Modernice su plataforma de ingeniería de datos con Lakeflow en Azure Databricks
Databricks Lakeflow on Azure ofrece una solución de ingeniería de datos moderna, confiable y lista para la empresa
- Lakeflow proporciona una solución unificada de extremo a extremo para los ingenieros de datos que trabajan en Azure Databricks, que incluye la ingesta, la transformación y la orquestación de datos
- Desde la seguridad y la gobernanza unificadas hasta la observabilidad integrada, el procesamiento sin servidor, el procesamiento de streaming y una interfaz de usuario que prioriza el código, los profesionales de Azure Databricks pueden beneficiarse de una amplia gama de capacidades de Lakeflow, en combinación con su plataforma de datos de Azure.
- Los ingenieros de datos que utilizan Lakeflow en Azure Databricks pueden crear e implementar canalizaciones de datos listas para la producción hasta 25 veces más rápido, experimentar un mayor rendimiento y ver una reducción en los costos de ETL de hasta un 83 %.
Los ingenieros de datos están cada vez más frustrados por la cantidad de herramientas y soluciones inconexas que necesitan para crear canalizaciones listas para la producción. Sin una plataforma de inteligencia de datos centralizada o una gobernanza unificada, los equipos se enfrentan a muchos problemas, entre ellos:
- Rendimiento ineficiente y arranques lentos
- IU inconexa y cambio de contexto constante
- Falta de seguridad y control granular
- CI/CD complejo
- Visibilidad limitada del linaje de datos
- etc.
¿El resultado? Equipos más lentos y menos confianza en sus datos.
Con Lakeflow en Azure Databricks, puede resolver estos problemas centralizando todos sus esfuerzos de ingeniería de datos en una única plataforma nativa de Azure.

Una solución unificada de ingeniería de datos para Azure Databricks
Lakeflow es una solución moderna e integral de ingeniería de datos desarrollada sobre la Data Intelligence Platform de Databricks en Azure que integra todas las funciones esenciales de ingeniería de datos. Con Lakeflow, obtienes lo siguiente:
- Ingestión, transformación y orquestación de datos integradas en un solo lugar
- Conectores de ingestión gestionados
- ETL declarativo para un desarrollo más rápido y sencillo
- Procesamiento incremental y de streaming para obtener SLA más rápidos y estadísticas más recientes
- Gobernanza y linaje nativos a través de Unity Catalog, la solución de gobernanza integrada de Databricks
- Observabilidad integrada para la calidad de los datos y la confiabilidad de las canalizaciones
¡Y mucho más! Todo en una interfaz flexible y modular que puede adaptarse a las necesidades de todos los usuarios, ya sea que prefieran programar o usar una interfaz de apuntar y hacer clic.
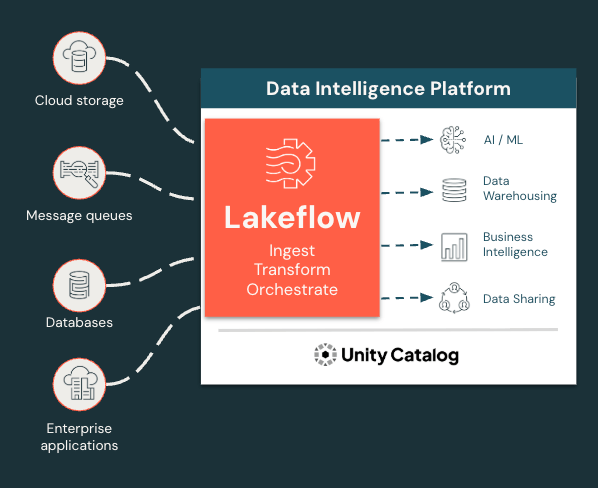
Ingiera, transforme y orqueste todas las cargas de trabajo en un solo lugar
Lakeflow unifica la experiencia de ingeniería de datos para que pueda avanzar con mayor rapidez y confiabilidad.
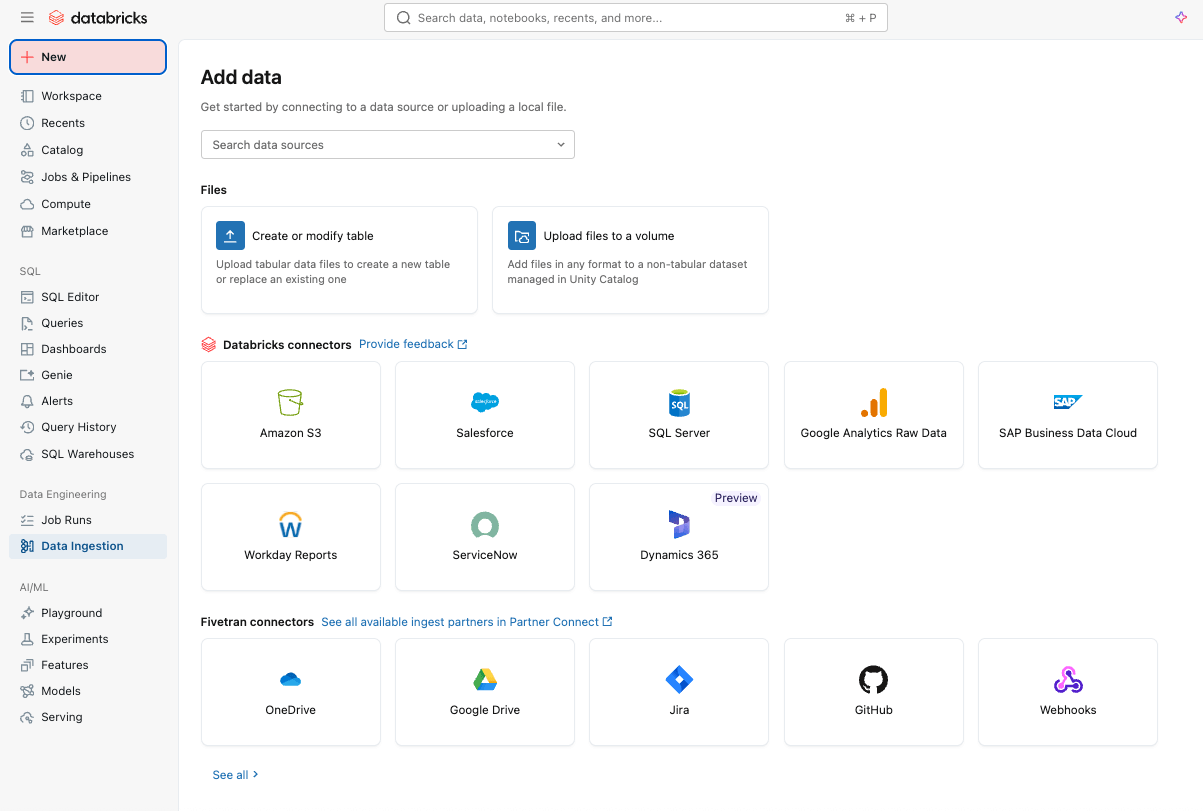
Ingestión de datos simple y eficiente con Lakeflow Connect
Puedes empezar por ingerir datos fácilmente en tu plataforma con Lakeflow Connect mediante una interfaz de apuntar y hacer clic o una API simple.
Puede incorporar tanto datos estructurados como no estructurados de una amplia gama de fuentes compatibles en Azure Databricks, incluidas las aplicaciones SaaS populares (p. ej., Salesforce, Workday, ServiceNow), bases de datos (p. ej., SQL Server), almacenamiento en la nube, buses de mensajes y más. Lakeflow Connect también es compatible con patrones de red de Azure, como Private Link y la implementación de puertas de enlace de incorporación en una VNet para bases de datos.
Para la ingestión en tiempo real, consulte Zerobus Ingest, una API de escritura directa sin servidor en Lakeflow en Azure Databricks. Envía los datos de eventos directamente a la plataforma de datos, lo que elimina la necesidad de un bus de mensajes para una ingestión más simple y de menor latencia.
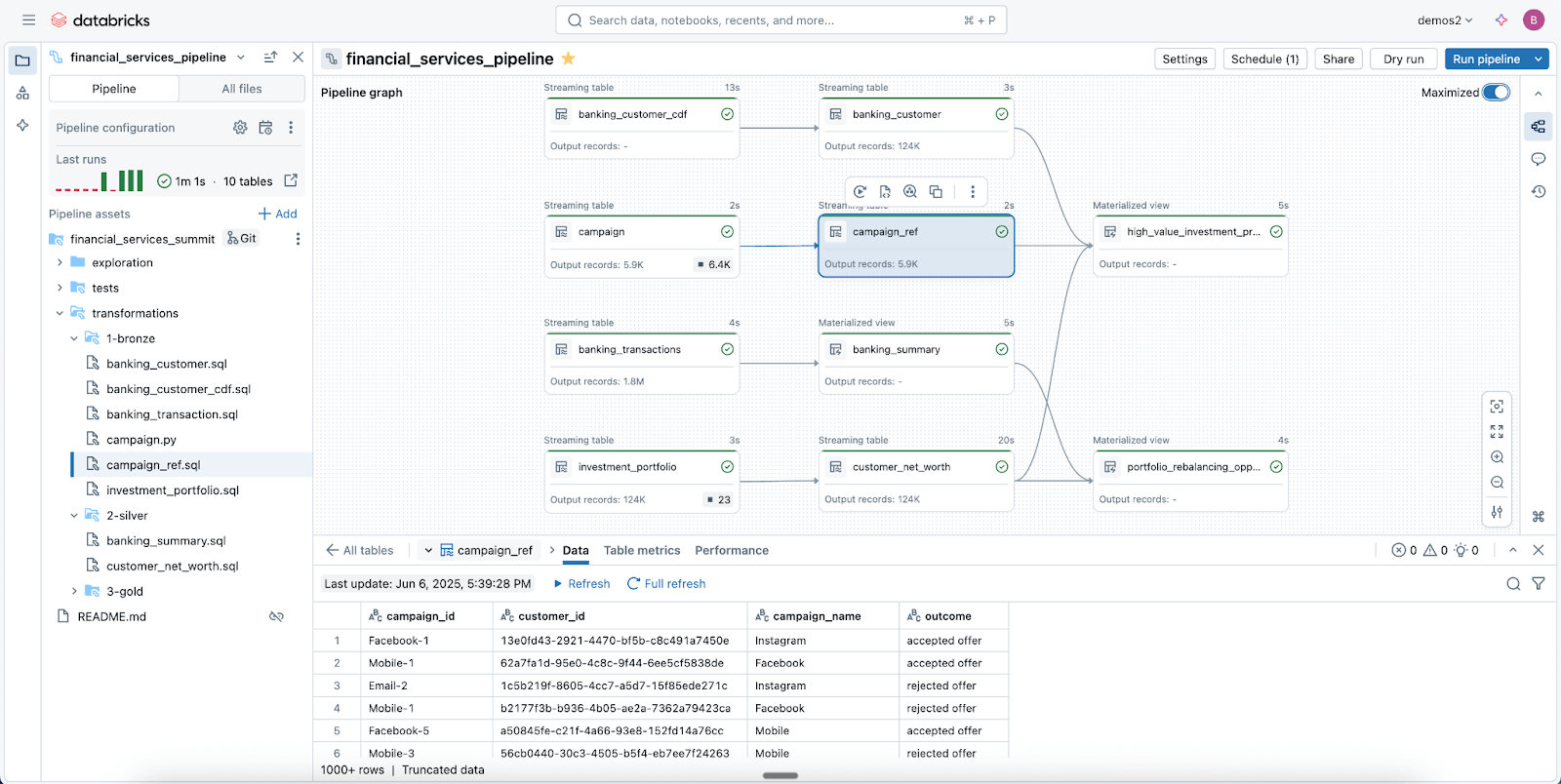
Canalizaciones de datos confiables y simplificadas con Spark Declarative Pipelines
Aproveche Lakeflow Spark Declarative Pipelines (SDP) para limpiar, dar forma y transformar sus datos fácilmente de la manera que su negocio lo necesite.
SDP le permite crear ETL por lotes y de streaming confiables con solo unas pocas líneas de Python (o SQL). Simplemente declare las transformaciones que necesita y SDP se encarga del resto, incluidos el mapeo de dependencias, la infraestructura de implementación y la calidad de los datos.
SDP minimiza el tiempo de desarrollo y la sobrecarga operativa, a la vez que codifica las mejores prácticas de ingeniería de datos listas para usar, lo que facilita la implementación de la incrementalización o de patrones complejos como SCD tipo 1 y 2 con solo unas pocas líneas de código. Es todo el poder de Spark Structured Streaming, simplificado de una forma increíble.
Y como Lakeflow está integrado en Azure Databricks, puedes usar las herramientas de Azure Databricks, como Databricks Asset Bundles (DABs), Lakehouse Monitoring y más, para implementar pipelines gobernados y listos para la producción en minutos.
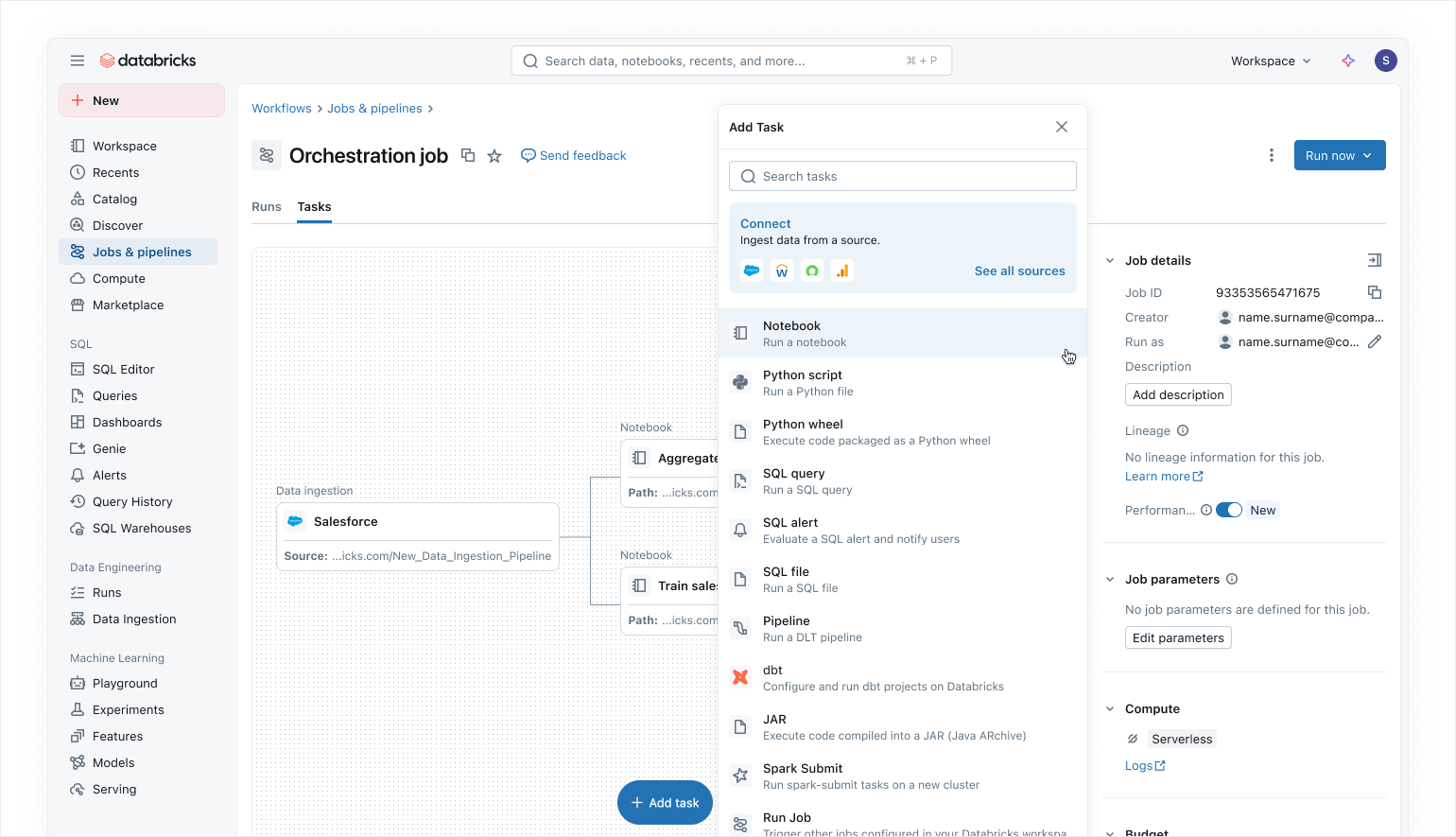
Orquestación moderna que prioriza los datos con Lakeflow Jobs
Use Lakeflow Jobs para orquestar sus cargas de trabajo de datos e IA en Azure Databricks. Con un enfoque moderno y simplificado que prioriza los datos, Lakeflow Jobs es el orquestador más confiable para Databricks, y es compatible con el procesamiento de datos e IA a gran escala y el análisis en tiempo real con una confiabilidad del 99,9 %.
En Lakeflow Jobs, puede visualizar todas sus dependencias coordinando cargas de trabajo de SQL, código Python, paneles, canalizaciones y sistemas externos en un único DAG unificado. La ejecución del flujo de trabajo es simple y flexible con desencadenadores basados en datos como actualizaciones de tablas o llegadas de archivos, y tareas de flujo de control. Gracias a las ejecuciones de relleno sin código y a la observabilidad integrada, Lakeflow Jobs facilita mantener los datos posteriores actualizados, accesibles y precisos.
Como usuarios de Azure Databricks, también pueden actualizar y renovar automáticamente los modelos semánticos de Power BI usando la tarea de Power BI en Lakeflow Jobs (lea más aquí), lo que convierte a Lakeflow Jobs en un orquestador fluido para las cargas de trabajo de Azure.
Seguridad integrada y gobernanza unificada
Con Unity Catalog, Lakeflow hereda los controles centralizados de identidad, seguridad y gobernanza en la ingesta, la transformación y la orquestación. Las conexiones almacenan las credenciales de forma segura, las políticas de acceso se aplican de forma coherente en todas las cargas de trabajo y los permisos granulares garantizan que solo los usuarios y sistemas adecuados puedan leer o escribir datos.
Unity Catalog también proporciona linaje de extremo a extremo desde la ingestión a través de Lakeflow Jobs hasta el análisis posterior y Power BI, lo que facilita el seguimiento de las dependencias y garantiza el cumplimiento. Las tablas del sistema ofrecen visibilidad operativa y de seguridad en todos los trabajos, usuarios y uso de datos para ayudar a los equipos a supervisar la calidad y aplicar las mejores prácticas sin tener que unir registros externos.
Juntos, Lakeflow y Unity Catalog brindan a los usuarios de Azure Databricks pipelines gobernados por defecto, lo que da como resultado una entrega de datos segura, auditable y lista para la producción en la que los equipos pueden confiar.
Lee nuestra publicación de blog sobre cómo Unity Catalog es compatible con OneLake.
Experiencia de usuario y creación flexibles para todos
Además de todas estas características, Lakeflow es increíblemente flexible y fácil de usar, lo que lo convierte en una excelente opción para cualquier persona de su organización, en particular para los desarrolladores.
A los usuarios que priorizan el código les encanta Lakeflow gracias a su potente motor de ejecución y a sus herramientas avanzadas centradas en el desarrollador. Con Lakeflow Pipeline Editor, los desarrolladores pueden aprovechar un IDE y utilizar herramientas de desarrollo robustas para crear sus pipelines. Lakeflow Jobs también incluye creación que prioriza el código y herramientas de desarrollo con DB Python SDK y DABs para patrones de CI/CD repetibles.
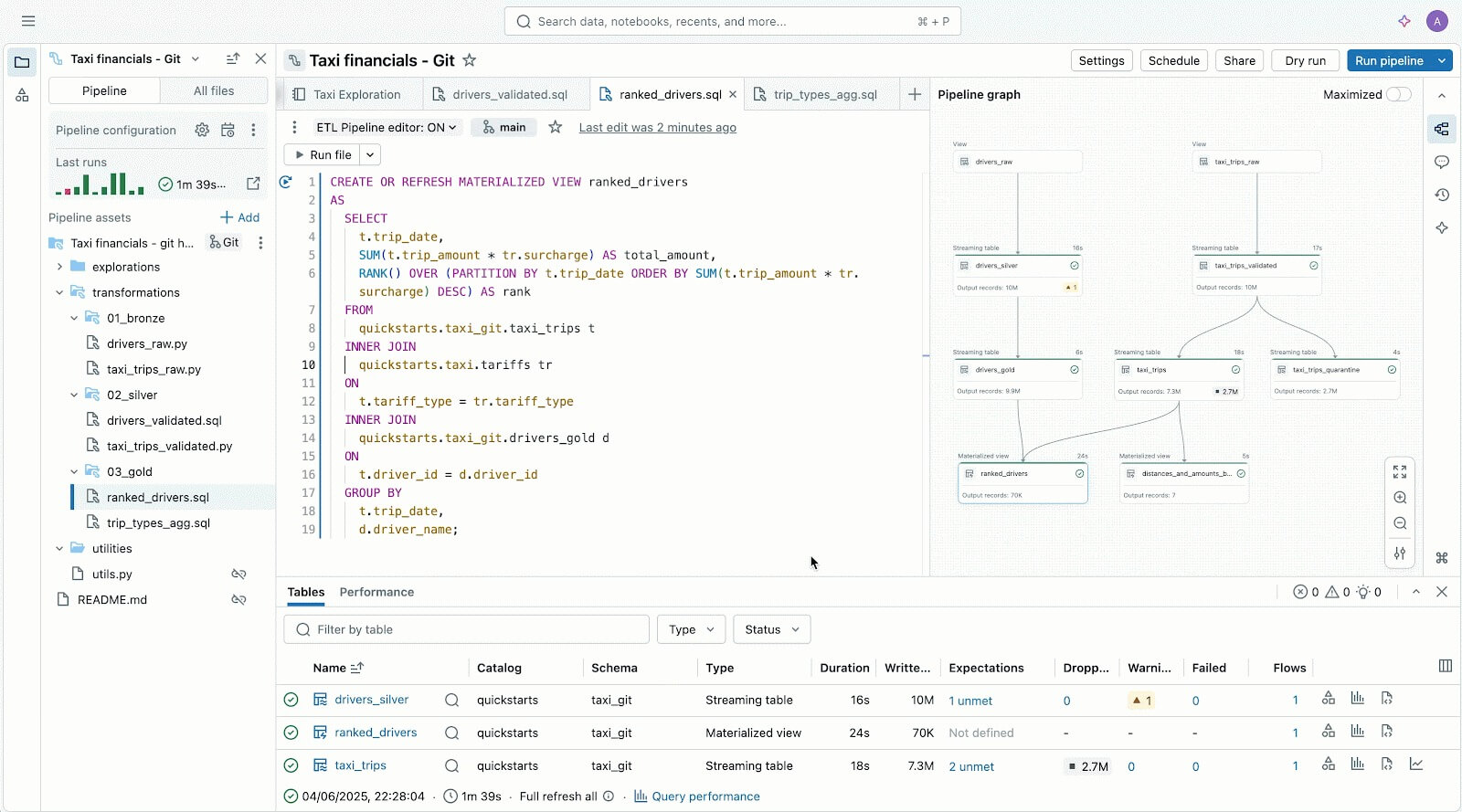
Lakeflow Pipelines Editor para ayudarte a crear y probar pipelines de datos, todo en un solo lugar.
Para los recién llegados y los usuarios de negocio, Lakeflow es muy intuitivo y fácil de usar, con una sencilla interfaz de apuntar y hacer clic y una API para la ingesta de datos a través de Lakeflow Connect.
Menos conjeturas y una solución de problemas más precisa con la observabilidad nativa
Las soluciones de supervisión a menudo están aisladas de su plataforma de datos, lo que dificulta la puesta en funcionamiento de la observabilidad y hace que sus canalizaciones sean más propensas a fallar
Lakeflow Jobs en Azure Databricks brinda a los ingenieros de datos la visibilidad profunda y de extremo a extremo que necesitan para comprender y resolver rápidamente los problemas en sus canalizaciones. Con las capacidades de observabilidad de Lakeflow, puede detectar inmediatamente problemas de rendimiento, cuellos de botella de dependencias y tareas fallidas en una única IU con nuestra lista de ejecuciones unificada.
Las tablas del sistema de Lakeflow y el linaje de datos integrado con Unity Catalog también proporcionan un contexto completo de los conjuntos de datos, los espacios de trabajo, las consultas y los impactos posteriores, lo que agiliza el análisis de la causa raíz. Con las recién lanzadas tablas del sistema en trabajos, puede crear paneles personalizados para todos sus trabajos y supervisar de forma centralizada el estado de estos.
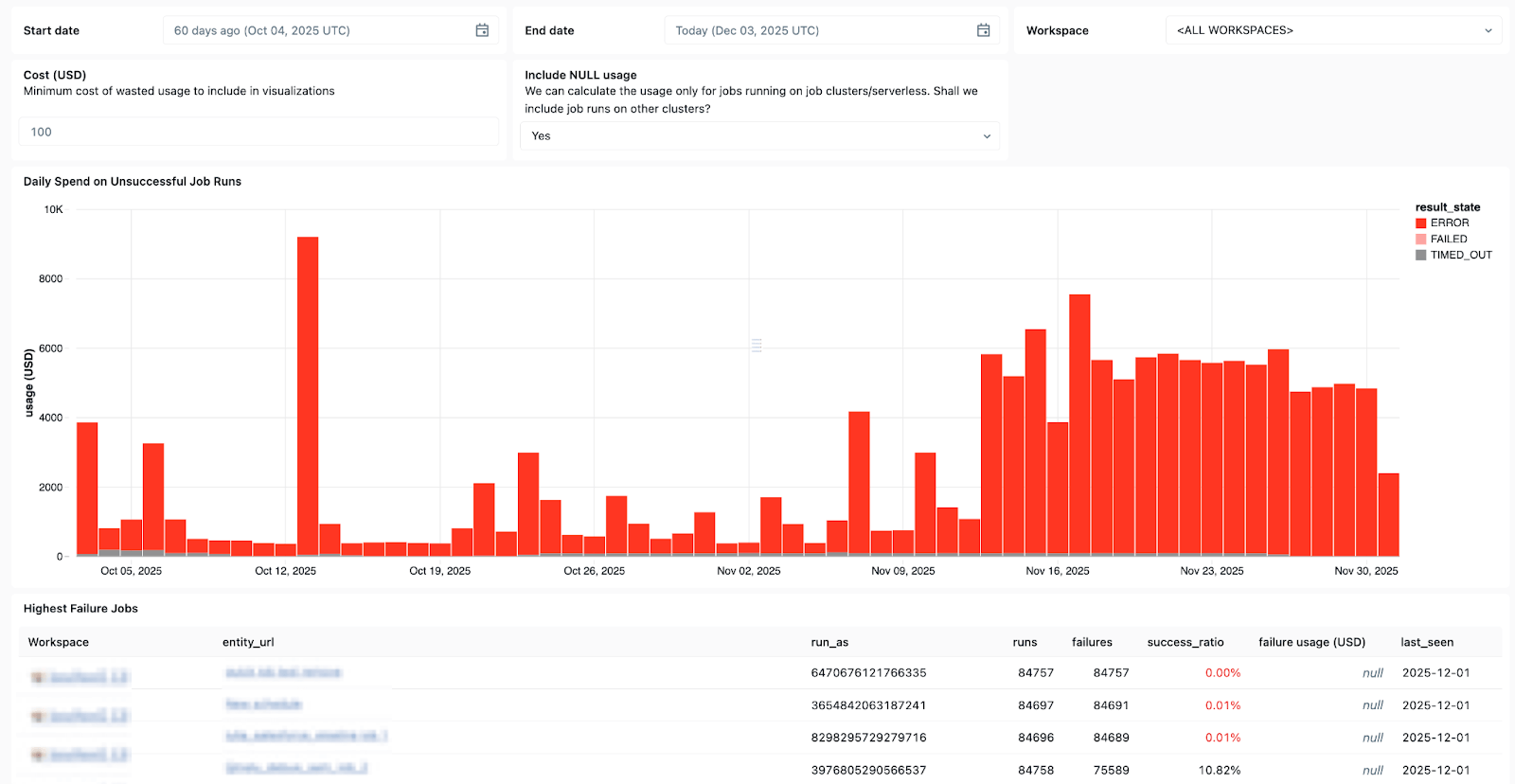
Usa las System Tables en Lakeflow para ver qué trabajos fallan con más frecuencia, las tendencias generales de errores y los mensajes de error comunes.
Y cuando surgen problemas, Databricks Assistant está aquí para ayudar.
Databricks Assistant es un copiloto de IA contextual integrado en Azure Databricks que le ayuda a recuperarse más rápido de los fallos al permitirle crear y solucionar rápidamente problemas de notebooks, consultas SQL, trabajos y paneles utilizando el lenguaje natural.
Pero el Asistente hace más que depurar. También puede generar código PySpark/SQL y explicarlo con características basadas en Unity Catalog, por lo que entiende su contexto. También se puede utilizar para ejecutar sugerencias, mostrar patrones y realizar el descubrimiento de datos y EDA, lo que lo convierte en un gran compañero para todas sus necesidades de ingeniería de datos.
Sus costos y consumo bajo control
Cuanto más grandes sean tus pipelines, más difícil es dimensionar correctamente el uso de los recursos y mantener los costos bajo control.
Con el procesamiento de datos sin servidor de Lakeflow, Databricks optimiza el procesamiento de forma automática y continua para minimizar el desperdicio de inactividad y el uso de recursos. Los ingenieros de datos pueden decidir si ejecutar sin servidor en modo de Rendimiento para cargas de trabajo de misión crítica o en modo Estándar, donde el costo es más importante, para una mayor flexibilidad.
Lakeflow Jobs también permite la reutilización de clústeres, por lo que varias tareas de un flujo de trabajo pueden ejecutarse en el mismo clúster de trabajo, eliminando los retrasos de arranque en frío, y admite un control detallado, por lo que cada tarea puede dirigirse al clúster de trabajo reutilizable o a su propio clúster dedicado. Junto con el procesamiento sin servidor, la reutilización de clústeres minimiza los arranques para que los ingenieros de datos puedan reducir los gastos operativos y obtener un mayor control sobre sus costos de datos.
Microsoft Azure + Databricks Lakeflow: una combinación ganadora probada
Databricks Lakeflow permite a los equipos de datos avanzar con mayor rapidez y fiabilidad, sin comprometer la gobernanza, la escalabilidad ni el rendimiento. Con la ingeniería de datos perfectamente integrada en Azure Databricks, los equipos pueden beneficiarse de una única plataforma de extremo a extremo que satisface todas las necesidades de datos e IA a escala.
Los clientes de Azure ya han visto resultados positivos al integrar Lakeflow en su stack, que incluyen:
- Desarrollo más rápido de canalizaciones: Los equipos pueden crear e implementar canalizaciones de datos listas para la producción hasta 25 veces más rápido y reducir el tiempo de creación en un 70 %.
- Mayor rendimiento y confiabilidad: Algunos clientes están experimentando una mejora del rendimiento de 90x y reduciendo los tiempos de procesamiento de horas a minutos.
- Más eficiencia y ahorro de costos: La automatización y el procesamiento optimizado reducen drásticamente los gastos operativos. Los clientes han reportado ahorros de hasta decenas de millones de dólares anuales y reducciones en los costos de ETL de hasta un 83 %.
Lee las historias de éxito de clientes de Azure y Lakeflow en nuestro blog de Databricks.
¿Sientes curiosidad por Lakeflow? Prueba Databricks gratis para ver de qué se trata la plataforma de ingeniería de datos.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.