coSTAR: Cómo enviamos agentes de IA en Databricks rápidamente, sin romper nada
Cómo pasamos de revisiones manuales de dos semanas a pruebas y refinamiento automatizados en horas
por Alkis Polyzotis
- En Databricks, creamos y desplegamos agentes utilizando una metodología integral y automatizada de pruebas y refinamiento denominada coSTAR (coupled Scenario, Trace, Assess, Refine), que desarrollamos con MLflow. La metodología se estructura en torno a una analogía con el desarrollo de software tradicional, utilizando jueces LLM como el conjunto de pruebas y un asistente de codificación para refinar automáticamente la implementación del agente hasta que las pruebas pasen.
- Esta metodología ha eliminado el anterior ciclo de desarrollo lento y manual de "ejecutar, revisar, corregir, repetir", que era propenso a regresiones y carecía de confianza. coSTAR ha reducido el tiempo para verificar cambios de dos semanas a horas, lo que permite una mayor velocidad de desarrollo.
- Las mismas pruebas se ejecutan en producción para detectar problemas en el tráfico real de usuarios y, como parte de nuestros pipelines de CI/CD, lo que nos ayuda a señalar regresiones causadas por cambios en la infraestructura dependiente.
Nunca permitirías que un asistente de codificación refactorizara tu base de código sin un conjunto de pruebas. Sin pruebas, el asistente opera a ciegas. Podría arreglar una función y romper silenciosamente otras tres. Las pruebas son lo que cierra el ciclo: ejecútalas, observa los fallos, corrige el código, ejecútalas de nuevo. Sin pruebas, no hay confianza.
En Databricks, desarrollamos y desplegamos continuamente agentes que cubren una amplia gama de funcionalidades, desde nuevas características en la plataforma Databricks (por ejemplo, las capacidades de ingeniería de datos, análisis de trazas y aprendizaje automático en Genie Code), hasta proyectos OSS (por ejemplo, el asistente MLflow), hasta flujos de trabajo de ingeniería interna (por ejemplo, soporte on-call o revisores de código automatizados). Estos agentes pueden realizar tareas de larga duración, generar miles de líneas de código y crear nuevos activos de datos e IA, entre otras cosas. Si bien teníamos algunas comprobaciones básicas implementadas desde el principio, carecíamos del tipo de conjunto de pruebas completo y automatizado que nos permitiera iterar con confianza. Esta publicación describe cómo cerramos esa brecha utilizando MLflow y la metodología coSTAR (coupled Scenario, Trace, Assess, Refine) de mejores prácticas que construimos a su alrededor. coSTAR ejecuta dos bucles acoplados: uno que alinea a los jueces con el juicio de expertos humanos para que puedan ser confiables, y otro que utiliza esos jueces confiables para refinar automáticamente al agente hasta que pase todos los escenarios de prueba.
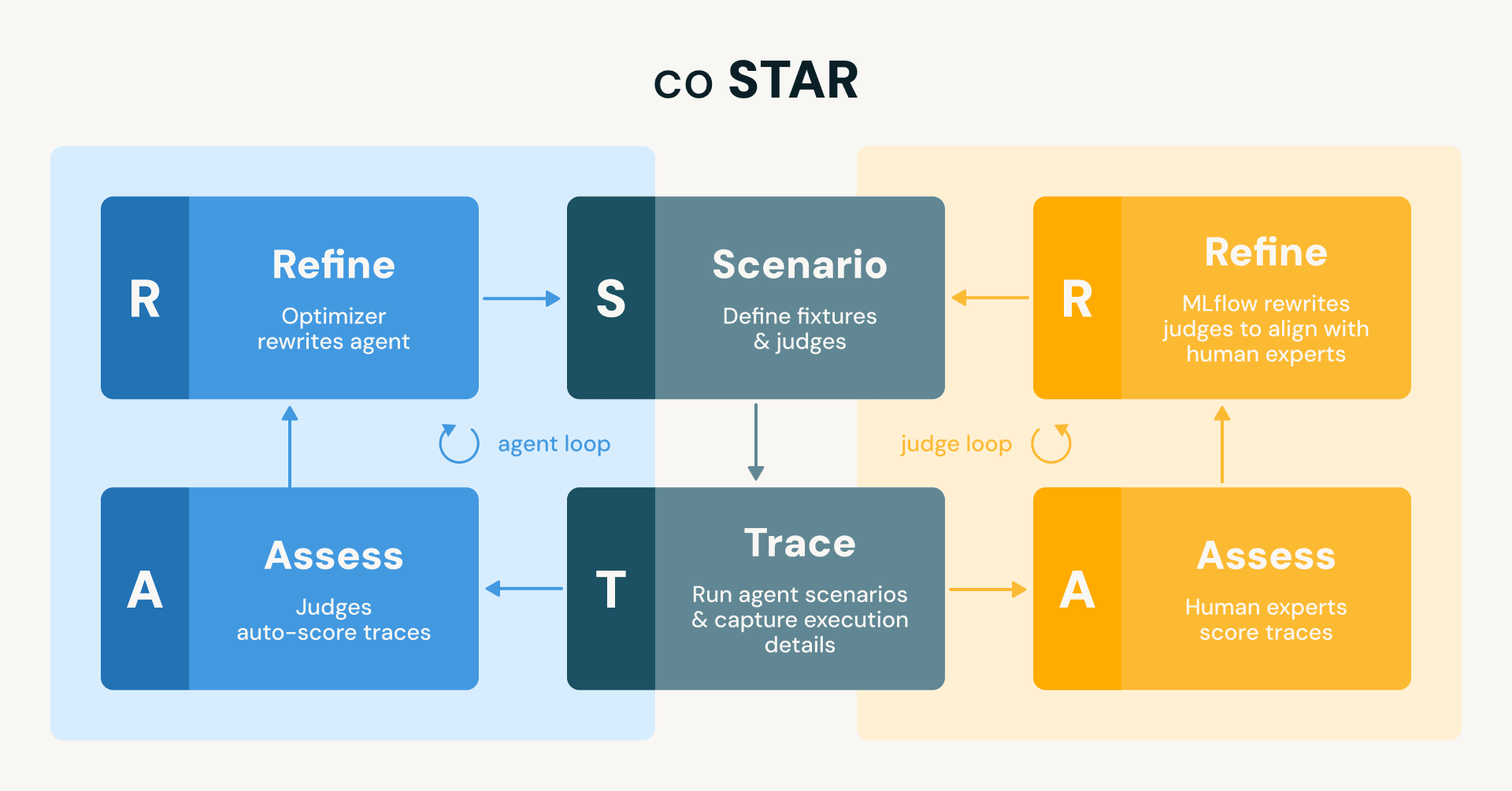
Figura: El marco coSTAR ejecuta dos bucles STAR (Scenario → Trace → Assess → Refine) duplicados. El bucle del agente (azul) utiliza jueces para puntuar automáticamente las trazas y refina al agente para alinearlo con los jueces. El bucle del juez (naranja) utiliza expertos humanos para puntuar las trazas y refina a los jueces para alinearlos con sus evaluaciones. Ambos bucles comparten los mismos escenarios y trazas.
El Problema: Codificar Sin Pruebas
Al principio, nuestro bucle de desarrollo era así: ejecutar el agente, revisar manualmente su salida, detectar un fallo, indicar a un asistente de codificación que lo corrigiera. Repetir.
Si esto te recuerda a escribir código sin pruebas y a hacer control de calidad manual de cada cambio, es exactamente lo que era. Y falló exactamente de la manera que predecirías. La reacción obvia es "entonces escribe pruebas". Pero probar agentes es estructuralmente diferente a probar una función determinista, y varios desafíos se acumulan a la vez:
- No determinismo. La misma implementación, la misma entrada, puede producir resultados diferentes en ejecuciones distintas. Las pruebas necesitan evaluar propiedades de la salida en lugar de afirmar resultados exactos.
- Bucles de retroalimentación lentos. La ejecución de un solo agente puede llevar decenas de minutos. No hay iteración de la manera que permite un conjunto de pruebas de subsegundo. Cada ciclo de evaluación es costoso.
- Errores en cascada. Una mala decisión en el paso 3 causa un fallo en el paso 7. Para cuando aparece el síntoma, la causa raíz está enterrada varios pasos atrás en la ejecución del agente.
- Calidad subjetiva. Para muchas dimensiones de prueba (¿es bueno este código de ingeniería de características? ¿es apropiado este enfoque de limpieza de datos?) no hay una verdad fundamental. Juzgar estas dimensiones depende de la experiencia en el dominio.
Estas restricciones dieron forma a cada decisión de diseño que sigue. También son lo que hace que este problema sea interesante: no solo estamos construyendo un ejecutor de pruebas, estamos construyendo una metodología de optimización automatizada para procesos estocásticos, de larga duración y de múltiples pasos donde "correcto" es una cuestión de juicio.
La Analogía Que Guía Nuestro Enfoque
Si entrecierras los ojos, el desarrollo de agentes se mapea limpiamente en el bucle de desarrollo que todo ingeniero ya conoce:
| Software tradicional | Desarrollo de agentes |
|---|---|
| Código fuente | Implementación del agente (incluyendo prompts, opciones de FMs, herramientas) |
| Conjunto de pruebas | Jueces LLM |
| Fixtures de prueba (configuración, entrada, salida esperada) | Definiciones de escenario (estado inicial, prompt, expectativas) |
| Ejecutor de pruebas / arnés | El arnés de pruebas ejecuta el agente bajo prueba, produce trazas |
| Corrección de pruebas (¿las pruebas comprueban lo correcto?) | Alineación del juez (¿el juez está de acuerdo con los expertos humanos?) |
| El asistente de codificación corrige el código hasta que las pruebas pasan | El asistente de codificación refina la implementación hasta que los jueces pasan |
| CI ejecuta todas las pruebas en cada cambio | CI ejecuta escenarios + jueces en cada cambio |
| Monitoreo de producción | Los mismos jueces se ejecutan en tráfico en vivo |
Esta analogía no es solo ilustrativa. Es la arquitectura literal de nuestro sistema, al que llamamos coSTAR: dos bucles complados que utilizan definiciones de Scenario como fixtures de prueba, captura de Trace como arnés de prueba, Assess con jueces como conjunto de pruebas, y Refine como bucle rojo-verde. Caminemos por cada pieza.
S - Definiciones de Escenario
En las pruebas tradicionales, un fixture de prueba configura las precondiciones: crear una base de datos, poblarla con datos, configurar el entorno. Nuestro equivalente es una definición de escenario: una descripción estructurada del estado inicial, el prompt del usuario y los resultados esperados.
Aquí hay un escenario simplificado para probar un agente de Data Analyst contra un conjunto de datos desordenado:
Cada escenario agrupa la configuración, la entrada y los criterios de éxito en un solo lugar, al igual que un fixture de prueba. Mantenemos un conjunto de estos para diferentes agentes, cubriendo casos comunes, casos extremos y fallos pasados conocidos. El conjunto crece con el tiempo a medida que descubrimos nuevos modos de fallo: cada error que encontramos en producción se convierte en un nuevo escenario, de la misma manera que cada error de producción debería convertirse en una prueba de regresión.
¿Por qué molestarse con esta estructura? Porque las ejecuciones de agentes son costosas. Un solo escenario tarda minutos en ejecutarse. Necesitamos ser deliberados sobre lo que probamos, y necesitamos que las definiciones de escenario sean portátiles: el mismo escenario puede ejecutarse contra diferentes implementaciones de agente o diferentes versiones del mismo agente.
T - Captura de Trazas
Para ejecutar nuestro conjunto de pruebas, utilizamos un arnés que envía el prompt de cada escenario al agente bajo prueba (AUT). Cada ejecución se captura como una traza de MLflow: un registro estructurado de cada llamada a herramienta, cada salida intermedia y cada artefacto que produce el agente. Piénsalo como una caja negra: captura todo lo que hizo el agente, en orden, para que podamos inspeccionar cualquier parte de la ejecución después del hecho.
Una decisión arquitectónica clave: desacoplamos la ejecución de la puntuación. El arnés de pruebas produce trazas; los jueces (que presentaremos a continuación) las puntúan. Estos son pasos separados. Al persistir las trazas, podemos iterar sobre los jueces sin volver a ejecutar los escenarios. ¿Ajustar un umbral? Volver a puntuar las trazas grabadas en segundos. ¿Añadir un nuevo juez? Ejecútalo contra cada traza que hayas recopilado. ¿Sospechas que un juez está equivocado? Compara sus veredictos con las grabaciones y depúralo sin conexión. Una ejecución costosa del agente produce datos que se reutilizan muchas veces, incluyendo como candidatos para el Conjunto Dorado que utilizaremos para alinear a los jueces más adelante.
A - Evaluar con Jueces
Los jueces operan sobre trazas y razonan sobre las propiedades de la ejecución: ¿el agente produjo código válido? ¿La salida cumplió un umbral de calidad? ¿El agente siguió el proceso correcto? Como se mencionó anteriormente, esta evaluación es diferente de las pruebas unitarias tradicionales: la salida del agente es no determinista y rica, por lo que afirmar resultados exactos es esencialmente inútil.
El enfoque estándar para implementar estos jueces es "LLM-como-Juez": alimentar la traza completa a un modelo y pedir una puntuación y, lo que es igualmente importante, una justificación para esa puntuación. Sin embargo, eso es como escribir una prueba que vuelca todo el estado del programa en una aserción. Es costoso, frágil y difícil de depurar. Para nuestros agentes, una sola traza puede tener miles de líneas de longitud. Meterla en la ventana de contexto de un juez degrada la calidad del juicio.
En su lugar, utilizamos jueces agenticos de MLflow: jueces que son ellos mismos agentes, equipados con herramientas para explorar la traza selectivamente. Al igual que una prueba bien escrita llama a una función específica y comprueba un valor de retorno específico, un juez agentico llama a una herramienta específica en la traza y comprueba una propiedad específica.
Aquí hay algunos jueces de ejemplo que hemos utilizado en nuestros agentes:
El juez de invocación de habilidades explora la traza e identifica si el agente invocó habilidades que son el objetivo del escenario (si no, entonces el propósito de la habilidad no está claro para el AUT):
El juez de mejores prácticas explora si la salida sigue las mejores prácticas según la documentación oficial de Databricks:
Outcome Judge inspects the trace for output assets and asserts certain properties. Going back to the Data Analyst example, identify the part of the trace where engineering code was authored and evaluate whether the code is appropriate for the task at hand:
This judge is interesting because it tackles the subjective quality problem head-on: what counts as good feature engineering depends on domain expertise. An LLM judge can't get this right out of the box. It's tempting to try writing out the complete criteria in the judge's prompt: "prefer median imputation over mean for skewed distributions, always scale features before distance-based models, ..." But encoding a domain expert's full judgment into a prompt is laborious and brittle. It's much easier for humans to look at an example and say "this is good" or "this is bad" than to write out the complete spec. This is exactly why alignment works, as we'll cover shortly.
In general, our test suite for a single agent includes judges across several categories:
Deterministic checks, things we can verify mechanically, no LLM needed:
- Syntax/linting on generated code
- Output schema validation (do expected tables exist? are column types correct?)
- Tool sequence linting (did the agent read the error logs before trying to fix the issue, or did it skip straight to editing code?)
LLM-based checks, judgment calls that require understanding context:
- Code diff guidelines (did the agent change unrelated lines? did it introduce deprecated APIs?)
- Best practice adherence (is the generated code following the conventions for this domain?)
Operational metrics, signals that don't pass/fail individually but track health over time:
- Token usage (high token counts often signal the agent is struggling, retrying, backtracking, or going in circles)
- Tool call counts and failure ratios (a spike in failed tool calls indicates something is wrong)
- Latency (wall-clock time for the agent to complete the task)
The operational metrics deserve a note. They don't gate a release the way pass/fail judges do, but they're critical for cost management and early warning. If token usage doubles after a change, something went wrong even if all judges still pass; the agent is probably doing more work than it should. We track these over time and alert on anomalies.
Growing the test suite over time
Test suites don't get authored in one sitting. They evolve over time. They start with the simplest checks that give a signal: does the output exist? Does it parse? Then structural checks follow: does the output have the right schema, the right columns, the right types? Only later come end-to-end data validation judges: does the output actually produce correct results when you run it?
This mirrors how test suites mature in traditional software. Exhaustive integration tests don't come on day one. It starts with smoke tests, then unit tests as failure modes emerge, building toward end-to-end coverage over time. The key is that the infrastructure supports adding new judges cheaply, so the test suite grows alongside the agent.
Testing the Tests: Judge Alignment
Here's a problem every engineer knows: a flaky or wrong test suite that greenlights bad code ships bugs with confidence. Similarly, judges who approve poor outcomes give a false sense of security. This is where the second loop of the coSTAR framework comes in: the same scenarios and traces that drive agent refinement also drive judge refinement, with human expert scores as the ground truth. This matters because, unlike traditional testing where test correctness can be verified by inspection, LLM judges are stochastic and can drift in how they interpret natural-language criteria. So we need a way to verify them and keep them aligned with human experts.
To do this alignment, we first curate a Golden Set of typically dozens of examples of agent outputs that our engineers have manually assessed. This is the ground truth the judges must agree with. Then we leverage MLflow's alignment capabilities (powered by techniques like GEPA and MemAlign) to automatically refine the judge against the Golden Set. Notice this is structurally the same STAR loop we use to refine the AUT itself, but the assess step is performed by human experts and the refine step applies to the judge.
R - Refine
With judges that the judge loop has aligned against human expert judgment, we can now trust the agent loop. A coding assistant treats the agent as its codebase and the judges as its test suite. It reads failures, diagnoses root causes, patches the agent, and re-runs everything. The engineer is still the reviewer and final arbiter of the proposed changes to the agent, but this automated iteration saves considerable human effort in analyzing and improving the agent.
Here's what one iteration looked like for the Data Analyst agent:
Red. We ran the initial version of the agent against our scenario suite. The best-practices judge flagged a discrepancy: our agent was generating code for logical views that was different from our official recommendations/documentation. While this discrepancy would not affect correctness, it had implications on the maintenance and deployment of the generated code. This is an example of an insidious regression that would be hard to catch by manual investigation.
Green. The coding assistant analyzed the judge feedback and identified the gap: the agent was using a skill that was not prescriptive about the type of views that should be created (temporary vs permanent). After adding the relevant guidance to the skill, the tests passed successfully and the change was verified to not introduce other regression (based on other test scenarios).
Regression Tests for Infrastructure, Not Just the Agent
So far we've described judges as tests for the agent, catching regressions when the agent implementation changes. But in practice, the agent itself isn't the only thing that changes. The agent depends on external tools and infrastructure, and those change too.
Our agents call MCP tools, standardized interfaces for data access, code execution, environment setup, and more. These tools have their own development teams and release cycles. When a tool changes its implementation (say, a code execution tool starts returning stderr in a different format, or a data access tool changes how it handles null values) the agent hasn't changed at all, but the agent's behavior can break.
Because we run our judges on every nightly build, they act as regression tests against the full stack, not just the agent’s current implementation. When a tool team ships a change that causes an agent to start failing its judges then we catch the error immediately, before it reaches customers. More importantly, the judge's failure tells us what broke (the specific quality dimension that regressed), which makes it far easier to triage whether the root cause is in the agent or in a tool the agent depends on.
This is the same value that integration tests provide in traditional software: they guard the contract between the code and its dependencies. The only difference is that here, the "code" is an agent and the "dependencies" are MCP tools.
From Eval to Production Monitoring
There's one more extension of the testing analogy that turned out to be surprisingly valuable: running the same judges on production traffic.
In traditional software, testing doesn't stop at CI. Production gets monitored too: error rates, latency percentiles, business metrics on live traffic. The same test logic that validates code in dev often reappears as health checks and alerts in prod.
We do the same thing. The judges we built for eval are designed to score any agent conversation, not just eval scenarios. So we run them (or a sampled subset) on real production conversations. This gives us:
- Early warning on drift. If judge's pass rate drops on production conversations, something changed. Maybe a model upgrade degraded quality, maybe user prompts shifted in a way the agent handles poorly. We see it in the judge scores before we see it in user complaints.
- Real-world signal for the test suite. Production conversations that judges flag as failures become candidates for new eval scenarios. This is how the test suite grows organically: real failures feed back into eval, closing the loop between production and development.
- Cost monitoring at the agent level. We track token usage and tool call counts on production conversations. A quality-neutral change that triples cost is still a regression.
La idea clave es que la misma infraestructura de puntuación (jueces, métricas, rastreos registrados) sirve para dos propósitos. Créala una vez para la evaluación y el monitoreo de producción vendrá como un efecto secundario.
Dónde Estamos Ahora
Hemos adoptado esta metodología en varios agentes que hemos lanzado en la plataforma Databricks (por ejemplo, las capacidades de ingeniería de datos, aprendizaje automático y análisis de rastreos en Genie), agentes internos para la productividad del desarrollador, así como otros agentes dirigidos a clientes (por ejemplo, AI Dev Kit, o el Asistente de MLflow OSS). En general, hemos visto beneficios tangibles:
- En comparación con las evaluaciones manuales, los conjuntos de pruebas automatizadas han reducido el tiempo para verificar cambios de 2 semanas a horas. En consecuencia, esto ha permitido a nuestros equipos lanzar mejoras con mayor velocidad.
- Varios conjuntos de pruebas han crecido a cientos de escenarios de prueba por agente, aumentando nuestra confianza en la detección de regresiones.
- Las pruebas de integración marcaron cambios en la infraestructura dependiente, lo que nos permitió prevenir regresiones en producción. Ejemplos de estos cambios incluyen el comportamiento de gestión de TODO en el modelo subyacente, cambios que afectan la latencia o cambios en el modelo.
MLflow también ha sido fundamental como plataforma de pruebas GenAI, ayudando a nuestros ingenieros a estandarizar la metodología, acelerar el desarrollo de pruebas y compartir las mejores prácticas entre equipos.
Lo Que No Funciona (Todavía)
La analogía de las pruebas también es útil aquí. Nuestras limitaciones se corresponden con problemas de pruebas familiares:
La generación de escenarios es manual (escribir casos de prueba es costoso). Hemos automatizado la puntuación, la alineación y la optimización, pero la generación de los escenarios en sí sigue siendo una tarea humana. Cada escenario requiere la creación de un estado inicial realista, un prompt significativo y expectativas correctas. Este es el cuello de botella que limita el tamaño del conjunto de pruebas, y un conjunto de pruebas estrecho conduce directamente al siguiente problema. La automatización de la generación de escenarios (síntesis de casos de prueba diversos y realistas a partir de patrones de tráfico de producción o de la especificación del agente) es un área de trabajo activa para nosotros.
El asistente de codificación puede sobreajustarse (conjunto de pruebas demasiado estrecho). Si el conjunto de pruebas no cubre suficientes casos, el asistente de codificación diseñará una implementación de agente que supere esas entradas específicas pero falle en las nuevas. Este es el equivalente del agente de escribir código que pasa las pruebas unitarias pero falla en producción. Mitigamos esto retroalimentando los fallos de producción a la evaluación y expandiendo la cobertura con el tiempo, pero hasta que la generación de escenarios esté automatizada, el conjunto de pruebas crece más lentamente de lo que nos gustaría.
La alineación de jueces es costosa (calibrar pruebas requiere mano de obra humana). La construcción del Conjunto Dorado requiere que los expertos en el dominio califiquen manualmente las salidas, el cuello de botella exacto que estamos tratando de eliminar. Y no es un costo único: a medida que los agentes evolucionan, los jueces necesitan recalibración. Estamos investigando formas de hacerlo más inteligente midiendo la incertidumbre del juez, identificando los ejemplos específicos donde el juez está insuficientemente especificado y una etiqueta humana resolvería la ambigüedad. El objetivo es el aprendizaje activo para la alineación de jueces: en lugar de pedir a los expertos que califiquen una muestra aleatoria, mostrar solo los ejemplos donde el juez está incierto y la entrada de un experto en el dominio agudizaría más sus criterios. El objetivo es el aprendizaje activo para la alineación de jueces: en lugar de pedir a los expertos que califiquen una muestra aleatoria, mostrar solo los ejemplos donde el juez está incierto y la entrada de un experto en el dominio agudizaría más sus criterios.
Los fallos de varios pasos son difíciles de atribuir (análisis de causa raíz). Cuando un agente falla en el paso 7 de una canalización de 10 pasos, ¿la causa raíz estuvo en el paso 7 o en el paso 3? Nuestros jueces detectan el síntoma, pero el asistente de codificación a veces soluciona el paso incorrecto, como corregir un fallo de prueba cambiando la función incorrecta. Un mejor rastreo causal es un área de trabajo activa.
Los modos de fallo novedosos se escapan (brechas de cobertura). coSTAR se optimiza dentro de las dimensiones que cubren los jueces. Si surge una nueva clase de fallo que ningún juez verifica, es invisible, al igual que un error en el código que ninguna prueba ejercita. coSTAR mejora *dentro* de su conjunto de pruebas, pero no puede expandir el conjunto de pruebas por sí solo. Los humanos todavía necesitan notar nuevos modos de fallo y agregar jueces.
Conclusiones Clave
- El desarrollo de agentes tiene un problema de pruebas. Sin evaluación automatizada, estás codificando sin pruebas y obtendrás las regresiones que mereces.
- Dale herramientas a los jueces, no rastreos. Un juez agentivo que llama a herramientas específicas es como una prueba unitaria enfocada. Volcar el rastreo completo en un juez es como volcar el estado del programa en una aserción. No escala.
- Prueba tus pruebas. Los jueces LLM son estocásticos. Aliéntalos contra conjuntos dorados calificados por humanos de la misma manera que validarías un conjunto de pruebas contra una especificación.
- Cierra el ciclo. La verdadera ganancia es el ciclo completo de coSTAR: escenarios confiables, rastreos registrados, jueces alineados y un asistente de codificación que refina el agente hasta que las pruebas pasen. La evaluación sin refinamiento automatizado es solo la mitad de la historia.
- Crea una vez, monitorea en todas partes. Los mismos jueces que validan en la evaluación pueden monitorear la producción. Una inversión, dos retornos.
- El acoplamiento es crítico. Refinar el agente solo es tan confiable como los jueces que lo impulsan. Los dos bucles acoplados de coSTAR —uno que gana confianza en los jueces, otro que usa esa confianza para refinar el agente— son lo que hace que el refinamiento automatizado sea significativo en lugar de solo rápido.
Estamos construyendo coSTAR como parte de MLflow. Si estás abordando problemas similares, nos encantaría saber de ti.
- Prueba Genie Code para ver la funcionalidad que lanzamos utilizando la metodología coSTAR.
- Sigue los tutoriales en MLflow para empezar a definir y usar jueces LLM para el refinamiento iterativo de agentes.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.