Tener el panorama completo: unificación de los costos de Databricks y de la infraestructura en la nube
Aprenda a automatizar dashboards de costos unificados que los equipos de FinOps y de plataforma realmente quieran usar.
- La nueva Cloud Infra Cost Field Solution (disponible para AWS y Azure) demuestra cómo ingerir, enriquecer, unir y visualizar los datos de costos de Databricks y de la nube relacionados para ver los costos totales a nivel de cuenta, de clúster e incluso de etiqueta.
- La implementación de la Field Solution proporciona a los equipos de FinOps y de plataforma una vista única y fiable del TCO, lo que les permite desglosar los costos completos por espacio de trabajo, carga de trabajo y unidad de negocio para alinear el uso con los presupuestos, eliminando la conciliación manual y convirtiendo los informes de costos en una capacidad operativa siempre activa.
- Empresas como General Motors han adoptado este enfoque para desarrollar una comprensión integral de sus costos de Databricks, asegurando que sean visibles y se comprendan bien.
Comprensión del TCO en Databricks
Comprender el valor de sus inversiones en IA y datos es fundamental; sin embargo, más del 52 % de las empresas no miden el retorno de la inversión (ROI) de forma rigurosa [Futurum]. La visibilidad completa del ROI requiere conectar el uso de la plataforma y la infraestructura de la nube en un panorama financiero claro. A menudo, los datos están disponibles, pero fragmentados, ya que las plataformas de datos actuales deben admitir una gama cada vez mayor de arquitecturas de almacenamiento y computación.
En Databricks, los clientes gestionan entornos multinube, de múltiples cargas de trabajo y de múltiples equipos. En estos entornos, tener una visión coherente y completa de los costos es esencial para tomar decisiones informadas.
En el núcleo de la visibilidad de costos en plataformas como Databricks se encuentra el concepto de costo total de propiedad (TCO).
En las plataformas de datos multinube, como Databricks, el TCO consta de dos componentes principales:
- Costos de la plataforma, como los de cómputo y almacenamiento administrado, son costos generados por el uso directo de los productos de Databricks.
- Los costos de la infraestructura de la nube, como las máquinas virtuales, el almacenamiento y los cargos de red, son costos incurridos por el uso subyacente de los servicios en la nube necesarios para dar soporte a Databricks.
Comprender el TCO se simplifica al utilizar productos serverless. Debido a que Databricks administra el cómputo, los costos de la infraestructura de la nube se incluyen en los costos de Databricks, lo que le brinda una visibilidad centralizada de los costos directamente en las tablas del sistema de Databricks (aunque los costos de almacenamiento seguirán siendo del proveedor de la nube).
Sin embargo, comprender el TCO de los productos de cómputo clásicos es más complejo. En este caso, los clientes administran el cómputo directamente con el proveedor de la nube, lo que significa que es necesario conciliar tanto los costos de la plataforma Databricks como los de la infraestructura de la nube. En estos casos, hay dos fuentes de datos distintas que se deben resolver:
- Las tablas del sistema (AWS | AZURE | GCP) en Databricks proporcionarán metadatos operativos a nivel de carga de trabajo y el uso de Databricks.
- Los informes de costos del proveedor de la nube detallarán los costos de la infraestructura de la nube, incluidos los descuentos.
En conjunto, estas fuentes forman la vista completa del TCO. A medida que su entorno crece a través de muchos clústeres, trabajos y cuentas en la nube, comprender estos conjuntos de datos se convierte en una parte fundamental de la observabilidad de los costos y la gobernanza financiera.
La complejidad del TCO
La complejidad de medir su TCO de Databricks se ve agravada por las formas dispares en que los proveedores de la nube exponen e informan los datos de costos. Comprender cómo unir estos conjuntos de datos con las tablas del sistema para producir KPI de costos precisos requiere un conocimiento profundo de la mecánica de facturación en la nube, conocimiento que muchos administradores de plataformas centrados en Databricks pueden no tener. Aquí, profundizamos en la medición de su TCO para Azure Databricks y Databricks en AWS.
Azure Databricks: Aprovechamiento de los datos de facturación de origen
Dado que Azure Databricks es un servicio nativo del ecosistema de Microsoft Azure, los cargos relacionados con Databricks aparecen directamente en Azure Cost Management junto con otros servicios de Azure, incluidas las etiquetas específicas de Databricks. Los costos de Databricks aparecen en la interfaz de usuario de análisis de costos de Azure y como datos de administración de costos.
Sin embargo, los datos de Azure Cost Management no contendrán los metadatos más profundos a nivel de carga de trabajo ni las métricas de rendimiento que se encuentran en las tablas del sistema de Databricks. Por lo tanto, muchas organizaciones buscan llevar las exportaciones de facturación de Azure a Databricks.
Sin embargo, unir completamente estas dos fuentes de datos consume mucho tiempo y requiere un profundo conocimiento del dominio, un esfuerzo que la mayoría de los clientes simplemente no tienen tiempo de definir, mantener y replicar. Varios desafíos contribuyen a esto:
- La infraestructura debe configurarse para exportaciones de costos automatizadas a ADLS, que luego se pueden referenciar y consultar directamente en Databricks.
- Los datos de costos de Azure se agregan y actualizan diariamente, a diferencia de las tablas del sistema, que se actualizan en cuestión de horas; los datos deben desduplicarse cuidadosamente y las marcas de tiempo deben coincidir.
- Unir las dos fuentes requiere analizar los datos de etiquetas de Azure de alta cardinalidad e identificar la clave de unión correcta (p. ej., ClusterId).
Databricks en AWS: cómo alinear los costos del Marketplace y de la infraestructura
En AWS, si bien los costos de Databricks aparecen en el Informe de costos y uso (CUR) y en AWS Cost Explorer, los costos se representan en un nivel más agregado, a nivel de SKU, a diferencia de Azure. Además, los costos de Databricks aparecen solo en el CUR cuando Databricks se compra a través de AWS Marketplace; de lo contrario, el CUR solo reflejará los costos de infraestructura de AWS.
En este caso, entender cómo coanalizar el CUR de AWS junto con las tablas del sistema es aún más fundamental para los clientes con entornos de AWS. Esto permite a los equipos analizar el gasto en infraestructura, el uso de DBU y los descuentos junto con el contexto a nivel de clúster y de carga de trabajo, lo que crea una visión más completa del TCO en todas las cuentas y regiones de AWS.
Sin embargo, unir el CUR de AWS con las tablas del sistema también puede ser un desafío. Los problemas comunes incluyen:
- La infraestructura debe admitir el reprocesamiento recurrente de CUR, ya que AWS actualiza y reemplaza los datos de costos varias veces al día (sin clave principal) para el mes actual y cualquier período de facturación anterior con cambios.
- Los datos de costos de AWS abarcan múltiples tipos de partidas individuales y campos de costos, lo que requiere que se preste atención para seleccionar el costo efectivo correcto por tipo de uso (bajo demanda, Savings Plans, instancias reservadas) antes de la agregación.
- Unir CUR con los metadatos de Databricks requiere una atribución cuidadosa, ya que la cardinalidad puede ser diferente; por ejemplo, los clústeres compartidos de uso general se representan como una única fila de uso de AWS, pero pueden asignarse a varios trabajos en las tablas del sistema.
Simplificación de los cálculos del TCO de Databricks
En los entornos de Databricks a escala de producción, las preguntas sobre los costos superan rápidamente el gasto general. Los equipos quieren entender los costos en contexto: cómo el uso de la infraestructura y la plataforma se conecta con las cargas de trabajo y las decisiones reales. Las preguntas comunes incluyen:
- ¿Cómo se compara el costo total de un trabajo serverless con el de un trabajo clásico?
- ¿Qué clústeres, jobs y warehouses son los mayores consumidores de VM administradas por la nube?
- ¿Cómo cambian las tendencias de costos a medida que las cargas de trabajo escalan, cambian o se consolidan?
Responder a estas preguntas requiere unir los datos financieros de los proveedores de la nube con los metadatos operativos de Databricks. Sin embargo, como se describió anteriormente, los equipos necesitan mantener pipelines personalizados y una base de conocimientos detallada de la facturación de la nube y de Databricks para lograrlo.
Para satisfacer esta necesidad, Databricks presenta la solución de campo de costos de infraestructura en la nube (Cloud Infra Cost Field Solution), una solución de código abierto que automatiza la ingesta y el análisis unificado de los datos de uso de la infraestructura de la nube y de Databricks, dentro de la plataforma de Databricks.
Al proporcionar una base unificada para el análisis del TCO en los entornos de computación serverless (sin servidor) y clásica de Databricks, la solución de campo ayuda a las organizaciones a obtener una visibilidad de costos más clara y a comprender las compensaciones arquitectónicas. Los equipos de ingeniería pueden hacer un seguimiento del gasto y los descuentos en la nube, mientras que los equipos de finanzas pueden identificar el contexto empresarial y la propiedad de los principales generadores de costos.
En la siguiente sección, explicaremos cómo funciona la solución y cómo empezar a usarla.
Desglose de la solución técnica
Aunque los componentes pueden tener nombres diferentes, la solución de campo de costos de infraestructura en la nube para clientes tanto de Azure como de AWS comparte los mismos principios y se puede desglosar en los siguientes componentes:
- Exportar datos de costos y uso al almacenamiento en la nube
- Ingerir y modelar datos en Databricks usando Lakeflow Spark Declarative Pipelines
- Visualice el TCO completo (costos de Databricks y del proveedor de nube relacionado) con paneles de AI/BI.
Tanto las soluciones de campo de AWS como las de Azure son excelentes para las organizaciones que operan en una sola nube, pero también se pueden combinar para clientes de Databricks multinube mediante Delta Sharing.
Solución de campo de Azure Databricks
La solución de campo de costos de infraestructura en la nube para Azure Databricks consta de los siguientes componentes de arquitectura:
Arquitectura de la solución de Azure Databricks
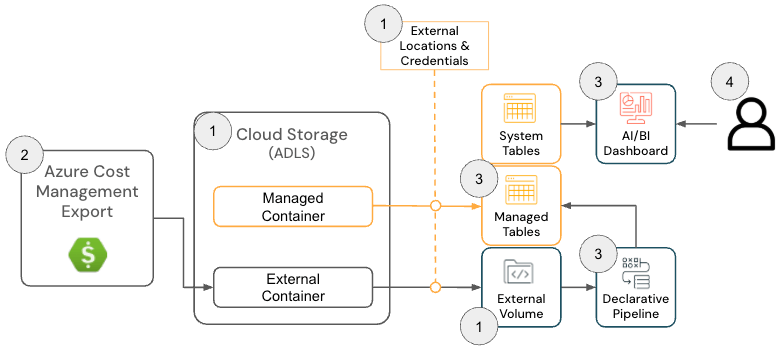
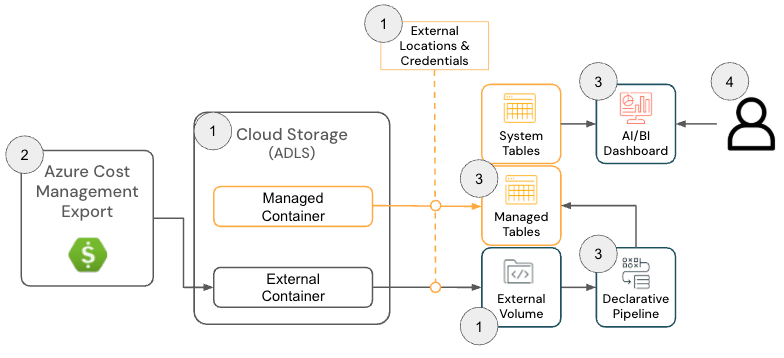{kind=link}
Para implementar esta solución, los administradores deben tener los siguientes permisos en Azure y Databricks:
- Azure
- Permisos para crear una exportación de costos de Azure
- Permisos para crear los siguientes recursos dentro de un grupo de recursos:
- Databricks
- Permiso para crear los siguientes recursos:
- Credencial de almacenamiento
- Ubicación externa
- Permiso para crear los siguientes recursos:
El repositorio de GitHub proporciona instrucciones de configuración más detalladas; sin embargo, a un alto nivel, la solución para Azure Databricks tiene los siguientes pasos:
- [Terraform] Implemente Terraform para configurar los componentes dependientes, incluidos una cuenta de almacenamiento, una ubicación externa y un volumen.
- El propósito de este paso es configurar una ubicación donde se exportan los datos de facturación de Azure para que Databricks pueda leerlos. Este paso es opcional si existe un volumen (Volume) preexistente, ya que la ubicación de exportación de Azure Cost Management se puede configurar en el siguiente paso.
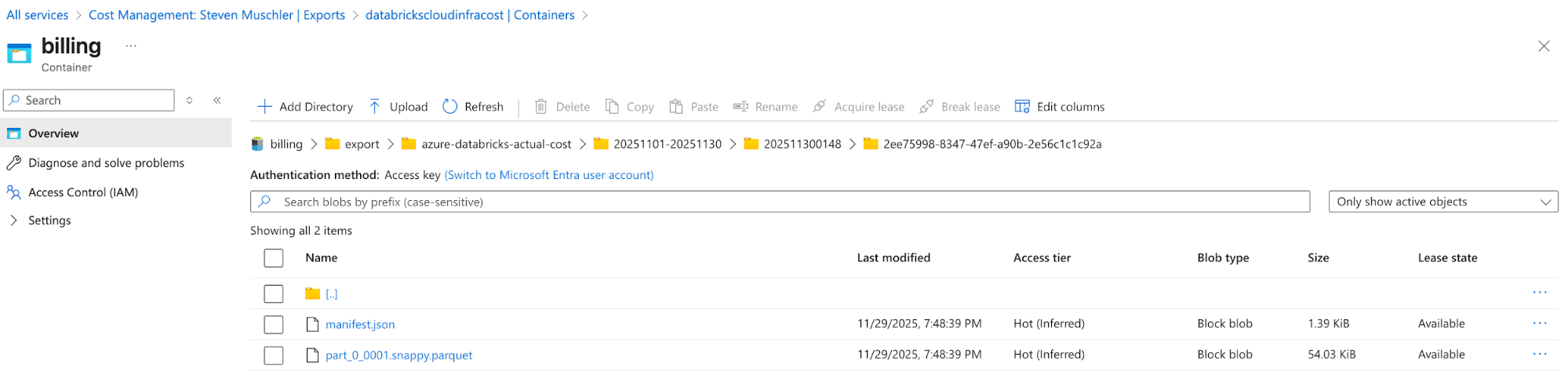
[Azure] Configure Azure Cost Management Export para exportar los datos de facturación de Azure a la cuenta de almacenamiento y confirme que los datos se están exportando correctamente
- El propósito de este paso es usar la funcionalidad de exportación de Azure Cost Management para que los datos de facturación de Azure estén disponibles en un formato fácil de consumir (p. ej., Parquet).
Cuenta de almacenamiento con la exportación de Azure Cost Management configurada
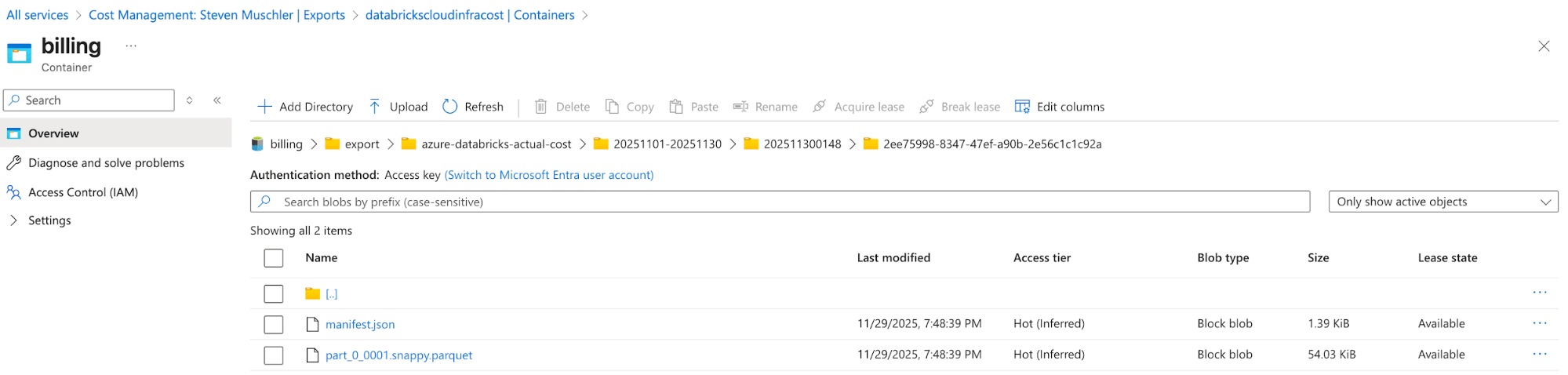
Azure Cost Management Export automatically delivers cost files to this location - [Databricks] Databricks Asset Bundle (DAB) Configuration para implementar un Lakeflow Job, una Spark Declarative Pipeline y un AI/BI Dashboard
- El propósito de este paso es incorporar y modelar los datos de facturación de Azure para su visualización mediante un panel de AI/BI.
- [Databricks] Validar los datos en el panel de IA/BI y validar el trabajo de Lakeflow
- Este último paso es donde se materializa el valor. ¡Los clientes ahora tienen un proceso automatizado que les permite ver el TCO de su arquitectura Lakehouse!
{kind=link}
Panel de control de IA/BI que muestra el TCO de Azure Databricks
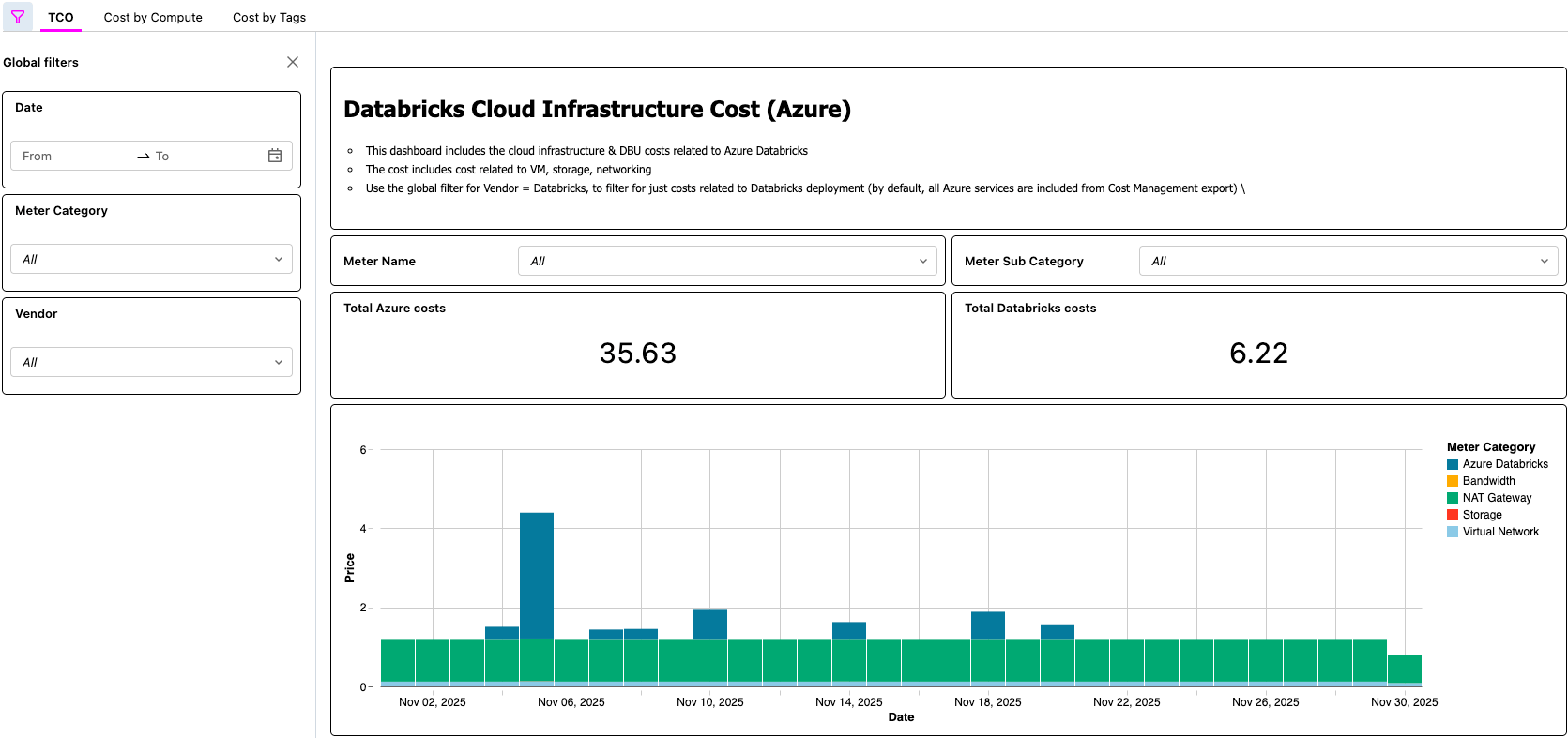
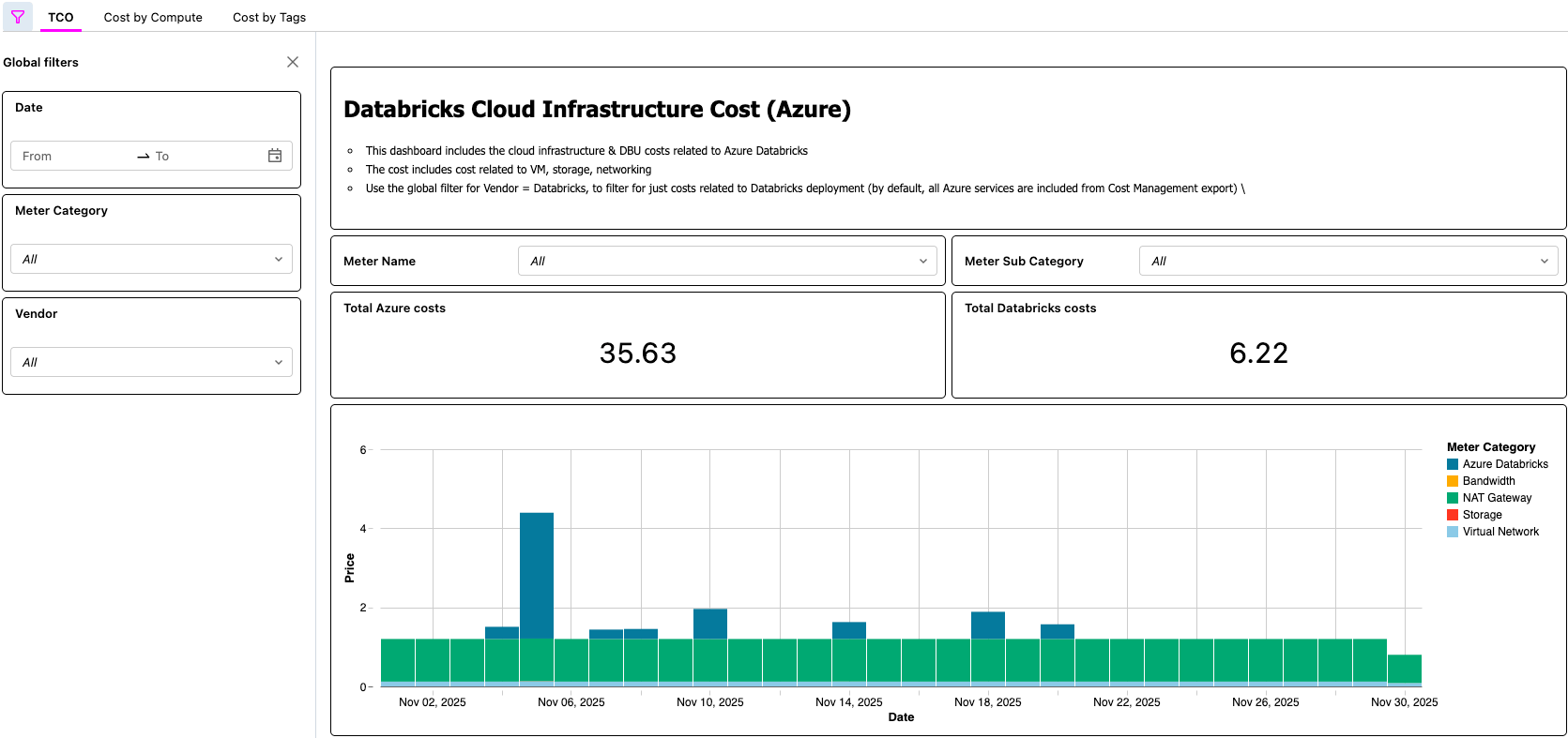{kind=link}
Solución de Databricks en AWS
La solución para Databricks en AWS consta de varios componentes de arquitectura que trabajan en conjunto para incorporar datos del informe de costos y uso (CUR) 2.0 de AWS y persistirlos en Databricks utilizando la arquitectura Medallion.
Para implementar esta solución, se deben tener los siguientes permisos y configuraciones en AWS y Databricks:
- AWS
- Permisos para crear un CUR
- Permisos para crear un bucket de Amazon S3 (o permisos para implementar el CUR en un bucket existente)
- Nota: La solución requiere AWS CUR 2.0. Si todavía tiene una exportación de CUR 1.0, la documentación de AWS proporciona los pasos necesarios para actualizar.
- Databricks
- Permiso para crear los siguientes recursos:
- Credencial de almacenamiento
- Ubicación externa
- Permiso para crear los siguientes recursos:
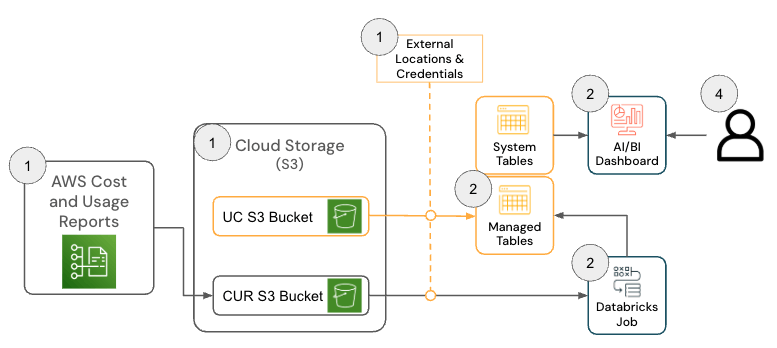
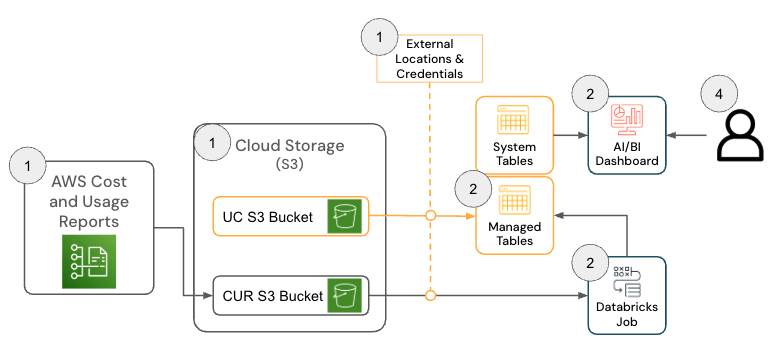{kind=link}
El repositorio de GitHub proporciona instrucciones de configuración más detalladas; sin embargo, a un alto nivel, la solución para Databricks en AWS tiene los siguientes pasos.
- [AWS] Configuración de AWS Cost & Usage Report (CUR) 2.0
- El propósito de este paso es aprovechar la funcionalidad de AWS CUR para que los datos de facturación de AWS estén disponibles en un formato fácil de consumir.
- [Databricks] Configuración de Databricks Asset Bundle (DAB)
- El propósito de este paso es ingerir y modelar los datos de facturación de AWS para que puedan visualizarse con un panel de IA/BI.
- [Databricks] Revise el dashboard y valide el trabajo de Lakeflow
- Este paso final es donde se materializa el valor. ¡Los clientes ahora tienen un proceso automatizado que pone a su disposición el TCO de su arquitectura lakehouse!
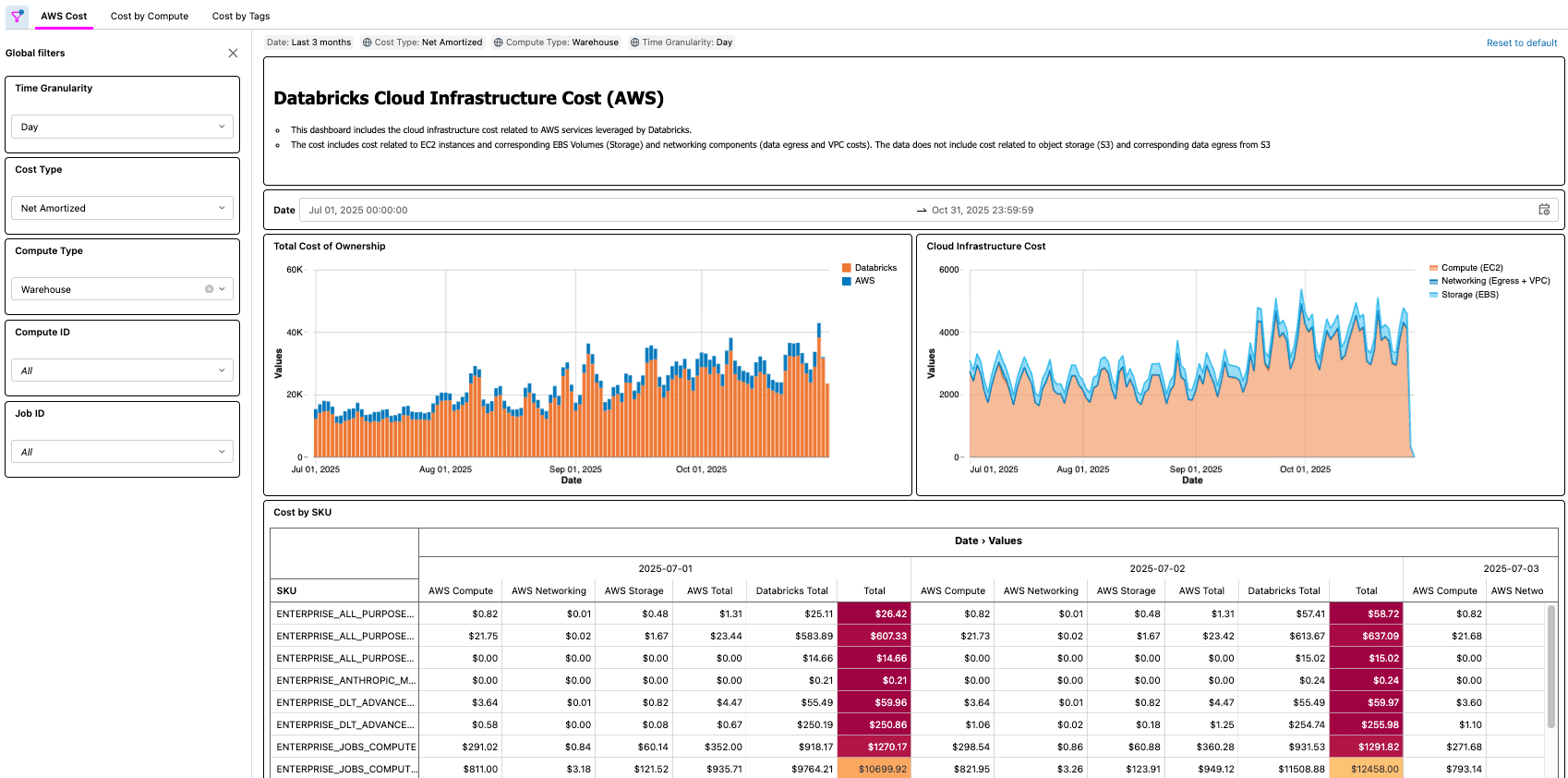
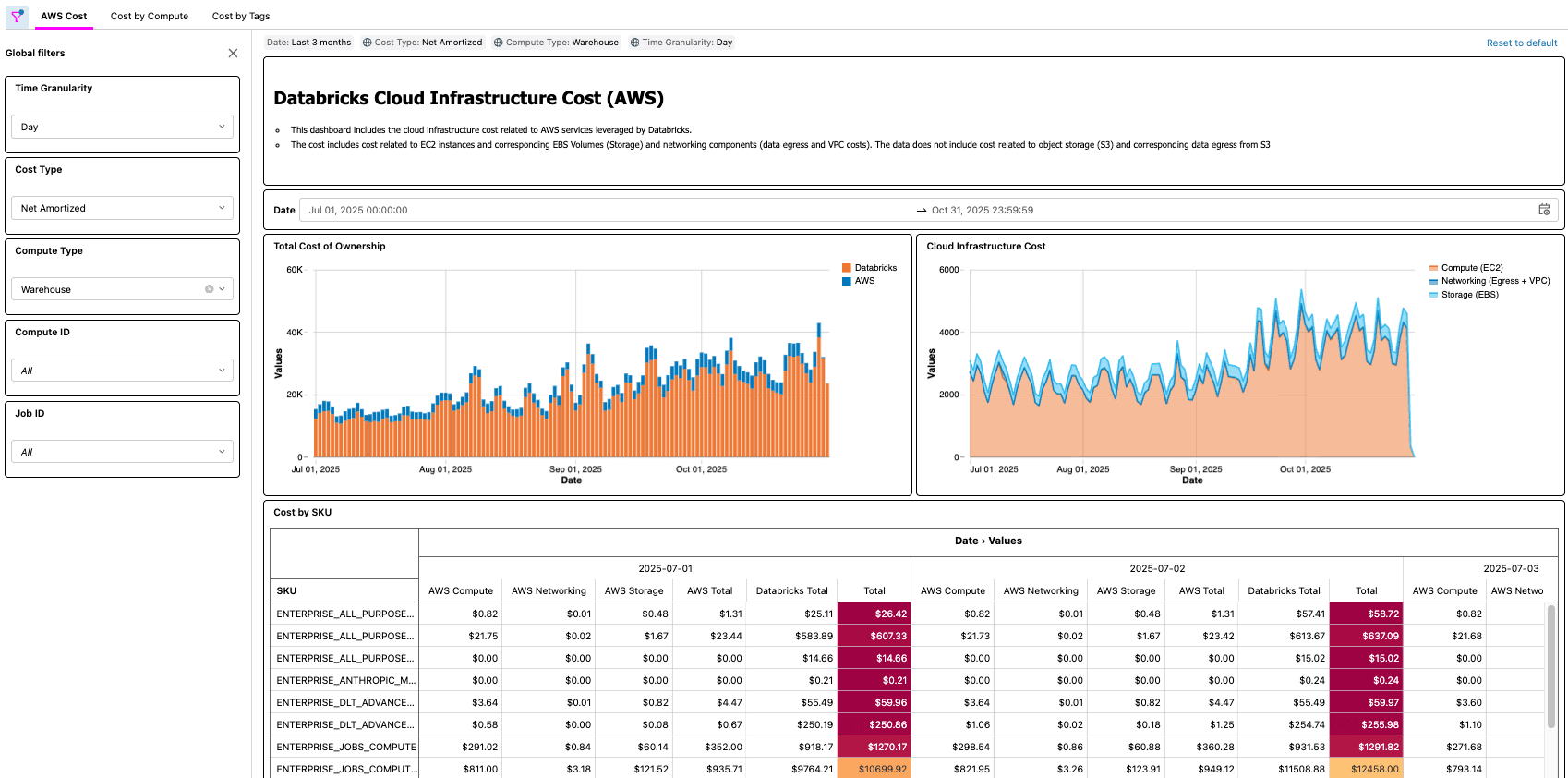{kind=link}
Escenarios del mundo real
Como se demostró con las soluciones de Azure y AWS, hay muchos ejemplos del mundo real que una solución como esta permite, por ejemplo:
- Identificar y calcular el ahorro total de costos después de optimizar un trabajo con poca CPU o memoria
- Identificar las cargas de trabajo que se ejecutan en tipos de VM que no tienen una reserva
- Identificación de cargas de trabajo con costos de red o almacenamiento local anormalmente altos
Como ejemplo práctico, un profesional de FinOps en una organización grande con miles de cargas de trabajo podría tener la tarea de encontrar las oportunidades de optimización más sencillas, buscando cargas de trabajo que cuesten una cierta cantidad, pero que también tengan una baja utilización de CPU o memoria. Dado que la información del TCO de la organización ahora se presenta a través de la Cloud Infra Cost Field Solution, el profesional puede unir esos datos a la Node Timeline System Table (AWS, AZURE, GCP) para presentar esta información y cuantificar con precisión el ahorro de costos una vez que se completen las optimizaciones. Las preguntas más importantes dependerán de las necesidades de negocio de cada cliente. Por ejemplo, General Motors utiliza este tipo de solución para responder muchas de las preguntas anteriores y más, a fin de asegurarse de que están obteniendo el máximo valor de su arquitectura lakehouse.
Conclusiones principales
Después de implementar la solución de campo de costos de infraestructura en la nube (Cloud Infra Cost Field Solution), las organizaciones obtienen una vista única y confiable del TCO que combina el gasto de Databricks y el de la infraestructura de la nube relacionada, lo que elimina la necesidad de una conciliación manual de costos entre plataformas. Algunos ejemplos de preguntas que puede responder con la solución son:
- ¿Cuál es el desglose de costos de mi uso de Databricks entre el proveedor de la nube y Databricks?
- ¿Cuál es el costo total de ejecutar una carga de trabajo, incluidos los costos de VM, almacenamiento local y redes?
- ¿Cuál es la diferencia en el costo total de una carga de trabajo cuando se ejecuta en un entorno serverless (sin servidor) en comparación con cuando se ejecuta en uno de computación clásica?
Los equipos de plataforma y FinOps pueden analizar en detalle los costos completos por espacio de trabajo, carga de trabajo y unidad de negocio directamente en Databricks, lo que facilita mucho más alinear el uso con los presupuestos, los modelos de responsabilidad y las prácticas de FinOps. Debido a que todos los datos subyacentes están disponibles como tablas gobernadas, los equipos pueden crear sus propias aplicaciones de costos —paneles, aplicaciones internas o usar asistentes de IA integrados como Databricks Genie—, lo que acelera la generación de información y convierte a FinOps de un ejercicio de informes periódicos en una capacidad operativa siempre activa.
Siguientes pasos & Recursos
Implemente hoy mismo la Cloud Infra Cost Field Solution desde GitHub (enlace aquí, disponible en AWS y Azure) y obtenga una visibilidad completa de su gasto total en Databricks. Con una visibilidad completa, puede optimizar sus costos de Databricks, lo que incluye considerar la opción serverless para la gestión automatizada de la infraestructura.
El dashboard y la pipeline creados como parte de esta solución ofrecen una forma rápida y eficaz de comenzar a analizar el gasto de Databricks junto con el resto de los costos de su infraestructura. Sin embargo, cada organización asigna e interpreta los cargos de forma diferente, por lo que puede optar por adaptar aún más los modelos y las transformaciones a sus necesidades. Las extensiones habituales incluyen unir los datos de costos de infraestructura con tablas de sistema de Databricks adicionales (AWS | AZURE | GCP) para mejorar la precisión de la atribución, crear una lógica para separar o reasignar los costos compartidos de las VM cuando se usan grupos de instancias, modelar las reservas de VM de forma diferente o incorporar rellenos históricos para respaldar las tendencias de costos a largo plazo. Al igual que con cualquier modelo de costos de hiperescalador, existe un margen considerable para personalizar las canalizaciones más allá de la implementación predeterminada para alinearlas con los informes internos, las estrategias de etiquetado y los requisitos de FinOps.
Los Delivery Solutions Architects (DSA) de Databricks aceleran las iniciativas de datos e IA en todas las organizaciones. Proporcionan liderazgo arquitectónico, optimizan las plataformas en cuanto a costo y rendimiento, mejoran la experiencia del desarrollador e impulsan la ejecución exitosa de los proyectos. Los DSA cierran la brecha entre la implementación inicial y las soluciones listas para producción, trabajando en estrecha colaboración con varios equipos, incluidos los de ingeniería de datos, los líderes técnicos, los ejecutivos y otras partes interesadas, para garantizar soluciones personalizadas y un tiempo de obtención de valor más rápido. Para beneficiarse de un plan de ejecución personalizado, orientación estratégica y soporte de un DSA a lo largo de su recorrido por los datos y la IA, póngase en contacto con su equipo de cuenta de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.