Feature flagging de alta disponibilidad en Databricks
Cómo creamos un sistema de feature flags sin tiempo de inactividad para la infraestructura global de Databricks
por Benjamin Congdon
- SAFE es la plataforma interna de feature flagging de Databricks que permite a los ingenieros desacoplar el despliegue de código de la habilitación de funcionalidades, lo que permite despliegues más seguros y una mitigación de incidentes más rápida en cientos de servicios
- Esta publicación describe la arquitectura de SAFE, que gestiona más de 25 000 flags activos y más de 300 millones de evaluaciones por segundo con una latencia a escala de microsegundos mediante técnicas como la preevaluación de dimensiones estáticas y la entrega global en varios niveles.
- El sistema logra una alta fiabilidad a través de mecanismos de resiliencia por capas que incluyen el comportamiento de falla estática, rutas de entrega fuera de banda y paquetes de configuración de inicio en frío que garantizan que los servicios continúen operando incluso durante las fallas en el pipeline de entrega.
Distribuir software rápidamente y a la vez mantener la fiabilidad es una tensión constante. A medida que Databricks ha crecido, también lo ha hecho la complejidad de desplegar cambios de forma segura en cientos de servicios, múltiples nubes y miles de cargas de trabajo de clientes. Los feature flags nos ayudan a gestionar esta complejidad al separar la decisión de desplegar el código de la decisión de habilitarlo. Esta separación permite a los ingenieros aislar fallas y mitigar incidentes más rápido, sin sacrificar la velocidad de distribución.
Uno de los componentes clave de la postura de estabilidad de Databricks es nuestra plataforma interna de feature flagging y experimentación, llamada "SAFE". Los ingenieros de Databricks utilizan SAFE a diario para lanzar nuevas funcionalidades, controlar dinámicamente el comportamiento de los servicios y medir la efectividad de sus funcionalidades con experimentos A/B.
Contexto
SAFE se inició con el objetivo "norte" de desacoplar por completo los lanzamientos de binarios de servicio de la habilitación de funcionalidades, lo que permite a los equipos lanzar funcionalidades independientemente de su despliegue de binarios. Esto permite muchos beneficios adicionales, como la capacidad de implementar de forma fiable una función para poblaciones de usuarios progresivamente más grandes y mitigar rápidamente los incidentes causados por un despliegue.
A la escala de Databricks, atendiendo a miles de clientes empresariales en múltiples nubes con un área de superficie de producto en rápido crecimiento, necesitábamos un sistema de feature flagging que pudiera cumplir con nuestros requisitos únicos:
- Altos estándares de seguridad y gestión de cambios. La principal propuesta de valor de SAFE era mejorar la estabilidad y la postura operativa de Databricks, por lo que casi todos los demás requisitos se derivaron de esto.
- Entrega global multinube y sin interrupciones en Azure, AWS y GCP, con una latencia de evaluación de flags de menos de un milisegundo para admitir servicios de producción de alto rendimiento y sensibles a la latencia.
- Soporte transparente para todos los lugares donde los ingenieros de Databricks escriben código, incluido nuestro plano de control, la UI de Databricks, Databricks Runtime Environment y el plano de datos Serverless de Databricks.
- Una interfaz lo suficientemente dogmática sobre las prácticas de lanzamiento de Databricks para hacer que los lanzamientos de flags comunes fueran "seguros por defecto", pero a la vez lo suficientemente flexible para admitir un gran conjunto de casos de uso más esotéricos.
- Requisitos de disponibilidad extremadamente rigurosos, ya que los servicios no pueden iniciarse de forma segura sin que se carguen las definiciones de los flags.
Después de considerar cuidadosamente estos requisitos, finalmente optamos por crear un sistema de feature flagging personalizado e interno. Necesitábamos una solución que pudiera evolucionar junto con nuestra arquitectura y que proporcionara los controles de gobernanza necesarios para gestionar de forma segura los flags en cientos de servicios y miles de ingenieros. Lograr con éxito nuestros objetivos de escalabilidad y seguridad requirió una integración profunda con nuestro modelo de datos de infraestructura, marcos de servicios y sistemas de CI.
A finales de 2025, SAFE tiene aproximadamente 25 000 flags activos, con 4000 cambios de estado de flags por semana. En su punto máximo, SAFE ejecuta más de 300 millones de evaluaciones por segundo, todo mientras mantiene una latencia p95 de ~10 μs para las evaluaciones de flags.
Esta publicación explora cómo creamos SAFE para cumplir con estos requisitos y los aprendizajes que hemos encontrado en el camino.
Feature Flags en acción
Para empezar, analizaremos el recorrido típico de un usuario para un flag de SAFE. En esencia, un feature flag es una variable a la que se puede acceder en el flujo de control de un servicio, que puede tomar diferentes valores dependiendo de las condiciones controladas desde una configuración externa. Un caso de uso extremadamente común para los feature flags es habilitar gradualmente una nueva ruta de código de forma controlada, comenzando primero con una pequeña porción del tráfico y habilitándola gradualmente a nivel global.
Los usuarios de SAFE comienzan por definir su flag en el código de su servicio y lo utilizan como una compuerta condicional para la lógica de la nueva función:
Luego, el usuario va a la UI interna de SAFE, registra este flag y selecciona una plantilla para su lanzamiento. Esta plantilla define un plan de implementación gradual que consiste en una lista de etapas ordenadas. Cada etapa se implementa lentamente por porcentajes. Una vez creado el flag, al usuario se le presenta una UI con este aspecto:
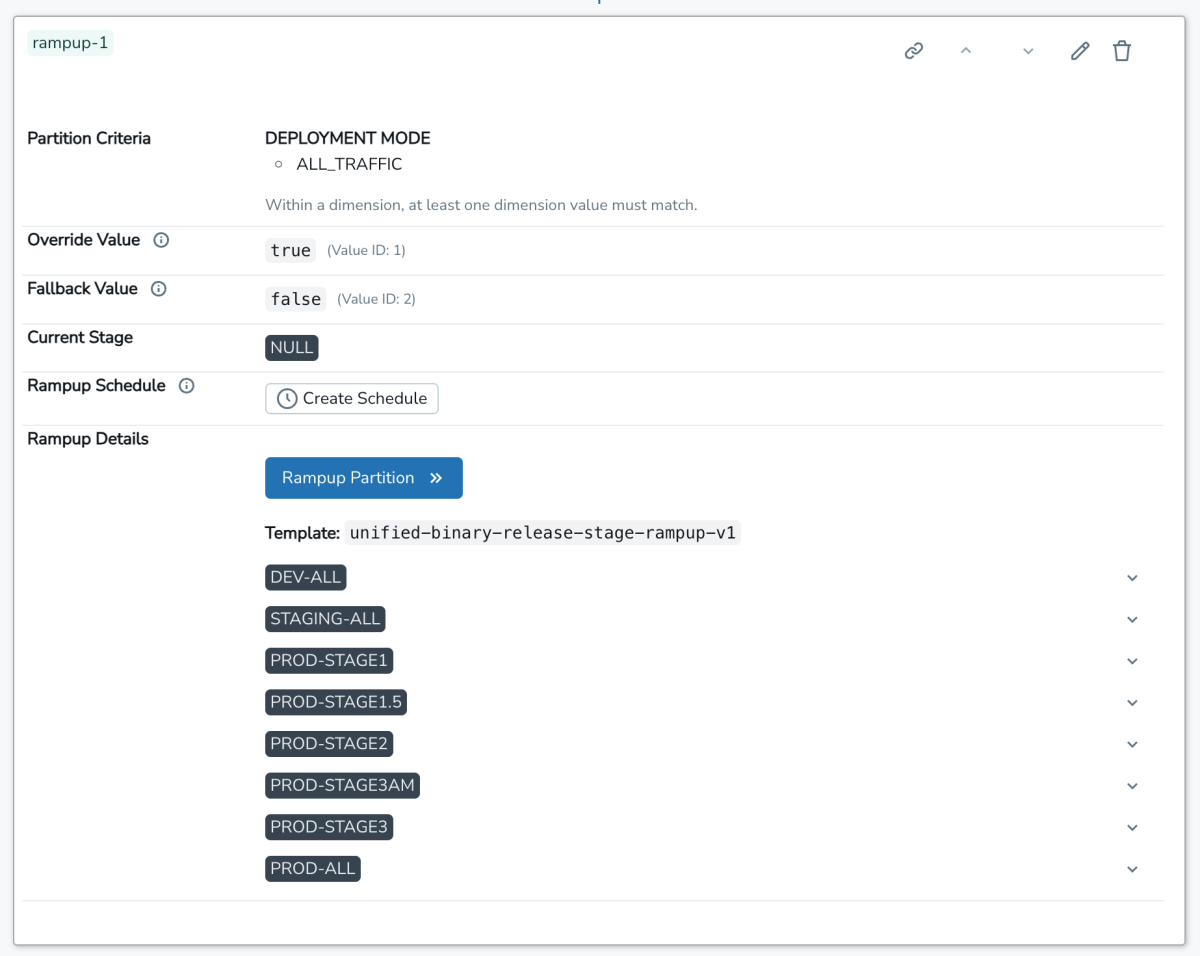
Desde aquí, el usuario puede desplegar manualmente su flag una etapa a la vez o configurar una programación para que los cambios de estado del flag se creen en su nombre. Internamente, la fuente de verdad para la configuración del flag es un archivo jsonnet registrado en el monorepo de Databricks, que utiliza un lenguaje de dominio específico (DSL) ligero para gestionar la configuración del flag:
Cuando los usuarios modifican un flag desde la UI, el resultado de ese cambio es un Pull Request que debe ser revisado por al menos otro ingeniero. SAFE también ejecuta una variedad de verificaciones previas a la fusión para protegerse contra cambios inseguros o no deseados. Una vez que se fusiona el cambio, el servicio del usuario lo aplicará y comenzará a emitir el nuevo valor entre 2 y 5 minutos después de la fusión del PR.
CASOS DE USO
Además del caso de uso descrito anteriormente para el lanzamiento de funcionalidades, SAFE también se utiliza para otros aspectos de la configuración dinámica de servicios, como por ejemplo: configuraciones dinámicas de larga duración (p. ej., tiempos de espera o límites de velocidad), control de máquinas de estado para migraciones de infraestructura, o para entregar pequeños blobs de configuración (p. ej., políticas de registro específicas).
Arquitectura
Bibliotecas de cliente
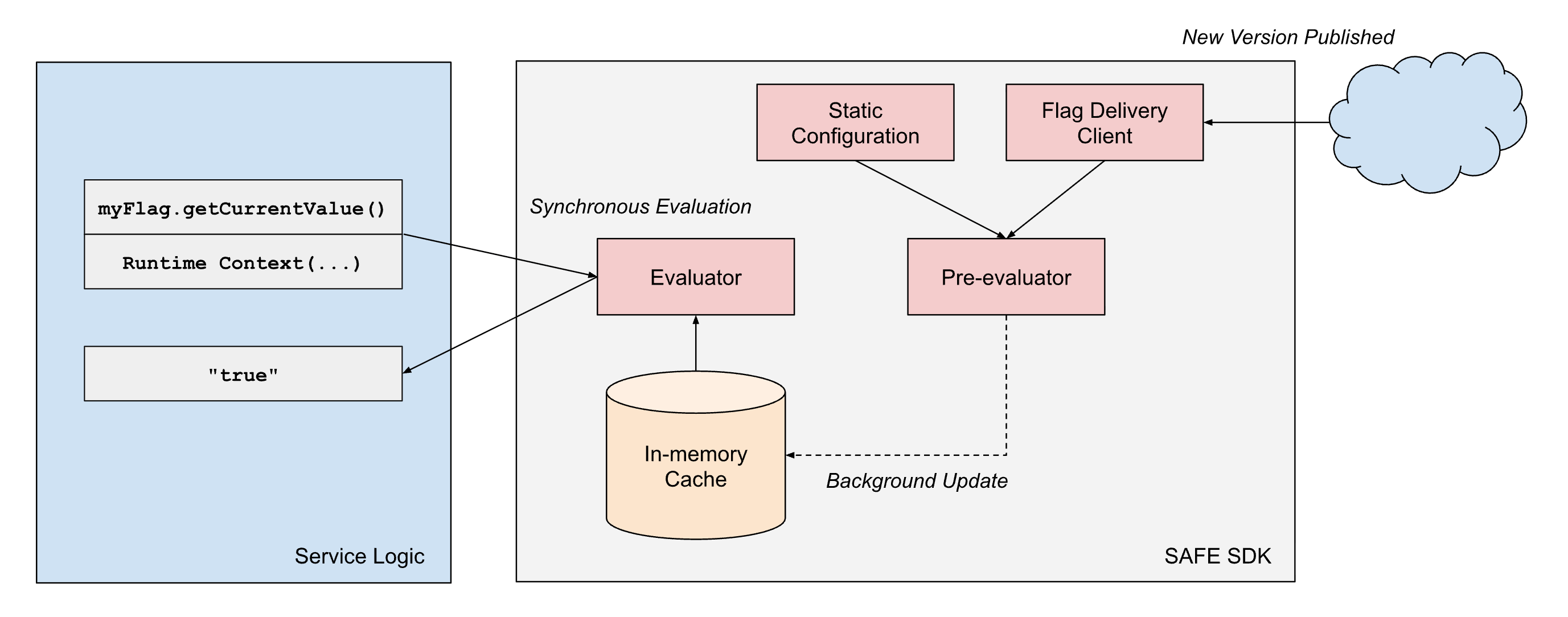
SAFE proporciona "SDK" de cliente en múltiples lenguajes con soporte interno, siendo el SDK de Scala el más maduro y ampliamente adoptado. El SDK es esencialmente una biblioteca de evaluación de criterios, combinada con un componente de carga de configuración. Para cada flag, hay un conjunto de criterios que controlan qué valor debe devolver el SDK en tiempo de ejecución. El SDK gestiona la carga del último conjunto de configuraciones y necesita devolver rápidamente el resultado de la evaluación de esos criterios en tiempo de ejecución.
En seudocódigo, los criterios se ven internamente de la siguiente manera:
Los criterios se pueden modelar como algo parecido a una secuencia de árboles de expresión booleanos. Cada expresión condicional debe evaluarse de manera eficiente para devolver un resultado rápido.
Para cumplir con nuestros requisitos de rendimiento, el diseño del SDK de SAFE incorpora algunos principios de arquitectura: (1) separación de la entrega de la configuración de la evaluación, y (2) separación de las dimensiones de evaluación estáticas y de tiempo de ejecución.
- Separación de la entrega y la evaluación: las bibliotecas de cliente SAFE siempre tratan la entrega como un proceso asíncrono y nunca bloquean la "ruta crítica" de la evaluación del flag en la entrega de la configuración. Una vez que el cliente tiene una instantánea de la configuración de un flag, seguirá devolviendo resultados basados en esa instantánea hasta que un proceso asíncrono en segundo plano realice una actualización atómica de esa instantánea a una más reciente.
- Separación de tipos de dimensión: la evaluación de flags en SAFE opera en dos tipos de dimensiones:
- Dimensiones estáticas representan características del propio binario en ejecución, como el proveedor de la nube, la región de la nube y el entorno (dev/staging/prod). Estos valores permanecen constantes durante la vida útil de un proceso.
- Dimensiones de tiempo de ejecución capturan el contexto específico de la solicitud, como los ID de los espacios de trabajo, los ID de las cuentas, los valores proporcionados por la aplicación y otros atributos por solicitud que varían con cada evaluación.
Para lograr de manera confiable una latencia de evaluación de menos de un milisegundo a escala, SAFE emplea la preevaluación de las partes estáticas del árbol de expresión booleana. Cuando se entrega un paquete de configuración de SAFE a un servicio, el SDK evalúa inmediatamente todas las dimensiones estáticas con respecto a la representación en memoria de la configuración del flag. Esto produce un �árbol de configuración simplificado que contiene solo la lógica relevante para esa instancia de servicio específica.
Cuando se solicita la evaluación de un flag durante el procesamiento de la solicitud, el SDK solo necesita evaluar las dimensiones de tiempo de ejecución restantes con esta configuración precompilada. Esto reduce significativamente el costo computacional de cada evaluación. Dado que muchos flags solo utilizan dimensiones estáticas en sus árboles de expresión booleana, muchos flags pueden ser preevaluados por completo de forma eficaz.
Entrega de flags
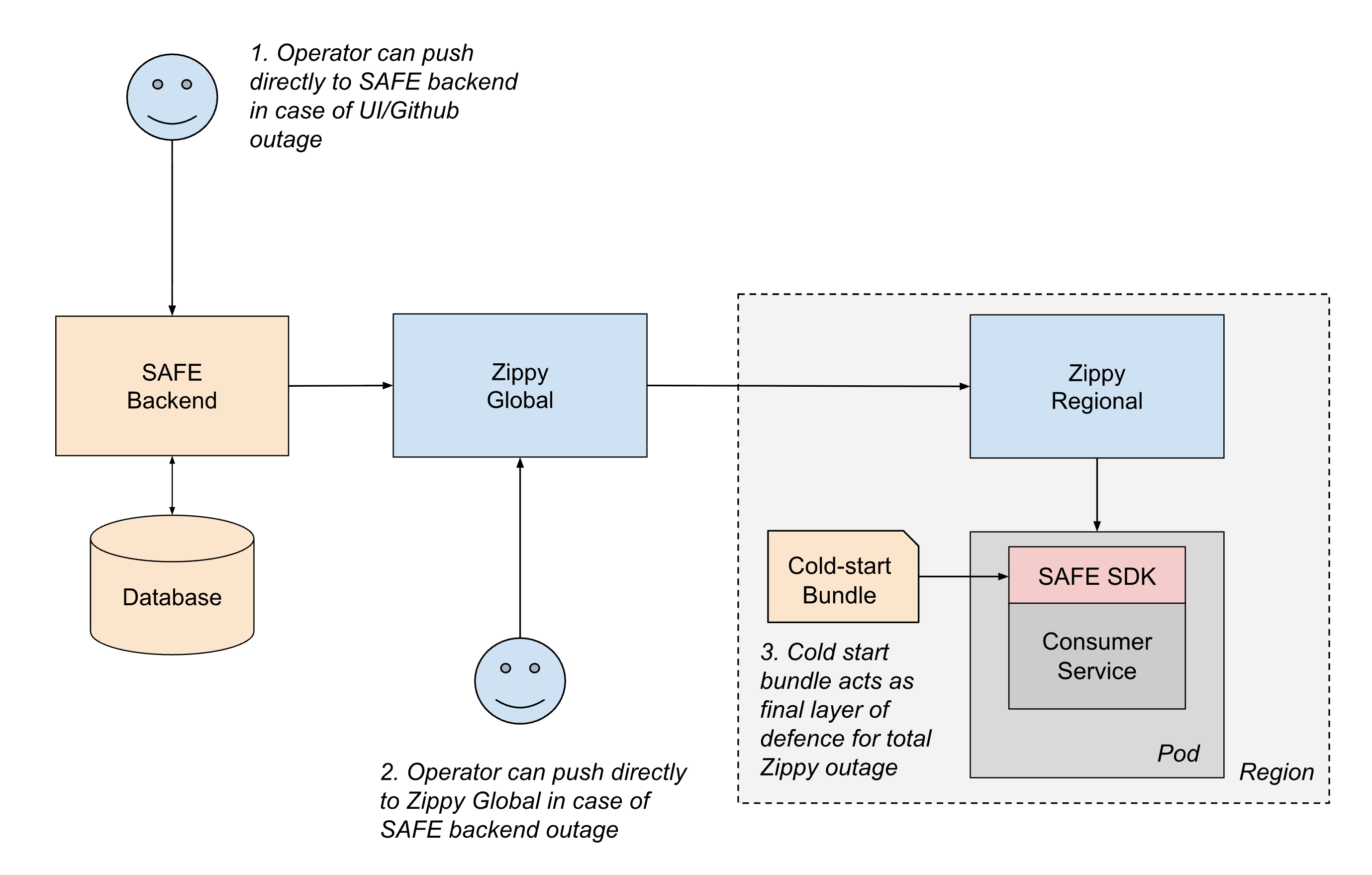
Para entregar de manera confiable la configuración a todos los servicios en Databricks, SAFE opera en conjunto con nuestra plataforma interna de entrega de configuración dinámica, Zippy. Una descripción detallada de la arquitectura de Zippy queda como tema para otra publicación, pero en resumen, Zippy utiliza una arquitectura global/regional de varios niveles y un almacenamiento de blobs por nube para transportar blobs de configuración arbitrarios desde una fuente central a (entre otras superficies) todos los pods de Kubernetes que se ejecutan en el Control Plane de Databricks.
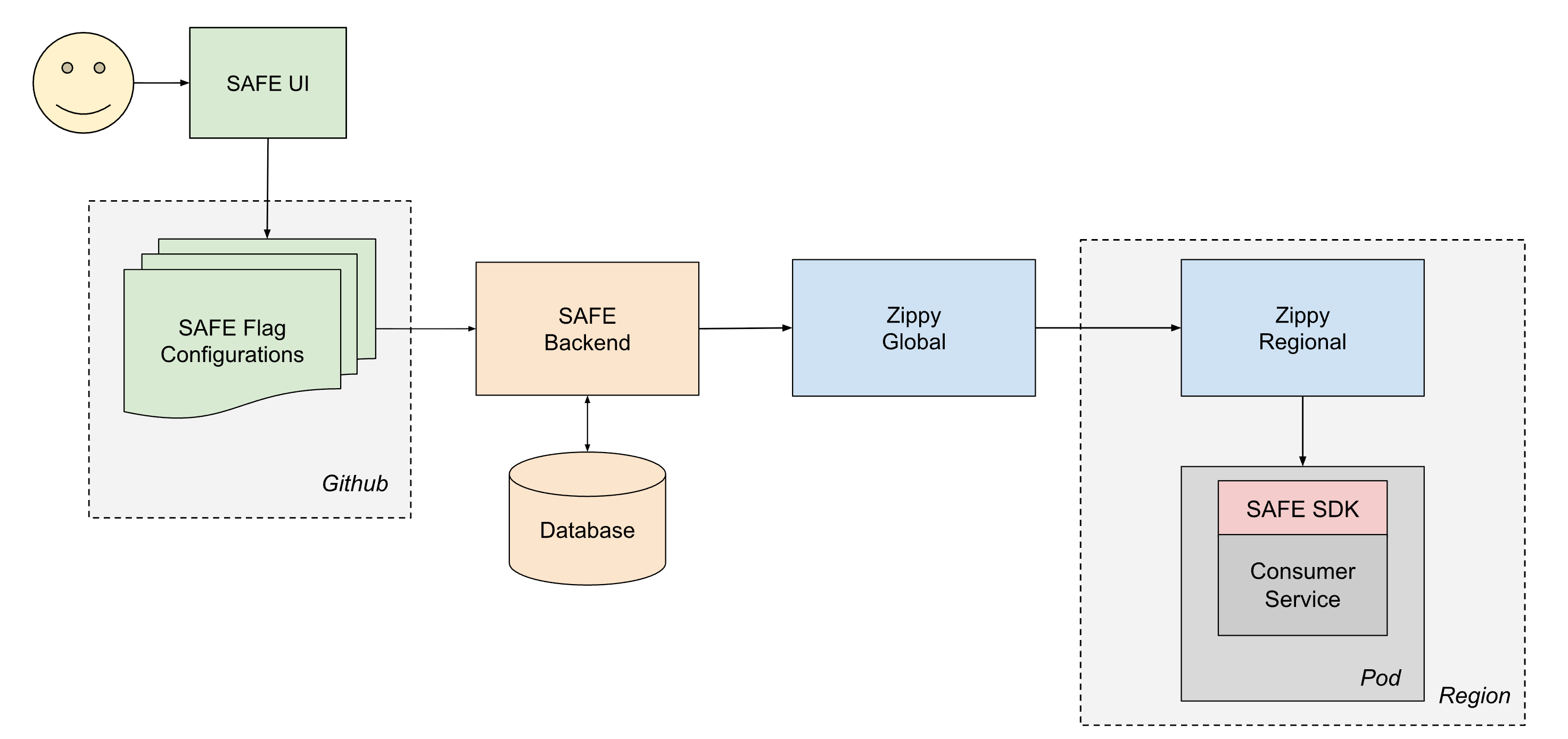
El ciclo de vida de un flag entregado es el siguiente:
- Un usuario crea y fusiona un PR en uno de sus archivos jsonnet de configuración de flags, que luego se fusiona en el monorepo de Databricks en Github.
- En aproximadamente 1 minuto, un trabajo de CI posterior a la fusión recoge el archivo modificado y lo envía al backend de SAFE, que posteriormente almacena una copia de la nueva configuración en una base de datos.
- Periódicamente (en intervalos de ~1 minuto), el backend de SAFE agrupa todas las configuraciones de flags de SAFE y las envía al backend de Zippy Global.
- Zippy Global distribuye estas configuraciones a cada una de sus instancias de Zippy Regional, en unos 30 segundos.
- El SDK de SAFE, que se ejecuta en cada pod de servicio, recibe periódicamente los nuevos paquetes de versiones mediante una combinación de entrega basada en push y pull.
- Una vez entregada, el SDK de SAFE puede utilizar la nueva configuración durante la evaluación.
De extremo a extremo, un cambio de flag normalmente se propaga a todos los servicios entre 3 y 5 minutos después de que se fusione un PR.
Pipeline de configuración de flags
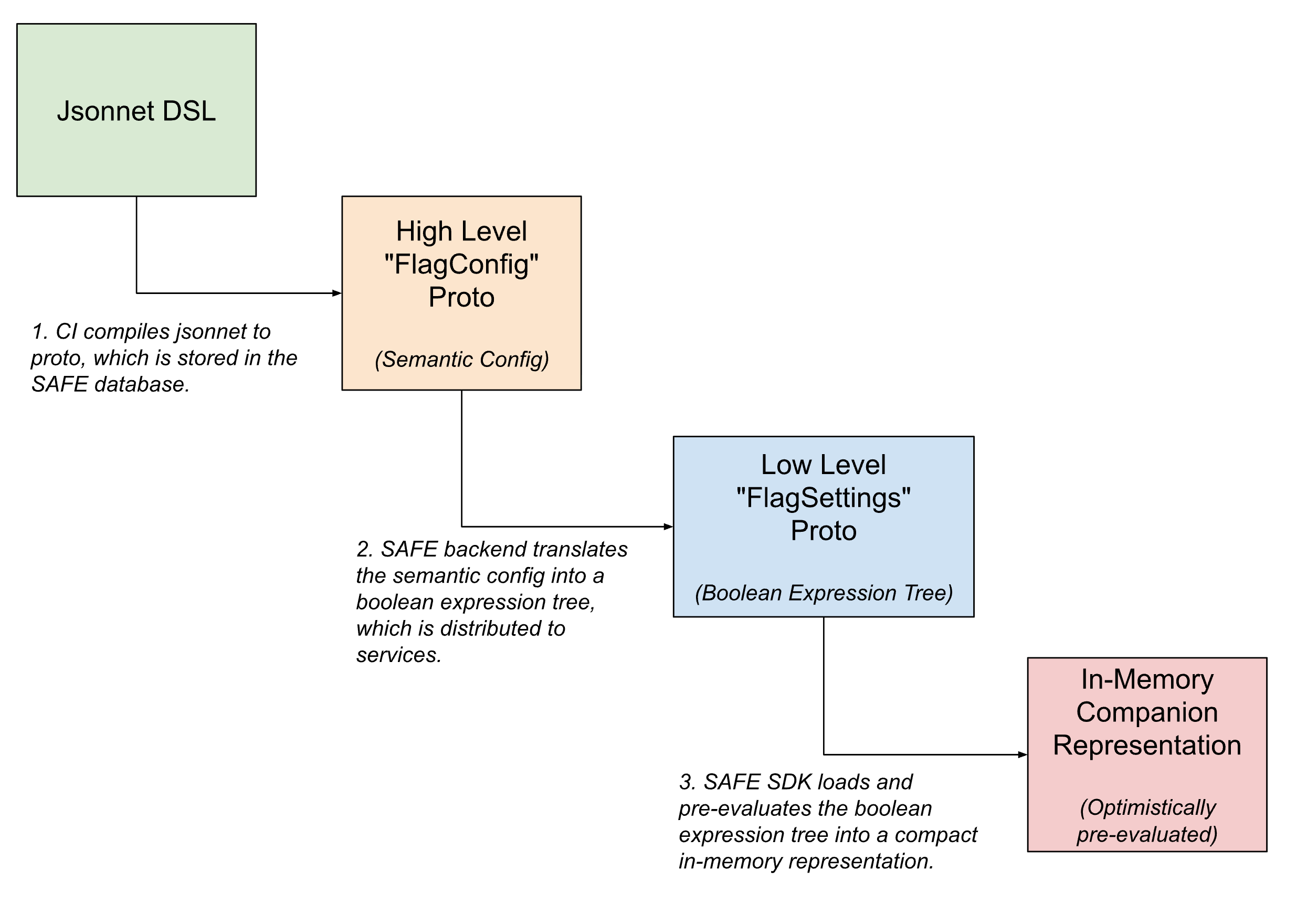
Dentro del pipeline de entrega de flags, las configuraciones de los flags adoptan múltiples formas, traduciéndose progresivamente desde configuraciones semánticas de alto nivel legibles por humanos a versiones compactas legibles por máquina a medida que el flag se acerca a su evaluación.
En la interfaz de usuario, los flags se definen usando Jsonnet con un DSL personalizado para permitir configuraciones de flags arbitrariamente complicadas. Este DSL ofrece facilidades para casos de uso comunes, como configurar un flag para su despliegue mediante una plantilla predefinida o para establecer anulaciones específicas en segmentos de tráfico.
Una vez registrado, este DSL se traduce a un equivalente interno de protobuf, que captura la intención semántica de la configuración. El backend de SAFE traduce a su vez esta configuración semántica en un árbol de expresiones booleanas. Una descripción protobuf de este árbol de expresiones booleanas se entrega al SDK de SAFE, que la carga en una representación en memoria aún más compacta de la configuración.
UI
La mayoría de los cambios de estado de los flags se inician desde una IU interna para gestionar los flags de SAFE. Esta IU permite a los usuarios crear, modificar y retirar flags a través de un flujo de trabajo que abstrae gran parte de la complejidad de Jsonnet para cambios sencillos, a la vez que proporciona acceso a la mayor parte de la potencia del DSL para casos de uso avanzados.
Una UI enriquecida también nos ha permitido exponer funcionalidades adicionales para mejorar la experiencia, como la capacidad de programar cambios de estado de los flags, soporte para verificaciones de estado posteriores a la fusión y herramientas de depuración para determinar cambios recientes de flags que afectaron a una región o servicio en particular.
Revisión de la configuración de flags
Todos los cambios de flags de SAFE se crean como PR normales de Github y se validan mediante un amplio conjunto de validadores previos a la fusión. Este conjunto de validadores ha crecido hasta abarcar docenas de comprobaciones individuales, a medida que hemos aprendido más sobre la mejor manera de protegernos contra cambios de flags potencialmente inseguros. Durante la introducción inicial de SAFE, las revisiones post-mortem de los incidentes que fueron causados o mitigados a través de un cambio de estado de un flag de SAFE sirvieron de base para muchas de estas comprobaciones. Ahora tenemos comprobaciones que, por ejemplo, requieren una revisión especializada en cambios de gran radio de impacto, exigen que se despliegue una versión binaria de servicio concreta antes de poder habilitar un flag, evitan patrones sutiles y comunes de configuración incorrecta, etcétera.
Los equipos también pueden definir sus propias comprobaciones previas a la fusión (pre-merge), específicas para un flag o un equipo, para hacer cumplir las invariantes de sus configuraciones.
Manejo de los modos de falla
Dado el papel fundamental de SAFE en la estabilidad del servicio, el sistema está diseñado con múltiples capas de resiliencia para garantizar un funcionamiento continuo incluso cuando fallan partes del pipeline de entrega.
El escenario de falla más común implica interrupciones en la ruta de entrega de la configuración. Si algo en la ruta de entrega provoca un error al actualizar las configuraciones, los servicios simplemente continúan operando con su última configuración conocida hasta que se restablece la ruta de entrega. Este enfoque de "falla estática" (fail static) garantiza que el comportamiento del servicio existente permanezca estable incluso durante las interrupciones de los sistemas ascendentes.
Para escenarios más graves, mantenemos múltiples mecanismos de respaldo (fallback):
- Entrega fuera de banda: si alguna parte de la ruta de push de CI o Github no está disponible, los operadores pueden enviar configuraciones directamente al backend de SAFE utilizando herramientas de emergencia.
- Conmutación por error regional: si el backend de SAFE o Zippy Global están caídos, los operadores pueden enviar configuraciones temporalmente directamente a las instancias regionales de Zippy. Los servicios también pueden sondear entre regiones para mitigar el impacto de una única interrupción de Zippy Regional.
- Paquetes de arranque en frío: para manejar los casos en que Zippy no está disponible durante el inicio del servicio, SAFE distribuye periódicamente paquetes de configuración a los servicios a través de un registro de artefactos. Si bien estos paquetes pueden estar desactualizados por algunas horas, proporcionan un respaldo suficiente para que los servicios se inicien de forma segura en lugar de bloquearse esperando la entrega en vivo.
Dentro del propio SDK de SAFE, el diseño defensivo garantiza que los errores de configuración tengan un radio de impacto limitado. Si la configuración de un flag en particular está mal formada, solo ese flag se ve afectado. El SDK también mantiene el contrato de no lanzar nunca excepciones, y siempre falla en estado abierto al valor predeterminado del código, por lo que los desarrolladores de aplicaciones no necesitan tratar la evaluación de flags como algo falible. El SDK también alerta inmediatamente a los ingenieros de guardia cuando se producen fallos de análisis de configuración o de evaluación. Debido a la madurez de SAFE y a la exhaustiva validación previa a la fusión, este tipo de fallos son ahora extremadamente infrecuentes en producción.
Este enfoque por capas para la resiliencia garantiza que SAFE se degrade gradualmente y minimiza el riesgo de que se convierta en un único punto de falla.
Lecciones aprendidas
Minimizar las dependencias y la reserva redundante por capas reduce la carga operativa. A pesar de estar desplegado y ser utilizado intensivamente en casi todas las superficies de computación de Databricks, la carga operativa de mantener SAFE ha sido bastante manejable. Añadir redundancias por capas, como el paquete de inicio en frío y el comportamiento de "falla estática" (fail static) del SDK, ha hecho que gran parte de la arquitectura de SAFE se autorrepare.
La experiencia del desarrollador es primordial. Escalar el "aspecto humano" de un sistema de flags robusto requirió un fuerte enfoque en la experiencia de usuario (UX). SAFE es un sistema de misión crítica, que se utiliza a menudo para mitigar incidentes. Por ello, crear una experiencia de usuario (UX) intuitiva para cambiar el estado de los flags durante las emergencias fue de gran ayuda. Adoptar una mentalidad centrada en el producto dio lugar a menos fricciones menores, menos confusión y, en última instancia, a un menor tiempo medio de recuperación (MTTR) de incidentes en toda la empresa.
Hacer de las "mejores prácticas" la ruta de menor fricción. Uno de nuestros mayores aprendizajes fue que no basta con documentar las mejores prácticas y esperar que los ingenieros las sigan. Los ingenieros tienen muchas prioridades contrapuestas al lanzar funciones. SAFE hace que el camino seguro sea el camino fácil: los despliegues graduales requieren menos esfuerzo y tienen más funciones de calidad de vida disponibles que los patrones de habilitación más riesgosos. Cuando el sistema incentiva un comportamiento más seguro, la plataforma puede impulsar a los ingenieros hacia una cultura de gestión responsable del cambio.
Estado actual y trabajo futuro
SAFE es ahora una plataforma interna madura dentro de Databricks y es ampliamente utilizada. Las inversiones realizadas en disponibilidad y experiencia del desarrollador rinden frutos, ya que vemos una reducción continua tanto en el tiempo medio de resolución como en el radio de impacto de los incidentes de producción mediante el uso de los flags de SAFE.
A medida que la superficie de productos de Databricks continúa expandiéndose, las primitivas de infraestructura subyacentes a esos productos se expanden tanto en amplitud como en complejidad. Como resultado, ha habido una importante inversión continua para garantizar que SAFE sea compatible con todos los lugares donde los ingenieros de Databricks escriben y despliegan código.
Si te interesa escalar infraestructura de misión crítica como esta, ¡explora las vacantes abiertas en Databricks!
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.