Deja de codificar manualmente pipelines de captura de datos de cambio
Cómo AutoCDC automatiza CDC y Dimensiones de Cambio Lento
por Matt Jones, Zoé Durand, Phoebe Weiser, Bilal Aslam y Ray Zhu
- Por qué las canalizaciones de CDC y SCD codificadas manualmente son frágiles, complejas y costosas de operar a escala
- Cómo AutoCDC automatiza declarativamente los patrones de CDC basados en SCD Tipo 1, SCD Tipo 2 y instantáneas
- Ganancias del mundo real en corrección, rendimiento y costo de las cargas de trabajo de producción de AutoCDC
Probé AutoCDC a partir de instantáneas en Python y me sorprendió cómo 4 líneas de código pudieron reemplazar lo que antes hacía en 1.500 líneas de código. —Ingeniero de Datos Senior, Empresa Aeroespacial y de Defensa Fortune 500
La captura de datos de cambios (CDC) y las dimensiones de cambio lento (SCD) son fundamentales para las cargas de trabajo modernas de análisis e IA. Los equipos confían en ellas para mantener la precisión de las tablas descendentes a medida que cambian los datos operativos, ya sea para mantener una vista actual del negocio o para conservar el contexto histórico completo.
Sin embargo, en la práctica, las canalizaciones de CDC suelen ser algunas de las más difíciles de construir y operar. Los equipos suelen crear manualmente lógica compleja de MERGE para manejar actualizaciones, eliminaciones y datos que llegan tarde: superponiendo tablas provisionales, funciones de ventana y suposiciones de secuenciación que son difíciles de razonar y aún más difíciles de mantener a medida que evolucionan las canalizaciones.
En esta publicación, analizaremos los patrones de CDC y SCD que los ingenieros de datos y los profesionales de SQL encuentran a diario, por qué estos patrones son difíciles de implementar manualmente y cómo AutoCDC en las Canalizaciones Declarativas de Spark de Lakeflow las automatiza de forma declarativa, al tiempo que ofrece mejoras significativas en precio y rendimiento.
CDC y SCD siguen siendo difíciles para los ingenieros de datos
Incluso para los equipos que entienden bien estos patrones, lograr que sean correctos y mantenerlos correctos con el tiempo es donde las cosas fallan. A medida que aumentan los volúmenes de datos y se expanden los casos de uso, las canalizaciones se vuelven frágiles; los problemas de corrección surgen tarde; e incluso los cambios pequeños requieren reescrituras cuidadosas para evitar corromper las tablas descendentes.
Mantenimiento de tablas SCD Tipo 1
Las tablas SCD Tipo 1 sobrescriben las filas existentes para reflejar el último estado. Incluso este caso “simple” se topa rápidamente con desafíos:
- Las actualizaciones llegan desordenadas
- Los eventos duplicados deben deduplicarse de manera consistente
- Las eliminaciones deben aplicarse correctamente
- La lógica debe permanecer idempotente en reintentos y reprocesamiento
Lo que a menudo comienza como un simple MERGE INTO evoluciona hacia una lógica profundamente anidada con tablas provisionales, funciones de ventana y suposiciones de secuenciación que son difíciles de razonar (o cambiar de forma segura). Con el tiempo, los equipos se vuelven reacios a tocar estas canalizaciones.
Mantenimiento del historial SCD Tipo 2
SCD Tipo 2 introduce complejidad adicional:
- Seguimiento de versiones de filas y ventanas de validez
- Manejo de actualizaciones tardías sin corromper el historial
- Garantizar que exista exactamente una versión “actual” en todo momento
Los errores aquí no siempre fallan de forma evidente. A menudo surgen semanas después como una sutil deriva métrica, o la necesidad de reconstruir tablas históricas por completo.
Extracción de datos de cambios de diferentes fuentes
No todos los sistemas emiten registros de CDC limpios. Algunos sistemas emiten flujos de datos de cambios nativos, mientras que otros no, a menudo porque el equipo que consume los datos no controla la base de datos de origen, lo que obliga a los equipos a reconstruir los cambios comparando instantáneas sucesivas de una tabla de origen.
Soportar ambos normalmente significa una lógica de ingesta y procesamiento separada; diferentes suposiciones de corrección; y más rutas de código para mantener y depurar.
Operación de canalizaciones de CDC a lo largo del tiempo
Incluso una vez que una canalización de CDC es correcta, aún debe sobrevivir al reprocesamiento y a los backfills, la evolución del esquema, las fallas y los reinicios. La lógica de CDC escrita manualmente tiende a volverse más frágil con el tiempo a medida que estas realidades se acumulan, lo que aumenta el riesgo operativo y el costo de mantenimiento.
Automatización de patrones complejos de CDC con ingeniería de datos declarativa
AutoCDC se diseñó para estandarizar estos patrones comunes de CDC y SCD detrás de una abstracción declarativa. En lugar de codificar manualmente cómo se deben aplicar los cambios, los equipos declaran qué semántica desean, y la plataforma gestiona el orden, el estado y el procesamiento incremental.
| Carga de trabajo de CDC | AutoCDC | Lógica de MERGE / Instantánea escrita manualmente |
|---|---|---|
| Mantenimiento de tablas de estado actual (SCD Tipo 1) | La definición declarativa de la canalización maneja automáticamente la secuenciación, la deduplicación y las eliminaciones | Lógica MERGE personalizada con funciones de ventana y reglas de secuenciación |
| Mantenimiento de tablas históricas (SCD Tipo 2) | Gestión automática de versiones con seguimiento de historial integrado | Lógica MERGE de varios pasos para cerrar e insertar versiones de registros |
| Inferencia de cambios a partir de fuentes de instantáneas | Soporte integrado de CDC de instantáneas | Canalizaciones manuales de diferencias de instantáneas con uniones y comparaciones |
| Operación confiable de canalizaciones a lo largo del tiempo (datos tardíos, reintentos, reprocesamiento) | Secuenciación automática y ejecución idempotente | Requiere salvaguardias personalizadas y lógica adicional |
| Huella de código y complejidad operativa | ~6–10 líneas de definición de canalización declarativa | 40–200+ líneas de lógica de canalización personalizada |
Esto brinda a los equipos una forma consistente y repetible de implementar CDC y SCD en todas las canalizaciones, en lugar de reinventar el patrón cada vez (que es realmente el valor central de la programación declarativa en general, y de las Canalizaciones Declarativas de Spark específicamente).
Al procesar registros de cambios de un flujo de datos de cambios (CDF), AutoCDC maneja automáticamente los registros fuera de secuencia y aplica las actualizaciones correctamente según una columna de secuenciación declarada. Para mostrar cómo funciona esto en la práctica, consideremos el siguiente flujo de CDC de ejemplo:
| userId | name | city | operation | sequenceNum |
|---|---|---|---|---|
| 124 | Raul | Oaxaca | INSERT | 1 |
| 123 | Isabel | Monterrey | INSERT | 1 |
| 125 | Mercedes | Tijuana | INSERT | 2 |
| 126 | Lily | Cancun | INSERT | 2 |
| 123 | null | null | DELETE | 6 |
| 125 | Mercedes | Guadalajara | UPDATE | 6 |
| 125 | Mercedes | Mexicali | UPDATE | 5 |
| 123 | Isabel | Chihuahua | UPDATE | 5 |
Recuerde, debe elegir SCD Tipo 1 para conservar solo los datos más recientes o SCD Tipo 2 para conservar los datos históricos. Empecemos con el Tipo 1.
Automatización del mantenimiento de SCD Tipo 1 (fuentes de flujo de datos de cambios)
En este ejemplo, un flujo de datos de cambios contiene inserciones, actualizaciones y eliminaciones para una tabla de usuarios. El objetivo es mantener una vista actual de cada registro, donde las nuevas actualizaciones sobrescriben los valores anteriores.
Tabla de salida para SCD Tipo 1
| id | name | city |
|---|---|---|
| 124 | Raul | Oaxaca |
| 125 | Mercedes | Guadalajara |
| 126 | Lily | Cancun |
El usuario 123 (Isabel) fue eliminado, por lo que no aparece en la salida. El usuario 125 (Mercedes) muestra solo la última ciudad (Guadalajara) porque SCD Tipo 1 sobrescribe los valores anteriores.
Con un enfoque tradicional, esto requiere lógica MERGE personalizada para deduplicar eventos, aplicar orden, aplicar eliminaciones y garantizar que la canalización siga siendo correcta en reintentos o datos que llegan tarde. AutoCDC reemplaza esta lógica frágil con una definición de canalización declarativa que maneja automáticamente la secuenciación, la deduplicación, los datos que llegan tarde y el procesamiento incremental, eliminando docenas de líneas de lógica MERGE personalizada.
Ver ejemplo de código completo en apéndice
Automatización del historial de SCD Tipo 2 (fuentes de flujo de datos de cambios)
En muchos sistemas analíticos, conservar solo el último estado no es suficiente: los equipos necesitan un historial completo de cómo cambian los registros con el tiempo. Este es el patrón SCD Tipo 2, donde cada versión de un registro se almacena con ventanas de validez que indican cuándo estuvo activo.
Tabla de salida para SCD tipo 2:
| id | name | city | __START_AT | __END_AT |
|---|---|---|---|---|
| 123 | Isabel | Monterrey | 1 | 5 |
| 123 | Isabel | Chihuahua | 5 | 6 |
| 124 | Raul | Oaxaca | 1 | NULL |
| 125 | Mercedes | Tijuana | 2 | 5 |
| 125 | Mercedes | Mexicali | 5 | 6 |
| 125 | Mercedes | Guadalajara | 6 | NULL |
| 126 | Lily | Cancun | 2 | NULL |
La tabla conserva el historial completo. El usuario 123 tiene dos versiones (finalizadas en la secuencia 6 cuando se eliminó). El usuario 125 tiene tres versiones que muestran cambios de ciudad. Los registros con __END_AT = NULL están actualmente activos.
Implementar esto manualmente requiere una lógica MERGE de varios pasos para cerrar los registros anteriores, insertar nuevas versiones y asegurar que solo una versión permanezca activa a la vez. AutoCDC automatiza estas transiciones de forma declarativa, gestionando las columnas de historial y la lógica de versionado automáticamente, al tiempo que garantiza la corrección incluso cuando las actualizaciones llegan desordenadas.
Ver ejemplo de código completo en el apéndice
Inferencia de CDC a partir de fuentes de instantáneas
No todos los sistemas de origen emiten registros de cambios. En muchos casos, los equipos reciben instantáneas periódicas de una tabla de origen y deben inferir qué cambió entre ejecuciones.
Tradicionalmente, esto requiere comparar manualmente las instantáneas para detectar inserciones, actualizaciones y eliminaciones antes de aplicar esos cambios con lógica MERGE. AutoCDC trata la CDC basada en instantáneas como un patrón de primera clase, detectando automáticamente los cambios a nivel de fila entre instantáneas y aplicándolos incrementalmente sin necesidad de lógica de diferencia personalizada o gestión de estado.
La implementación manual requiere detectar cambios a nivel de fila entre instantáneas, cerrar los registros activos anteriores e insertar nuevas versiones con ventanas de validez actualizadas. AutoCDC deriva automáticamente estos cambios y aplica la semántica de SCD Tipo 2, manteniendo el historial de versiones sin necesidad de lógica de fusión de varios pasos o seguimiento de estado de instantáneas personalizado.
Gestión de ordenación, estado y reprocesamiento
Lakeflow Spark Declarative Pipelines rastrea automáticamente el progreso incremental y maneja los datos fuera de secuencia. Las canalizaciones pueden recuperarse de fallos, reprocesar datos históricos y evolucionar con el tiempo sin aplicar doblemente ni perder cambios.
En la práctica, esto elimina la necesidad de que los equipos gestionen la lógica de secuenciación, la contabilidad de marcas de agua o la seguridad del reprocesamiento por sí mismos: la plataforma se encarga de ello.
Novedades: importantes mejoras de precio y rendimiento
Además de simplificar la lógica de las canalizaciones, las recientes mejoras de Databricks Runtime han proporcionado importantes mejoras tanto en rendimiento como en eficiencia de costes para las cargas de trabajo de AutoCDC, solo desde noviembre de 2025:
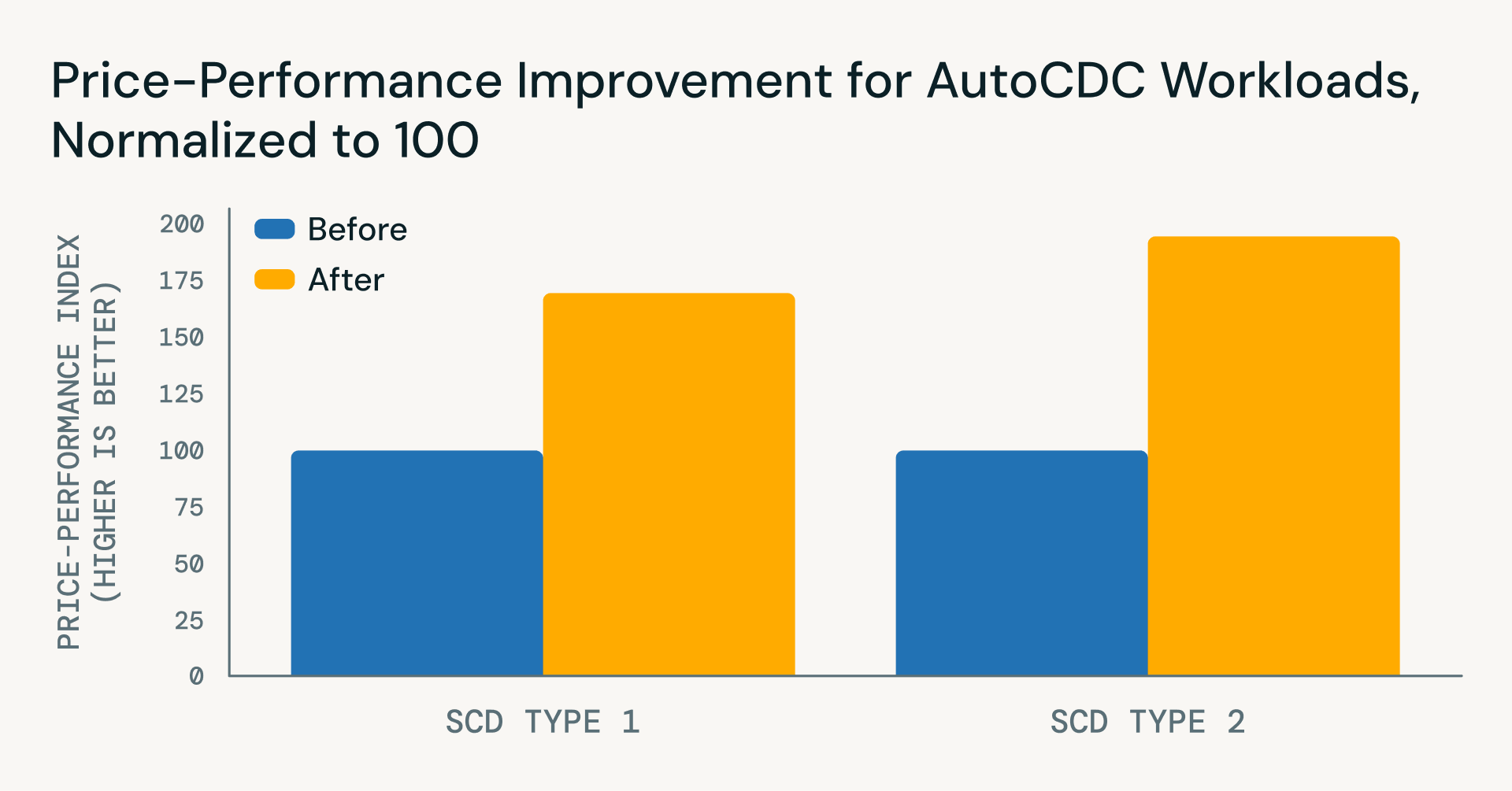
- SCD Tipo 1
- Mejora de ~22% en latencia
- Reducción de ~40% en coste
- Beneficio neto de precio-rendimiento de ~71%
- SCD Tipo 2
- Reducción de ~45% en latencia
- Reducción de ~35% en coste para actualizaciones incrementales
- Beneficio neto de precio-rendimiento de ~96%
Estas mejoras son importantes para las canalizaciones del mundo real que se ejecutan continuamente a escala. Si bien MERGE INTO sigue siendo un primitivo fundamental de Spark, AutoCDC se basa en él para manejar datos fuera de secuencia y procesamiento incremental de manera más eficiente a medida que crecen los volúmenes de datos.
Éxito del cliente con AutoCDC
Los equipos que ejecutan canalizaciones CDC y SCD en producción han citado explícitamente AutoCDC como un proveedor de valor significativo:
Navy Federal Credit Union utiliza AutoCDC en Lakeflow Spark Declarative Pipelines para potenciar el procesamiento de eventos a gran escala y en tiempo real, manejando miles de millones de eventos de aplicaciones de forma continua, al tiempo que elimina el código CDC personalizado y el mantenimiento continuo de las canalizaciones.
La simplicidad del modelo de programación de Spark Declarative Pipelines, combinada con sus capacidades de servicio, resultó en un tiempo de respuesta increíblemente rápido. —Jian (Miracle) Zhou, Gerente Senior de Ingeniería, Navy Federal Credit Union
Block utiliza AutoCDC en Lakeflow Spark Declarative Pipelines para simplificar la captura de datos de cambios y las canalizaciones de streaming en tiempo real en Delta Lake, reemplazando el código CDC y la lógica de fusión escritos a mano con un enfoque declarativo que es rápido de implementar y fácil de operar.
Con la adopción de Spark Declarative Pipelines, el tiempo necesario para definir y desarrollar una canalización de streaming ha pasado de días a horas. —Yue Zhang, Ingeniero de Software Principal, Fundaciones de Datos, Block
Valora Group, un proveedor líder suizo de "foodvenience", utiliza AutoCDC en Lakeflow Spark Declarative Pipelines para optimizar la captura de datos de cambios para datos maestros y análisis minoristas en tiempo real, reemplazando el código CDC personalizado con un enfoque declarativo que es fácil de implementar, repetir y escalar entre equipos.
Ganamos mucho al hacer CDC en SDP, porque no escribes ningún código, todo está abstraído en segundo plano. AutoCDC minimiza el número de líneas... es muy fácil de hacer. —Alexane Rose, Arquitecto de Datos e IA, Valora Holding
Comenzar
AutoCDC está disponible como parte de Lakeflow Spark Declarative Pipelines en Databricks.
Para obtener más información:
- Revise la documentación de AutoCDC (SQL y Python)
- Explore ejemplos para SCD Tipo 1, SCD Tipo 2 y CDC basada en instantáneas
¡Pruebe AutoCDC en sus propias canalizaciones y elimine la lógica CDC escrita a mano!
Apéndice
Ejemplo de SCD Tipo 1
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import max_by, struct
# Deduplicar: mantener el último registro por userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Aplicar SCD Tipo 1: actualizar inserciones, eliminar eliminaciones
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(updates.alias("s"), "s.userId = t.userId")
.whenMatchedDelete(condition="s.operation = 'DELETE'")
.whenMatchedUpdate(
condition="s.sequenceNum > t.sequenceNum",
set={"name": "s.name", "city": "s.city", "sequenceNum": "s.sequenceNum"}
)
.whenNotMatchedInsertAll(condition="s.operation != 'DELETE'")
.execute())
| from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr
@dp.view
def users():
return spark.readStream.table("cdc_data.users")
dp.create_streaming_table("target")
dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=1
)
|
Ejemplo de SCD Tipo 2
| MERGE | AutoCDC |
from delta.tables import DeltaTable
from pyspark.sql.functions import col, lit, max_by, struct
# Deduplicar: mantener el último registro por userId
updates = (spark.read.table("cdc_data.users")
.groupBy("userId")
.agg(max_by(struct("*"), "sequenceNum").alias("row"))
.select("row.*"))
# Paso 1: cerrar las filas activas para los registros que se actualizan o eliminan
(DeltaTable.forName(spark, "target")
.alias("t")
.merge(
updates.alias("s"),
"s.userId = t.userId AND t.__END_AT IS NULL AND s.sequenceNum > t.__START_AT"
)
.whenMatchedUpdate(set={"__END_AT": "s.sequenceNum"})
.execute())
# Paso 2: insertar nuevas filas para inserciones y actualizaciones (no eliminaciones)
new_rows = (updates
.filter("operation != 'DELETE'")
.withColumn("__START_AT", col("sequenceNum"))
.withColumn("__END_AT", lit(None).cast("long"))
.drop("operation"))
new_rows.write.mode("append").saveAsTable("target")
| dp.create_auto_cdc_flow(
target="target",
source="users",
keys=["userId"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
stored_as_scd_type=2
)
|
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.