Cómo construir detección de fraude en tiempo real utilizando el modo en tiempo real de Spark y Lakebase
Modernizando Ecosistemas Financieros con Latencia de Subsegundo e Inteligencia de Datos Escalable
por Sixuan He y Navneeth Nair
- Los sistemas tradicionales de detección de fraude sufren de un retraso en la detección, basándose en el procesamiento por lotes lento o en motores de streaming complejos y acoplados que no logran bloquear las amenazas en tiempo real.\r\n- Spark Real-Time Mode y Lakebase permiten a los equipos de datos construir y automatizar fácilmente un flujo de trabajo de detección de fraude de extremo a extremo: procesando flujos de datos de alto rendimiento, ejecutando modelos de ML de baja latencia y sirviendo puntuaciones de fraude explicables, todo dentro de una plataforma unificada.\r\n- Las organizaciones pueden lograr una intervención en menos de un segundo en transacciones fraudulentas, reduciendo la complejidad operativa mientras protegen los ingresos y mantienen la confianza del cliente sin necesidad de infraestructura externa.
El fraude con tarjetas opera en segundos. Un número de tarjeta de crédito robado puede impulsar docenas de compras en minutos, y una vez que una transacción se liquida, recuperar esos fondos se vuelve exponencialmente más difícil. Según el Nilson Report, las instituciones financieras pierden un estimado de $33 mil millones anualmente debido a transacciones fraudulentas con tarjetas, y esa cifra solo crecerá a medida que el volumen de transacciones digitales se acelere.
El desafío no es detectar el fraude. La mayoría de las organizaciones ya tienen modelos de fraude capaces y reglas bien ajustadas. El desafío es detectarlo lo suficientemente rápido como para bloquear una transacción sospechosa antes de que se liquide, en la ventana de subsegundos entre la autorización y la liquidación, y hacerlo sin añadir un motor de streaming separado y especializado que duplique su complejidad operativa.
En este blog, presentamos un nuevo Acelerador de Soluciones: una implementación de referencia de código abierto que puede clonar y desplegar directamente en su entorno de Databricks. Demuestra cómo construir un sistema completo de detección de fraude de extremo a extremo, desde la ingesta de transacciones en bruto y la puntuación de ML en tiempo real hasta un panel de monitoreo en vivo construido con Databricks Apps, todo ello en la Plataforma Databricks. En su núcleo hay dos tecnologías: Real-Time Mode (RTM) para Apache Spark Structured Streaming en Databricks que ofrece procesamiento de flujo de menos de 300 ms, y Lakebase, una base de datos Postgres completamente administrada y sin servidor integrada en la Plataforma Databricks.
Velocidad vs. Simplicidad: La Compensación en Tiempo Real para la Detección de Fraude
La detección de fraude se encuentra en la intersección de dos demandas conflictivas.
Por un lado, está la velocidad. Una transacción fraudulenta debe ser identificada y bloqueada en cientos de milisegundos antes de que se liquide. Las sofisticadas redes de fraude prueban tarjetas robadas con microcompras rápidas, explotan anomalías geográficas y adaptan sus patrones más rápido de lo que las reglas estáticas pueden seguir.
Por otro lado, está la simplicidad. Los equipos de datos quieren construir, entrenar y desplegar modelos de fraude en una única plataforma, con gobernanza unificada, datos compartidos y un solo conjunto de herramientas. No quieren mantener una pila de streaming separada solo para la "última milla" de la puntuación en tiempo real.
Hasta ahora, los equipos se han visto obligados a elegir. Históricamente, cumplir con estos requisitos de latencia ultrabaja significaba introducir un motor especializado junto a Spark, como Apache Flink. El resultado es un patrón familiar: dos sistemas paralelos, datos duplicados, gobernanza dividida y equipos de ingeniería dedicando más tiempo a gestionar pipelines en lugar de mejorar los modelos de fraude. Con la introducción de RTM en Spark Structured Streaming, esa compensación ya no es necesaria.
RTM: Procesamiento en Subsegundos Sin la Sobrecarga Operativa de Múltiples Sistemas
RTM es una evolución del motor Spark Structured Streaming que permite el procesamiento de datos en subsegundos para aplicaciones operativas sensibles a la latencia, como la ingeniería de características.
En el lado de la velocidad, RTM procesa eventos en milisegundos y es hasta un 92% más rápido que Apache Flink en cargas de trabajo de transformación sin estado, enriquecimiento basado en uniones y agregación. Clientes como Coinbase ya están utilizando RTM para calcular más de 250 características de ML, y han logrado latencias de procesamiento P99 de menos de 100 ms.
En el lado de la simplicidad, RTM reside dentro del motor Spark que ya utiliza, no junto a él. Por lo tanto, se beneficiará inmediatamente de:
- Sin desviación lógica. Sus reglas de puntuación de fraude, ingeniería de características y preprocesamiento de ML existen una sola vez. El mismo código que se ejecuta en su pipeline de entrenamiento offline se ejecuta en su entorno de puntuación en tiempo real. Esto le permite llevar a producción las características más rápido y con mayor precisión.
- Una superficie operativa. Spark UI, monitoreo de clústeres, trabajos, alertas, etc. Todas las herramientas que ya utiliza se aplican. No hay una segunda rotación de guardia para el motor de streaming.
- Flexibilidad en costo vs. frescura. Cuando la frescura en subsegundos no vale el costo, volver a un disparador más lento es el mismo cambio de código de una línea en la otra dirección. No es necesario dedicar tiempo a ajustar manualmente el paralelismo u orquestar el apagado y reinicio de los recursos informáticos.
Como resultado, el equipo ya no necesita elegir; obtiene tanto la velocidad como la simplicidad, y las horas de ingeniería se dedican a ajustar las señales de fraude en lugar de gestionar la infraestructura.
Escenario de ejemplo: Bloqueo de fraude en transacciones con tarjeta de crédito
Para concretar esto, nuestro Acelerador de Soluciones implementa un sistema de detección de fraude en tiempo real para transacciones con tarjeta de crédito. Aquí está el escenario:
Las transacciones fluyen desde un sistema de mensajería (Kafka, Kinesis, etc.). Cada transacción lleva un ID de tarjeta, monto, categoría de comerciante, coordenadas geográficas y canal (en línea vs. punto de venta). El sistema debe evaluar cada transacción contra múltiples señales de fraude, asignar una puntuación de riesgo y enrutarla al resultado apropiado — aprobada, marcada para revisión o bloqueada — todo dentro de los 300 ms.
La arquitectura refleja cómo son los sistemas de fraude en producción en las principales instituciones financieras, con seguimiento de estado, enriquecimiento de características desde Lakebase como capa de servicio en línea, puntuación de ML y una aplicación en vivo de Databricks Apps para el monitoreo de analistas de fraude. La diferencia es que se ejecuta completamente en una sola plataforma.
Cómo lo Construimos
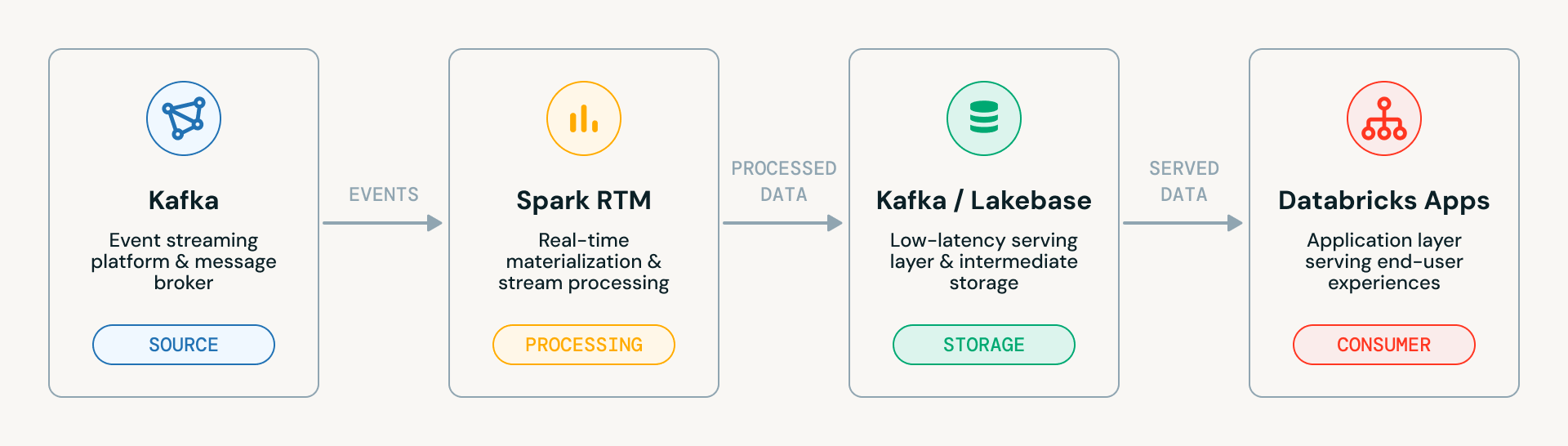
El acelerador pasa por cuatro etapas progresivas, cada una construyendo sobre la anterior. Aquí está el diagrama de arquitectura del sistema de alto nivel. Muestra el flujo de datos limpio a través de los cuatro componentes principales:
- Kafka (Fuente): La plataforma de streaming de eventos que ingesta eventos en bruto
- Spark RTM: El motor de materialización en tiempo real que procesa los datos de streaming
- Kafka / Lakebase: La capa intermedia donde aterrizan los datos procesados, ya sea de vuelta en Kafka o en Lakebase (la capa de servicio de baja latencia de Databricks)
- Databricks Apps: La capa de aplicación que sirve los datos finales a los usuarios finales
Vea el video de demostración completo de extremo a extremo a continuación, o continúe leyendo el paso a paso para aprender exactamente cómo lo construimos. Comience con el Inicio Rápido a continuación (sin dependencias externas) y agregue complejidad a medida que avanza.
Paso 1: Vea Real-Time Mode en Acción
Para las instituciones financieras que evalúan la infraestructura de fraude en tiempo real, un rápido tiempo de valor es crítico. El notebook de Inicio Rápido permite a su equipo experimentar Real-Time Mode inmediatamente, y validar los puntos de referencia de latencia clave y la idoneidad de la plataforma en menos de cinco minutos, antes de cualquier compromiso de producción. No es necesario conectarse a Kafka ni configurar nada externo. Genera transacciones sintéticas utilizando la fuente de tasa incorporada de Spark, aplica la lógica de puntuación de fraude y muestra los resultados en vivo en el notebook. Este es su "hola mundo" para Real-Time Mode. Ejecútelo, vea los números de latencia y valide que su clúster esté configurado correctamente.
Paso 2: Construya el Pipeline de Detección de Fraude
Con Real-Time Mode validado, el siguiente notebook construye un pipeline de detección de fraude de grado de producción que refleja cómo las principales instituciones financieras operacionalizan la toma de decisiones de fraude en tiempo real. Procesa transacciones de extremo a extremo, entregando la puntuación explicable requerida tanto por los equipos de operaciones de fraude como por los de cumplimiento. Las transacciones fluyen desde Kafka a través de cinco etapas, cada una ejecutándose continuamente, cada una añadiendo inteligencia:
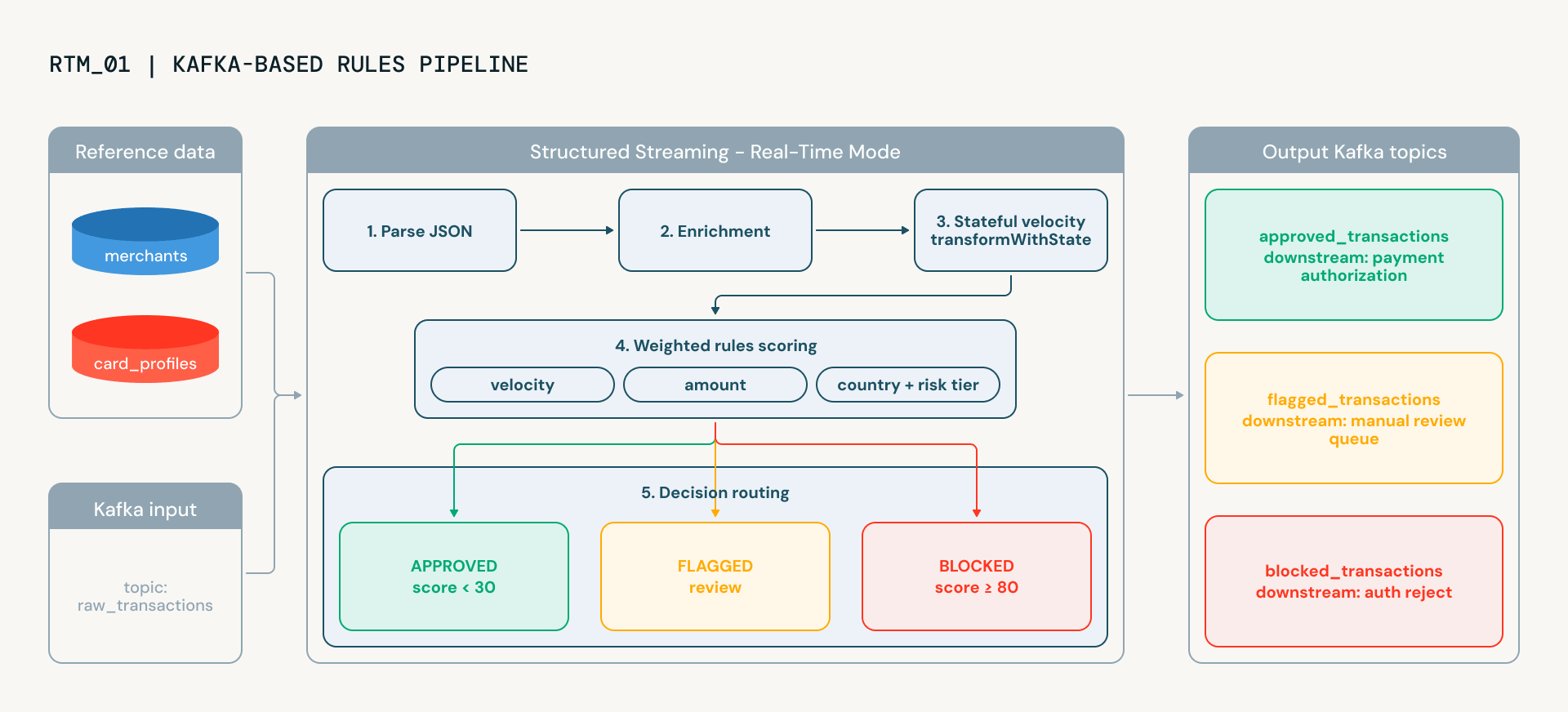
- Análisis toma el JSON sin procesar de Kafka y lo estructura en columnas tipadas
- Seguimiento de velocidad es donde las cosas se ponen interesantes. Usando transformWithState (el potente operador de Spark para construir transformaciones con estado arbitrarias o personalizadas), la pipeline mantiene el estado por tarjeta a través del flujo: ¿cuántas transacciones ha realizado esta tarjeta en los últimos 60 segundos? Una tarjeta que de repente realiza cinco transacciones en un minuto está mostrando un comportamiento clásico de prueba de tarjetas. El estado caduca automáticamente a través de TTL, por lo que no hay un crecimiento ilimitado de la memoria ni limpieza manual.
- Enriquecimiento añade contexto de los perfiles de riesgo del comerciante y los datos del titular de la tarjeta. ¿Es esta una categoría de comerciante de alto riesgo (tarjetas de regalo, joyas)? ¿El titular de la tarjeta normalmente gasta $50 o $5,000? Estas búsquedas utilizan diccionarios de Python en lugar de uniones de difusión (broadcast joins), evitando la sobrecarga de BroadcastExchange que puede añadir latencia en las pipelines de streaming.
- Puntuación combina cinco señales de fraude ponderadas: velocidad, anomalía geográfica, desviación de cantidad, riesgo de categoría de comerciante y riesgo de país, en una única puntuación de 0 a 100. Cada señal es calculada por una UDF dedicada, y los pesos son configurables. El resultado es una puntuación explicable: puedes ver exactamente qué señales contribuyeron y en qué medida.
- Enrutamiento toma la decisión final. Las transacciones se clasifican como aprobadas, marcadas para revisión manual o bloqueadas automáticamente, y se escriben en el tema de salida de Kafka apropiado.
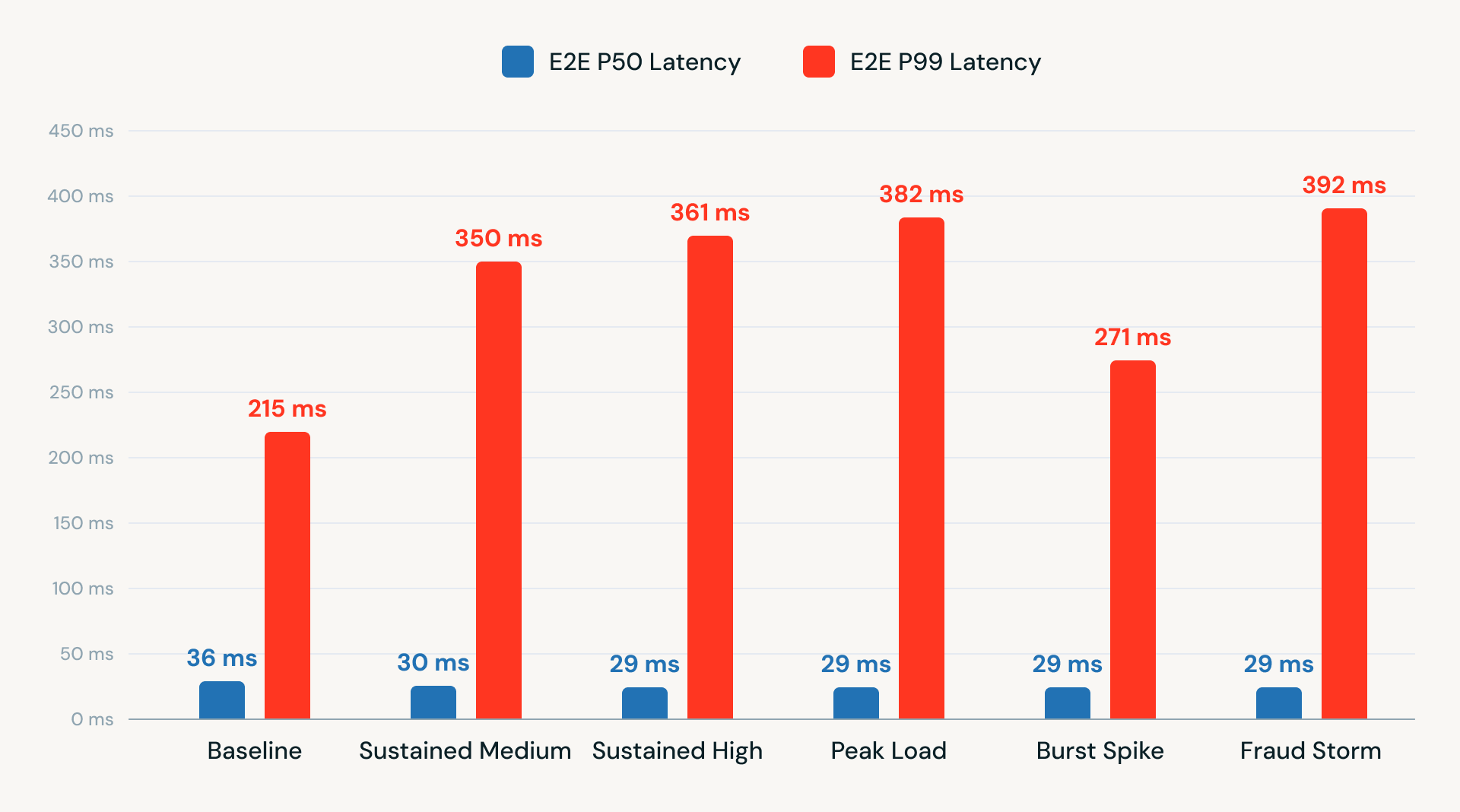
También realizamos pruebas de latencia de extremo a extremo en diferentes niveles de TPS. Los resultados mostraron un rendimiento consistente, con una latencia P50 inferior a 40 ms y una latencia P99 que osciló entre 215 y 392 ms. Estos resultados demuestran que una arquitectura Kafka-in, Kafka-out que utiliza RTM en la plataforma Databricks puede ofrecer un rendimiento de baja latencia y listo para producción sin depender de APIs externas o infraestructura adicional.
Paso 3: Actualización a Machine Learning
La detección de fraude basada en reglas estáticas crea sistemas fáciles de auditar pero frágiles. Los umbrales son arbitrarios: ¿por qué cinco transacciones en 60 segundos son "sospechosas"? ¿Por qué no cuatro o seis? Y debido a que no hay aprendizaje, el sistema nunca mejora a partir de decisiones pasadas.
El notebook avanzado actualiza esta lógica a un modelo de machine learning gobernado. Esta transición permite a los equipos de riesgo reducir los falsos positivos, adaptarse a los patrones de fraude emergentes y demostrar el linaje del modelo a los reguladores a través del seguimiento de experimentos y el versionado integrados de MLflow. Esto introduce dos nuevas capacidades de la plataforma:
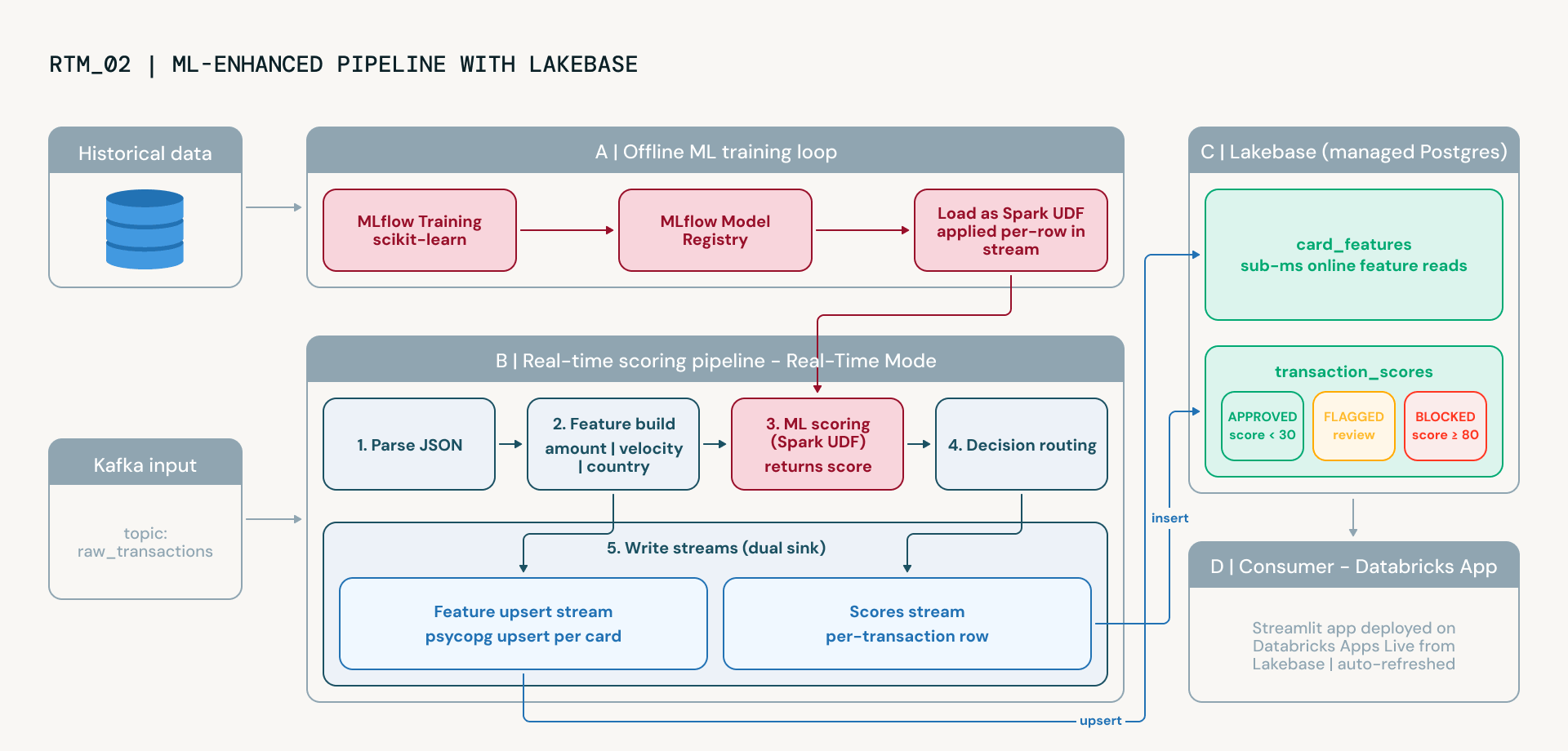
- Lakebase como capa de servicio en línea. Lakebase es el servicio PostgreSQL gestionado de Databricks. Usando el sink foreach de Spark Structured Streaming con un LakebaseFeatureWriter personalizado, la pipeline transmite continuamente características por tarjeta, patrones de velocidad, montos promedio de transacciones, dispersión geográfica, todo directamente a las tablas de Lakebase con semántica de upsert. Lakebase proporciona lecturas en submilisegundos, lo que lo hace ideal para el servicio de características en tiempo real sin gestionar infraestructura externa.
- MLflow para el entrenamiento y servicio de modelos. Un clasificador RandomForest se entrena con datos históricos etiquetados utilizando MLflow para el seguimiento de experimentos y el versionado de modelos. El modelo entrenado se carga como una UDF de Spark y se aplica a cada transacción en la pipeline de streaming. Combinado con características en vivo de Lakebase, el modelo aprende relaciones no lineales entre señales que las reglas estáticas pasan por alto, y mejora con el tiempo a medida que nuevos datos etiquetados están disponibles.
Paso 4: Monitorización de todo en tiempo real
La visibilidad operativa es innegociable para los equipos de fraude que trabajan bajo obligaciones de informes regulatorios en tiempo real. Para hacer el sistema observable, el acelerador incluye una Databricks Apps basada en Streamlit que lee directamente de Lakebase para proporcionar un panel de control de monitorización de fraude en vivo. Esto proporciona a los analistas de fraude y a los gestores de riesgo una vista en vivo y auditable de cada decisión que toma el sistema, sin requerir soporte de ingeniería para acceder a ella. Los usuarios pueden rastrear el total de transacciones puntuadas, los desgloses de decisiones (aprobadas, marcadas, bloqueadas), las puntuaciones de fraude recientes con detalles a nivel de tarjeta y las distribuciones de probabilidad de fraude, todo ello con actualización automática cada 10 segundos. Esta es la capa operativa que hace que el sistema sea utilizable en la práctica, no solo funcionalmente técnico.
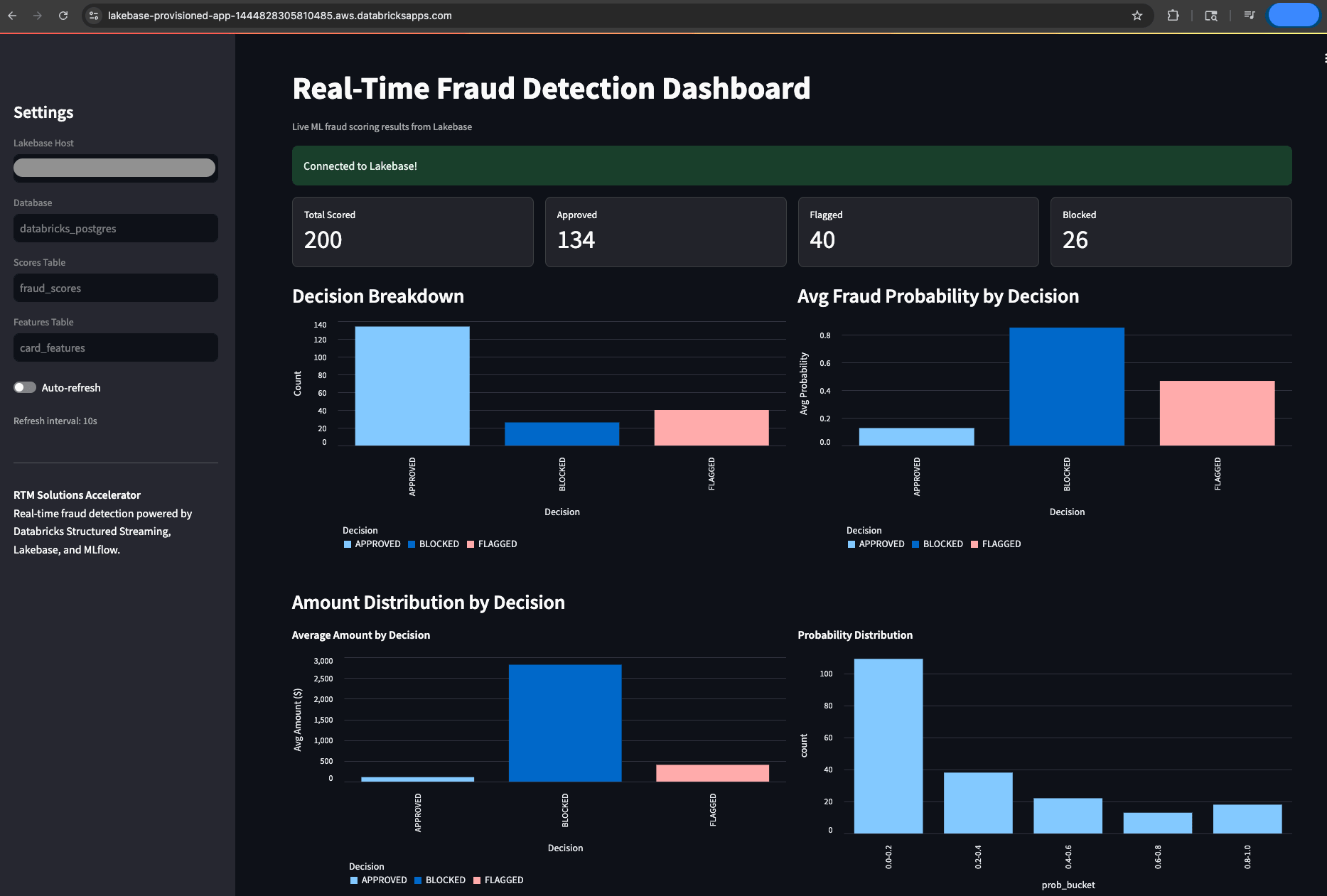
La clave es que todo se ejecuta en una única plataforma. El mismo motor de Spark que impulsa su ETL por lotes y el entrenamiento de ML ahora maneja el streaming de menos de 300 ms. Unity Catalog ahora gobierna tanto sus tablas de streaming como sus datos de entrenamiento. MLflow ahora rastrea sus modelos de fraude, ya sea que se utilicen en inferencia por lotes o en puntuación en tiempo real. No hay brecha de integración, ni división de gobernanza, ni una segunda pila que mantener porque todo está en la misma plataforma.
Primeros pasos
Este Acelerador de Soluciones está diseñado para ser progresivamente adaptable: empiece de forma sencilla y añada complejidad si es necesario.
- Inicio rápido: Clone el repositorio, abra `notebooks/RTM_00_Quick_Start.py` y ejecútelo en un clúster configurado para el modo en tiempo real. Verá a RTM procesar transacciones sintéticas con una latencia inferior a 300 ms, sin Kafka ni configuración externa.
- Pipeline completa: Configure un ámbito de secretos de Kafka con sus direcciones de broker, luego ejecute `notebooks/RTM_01_Introduction_fraud_detection.py`. Esto le proporciona la pipeline completa de análisis-enriquecimiento-puntuación-enrutamiento que lee y escribe en Kafka. Al ejecutarlo, verá las transacciones fluir por las cinco etapas y las decisiones aterrizar en el tema de salida de aprobadas, marcadas y bloqueadas. Esto le proporciona la pipeline completa de análisis-enriquecimiento-puntuación-enrutamiento que lee y escribe en Kafka.
- Puntuación con ML: Cree una instancia de Lakebase, luego ejecute `notebooks/RTM_02_Advanced_fraud_detection_ml.py`. Esto añade el streaming de características a Lakebase, el entrenamiento de modelos con MLflow y la puntuación basada en ML en la pipeline. Una vez completado, MLflow registrará el modelo entrenado y la pipeline comenzará a emitir puntuaciones de fraude derivadas de ML en lugar de los pesos basados en reglas.
- Aplicación de monitorización en vivo: Despliegue la aplicación Streamlit desde `apps/` como una Databricks Apps con una vinculación de recursos de Lakebase. La aplicación se conecta automáticamente y comienza a mostrar las puntuaciones de fraude en vivo.
La ruta más rápida es con Databricks Asset Bundles — simplemente clone, despliegue y ejecute:
El bundle aprovisiona automáticamente un clúster correctamente configurado y ejecuta todos los notebooks en secuencia.
Más información sobre el modo en tiempo real
El modo en tiempo real (Real-Time Mode) está disponible de forma general en Databricks en AWS, Azure y GCP. El Acelerador de Soluciones de detección de fraude es de código abierto y está listo para ser desplegado.
- Obtenga el Acelerador de Soluciones en GitHub
- Documentación del modo en tiempo real
- Anuncio de disponibilidad general del modo en tiempo real
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.