¿Qué son los modelos de lenguaje grande (LLM)?
Redes neuronales con miles de millones de parámetros entrenadas en corpus de texto masivos a través del aprendizaje autosupervisado, capaces de generar texto similar al humano para tareas de PNL.
- La arquitectura emplea modelos de transformador con mecanismos de atención que permiten el procesamiento paralelo de secuencias, entrenados mediante la predicción del siguiente token en texto a escala de internet, utilizando recursos computacionales masivos y hardware especializado (GPU, TPU).
- Las capacidades incluyen aprendizaje de pocos intentos y de cero intentos, adaptándose a nuevas tareas a partir de ejemplos, comprensión multilingüe, razonamiento sobre ventanas de contexto que abarcan miles de tokens y capacidades emergentes que surgen a escala.
- Las aplicaciones abarcan chatbots, creación de contenido, generación de código, asistencia en investigación, traducción de idiomas, resumen de documentos, análisis de sentimientos y gestión del conocimiento empresarial, a la vez que requieren una implementación cuidadosa que aborde el sesgo, la seguridad y los costos computacionales.
¿Qué son los modelos de lenguaje grande (LLM)?
Los modelos de lenguaje son un tipo de IA generativa (GenAI) que usan el procesamiento del lenguaje natural (PLN) para comprender y generar lenguaje humano. Los modelos de lenguaje grande (LLM) son los más potentes de estos. Los LLM se entrenan a partir de conjuntos de datos masivos utilizando algoritmos avanzados de aprendizaje automático (ML) para aprender los patrones y las estructuras del lenguaje humano y generar respuestas de texto a indicaciones escritas. Ejemplos de LLM incluyen BERT, Claude, Gemini, Llama y la familia de LLM Generative Pretrained Transformer (GPT).
Los modelos de lenguaje grande (LLM) han superado significativamente a sus predecesores en rendimiento y capacidad en una variedad de tareas relacionadas con el lenguaje. Su capacidad para generar contenido complejo y matizado, y automatizar tareas para obtener resultados similares a los humanos, impulsa avances en diversos campos. Los modelos de lenguaje grande (LLM) se están integrando ampliamente en el mundo empresarial para generar impacto en una variedad de entornos y usos comerciales, lo que incluye la automatización del soporte, la obtención de insights y la generación de contenido personalizado.
Las capacidades de lenguaje e IA de los LLM principales incluyen las siguientes:
- Comprensión del lenguaje natural: los LLM pueden entender los matices del lenguaje humano, lo que incluye el contexto, la semántica y la intención.
- Generación de contenido multimodal: los LLM pueden generar texto similar al humano para diversos propósitos, desde codificación hasta escritura creativa, así como imágenes, voz y más.
- Respuesta a preguntas: los LLM pueden responder de forma inteligente a preguntas abiertas.
- Escalabilidad: los LLM pueden aprovechar las capacidades de la unidad de procesamiento de gráficos (GPU) para asumir de manera eficiente tareas de lenguaje a gran escala y adaptarse a las crecientes necesidades del negocio.
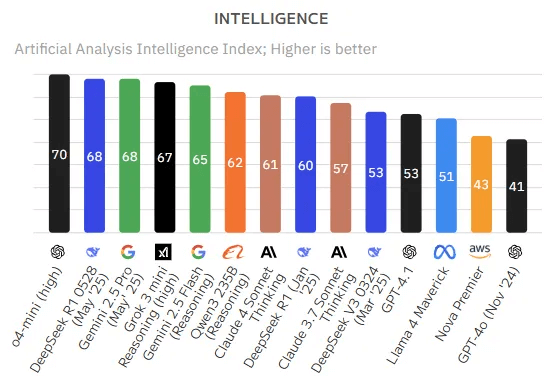
¿Cómo funcionan los LLM?
La mayoría de los LLM se construyen con una arquitectura de transformador. Funcionan dividiendo el texto de entrada en tokens (unidades de subpalabras), integrando esos tokens en vectores numéricos y utilizando mecanismos de atención para comprender las relaciones en el texto de entrada. Luego predicen el siguiente token en una secuencia para generar resultados coherentes.
¿Qué significa preentrenar a los LLM?
El preentrenamiento de un modelo LLM se refiere al proceso de entrenarlo con un gran volumen de datos, como texto o código, sin aprovechar el conocimiento previo ni los pesos de un modelo existente. El resultado del preentrenamiento completo es un modelo base que se puede utilizar directamente o ajustar aún más para tareas posteriores.
La capacitación previa asegura que el conocimiento fundamental del modelo se adapte a tu dominio específico. El resultado es un modelo personalizado que se diferencia por los datos únicos de tu organización. Sin embargo, la capacitación previa suele ser el tipo de capacitación más extenso y costoso, y no es habitual en la mayoría de las organizaciones.
¿Qué significa ajustar con precisión los LLM?
El ajuste preciso es el proceso de adaptar un LLM preentrenado en un conjunto de datos comparativamente más pequeño que es específico de un dominio o tarea individual. Durante el proceso de ajuste preciso, el LLM continúa entrenándose por un corto tiempo, posiblemente ajustando un número relativamente menor de pesos en comparación con el modelo completo.
Las dos formas más comunes de ajuste preciso son:
Ajuste preciso de la instrucción supervisada: este enfoque implica el entrenamiento continuo de un LLM preentrenado en un conjunto de datos de ejemplos de entrenamiento de entrada-salida, que normalmente se lleva a cabo con miles de ejemplos de entrenamiento.
Preentrenamiento continuo: este método de ajuste preciso no se basa en ejemplos de entrada y salida, sino que utiliza texto no estructurado específico del dominio para continuar el mismo proceso de preentrenamiento (como la predicción del siguiente token y el modelado de lenguaje enmascarado).
El ajuste preciso es importante porque permite a una organización tomar un LLM de base y entrenarlo con sus propios datos para lograr una mayor precisión y personalización para el dominio y las cargas de trabajo de la empresa. Esto también le da a la organización control para gestionar los datos utilizados para el entrenamiento, y te asegura un uso responsable de la IA.
Redes neuronales y arquitectura de transformadores
Los LLM se basan en el aprendizaje profundo, una forma de IA en la que se introducen grandes cantidades de datos en un programa para entrenarlo, basado en la probabilidad. Al estar expuestos a enormes conjuntos de datos, los LLM pueden entrenarse a sí mismos para reconocer patrones y relaciones lingüísticas sin necesidad de programación explícita, gracias a mecanismos de autoaprendizaje que mejoran continuamente su precisión.
La base de los LLM son las redes neuronales artificiales, inspiradas en la estructura del cerebro humano. Estas redes están formadas por nodos interconectados dispuestos en capas, que incluyen una capa de entrada, una capa de salida y una o más capas intermedias. Cada nodo procesa y transmite información a la siguiente capa basándose en los patrones aprendidos.
Los LLM utilizan un tipo de red neuronal llamada modelo de transformador. Estos modelos innovadores pueden analizar una oración completa de una sola vez, a diferencia de los modelos anteriores que procesan las palabras de forma secuencial. Esto les permite entender el lenguaje más rápido y eficientemente. Los modelos transformers emplean una técnica matemática llamada autoatención, que asigna distintas importancias a las palabras de una oración, permitiendo al modelo captar matices de significado y comprender el contexto. La codificación posicional ayuda al modelo a comprender la importancia del orden de las palabras dentro de una oración, lo cual es esencial para comprender el lenguaje. El modelo transformador permite a los LLM procesar grandes cantidades de datos, aprender información relevante para el contexto y generar contenido coherente.
Una versión simplificada del proceso de entrenamiento de LLM

Obtén más información sobre los transformadores, la base de todo LLM
¿Cuáles son los casos de uso de los LLM?
Los LLM pueden impulsar el impacto empresarial en casos de uso y diferentes industrias. Ejemplos de casos de uso incluyen los siguientes:
- Chatbots y asistentes virtuales: los LLM se usan para potenciar chatbots, lo que les permite a los clientes y empleados mantener conversaciones abiertas que ayudan con el soporte al cliente, el seguimiento de clientes potenciales en sitios web y los servicios de asistente personal.
- Creación de contenido: los LLM pueden generar diferentes tipos de contenido, como artículos, publicaciones de blog y actualizaciones en redes sociales.
- Generación y depuración de código: los LLM pueden generar fragmentos de código útiles, identificar y corregir errores en el código y completar programas basándose en las instrucciones proporcionadas.
- Análisis de sentimiento: los LLM pueden comprender automáticamente el sentimiento de un texto para evaluar la satisfacción del cliente.
- Clasificación y agrupación de textos: los LLM pueden organizar, categorizar y clasificar grandes volúmenes de datos para identificar temas y tendencias comunes que sirvan de base para la toma de decisiones informadas.
- Traducción de idiomas: los modelos de lenguaje grande (LLM) pueden traducir documentos y páginas web a diferentes idiomas para llegar a diferentes mercados.
- Resumen y paráfrasis: los LLM pueden resumir documentos, artículos, llamadas de clientes o reuniones y capturar de manera concisa los puntos más importantes.
- Seguridad: los LLM se pueden utilizar en ciberseguridad para identificar patrones de amenazas y automatizar las respuestas.
¿Cuáles son ejemplos de clientes donde los LLM se han implementado con éxito?
La guía de IA agéntica para la empresa

JetBlue
JetBlue implementó “BlueBot”, un chatbot que usa modelos de IA generativa de código abierto complementados con datos corporativos y potenciado por Databricks. Todos los equipos de JetBlue pueden usar este chatbot para acceder a datos regulados por funciones. Por ejemplo, el equipo financiero puede ver datos de SAP y documentos reglamentarios, pero el equipo de operaciones solo verá información de mantenimiento.
Chevron Phillips
Chevron Phillips aprovecha las soluciones de IA generativa impulsadas por modelos de código abierto como Dolly de Databricks para agilizar la automatización de procesos de documentos. Estas herramientas transforman los datos no estructurados de los PDF y los manuales en insights estructurados, lo que permite una extracción de datos más rápida y precisa para las operaciones y la inteligencia de mercado. Las políticas de gobernanza garantizan la productividad y la gestión de riesgos, lo que mantiene la trazabilidad.
Thrivent Financial
Thrivent Financial aprovecha la IA generativa y Databricks para acelerar las búsquedas, ofrecer insights más claros y accesibles, y aumentar la productividad en ingeniería. Al reunir los datos en una única plataforma con gobernanza basada en roles, la empresa está creando un espacio seguro donde los equipos pueden innovar, explorar y trabajar de manera más eficiente.
¿Por qué los LLM están ganando popularidad de repente?
Hay muchos avances tecnológicos recientes que han llevado a los LLM al centro de atención:
- Avance de las tecnologías de aprendizaje automático: los LLM usan diversos avances en técnicas de ML. La más destacada es la arquitectura de transformadores, que constituye la arquitectura fundamental para la mayoría de los modelos de LLM.
- Mayor accesibilidad: el lanzamiento de ChatGPT abrió la puerta para que cualquier persona con acceso a Internet interactuara con uno de los LLM más avanzados a través de una sencilla interfaz web, lo que le permitió al mundo entender el poder de los LLM.
- Mayor potencia de cómputo: la disponibilidad de recursos informáticos más potentes, como las unidades de procesamiento gráfico (GPU) y mejores técnicas de procesamiento de datos, permitió a los investigadores entrenar modelos mucho más grandes.
- Cantidad y calidad de los datos de capacitación: la disponibilidad de grandes conjuntos de datos y la capacidad de procesarlos mejoró de manera considerable el rendimiento del modelo. Por ejemplo, GPT-3 se capacitó con big data (unos 500 000 millones de tokens) que incluían subconjuntos de alta calidad como el conjunto de datos WebText2 (17 millones de documentos), que contiene páginas web rastreadas públicamente con énfasis en la calidad.
¿Cómo personalizo un LLM con los datos de mi organización?
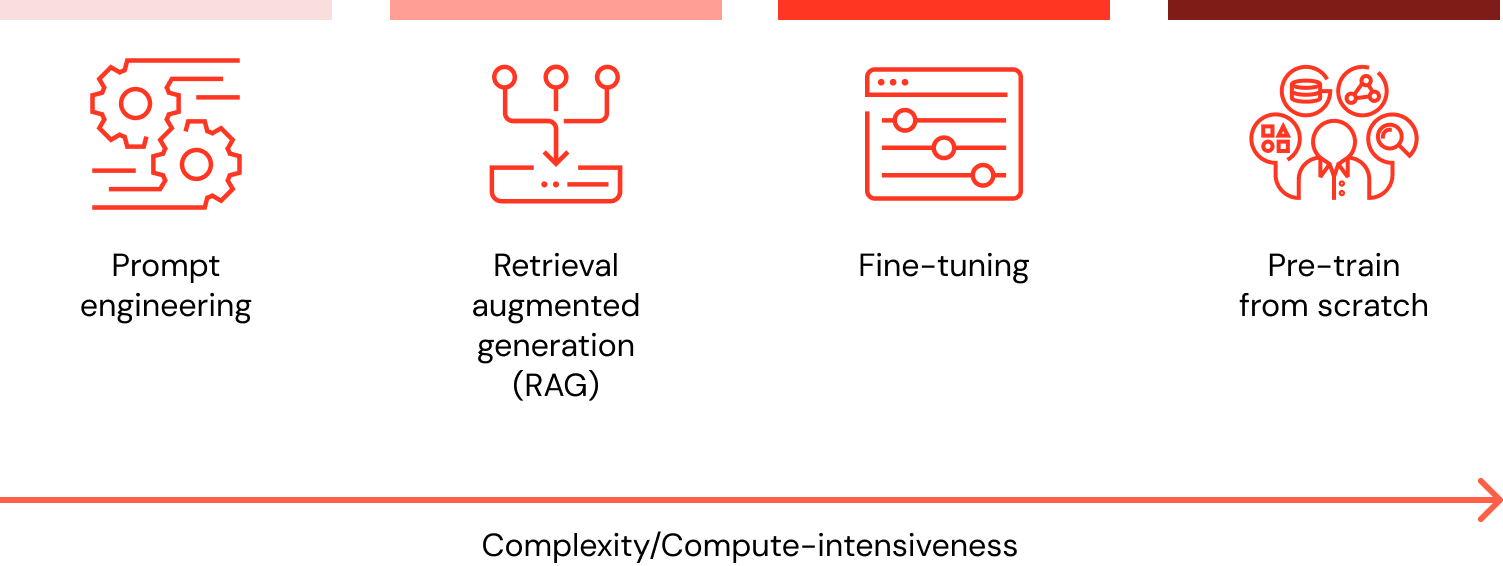
Existen cuatro patrones arquitectónicos a considerar al personalizar una aplicación de LLM con los datos de tu organización. Estas técnicas se describen a continuación y no son mutuamente excluyentes. Más bien, pueden (y deben) combinarse para aprovechar las fortalezas de cada una.
Independientemente de la técnica seleccionada, construir una solución de manera bien estructurada y modularizada garantiza que las organizaciones estén preparadas para iterar y adaptarse. Obtén más información sobre este enfoque y más en El Gran Libro de la IA Generativa.
| Método | Definición | Caso de uso principal | Requisitos de datos | Beneficios | Consideraciones |
|---|---|---|---|---|---|
| Elaboración de indicaciones especializadas para guiar el comportamiento de los LLM | Guía rápida y en tiempo real del modelo | Ninguno | Rápido, económico, no requiere entrenamiento | Menos control que el ajuste preciso | |
| Combinación de un LLM con recuperación de conocimientos externos | Conjuntos de datos dinámicos y conocimiento externo | Base de conocimientos o base de datos externa (por ejemplo, base de datos vectorial). | Contexto actualizado din�ámicamente, precisión mejorada | Aumenta la longitud de las indicaciones y el cálculo de inferencias | |
| Adaptación de un LLM preentrenado a conjuntos de datos o dominios específicos | Especialización en un dominio o tarea | Miles de ejemplos específicos de dominios o instrucciones | Control granular, alta especialización | Requiere datos etiquetados, costo de cómputo | |
| Entrenamiento de un LLM desde cero | Tareas únicas o corpus específicos del dominio | Grandes conjuntos de datos (miles de millones a billones de tokens) | Control máximo, adaptado a necesidades específicas | Muy demandante en cuanto al uso de recursos |

{kind=link}
¿Qué significa la ingeniería de indicaciones en relación con los LLM?
La ingeniería de indicaciones es la práctica de ajustar las indicaciones de texto que se entregan a un LLM para obtener respuestas más precisas o relevantes. No todos los modelos de LLM producirán la misma calidad, ya que la ingeniería de indicaciones es específica de cada modelo. Los siguientes son algunos consejos generalizados que funcionan para una variedad de modelos:
- Usa indicaciones claras y concisas, que pueden incluir una instrucción, contexto (si es necesario), una consulta o entrada del usuario y una descripción del tipo o formato de salida deseado.
- Proporciona ejemplos en tu pregunta (“aprendizaje con pocos ejemplos”) para ayudar al LLM a comprender lo que deseas.
- Indícale al modelo cómo debe comportarse, por ejemplo, diciéndole que admita si no puede responder a una pregunta.
- Dile al modelo que piense paso a paso o explique su razonamiento.
- Si tu prompt incluye entrada del usuario, emplea técnicas para evitar el hacking de prompts, como dejar muy claro qué partes del prompt corresponden a tu instrucción frente a la entrada del usuario.
¿Qué significa la generación aumentada por recuperación (RAG) en relación con los LLM?
La generación aumentada por recuperación, o RAG, es un enfoque de arquitectura que puede mejorar la eficacia de las aplicaciones LLM, ya que aprovecha datos personalizados. Esto se logra recuperando los datos/documentos relevantes a una pregunta o tarea, y proporcionándolos como contexto al LLM. RAG demostró ser exitoso en el soporte de chatbots y sistemas de preguntas y respuestas que necesitan mantener información actualizada o acceder a conocimientos específicos del dominio.
Descubre más sobre RAG aquí.
¿Cuáles son los LLM más comunes y en qué se diferencian?
El campo de los LLM está lleno de muchas opciones para elegir. En términos generales, se pueden agrupar los LLM en dos categorías: modelos propietarios y modelos de código abierto.
Modelos patentados
Los modelos LLM patentados se desarrollan por empresas privadas y son propiedad de estas y, normalmente, requieren licencias para acceder. Quizás el LLM propietario de más alto perfil sea GPT-4o, que impulsa ChatGPT, que se lanzó en 2022 con gran expectativa. ChatGPT ofrece una interfaz de búsqueda amigable donde los usuarios pueden enviar mensajes y, por lo general, recibir una respuesta rápida y relevante. Los desarrolladores pueden acceder a la API de ChatGPT para integrarla en sus propias aplicaciones, productos o servicios. Otros modelos patentados incluyen Gemini de Google y Claude de Anthropic.
Modelos de código abierto
Otra opción es autohospedar un LLM, por lo general, usando un modelo de código abierto y disponible para uso comercial. La comunidad de código abierto alcanzó rápidamente el rendimiento de los modelos patentados. Los modelos LLM populares de código abierto incluyen Llama 4 de Meta y Mixtral 8x22B.
Cómo evaluar la mejor opción
Las principales consideraciones y diferencias en el enfoque entre utilizar una API de un proveedor externo cerrado frente a alojar tu propio modelo LLM de código abierto (o perfeccionado) son la preparación para el futuro, la gestión de costos y el aprovechamiento de tus datos como una ventaja competitiva. Los modelos patentados pueden quedar obsoletos y eliminarse, lo que rompería sus procesos e índices vectoriales existentes, mientras que los modelos de código abierto estarán disponibles para ti para siempre. Los modelos de código abierto y perfeccionados pueden ofrecer más opciones y personalización para tu aplicación, lo que permite mejores compensaciones entre rendimiento y costo. La planificación para el ajuste futuro de tus propios modelos te permitirá aprovechar los datos de tu organización como una ventaja competitiva para construir mejores modelos que los disponibles públicamente. Finalmente, los modelos patentados pueden suscitar problemas de gobernanza, ya que estos LLM de “caja negra” brindan menor transparencia sobre cómo fueron entrenados y ponderados.
Alojar tus propios modelos LLM de código abierto requiere más trabajo que usar LLM patentados. MLflow de Databricks facilita que alguien con experiencia en Python pueda extraer cualquier modelo de transformador y usarlo como objeto Python.
¿Cómo elijo qué LLM utilizar?
La evaluación de los LLM es un dominio desafiante y en evolución, principalmente porque los LLM a menudo demuestran capacidades desiguales en diferentes tareas. Un LLM podría destacar en una prueba de rendimiento, pero basta con pequeñas variaciones en la indicación o en el problema para que su rendimiento se vea radicalmente afectado.
Algunas herramientas y puntos de referencia destacados que se usan para evaluar el rendimiento de los modelos de lenguaje grande (LLM) incluyen lo siguiente:
- MLflow
- Proporciona un conjunto de herramientas LLMOps para la evaluación de modelos.
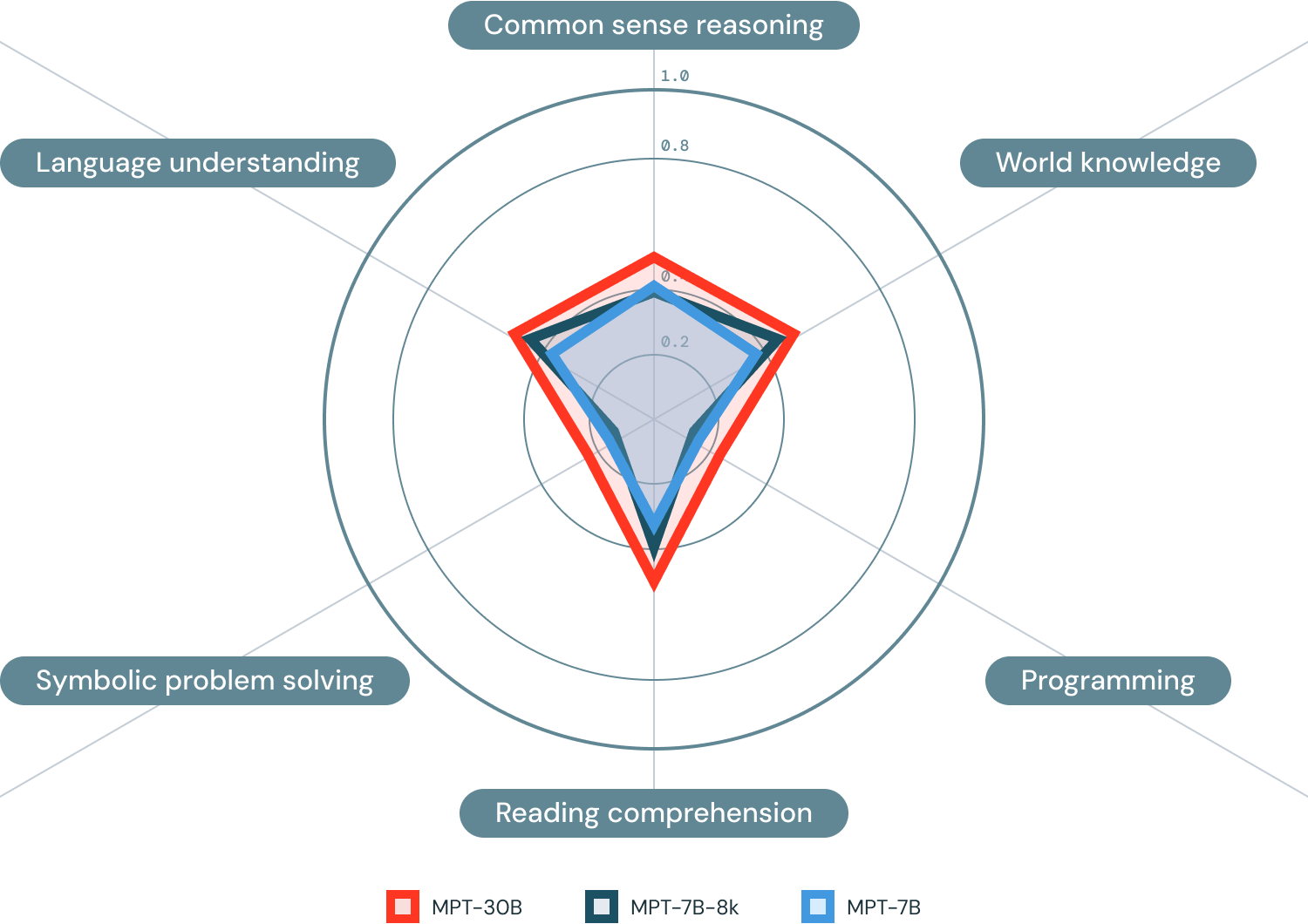
- Guantelete del modelo Mosaic
- Un enfoque de evaluación agregada que categoriza la competencia del modelo en seis dominios amplios (como se muestra a continuación), en lugar de resumirla en una única métrica monolítica.
- Hugging Face reúne cientos de miles de modelos de colaboradores de código abierto.
- BIG-bench (la evaluación más allá del juego de la imitación)
- Un marco dinámico de evaluación, que actualmente alberga más de 200 tareas, con un enfoque en la adaptación a las capacidades futuras de LLM.
- Marco de evaluación para LM de EleutherAI
- Un marco holístico que evalúa modelos en más de 200 tareas, al fusionar evaluaciones como BIG-bench y MMLU, fomentar la reproducibilidad y comparabilidad.
Además, lee las Prácticas recomendadas para la evaluación de aplicaciones RAG para LLM.
¿Cómo se operacionaliza la administración de LLM a través de operaciones de modelos de lenguaje grande?
Las operaciones de modelos de lenguaje grande (LLMOps) abarcan las prácticas, técnicas y herramientas que se usan para la administración operativa de LLM en entornos de producción.
LLMOps permite la implementación, la supervisión y el mantenimiento eficientes de los LLM. LLMOps, como las operaciones tradicionales de aprendizaje automático (MLOps), requieren la colaboración de científicos de datos, ingenieros de DevOps y profesionales de TI. Consulta más detalles sobre LLMOps aquí.
¿Dónde puedo encontrar más información sobre los modelos de lenguaje grande (LLM)?
Existen muchos recursos disponibles para encontrar más información sobre los LLM, entre ellos:
Capacitación
- LLM: modelos fundamentales desde cero (EDX y capacitación de Databricks): capacitación gratuita de Databricks que profundiza en los detalles de los modelos fundamentales en los LLM.
- LLM: de la aplicación a la producción (EDX y capacitación de Databricks): capacitación gratuita de Databricks que se centra en cómo construir aplicaciones enfocadas en LLM con los marcos más recientes y conocidos.
Libros electrónicos
- El gran libro de la IA generativa
- Guía compacta para el ajuste preciso y la creación de LLM personalizados
- Una guía compacta para los modelos de lenguaje grande
Blogs técnicos
- Presentamos Llama 4 de Meta en Databricks Data Intelligence Platform | Databricks Blog
- Desplegar modelos Qwen en Databricks | Blog de Databricks
- Mejores prácticas para la evaluación de aplicaciones RAG en LLM
- Uso de MLflow AI Gateway y Llama 2 para construir aplicaciones de IA generativa
- Crea aplicaciones RAG de alta calidad con Agent Bricks Custom Agents y Agent Evaluation, Model Serving y AI Search
- LLMOps: Todo lo que necesitas saber para gestionar los LLM.
Próximos pasos
- Ponte en contacto con Databricks para programar una demostración y hablar con un representante sobre tus proyectos de modelos de lenguaje grande (LLM).
- Lee acerca de las ofertas de Databricks para LLM
- Lee más sobre el caso de uso de la generación aumentada por recuperación (RAG) (la arquitectura LLM más común)
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.