Novedades de Databricks SQL, febrero de 2025
Nuevas funciones y mejoras de rendimiento para que Databricks SQL sea más simple, más rápido y más rentable
por Ina Felsheim y Gaurav Saraf
- La migración impulsada por IA a Databricks SQL ya está disponible para Oracle, SQL Server, Snowflake, Redshift y más.
- Solo en los últimos 5 meses, las cargas de trabajo de BI son un 14 % más rápidas, los trabajos de ETL son un 9 % más rápidos y las cargas de trabajo de exploración han mejorado en un 13 %.
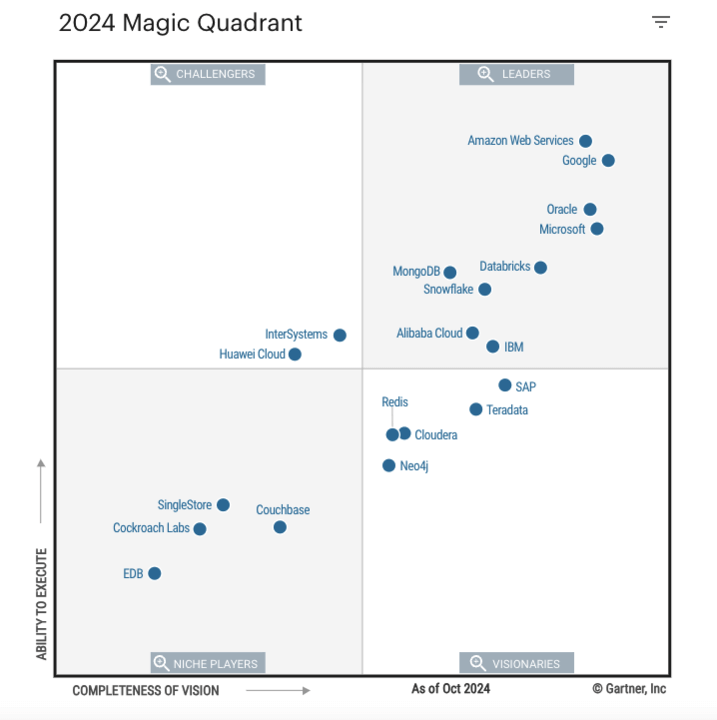
- Databricks fue nombrado Líder en el Magic Quadrant™ de Gartner® de 2024 para sistemas de gestión de bases de datos en la nube por cuarto año consecutivo.
Databricks SQL sigue evolucionando con nuevas funciones y mejoras de rendimiento diseñadas para que sea más simple, más rápido y más rentable. Basado en la arquitectura lakehouse dentro de la Databricks Data Intelligence Platform, más de 11,000 clientes confían en él para potenciar sus cargas de trabajo de datos.
En este blog, abordaremos las actualizaciones clave de los últimos tres meses, incluido nuestro reconocimiento en el Magic Quadrant™ de Gartner® de 2024 para sistemas de gestión de bases de datos en la nube, mejoras en AI/BI, experiencias inteligentes, administración y mucho más.
Migraciones de datos aceleradas con BladeBridge
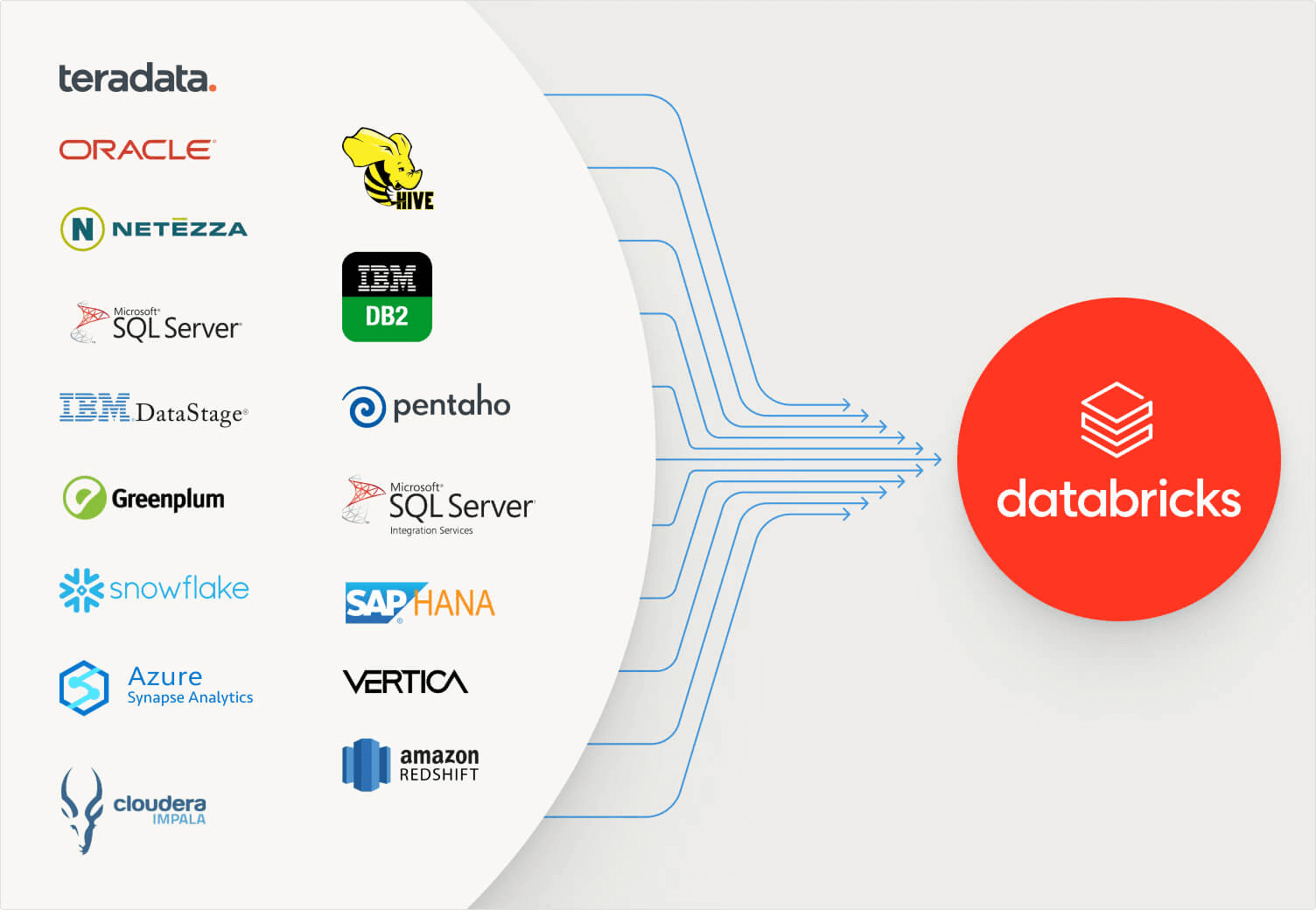
Databricks le da la bienvenida a BladeBridge, un proveedor consolidado de soluciones de migración impulsadas por IA para almacenes de datos empresariales. Juntos, Databricks y BladeBridge ayudarán a las empresas a acelerar el trabajo necesario para migrar los data warehouses heredados, como Oracle, SQL Server, Snowflake y Redshift, a Databricks SQL (DBSQL), el data warehouse creado sobre el lakehouse de Databricks, que define su categoría. BladeBridge proporcionará a los clientes una visión clara del alcance de la conversión, transpilación de código configurable, conversión impulsada por LLM y una validación sencilla de los sistemas migrados.
BladeBridge proporciona un enfoque mejorado con IA para migrar más de 20 data warehouses y herramientas de ETL heredados (entre ellos, Teradata, Oracle, Snowflake, SQL Server, Amazon Redshift, Azure Synapse Analytics y Hive) más de un 50 % más rápido que los enfoques tradicionales. Para obtener más información, lea el blog del anuncio.
Experiencias inteligentes
Nos centramos en hacer que la experiencia del analista de SQL sea más intuitiva, eficiente y atractiva. Al incorporar la IA en todos nuestros productos, puede dedicar menos tiempo a las tareas repetitivas y más tiempo al trabajo de alto valor.
IA/BI
Desde el lanzamiento de AI/BI en otoño de 2024, hemos lanzado nuevas funciones en Genie y Dashboards, y hay más en camino. Las actualizaciones recientes de Dashboard incluyen lo siguiente:
- asistencia de IA mejorada para generar gráficos
- compatibilidad para copiar y pegar widgets entre páginas
- Actualizamos las tablas dinámicas y los mapas de puntos para una mejor exploración de datos.
Para Genie, hemos mejorado:
- Benchmarking de preguntas para evaluaciones más precisas.
- visualizaciones editables y redimensionables para informes flexibles
- calidad de la respuesta, con mejoras en la forma en que maneja la clasificación de los resultados y la gestión de consultas relacionadas con fechas y horas
Profundice en las nuevas actualizaciones de AI/BI.
Editor de SQL
Mejoramos constantemente la experiencia de creación de SQL para ayudarte a trabajar de manera más eficiente. Una de las actualizaciones más importantes del último trimestre fue la compatibilidad de Git para las consultas, que facilita el control de versiones de su SQL y la integración con las canalizaciones de CI/CD.
*La compatibilidad con Git para consultas está disponible cuando se activa el nuevo editor de SQL.
También hemos añadido nuevas funciones para optimizar su flujo de trabajo:
- Múltiples sentencias de resultados: vea y compare los resultados de diferentes sentencias SQL lado a lado.
- Filtrado completo de la tabla de resultados: Aplica filtros a conjuntos de datos completos, no solo a la porción cargada en tu navegador.
- Cambio entre pestañas más rápido: Hasta un 80 % más rápido para las pestañas cargadas y un 62 % más rápido para las pestañas no cargadas, lo que hace que la navegación sea más fluida.
- Tamaño de fuente ajustable: Puedes cambiar rápidamente el tamaño de la fuente del editor de SQL con atajos de teclado (Alt + / Alt—en Windows/Linux, Opt + / Opt—en macOS).
- Comentarios mejorados con @mentions: Colabora en tiempo real mencionando a tus compañeros de equipo directamente en los comentarios usando “@” seguido de su nombre de usuario. Recibirán notificaciones por correo electrónico, lo que mantendrá a todos al tanto.
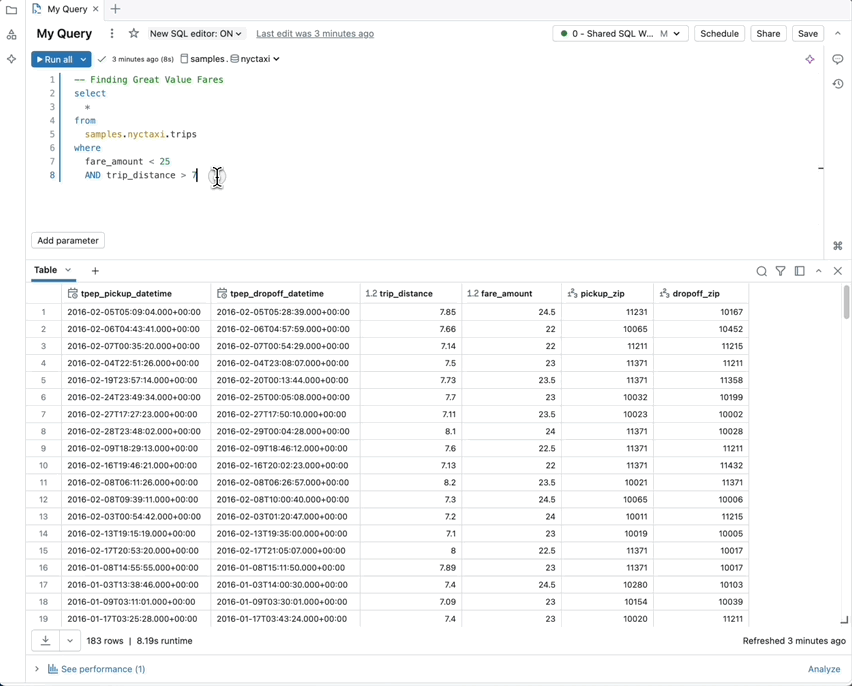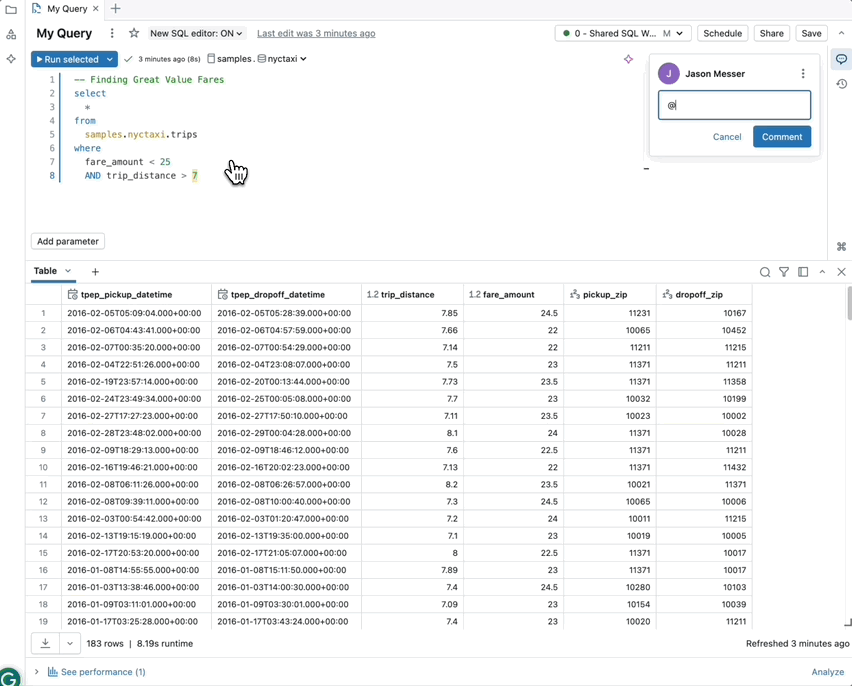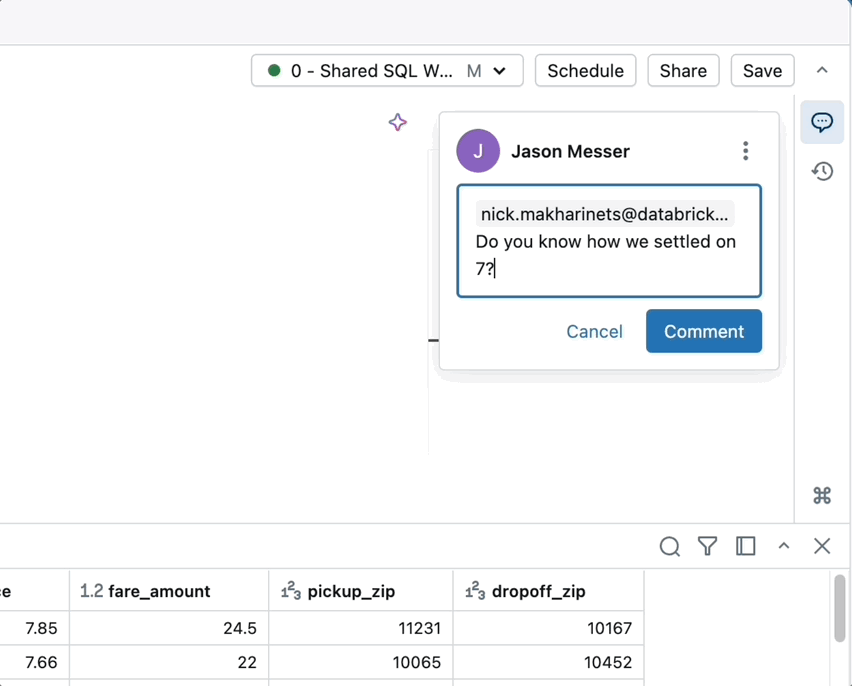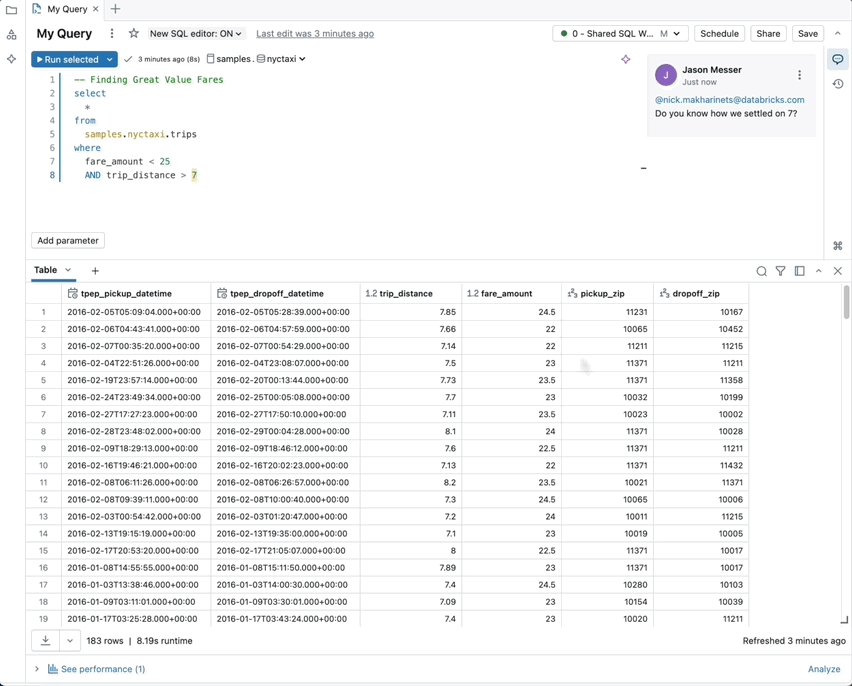
Optimización predictiva de tu plataforma
Las optimizaciones predictivas utilizan la IA para administrar automáticamente el rendimiento de todas tus cargas de trabajo. Mejoramos y agregamos funciones constantemente en esta área para eliminar la necesidad de realizar ajustes manuales en toda la plataforma.
Optimización predictiva para estadísticas
El data lakehouse utiliza dos tipos distintos de estadísticas: estadísticas de omisión de datos (también conocidas como estadísticas Delta) y estadísticas del optimizador de consultas. Las estadísticas de omisión de datos se recopilan automáticamente, pero a medida que los datos crecen y el uso se diversifica, determinar cuándo ejecutar el comando ANALYZE se vuelve complejo. También tienes que mantener activamente las estadísticas del optimizador de consultas.
Nos complace presentar la Public Preview restringida de la optimización predictiva para estadísticas. La optimización predictiva ya está disponible de forma general como un enfoque basado en la IA para optimizar los procesos de optimización. Actualmente, esta característica admite tareas esenciales de diseño y limpieza de datos, y los primeros comentarios de los usuarios destacan su eficacia para simplificar el mantenimiento rutinario de los datos. Con la incorporación de la gestión automática de estadísticas, la optimización predictiva aporta valor y simplifica las operaciones mediante los siguientes avances:
- Selección inteligente de estadísticas de omisión de datos, lo que elimina la necesidad de gestionar el orden de las columnas
- Recopilación automática de estadísticas de optimización de consultas, lo que elimina la necesidad de ejecutar ANALYZE después de la carga de datos
- Una vez recopiladas, las estadísticas informan las estrategias de ejecución de consultas y, en promedio, generan un mejor rendimiento y costos más bajos.
Utilizar estadísticas actualizadas mejora significativamente el rendimiento y el costo total de propiedad (TCO). El análisis comparativo de la ejecución de consultas con y sin estadísticas reveló un aumento promedio del rendimiento del 22 % en las cargas de trabajo observadas. Databricks aplica estas estadísticas para refinar los procesos de escaneo de datos y seleccionar el plan de ejecución de consultas más eficiente. Este enfoque es un ejemplo de las capacidades de la plataforma de inteligencia de datos para ofrecer un valor tangible a los usuarios.
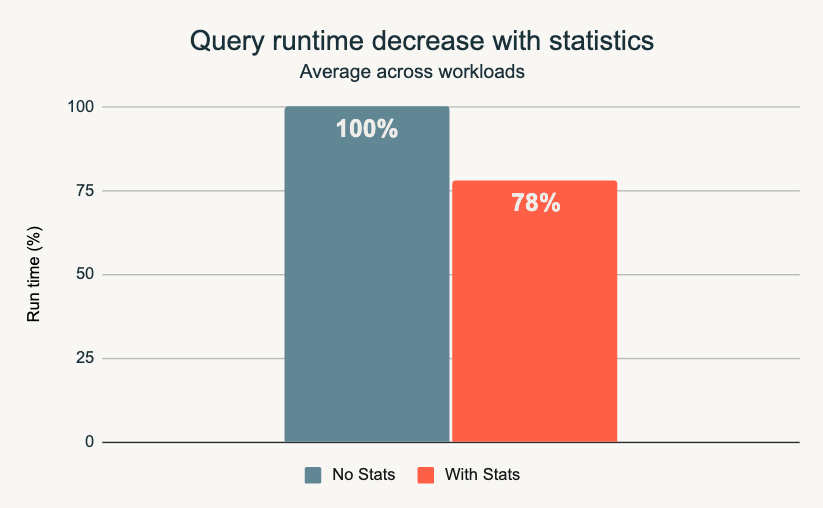
Para obtener más información, lea este blog.
Relación precio-rendimiento de primera clase
El motor de consultas se sigue optimizando para escalar los costos de computación de forma casi lineal con el volumen de datos. Nuestro objetivo es un rendimiento cada vez mejor en un mundo de concurrencia cada vez mayor, con una latencia cada vez menor.
Rendimiento mejorado en general
Databricks SQL ha experimentado una notable mejora del rendimiento del 77 % desde su lanzamiento en 2022, lo que ofrece consultas de BI más rápidas, dashboards más receptivos y una exploración de datos más ágil. Solo en los últimos 5 meses del año, las cargas de trabajo de BI son un 14 % más rápidas, los trabajos de ETL se completan un 9 % más rápido y las cargas de trabajo de exploración han mejorado un 13 %. Además, lanzamos características de simultaneidad mejoradas y compresión avanzada en versión preliminar privada, lo que garantiza que ahorre tiempo y costos.
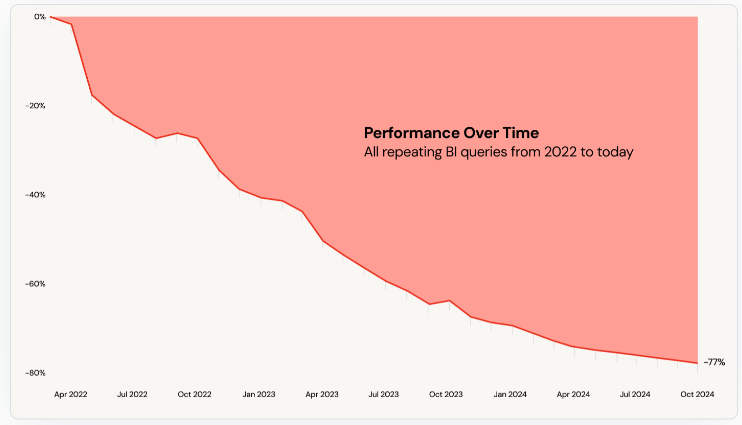
Databricks es nombrado líder en el Magic Quadrant™ de Gartner® de 2024 para sistemas de gestión de bases de datos en la nube
Por cuarto año consecutivo, Databricks ha sido nombrado Líder en el Magic Quadrant™ de Gartner® de 2024 para sistemas de gestión de bases de datos en la nube. Este año, hemos avanzado tanto en la Capacidad de Ejecución como en la Integridad de nuestra Visión. La evaluación abarcó la Plataforma de Inteligencia de Datos de Databricks en AWS, Google Cloud y Azure, junto con otros 19 proveedores.
Administración y gestión
Estamos ampliando las capacidades para ayudar a los administradores del espacio de trabajo a configurar y gestionar los almacenes de SQL, incluidas las tablas del sistema y un nuevo gráfico para solucionar problemas de rendimiento del almacén.
Gestión de costos
Para darte visibilidad de cómo tu organización utiliza Databricks, puedes usar los datos de facturación y costos en tus tablas de sistema. Para facilitar eso, ahora tenemos un panel de costos de AI/BI predefinido. El panel organiza tus datos de consumo utilizando las mejores prácticas de etiquetado y te ayuda a crear presupuestos para gestionar tus gastos a nivel de organización, unidad de negocio o proyecto. Luego, puedes configurar alertas de presupuesto para cuando excedas el presupuesto (y rastrear qué proyecto/carga de trabajo/usuario superó el gasto).
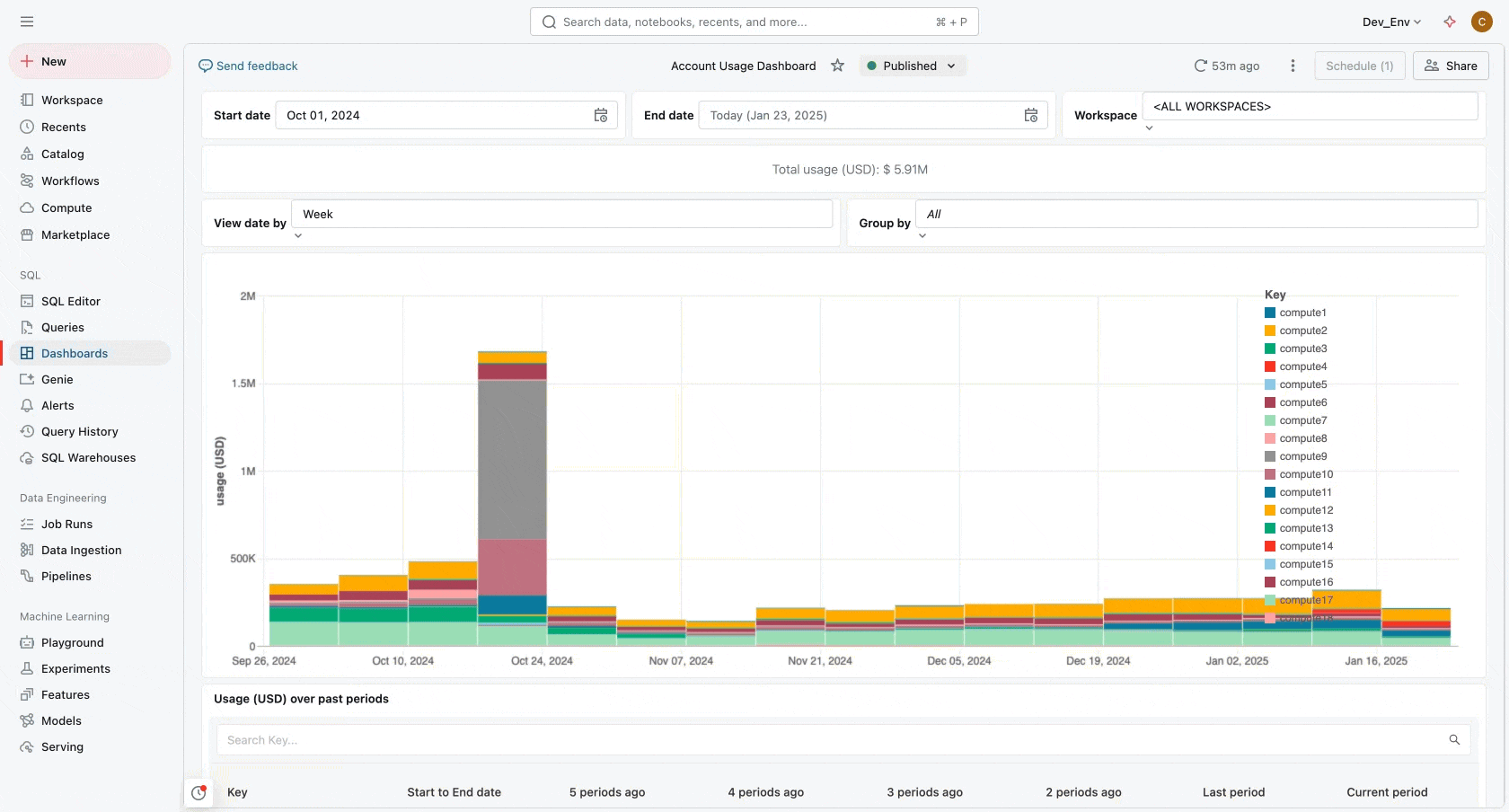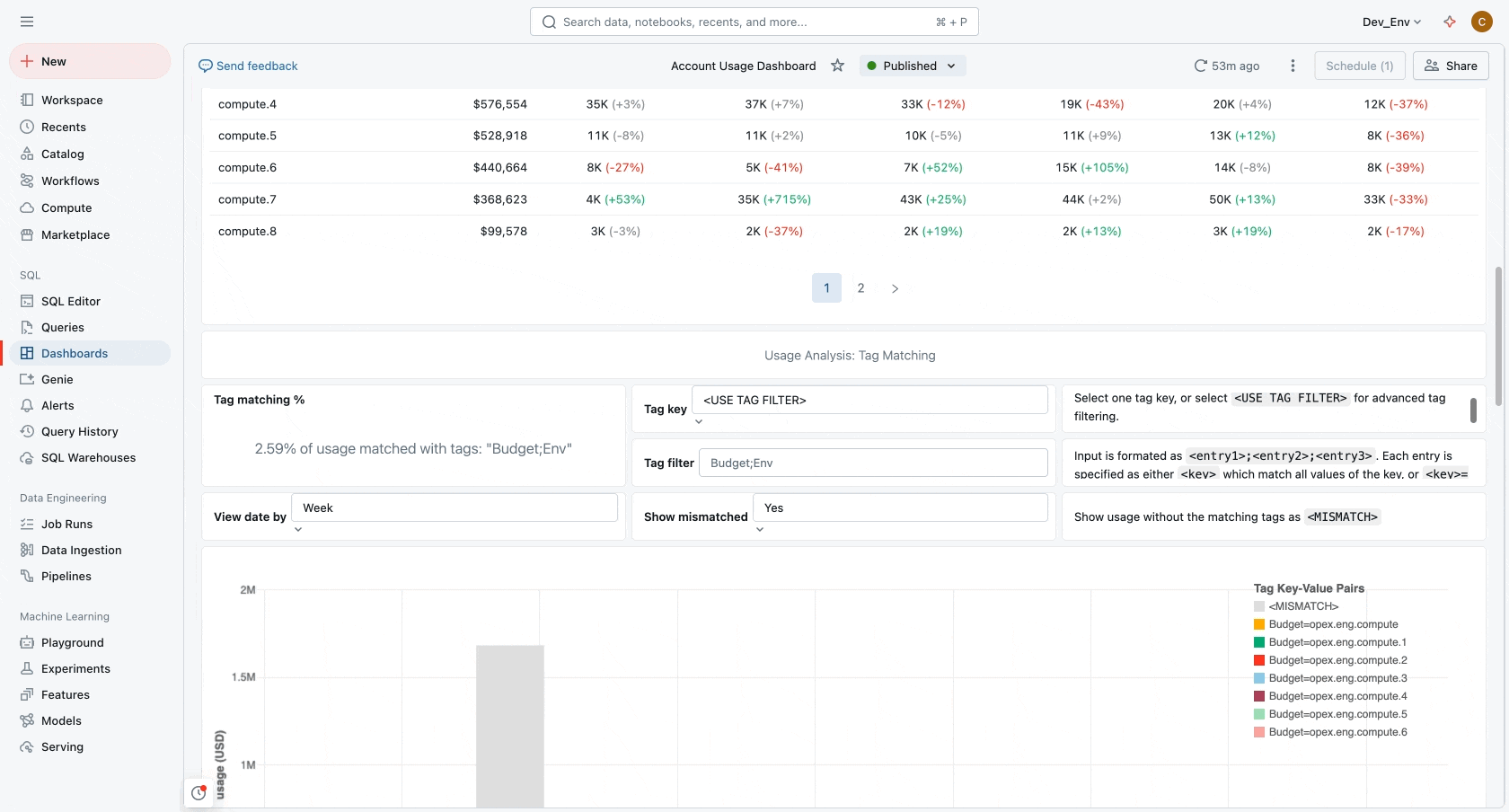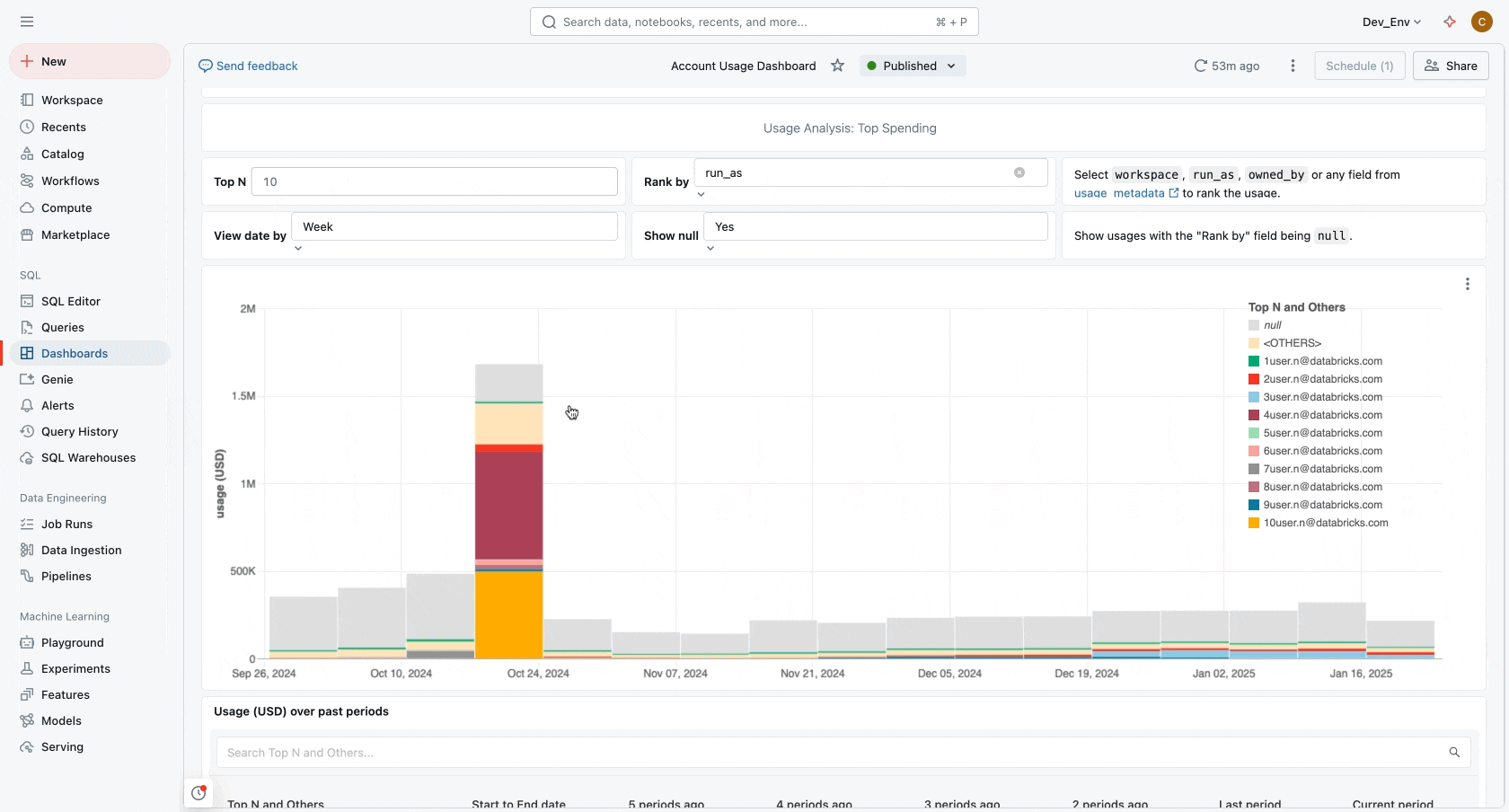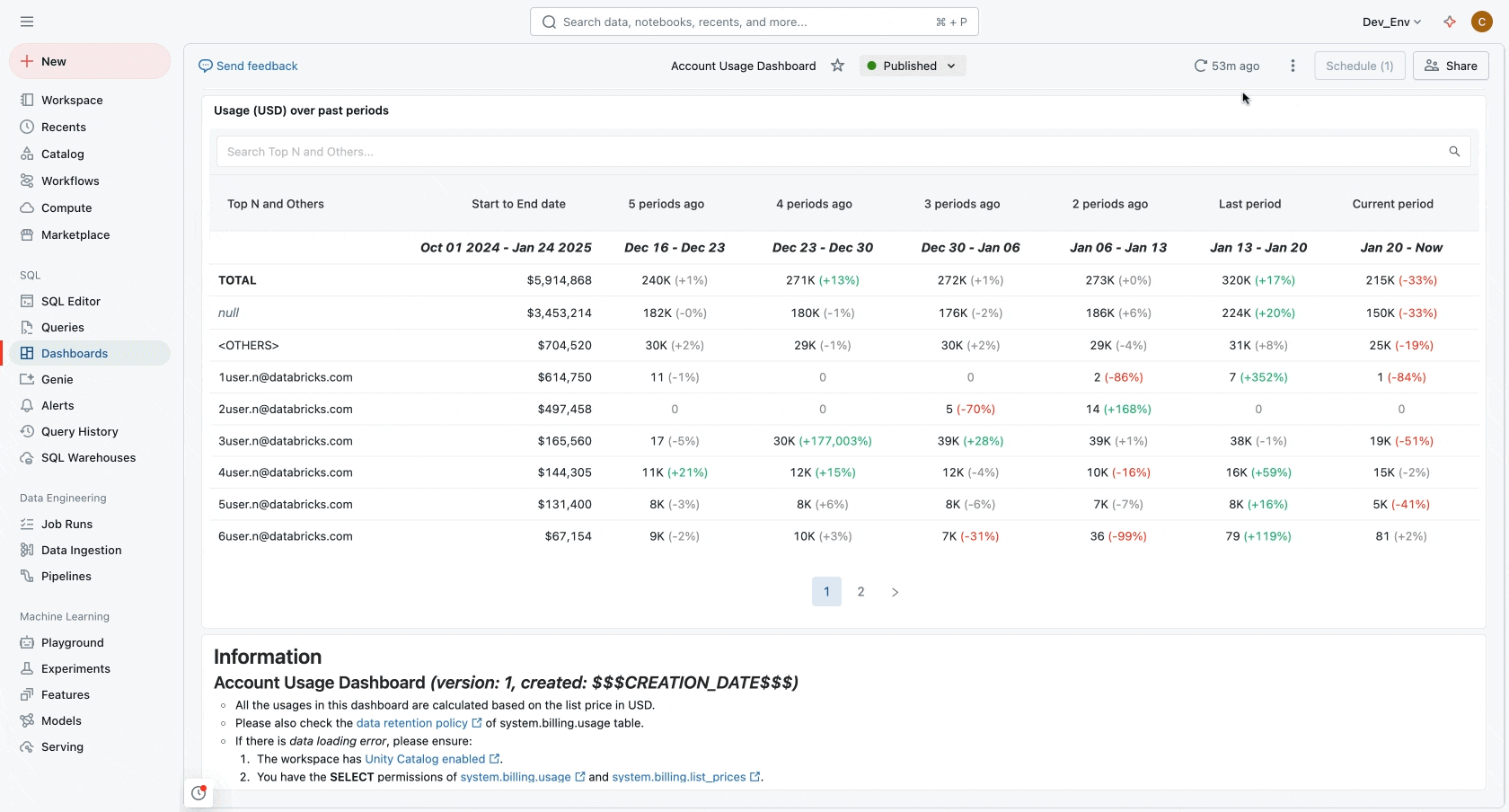
Para obtener más información, consulte este blog sobre gestión de costos.
Tablas del sistema
Recomendamos las tablas del sistema para observar detalles esenciales sobre su cuenta de Databricks, incluida la información de costos, el acceso a los datos, el rendimiento de la carga de trabajo, etc. Específicamente, son tablas propiedad de Databricks a las que puede acceder desde varias superficies, normalmente con baja latencia.
Almacenes
La tabla del sistema de almacenes (tabla system.compute.warehouses) registra cuándo se crean, editan y eliminan los almacenes de SQL. Puede usar la tabla para supervisar los cambios en la configuración del almacén, incluidos el nombre del almacén, el tipo, el tamaño, el canal, las etiquetas, la detención automática y la configuración de escalado automático. Cada fila es una instantánea de las propiedades de un almacén de SQL en un momento específico. Se crea una nueva instantánea cuando cambian las propiedades. Para obtener más detalles, consulte la referencia de la tabla de sistema de almacenes. Esta característica está en versión preliminar pública.
Historial de consultas
La tabla del historial de consultas (system. query.history) incluye registros de consultas ejecutadas con almacenes de SQL o proceso sin servidor para notebooks y trabajos. La tabla consta de registros de toda la cuenta de todas las áreas de trabajo en la misma región desde la que se accede a la tabla. Esta característica está en versión preliminar pública.
Para obtener más detalles, consulte la referencia de la tabla del sistema de historial de consultas.
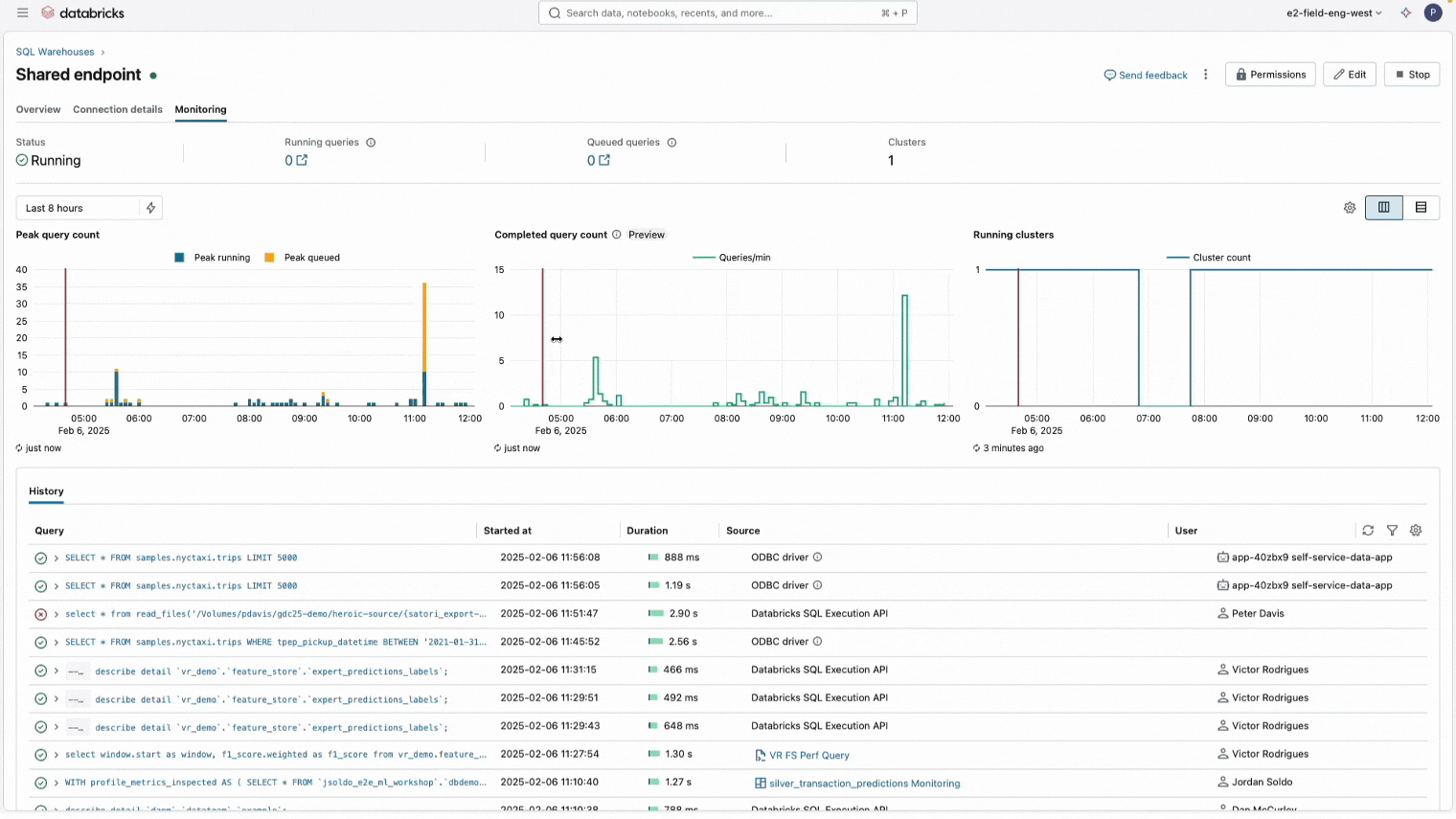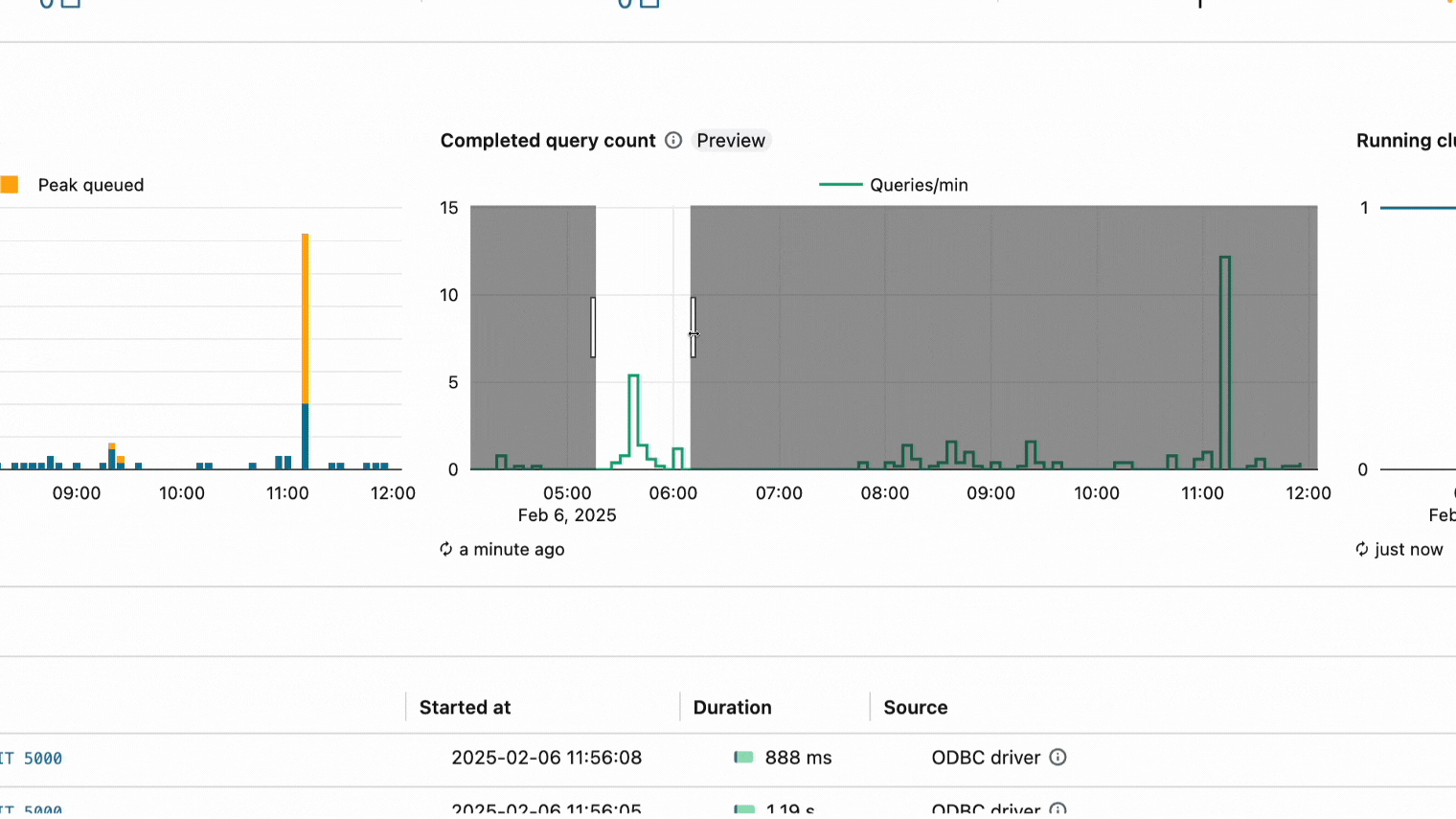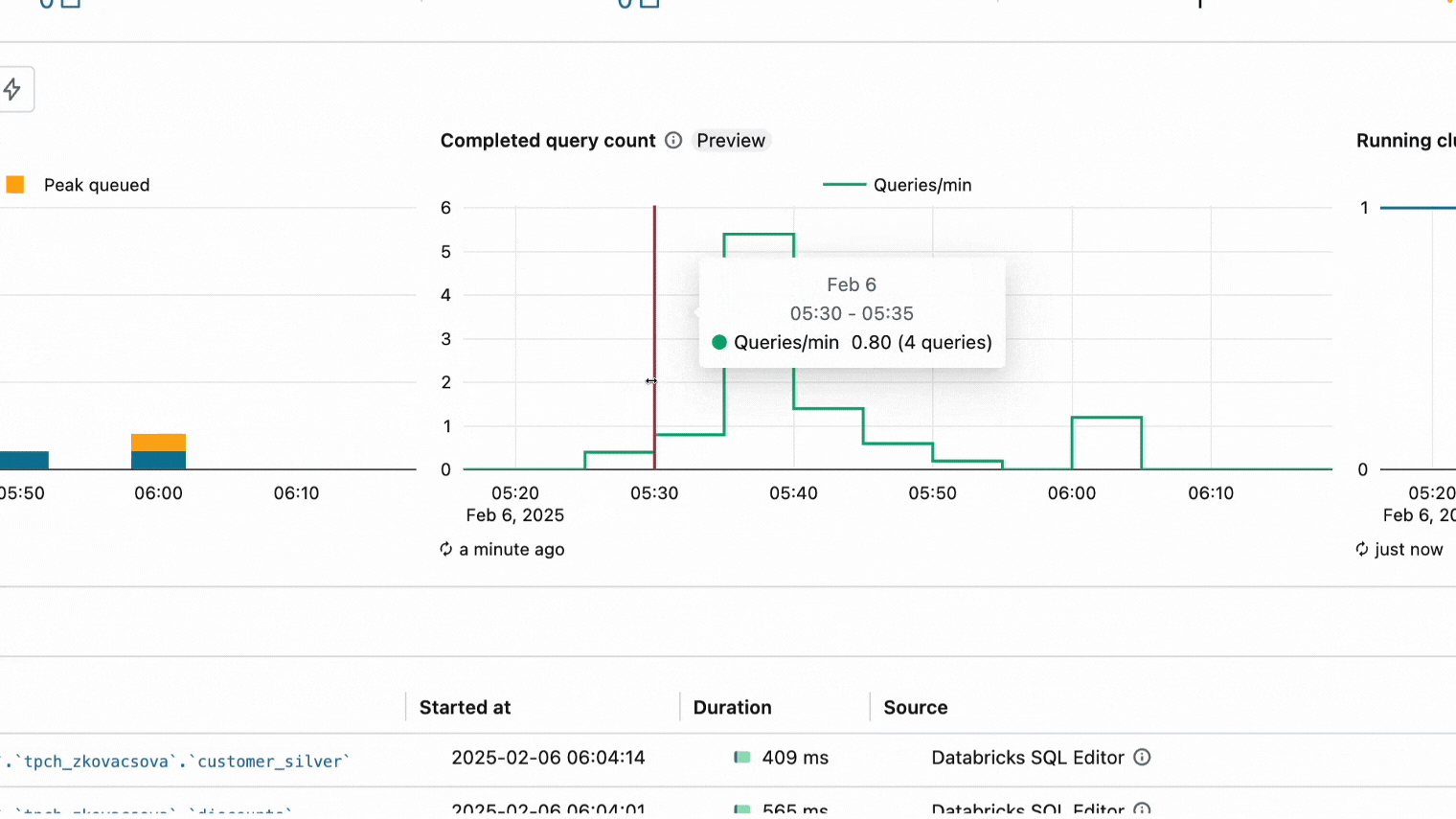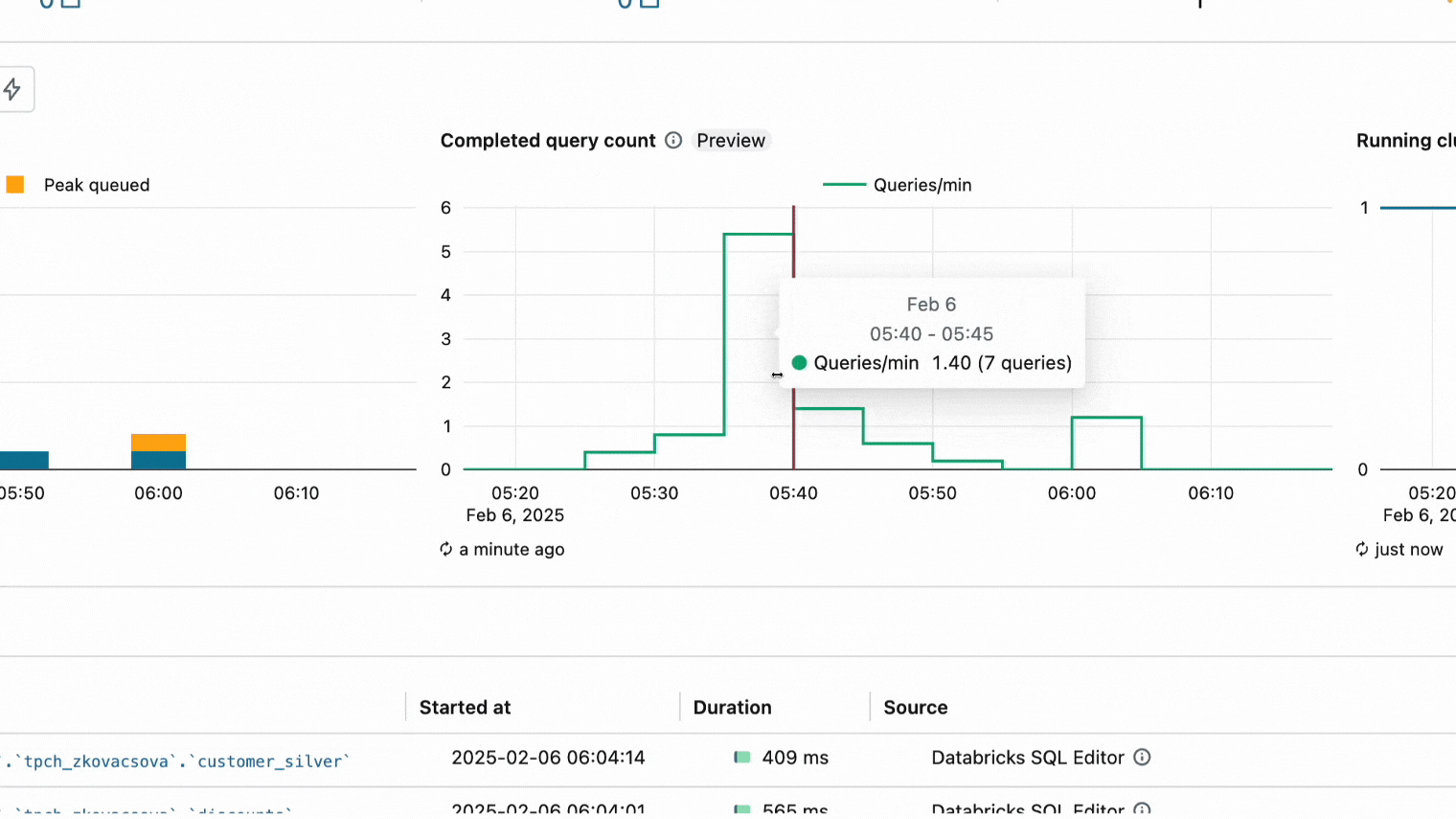
Gráfico de recuento de consultas completadas para ayudar a solucionar problemas de rendimiento del warehouse.
Un gráfico de recuento de consultas completadas (versión preliminar pública) ya está disponible en la UI de supervisión de SQL Warehouse. Este nuevo gráfico muestra el número de consultas finalizadas en una ventana de tiempo. El gráfico se puede utilizar junto con el gráfico de picos de consultas y clústeres en ejecución para visualizar los cambios en el rendimiento del almacén a medida que los clústeres se activan o desactivan en función del tráfico de su carga de trabajo y la configuración del almacén. Para obtener más información, consulte Supervisar un SQL Warehouse.
Ampliación de regiones y disponibilidad de cumplimiento para Databricks SQL Serverless
La disponibilidad y el cumplimiento se amplían para los warehouses de Databricks SQL Serverless.
- Nuevas regiones de Serverless:
- GCP ya está disponible de forma general en las siete regiones existentes.
- AWS agrega la región eu-west-2 para Londres.
- Azure agrega cuatro regiones: France Central, Sweden Central, Germany West Central y UAE North.
- Cumplimiento de normativas para serverless por región
- HIPAA: El cumplimiento de HIPAA está disponible en todas las regiones donde Serverless SQL está disponible en todos los proveedores de la nube (Azure, AWS y GCP).
- AWS US-East-1: El cumplimiento con PCI-DSS y FedRamp Mod ya está disponible de forma general
- AWS AP-Southeast-2: Cumplimiento de PCI-DSS e IRAP ahora en GA
- Seguridad serverless
- Enlace privado: enlace privado te ayuda a usar una red privada desde tus usuarios hasta tus datos y de vuelta. Ya está disponible de forma general.
- Secure Egress ayuda a controlar de forma segura el acceso a los datos de salida, garantizando la seguridad y el cumplimiento. Configurar controles de egreso ya está disponible en versión preliminar pública.
Integración con la Plataforma de Inteligencia de Datos
Estas características para Databricks SQL forman parte de Databricks Data Intelligence Platform. Databricks SQL se beneficia de las capacidades de la plataforma de simplicidad, gobierno unificado y apertura de la arquitectura de lakehouse. A continuación, se presentan algunas funciones nuevas de la plataforma que benefician a Databricks SQL.
Mejoras del lenguaje SQL: Intercalaciones
Crear aplicaciones empresariales globales implica manejar diversos idiomas y una entrada de datos incoherente. Las intercalaciones optimizan el procesamiento de datos al definir reglas para ordenar y comparar texto de forma que se respete el idioma y la distinción entre mayúsculas y minúsculas. Las intercalaciones hacen que las bases de datos reconozcan el idioma y el contexto, lo que garantiza que gestionen el texto como esperan los usuarios.
Estamos muy contentos de que las intercalaciones ya estén disponibles en versión preliminar pública con Databricks SQL. Lea el blog sobre intercalaciones para obtener más detalles.
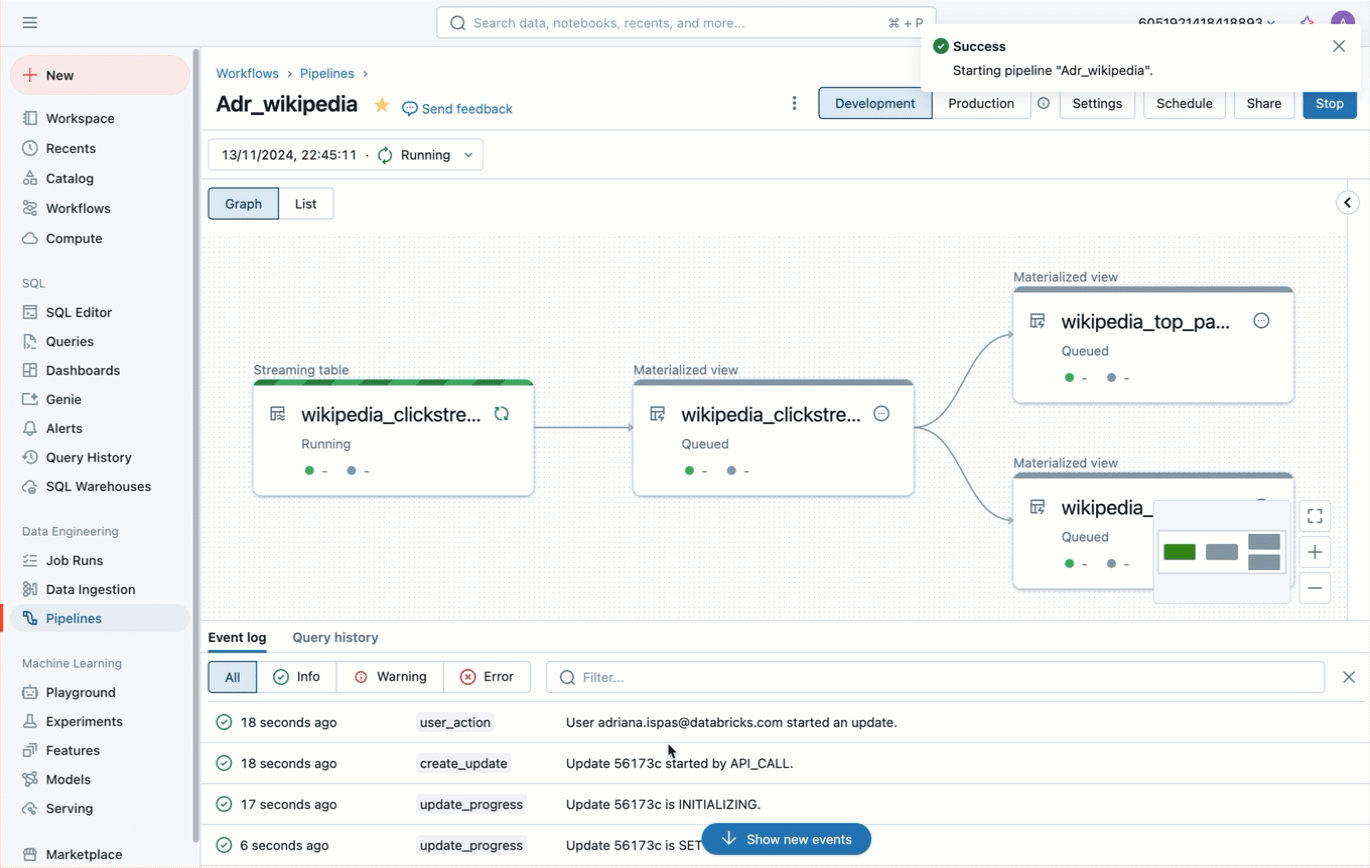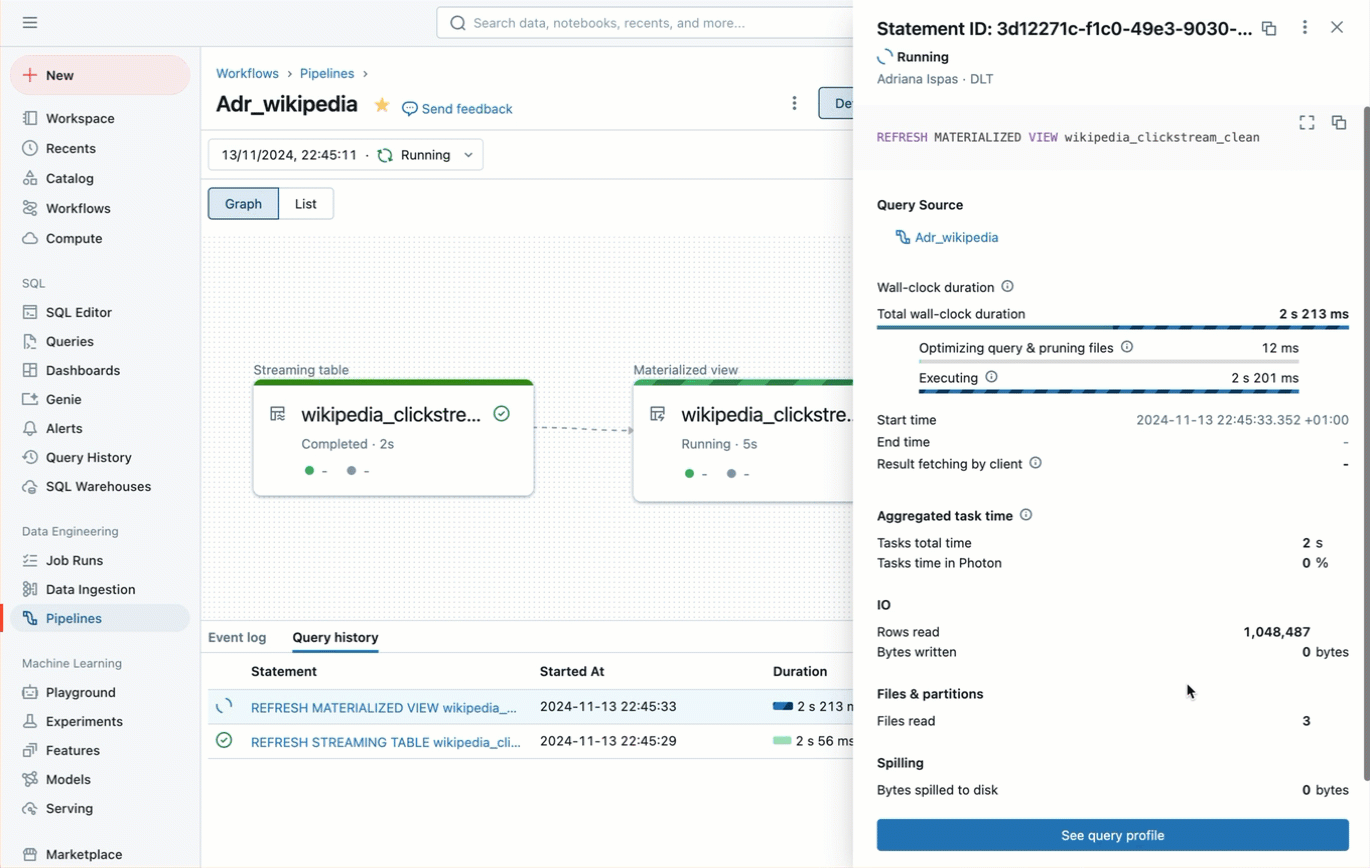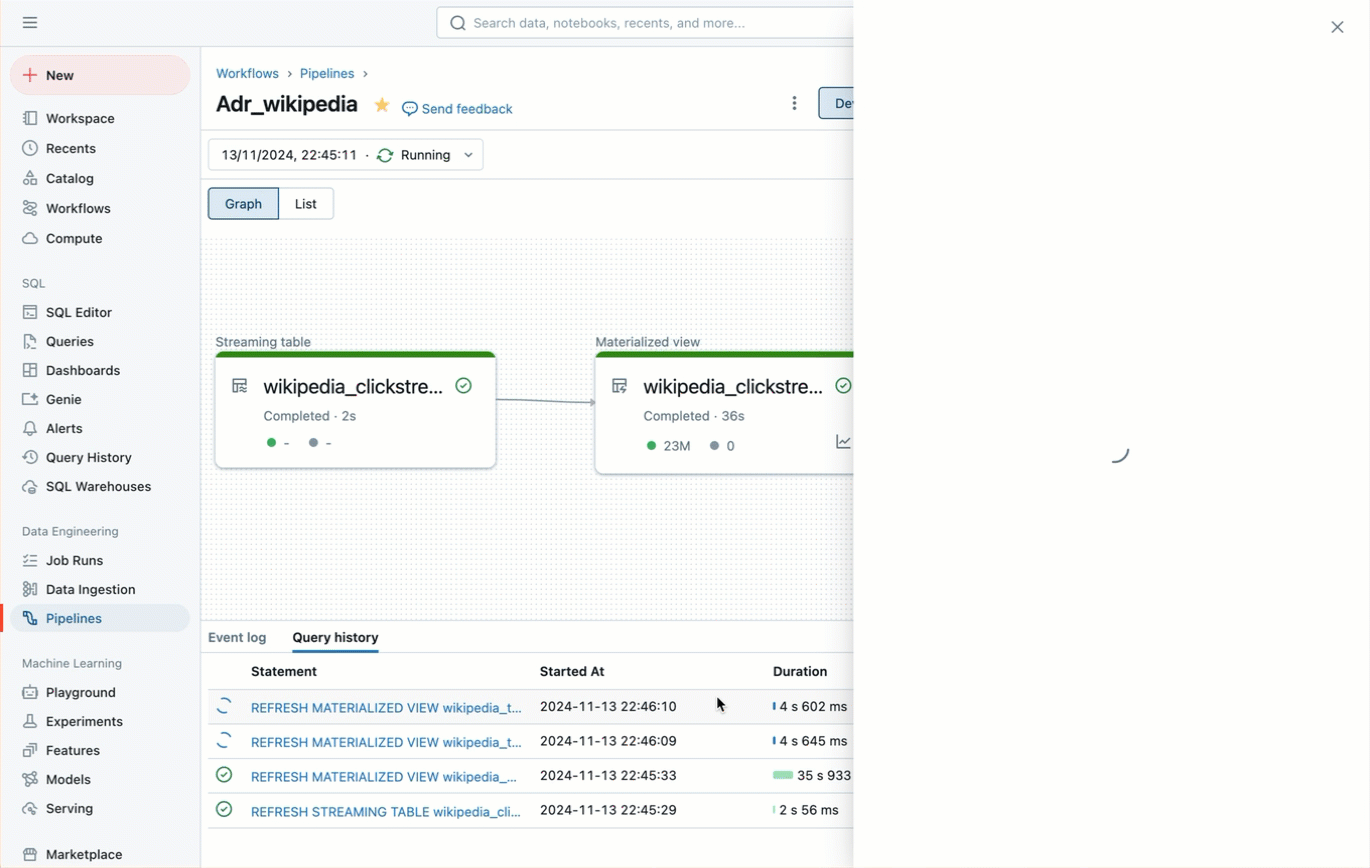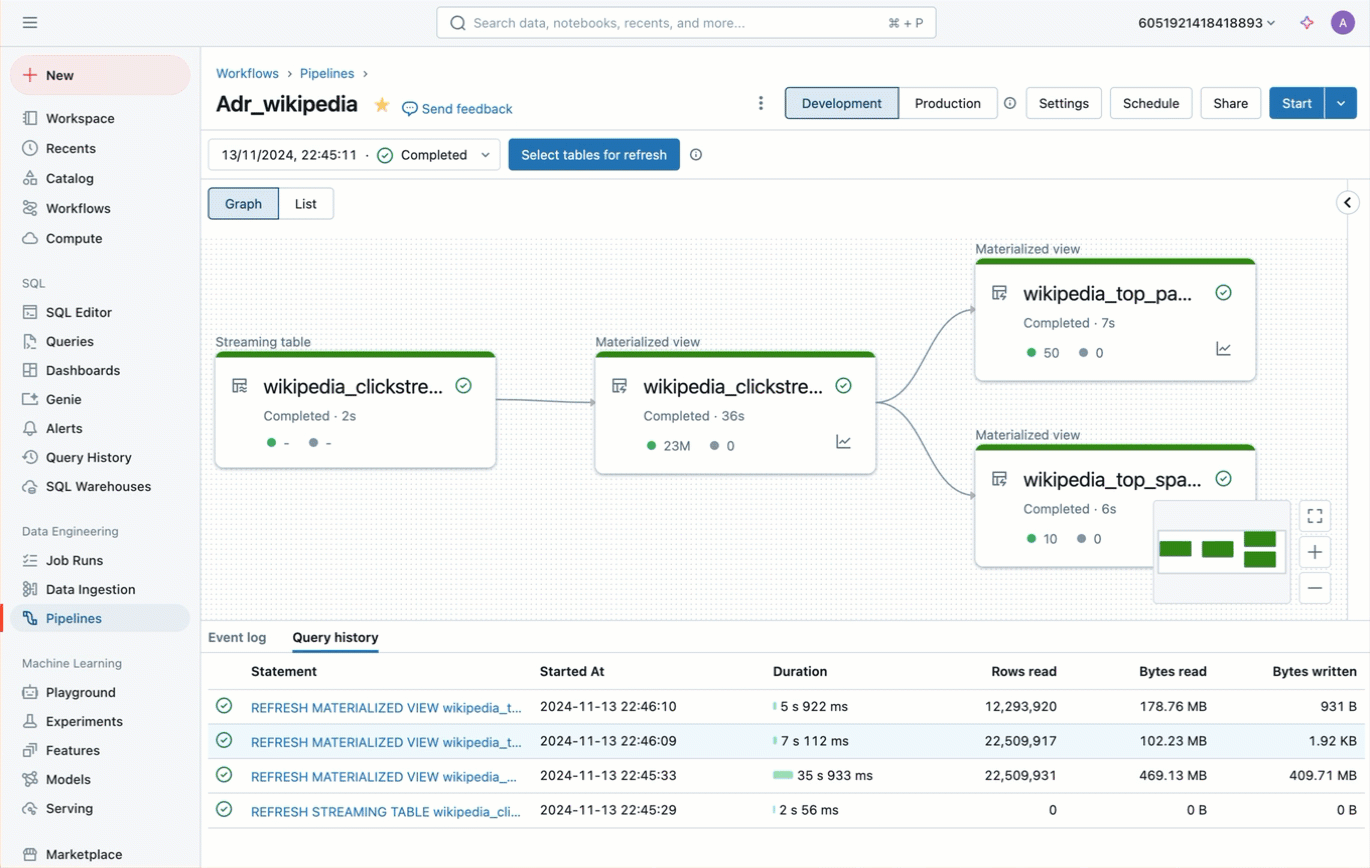
Vistas materializadas y tablas de streaming
Las vistas materializadas (MV) y las tablas de streaming (ST) ya están disponibles de forma general en Databricks SQL en AWS, Azure y GCP. Las tablas de streaming ofrecen una ingesta sencilla e incremental desde fuentes como el almacenamiento en la nube y los buses de mensajes con solo unas pocas líneas de SQL. Las vistas materializadas precalculan y actualizan de forma incremental los resultados de las consultas para que sus paneles y consultas puedan ejecutarse de forma mucho más rápida que antes. Juntas, te permiten crear canalizaciones de datos eficientes y escalables usando SQL, desde la ingesta hasta la transformación.
Para más información, lee la publicación del blog sobre el anuncio de MV y ST.
Programación más sencilla para las tablas de streaming y las vistas materializadas de Databricks SQL.
Introdujimos la sintaxis EVERY para programar las actualizaciones de MV y ST usando DDL. EVERY simplifica la programación basada en el tiempo, eliminando la necesidad de escribir expresiones CRON complejas. Para los usuarios que necesitan más flexibilidad, se seguirá admitiendo la programación con CRON.
Para obtener más información, lea la documentación de ALTER MATERIALIZED VIEW, ALTER STREAMING TABLE, CREATE MATERIALIZED VIEW y CREATE STREAMING TABLE.
Compatibilidad de las tablas de streaming para consultas de time travel.
Ahora puede usar time travel para consultar versiones anteriores de la tabla de streaming basadas en marcas de tiempo o versiones de la tabla (tal y como se registran en el registro de transacciones). Es posible que tenga que actualizar su tabla de streaming antes de usar las consultas de time travel.
Las consultas de viaje en el tiempo no se admiten para las vistas materializadas.
Soporte del historial de consultas para Delta Live Tables
El historial de consultas y el perfil de consulta ahora cubren las consultas ejecutadas a través de una canalización DLT. Además, se han mejorado los insights de las consultas para las vistas materializadas (MV) y las tablas de streaming (ST) de Databricks SQL. Se puede acceder a estas consultas desde la página Historial de consultas junto con las consultas ejecutadas en SQL Warehouses y Serverless Compute. También se enumeran en el contexto de la UI de Pipeline, los Notebooks y el editor de SQL.
Esta característica está disponible en Vista Previa Pública. Para obtener más detalles, consulte Acceder al historial de consultas de las canalizaciones de Delta Live Table.
Uso compartido de vistas multiplataforma para Azure Databricks
Los destinatarios de Databricks ahora pueden consultar vistas compartidas usando cualquier recurso de computación de Databricks. Anteriormente, si la cuenta de Azure Databricks de un destinatario difería de la del proveedor, los destinatarios solo podían consultar una vista compartida mediante un almacén de SQL sin servidor. Consulta Leer vistas compartidas.
El uso compartido de vistas ahora también se extiende a los conectores de uso compartido abierto. Consulta Leer datos compartidos mediante el uso compartido abierto de Delta Sharing (para destinatarios).
Esta funcionalidad ya está en versión preliminar pública.
Más detalles sobre las nuevas innovaciones
Esperamos que disfrute de esta gran cantidad de innovaciones en Databricks SQL. Siempre puede consultar esta publicación de novedades de los tres meses anteriores. A continuación se muestra un inventario completo de los lanzamientos sobre los que hemos publicado en el blog durante el último trimestre:
- Febrero de 2025: Novedades de AI/BI: feb. de 2025
- Febrero de 2025: Le damos la bienvenida a BladeBridge a Databricks: aceleración de las migraciones de almacenes de datos a Lakehouse
- Enero de 2025: Formas sencillas de optimizar tus costos
- Enero de 2025: Introducción de las intercalaciones en Databricks
- Diciembre de 2024: Databricks es nombrado líder en el Magic Quadrant de Gartner de 2024 para sistema de gestión de bases de datos en la nube
- Diciembre de 2024: Guía paso a paso para el análisis de opiniones de clientes impulsado por IA
- Noviembre de 2024: Presentación de las estadísticas de optimización predictiva
- Noviembre de 2024: Novedades en AI/BI Dashboards: otoño del 24
Como siempre, seguimos trabajando para ofrecerle aún más características geniales. Esté atento a los seminarios web trimestrales sobre la hoja de ruta para saber qué se avecina para el almacenamiento de datos y AI/BI. Es un momento emocionante para trabajar con datos, y estamos encantados de asociarnos con arquitectos de datos, analistas, analistas de BI y otros para democratizar los datos y la IA dentro de sus organizaciones.
Próximos pasos
Este es un breve adelanto de las funciones en las que estamos trabajando. Ninguna de estas funciones tiene plazos confirmados todavía, así que aún no podemos compartir fechas. :-)
Migre fácilmente su data warehouse a Databricks SQL.
Los clientes de todos los tamaños pueden reducir significativamente los costos y disminuir los riesgos al modernizar su infraestructura de datos y abandonar las plataformas patentadas, costosas y aisladas que han definido la historia del almacenamiento de datos. Estamos trabajando para ampliar las herramientas gratuitas que te ayudarán a analizar lo que se necesitaría para migrar desde tu almacén de datos actual a Databricks SQL y a convertir tu código para aprovechar las nuevas características de Databricks SQL.
Potencia al máximo tus cargas de trabajo de BI
El rendimiento es fundamental al cargar paneles de inteligencia de negocios. Estamos mejorando la latencia de las consultas de BI cada trimestre para que pueda potenciar sus herramientas de BI favoritas, como Power BI, Tableau, Looker y Sigma, con Databricks SQL.
Simplifique la gestión y la supervisión de los almacenes.
Estamos invirtiendo en más características y herramientas para ayudarlo a administrar y supervisar fácilmente su almacén. Esto incluye mejoras en la tabla del sistema, cambios a través de la UI y nuestras API.
Para obtener más información sobre Databricks SQL, visita nuestro sitio web o lee la documentación. También puedes consultar el recorrido del producto de Databricks SQL. Supongamos que quieres migrar tu almacén de datos existente a un almacén de datos serverless de alto rendimiento con una excelente experiencia de usuario y un menor costo total. En ese caso, Databricks SQL es la solución — pruébelo gratis.
Para participar en versiones preliminares privadas o públicas restringidas, póngase en contacto con su equipo de cuenta de Databricks.
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.