Clinical operations intelligence belongs on the Lakehouse
How Databricks Apps, Lakebase, and AI/BI Genie eliminate the integration stack between clinical data and decision-support applications — and why that architecture change is what clinical operations have been missing.
- What it is: The Site Feasibility Workbench is an open-source Databricks App that runs clinical trial site selection entirely within the Databricks workspace — combining ML-driven site scoring, Lakebase for operational state, and AI/BI Genie for natural language data access, with no external API calls or synchronization pipelines.
- The challenge it solves: 37% of investigator sites miss enrollment targets, and the root cause is architectural — clinical operations data and the applications that use it live in disconnected systems, forcing decisions into spreadsheets and creating integration overhead, credential sprawl, and synchronization lag that erodes trust in the data.
- Results and outcomes: TA-segmented LightGBM models trained on your own CTMS, EDC, and IRT history — not industry averages — produce scores that improve as your portfolio grows, with SHAP-driven explanations stored as governed, versioned Delta tables. Every prediction carries SHAP-driven attribution stored as a governed Delta table, making model rationale as auditable and versioned as the score itself.
The clinical data problem is not a storage problem. Most organizations already have a data warehouse, a CTMS, an EDC, and somewhere downstream, a BI layer. The problem is that none of these systems talk to each other in a way that supports the actual decisions clinical teams need to make — and so the decisions get made in spreadsheets instead.
Today we are releasing the Site Feasibility Workbench as a fully open-source Databricks App — to show what clinical operations intelligence looks like when the application, the models, and the data live on the same platform. The Tufts Center for the Study of Drug Development has documented that 37% of activated investigator sites enrolled fewer patients than their targets, and an additional 11% enrolled no patients at all — the combined effect being that 53% of trials exceeded their planned enrollment timelines, with one in six taking more than twice as long as planned (Lamberti et al.; subsequent CSDD impact reports continue to track underperformance at similar levels). Up to $500,000 per day in unrealized drug sales and $40,000 per day in direct trial costs, chronic site underperformance is one of the most consequential cost drivers in drug development. That combined underperformance rate has remained essentially flat for at least two decades. The tools are not the problem. The architecture is.
Clinical operations teams do not need more dashboards connected to existing systems. They need their decision-support applications to live where their data and models live — so that the feedback loop between a prediction and the operational outcome that validates it actually closes.
The Architecture Argument
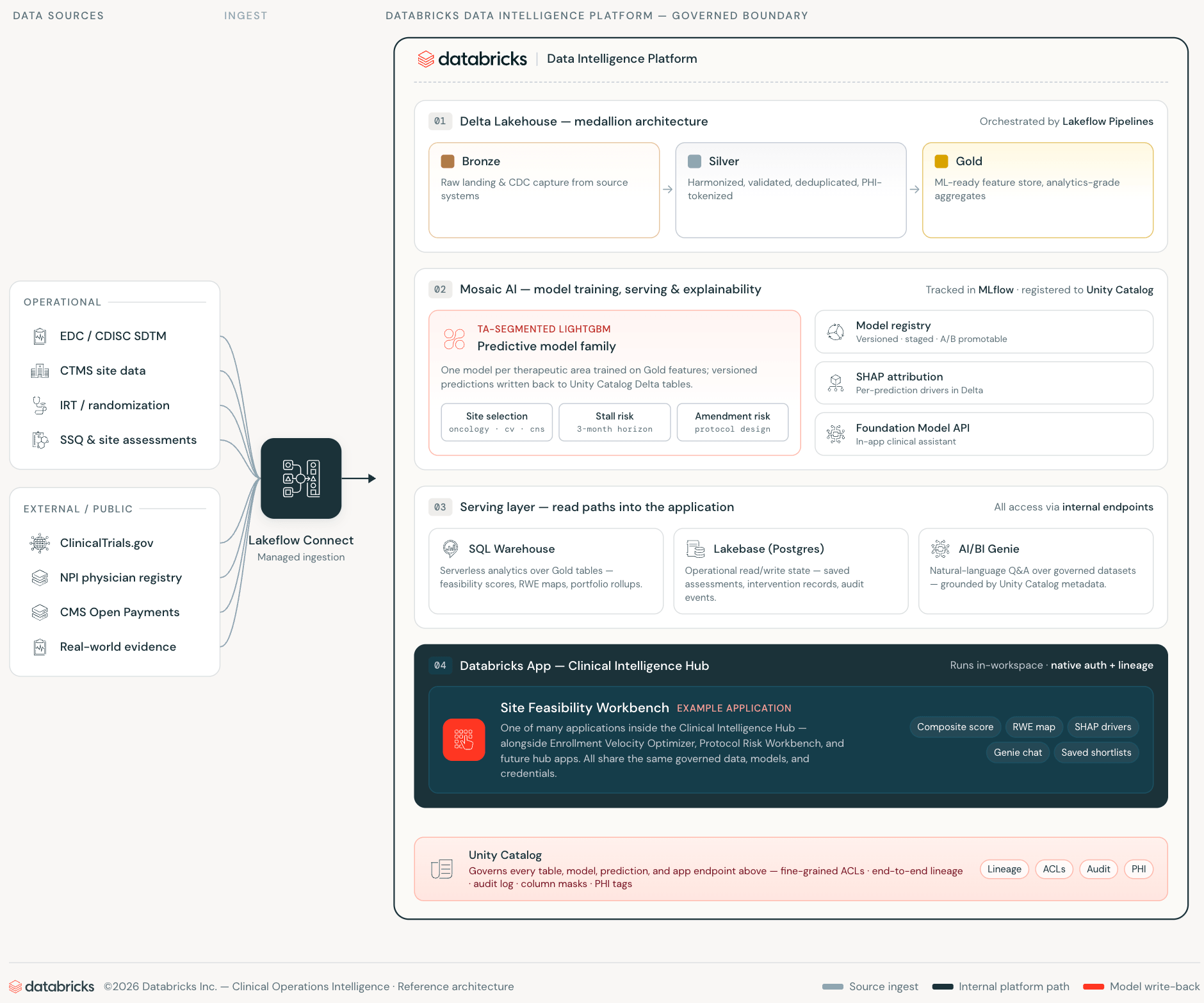
The conventional approach to clinical decision-support looks like this: analytical data lives in a data warehouse or Lakehouse. A separate application database holds operational state. A pipeline keeps them loosely synchronized. A web application sits in front of both, adding semantic harmonization in the Silver layer. Every layer introduces integration overhead, credential surface area, and a synchronization lag that erodes trust in the data the application shows.
Databricks Apps, Lakebase, and AI/BI Genie eliminate each of those layers — not by abstracting them away but by making them unnecessary.
Databricks Apps run the web application inside the workspace. The app authenticates as a first-class workspace service principal, queries Unity Catalog via the SQL Statement API, and calls AI/BI Genie over the workspace REST API — all on internal connections. Clinical operations data never crosses a workspace boundary. The app inherits Unity Catalog access controls without any additional configuration.
Lakebase is the operational database layer — managed PostgreSQL that scales to zero when idle, provisioned and credentialed entirely within the workspace identity system. Where a traditional application would require a separately managed RDS instance with its own schema drift, sync jobs, and credential rotation, Lakebase is in the same platform where the data and models live.
AI/BI Genie closes the last gap: natural language access to governed data, embedded directly in the application workflow. Study managers ask questions in plain English against the same Unity Catalog tables the ML models trained on, with the same access controls applied.
The result is a clinical operations application that makes no external API calls, maintains no separate operational database infrastructure, and requires no synchronization pipeline between the analytical and operational layers.
The Auditability Argument
The standard industry approach to site feasibility relies on commercial scoring products from vendors or CRO-provided analytics platforms. Those tools are built on aggregated industry data — useful as a baseline, but blind to the specifics of your portfolio. A sponsor with a decade of CTMS, EDC, and IRT history carries significant signals about how their sites perform on their protocols.
When the ML stack lives on Databricks, that institutional knowledge becomes the training data. The models in this workbench are trained on your historical enrollment rates, your site qualification history, your screen failure patterns, and your protocol execution record — not industry averages. CMS Open Payments adds a public signal layer that, when used appropriately, correlates with research engagement and infrastructure and it is freely available. As the trial portfolio grows, the models improve on the same infrastructure. That is the compounding return that a single-platform architecture enables and that a licensed scoring product cannot: every new study makes the prediction better, and every new site relationship is reflected in the next training run. MLflow tracks every model training run, parameters, metrics, and artifact — enabling comparison across model versions, reproducibility on demand, and a complete audit trail from raw CTMS and EDC records to deployed prediction.
The regulatory dimension matters here too. 21 CFR Part 11, ICH E6(R3), and FDA's Good Machine Learning Practice (GMLP) guidance, along with increasing FDA emphasis on transparency in algorithmic decision support, make model explainability and data governance material considerations, not optional features. Because every prediction carries a SHAP attribution stored as a governed Unity Catalog Delta table — versioned in MLflow, lineaged through Unity Catalog, queryable — the rationale behind a site selection is as auditable as the score itself. A clinical affairs team can answer a question from a data monitoring committee with a SQL query, not a black-box vendor report.
What We Built
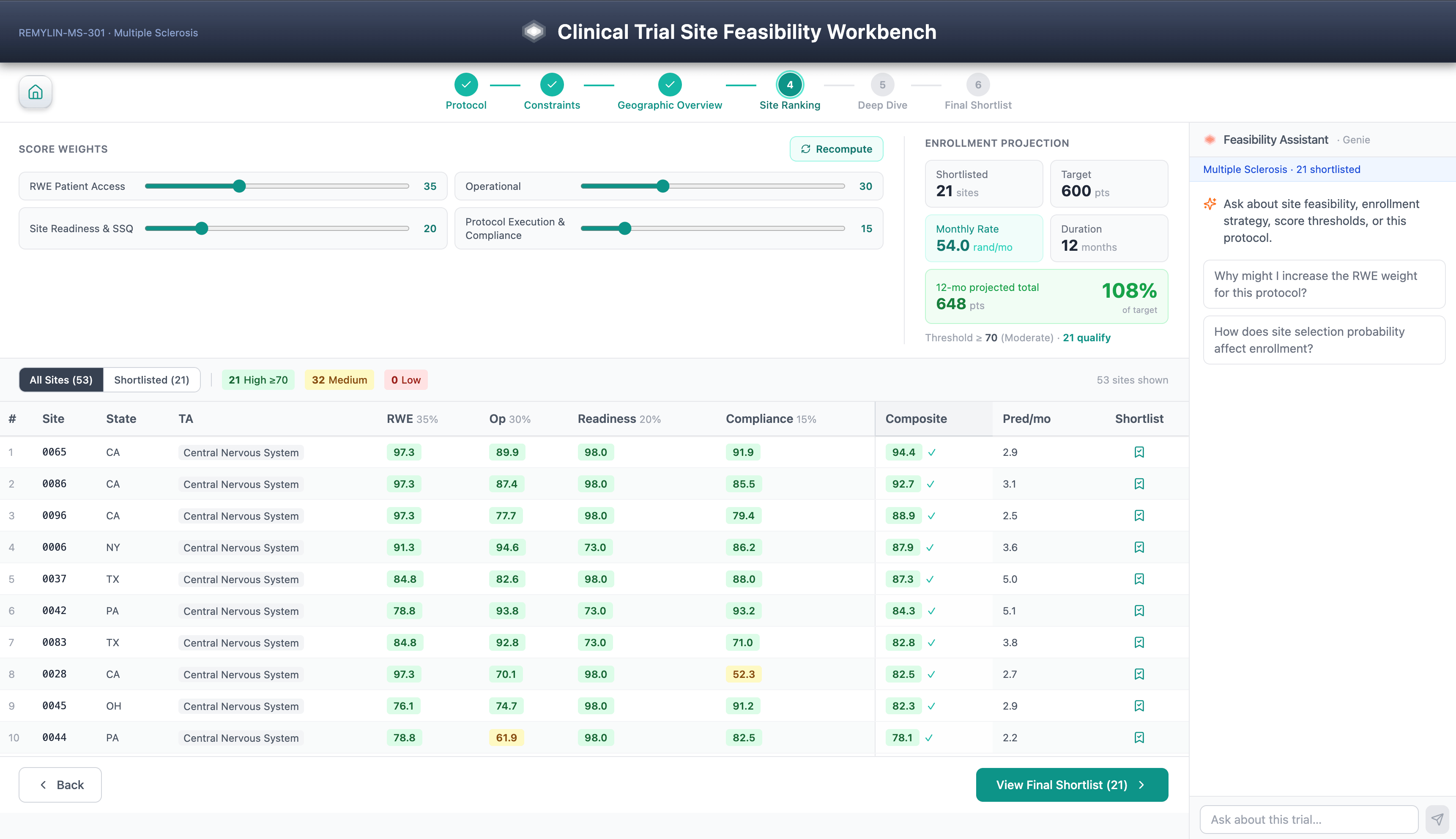
The Site Feasibility Workbench is a six-step guided workflow for clinical trial site selection: protocol selection, score constraints, geographic overview, site ranking, SHAP-driven site deep dive, and final shortlist. Diversity considerations are a first-class scoring dimension, aligned with FDA's Diversity Action Plan expectations under FDORA 2022.
Composite feasibility scores combine real-world evidence, patient access data, historical site performance, site qualification history, Open Payments KOL signal, and protocol execution factors — all driven by TA-segmented LightGBM models trained on the organization's own CTMS, EDC, and IRT history.
The part worth emphasizing is not the workflow steps or the model features. Patient-level data inherits Unity Catalog access controls & PHI handling follows the sponsor's HIPAA Safe Harbor / Expert Determination posture configured at the catalog or schema level.
It is what the architecture makes possible: every prediction carries a SHAP explanation stored as a governed Delta table alongside the prediction itself, making the model rationale as auditable and versioned as the score it explains. Because every prediction is decomposed into governed SHAP attributions, sponsors can audit recommendations for systematic under-weighting of community sites, minority-serving institutions, or first-time investigators — turning explainability into a fairness control.
Saved shortlists persist to Lakebase for team sharing. The AI/BI Genie assistant answers cross-domain questions against the same Unity Catalog tables in natural language. None of this requires infrastructure outside the workspace.
This is a decision-support layer, not a source-of-record system. The CTMS/EDC/IRT remain authoritative. The workbench produces predictions whose lineage is governed in Unity Catalog and MLflow.
The full application — FastAPI backend, React frontend, seed notebooks, and deploy scripts — is published as an open-source repository. Deploying into an existing Databricks workspace with Unity Catalog takes approximately 30 minutes of technical deployment time, before sponsor-specific security review and validation.
One Module of a Larger Platform
The Site Feasibility Workbench is the first public release of a broader architecture — the Databricks Clinical Operations Intelligence Hub — covering the full trial lifecycle:
- Site Feasibility and Selection — what this repository covers
- Patient Cohort and Recruitment — protocol-aligned cohort building from EHR and real-world evidence at Lakehouse scale
- Enrollment Velocity Optimizer — ML stall prediction per site per month with a 1–3 month forward horizon
- Risk-Based Monitoring and Compliance — continuous monitoring for enrollment anomalies, data lags, and protocol deviations
All four deploy as Databricks Apps. All four query Unity Catalog directly. None make external API calls. When clinical applications live where your data and models live, the feedback loop closes. Site selection models learn from enrollment outcomes. Risk scores update as amendment history grows. Every AI-driven recommendation carries a lineage trail back to the CTMS, EDC, and IRT records that produced it.
Get Started
Clone the public repository. Deploy. Tell us what you change.
For the full Clinical Operations Intelligence Hub — watch the BrickTalk recording: Scaling BioPharma Intelligence + Databricks Agentic Clinical Ops.
Lakebase and Databricks Apps in production cover the platform primitives in depth.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.