How to Build Production-Ready Data and AI Apps with Databricks Apps and Lakebase
Run your app, sync your data, and deploy everything on Databricks
by Pascal Vogel, Evan Pandya and Christopher Pries
- Build full-stack data apps with Databricks Apps and Lakebase without managing servers or containers.
- Keep data fresh automatically with Lakebase synced tables that replicate Unity Catalog data in seconds.
- Deploy everything as code using Databricks Asset Bundles for consistent, CI/CD-driven releases.
The Challenge of Production Data Applications
Building production-ready data applications is complex. You often need separate tools to host the app, manage the database, and move data between systems. Each layer adds setup, maintenance, and deployment overhead.
Databricks simplifies this by consolidating everything on a single platform - the Databricks Data Intelligence Platform. Databricks Apps runs your web applications on serverless compute. Lakebase provides a managed Postgres database that syncs with Unity Catalog, giving your app fast access to governed data. And with Databricks Asset Bundles (DABs), you can package code, infrastructure, and data pipelines together and deploy them with a single command.
This blog shows how these three pieces work together to build and deploy a real data application from syncing Unity Catalog data to Lakebase, to running a web app on Databricks and automating deployment with Asset Bundles.
Architecture and How it Works
We'll walk through a taxi trip application that demonstrates the entire pattern: a React and FastAPI application that reads from Lakebase synced tables, with automatic data updates from Unity Catalog Delta tables happening within seconds.
The following diagram provides a simplified view of the solution architecture:
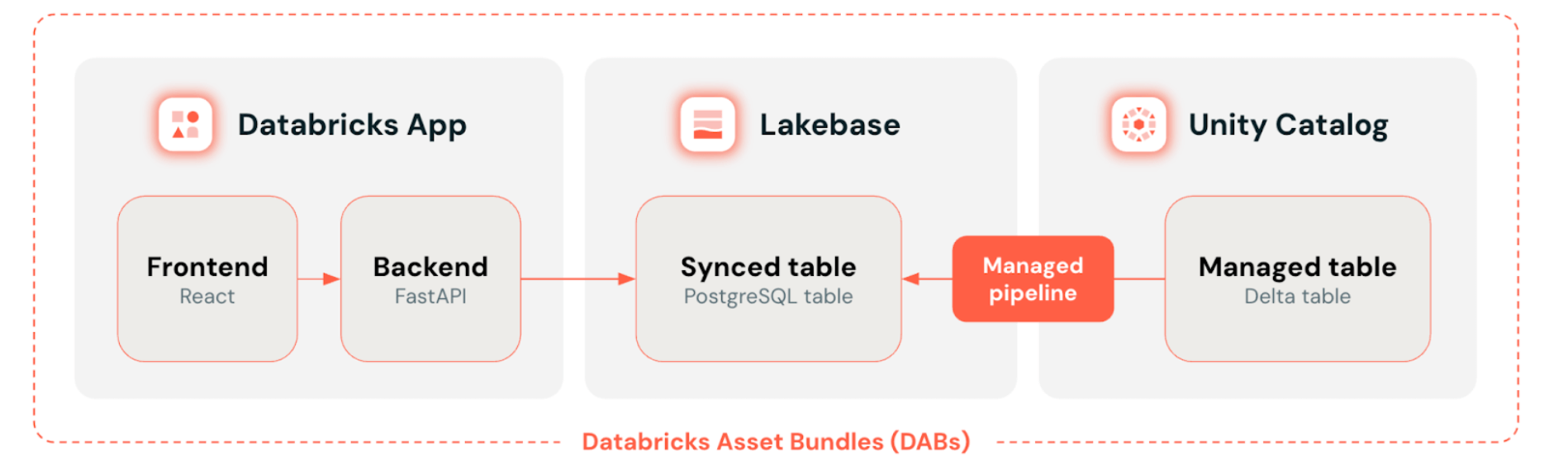
At a high level, Databricks Apps serves as the front end where users explore and visualize data. Lakebase provides the Postgres database that the app queries, keeping it close to live data from Unity Catalog with synced tables. Databricks Asset Bundles tie everything together by defining and deploying all resources—app, database, and data synchronization—as one version-controlled unit.
Main solution components:
- Databricks App: users interact with a web application built using React, TypeScript, Vite, and FastAPI. The app reads data from a Unity Catalog synced table stored in a Lakebase Postgres database.
- Unity Catalog synced table: read-only Postgres table that is automatically synced with a Unity Catalog table via a managed synchronization pipeline. Runs on a Lakebase database instance.
- Lakebase database instance: manages Lakebase storage and compute, provides Postgres endpoints for the Databricks App to connect to.
- Unity Catalog table: Delta table containing data about taxi rides in New York City cloned from the samples.nyctaxi.trips sample table available in every database workspace.
- Databricks Asset Bundles (DABs): all key elements of the architecture are defined in code using a DABs bundle.
The example app displays recent taxi trips in both table and chart format and automatically polls for new trips. It reads data from a Lakebase synced table, which mirrors a Delta table in Unity Catalog.
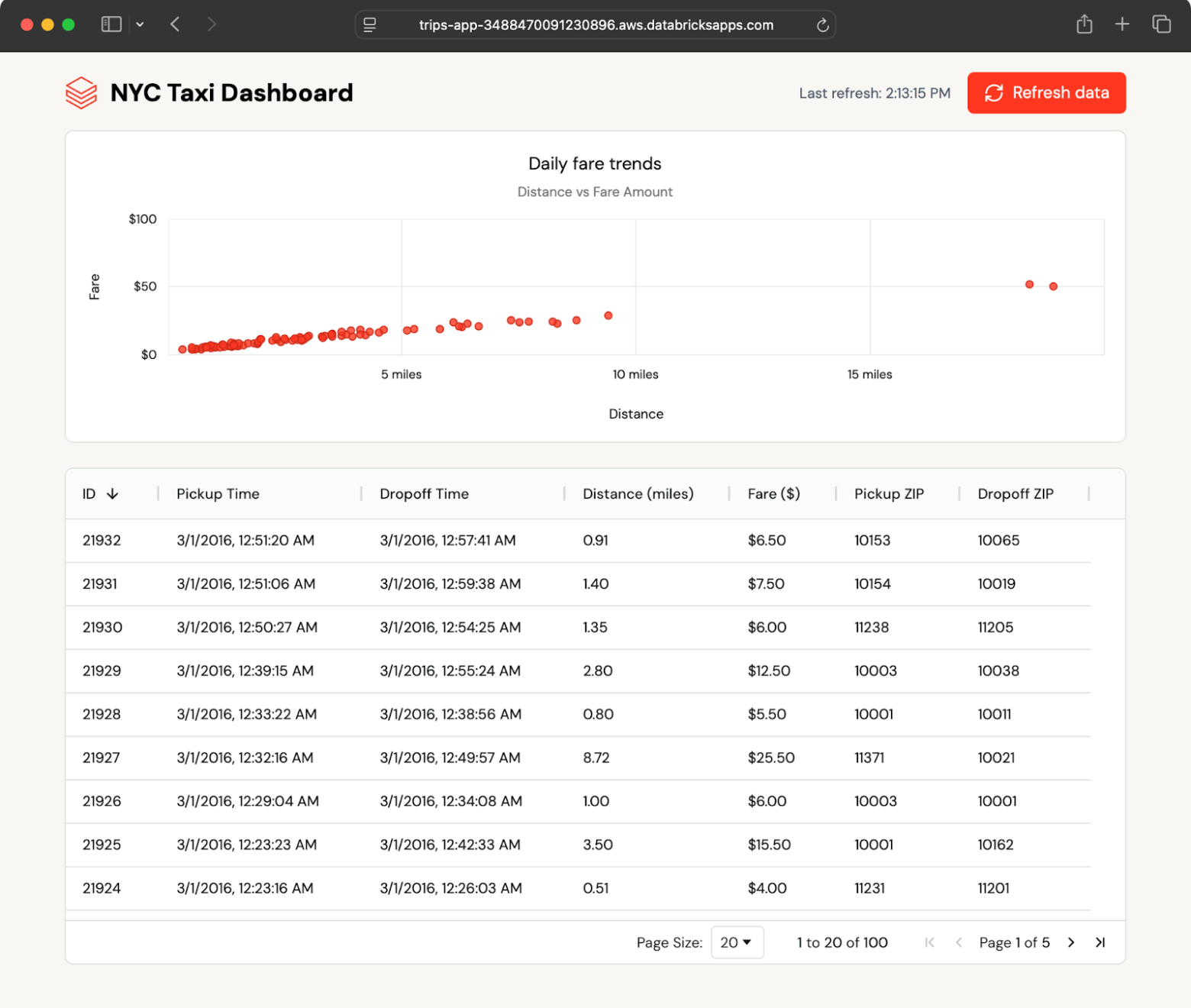
Because the synced table updates automatically, any change in the Unity Catalog table appears in the app within seconds—no custom ETL needed.
You can test this by inserting new data into the source Delta table and then refreshing the synced table:
Then trigger a refresh of the synced trips_synced table.
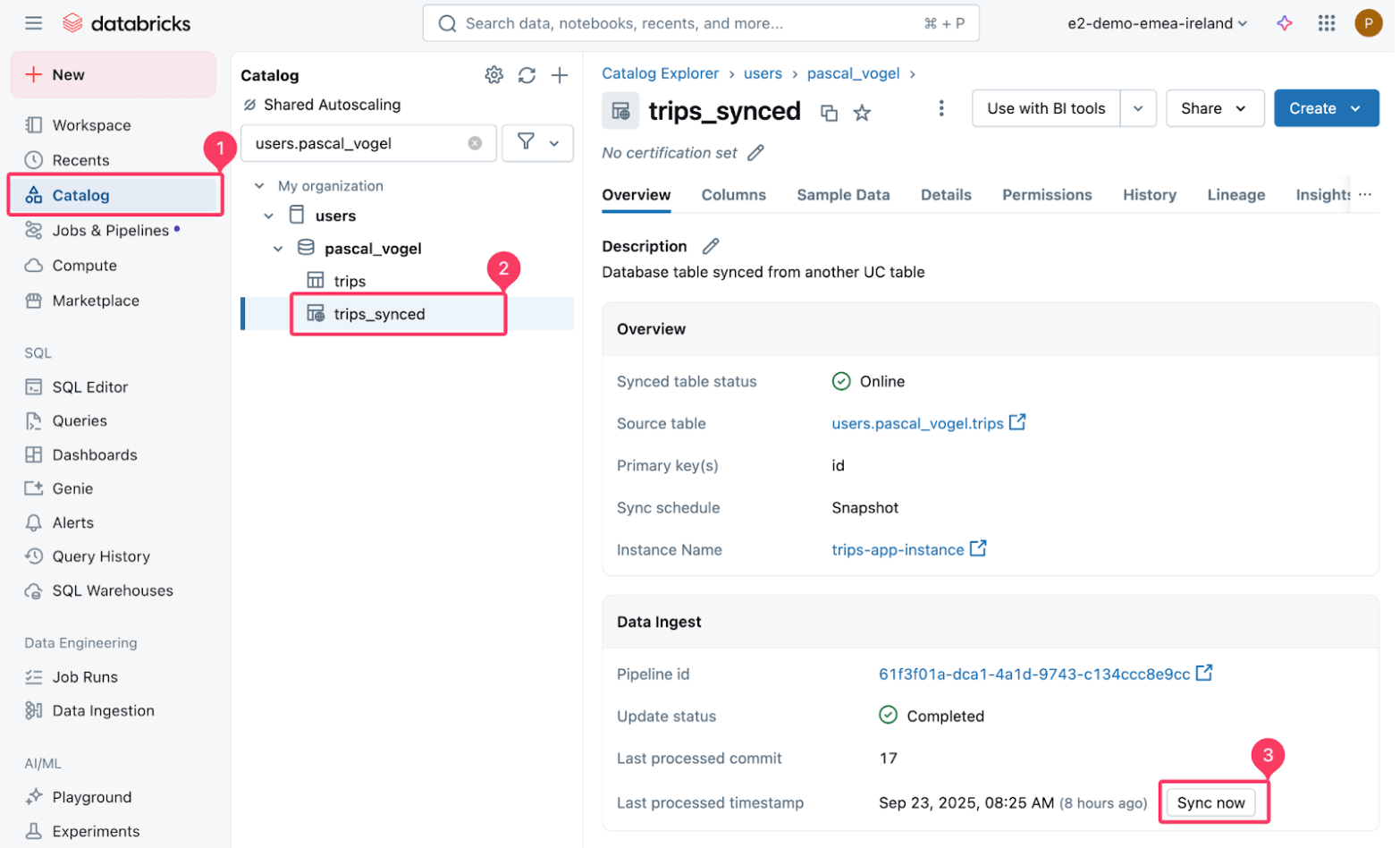
The managed pipeline that powers the sync performs a snapshot copy of the source Delta table to the target Postgres table.
Within a few seconds, the new records appear in the dashboard. The app polls for updates and lets users refresh on demand, showing how Lakebase keeps operational data current without extra engineering.
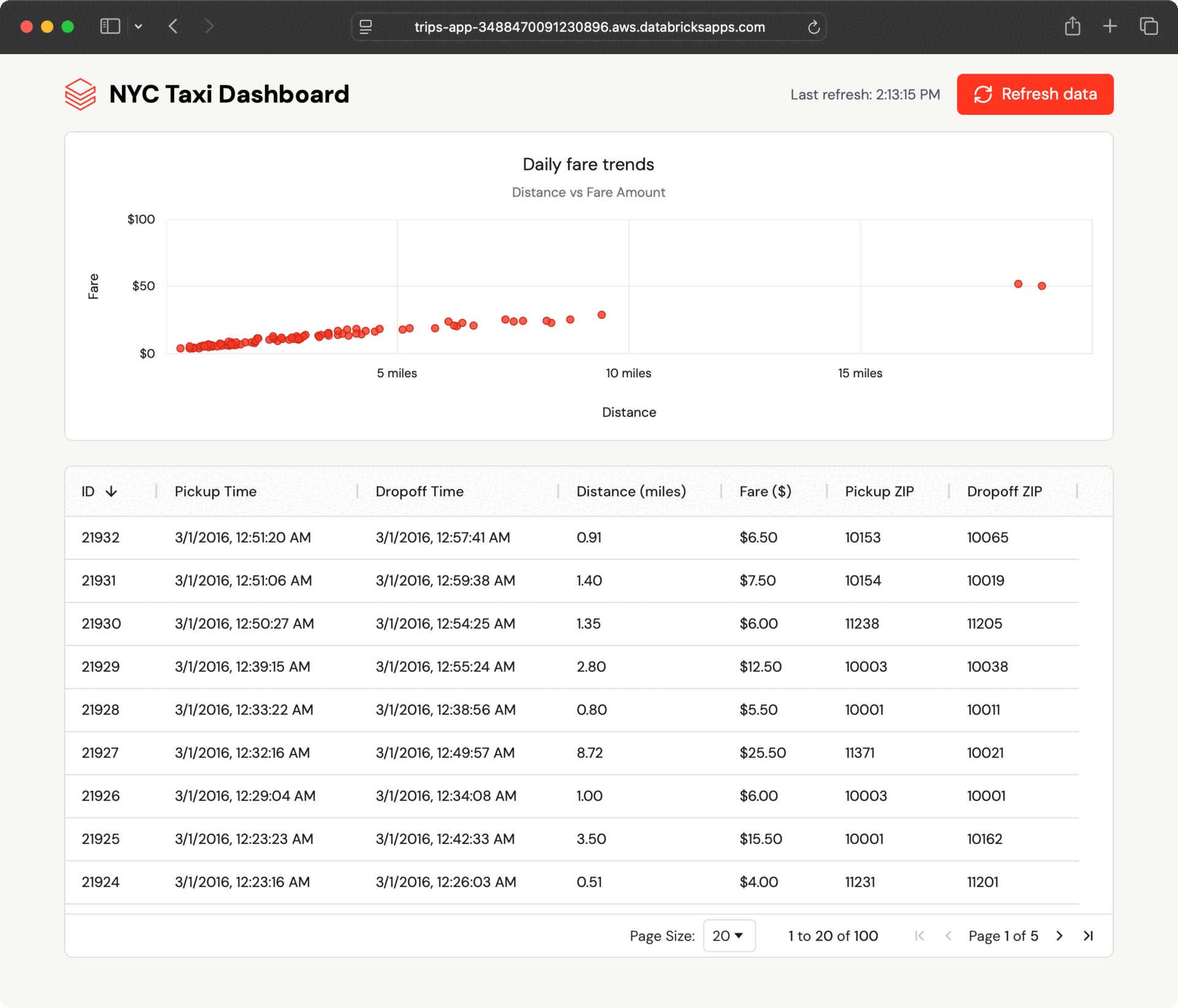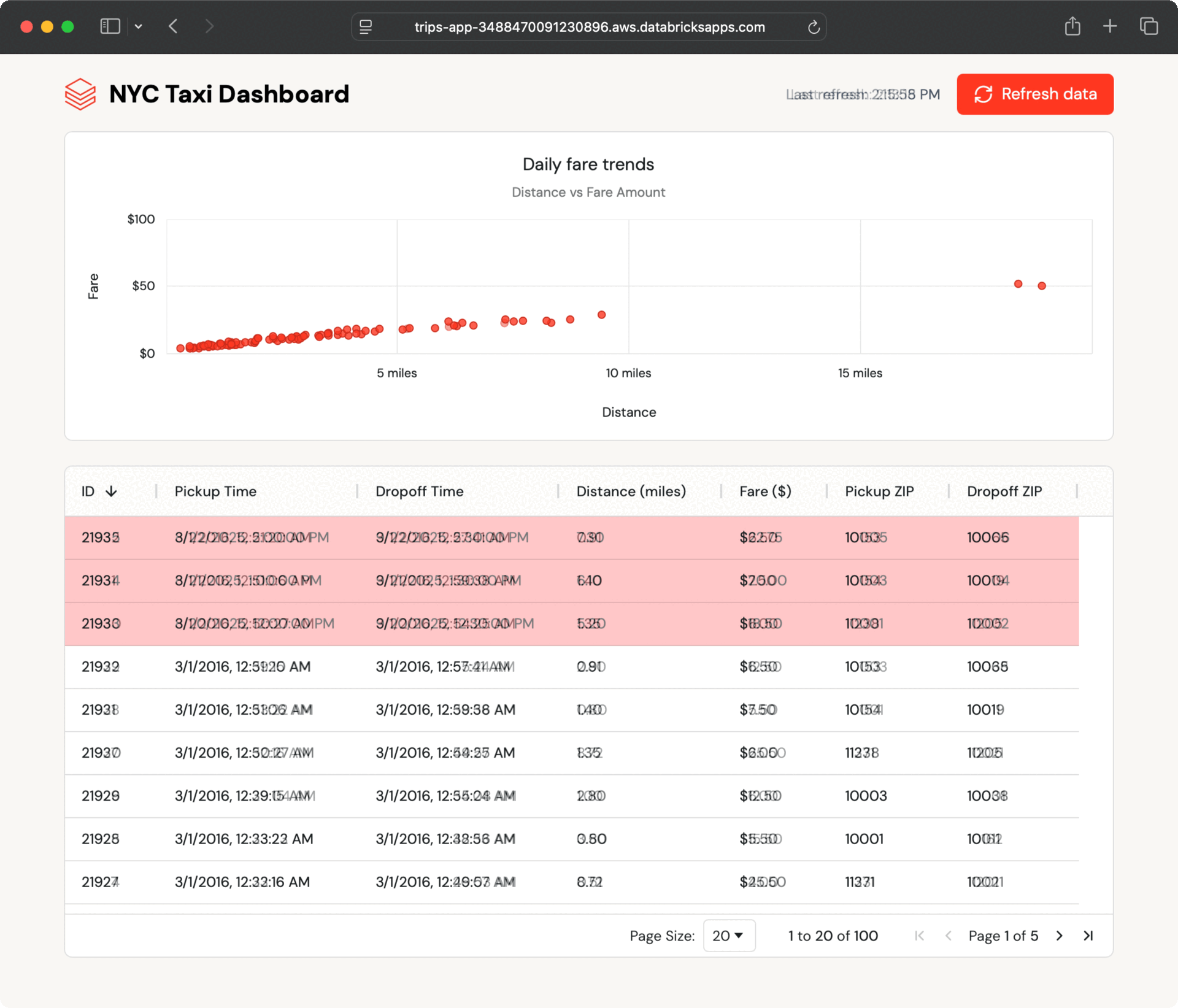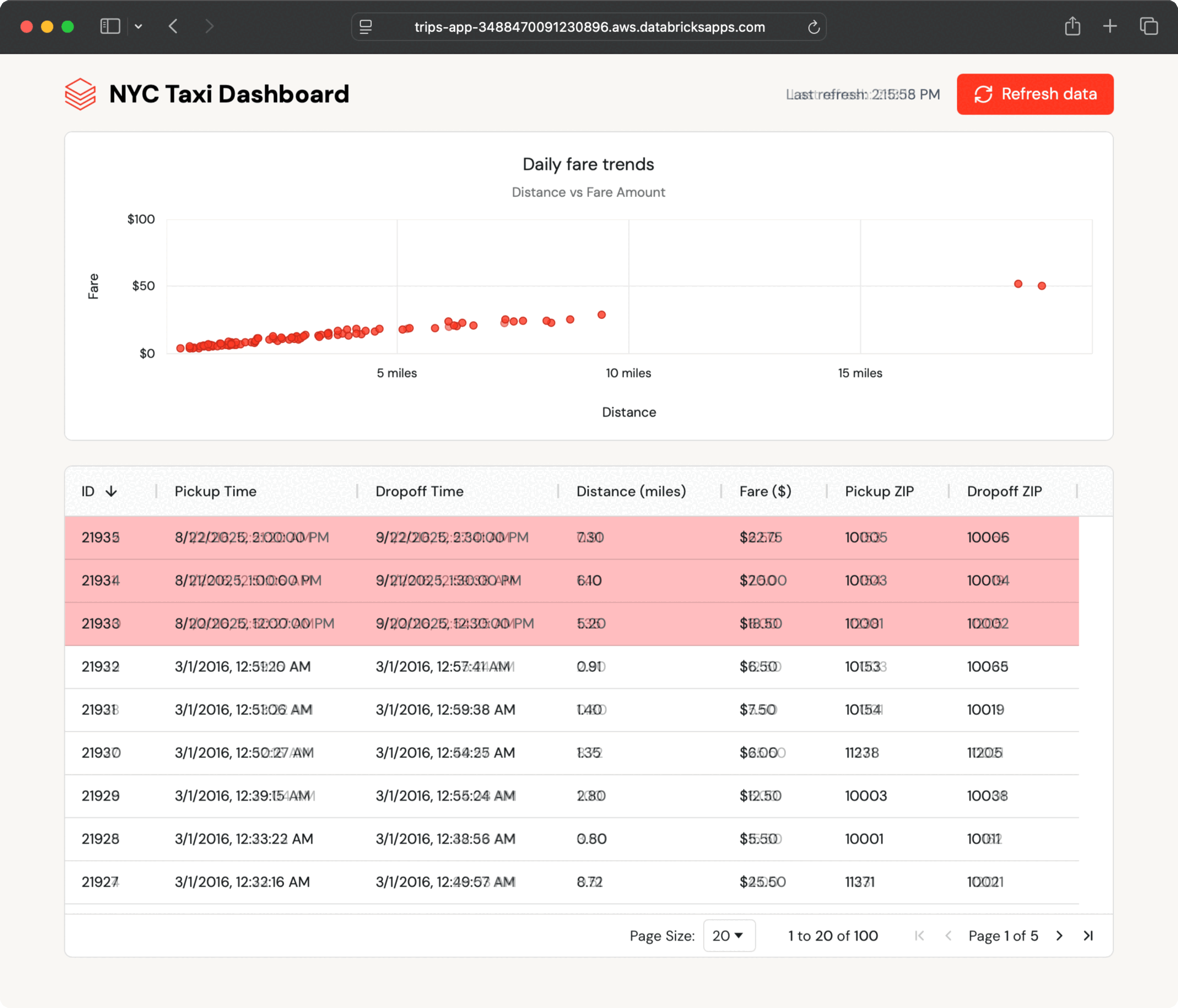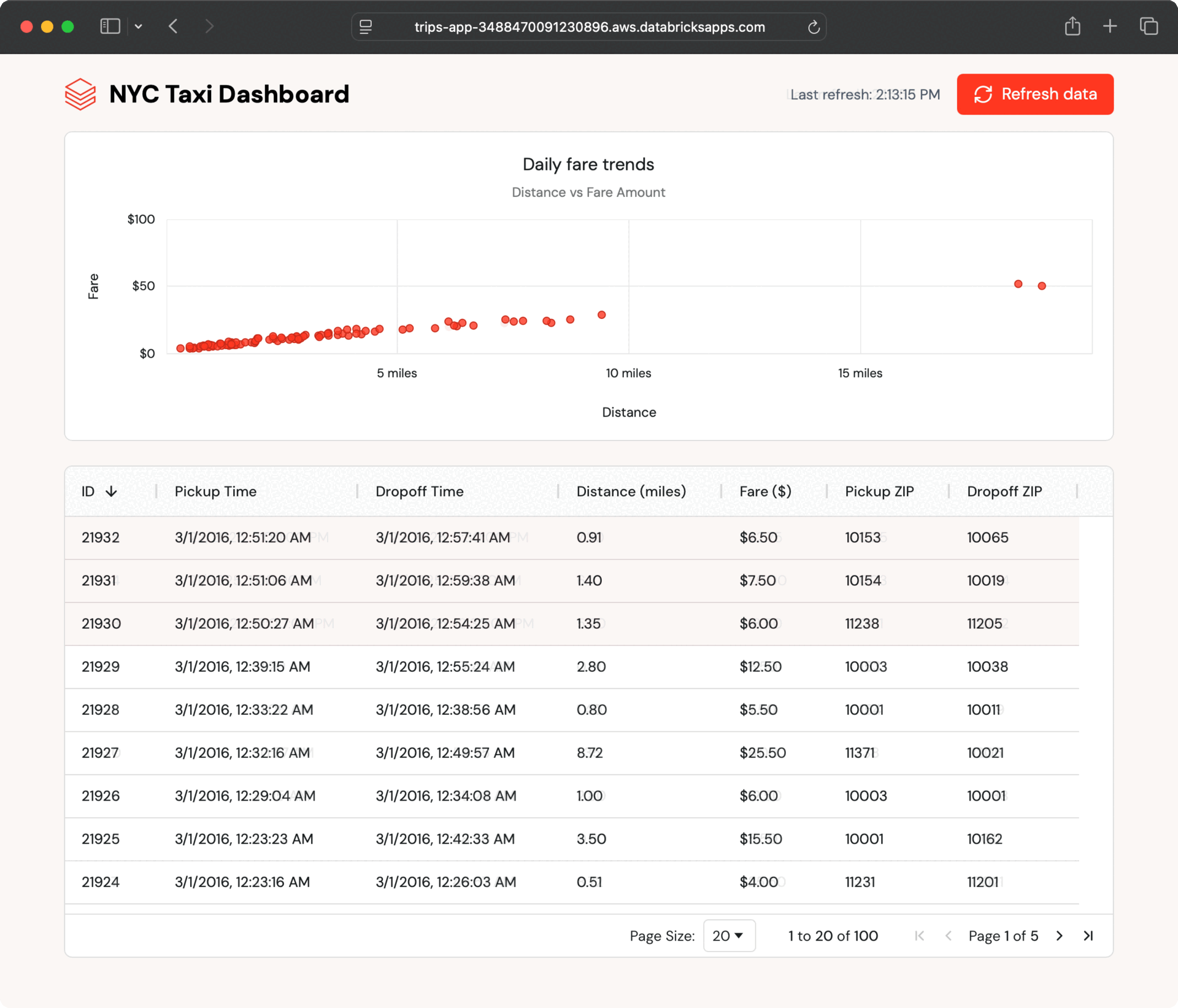
This seamless data flow happens because Lakebase synced tables handle all the synchronization automatically, without the need for custom ETL code or coordination between teams.
Anatomy of the Databricks App
Let's take a look at how the different elements of the solution come together in the Databricks App.
Authentication and database connection
Each Databricks App has a unique service principal identity assigned on creation that the app uses to interact with other Databricks resources, including Lakebase.
Lakebase supports OAuth machine-to-machine (M2M) authentication. An app can obtain a valid token using the Databricks SDK for Python’s WorkspaceClient and its service principal credentials. The WorkspaceClient takes care of refreshing the short-lived (one hour) OAuth token.
The app then uses this token when establishing a connection to Lakebase using the Psycopg Python Postgres adapter:
The Postgres host and database name are automatically set as environment variables for the Databricks App when using the Lakebase resource for apps.
The Postgres user is either the app service principal (when deployed to Databricks Apps) or the Databricks user name of the user running the app locally.
RESTful FastAPI backend
The app’s FastAPI backend uses this connection to query Lakebase and fetch the latest trips data from the synced table:
In addition to serving API endpoints, FastAPI can also serve static files using the StaticFiles class. By bundling our React frontend (app/frontend) using Vite’s build process, we can generate a set of static files that we can serve using FastAPI.
React frontend
The React frontend calls the FastAPI endpoint to display the data:
The example application uses ag-grid and ag-charts for visualization and automatically checks for new data every few seconds:
Defining Databricks Asset Bundles (DABs) Resources
All the Databricks resources and application code shown above can be maintained as a DABs bundle in one source code repository. This also means that all resources can be deployed to a Databricks workspace with a single command. See the GitHub repository for detailed deployment instructions.
This simplifies the software development lifecycle and enables deployments via CI/CD best practices across development, staging, and production environments.
The following sections explain the bundle files in more detail.
Bundle configuration
The databricks.yml contains the DABs bundle configuration in the form of bundle settings and included resources:
In our example, we only define a development and a staging environment. For a production use case, consider adding additional environments. See the databricks-dab-examples repository and the DABs documentation for more advanced configuration examples.
Lakebase setup and sync with Unity Catalog
To define a Lakebase instance in DABs, use the database_instances resource. At a minimum, we need to define the capacity field of the instance.
In addition, we define a synced_database_tables resource, which sets up a managed synchronization pipeline between a Unity Catalog table and a Postgres table.
For this, define a source table via source_table_full_name. The source table in Unity Catalog needs a unique (composite) primary key to be able to process updates defined in the primary_key_columns field.
The location of the target table in Lakebase is determined by the target database object specified as logical_database_name and the table name defined as name.
A synced table is also a Unity Catalog object. In this resource definition, we place the synced table in the same catalog and schema as the source table using DABs variables defined in databricks.yml. You can override these defaults by setting different variable values.
For our use case, we use the SNAPSHOP sync mode. See the considerations and best practices sections for a discussion of the available options.
Databricks Apps resource
DABs allows us to define both the Databricks Apps compute resource as an apps resource as well as the application source code in one bundle. This allows us to keep both Databricks resource definition and source code in a single repository. In our case, the app source code based on FastAPI and Vite is stored in the top-level app directory of the project.
The configuration dynamically references the database_name and instance_name defined in the database.yml resource definition.
database is a supported app resource that can be defined in DABs. By defining the database as an app resource, we automatically create a Postgres role to be used by the app service principal when interacting with the Lakebase instance.
Considerations and Best Practices
Create modular and reusable bundles
While this example deploys to development and staging environments, DABs makes it easy to define multiple environments to fit your development lifecycle. Automate deployment across these environments by setting up CI/CD pipelines with Azure DevOps, GitHub Actions, or other DevOps platforms.
Use DABs substitutions and variables to define environment-specific configurations. For instance, you can define different Lakebase instance capacity configurations for development and production to reduce cost. Similarly, you can define different Lakebase sync modes for your synced tables to meet environment-specific data latency requirements.
Choose Lakebase sync modes and optimize performance
Choosing the right Lakebase sync mode is key to balance cost and data freshness.
Snapshot | Triggered | Continuous | |
Update method | Full table replacement on each run | Initial full copy + incremental changes | Initial load + real-time streaming updates |
Performance | 10x more efficient than other modes | Balanced cost and performance | Higher cost (continuously running) |
Latency | High latency (scheduled/manual) | Medium latency (on-demand) | Lowest latency (real-time, ~15 sec) |
Best for |
|
|
|
Limitations |
|
|
|
Set up notifications for your managed sync pipeline to be alerted in case of failures.
To improve query performance, right-size your Lakebase database instance by choosing an appropriate instance capacity. Consider creating indexes on the synced table in Postgres that match your query patterns. Use the pre-installed pg_stat_statements extension to investigate query performance.
Prepare your app for production
The example application implements a polling-based approach to get the latest data from Lakebase. Depending on your requirements, you can also implement a push-based approach based on WebSockets or Server-Sent-Events to use server resources more efficiently and increase the timeliness of data updates.
To scale to a larger number of app users by reducing the need for the FastAPI backend to trigger database operations, consider implementing caching, for example, using fastapi-cache for caching query results in-memory.
Authentication and authorization
Use OAuth 2.0 for authorization and authentication–do not rely on legacy personal access tokens (PATs). During development on your local machine, use the Databricks CLI to set up OAuth U2M authentication to seamlessly interact with live Databricks resources such as Lakebase.
Similarly, your deployed app uses its associated service principal for OAuth M2M authentication and authorization with other Databricks services. Alternatively, set up user authorization for your app to perform actions on Databricks resources on behalf of your app users.
See also Best practices for apps in the Databricks Apps documentation for additional general and security best practices.
Conclusion
Building production data applications shouldn't mean juggling separate tools for deployment, data synchronization, and infrastructure management. Databricks Apps gives you serverless compute to run your Python and Node.js applications without managing infrastructure. Lakebase synced tables automatically deliver low-latency data from Unity Catalog Delta tables to Postgres, eliminating custom ETL pipelines. Databricks Asset Bundles tie it all together by allowing you to package your application code, infrastructure definitions, and data sync configurations into a single, version-controlled bundle that deploys consistently across environments.
Deployment complexity kills momentum. When you can't ship changes quickly and confidently, you slow down iteration, introduce environment drift, and waste time coordinating between teams. By treating your entire application stack as code with DABs, you enable CI/CD automation, ensure consistent deployments across dev, staging, and production, and let you and your team focus on building features instead of fighting deployment pipelines. This is how you move from prototype to production without the usual deployment headaches.
The complete example is available in the GitHub repository with step-by-step deployment instructions.
Get Started
Learn more about Lakebase, Databricks Apps, and Databricks Asset Bundles by visiting the Databricks documentation. For more developer resources on Databricks Apps, take a look at the Databricks Apps Cookbook and Cookbook Resource Collection.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.