Chatbot de fútbol americano autooptimizable guiado por expertos en el dominio en Databricks
Una guía práctica para crear, implementar, evaluar y controlar un asistente agéntico que ayuda a los coordinadores defensivos a anticipar las tendencias del oponente y se optimiza continuamente en función de los comentarios de los expertos en la materia.
por Wesley Pasfield y Nick Ragonese
- Propósito: Crear un asistente agéntico orientado al entrenador que responda preguntas como “¿Qué hará esta ofensiva?” utilizando herramientas controladas y de nivel de producción sobre datos de jugada por jugada, participación y de la plantilla.
- Enfoque: Crear un agente de llamada de herramientas con funciones de Unity Catalog (análisis de SQL sobre Delta) y desplegarlo mediante Agent Framework con MLflow Tracing. Implementar un bucle de autooptimización donde los comentarios de los SME capturados en las sesiones de etiquetado de MLflow entrenan a los jueces alineados (align()) que impulsan la mejora automática de prompts (optimize_prompts()), codificando el conocimiento experto sobre fútbol directamente en el sistema.
- Resultado: Los coordinadores obtienen tendencias adaptadas a la situación (down y distancia, formación/personal, ofensiva de dos minutos, índices de jugadas de pantalla) con iteración rápida y controles de calidad listos para la preparación de la semana del partido. Los desarrolladores obtienen una arquitectura reutilizable para cualquier dominio: capturar los comentarios de los expertos, alinear a los evaluadores con lo que significa “bueno” para tu caso de uso y dejar que el sistema mejore continuamente con la optimización de prompts guiada por los evaluadores alineados.
Los jueces de LLM genéricos y los prompts estáticos no logran capturar los matices específicos del dominio. Determinar qué hace que un análisis defensivo de fútbol americano sea “bueno” requiere un conocimiento profundo del fútbol americano: esquemas de cobertura, tendencias de formación, contexto situacional. Los evaluadores de propósito general pasan esto por alto. Lo mismo ocurre con la revisión legal, el triage médico, la due diligence financiera o cualquier dominio en el que el juicio de un experto es importante.
Esta publicación explica una arquitectura para agentes autooptimizados construida sobre Databricks Agent Framework, donde la experiencia humana específica de la empresa mejora continuamente la calidad de la IA mediante MLflow y los desarrolladores controlan toda la experiencia. En esta publicación, utilizamos como ejemplo un asistente de coordinador defensivo (CD) de fútbol americano: un agente de invocación de herramientas que puede responder preguntas como "¿Quién recibe el balón en una formación de 11 jugadores en 3.ª y 6?" o "¿Qué hace el oponente en los últimos 2 minutos de cada mitad?". El siguiente ejemplo muestra a este agente interactuando con un usuario a través de Databricks Apps.

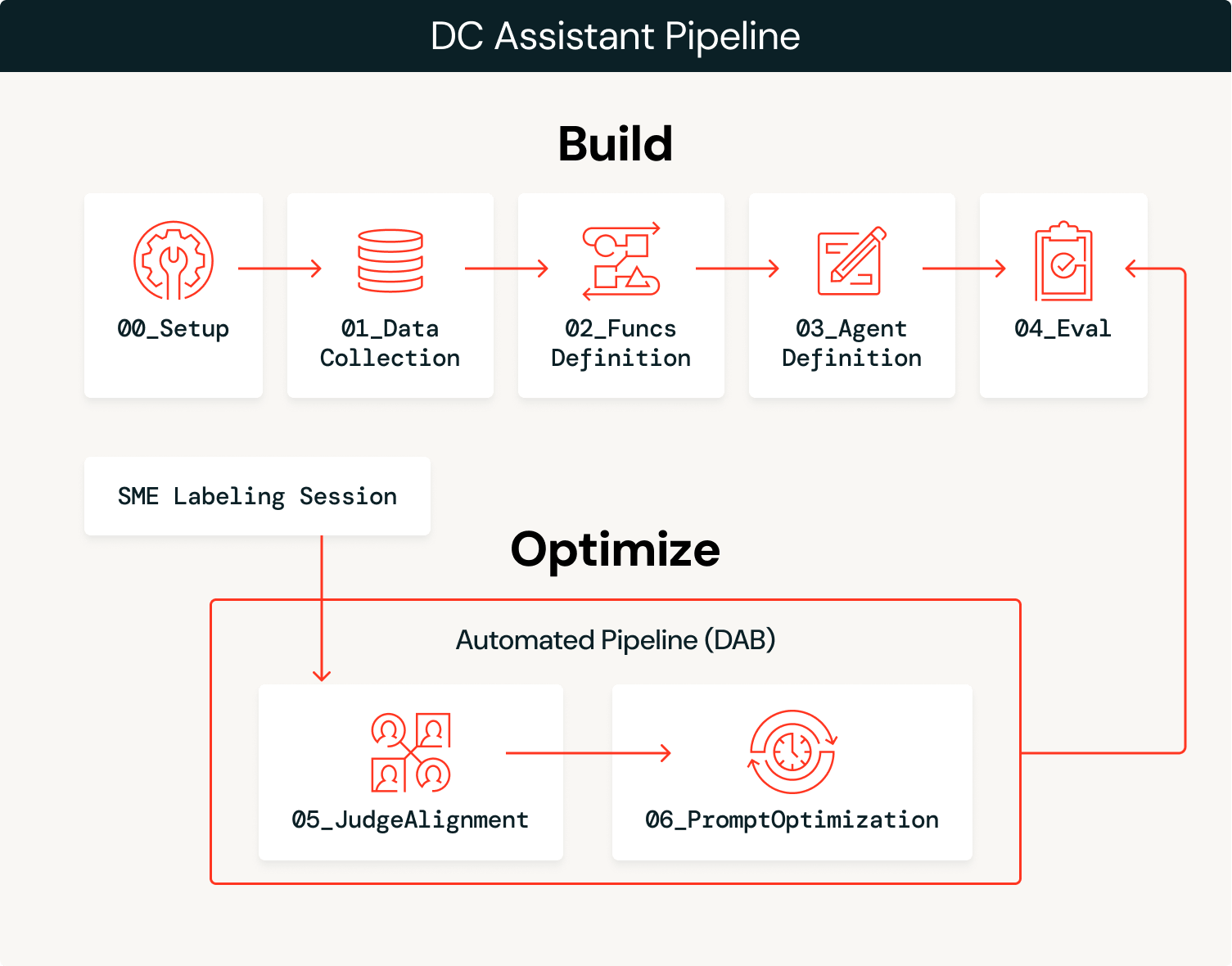
De agente a sistema autooptimizable
La solución tiene dos fases: crear el agente y, luego, optimizarlo continuamente con los comentarios de expertos.
Crear
- Ingesta de datos: cargue los datos de dominio (jugada por jugada, participación, listas de jugadores) en tablas Delta gobernadas en Unity Catalog.
- Ingerimos dos años (2023–2024) de datos de participación y jugada por jugada de fútbol americano de
nflreadpycomo los datos para este agente.
- Ingerimos dos años (2023–2024) de datos de participación y jugada por jugada de fútbol americano de
- Crear herramientas: defina funciones de SQL como herramientas de Unity Catalog que el agente puede llamar, aprovechando los datos extraídos.
- Define e implementa el agente: conecta las herramientas a un
ResponsesAgent, registra un prompt del sistema de referencia en el Prompt Registry e impleméntalo en Model Serving. - Evaluación inicial: ejecute la evaluación automatizada con jueces de LLM y registre los seguimientos utilizando versiones de referencia de jueces personalizados.
Optimizado
- Capturar los comentarios de los expertos: Los SME revisan los resultados del agente y proporcionan comentarios estructurados a través de sesiones de etiquetado de MLflow.
- Alinear jueces: Usa la función
align()de MLflow para calibrar el juez LLM de referencia para que coincida con las preferencias de los SME, enseñándole qué es lo "bueno" para este dominio. - Optimizar prompts: La función
optimize_prompts()de MLflow utiliza un optimizador GEPA guiado por el juez alineado para mejorar iterativamente el prompt del sistema original. - Repetir: Cada sesión de etiquetado de MLflow se utiliza para mejorar el juez, que a su vez se utiliza para optimizar el prompt del sistema. Todo este proceso se puede automatizar para promover automáticamente nuevas versiones de prompts que superen los puntos de referencia de rendimiento, o puede informar las actualizaciones manuales del agente, como agregar más herramientas o datos, según los modos de falla observados.
La fase de construcción te lleva a un prototipo inicial y la fase de optimización te acelera hacia la producción, optimizando continuamente tu agente utilizando los comentarios de los expertos en el dominio como motor.
descripción general de la arquitectura
El agente equilibra el probabilismo y el determinismo: un LLM interpreta la intención semántica de las consultas de los usuarios y selecciona las herramientas adecuadas, mientras que las funciones SQL deterministas extraen datos con un 100 % de precisión. Por ejemplo, cuando un entrenador pregunta “¿Cómo ataca nuestro oponente el Blitz?”, el LLM lo interpreta como una solicitud de análisis de la presión al pasador y la cobertura, y selecciona success_by_pass_rush_and_coverage(). La función SQL devuelve estadísticas exactas de los datos subyacentes. Al usar las funciones de Unity Catalog, garantizamos que las estadísticas sean 100 % precisas, mientras que el LLM se encarga del contexto conversacional.
| Paso | Tecnología |
|---|---|
| Ingresar datos | Delta Lake + Unity Catalog |
| Crear herramientas | Funciones de Unity Catalog |
| Desplegar agente | ResponsesAgent + Servicio de modelos a través de agents.deploy() |
| Evaluar con un LLM como juez | MLflow GenAI evaluate() con jueces integrados y personalizados |
| Recopilar comentarios | MLflow sesiones de etiquetado para recibir comentarios de SME |
| Alinear jueces | MLflow align() con un optimizador SIMBA personalizado |
| Optimizar prompts | MLflow optimize_prompts() usando un optimizador GEPA |
Repasemos cada paso con el código y los resultados de la implementación del Asistente de DC.
Crear
1. Ingerir datos.
Un notebook de configuración (00_setup.ipynb) define todas las variables de configuración globales utilizadas en todo el flujo de trabajo: catálogo/esquema del workspace, experimento de MLflow, endpoints de LLM, nombres de modelos, conjuntos de datos de evaluación, nombres de herramientas de Unity Catalog y configuraciones de autenticación. Esta configuración se guarda en config/dc_assistant.json y la cargan todos los notebooks posteriores, lo que garantiza la coherencia en todo el pipeline. Este paso es opcional, pero ayuda con la organización general.
Con esta configuración, cargamos datos de fútbol americano a través de nflreadpy y aplicamos un procesamiento incremental para prepararlos para el consumo del agente: eliminamos las columnas no utilizadas, estandarizamos los esquemas y almacenamos tablas Delta limpias en Unity Catalog. Este es un ejemplo sencillo de cómo cargar los datos que no abarca gran parte del procesamiento de datos:
Los resultados de este proceso son tablas Delta gobernadas en Unity Catalog (jugada por jugada, participación, listas de jugadores, equipos, jugadores) que están listas para la creación de herramientas y el consumo de agentes.
2. Crear herramientas.
El agente necesita herramientas deterministas para consultar los datos subyacentes. Las definimos como funciones SQL de Unity Catalog que calculan las tendencias ofensivas en diversas dimensiones situacionales. Cada función toma parámetros como team y season y devuelve estadísticas agregadas que el agente puede usar para responder las preguntas del coordinador. Solo usamos funciones basadas en SQL para este ejemplo, pero es posible configurar funciones de UC basadas en Python, índices de búsqueda vectorial, herramientas del Protocolo de Contexto del Modelo (MCP) y espacios de Genie como funcionalidad adicional que un agente puede aprovechar para complementar el LLM que supervisa el proceso.
En el siguiente ejemplo, se muestra success_by_pass_rush_and_coverage(), que computa las divisiones de pases y carreras, los EPA (puntos esperados agregados), la tasa de éxito y las yardas ganadas, agrupados por número de “pass rushers” (jugadores que presionan al mariscal) y tipo de cobertura defensiva. La función incluye un COMMENT que describe su propósito, el cual el LLM utiliza para determinar cuándo llamarla.
Debido a que estas funciones se encuentran en Unity Catalog, heredan el modelo de gobernanza de la plataforma: controles de acceso basados en roles, seguimiento de linaje y detectabilidad en todo el workspace. Los equipos pueden encontrar y reutilizar herramientas sin duplicar la lógica, y los administradores mantienen la visibilidad de los datos a los que puede acceder el agente.
3. Definir y desplegar el agente.
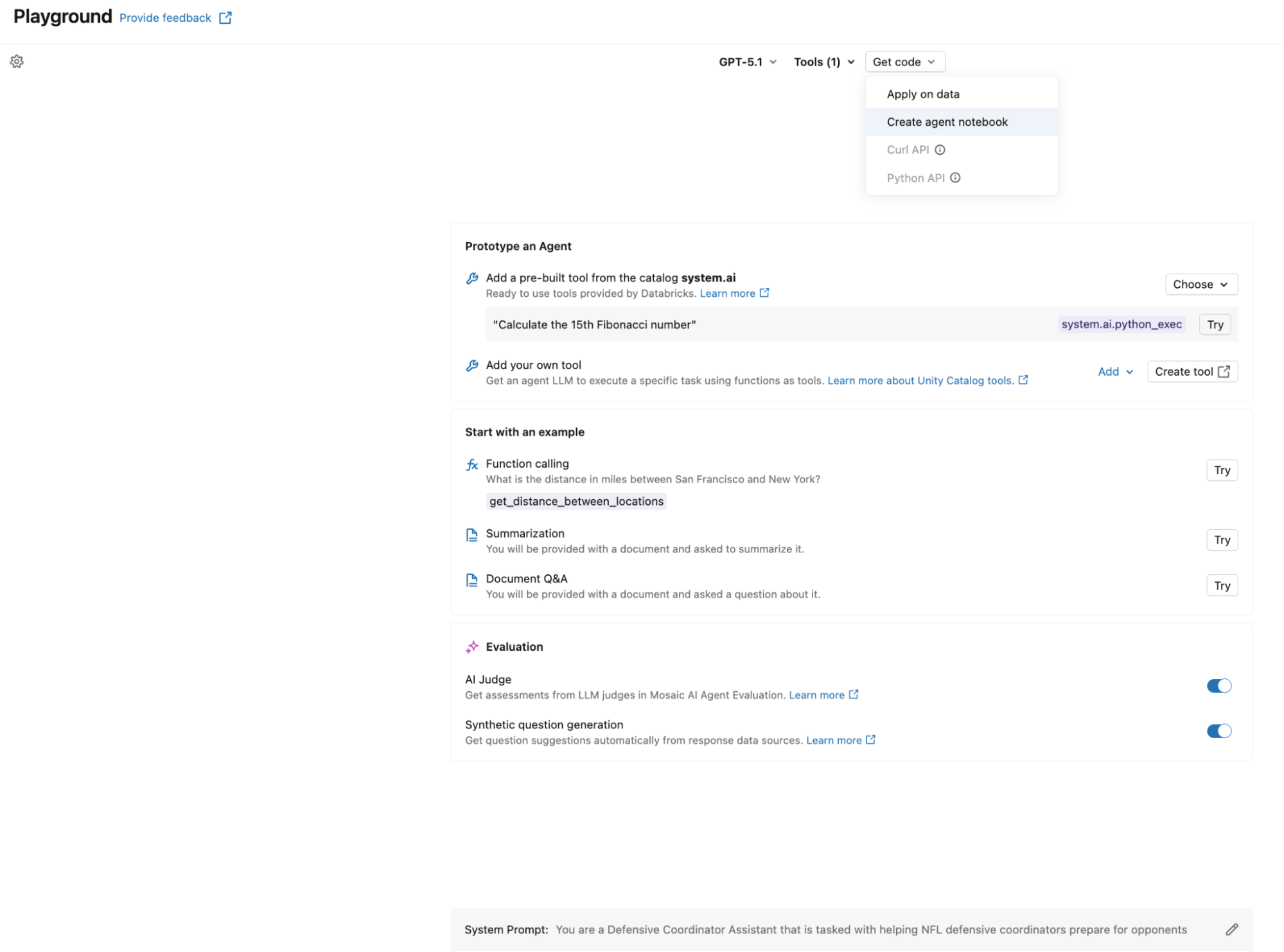
Crear el agente puede ser tan simple como usar el AI Playground. Seleccione el LLM que desea usar, agregue sus herramientas de Unity Catalog, defina su prompt del sistema y haga clic en “Crear notebook del agente” para exportar un notebook que produce un agente en el formato ResponsesAgent. La siguiente captura de pantalla muestra este flujo de trabajo en acción. El notebook exportado contiene la estructura de definición del agente y conecta sus funciones de UC con el agente a través del UCFunctionToolkit.
Para habilitar el ciclo de autooptimización, registramos el prompt del sistema en el Prompt Registry en lugar de hardcodearlo. Esto permite que la fase de optimización actualice el prompt sin volver a implementar el agente:
Una vez que se prueba el código del agente y se registra el modelo en Unity Catalog, implementarlo en un punto de conexión persistente es tan simple como el código que aparece a continuación. Esto crea un punto de conexión de servicio de modelos con MLflow Tracing habilitado, tablas de inferencia para registrar solicitudes/respuestas y escalado automático:
Para el acceso del usuario final, el agente también se puede implementar como una App de Databricks, lo que proporciona una interfaz de chat que los coordinadores y analistas pueden usar directamente sin necesidad de acceso a notebooks o a la API. La captura de pantalla de la introducción muestra esta implementación basada en la App en acción.
4. Evaluación inicial.
Con el agente implementado, ejecutamos una evaluación automatizada con jueces de LLM para establecer una medición de calidad de referencia. MLflow admite múltiples tipos de jueces, y usamos tres en combinación.
Los evaluadores integrados manejan los criterios de evaluación comunes de forma predeterminada. RelevanceToQuery() comprueba si la respuesta aborda la pregunta del usuario. Los evaluadores basados en directrices evalúan en función de reglas específicas basadas en texto de forma de aprobado/reprobado. Definimos una pauta para garantizar que las respuestas utilicen la terminología del fútbol profesional adecuada:
Los jueces personalizados usan make_judge() para una evaluación específica del dominio con control total sobre los criterios de puntuación. Este es el juez que alinearemos con los comentarios de los SME en la fase de optimización:
Una vez definidos todos los jueces, podemos ejecutar una evaluación en el conjunto de datos:
El juez personalizado football_analysis_base proporciona una puntuación de referencia, pero solo refleja un intento de mejor esfuerzo por ofrecer una rúbrica desde cero que el LLM pueda usar para sus juicios, en lugar de una verdadera experiencia en el dominio. La UI de experimentos de MLflow nos muestra el rendimiento del agente en este juez de referencia, así como una justificación de la puntuación en cada ejemplo.
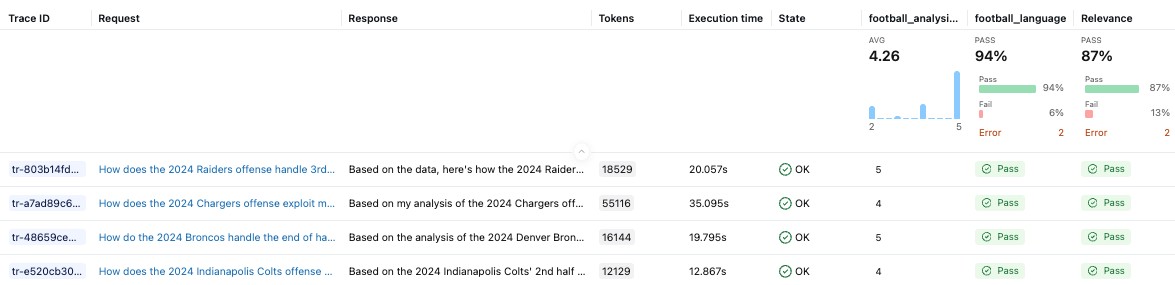

En la fase de optimización, alinearemos el evaluador de análisis de fútbol con las preferencias de los SME, enseñándole lo que realmente significa “bueno” para el análisis del coordinador defensivo.
Optimizado
5. Capturar los comentarios de los expertos.
Con el agente desplegado y la evaluación de referencia completa, entramos en el ciclo de optimización. Aquí es donde la experiencia en el dominio se codifica en el sistema, primero a través de jueces LLM alineados y, luego, directamente en el agente a través de la optimización de los prompts del sistema guiada por nuestro juez alineado.
Comenzamos creando un esquema de etiquetas que utiliza las mismas instrucciones y criterios de evaluación que el juez de análisis de fútbol que creamos con make_judge(). Luego, creamos una sesión de etiquetado que le permite a nuestro experto en el dominio revisar las respuestas para los mismos seguimientos utilizados en el trabajo evaluate() y proporcionar sus puntuaciones y comentarios a través de la aplicación de revisión (que se muestra a continuación).
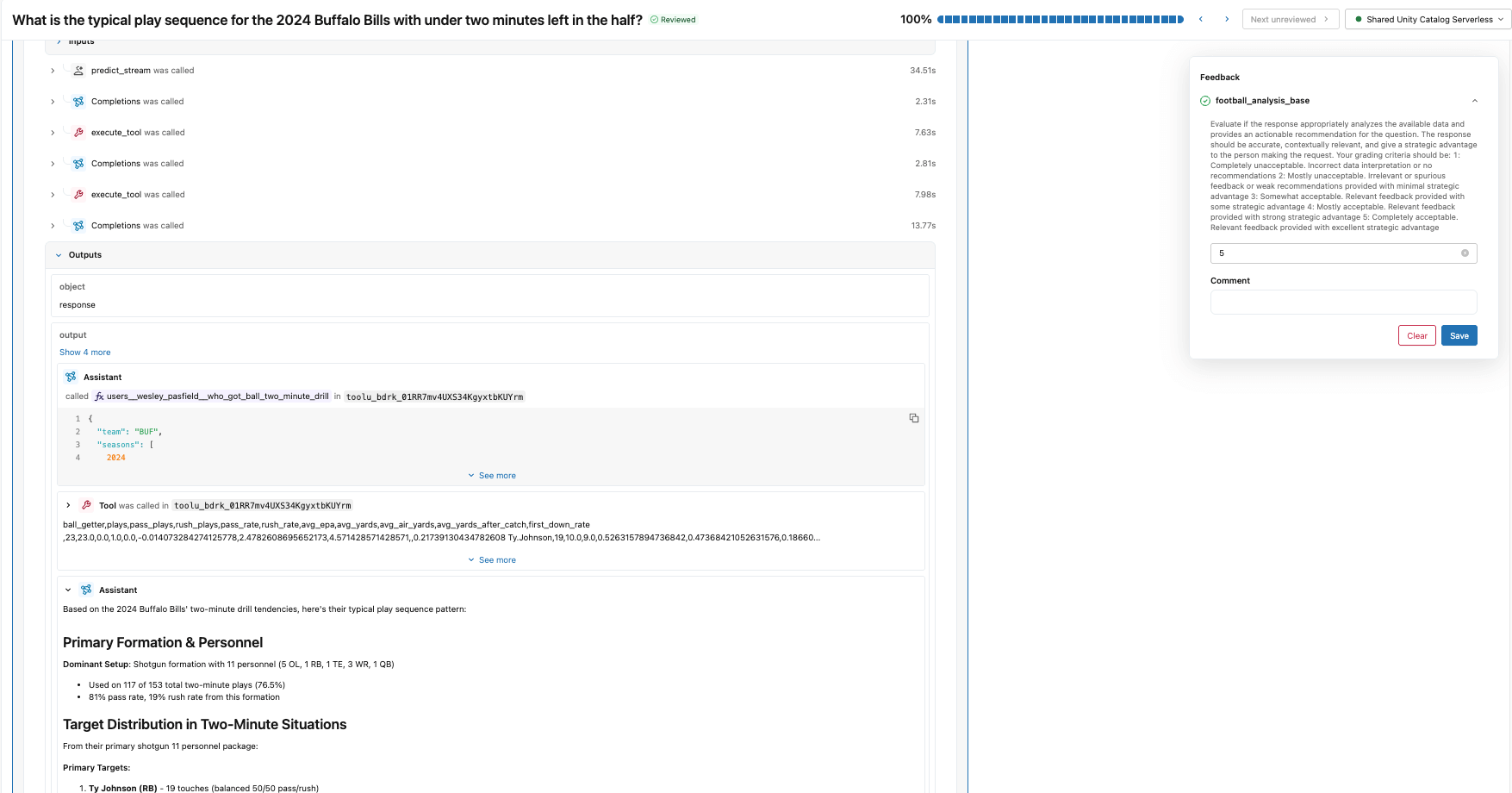
Esta retroalimentación se convierte en la verdad fundamental para la alineación del juez. Al observar dónde divergen las puntuaciones del juez de referencia y del SME, aprendemos en qué se equivoca el juez sobre este dominio específico.
6. Alinear jueces.
Ahora que tenemos seguimientos que incluyen tanto los comentarios de los expertos en el dominio como los de los jueces de LLM, podemos aprovechar la funcionalidad align() de MLflow para alinear nuestro juez de LLM con los comentarios de nuestros expertos en el dominio. Un juez alineado refleja la perspectiva de sus expertos en el dominio y los datos exclusivos de su organización. La alineación incorpora a los expertos en el dominio al proceso de desarrollo de una manera que antes no era posible: los comentarios del dominio dan forma directamente a cómo el sistema mide la calidad, lo que hace que las métricas de rendimiento del agente sean confiables y escalables.
align() le permite utilizar su propio optimizador o el optimizador binario predeterminado SIMBA (Simplified Multi-Bootstrap Aggregation). En este caso, utilizamos un optimizador SIMBA personalizado para calibrar un juez de escala de Likert:
A continuación, recuperamos las trazas que tienen tanto las puntuaciones del juez de LLM como los comentarios de SME que hemos etiquetado durante todo el proceso. Estas puntuaciones emparejadas son las que SIMBA utiliza para aprender la diferencia entre el juicio genérico y el de un experto.
La siguiente captura de pantalla muestra el proceso de alineación en curso. El modelo identifica las brechas entre los jueces de LLM y los comentarios de SME, propone nuevas reglas y detalles para incorporar en el juez a fin de cerrar estas brechas y, luego, evalúa a los nuevos jueces candidatos para ver si superan el rendimiento del juez de referencia.

El resultado final de este proceso es un juez alineado que refleja directamente los comentarios de los expertos del dominio con instrucciones detalladas.

Consejos para una alineación eficaz:
- El objetivo de la alineación es hacerte sentir como si tuvieras a expertos en el dominio sentados a tu lado durante el desarrollo. Este proceso puede dar lugar a puntuaciones de rendimiento más bajas para tu agente de referencia, lo que significa que tu evaluador de referencia estaba subespecificado. Ahora que tienes un evaluador que critica al agente de la misma manera que lo harían tus SME, puedes realizar mejoras manuales o automatizadas para mejorar el rendimiento.
- El proceso de alineación es tan bueno como los comentarios que se proporcionan. Prioriza la calidad sobre la cantidad. Los comentarios detallados y consistentes sobre un número menor de ejemplos (mínimo 10) producen mejores resultados que los comentarios inconsistentes sobre muchos ejemplos.
Definir la calidad suele ser el principal obstáculo para impulsar un mejor rendimiento del agente. Independientemente de la técnica de optimización, si no hay una definición clara de calidad, el rendimiento del agente será decepcionante. Databricks ofrece un taller que ayuda a los clientes a definir la calidad a través de un ejercicio iterativo e interfuncional. Para obtener más información, comunícate con tu equipo de cuentas de Databricks o completa este formulario.
7. Optimizar prompts.
Con un juez alineado que refleje las preferencias de los SME, ahora podemos mejorar automáticamente el prompt del sistema del agente. La función optimize_prompts() de MLflow utiliza GEPA para refinar iterativamente el prompt basándose en la puntuación del juez alineado. GEPA (genético-Pareto), cocreado por el CTO de Databricks, Matei Zaharia, es un algoritmo genético evolutivo de prompts que aprovecha los modelos de lenguaje grandes para realizar mutaciones reflexivas en los prompts, lo que le permite refinar iterativamente las instrucciones y superar a las técnicas tradicionales de aprendizaje por refuerzo en la optimización del rendimiento del modelo.
En lugar de que un desarrollador adivine qué adjetivos agregar al prompt del sistema, el optimizador GEPA evoluciona matemáticamente el prompt para maximizar el puntaje específico definido por el experto. El proceso de optimización requiere un conjunto de datos con respuestas esperadas que guíen al optimizador hacia los comportamientos deseados, como este:
El optimizador GEPA toma el prompt del sistema actual y propone mejoras de forma iterativa, evaluando a cada candidato frente al juez alineado. Aquí, tomamos el prompt inicial, el conjunto de datos de optimización que creamos y el juez alineado para aprovechar optimize_prompts() de MLflow. Luego, usamos el optimizador GEPA para crear un nuevo prompt del sistema guiado por nuestro juez alineado:
La siguiente captura de pantalla muestra el cambio en el prompt del sistema: el antiguo está a la izquierda y el nuevo a la derecha. El prompt final elegido es el que tiene la puntuación más alta según la medición de nuestro juez alineado. El nuevo prompt se ha truncado por razones de espacio, pero con este ejemplo queda claro que hemos podido incorporar las respuestas de los expertos del dominio para elaborar un prompt que se base en un lenguaje específico del dominio con una guía explícita sobre cómo gestionar ciertas solicitudes.

La capacidad de generar automáticamente este tipo de orientación utilizando los comentarios de los SME esencialmente permite a tus SME dar instrucciones indirectamente a un agente con solo dar su opinión sobre los seguimientos del agente.
En este caso, el nuevo prompt generó un mejor rendimiento en nuestro dataset de optimización según nuestro juez alineado, por lo que le dimos al prompt recién registrado el alias de producción, lo que nos permitió volver a implementar nuestro agente con este prompt mejorado.
Consejos para la optimización de prompts:
- El conjunto de datos de optimización debe abarcar la diversidad de consultas que tu agente gestionará. Incluye casos extremos, solicitudes ambiguas y escenarios donde la selección de la herramienta es importante.
- Las respuestas esperadas deben describir lo que el agente debe hacer (qué herramientas llamar, qué información incluir) en lugar del texto de salida exacto.
- Comience con
max_metric_callsestablecido en un valor entre50y100. Los valores más altos exploran más candidatos, pero aumentan el costo y el tiempo de ejecución. - El optimizador GEPA aprende de los modos de falla. Si el juez alineado penaliza la falta de benchmarks o las advertencias sobre muestras pequeñas, GEPA inyectará esos requisitos en el prompt optimizado.
8. Cerrar el ciclo: automatización y mejora continua.
Los pasos individuales que hemos recorrido se pueden organizar en un pipeline de optimización continua donde el etiquetado del experto en el dominio se convierte en el disparador del ciclo de optimización, y todo se puede englobar en un trabajo de Databricks mediante Asset Bundles:
- Los expertos en la materia etiquetan los resultados del agente a través de la UI de la sesión de etiquetado de MLflow, proporcionando puntuaciones y comentarios sobre trazas de producción reales.
- El pipeline detecta nuevas etiquetas y extrae trazas tanto con los comentarios de los SME como con las puntuaciones del juez LLM de referencia.
- Se ejecuta la alineación del juez, lo que produce una nueva versión del juez calibrada según las preferencias más recientes de los SME.
- Se ejecutan optimizaciones de prompts, utilizando el juez alineado para mejorar iterativamente el prompt del sistema.
- La promoción condicional envía el nuevo prompt a producción si supera los umbrales de rendimiento. Esto podría implicar desencadenar otro trabajo de evaluación para garantizar que el nuevo prompt se generalice a otros ejemplos.
- El agente mejora automáticamente a medida que el registro de prompts sirve la versión optimizada.
Cuando los expertos en el dominio completan una sesión de etiquetado, se activa un trabajo evaluate() para generar las puntuaciones del juez LLM en los mismos seguimientos. Cuando el trabajo evaluate() se completa, se ejecuta un trabajo align() para alinear el juez LLM con los comentarios de los expertos en el dominio. Cuando ese trabajo finaliza, se ejecuta un trabajo optimize_prompts() para generar un nuevo y mejorado prompt del sistema que se puede probar de inmediato con un nuevo conjunto de datos y, si corresponde, promover a producción.
Todo este proceso puede automatizarse por completo, pero también se puede insertar una revisión manual en cualquier paso, lo que les da a los desarrolladores un control total sobre el nivel de automatización involucrado. El proceso se repite a medida que los SME continúan etiquetando, lo que da como resultado pruebas rápidas de rendimiento en las nuevas versiones del agente y ganancias de rendimiento acumuladas en las que los desarrolladores realmente pueden confiar.
Conclusión
Esta arquitectura transforma la manera en que los agentes mejoran con el tiempo, usando el Agent Framework de Databricks y MLflow. En lugar de que los desarrolladores adivinen qué es una buena respuesta, los expertos en el dominio le dan forma directamente al comportamiento del agente mediante sus comentarios. Los procesos de alineación y optimización del juez traducen la experiencia en el dominio en cambios concretos en el sistema, mientras que los desarrolladores mantienen el control sobre todo el sistema, incluyendo qué partes automatizar y dónde permitir la intervención manual.
En esta publicación, ilustramos cómo adaptar un agente para que refleje el lenguaje y los detalles específicos que son importantes para los expertos en el dominio del fútbol profesional. El Asistente de DC demuestra el patrón, pero el enfoque funciona para cualquier dominio en el que el juicio de los expertos sea importante: revisión de documentos legales, preparación para el bateo en el béisbol profesional, triaje médico, análisis de tiros de golf, escalamiento del servicio de atención al cliente o cualquier otra aplicación en la que sea difícil para los desarrolladores especificar qué es “bueno” sin el apoyo de los expertos en el dominio.
¡Pruébelo en su propio problema específico del dominio y vea cómo puede impulsar una mejora automatizada y continua basada en los comentarios de los SME!
Obtenga más información sobre Databricks Sports y Agent Bricks, o solicite una demostración para ver cómo su organización puede obtener información competitiva.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.