La Próxima Era del Lakehouse Abierto: Apache Iceberg™ v3 en Vista Previa Pública en Databricks
Rendimiento completo. Interoperabilidad completa. Sin compensaciones.
por Ryan Blue, Daniel Weeks, Jason Reid, Benjamin Mathew y Hao Jiang
• Unity Catalog es el centro de su ecosistema Iceberg: sin importar qué motores o catálogos utilice su equipo, cada herramienta lee los mismos datos con una gobernanza consistente y granular
• Iceberg v3 introduce Row Lineage, Deletion Vectors y VARIANT, lo que permite cargas de trabajo de procesamiento incremental de alto rendimiento y datos semiestructurados
• Iceberg v3 pone fin a la compensación entre rendimiento e interoperabilidad: Deletion Vectors, Row Lineage y VARIANT forman parte de la especificación abierta, por lo que los equipos de datos obtienen estas mejoras de rendimiento sin sacrificar la compatibilidad entre motores
Hoy, el soporte de Databricks para Iceberg v3 entra en Vista Previa Pública, desbloqueando las últimas innovaciones de la comunidad Iceberg de forma nativa en el lakehouse abierto.
Iceberg v3 marca un gran avance para los formatos de tabla abiertos, desbloqueando casos de uso en el procesamiento incremental de datos y el análisis de datos semiestructurados que anteriormente requerían soluciones alternativas frágiles. Más allá de esto, Iceberg v3 representa una innovación tecnológica significativa al unificar aún más la capa de datos de Iceberg y Delta Lake, eliminando la necesidad de reescribir datos al crear pipelines interoperables.
Aquí te mostramos qué hay de nuevo en Iceberg v3, por qué es importante y por qué Databricks es el mejor lugar para ejecutar tu lakehouse.
¿Qué hay de nuevo en Iceberg v3?
Las tablas de Iceberg v3 gestionadas por Unity Catalog Managed Iceberg admiten el linaje de filas (Row Lineage), los vectores de eliminación (Deletion Vectors) y VARIANT, desbloqueando nuevos casos de uso y beneficios de rendimiento significativos. Databricks también puede interoperar con estas características en tablas externas de Iceberg (tablas de Iceberg registradas en otros catálogos), lo que permite a los clientes crear agentes y aplicaciones de IA contra sus datos, independientemente de dónde residan.
Procesamiento Incremental a Escala: Linaje de Filas y Vectores de Eliminación
La mayoría de los datos llegan como un flujo de cambios (INSERTs, UPDATEs, MERGEs, DELETEs) en lugar de en lotes, típicamente provenientes de bases de datos operacionales, flujos de eventos y APIs de terceros. Históricamente, procesar estos cambios requería resolver dos problemas difíciles:
- Identificar qué filas cambiaron en los conjuntos de datos bronce
- Aplicar esos cambios de manera eficiente a los conjuntos de datos plata/oro
Los equipos solían recurrir a escaneos completos de tablas o a sistemas externos de CDC para detectar cambios, y a costosas reescrituras de archivos para aplicarlos. Esto resultaba en pipelines lentos, costosos de mantener y propensos a la deriva y a silos de datos.
Ahora, el linaje de filas permite a los equipos identificar rápidamente qué filas cambiaron. Cada fila en una tabla Iceberg v3 tiene un ID de fila permanente y un número de secuencia que refleja cuándo se modificó por última vez la fila.
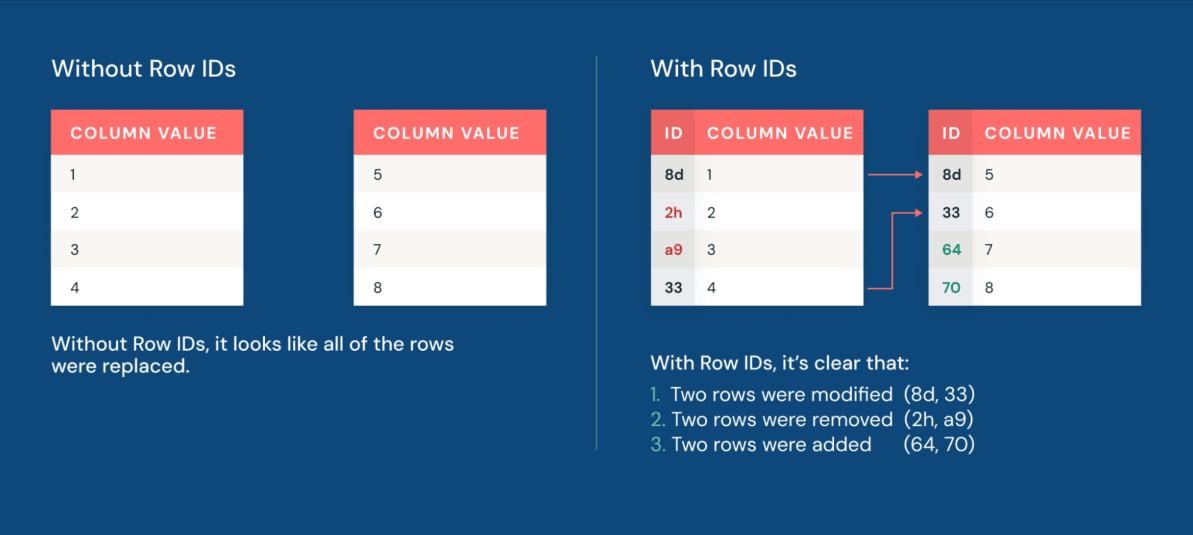
Además, los vectores de eliminación hacen que la aplicación de cambios a los conjuntos de datos sea más eficiente que nunca. Los vectores de eliminación permiten a Iceberg rastrear qué filas se han eliminado lógicamente sin reescribir inmediatamente los archivos de datos subyacentes. En lugar de eliminar físicamente las filas reescribiendo grandes archivos Parquet, el motor escribe un archivo de eliminación ligero junto a los datos. El resultado es un rendimiento de manipulación de datos hasta 10 veces más rápido que el enfoque tradicional de copia en escritura (copy-on-write).

Con los vectores de eliminación ahora nativos en Iceberg, Geodis puede construir su Lakehouse de Iceberg en Databricks sin comprometer el rendimiento o la elección del motor.
“Ahora que los vectores de eliminación han llegado a Iceberg, podemos centralizar nuestro patrimonio de datos de Iceberg en Unity Catalog, mientras aprovechamos el motor de nuestra elección y mantenemos un rendimiento de primer nivel.” —Delio Amato, Arquitecto Jefe y Director de Datos, Geodis
Juntos, el linaje de filas y los vectores de eliminación hacen que CDC sea una propiedad nativa de la tabla misma. Los equipos pueden construir pipelines que se centran en procesar incrementalmente solo lo que realmente cambió, reduciendo costos e impulsando un tiempo de obtención de información más rápido para cada analista y científico de datos aguas abajo.

Datos Semiestructurados como Ciudadanos de Primera Clase a través de VARIANT
Los registros (logs), las respuestas de API, los flujos de clics y las cargas útiles de IoT son fuentes de datos semiestructurados muy valiosas. A medida que evolucionan, los modelos de IA pueden adaptarse junto con ellos, aprendiendo directamente de las señales cambiantes del mundo real.
Sin embargo, históricamente, los equipos de datos se enfrentaron a una elección difícil al trabajar con datos semiestructurados. Un enfoque estándar era imponer esquemas rígidos, pero esto conducía a pipelines frágiles que se rompían cada vez que los datos de origen evolucionaban. Otra solución alternativa era almacenar los datos como volcados de cadenas de texto sin formato, pero esto hacía que las consultas fueran muy complejas y lentas. Ningún enfoque era escalable.
El tipo VARIANT de Iceberg v3 resuelve esta disyuntiva. VARIANT es un tipo de columna nativo que almacena cargas útiles semiestructuradas junto con columnas relacionales en la misma tabla Iceberg. Esto no requiere aplanamiento, almacenamiento en un sistema separado, ni un pipeline ETL para la normalización. Más bien, los equipos de datos pueden ingerir datos semiestructurados sin procesar tal cual y consultarlos con SQL estándar.

Panther utiliza VARIANT para potenciar la ingesta y el análisis a gran escala de registros de seguridad semiestructurados.
“Unity Catalog e Iceberg v3 desbloquean el poder de los datos semiestructurados a través de VARIANT. Esto permite la interoperabilidad y la recopilación de registros a escala de petabytes y rentable.” —Russell Leighton, Arquitecto Jefe, Panther
Con VARIANT, tus modelos de IA y pipelines de análisis funcionan directamente sobre datos en vivo y en evolución en una única tabla gobernada. Cuando aparecen nuevos campos en las respuestas de la API o entran nuevos tipos de eventos en los flujos de clics, se pueden consultar inmediatamente sin una migración de esquema. Con optimizaciones de rendimiento como el shredding, los clientes pueden beneficiarse del rendimiento similar al columnar en sus datos semiestructurados, desbloqueando pipelines de BI, dashboards y alertas de baja latencia.
Unity Catalog ofrece interoperabilidad y rendimiento para empresas multi-motor y multi-catálogo
Las empresas modernas dependen de múltiples motores y catálogos para admitir diversos casos de uso en unidades de negocio y sistemas heredados. Unity Catalog fue diseñado para permitir la interoperabilidad y la gobernanza entre catálogos, al tiempo que optimiza los diseños de datos en función de los patrones de consulta.
Gobernanza unificada en catálogos y motores
Las APIs abiertas de Unity Catalog permiten a los clientes escribir una vez y leer en cualquier lugar: no más duplicación de datos ni controles de acceso aislados. UC puede federarse a otros catálogos de Iceberg, permitiendo la interoperabilidad bidireccional. Todos los datos de Iceberg en Snowflake, AWS Glue, Salesforce y otros catálogos importantes, pueden ser leídos por Unity Catalog, y todos los datos en UC pueden ser accedidos por esas mismas plataformas de terceros a través de APIs abiertas.
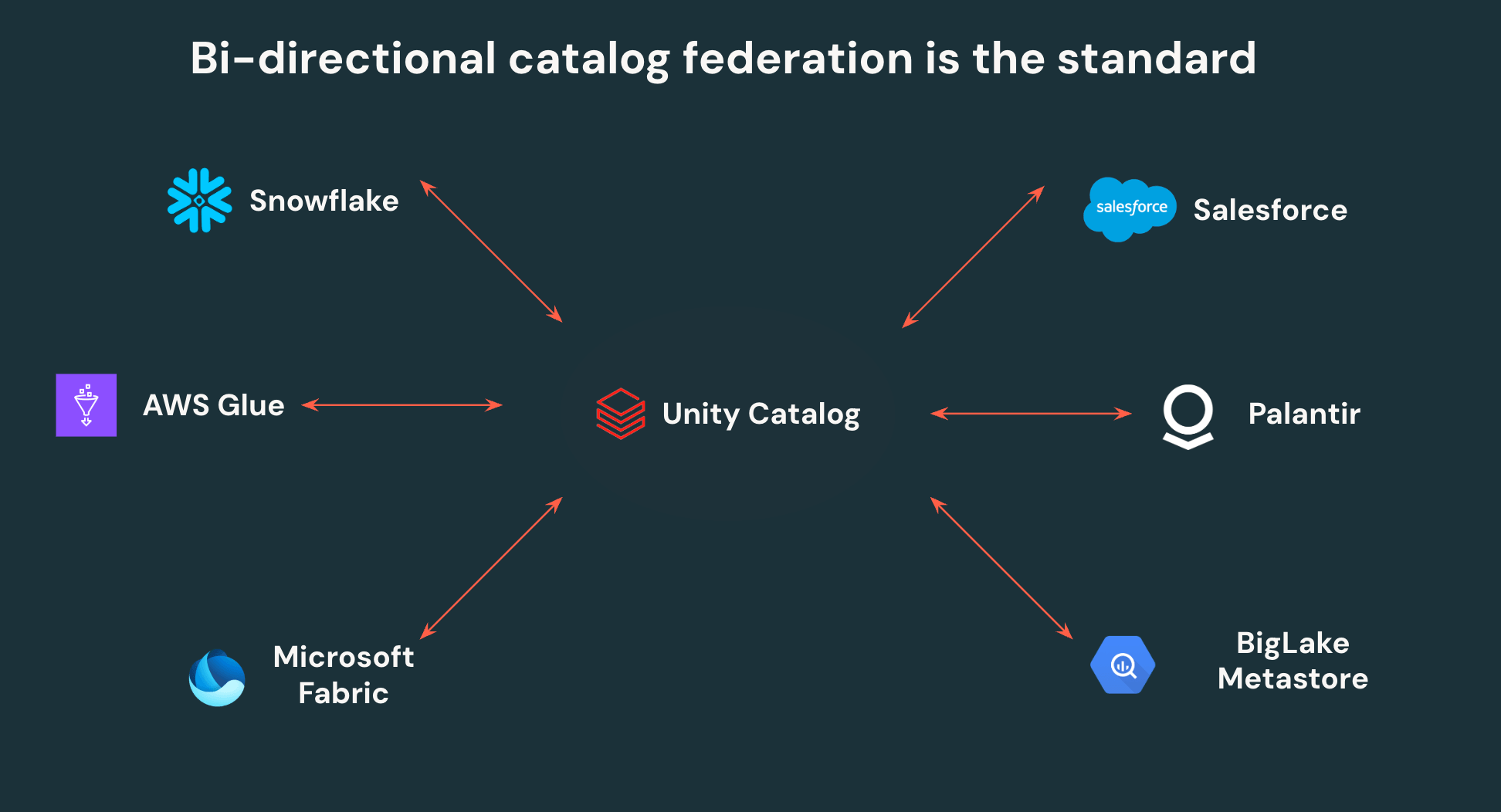
Más allá de esto, Unity Catalog es el primer catálogo que admite control de acceso granular en motores externos, lo que permite a los equipos definir filtros de fila y máscaras de columna una vez y que se apliquen en todas partes donde se acceden los datos. Centralizar la gobernanza en Unity Catalog facilita enormemente a los equipos de seguridad la gobernanza y monitorización de su lakehouse, al tiempo que otorga a los equipos de datos autonomía para apuntar cualquier herramienta a su lakehouse.

Interoperabilidad de Delta y Iceberg
Delta Lake con UniForm desbloquea la interoperabilidad entre los ecosistemas Delta Lake e Iceberg de los clientes: escribe una vez en Delta Lake y lee como Iceberg desde Snowflake, BigQuery, Redshift, Athena, Trino o cualquier otro motor de Iceberg. Con Iceberg v3 adoptando Deletion Vectors, Row Lineage y VARIANT de forma nativa, los clientes ya no se enfrentan a una disyuntiva entre las características de rendimiento de Delta Lake y la compatibilidad con Iceberg. El resultado es una única copia de datos que sirve a todos los motores de tu stack, sin pipelines de replicación que mantener ni riesgo de deriva. Un proveedor líder de servicios financieros reemplazó un costoso servicio de replicación de tablas completas con UniForm, permitiendo a Snowflake leer directamente de las tablas gestionadas por Unity Catalog.
Rendimiento y optimización automatizados
Más allá de la interoperabilidad, Databricks reúne rendimiento, optimización de diseño y gobernanza en un solo sistema para que los equipos no tengan que unir estas capacidades por su cuenta. Databricks combina el mantenimiento inteligente (Optimización Predictiva), optimizaciones de diseño físico basadas en patrones de consulta (Clustering Líquido Automático) y gobernanza entre motores (Unity Catalog) en una sola capa, sin necesidad de configuración manual.
Otras ofertas gestionadas de Iceberg requieren que los equipos administren el mantenimiento de tablas, el diseño de archivos y la aplicación de políticas de acceso de forma independiente. En Databricks, estas capacidades están unificadas y son automáticas, eliminando toda una clase de sobrecarga operativa y preservando al mismo tiempo la portabilidad total de los datos.
Comienza con Apache Iceberg v3 en Databricks
Iceberg v3 en Databricks está en vista previa pública hoy. Los equipos ahora pueden aprovechar las mejores características de Delta e Iceberg sin sacrificar el rendimiento ni la interoperabilidad.
Iceberg v3 está disponible en Databricks Runtime 18.0+ con Unity Catalog habilitado.
Crear una tabla Iceberg administrada por Unity Catalog con v3 habilitado es fácil:
Crear una tabla Delta administrada por Unity Catalog con UniForm y v3 habilitado es igual de sencillo:
Mirando hacia el futuro: Iceberg v4
Iceberg v3 unifica la capa de datos entre Delta e Iceberg sobre una base de alto rendimiento e interoperable; la próxima frontera es la capa de metadatos. Los ingenieros de Databricks están impulsando activamente varias propuestas principales de Iceberg v4 en la comunidad Apache para hacer que los metadatos sean más simples, rápidos y escalables. Estas incluyen el árbol de metadatos adaptativo, que simplifica la estructura de metadatos para que la mayoría de las operaciones requieran escribir solo un archivo en lugar de varios. Las propuestas adicionales incluyen el soporte de rutas relativas para una reubicación fluida de tablas entre entornos y un modelo de estadísticas modernizado que se extiende a tipos de datos más nuevos como VARIANT y GEOMETRY. En conjunto, estos avances significarán una ingesta más rápida, una planificación de consultas más eficiente y una gestión de tablas más simple a escala empresarial. Estamos entusiasmados de seguir avanzando en la especificación de Iceberg con la comunidad.
Más información en Data and AI Summit
Comienza con Iceberg v3 y únete a nosotros en el próximo Data and AI Summit en San Francisco, del 15 al 18 de junio de 2026, para obtener más información sobre nuestra hoja de ruta de Iceberg y el trabajo en todo el ecosistema.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.