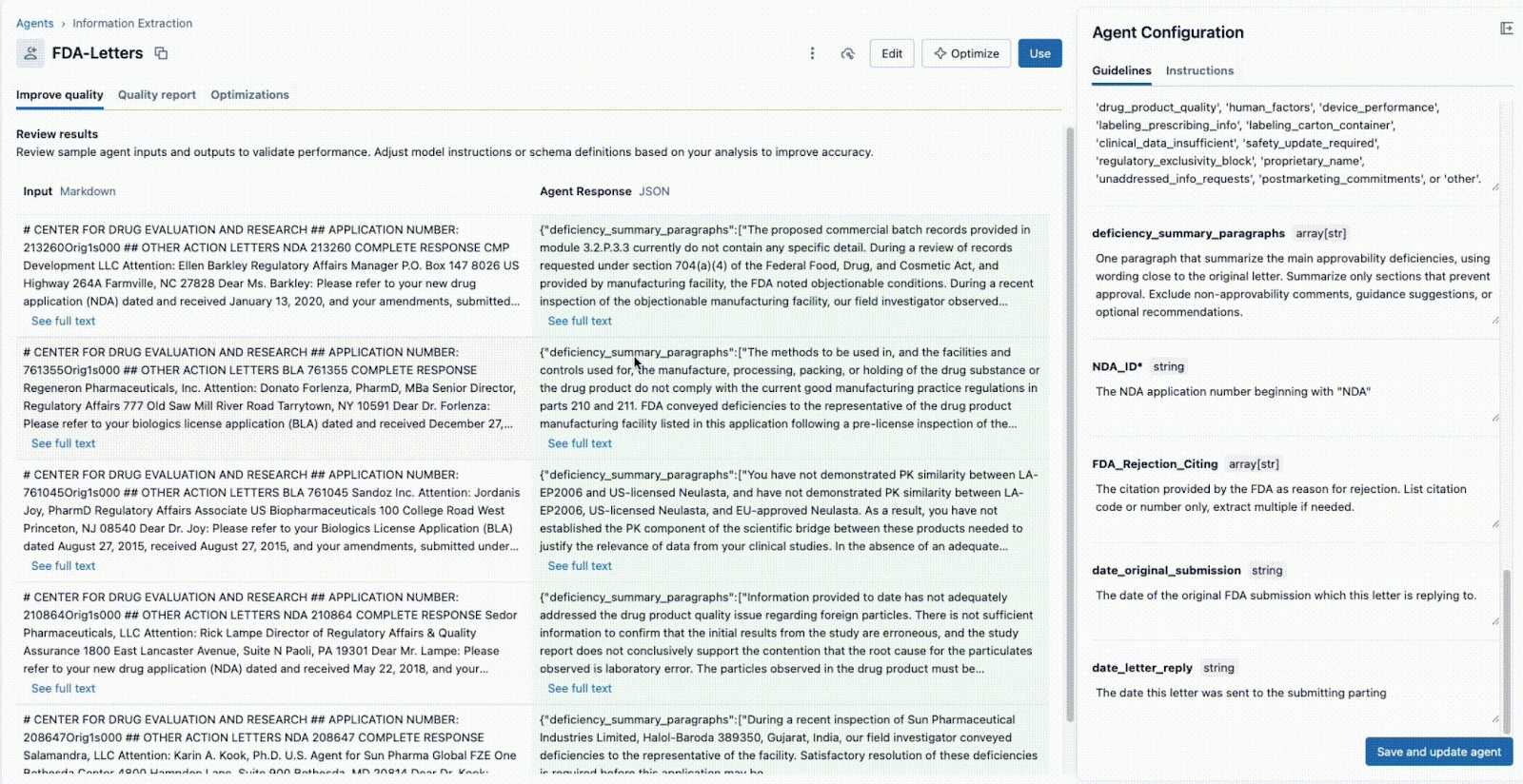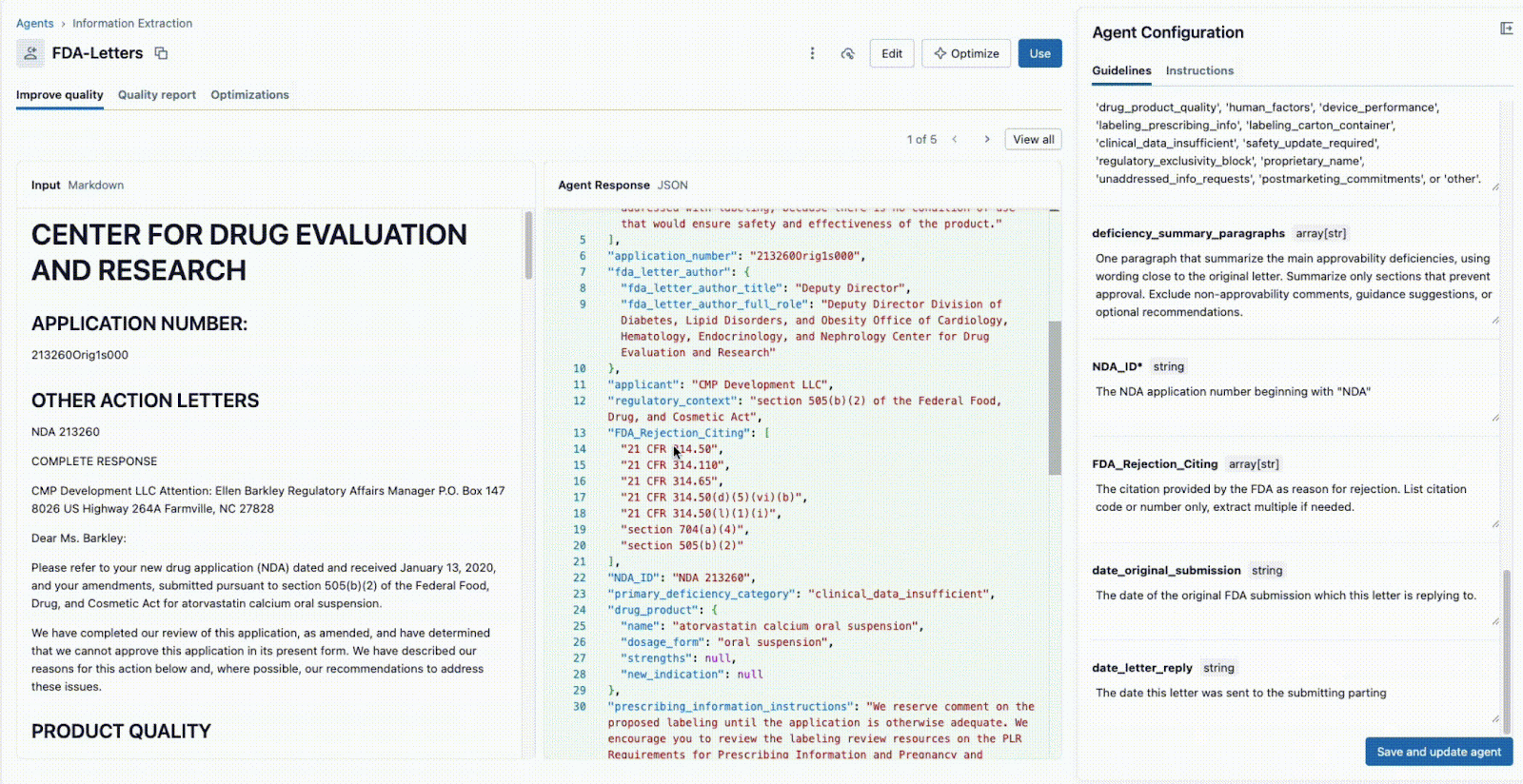
Este ciclo de retroalimentación instantánea es la clave del éxito. Si un campo no se extrae correctamente, el equipo puede ajustar el prompt, agregar un nuevo campo o refinar las instrucciones y ver el resultado en segundos. Este proceso iterativo, en el que varios expertos colaboran en una única interfaz, es lo que diferencia a los proyectos de IA exitosos de los que fracasan en silos.
Paso 3: Evaluar y validar el agente
En el paso 2, creamos un agente que, a simple vista, parecía correcto durante el desarrollo iterativo. Pero ¿cómo garantizamos una alta precisión y escalabilidad al procesar nuevos datos? Un cambio en el prompt que soluciona un documento podría estropear otros diez. Aquí es donde entra en juego la evaluación formal, una parte fundamental e integrada del flujo de trabajo de Agent Bricks.
Este paso es su puerta de calidad y proporciona dos métodos potentes para la validación:
Método A: Evaluar con etiquetas de datos de referencia (El estándar de oro)
La AI, como cualquier proyecto de ciencia de datos, fracasa en el vacío sin un conocimiento adecuado del dominio. Una inversión de los SME para proporcionar un "conjunto de oro" (también conocido como datos de referencia, conjuntos de datos etiquetados) de información correcta y relevante extraída manualmente y validada por humanos, ayuda en gran medida a garantizar que esta solución se generalice a nuevos archivos y formatos. Esto se debe a que los pares clave-valor etiquetados ayudan rápidamente al agente a ajustar indicaciones de alta calidad que conducen a extracciones precisas y relevantes para el negocio. Profundicemos en cómo Agent Bricks utiliza estas etiquetas para calificar formalmente a su agente.
Dentro de la interfaz de usuario de Agent Bricks, proporcione el conjunto de datos de prueba de verdad fundamental y, en segundo plano, Agent Bricks se ejecuta en los documentos de prueba. La interfaz de usuario proporcionará una comparación en paralelo de la salida extraída de su agente frente a la respuesta etiquetada "correcta".
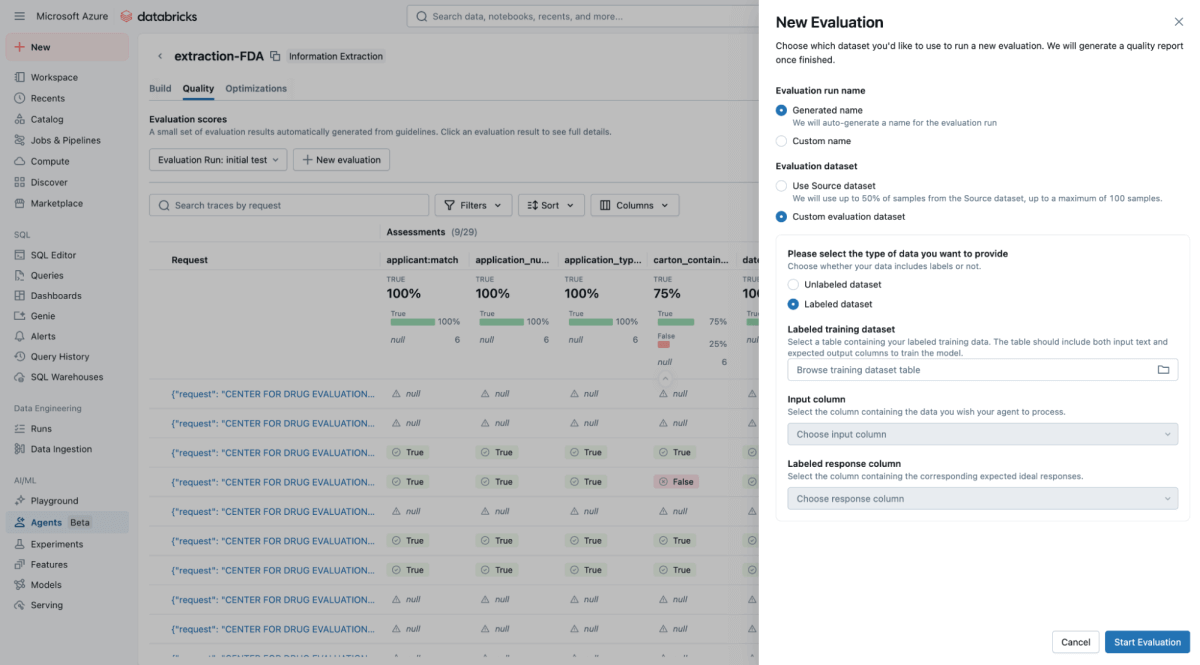
La UI proporciona un puntaje de precisión claro para cada campo de extracción, lo que le permite detectar regresiones al instante cuando cambia un prompt. Con los Agent Bricks, usted obtiene confianza a nivel de negocio de que el agente está rindiendo con una precisión igual o superior a la humana.
Método B: ¿Sin etiquetas? Utilice LLM-as-a-Judge
¿Pero qué pasa si está empezando desde cero y no tiene etiquetas de verdad fundamental (ground truth)? Este es un problema común de "arranque en frío".
El conjunto de evaluación de Agent Bricks proporciona una solución potente: LLM-as-a-Judge. Databricks proporciona un conjunto de marcos de evaluación, y Agent Bricks aprovechará los modelos de evaluación para actuar como un evaluador imparcial. Al modelo "Juez" se le presenta el texto del documento original y un conjunto de indicaciones de campo para cada documento. La función del “Juez” es generar una respuesta "esperada" y luego evaluarla en comparación con el resultado extraído por el agente.
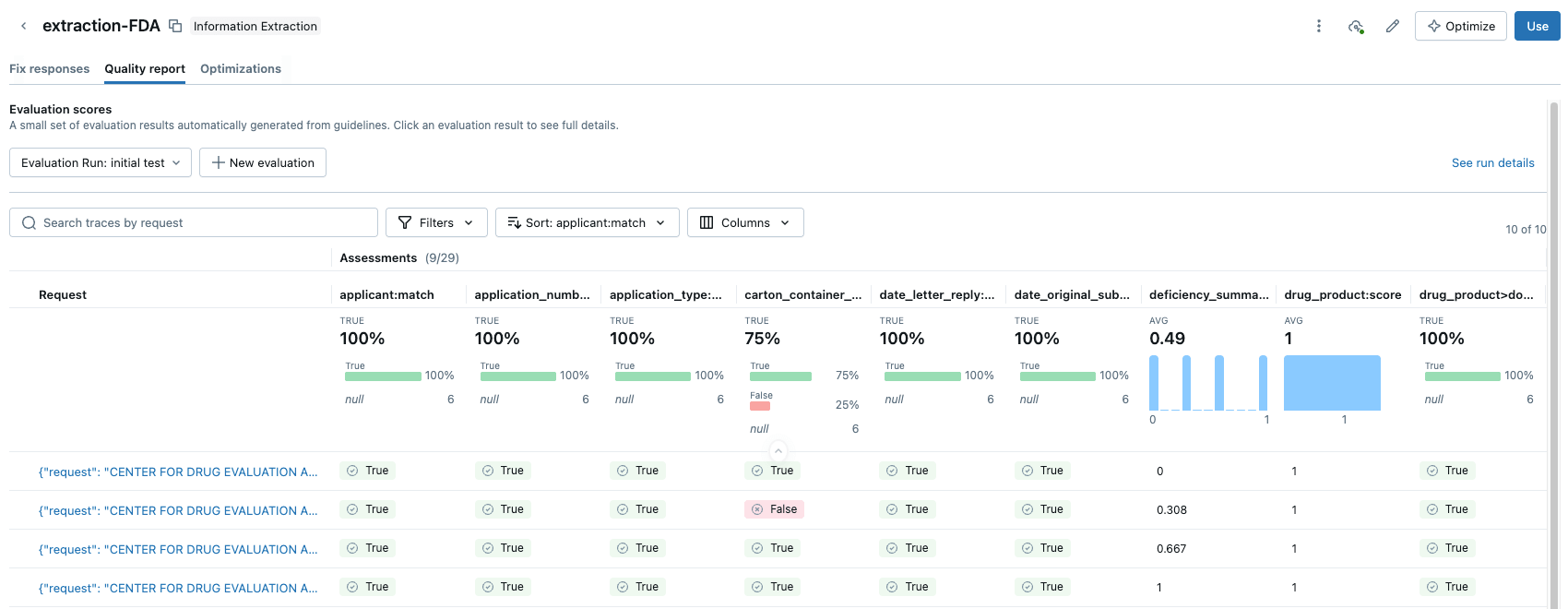
LLM-as-a-Judge le permite obtener una puntuación de evaluación escalable y de alta calidad y, además, también se puede utilizar en producción para garantizar que los agentes sigan siendo confiables y generalizables a la variabilidad y escala de la producción. Más sobre esto en un futuro blog.
Paso 4: Integración del agente con ai_query() en tu canalización de ETL
En este punto, usted construyó su agente en el Paso 2 y validó su precisión en el Paso 3, y ahora tiene la confianza para integrar la extracción en su flujo de trabajo. Con un solo clic, puede implementar su agente como un punto final de modelo sin servidor; de inmediato, su lógica de extracción está disponible como una función simple y escalable.
Para ello, utilice la función ai_query() en SQL para aplicar esta lógica a los nuevos documentos a medida que llegan. La función ai_query() le permite invocar cualquier endpoint de servicio de modelos de forma directa y transparente en su canalización de datos ETL de extremo a extremo.
Con esto, Databricks Lakeflow Jobs garantiza que tengas una canalización de ETL totalmente automatizada y de nivel de producción. Tu trabajo de Databricks toma los PDF sin procesar que llegan a tu almacenamiento en la nube, los analiza, extrae información estructurada con tu agente de alta calidad y los deposita en una tabla lista para su análisis, la generación de informes o para ser referenciada en la recuperación de una aplicación de agente descendente.
Databricks es la plataforma de IA de última generación que derriba las barreras entre los equipos muy técnicos y los expertos en el dominio que tienen el contexto necesario para crear una IA significativa. El éxito con la IA no se trata solo de modelos o infraestructura; es la colaboración estrecha e iterativa entre los ingenieros y los SME, donde cada uno refina el pensamiento del otro. Databricks ofrece a los equipos un entorno único para codesarrollar, experimentar rápidamente, gobernar de manera responsable y devolverle la ciencia a la ciencia de datos.
Agent Bricks es la encarnación de esta visión. Con ai_parse_document() para analizar contenido no estructurado, la interfaz de diseño colaborativo de Agent Bricks: Information Extraction para acelerar las extracciones de alta calidad y ai_query() para aplicar la solución en canalizaciones de nivel de producción, los equipos pueden pasar de millones de PDF desordenados a información validada más rápido que nunca.
En nuestro próximo blog, mostraremos cómo tomar esta información extraída y crear un agente de chat de nivel de producción capaz de responder a preguntas en lenguaje natural como: “¿Cuáles son los problemas más comunes de preparación para la fabricación de medicamentos oncológicos?”
- Más información: Lea la documentación oficial de ai_parse_document(), Agent Bricks: Extracción de información y ai_query().
- Comenzar: Regístrese para obtener una prueba gratuita de Databricks y cree hoy mismo sus propias soluciones basadas en IA.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.