Deuda técnica oculta de los sistemas de IA generativa
Los costos ocultos de la IA generativa: gestión de la proliferación de herramientas, pipelines opacos y evaluaciones subjetivas
por Jeanne Choo y Conor Murphy
- Los desarrolladores que trabajan en el ML clásico y la IA generativa asignan su tiempo de forma muy diferente
- La IA generativa introduce nuevas formas de deuda técnica que deben saldarse
- Hay que introducir nuevas prácticas de desarrollo para hacer frente a estas nuevas formas de deuda técnica
Introducción
Si comparamos a grandes rasgos los flujos de trabajo del aprendizaje automático clásico y de la IA generativa, observamos que los pasos generales del flujo de trabajo son similares en ambos casos. Ambos requieren recopilación de datos, ingeniería de características, optimización del modelo, despliegue, evaluación, etc., pero los detalles de ejecución y la asignación de tiempo son fundamentalmente diferentes. Lo que es más importante, la IA generativa introduce fuentes únicas de deuda técnica que pueden acumularse rápidamente si no se gestionan adecuadamente, entre ellas:
- Proliferación de herramientas: dificultad para administrar y seleccionar entre la creciente cantidad de herramientas de agentes
- Prompt stuffing: prompts demasiado complejos que se vuelven imposibles de mantener
- Canalizaciones opacas: la falta de un seguimiento adecuado dificulta la depuración
- Sistemas de retroalimentación inadecuados: no logran capturar y utilizar eficazmente la retroalimentación humana
- Participación insuficiente de las partes interesadas: no mantener una comunicación regular con los usuarios finales
En este blog, abordaremos cada forma de deuda técnica una por una. En última instancia, los equipos que hacen la transición del ML clásico a la IA generativa deben ser conscientes de estas nuevas fuentes de deuda y adaptar sus prácticas de desarrollo en consecuencia, dedicando más tiempo a la evaluación, la gestión de las partes interesadas, el seguimiento de la calidad subjetiva y la instrumentación en lugar de la limpieza de datos y la ingeniería de características que dominaban los proyectos de ML clásico.
¿En qué se diferencian los flujos de trabajo del aprendizaje automático (ML) clásico y los de la inteligencia artificial (IA) generativa?
Para apreciar dónde se encuentra el campo ahora, es útil comparar cómo nuestros flujos de trabajo para la IA generativa se comparan con lo que usamos para los problemas clásicos de machine learning. A continuación, se presenta una descripción general. Como revela esta comparación, los pasos generales del flujo de trabajo siguen siendo los mismos, pero hay diferencias en los detalles de ejecución que hacen que se enfaticen diferentes pasos. Como veremos, la IA generativa también introduce nuevas formas de deuda técnica, lo que tiene implicaciones en cómo mantenemos nuestros sistemas en producción.
| Paso del flujo de trabajo | ML clásico | IA generativa |
|---|---|---|
| Recopilación de datos | Los datos recopilados representan eventos del mundo real, como ventas minoristas o fallas de equipos. A menudo se utilizan formatos estructurados, como CSV y JSON. | Los datos recopilados representan conocimiento contextual que ayuda a un modelo de lenguaje a proporcionar respuestas relevantes. Se pueden utilizar tanto datos estructurados (a menudo en tablas en tiempo real) como datos no estructurados (imágenes, videos, archivos de texto). |
| Ingeniería de características/ Transformación de datos | Los pasos de transformación de datos implican la creación de nuevas características para reflejar mejor el espacio del problema (p. ej., la creación de características de días de semana y de fin de semana a partir de datos de marca de tiempo) o la realización de transformaciones estadísticas para que los modelos se ajusten mejor a los datos (p. ej., la estandarización de variables continuas para la agrupación de k-medias y la realización de una transformación logarítmica de los datos sesgados para que sigan una distribución normal). | Para los datos no estructurados, la transformación implica la fragmentación, la creación de representaciones de *embedding* y (posiblemente) la adición de metadatos, como encabezados y etiquetas, a los fragmentos. Para los datos estructurados, podría implicar la desnormalización de tablas para que los modelos de lenguaje grandes (LLM) no tengan que considerar uniones de tablas. Agregar descripciones de metadatos de tablas y columnas también es importante. |
| Diseño de la canalización del modelo | Generalmente cubierto por un pipeline básico de tres pasos:
| Generalmente, implica un paso de reescritura de consultas, alguna forma de recuperación de información, posiblemente llamadas a herramientas y verificaciones de seguridad al final. Las canalizaciones son mucho más complejas, implican una infraestructura más compleja, como bases de datos e integraciones de API, y a veces se gestionan con estructuras similares a grafos. |
| Optimización del modelo | La optimización del modelo implica el ajuste de hiperparámetros mediante métodos como la validación cruzada, la búsqueda en cuadrícula y la búsqueda aleatoria. | Aunque se pueden cambiar algunos hiperparámetros, como la temperatura, top-k y top-p, la mayor parte del esfuerzo se dedica a ajustar las instrucciones para guiar el comportamiento del modelo. Dado que una cadena de LLM puede implicar muchos pasos, un ingeniero de IA también puede experimentar con la descomposición de una operación compleja en componentes más pequeños. |
| Implementación | Los modelos son mucho más pequeños que los modelos fundacionales, como los LLM. Las aplicaciones de ML completas se pueden alojar en una CPU sin necesidad de GPU. El versionado, el monitoreo y el linaje de los modelos son consideraciones importantes. Las predicciones del modelo rara vez requieren cadenas o grafos complejos, por lo que no se suelen utilizar trazas. | Debido a que los modelos fundacionales son muy grandes, pueden alojarse en una GPU central y exponerse como una API a varias aplicaciones de IA orientadas al usuario. Esas aplicaciones actúan como “wrappers” en torno a la API del modelo fundacional y se alojan en CPU más pequeñas. La gestión de versiones de la aplicación, el monitoreo y el linaje son consideraciones importantes. Además, debido a que las cadenas y los grafos de los LLM pueden ser complejos, se necesita un seguimiento adecuado para identificar los cuellos de botella y los errores de las consultas. |
| Evaluación | Para el rendimiento del modelo, los científicos de datos pueden usar métricas cuantitativas definidas, como la puntuación F1 para la clasificación o el error cuadrático medio para la regresión. | La corrección del resultado de un LLM depende de juicios subjetivos; por ejemplo, de la calidad de un resumen o una traducción. Por lo tanto, la calidad de la respuesta generalmente se juzga con directrices en lugar de métricas cuantitativas. |
¿Cómo asignan su tiempo de forma diferente los desarrolladores de aprendizaje automático en los proyectos de IA generativa?
A partir de la experiencia de primera mano, equilibrando un proyecto de pron�óstico de precios con un proyecto que crea un agente de llamada a herramientas, descubrimos que existen algunas diferencias importantes en los pasos de desarrollo e implementación del modelo.
Ciclo de desarrollo de modelos
El ciclo de desarrollo interno generalmente se refiere al proceso iterativo por el que pasan los desarrolladores de aprendizaje automático al crear y perfeccionar las canalizaciones de sus modelos. Generalmente, ocurre antes de las pruebas de producción y la implementación del modelo.
Así es como los profesionales de ML clásico e IA generativa invierten su tiempo de manera diferente en este paso:
Pérdidas de tiempo en el desarrollo de modelos de ML clásico
- Recopilación de datos y refinamiento de características: en un proyecto clásico de machine learning, la mayor parte del tiempo se dedica a refinar iterativamente las características y los datos de entrada. Se utiliza una herramienta para gestionar y compartir características, como Databricks Feature Store, cuando hay muchos equipos implicados o demasiadas características para gestionarlas fácilmente de forma manual.
Por el contrario, la evaluación es sencilla: ejecute su modelo y vea si ha habido una mejora en sus métricas cuantitativas, antes de volver a considerar cómo una mejor recopilación de datos y características pueden mejorar el modelo. Por ejemplo, en el caso de nuestro modelo de previsión de precios, nuestro equipo observó que la mayoría de las predicciones erróneas se debían a no tener en cuenta los valores atípicos de los datos. Luego tuvimos que considerar cómo incluir características que representaran estos valores atípicos, lo que permitiría al modelo identificar esos patrones.
Pérdidas de tiempo en el desarrollo de modelos y pipelines de IA generativa
- Evaluación: en un proyecto de IA generativa, la asignación de tiempo relativo entre la recopilación y transformación de datos y la evaluación se invierte. La recopilación de datos suele implicar reunir suficiente contexto para el modelo, que puede ser en forma de documentos de bases de conocimiento no estructuradas o manuales. Estos datos no requieren una limpieza exhaustiva. Pero la evaluación es mucho más subjetiva y compleja y, por consiguiente, consume más tiempo. No solo estás iterando en el pipeline del modelo, sino que también necesitas iterar en tu conjunto de evaluación. Y se dedica más tiempo a tener en cuenta los casos extremos que con el ML clásico.
Por ejemplo, un conjunto inicial de 10 preguntas de evaluación podría no cubrir todo el espectro de preguntas que un usuario podría hacerle a un bot de soporte, en cuyo caso necesitarás reunir más evaluaciones, o los jueces LLM que has configurado podrían ser demasiado estrictos, por lo que necesitas reformular sus prompts para evitar que las respuestas relevantes fallen en las pruebas. Los Evaluation Datasets de MLflow son útiles para versionar, desarrollar y auditar un “conjunto dorado” de ejemplos que siempre deben funcionar correctamente. - Gestión de las partes interesadas: Además, debido a que la calidad de la respuesta depende de la entrada del usuario final, los ingenieros dedican mucho más tiempo a reunirse con los usuarios finales del negocio y los gerentes de producto para recopilar y priorizar los requisitos, así como para iterar sobre la retroalimentación de los usuarios. Históricamente, el ML clásico a menudo no estaba ampliamente orientado al usuario final (p. ej., pronósticos de series temporales) o estaba menos expuesto a usuarios no técnicos, por lo que las exigencias de gestión de producto de la IA generativa son mucho mayores. La recopilación de comentarios sobre la calidad de las respuestas se puede hacer a través de una UI simple alojada en Databricks Apps que llama a la API de comentarios de MLflow. Los comentarios pueden agregarse a un Trace de MLflow y a un conjunto de datos de evaluación de MLflow, lo que crea un ciclo virtuoso entre los comentarios y la mejora del modelo.
Los siguientes diagramas comparan las asignaciones de tiempo del ML clásico y la IA generativa para el ciclo de desarrollo del modelo.
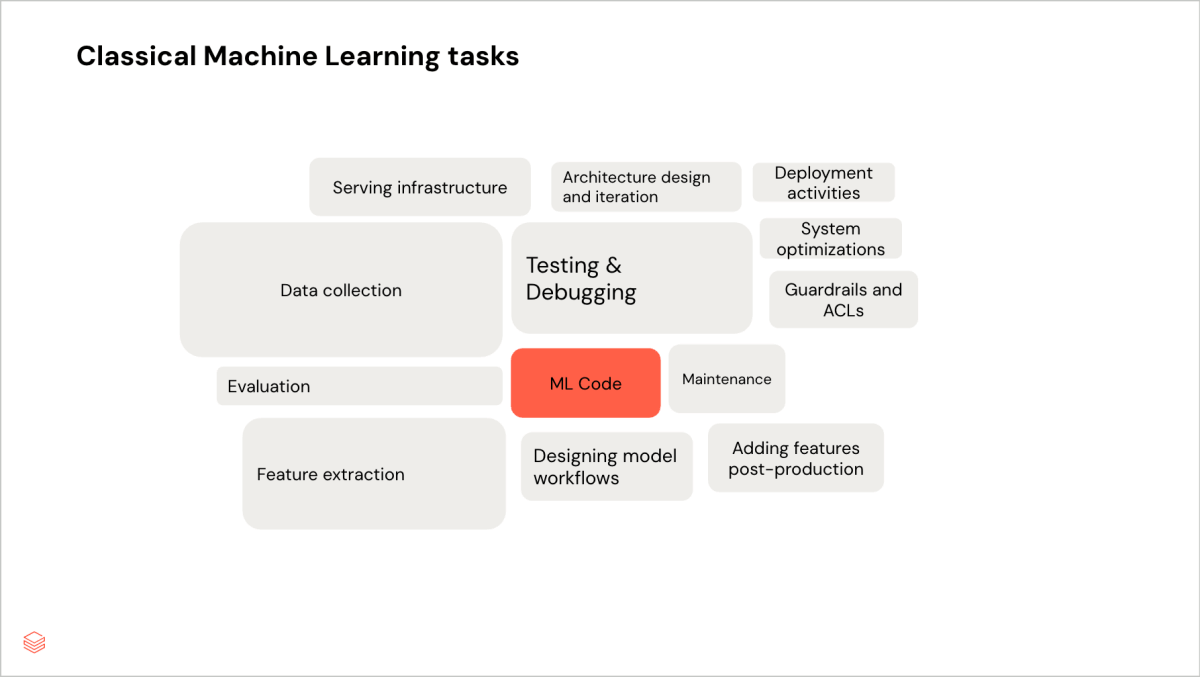

Bucle de implementación de modelos
A diferencia del ciclo de desarrollo del modelo, el ciclo de despliegue del modelo no se centra en optimizar el rendimiento del modelo. En cambio, los ingenieros se centran en las pruebas sistemáticas, el despliegue y la supervisión en entornos de producción.
Aquí, los desarrolladores pueden mover las configuraciones a archivos YAML para facilitar las actualizaciones del proyecto. También podrían refactorizar las canalizaciones de procesamiento de datos estáticos para que se ejecuten en modo de streaming, utilizando un marco de trabajo más robusto como PySpark en lugar de Pandas. Finalmente, deben considerar cómo configurar los procesos de prueba, supervisión y retroalimentación para mantener la calidad del modelo.
En este punto, la automatización es esencial, y la integración y entrega continuas es un requisito no negociable. Para gestionar la CI/CD para proyectos de datos e IA en Databricks, los Paquetes de activos de Databricks suelen ser la herramienta elegida. Permiten describir los recursos de Databricks (como trabajos y pipelines) como archivos de origen y proporcionan una forma de incluir metadatos junto con los archivos de origen de su proyecto.
Al igual que en la etapa de desarrollo del modelo, las actividades que llevan más tiempo en los proyectos de IA generativa frente a los de ML clásico en esta etapa no son las mismas.
Pérdidas de tiempo en la implementación del modelo de ML clásico
- Refactorización: en un proyecto clásico de machine learning, el código de los notebooks puede ser bastante desordenado. Se prueban, descartan y recombinan continuamente diferentes combinaciones de datasets, características y modelos. Como resultado, puede que sea necesario dedicar un esfuerzo significativo a refactorizar el código de los notebooks para hacerlo más robusto. Tener una estructura de carpetas de repositorio de código establecida (como la plantilla Databricks Asset Bundles MLOps Stacks) puede proporcionar el andamiaje necesario para este proceso de refactorización.
Algunos ejemplos de actividades de refactorización incluyen:- Abstraer el código auxiliar en funciones
- Crear bibliotecas de ayuda para que las funciones de utilidad puedan importarse y reutilizarse varias veces
- Mover las configuraciones de los notebooks a archivos YAML
- Crear implementaciones de código más eficientes que se ejecuten de forma más rápida y eficiente (p. ej., eliminar bucles
foranidados)
- Monitoreo de calidad: El monitoreo de calidad es otro gran consumidor de tiempo porque los errores de datos pueden presentarse de muchas formas y ser difíciles de detectar. En particular, como señalan Shreya Shankar et al. en su artículo “Operationalizing Machine Learning: An Interview Study” , “los errores blandos (soft errors), como algunas características con valores nulos en un punto de datos, son menos perniciosos y aun así pueden producir predicciones razonables, lo que los hace difíciles de detectar y cuantificar”. Además, los diferentes tipos de errores requieren diferentes respuestas, y determinar la respuesta adecuada no siempre es fácil.
Un desafío adicional es que los diferentes tipos de deriva del modelo (como la deriva de características, la deriva de datos y la deriva de etiquetas) deben medirse en diferentes granularidades de tiempo (diaria, semanal y mensual), lo que aumenta la complejidad. Para facilitar el proceso, los desarrolladores pueden usar Databricks Data Quality Monitoring para hacer un seguimiento de las métricas de calidad del modelo, la calidad de los datos de entrada y la posible deriva de las entradas y predicciones del modelo dentro de un marco holístico.
Pérdidas de tiempo en la implementación de modelos de IA generativa
- Monitoreo de calidad: Con la IA generativa, el monitoreo también consume una cantidad sustancial de tiempo, pero por diferentes razones:
- Requisitos en tiempo real: los proyectos de aprendizaje automático clásico para tareas como la predicción de la pérdida de clientes, la previsión de precios o la readmisión de pacientes pueden ofrecer predicciones en modo por lotes, ejecutándose quizás una vez al día, una vez a la semana o una vez al mes. Sin embargo, muchos proyectos de IA generativa son aplicaciones en tiempo real, como agentes de soporte virtual, agentes de transcripción en vivo o agentes de codificación. En consecuencia, es necesario configurar herramientas de monitoreo en tiempo real, lo que significa monitoreo de endpoints en tiempo real, pipelines de análisis de inferencia en tiempo real y alertas en tiempo real.
Configurar puertas de enlace de API (como Databricks AI Gateway) para realizar comprobaciones de protección en la API de LLM puede respaldar los requisitos de seguridad y privacidad de los datos. Este es un enfoque diferente a la supervisión de modelos tradicional, que se realiza como un proceso fuera de línea. - Evaluaciones subjetivas: como se mencionó anteriormente, las evaluaciones para las aplicaciones de IA generativa son subjetivas. Los ingenieros de despliegue de modelos deben considerar cómo operacionalizar la recopilación de comentarios subjetivos en sus canalizaciones de inferencia. Esto podría tomar la forma de evaluaciones de jueces de LLM que se ejecutan en las respuestas del modelo, o seleccionar un subconjunto de respuestas del modelo para presentarlas a un experto en el dominio para que las evalúe. Los proveedores de modelos propietarios optimizan sus modelos con el tiempo, por lo que sus “modelos” son en realidad servicios propensos a regresiones, y los criterios de evaluación deben tener en cuenta que los pesos del modelo no están congelados como en los modelos autoentrenados.
La capacidad de proporcionar comentarios de formato libre y calificaciones subjetivas cobra protagonismo. Frameworks como Databracks Apps y la MLflow Feedback API permiten interfaces de usuario más simples que pueden capturar dichos comentarios y vincularlos a llamadas específicas de LLM.
- Requisitos en tiempo real: los proyectos de aprendizaje automático clásico para tareas como la predicción de la pérdida de clientes, la previsión de precios o la readmisión de pacientes pueden ofrecer predicciones en modo por lotes, ejecutándose quizás una vez al día, una vez a la semana o una vez al mes. Sin embargo, muchos proyectos de IA generativa son aplicaciones en tiempo real, como agentes de soporte virtual, agentes de transcripción en vivo o agentes de codificación. En consecuencia, es necesario configurar herramientas de monitoreo en tiempo real, lo que significa monitoreo de endpoints en tiempo real, pipelines de análisis de inferencia en tiempo real y alertas en tiempo real.
- Pruebas: Las pruebas suelen consumir más tiempo en las aplicaciones de IA generativa, por algunas razones:
- Desafíos no resueltos: Las aplicaciones de IA generativa en sí mismas son cada vez más complejas, pero los marcos de evaluación y prueba aún no se han puesto al día. Algunos escenarios que hacen que las pruebas sean un desafío incluyen:
- Conversaciones largas de varios turnos
- Salida de SQL que puede o no capturar detalles importantes sobre el contexto organizacional de una empresa
- Tener en cuenta que se usen las herramientas correctas en una cadena
- Evaluar múltiples agentes en una aplicación
El primer paso para manejar esta complejidad suele ser capturar con la mayor precisión posible una traza de la salida del agente (un historial de ejecución de llamadas a herramientas, razonamiento y respuesta final). Una combinación de captura automática de trazas e instrumentación manual puede proporcionar la flexibilidad necesaria para cubrir toda la gama de interacciones del agente. Por ejemplo, el MLflow Tracestracedecorator se puede usar en cualquier función para capturar sus entradas y salidas. Al mismo tiempo, se pueden crear spans personalizados de MLflow Traces dentro de bloques de código específicos para registrar operaciones más granulares. Solo después de usar la instrumentación para agregar una fuente de verdad confiable de las salidas del agente, los desarrolladores pueden comenzar a identificar los modos de fallo y diseñar las pruebas correspondientes.
- Incorporar los comentarios humanos: Es fundamental incorporar esta información al evaluar la calidad. Pero algunas actividades consumen mucho tiempo. Por ejemplo:
- Diseñar rúbricas para que los anotadores tengan pautas que seguir
- Diseñar diferentes métricas y jueces para diferentes escenarios (por ejemplo, si un resultado es seguro frente a si un resultado es útil)
Las discusiones y talleres presenciales suelen ser necesarios para crear una rúbrica compartida de cómo se espera que responda un agente. Solo después de que los anotadores humanos estén alineados, sus evaluaciones pueden integrarse de forma fiable en los jueces basados en LLM, utilizando funciones como la APImake_judgede MLflow o elSIMBAAlignmentOptimizer.
- Desafíos no resueltos: Las aplicaciones de IA generativa en sí mismas son cada vez más complejas, pero los marcos de evaluación y prueba aún no se han puesto al día. Algunos escenarios que hacen que las pruebas sean un desafío incluyen:
Deuda técnica de la IA
La deuda técnica se acumula cuando los desarrolladores implementan una solución rápida y poco elegante a expensas de la mantenibilidad a largo plazo.
Deuda técnica del ML clásico
Dan Sculley et al. han proporcionado un gran resumen de los tipos de deuda técnica que estos sistemas pueden acumular. En su artículo “Aprendizaje automático: la tarjeta de crédito de alto interés de la deuda técnica”, las desglosan en tres grandes áreas:
- Deuda de datos: dependencias de datos que están mal documentadas, no se tienen en cuenta o cambian silenciosamente
- Deuda a nivel de sistema: código de acoplamiento extenso, “selvas” de pipelines y rutas “muertas” codificadas
- Cambios externos: umbrales modificados (como el umbral de precisión-recall) o la eliminación de correlaciones que antes eran importantes
La IA generativa introduce nuevas formas de deuda técnica, muchas de las cuales pueden no ser evidentes. En esta sección se exploran las fuentes de esta deuda técnica oculta.
Proliferación de herramientas
Las herramientas son una forma poderosa de ampliar las capacidades de un LLM. Sin embargo, a medida que aumenta el número de herramientas utilizadas, pueden volverse difíciles de gestionar.
La proliferación de herramientas no solo presenta un problema de detectabilidad y reutilización, sino que también puede afectar negativamente la calidad de un sistema de IA generativa. Cuando las herramientas proliferan, surgen dos puntos de falla clave:
- Selección de herramientas: el LLM debe ser capaz de seleccionar correctamente la herramienta adecuada a la que llamar de entre una amplia gama de herramientas. Si las herramientas hacen cosas más o menos similares, como llamar a las API de datos para obtener estadísticas de ventas semanales frente a mensuales, asegurarse de que se llama a la herramienta correcta se vuelve difícil. Los LLM comenzarán a cometer errores.
- Parámetros de la herramienta: incluso después de seleccionar con éxito la herramienta correcta a la que llamar, un LLM todavía necesita poder analizar la pregunta de un usuario en el conjunto correcto de parámetros para pasar a la herramienta. Este es otro punto de falla a tener en cuenta y se vuelve particularmente difícil cuando varias herramientas tienen estructuras de parámetros similares.
La solución más limpia para la proliferación de herramientas es ser estratégico y minimalista con las herramientas que utiliza un equipo.
Sin embargo, la estrategia de gobernanza correcta puede ayudar a que la administración de múltiples herramientas y accesos sea escalable a medida que más y más equipos integran la GenAI en sus proyectos y sistemas. Los productos de Databricks, Unity Catalog y AI Gateway, están diseñados para este tipo de escala.
Saturación de prompts
Aunque los modelos de última generación pueden manejar páginas de instrucciones, las instrucciones demasiado complejas pueden introducir problemas como instrucciones contradictorias o información desactualizada. Este es el caso, especialmente, cuando las instrucciones no se editan, sino que simplemente diferentes expertos de dominio o desarrolladores las agregan con el tiempo.
A medida que surgen diferentes modos de falla o se agregan nuevas consultas al alcance, es tentador seguir agregando más y más instrucciones a un prompt de LLM. Por ejemplo, un prompt podría comenzar proporcionando instrucciones para manejar preguntas relacionadas con las finanzas, y luego extenderse a preguntas relacionadas con productos, ingeniería y recursos humanos.
Así como una “clase dios” en ingeniería de software no es una buena idea y debe dividirse, los megaprompts deben separarse en otros más pequeños. De hecho, Anthropic lo menciona en su guía de ingeniería de prompts, y, como regla general, tener varios prompts más pequeños en lugar de uno largo y complejo ayuda con la claridad, la precisión y la resolución de problemas.
Los frameworks pueden ayudar a que los prompts sean manejables mediante el seguimiento de sus versiones y la aplicación de las entradas y salidas esperadas. Un ejemplo de una herramienta de control de versiones de prompts es el Registro de prompts de MLflow, mientras que los optimizadores de prompts como DSPy se pueden ejecutar en Databricks para descomponer un prompt en módulos autónomos que se pueden optimizar de forma individual o en conjunto.
Pipelines opacos
Hay una razón por la que el rastreo (tracing) ha estado recibiendo atención últimamente, y es que la mayoría de las bibliotecas de LLM y herramientas de seguimiento ofrecen la capacidad de rastrear las entradas y salidas de una cadena de LLM. Cuando una respuesta devuelve un error (el temido “Lo siento, no puedo responder a tu pregunta”), examinar las entradas y salidas de las llamadas intermedias del LLM es crucial para identificar la causa raíz.
Una vez trabajé en una aplicación en la que inicialmente supuse que la generación de SQL sería el paso más problemático del flujo de trabajo. Sin embargo, la inspección de mis trazas contó una historia diferente: la mayor fuente de errores era en realidad un paso de reescritura de consultas donde actualizábamos las entidades en la pregunta del usuario a entidades que coincidían con los valores de nuestra base de datos. El LLM reescribía consultas que no necesitaban reescritura o empezaba a llenar la consulta original con todo tipo de información extra. Esto solía estropear el proceso de generación de SQL posterior. El rastreo ayudó en este caso a identificar rápidamente el problema.
Rastrear las llamadas correctas del LLM puede llevar tiempo. No basta con implementar el rastreo listo para usar. Instrumentar adecuadamente una aplicación con observabilidad, utilizando un framework como MLflow Traces, es un primer paso para que las interacciones de los agentes sean más transparentes.
Sistemas inadecuados para capturar y utilizar los comentarios humanos
Los LLM son extraordinarios porque se les pueden pasar unos cuantos prompts sencillos, encadenar los resultados y terminar con algo que parece entender muy bien los matices y las instrucciones. Pero si se avanza demasiado por este camino sin basar las respuestas en los comentarios de los usuarios, la deuda de calidad puede acumularse rápidamente. Aquí es donde puede ayudar crear un “volante de inercia de datos” lo antes posible, que consta de tres pasos:
- Decidir las métricas de éxito
- Automatizar la forma de medir estas métricas, quizá a través de una UI que los usuarios puedan utilizar para dar su opinión sobre lo que funciona
- Ajustar iterativamente los prompts o los pipelines para mejorar las métricas
Recordé la importancia de los comentarios humanos al desarrollar una aplicación de texto a SQL para consultar estadísticas deportivas. El experto en el dominio pudo explicar cómo un aficionado a los deportes querría interactuar con los datos, aclarando qué le importaría y proporcionando otras perspectivas que yo, como alguien que rara vez ve deportes, nunca habría podido imaginar. Sin sus aportes, la aplicación que creé probablemente no habría satisfecho las necesidades de los usuarios.
Aunque capturar la retroalimentación humana es invaluable, generalmente consume muchísimo tiempo. Primero, es necesario programar tiempo con los expertos en el dominio, luego crear rúbricas para conciliar las diferencias entre los expertos y, después, evaluar los comentarios para realizar mejoras. Si la IU de retroalimentación está alojada en un entorno al que los usuarios de negocio no pueden acceder, ponerse en contacto con los administradores de TI para proporcionar el nivel de acceso correcto puede parecer un proceso interminable.
Desarrollar sin revisiones periódicas con las partes interesadas
Consultar regularmente con los usuarios finales, los patrocinadores del negocio y los equipos adyacentes para ver si se está construyendo lo correcto es fundamental para todo tipo de proyectos. Sin embargo, con los proyectos de IA generativa, la comunicación con las partes interesadas es más crucial que nunca.
Por qué es importante la comunicación frecuente y de alto contacto:
- Propiedad y control: las reuniones regulares ayudan a las partes interesadas a sentir que tienen una manera de influir en la calidad final de una aplicación. En lugar de ser críticos, pueden convertirse en colaboradores. Por supuesto, no todos los comentarios tienen el mismo valor. Algunas partes interesadas inevitablemente comenzarán a solicitar cosas que son prematuras para implementar en un MVP o que están fuera de lo que los LLM pueden manejar actualmente. Es importante negociar y educar a todos sobre lo que se puede y no se puede lograr. De lo contrario, puede aparecer otro riesgo: demasiadas solicitudes de funciones sin freno.
- No sabemos lo que no sabemos: la IA generativa es tan nueva que la mayoría de las personas, tanto técnicas como no técnicas, no saben lo que un LLM puede y no puede manejar adecuadamente. Desarrollar una aplicación de LLM es un viaje de aprendizaje para todos los involucrados, y los puntos de contacto regulares son una forma de mantener a todos informados.
Existen muchas otras formas de deuda técnica que pueden necesitar ser abordadas en proyectos de IA generativa, incluyendo la aplicación de controles de acceso a datos adecuados, la implementación de barreras de protección para gestionar la seguridad y prevenir las inyecciones de prompts, evitar que los costos se disparen, y más. Solo he incluido los que parecen más importantes aquí y que podrían pasarse por alto fácilmente.
Conclusión
El ML clásico y la IA generativa son diferentes variantes del mismo dominio técnico. Si bien es importante ser consciente de las diferencias entre ellos y considerar el impacto de estas diferencias en cómo construimos y mantenemos nuestras soluciones, ciertas verdades permanecen constantes: la comunicación sigue cerrando brechas, el monitoreo sigue previniendo catástrofes y los sistemas limpios y mantenibles siguen superando a los caóticos a largo plazo.
¿Quiere evaluar la madurez de su propia organización en materia de IA? Lea nuestra guía: Desbloquee el valor de la IA: la guía empresarial para la preparación para la IA.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.