La inteligencia de operaciones clínicas pertenece al Lakehouse
Cómo las aplicaciones Databricks, Lakebase y AI/BI Genie eliminan la pila de integración entre datos clínicos y aplicaciones de soporte a la toma de decisiones — y por qué ese cambio arquitectónico es lo que las operaciones clínicas han estado esperando.
- Qué es: El Site Feasibility Workbench es una aplicación Databricks de código abierto que ejecuta la selección de sitios de ensayos clínicos completamente dentro del espacio de trabajo Databricks — combinando puntuación de sitios impulsada por ML, Lakebase para el estado operativo y AI/BI Genie para acceso a datos en lenguaje natural, sin llamadas a API externas ni canalizaciones de sincronización.
- El desafío que resuelve: El 37% de los sitios investigadores no alcanzan los objetivos de inscripción, y la causa raíz es arquitectónica — los datos de operaciones clínicas y las aplicaciones que los utilizan residen en sistemas desconectados, forzando decisiones en hojas de cálculo y creando sobrecarga de integración, proliferación de credenciales y retraso de sincronización que erosiona la confianza en los datos.
- Resultados y logros: Los modelos LightGBM segmentados por TA entrenados con su propio historial de CTMS, EDC e IRT — no con promedios de la industria — producen puntuaciones que mejoran a medida que su cartera crece, con explicaciones impulsadas por SHAP almacenadas como tablas Delta gobernadas y versionadas. Cada predicción lleva atribución impulsada por SHAP almacenada como una tabla Delta gobernada, haciendo que la lógica del modelo sea tan auditable y versionada como la puntuación misma.
El problema de los datos clínicos no es un problema de almacenamiento. La mayoría de las organizaciones ya tienen un almacén de datos, un CTMS, un EDC y, en algún punto posterior, una capa de BI. El problema es que ninguno de estos sistemas se comunica entre sí de una manera que respalde las decisiones reales que los equipos clínicos necesitan tomar, y por lo tanto, las decisiones se toman en hojas de cálculo en su lugar.
Hoy lanzamos el Site Feasibility Workbench como una Databricks App completamente de código abierto, para mostrar cómo se ve la inteligencia de operaciones clínicas cuando la aplicación, los modelos y los datos residen en la misma plataforma. El Tufts Center for the Study of Drug Development ha documentado que el 37% de los sitios investigadores activados inscribieron menos pacientes de los previstos, y un 11% adicional no inscribió a ningún paciente, lo que resulta en que el 53% de los ensayos excedieron sus plazos de inscripción planificados, y uno de cada seis tardó más del doble de lo planeado (Lamberti et al.; los informes de impacto posteriores del CSDD continúan rastreando el bajo rendimiento a niveles similares). Hasta 500.000 $ por día en ventas de medicamentos no realizadas y 40.000 $ por día en costos directos del ensayo, el bajo rendimiento crónico del sitio es uno de los impulsores de costos más importantes en el desarrollo de fármacos. Esa tasa combinada de bajo rendimiento se ha mantenido esencialmente plana durante al menos dos décadas. Las herramientas no son el problema. La arquitectura sí lo es.
Los equipos de operaciones clínicas no necesitan más paneles de control conectados a los sistemas existentes. Necesitan que sus aplicaciones de soporte a la toma de decisiones residan donde residen sus datos y modelos, para que el ciclo de retroalimentación entre una predicción y el resultado operativo que la valida realmente se cierre.
El Argumento de la Arquitectura
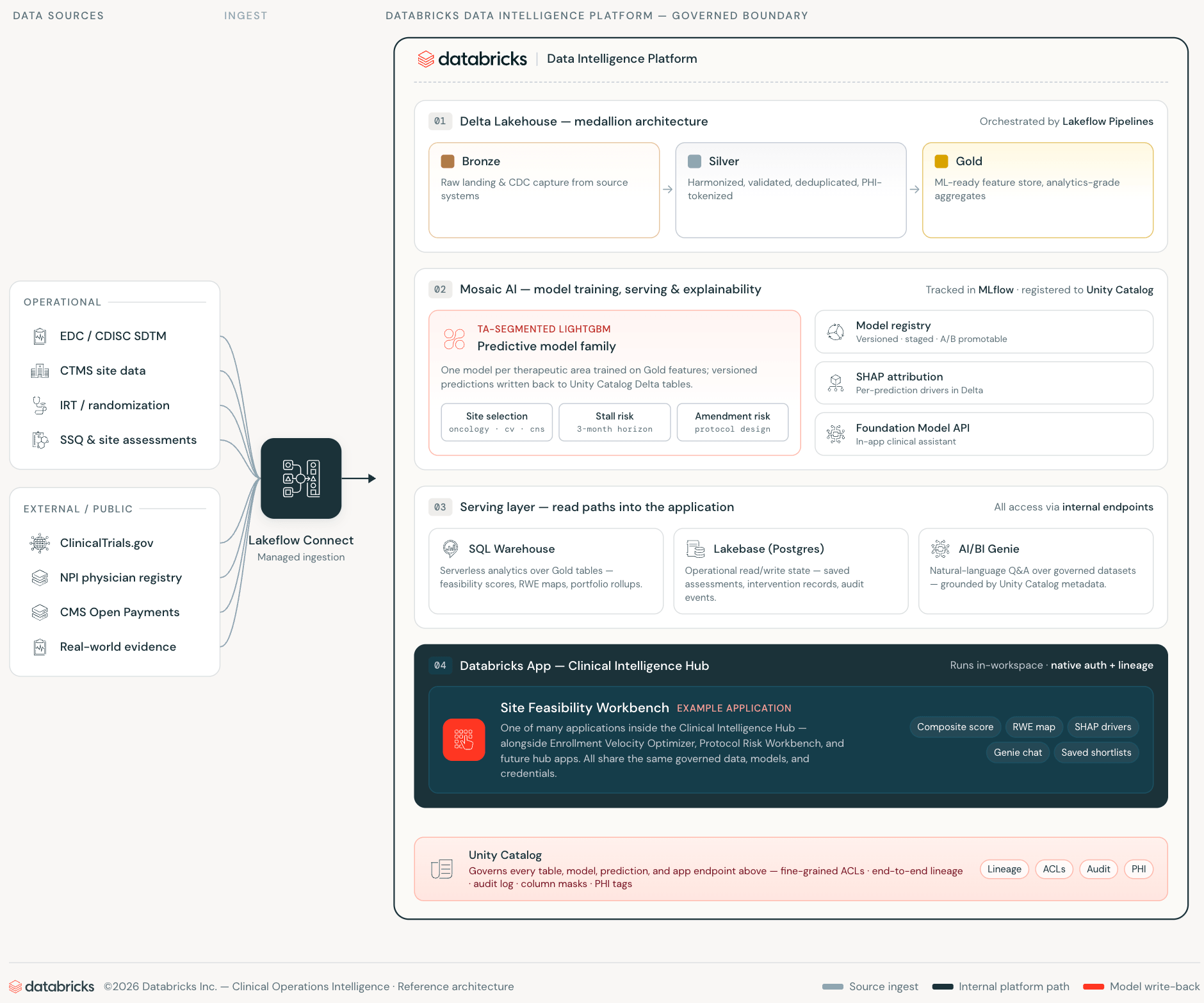
El enfoque convencional para el soporte de decisiones clínicas se ve así: los datos analíticos residen en un almacén de datos o Lakehouse. Una base de datos de aplicaciones separada contiene el estado operativo. Una canalización los mantiene débilmente sincronizados. Una aplicación web se sitúa delante de ambos, añadiendo armonización semántica en la capa Silver. Cada capa introduce sobrecarga de integración, superficie de credenciales y un retraso de sincronización que erosiona la confianza en los datos que muestra la aplicación.
Databricks Apps, Lakebase y AI/BI Genie eliminan cada una de esas capas, no al abstraerlas, sino al hacerlas innecesarias.
Databricks Apps ejecuta la aplicación web dentro del espacio de trabajo. La aplicación se autentica como un principal de servicio del espacio de trabajo de primera clase, consulta Unity Catalog a través de la API de sentencias SQL y llama a AI/BI Genie a través de la API REST del espacio de trabajo, todo ello en conexiones internas. Los datos de operaciones clínicas nunca cruzan un límite del espacio de trabajo. La aplicación hereda los controles de acceso de Unity Catalog sin ninguna configuración adicional.
Lakebase es la capa de base de datos operativa, PostgreSQL administrado que escala a cero cuando está inactivo, aprovisionado y con credenciales completamente dentro del sistema de identidad del espacio de trabajo. Donde una aplicación tradicional requeriría una instancia RDS administrada por separado con su propio esquema, trabajos de sincronización y rotación de credenciales, Lakebase está en la misma plataforma donde residen los datos y los modelos.
AI/BI Genie cierra la última brecha: acceso en lenguaje natural a datos gobernados, incrustado directamente en el flujo de trabajo de la aplicación. Los gerentes de estudio hacen preguntas en lenguaje natural contra las mismas tablas de Unity Catalog en las que se entrenaron los modelos de ML, con los mismos controles de acceso aplicados.
El resultado es una aplicación de operaciones clínicas que no realiza llamadas API externas, no mantiene infraestructura de base de datos operativa separada y no requiere ninguna canalización de sincronización entre las capas analítica y operativa.
El Argumento de la Auditabilidad
El enfoque estándar de la industria para la viabilidad del sitio se basa en productos de puntuación comerciales de proveedores o plataformas de análisis proporcionadas por CRO. Esas herramientas se basan en datos agregados de la industria, útiles como línea de base, pero ciegas a los detalles específicos de su cartera. Un patrocinador con una década de historial de CTMS, EDC e IRT tiene señales significativas sobre el rendimiento de sus sitios en sus protocolos.
Cuando la pila de ML reside en Databricks, ese conocimiento institucional se convierte en los datos de entrenamiento. Los modelos en este workbench se entrenan con sus tasas de inscripción históricas, su historial de calificación de sitios, sus patrones de fallos de cribado y su historial de ejecución de protocolos, no con promedios de la industria. CMS Open Payments añade una capa de señal pública que, cuando se utiliza adecuadamente, se correlaciona con el compromiso y la infraestructura de investigación y está disponible gratuitamente. A medida que la cartera de ensayos crece, los modelos mejoran en la misma infraestructura. Ese es el retorno compuesto que permite una arquitectura de plataforma única y que un producto de puntuación con licencia no puede ofrecer: cada nuevo estudio mejora la predicción, y cada nueva relación con un sitio se refleja en la próxima ejecución de entrenamiento. MLflow rastrea cada ejecución de entrenamiento de modelos, parámetros, métricas y artefactos, lo que permite la comparación entre versiones de modelos, la reproducibilidad bajo demanda y una pista de auditoría completa desde los registros brutos de CTMS y EDC hasta la predicción implementada.
La dimensión regulatoria también es importante aquí. 21 CFR Part 11, ICH E6(R3) y la guía de Buenas Prácticas de Aprendizaje Automático (GMLP) de la FDA, junto con el creciente énfasis de la FDA en la transparencia en el soporte de decisiones algorítmicas, hacen que la explicabilidad del modelo y la gobernanza de datos sean consideraciones materiales, no características opcionales. Dado que cada predicción lleva una atribución SHAP almacenada como una tabla Delta gobernada de Unity Catalog —versionada en MLflow, con linaje a través de Unity Catalog, consultable— la justificación detrás de la selección de un sitio es tan auditable como la puntuación misma. Un equipo de asuntos clínicos puede responder a una pregunta de un comité de monitorización de datos con una consulta SQL, no con un informe de proveedor de caja negra.
Lo que Construimos
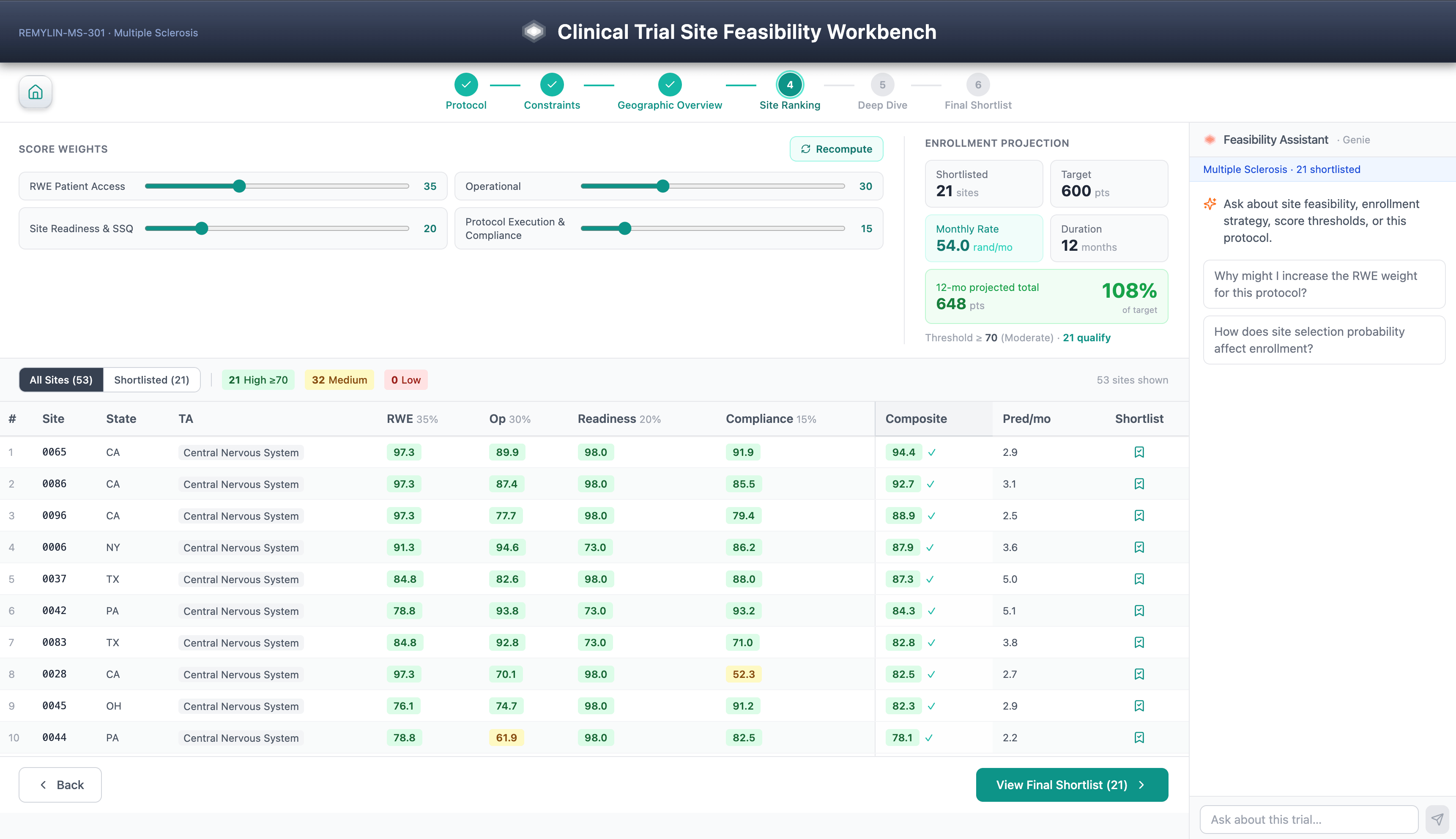
El Site Feasibility Workbench es un flujo de trabajo guiado de seis pasos para la selección de sitios de ensayos clínicos: selección de protocolo, restricciones de puntuación, vista general geográfica, clasificación de sitios, análisis profundo de sitios impulsado por SHAP y lista corta final. Las consideraciones de diversidad son una dimensión de puntuación de primera clase, alineada con las expectativas del Plan de Acción de Diversidad de la FDA bajo FDORA 2022.
Las puntuaciones compuestas de viabilidad combinan evidencia del mundo real, datos de acceso a pacientes, rendimiento histórico del sitio, historial de calificación del sitio, señal KOL de Open Payments y factores de ejecución del protocolo, todo ello impulsado por modelos LightGBM segmentados por TA entrenados en el historial CTMS, EDC e IRT de la organización.
La parte que vale la pena enfatizar no son los pasos del flujo de trabajo ni las características del modelo. Los datos a nivel de paciente heredan los controles de acceso de Unity Catalog y el manejo de PHI sigue la postura de HIPAA Safe Harbor / Expert Determination del patrocinador configurada a nivel de catálogo o esquema.
Es lo que la arquitectura hace posible: cada predicción lleva una explicación SHAP almacenada como una tabla Delta gobernada junto con la predicción misma, lo que hace que la justificación del modelo sea tan auditable y versionada como la puntuación que explica. Dado que cada predicción se descompone en atribuciones SHAP gobernadas, los patrocinadores pueden auditar las recomendaciones de subponderación sistemática de sitios comunitarios, instituciones que atienden a minorías o investigadores primerizos, convirtiendo la explicabilidad en un control de equidad.
Las listas cortas guardadas persisten en Lakebase para compartir en equipo. El asistente AI/BI Genie responde preguntas interdominio contra las mismas tablas de Unity Catalog en lenguaje natural. Nada de esto requiere infraestructura fuera del espacio de trabajo.
Esta es una capa de soporte a la toma de decisiones, no un sistema fuente de registro. El CTMS/EDC/IRT siguen siendo autoritativos. El workbench produce predicciones cuyo linaje está gobernado en Unity Catalog y MLflow.
La aplicación completa —backend FastAPI, frontend React, notebooks semilla y scripts de despliegue— se publica como un repositorio de código abierto. El despliegue en un espacio de trabajo Databricks existente con Unity Catalog toma aproximadamente 30 minutos de tiempo de despliegue técnico, antes de la revisión de seguridad y validación específica del patrocinador.
Un Módulo de una Plataforma Más Grande
El Site Feasibility Workbench es la primera versión pública de una arquitectura más amplia — el Databricks Clinical Operations Intelligence Hub — que cubre el ciclo de vida completo del ensayo:
- Viabilidad y Selección del Sitio — lo que cubre este repositorio
- Cohorte y Reclutamiento de Pacientes — creación de cohortes alineadas con el protocolo a partir de EHR y evidencia del mundo real a escala Lakehouse
- Optimizador de Velocidad de Inscripción — predicción de estancamiento de ML por sitio por mes con un horizonte de 1 a 3 meses
- Monitoreo y Cumplimiento Basado en Riesgos — monitoreo continuo de anomalías en la inscripción, retrasos en los datos y desviaciones del protocolo
Los cuatro se implementan como Databricks Apps. Los cuatro consultan Unity Catalog directamente. Ninguno realiza llamadas a API externas. Cuando las aplicaciones clínicas viven donde viven sus datos y modelos, el ciclo de retroalimentación se cierra. Los modelos de selección de sitios aprenden de los resultados de la inscripción. Las puntuaciones de riesgo se actualizan a medida que crece el historial de enmiendas. Cada recomendación impulsada por IA lleva un rastro de linaje hasta los registros CTMS, EDC e IRT que la produjeron.
Comienza
Clona el repositorio público. Implementa. Dinos qué cambias.
Para el Clinical Operations Intelligence Hub completo — mira la grabación de BrickTalk: Scaling BioPharma Intelligence + Databricks Agentic Clinical Ops. BrickTalk.
Lakebase y Databricks Apps en producción cubren los primitivos de la plataforma en profundidad.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.