Lakeflow: Una nueva era de ingeniería de datos agéntica
La base unificada de datos en tiempo real en la que tu empresa puede confiar
por Bilal Aslam, Ray Zhu, Manish Dalwadi, Saad Ansari y Giselle Goicochea
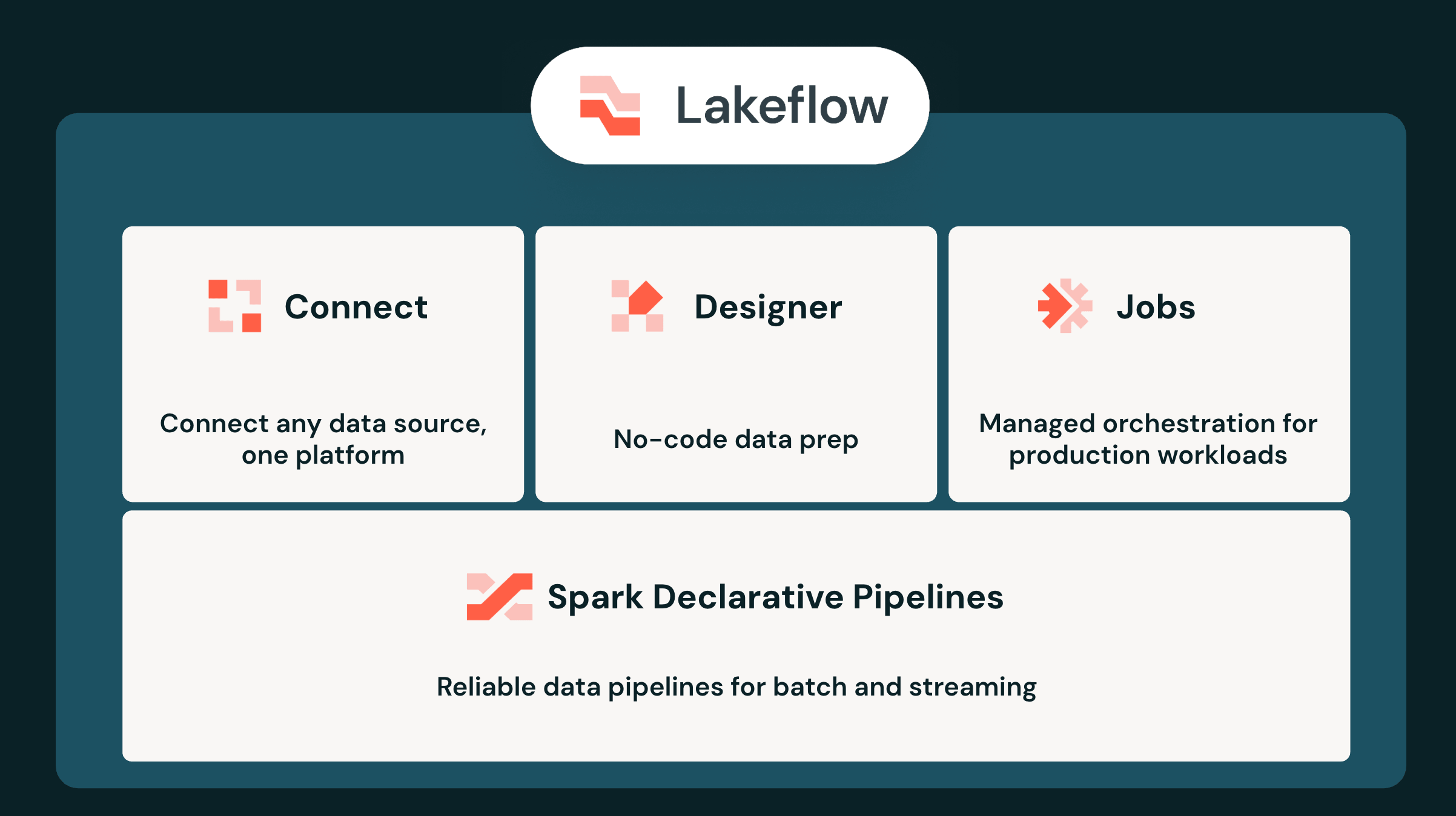
- Base unificada para la IA agéntica: Lakeflow unifica la ingesta, la transformación y la orquestación bajo Unity Catalog, lo que elimina la brecha causada por la proliferación de herramientas y ofrece a los agentes de IA una única fuente de contexto confiable y en tiempo real.
- Ingesta y streaming de alto rendimiento: conéctate a más de 100 fuentes de datos empresariales con Lakeflow Connect, transmite datos de eventos de gran volumen a través de múltiples interfaces en Zerobus Ingest y obtén una latencia de milisegundos con Real-Time Mode para Spark Declarative Pipelines.
- Desarrollo y operaciones agénticas: crea pipelines de forma visual con Lakeflow Designer, acelera la creación con Genie Code, reduce la carga operativa con Genie ZeroOps y consolida los orquestadores heredados con Lakeflow Jobs.
Todos los análisis, AI y aplicaciones comienzan con los datos. Durante las últimas décadas, las herramientas de ingeniería de datos han proliferado en una variedad de casos de uso y perfiles de usuario. Como resultado, la mayoría de las empresas terminan con una infraestructura de datos muy compleja y fragmentada que es difícil de integrar, mantener o gobernar. Con la AI impulsando todos los datos y a los profesionales de la AI, se ejercerá aún más presión sobre estas frágiles infraestructuras de datos.
Por eso nos propusimos crear Databricks Lakeflow, una plataforma unificada para toda la ingeniería de datos, desde la ingesta hasta la transformación y la orquestación. Todas las capacidades de Lakeflow están completamente integradas y gobernadas de manera centralizada por Unity Catalog. En la era de los agentes, esta arquitectura unificada ofrece ventajas significativas, lo que permite a los agentes no solo crear sino también operar sus canalizaciones de datos. Hoy, en el Data + AI Summit, anunciamos la próxima gran evolución de Databricks Lakeflow.
Genie Code y Lakeflow Designer: desarrollo de canalizaciones basado en agentes
Genie Code ahora está profundamente integrado en cada aspecto de la experiencia de usuario de Lakeflow. Puede usar Genie Code para crear conectores de ingesta, compilar canalizaciones en Python y SQL, y desarrollar trabajos con tareas, desencadenadores y dependencias. Todo esto es posible gracias a la infraestructura unificada de ingeniería de datos, que proporciona a Genie Code un contexto completo de extremo a extremo en sus cargas de trabajo de ingesta, transformación y orquestación.
Ahora disponible para el público general, Lakeflow Designer democratiza la ingeniería de datos en toda la empresa. Esta interfaz visual, sin código y potenciada por AI, permite a los equipos crear canalizaciones mediante un lienzo de arrastrar y soltar e indicaciones en lenguaje natural. Los analistas de negocios y los usuarios no técnicos pueden crear canalizaciones ETL listas para producción sin escribir código. Cada Flow visual creado en Designer se ejecuta de forma nativa en un Spark Declarative Pipeline listo para producción, lo que garantiza una pérdida de traducción cero sin traspasos complejos. Los ingenieros de datos pueden revisar y perfeccionar fácilmente este código directamente en el lugar, sin cambiar de contexto ni reescribir la lógica.
Genie ZeroOps: Ponga las operaciones de datos y AI en piloto automático
Anunciado hoy, Genie ZeroOps ayuda a los equipos de datos a operar activos de datos y AI en producción. Genie ZeroOps es un agente de AI en segundo plano diseñado específicamente para monitorear y gestionar activos de datos y AI. ZeroOps detecta fallas y realiza análisis de causa raíz para identificar qué salió mal utilizando métricas de calidad de datos, registros de errores y datos de linaje de Unity Catalog. Además, genera propuestas de solución y las valida en un entorno de sandbox seguro y aislado gobernado por Unity Catalog. La aplicación de una solución se realiza con supervisión humana, por lo que Genie ZeroOps hace el trabajo pesado y usted mantiene el control. Al igual que el desarrollo basado en agentes, la funcionalidad de Genie ZeroOps solo es posible gracias al conocimiento completo del contexto y al gobierno de extremo a extremo que permite una infraestructura de datos unificada con Lakeflow.
Lakeflow Connect: Un ecosistema de rápido crecimiento con más de 100 conectores integrados
Las canalizaciones automatizadas solo son tan valiosas como los datos que fluyen a través de ellas. Para construir una "memoria empresarial" completa y fundamentar agentes de AI como Databricks Genie, necesita un acceso sin interrupciones al contexto gobernado más reciente que abarque todas las áreas de su negocio. Lakeflow Connect simplifica este proceso al ingerir de forma incremental datos nuevos desde una lista en constante crecimiento de sistemas empresariales directamente en tablas Delta gobernadas por Unity Catalog.
Hoy anunciamos que Lakeflow Connect se está expandiendo para admitir más de 100 conectores nativos y gestionados en aplicaciones empresariales, bases de datos, fuentes de archivos y almacenamiento en la nube. Ahora puede eliminar las frágiles herramientas de terceros y ejecutar canalizaciones de ingesta optimizadas para los casos de uso que los clientes más necesitan:
- Gestión del conocimiento empresarial: Unifique los datos comerciales de Jira (Beta), GitHub (Beta) y Confluence (GA) junto con documentos no estructurados, contratos y PDFs de SharePoint (GA), Google Drive (Beta) y Outlook (Beta). Potencie aplicaciones de AI conscientes del contexto, agentes de soporte y procesamiento inteligente de documentos en una única base.
- MarTech: Ingiera datos de campañas y clientes directamente desde Meta Ads (Beta), TikTok Ads (Beta), Google Ads (Beta) y HubSpot (GA) para impulsar la personalización en tiempo real.
- Operaciones de IT y seguridad: Centralice los registros y la telemetría para un análisis SIEM sólido.
- Captura basada en consultas para todos los conectores de bases de datos y fuentes de Lakehouse Federation (GA): Consulte la base de datos directamente para la captura de cambios sin necesidad de analizar registros.
Para organizaciones con sistemas especializados o propietarios, los Community Connectors (Beta) proporcionan una solución de código abierto creada en Databricks. Implemente un conector preconstruido de la comunidad o cree el suyo propio para compartirlo en toda su organización o en el ecosistema en general.
Panasonic utilizó Lakeflow Connect para unificar datos de SAP, Workday y SharePoint, reemplazando un ETL heredado y frágil con una única plataforma para inteligencia gobernada en tiempo real.
«Al pasar de una infraestructura ETL heredada y rígida a la plataforma Databricks, nuestros equipos de BI ahora pueden descubrir y acceder fácilmente a datos críticos, lo que reduce los tiempos de actualización de Power BI en un 50%. Estamos convirtiendo datos externos e inconsistentes en activos confiables y de nivel de producción que revelan nuevas perspectivas comerciales y fortalecen la ventaja competitiva de Panasonic».—Jerry Deng, director de BI, Panasonic
También estamos facilitando que las organizaciones reduzcan de forma permanente el TCO de la ingesta de alto volumen con el nivel gratuito de Lakeflow Connect. Los clientes reciben automáticamente 100 DBUs gratuitas al día, lo que admite hasta 100 millones de registros diarios en conectores de bases de datos y SaaS gestionados populares.
Zerobus Ingest: Ingesta sin Kafka para sus productores de datos
Zerobus Ingest está cambiando la forma en que las organizaciones manejan los datos de eventos de alto volumen, sin necesidad de un bus de mensajes. Con escrituras casi en tiempo real en menos de 5 segundos y un alto rendimiento de hasta 100 MB/s (más de 10 GB/s por tabla), Zerobus entrega datos directamente a su plataforma a escala.
Sin embargo, el rendimiento solo importa si sus productores pueden conectarse sin fricciones. Una migración debería ser tan simple como un cambio de configuración. Desde que alcanzó la disponibilidad general (General Availability) a principios de este año, Zerobus se ha expandido para llegar a sus productores de datos donde ya operan:
- APIs compatibles con Kafka (Beta): Sus productores de Kafka existentes envían datos directamente a Databricks, sin necesidad de realizar cambios en el código.
- APIs gRPC y REST (GA): Transmisiones gRPC persistentes para aplicaciones de alto rendimiento, o APIs REST sin estado para webhooks y funciones sin servidor.
- Ecosistema de SDK (GA): Los SDK listos para producción para Python, Java, Rust, Go y TypeScript facilitan la integración de Zerobus directamente en sus aplicaciones personalizadas.
- OpenTelemetry (vista previa pública): Envíe métricas, trazas y registros directamente al lakehouse con solo un cambio de configuración.
Esta flexibilidad de múltiples interfaces proporciona un puente directo y de baja latencia a la nube para empresas globales. Por ejemplo, Meta ha estado utilizando Zerobus Ingest para conectar sus centros de datos locales (on-premises) con la nube, lo que permite un desarrollo rápido de soluciones basadas en datos a escala.
“Redujimos la latencia de nuestro pipeline de extremo a extremo a menos de un minuto con Zerobus Ingest y Spark Declarative Pipelines, lo que permite acelerar el tiempo de obtención de valor.”—Srikanth Sakhamuri, Líder de Ingeniería de Datos, Meta
Una vez que los datos llegan a las tablas Delta gobernadas por Unity Catalog, están disponibles al instante para las herramientas de AI y BI descendentes como Databricks Genie. Como parte de una pila analítica en tiempo real de extremo a extremo, Zerobus ingiere los datos y los procesa utilizando el Real-Time Mode en Apache Spark™ Declarative Pipelines (SDP), los transforma, y Lakehouse//RT, un nuevo tipo de data warehouse que se ejecuta en un motor nativo en tiempo real, los sirve con un rendimiento a escala de milisegundos.
Spark Declarative Pipelines: procesamiento por lotes y streaming, SQL y Python, y ahora en tiempo real
Lograr un streaming de ultra-baja latencia tradicionalmente ha obligado a los equipos de datos a gestionar arquitecturas complejas y fragmentadas, lo que a menudo requiere el mantenimiento de un segundo motor especializado, como Apache Flink, junto con Spark. Databricks resolvió inicialmente esta complejidad de doble motor al introducir el Real-Time Mode (RTM) para Spark Structured Streaming. Al pasar del microprocesamiento por lotes periódico al procesamiento de flujo continuo, el RTM actualmente impulsa los pipelines de marcas globales como Coinbase, DraftKings y MakeMyTrip.
Ahora, llevamos esa misma potencia a nuestro producto de ETL unificado: el Real-Time Mode (RTM) para Spark Declarative Pipelines ya está en Public Preview. El RTM para SDP logra latencias de extremo a extremo de tan solo 5 milisegundos sin la complejidad ni el costo de gestionar motores independientes. Disponible tanto en computación clásica como serverless, ofrece streaming de ultra-baja latencia junto con los beneficios operativos de Spark Declarative Pipelines: ejecución sin versiones, actualizaciones automáticas de infraestructura y mantenimiento con un tiempo de inactividad mínimo o nulo.
A continuación, haremos que las API declarativas de Spark Declarative Pipelines —incluidas Append, Auto CDC, incremental Replace Where y Materialized View— estén disponibles en toda la plataforma de Databricks. Esto significa que los usuarios pueden aprovechar el procesamiento de datos incremental directamente desde el producto, el tipo de computación y la interfaz de usuario que ya conocen. Todas estas API ya están disponibles en Databricks SQL y estarán disponibles en Notebooks serverless y Lakeflow Designer en las próximas semanas.
Lakeflow Jobs: ahora con más de 50 integraciones
La orquestación no debería ser la parte más difícil de gestionar tu pipeline de datos. Ya sea que estés ejecutando DAG de producción complejos, programando tareas o activando agentes de AI, Lakeflow Jobs es el motor de orquestación nativo de Databricks que se encarga de todas estas tareas. Al llevar la orquestación gestionada y la observabilidad de extremo a extremo a cada capa del ciclo de vida de los datos, los equipos de datos están consolidando los orquestadores heredados, como Apache Airflow, en una plataforma única y unificada.
Orquestación consciente de los datos y del contexto
Cada programación de cron es solo una suposición de cuándo estarán listos los datos. Lakeflow Jobs te permite dejar de adivinar y comenzar a activar pipelines en función de la disponibilidad real de los datos. Usando un lenguaje sencillo, puedes pedirle a Genie que escriba los activadores SQL que definen qué significa "listo" en tus datos. Tu trabajo se ejecuta tan pronto como se cumplen las condiciones, respetando tus contratos de datos y garantizando que nunca proceses datos desactualizados.
“Con Lakeflow Jobs, pudimos acceder a datos a los que las tecnologías heredadas no podían llegar, lo que nos permitió generar información comercial más profunda y confiable."—Sachin Wadhwa, Director de Arquitectura y Plataformas de Datos, The Rank Group
Orquestación universal para cualquier cosa y en cualquier lugar
Para los clientes con flujos de trabajo de datos fuera de Databricks, Lakeflow Jobs ofrece External Orchestration para ampliar de forma nativa tu alcance a sistemas externos sin necesidad de reconstruir integraciones desde cero. Al utilizar un marco de trabajo de operadores abierto, puedes activar sin problemas trabajos de Snowflake, ejecutar API REST personalizadas o gestionar alertas de Slack y PagerDuty. La computación se suspende de manera inteligente mientras se esperan condiciones externas que podrían tardar horas en cumplirse. Estamos publicando más de 40 ejemplos de operadores en GitHub y añadiremos docenas de integraciones gestionadas en los próximos trimestres. Además, cada credencial fluye a través de Unity Catalog y cuenta con un historial de auditoría completo.
Primeros pasos con Lakeflow
Lakeflow proporciona la base de datos unificada que necesitas para crear aplicaciones de AI agénticas y confiables. Para profundizar en las configuraciones técnicas y ver estas nuevas funciones en acción, explora nuestros tutoriales prácticos o revisa nuestra documentación técnica para comenzar con tu próximo proyecto.
¿Listo para empezar a crear? Prueba Databricks gratis para experimentar Lakeflow hoy mismo.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.