La latencia baja a menos de un segundo en Apache Spark Structured Streaming
Mejora de la gestión de "offsets" en el Proyecto Lightspeed
por Jerry Peng, Pranav Anand, Sourav Gulati, Karthik Ramasamy, Michael Armbrust y Matei Zaharia
Apache Spark Structured Streaming es la principal plataforma de procesamiento de streams de código abierto. También es la tecnología principal que impulsa el streaming en la plataforma Databricks Lakehouse y proporciona una API unificada para el procesamiento por lotes y de streams. A medida que la adopción del streaming crece rápidamente, diversas aplicaciones quieren aprovecharlo para la toma de decisiones en tiempo real. Algunas de estas aplicaciones, especialmente las de naturaleza operativa, exigen una latencia más baja. Aunque el diseño de Spark permite un alto rendimiento y facilidad de uso a un costo menor, no se ha optimizado para una latencia por debajo del segundo.
En este blog, nos centraremos en las mejoras que hemos realizado en la gestión de offsets para reducir la latencia de procesamiento inherente de Structured Streaming. Estas mejoras se dirigen principalmente a los casos de uso operativos, como el monitoreo y las alertas en tiempo real, que son simples y sin estado.
La evaluación exhaustiva de estas mejoras indica que la latencia ha mejorado entre un 68 y un 75 %, o hasta 3 veces, de 700-900 ms a 150-250 ms para rendimientos de 100 000 eventos/s, 500 000 eventos/s y 1 millón de eventos/s. Structured Streaming ahora puede alcanzar latencias inferiores a 250 ms, lo que cumple con los requisitos de SLA para un gran porcentaje de las cargas de trabajo operativas.
Este artículo asume que el lector tiene un conocimiento básico de Spark Structured Streaming. Consulte la siguiente documentación para obtener más información:
https://www.databricks.com/spark/getting-started-with-apache-spark/streaming
https://docs.databricks.com/structured-streaming/index.html
https://www.databricks.com/glossary/what-is-structured-streaming
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Motivación
Apache Spark Structured Streaming es un motor de procesamiento de flujos distribuidos construido sobre el motor Apache Spark SQL. Proporciona una API que permite a los desarrolladores procesar flujos de datos escribiendo consultas de streaming de la misma manera que las consultas por lotes, lo que facilita el análisis y la prueba de las aplicaciones de streaming. Según las descargas de Maven, Structured Streaming es el motor de streaming distribuido de código abierto más utilizado en la actualidad. Una de las principales razones de su popularidad es el rendimiento: alta capacidad de procesamiento a un menor costo con una latencia de extremo a extremo de menos de unos pocos segundos. Structured Streaming les ofrece a los usuarios la flexibilidad para equilibrar la relación entre rendimiento, costo y latencia.
A medida que la adopción del "streaming" crece rápidamente en las empresas, existe el deseo de permitir que un conjunto diverso de aplicaciones utilice la arquitectura de datos de "streaming". En nuestras conversaciones con muchos clientes, nos hemos encontrado con casos de uso que requieren una latencia constante por debajo del segundo. Estos casos de uso de baja latencia surgen de aplicaciones como las alertas operativas y el monitoreo en tiempo real, también conocidas como "cargas de trabajo operativas". Para incorporar estas cargas de trabajo en Structured Streaming, en 2022 lanzamos una iniciativa de mejora del rendimiento en el marco del Proyecto Lightspeed. Esta iniciativa identificó áreas y técnicas potenciales que pueden utilizarse para mejorar la latencia de procesamiento. En este blog, describimos en detalle una de estas áreas de mejora: la gestión de "offsets" para el seguimiento del progreso y cómo consigue una latencia por debajo del segundo para las cargas de trabajo operativas.
¿Qué son las cargas de trabajo operativas?
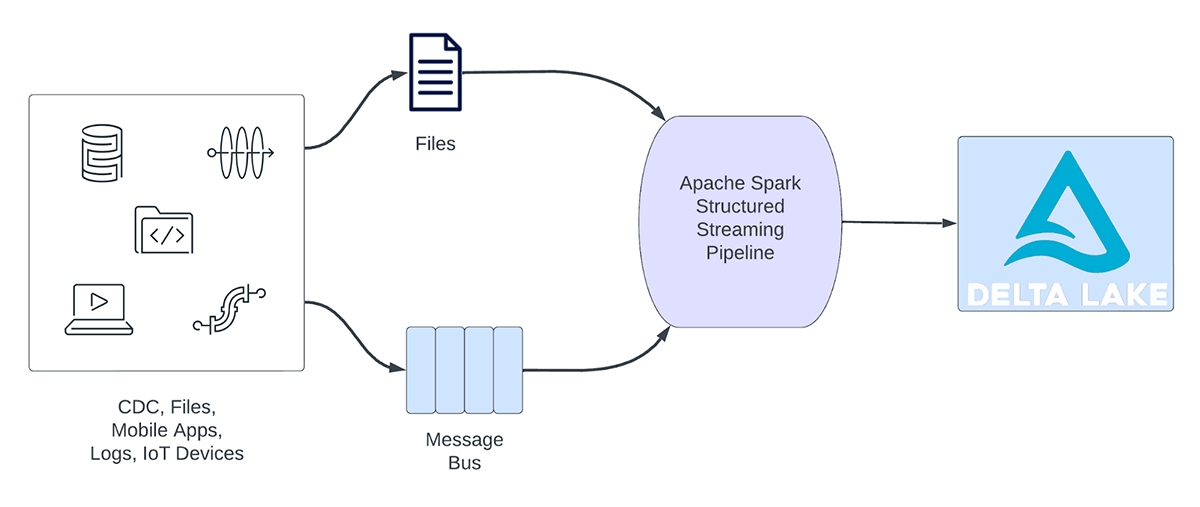
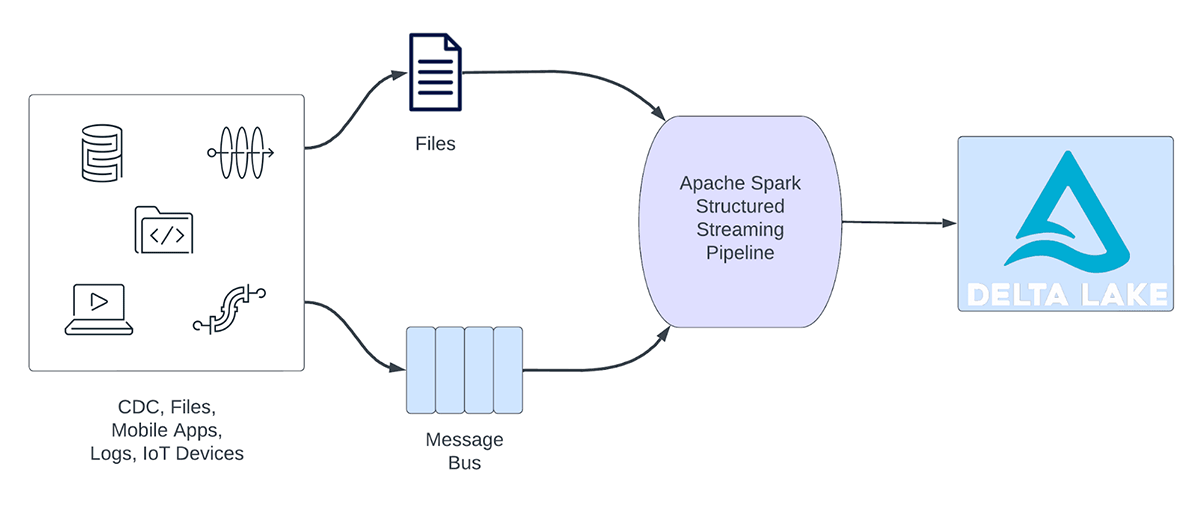
Las cargas de trabajo de streaming pueden clasificarse a grandes rasgos en cargas de trabajo analíticas y cargas de trabajo operativas. La Figura 1 ilustra tanto las cargas de trabajo analíticas como las operativas. Las cargas de trabajo analíticas normalmente ingieren, transforman, procesan y analizan datos en tiempo real y escriben los resultados en Delta Lake, respaldado por almacenamiento de objetos como AWS S3, Azure Data Lake Gen2 y Google Cloud Storage. Estos resultados son consumidos por motores de almacenamiento de datos y herramientas de visualización posteriores.
{kind=link}
{kind=link}
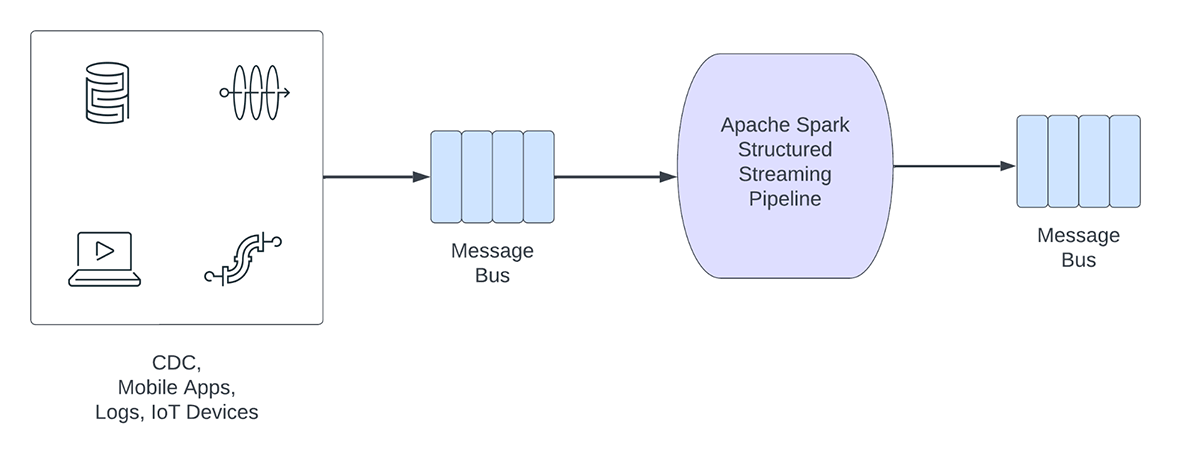
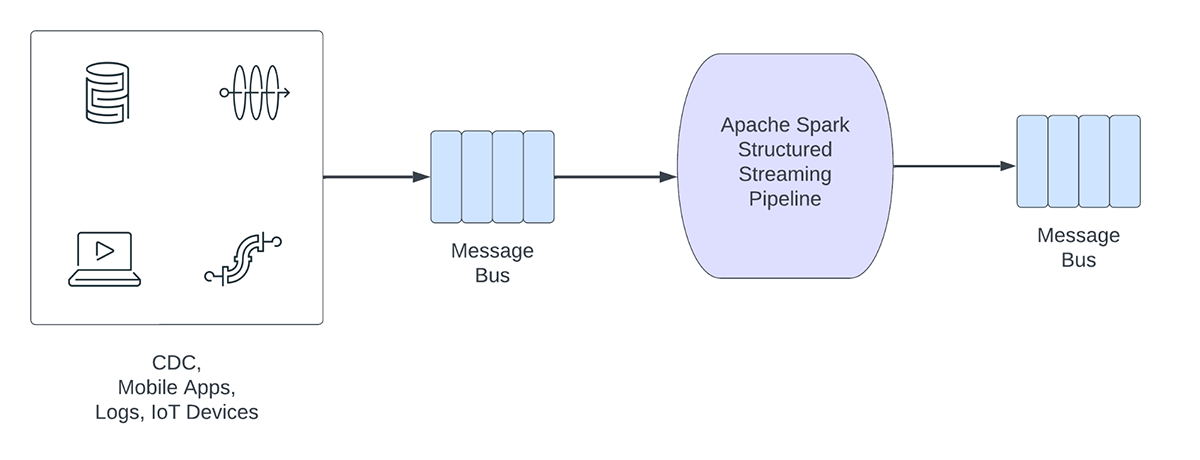
Figura 1. Cargas de trabajo analíticas vs. operativas
Algunos ejemplos de cargas de trabajo analíticas incluyen:
- Análisis del comportamiento del cliente: Una empresa de marketing puede usar el análisis de streaming para analizar el comportamiento del cliente en tiempo real. Al procesar datos de clickstream, feeds de redes sociales y otras fuentes de información, el sistema puede detectar patrones y preferencias que se pueden usar para dirigirse a los clientes de manera más efectiva.
- Análisis de sentimiento: una empresa podría utilizar datos de "streaming" de sus cuentas de redes sociales para analizar el sentimiento de los clientes en tiempo real. Por ejemplo, la empresa podría buscar clientes que expresen un sentimiento positivo o negativo sobre los productos o servicios de la empresa.
- Análisis de IoT: una ciudad inteligente puede utilizar el análisis de "streaming" para monitorear el flujo del tráfico, la calidad del aire y otras métricas en tiempo real. Al procesar los datos de los sensores integrados en toda la ciudad, el sistema puede detectar tendencias y tomar decisiones sobre los patrones de tráfico o las políticas medioambientales.
Por otro lado, las cargas de trabajo operativas ingieren y procesan datos en tiempo real y desencadenan automáticamente un proceso de negocio. Algunos ejemplos de estas cargas de trabajo incluyen:
- Ciberseguridad: una empresa puede utilizar datos de streaming de su red para monitorear problemas de seguridad o rendimiento. Por ejemplo, la empresa podría buscar picos en el tráfico o accesos no autorizados a las redes y enviar una alerta al departamento de seguridad.
- Fugas de información de identificación personal: una empresa podría supervisar los registros de microservicios, analizar y detectar si se está filtrando alguna información de identificación personal (PII) y, si es así, informar por correo electrónico al propietario del microservicio.
- Despacho de ascensores: Una empresa podría usar los datos de streaming del ascensor para detectar cuándo se activa el botón de alarma de un ascensor. Si se activa, podría buscar información adicional del ascensor para mejorar los datos y enviar una notificación al personal de seguridad.
- Mantenimiento proactivo: monitoree la temperatura usando los datos de streaming de un generador de energía e informe al supervisor cuando exceda un umbral determinado.
Las canalizaciones de streaming operativas comparten las siguientes características:
- Las expectativas de latencia suelen ser inferiores a un segundo
- Los pipelines leen de un bus de mensajes
- Los "pipelines" suelen realizar cálculos sencillos con transformación o enriquecimiento de datos.
- Los "pipelines" escriben en un bus de mensajes como Apache Kafka o Apache Pulsar o en almacenes de clave-valor rápidos como Apache Cassandra o Redis para la integración descendente en los procesos de negocio.
Para estos casos de uso, cuando perfilamos Structured Streaming, identificamos que la gestión de offsets para hacer un seguimiento del progreso de los microlotes consume una cantidad de tiempo considerable. En la siguiente sección, revisaremos la gestión de offsets existente y describiremos cómo la mejoramos en las secciones posteriores.
¿Qué es la gestión de offsets?
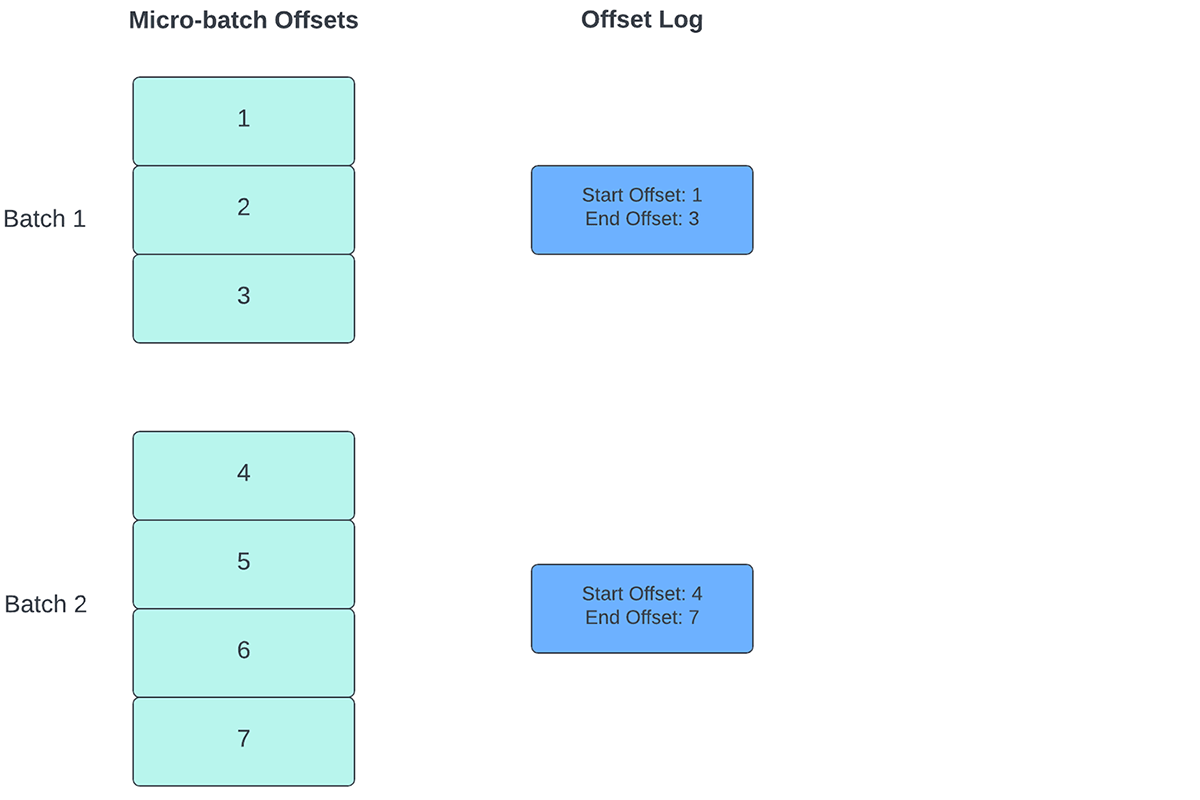
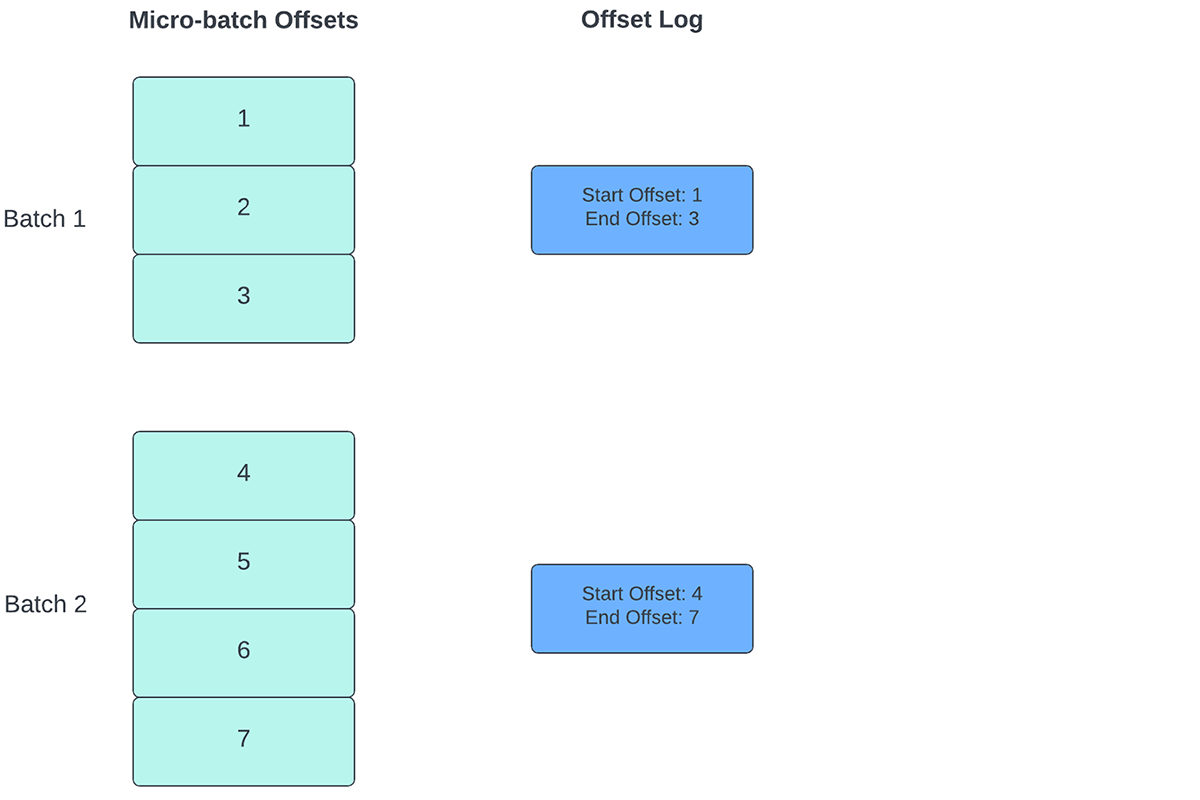
Para realizar un seguimiento del progreso hasta qué punto se han procesado los datos, Spark Structured Streaming se basa en la persistencia y la gestión de los offsets, que se utilizan como indicadores de progreso. Por lo general, un offset es definido de forma concreta por el conector de origen, ya que los diferentes sistemas tienen distintas formas de representar el progreso o las ubicaciones en los datos. Por ejemplo, una implementación concreta de un offset puede ser el número de línea en un archivo para indicar hasta dónde se han procesado los datos del archivo. Los registros duraderos (como se muestra en la Figura 2) se utilizan para almacenar estos offsets y marcar la finalización de los microlotes.
{kind=link}
En Structured Streaming, los datos se procesan en unidades de microlotes. Se realizan dos operaciones de gestión de offsets para cada microlote. Una al principio de cada microlote y una al final.
- Al principio de cada microlote (antes de que comience el procesamiento de datos), se calcula un offset en función de los nuevos datos que se pueden leer del sistema de destino. Este offset se guarda de forma persistente en un registro duradero llamado "offsetLog" en el directorio de puntos de control. Este offset se utiliza para calcular el rango de datos que se procesará en "este" microlote.
- Al final de cada microlote, se guarda una entrada en el registro duradero llamado "commitLog" para indicar que "este" microlote se ha procesado correctamente.
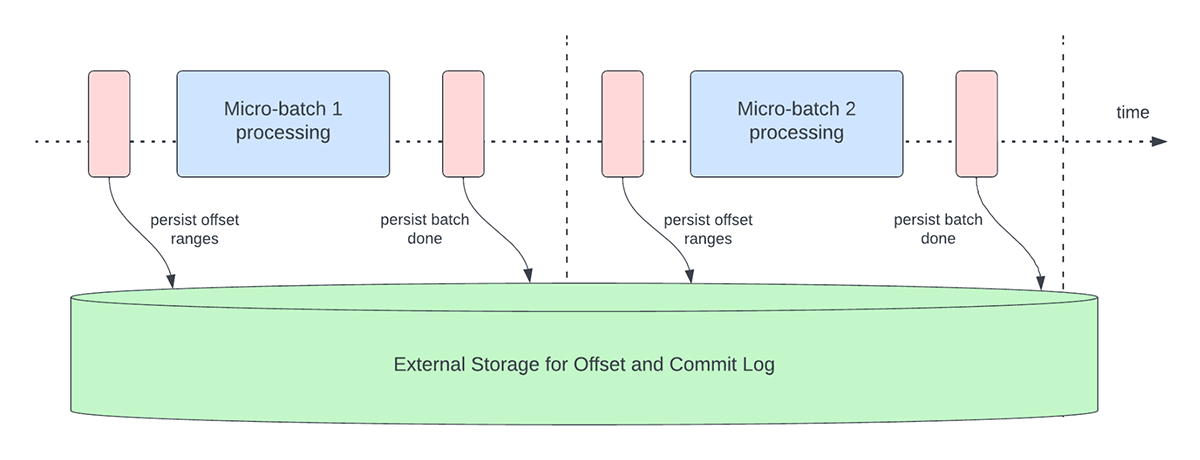
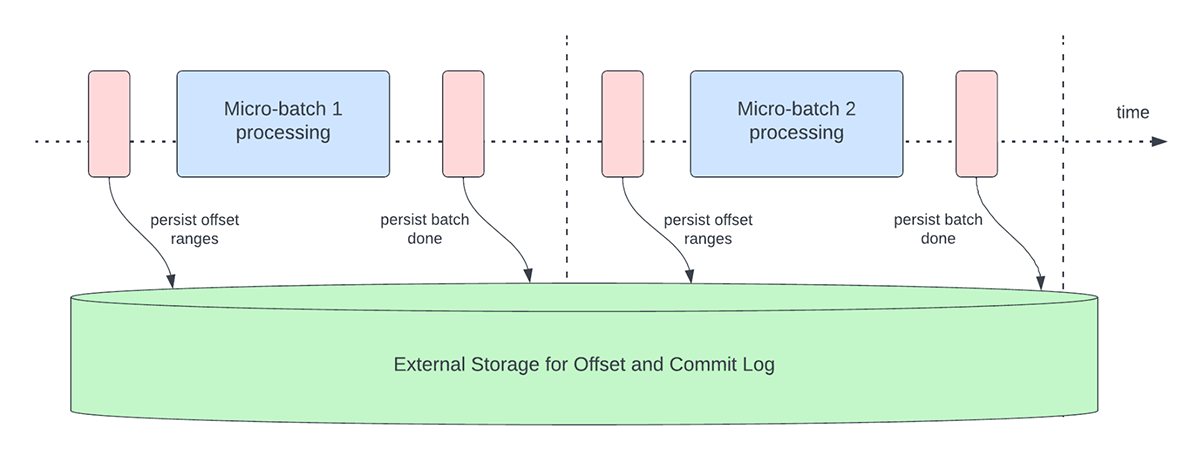
La figura 3 a continuación muestra las operaciones actuales de gestión de "offsets" que se producen.
{kind=link}
Otra operación de gestión de offsets se realiza al final de cada microlote. Esta operación es una operación de limpieza para eliminar/truncar entradas antiguas e innecesarias tanto del offsetLog como del commitLog para que estos registros no crezcan de forma ilimitada.
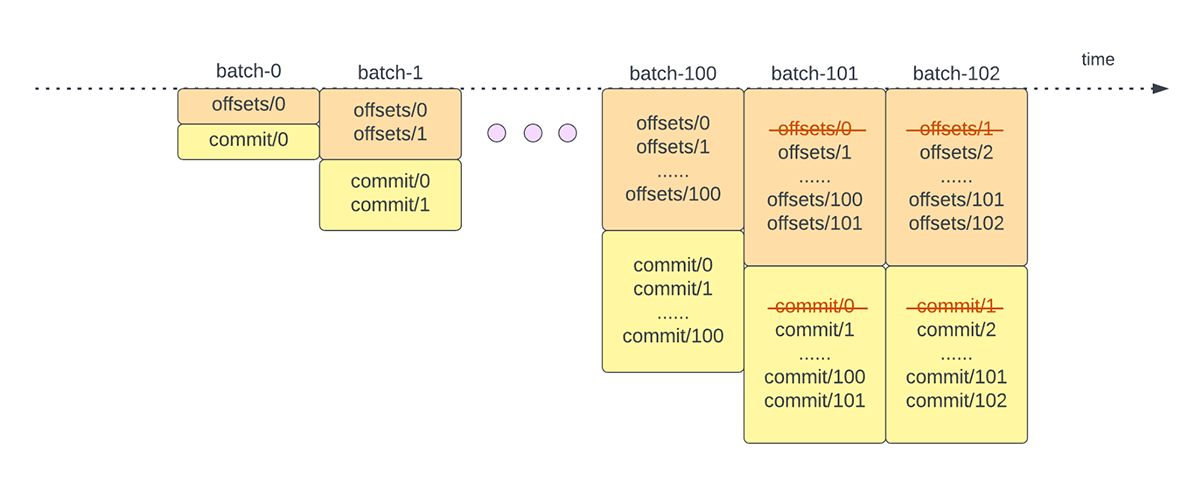
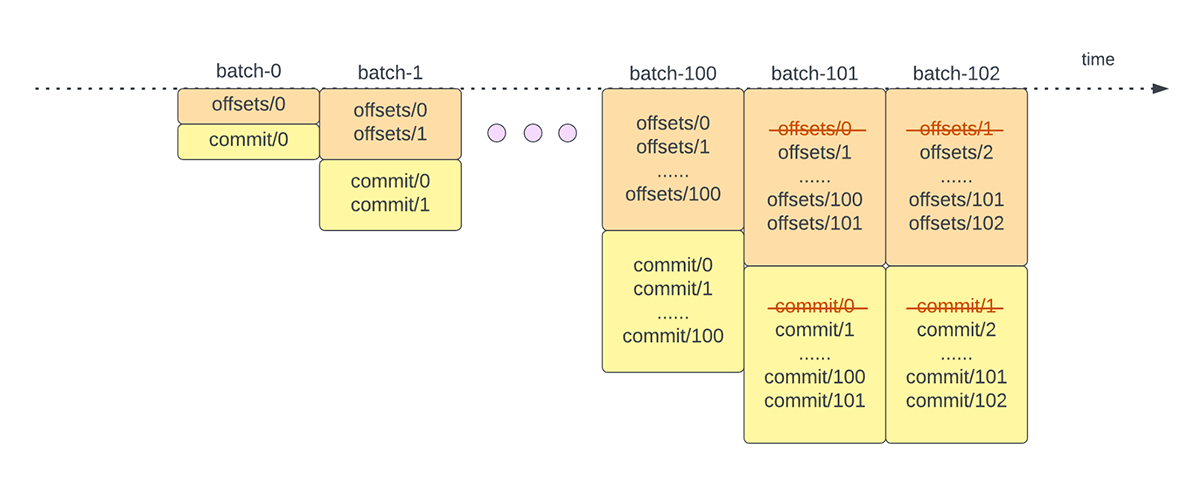{kind=link}
Estas operaciones de gestión de offsets se realizan en la ruta crítica y en línea con el procesamiento real de los datos. Esto significa que la duración de estas operaciones afecta directamente la latencia de procesamiento y no se puede realizar ningún procesamiento de datos hasta que estas operaciones se completen. Esto también afecta directamente la utilización del clúster.
A través de nuestros esfuerzos de "benchmarking" y elaboración de perfiles de rendimiento, hemos identificado que estas operaciones de gestión de "offsets" pueden ocupar la mayor parte del tiempo de procesamiento, especialmente en el caso de los "pipelines" sin estado y de estado único que se utilizan a menudo en los casos de uso de alertas operativas y monitoreo en tiempo real.
Mejoras de rendimiento en Structured Streaming
Seguimiento asíncrono del progreso
Esta característica se creó para solucionar la sobrecarga de latencia de la persistencia de los offsets para fines de seguimiento del progreso. Esta característica, cuando está habilitada, permitirá a los pipelines de Structured Streaming hacer checkpoint del progreso, es decir, actualizar el offsetLog y el commitLog, de forma asíncrona y en paralelo al procesamiento de datos real dentro de un microlote. En otras palabras, el procesamiento de datos real no se verá bloqueado por estas operaciones de gestión de offsets, lo que mejorará significativamente la latencia de las aplicaciones. La Figura 5 a continuación muestra este nuevo comportamiento para la gestión de offsets.
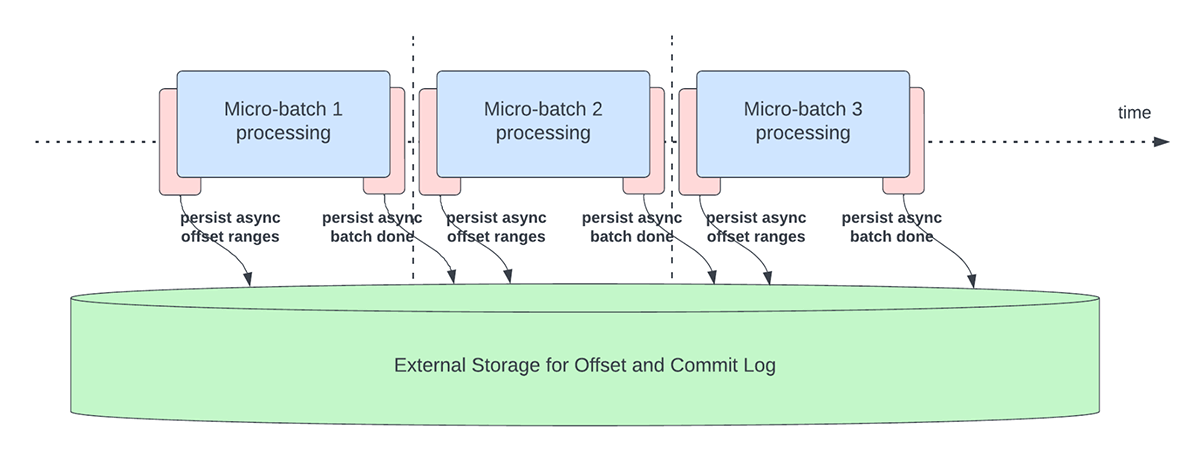
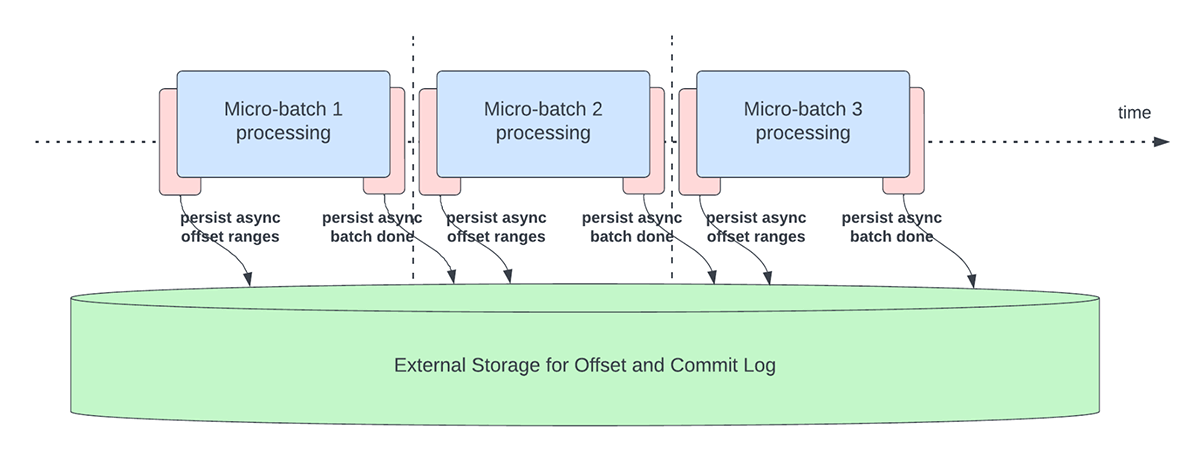{kind=link}
Junto con la realización de actualizaciones asíncronas, los usuarios pueden configurar la frecuencia con la que se crean puntos de control del progreso. Esto será útil para situaciones en las que las operaciones de gestión de offsets se producen a una velocidad mayor de la que pueden procesarse. Esto sucede en los pipelines cuando el tiempo que se dedica realmente a procesar los datos es considerablemente menor en comparación con estas operaciones de gestión de offsets. En tales situaciones, se producirá un backlog cada vez mayor de operaciones de gestión de offsets. Para contener este backlog creciente, el procesamiento de datos tendrá que bloquearse o ralentizarse, lo que, en esencia, revertirá el comportamiento del procesamiento para que sea el mismo que si estas operaciones de gestión de offsets se ejecutaran en línea con el procesamiento de datos. Normalmente, un usuario no necesitará configurar o establecer la frecuencia de los puntos de control, ya que se establecerá un valor predeterminado adecuado. Es importante tener en cuenta que el tiempo de recuperación de errores aumentará con el incremento del tiempo de intervalo de los puntos de control. En caso de error, un pipeline tiene que volver a procesar todos los datos anteriores al último punto de control exitoso. Los usuarios pueden considerar esta compensación entre una menor latencia durante el procesamiento regular y el tiempo de recuperación en caso de error.
Se presentan las siguientes configuraciones para habilitar y configurar esta característica:
asyncProgressTrackingEnabled: activa o desactiva el seguimiento asíncrono del progreso.Predeterminado: false
asyncProgressCheckpointingInterval: el intervalo en el que se realizan los commits de los offsets y de finalizaciónPredeterminado: 1 minuto
El siguiente ejemplo de código muestra cómo habilitar esta función:
Tenga en cuenta que esta característica no funcionará con Trigger.once o Trigger.availableNow, ya que estos desencadenadores ejecutan los pipelines de forma manual o programada. Por lo tanto, el seguimiento de progreso asíncrono no será relevante. La consulta fallará si se envía utilizando cualquiera de los desencadenadores antes mencionados.
Aplicabilidad y limitaciones
Existen un par de limitaciones en la(s) versión(es) actual(es) que podrían cambiar a medida que evolucionemos la característica:
- Actualmente, el seguimiento de progreso asíncrono solo es compatible con pipelines sin estado que usan Kafka Sink.
- El procesamiento de extremo a extremo "exactly once" no será compatible con este seguimiento de progreso asíncrono porque los rangos de offset para un lote pueden cambiar en caso de fallo. Sin embargo, muchos sinks, como el sink de Kafka, solo admiten garantías "at-least once", por lo que puede que esta no sea una limitación nueva.
Purga de registros asíncrona
Esta característica se creó para abordar la sobrecarga de latencia de las limpiezas de registros que se realizaban en línea dentro de un microlote. Al hacer que esta operación de limpieza/purga de registros sea asíncrona y se realice en segundo plano, podemos eliminar la sobrecarga de latencia que esta operación supondrá para el procesamiento real de los datos. Además, estas purgas no tienen por qué realizarse con cada microlote y pueden producirse con un calendario más relajado.
Tenga en cuenta que esta característica/mejora no tiene ninguna limitación sobre qué tipo de pipelines o cargas de trabajo pueden utilizarla, por lo que esta característica se habilitará en segundo plano de forma predeterminada para todos los pipelines de Structured Streaming.
Pruebas de rendimiento
Para comprender el rendimiento del seguimiento asíncrono del progreso y la purga asíncrona de registros, creamos algunos "benchmarks". Nuestro objetivo con los "benchmarks" es comprender la diferencia de rendimiento que proporciona la gestión mejorada de "offsets" en un "pipeline" de "streaming" de extremo a extremo. Los "benchmarks" se dividen en dos categorías:
- Origen de tasa a receptor de estadísticas: en este "benchmark", utilizamos un origen y un receptor básicos, sin estado y de recopilación de estadísticas, lo que resulta útil para determinar la diferencia en el rendimiento del motor principal sin ninguna dependencia externa.
- Origen de Kafka a receptor de Kafka: para este "benchmark", movemos datos de un origen de Kafka a un receptor de Kafka. Esto es similar a un escenario del mundo real para ver cuál sería la diferencia en un escenario de producción.
Para ambos benchmarks, medimos la latencia de extremo a extremo (percentil 50, percentil 99) a diferentes velocidades de entrada de datos (100K eventos/s, 500K eventos/s, 1M eventos/s).
Metodología del "benchmark"
La metodología principal consistió en generar datos a partir de un origen con un rendimiento constante determinado. Los registros generados contienen información sobre cuándo se crearon. En el lado del receptor, utilizamos la biblioteca Apache DataSketches para recopilar la diferencia entre el momento en que el receptor procesa el registro y el momento en que se creó en cada lote. Esto se utiliza para calcular la latencia. Utilizamos el mismo clúster con el mismo número de nodos para todos los experimentos.
Nota: Para el benchmark de Kafka, reservamos algunos nodos de un clúster para ejecutar Kafka y generar los datos para alimentar a Kafka. Calculamos la latencia de un registro solo después de que el registro se haya publicado con éxito en Kafka (en el sink).
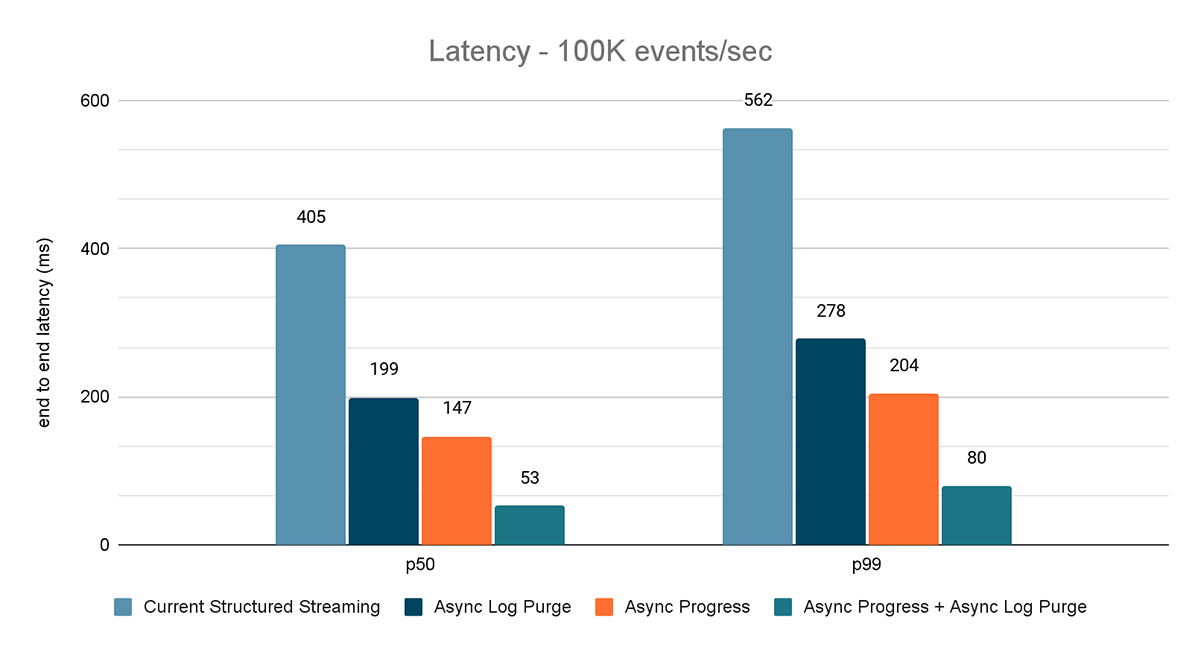
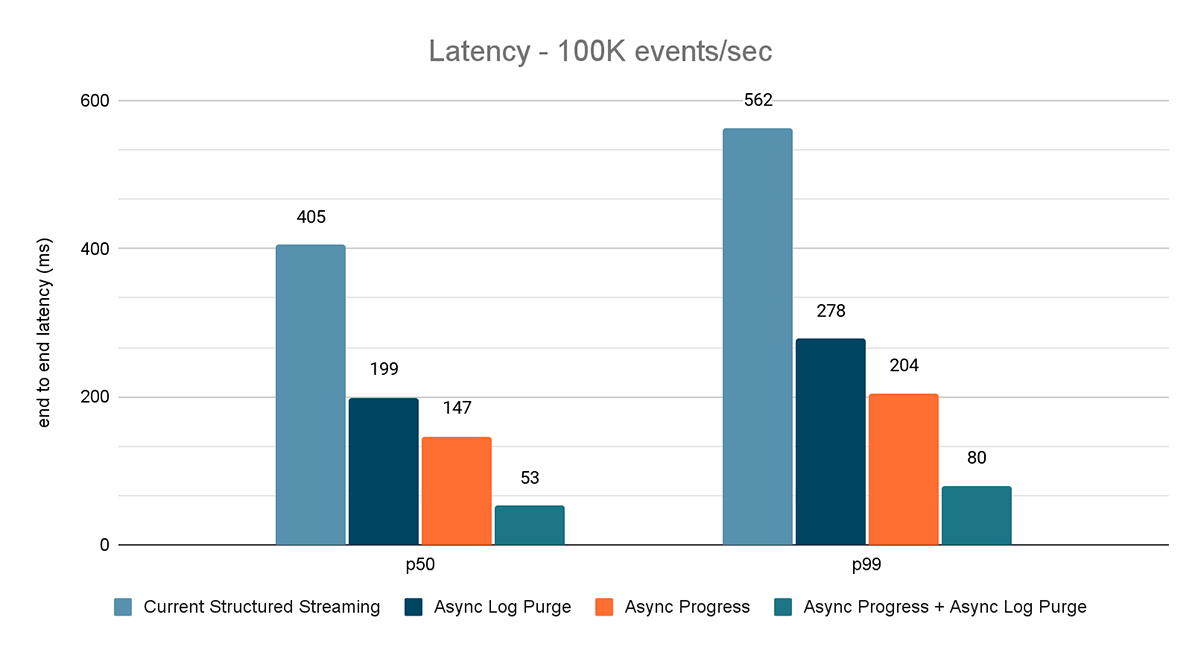
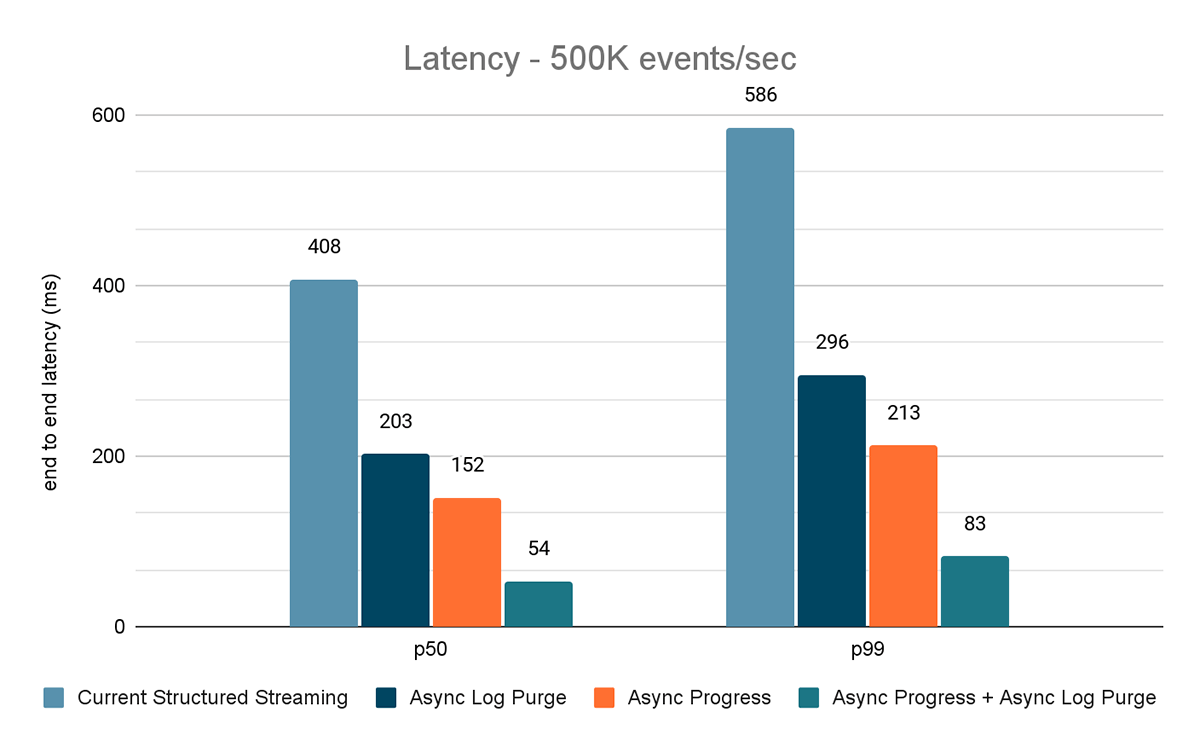
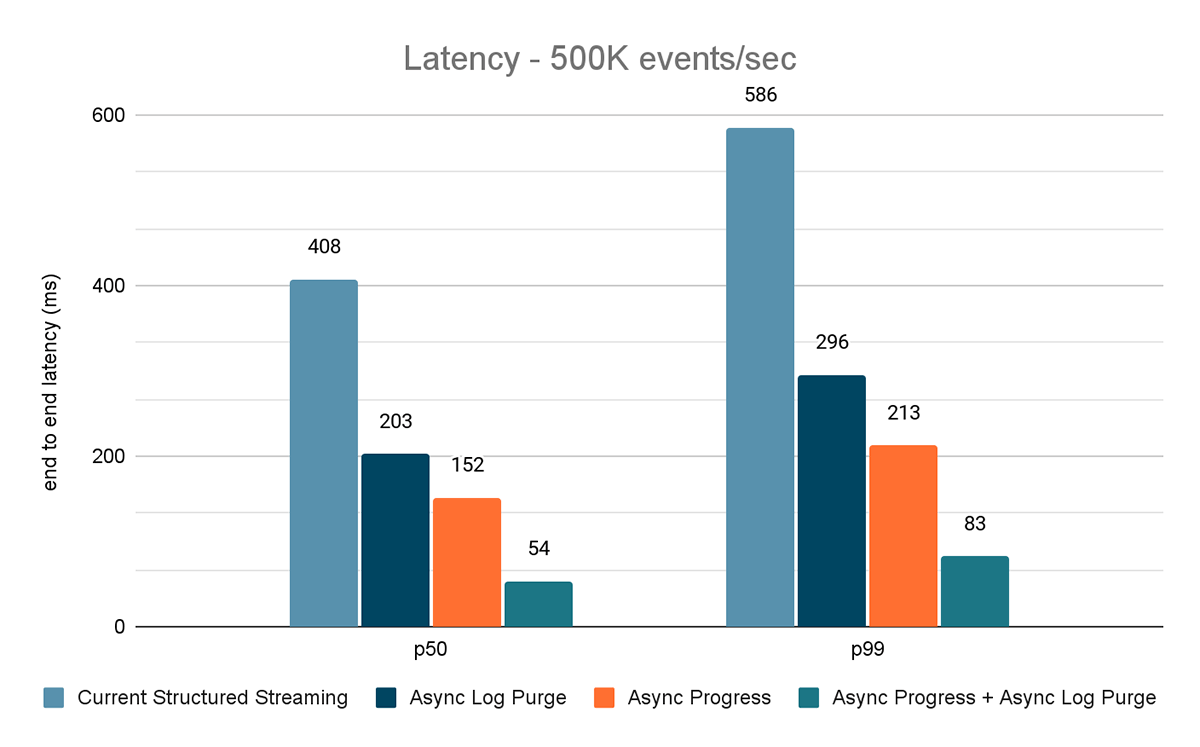
Prueba de rendimiento de la fuente de tasa al sink de estadísticas.
Para este benchmark, usamos un clúster de Spark de 7 nodos de trabajo (i3.2xlarge - 4 núcleos, 61 GiB de memoria) utilizando el runtime de Databricks (11.3). Medimos la latencia de extremo a extremo para los siguientes escenarios para cuantificar la contribución de cada mejora.
- Structured Streaming actual: esta es la latencia de referencia sin ninguna de las mejoras mencionadas.
- Purga de registros asíncrona: mide la latencia después de aplicar únicamente la purga de registros asíncrona.
- Progreso asíncrono: mide la latencia después de aplicar el seguimiento de progreso asíncrono
- Progreso asíncrono + Purga de registros asíncrona: mide la latencia después de aplicar ambas mejoras
Los resultados de estos experimentos se muestran en las Figuras 6, 7 y 8. Como puede ver, la purga asíncrona de registros reduce la latencia de forma consistente en aproximadamente un 50 %. Del mismo modo, el seguimiento de progreso asíncrono por sí solo mejora la latencia en aproximadamente un 65 %. En conjunto, la latencia se reduce en un 85-86 % y baja a menos de 100 ms.
{kind=link}
{kind=link}
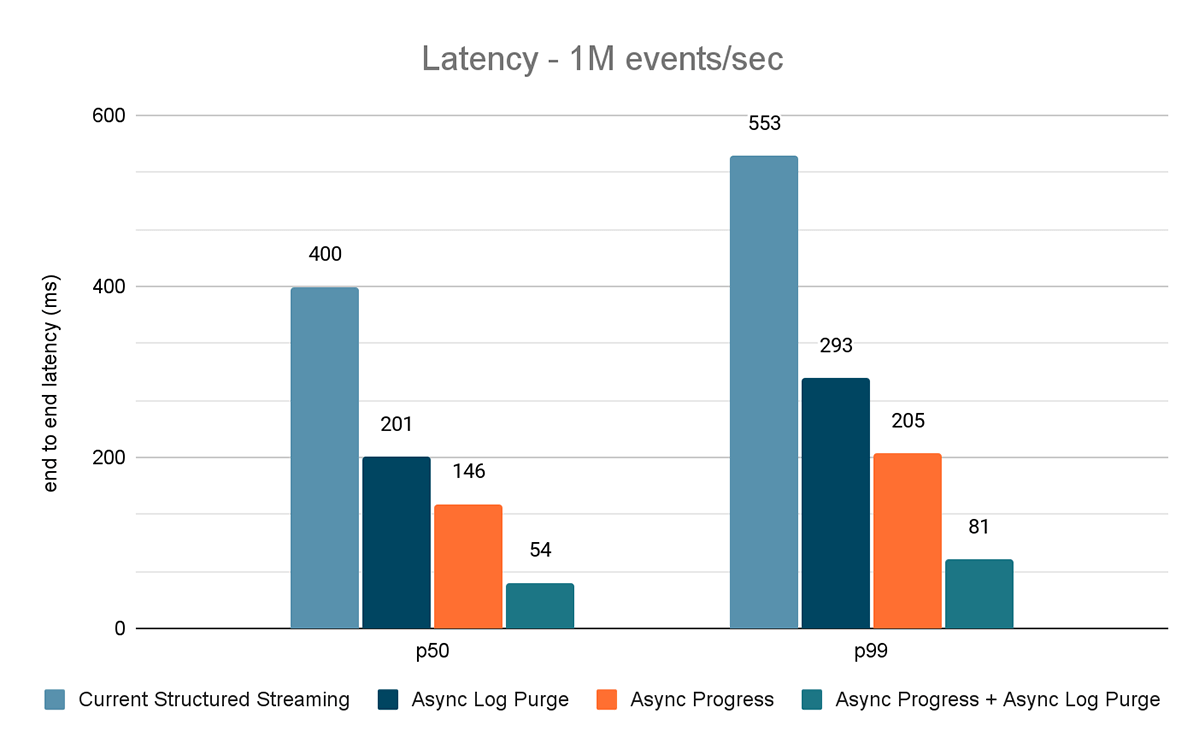
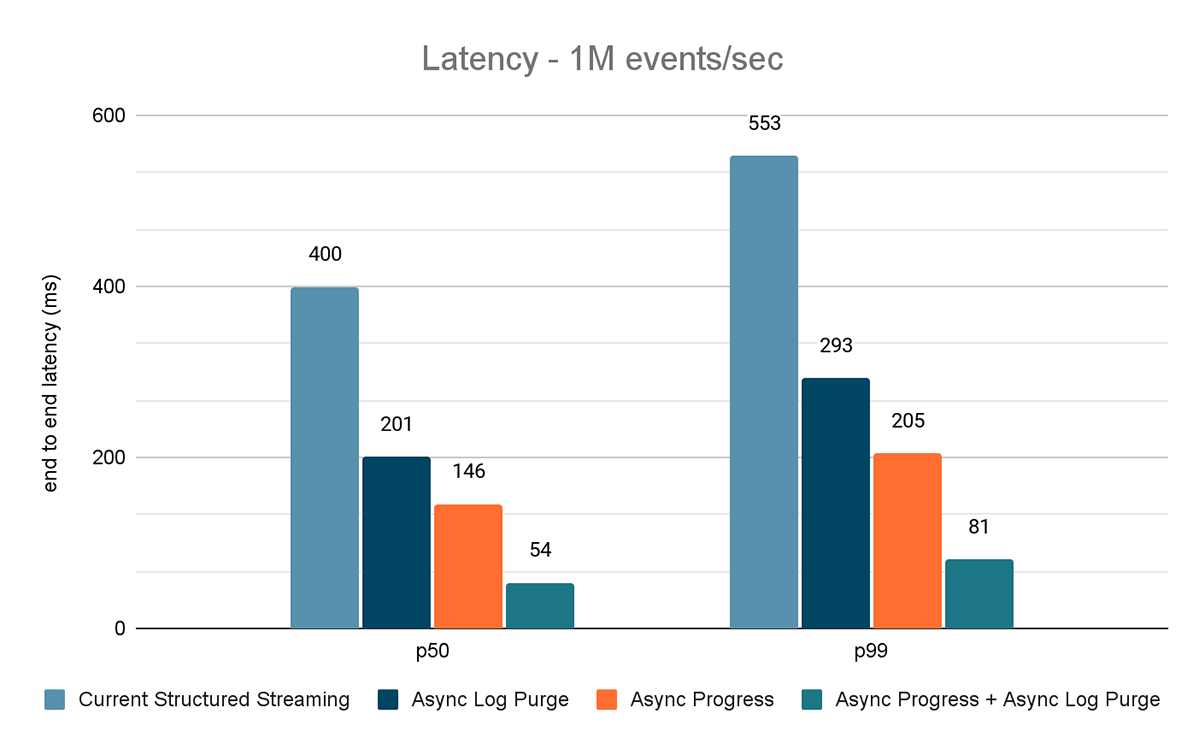{kind=link}
Benchmark de origen de Kafka a receptor de Kafka
Para los benchmarks de Kafka, utilizamos un clúster de Spark de 5 nodos de trabajo (i3.2xlarge - 4 núcleos, 61 GiB de memoria), un clúster separado de 3 nodos para ejecutar Kafka y 2 nodos adicionales para generar los datos añadidos a la fuente de Kafka. Nuestro tema de Kafka tiene 40 particiones y un factor de replicación de 3.
El generador de datos publica los datos en un tema de Kafka y el "pipeline" de Structured Streaming consume los datos y los vuelve a publicar en otro tema de Kafka. Los resultados de la evaluación del rendimiento se muestran en las figuras 9, 10 y 11. Como se puede observar, después de aplicar el progreso asíncrono y la purga asíncrona de registros, la latencia se reduce entre un 65 y un 75 %, o entre 3 y 3,5 veces, en diferentes rendimientos.
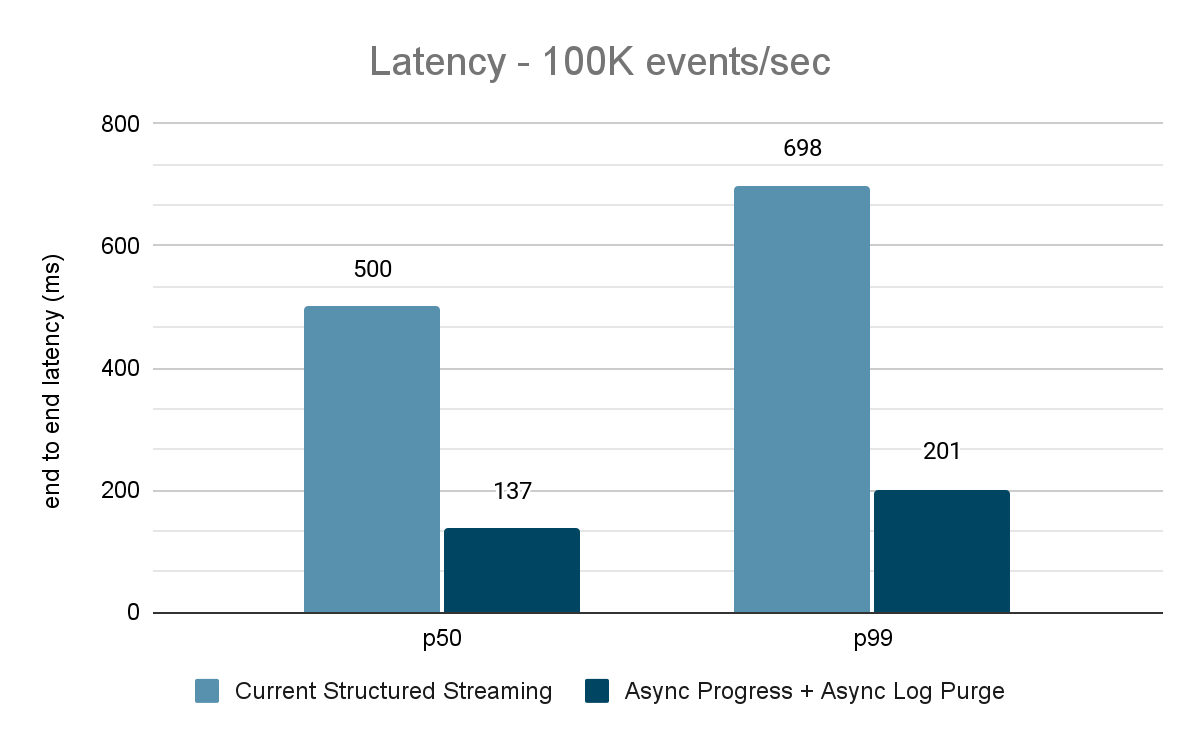
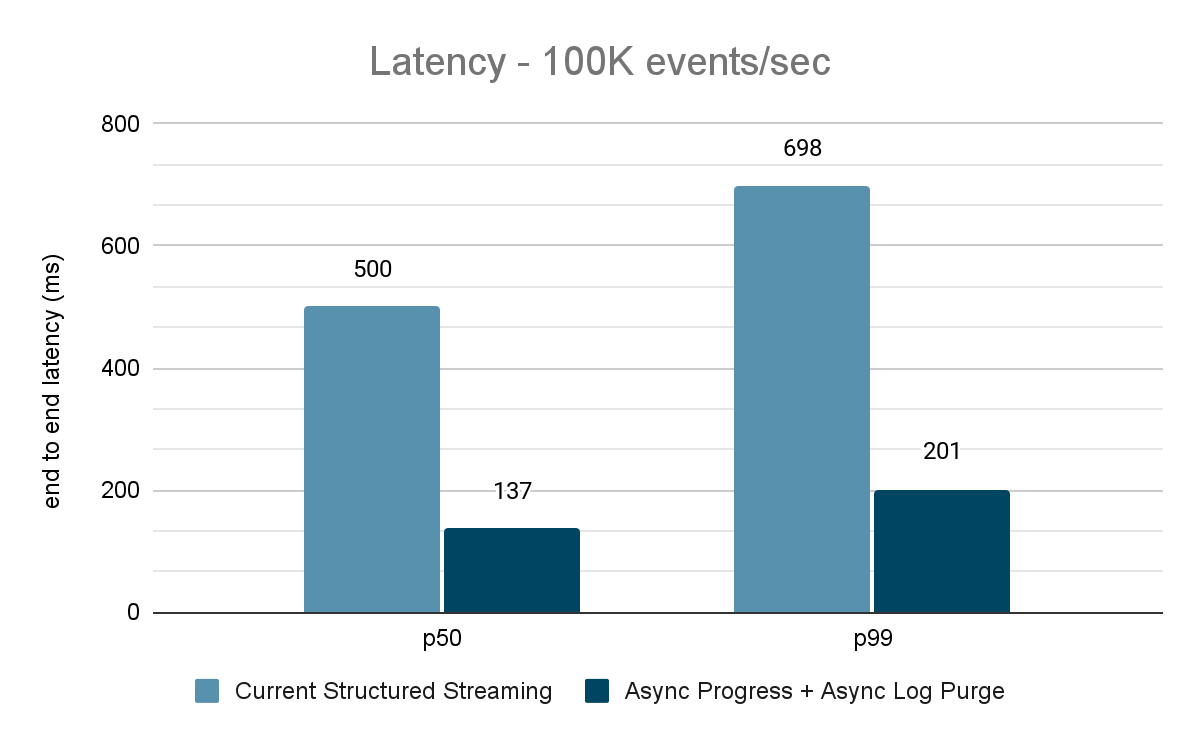{kind=link}
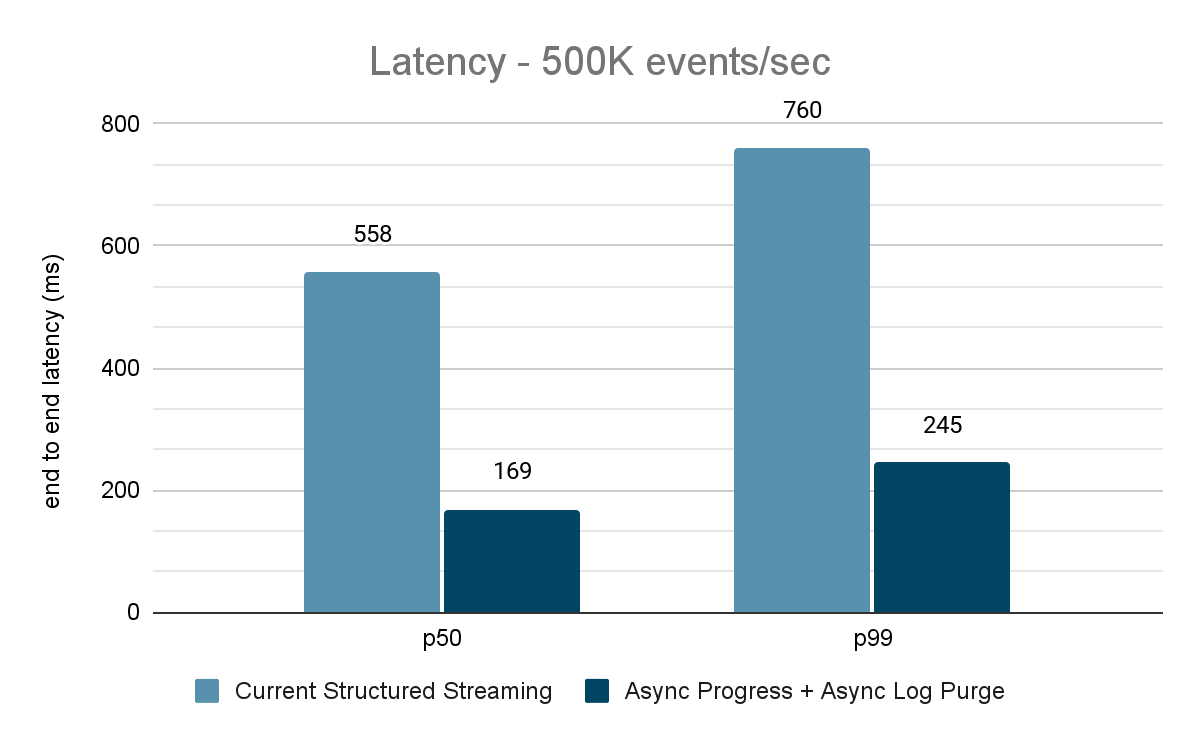
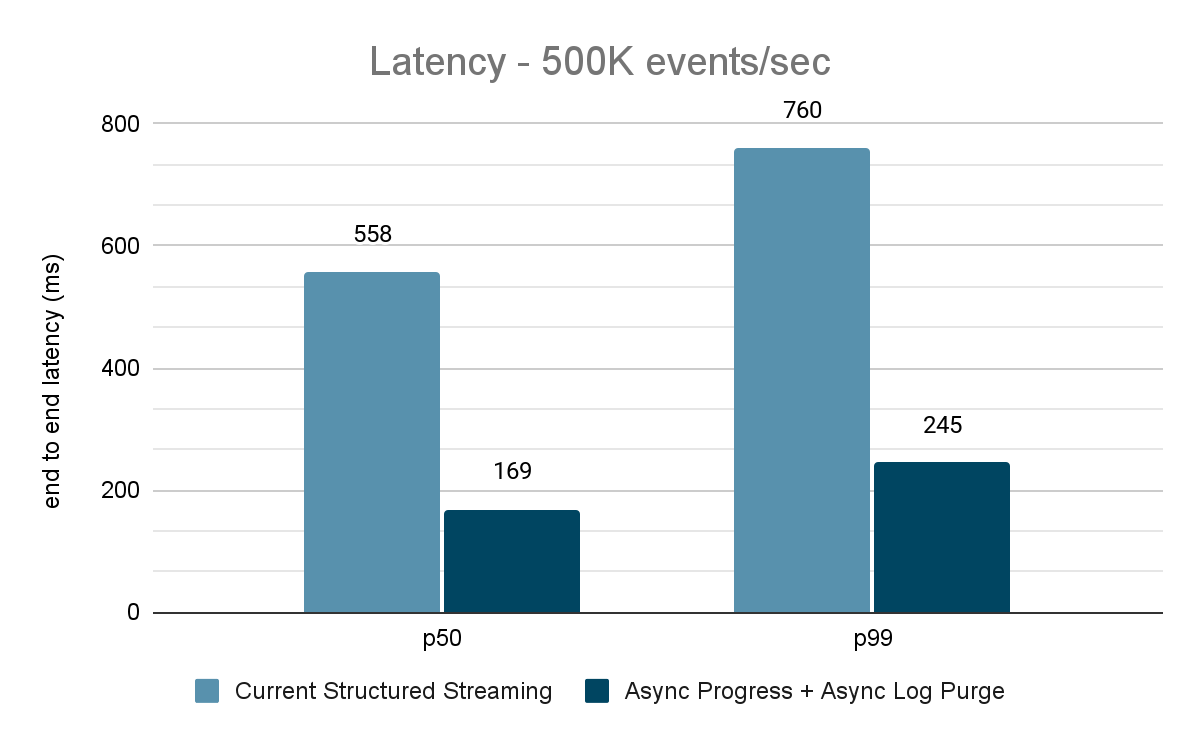{kind=link}
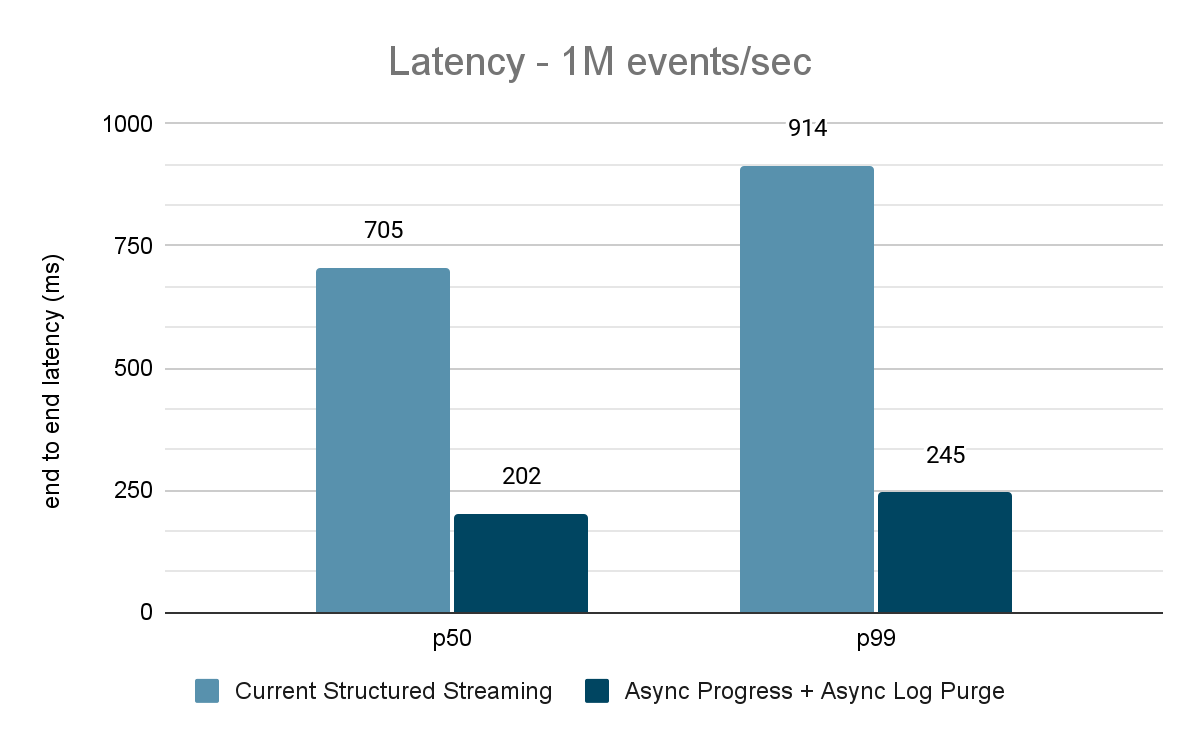
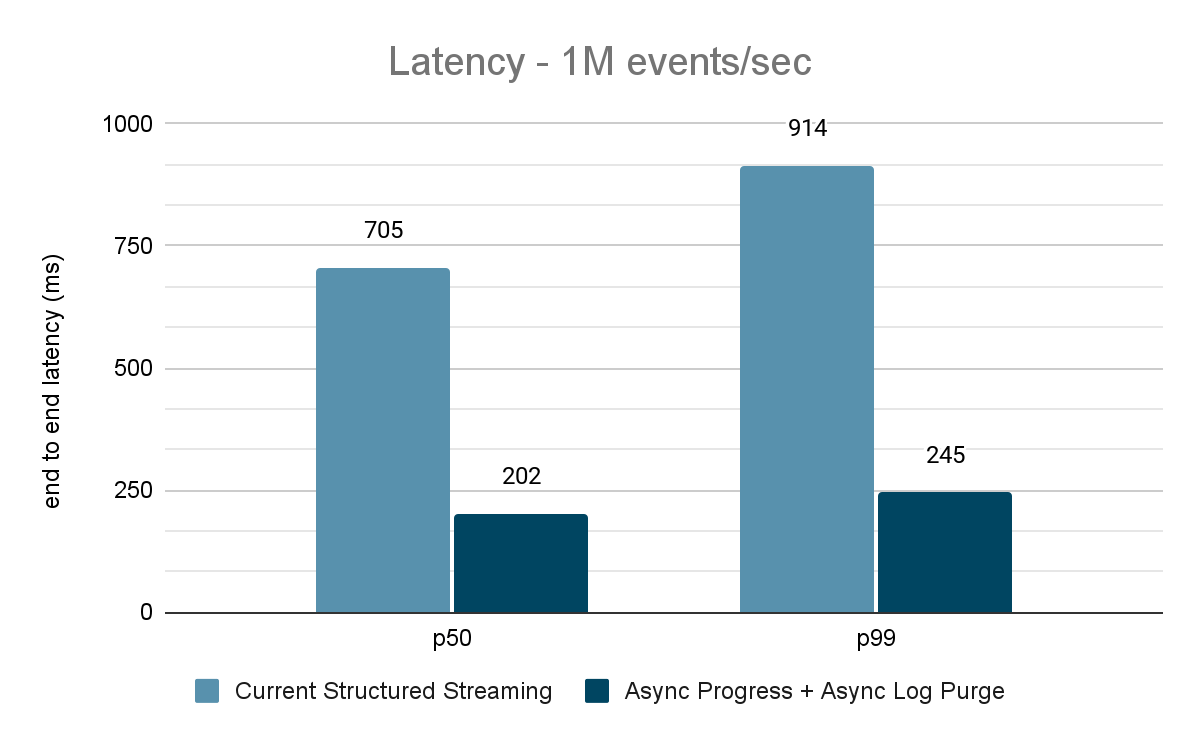{kind=link}
Resumen de los resultados de rendimiento
Con el nuevo seguimiento de progreso asíncrono y la purga de registros asíncrona, podemos ver que ambas configuraciones reducen la latencia hasta 3 veces. Trabajando juntas, la latencia se reduce considerablemente en todos los rendimientos. Los gráficos también muestran que la cantidad de tiempo ahorrado suele ser una cantidad constante (200 - 250 ms para cada configuración) y que juntas pueden reducir alrededor de 500 ms en general (dejando tiempo suficiente para la planificación de lotes y el procesamiento de consultas).
Disponibilidad
Estas mejoras de rendimiento están disponibles en Databricks Lakehouse Platform a partir de DBR 11.3 en adelante. La purga asíncrona de registros está habilitada de forma predeterminada en DBR 11.3 y versiones posteriores. Además, estas mejoras se han incorporado a Spark de código abierto y están disponibles a partir de Apache Spark 3.4.
Trabajo futuro
Actualmente existen algunas limitaciones en los tipos de cargas de trabajo y receptores admitidos por la función de seguimiento de progreso asíncrono. En el futuro, buscaremos admitir más tipos de cargas de trabajo con esta característica.
Este es solo el comienzo de las características de baja latencia predecible que estamos creando en Structured Streaming como parte de Project Lightspeed. Además, continuaremos haciendo benchmarks y perfiles de Structured Streaming para encontrar más áreas de mejora. ¡Estén atentos!
Acompáñenos en el Data and AI Summit en San Francisco, del 26 al 29 de junio, para obtener más información sobre Project Lightspeed y el streaming de datos en la Databricks Lakehouse Platform.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.