¿Qué es la capa convolucional?
Una capa de red neuronal que aplica filtros convolucionales aprendibles a los datos de entrada y detecta características espaciales a través de campos receptivos localizados.
- Aplica núcleos pequeños (normalmente filtros de 3x3 o 5x5) que se deslizan por las imágenes de entrada con parámetros de paso y relleno, utilizando pesos compartidos para reducir drásticamente los parámetros en comparación con las capas completamente conectadas.
- Detecta características espaciales jerárquicas: las capas iniciales identifican bordes y texturas, las capas intermedias reconocen formas y patrones, y las capas más profundas detectan objetos complejos y conceptos semánticos.
- Suele seguir a las funciones de activación (ReLU), la normalización por lotes y las capas de agrupación para la invariancia de la traducción, que constituyen los componentes básicos de las CNN para la visión artificial.
En el aprendizaje profundo, una red neuronal convolucional (CNN o ConvNet) es una clase de redes neuronales profundas, que generalmente se usan para reconocer patrones presentes en imágenes, pero también se usan para el análisis de datos espaciales, la visión artificial, el procesamiento de lenguaje natural, el procesamiento de señales y diversos otros fines. La arquitectura de una red convolucional se asemeja al patrón de conectividad de las neuronas en el cerebro humano y se inspiró en la organización de la corteza visual. Este tipo específico de red neuronal artificial recibe su nombre de una de las operaciones más importantes de la red: la convolución.
¿Qué es una convolución?
La convolución es un procedimiento ordenado donde dos fuentes de información se entrelazan; es una operación que transforma una función en otra cosa. Las convoluciones se usaron durante mucho tiempo, principalmente en procesamiento de imágenes para desenfocar y realzar imágenes, además de realizar otras operaciones. Por ejemplo, Las CNN (realzan los bordes y crean relieves) imponen un patrón de conectividad local entre las neuronas de capas adyacentes. 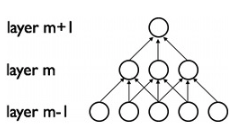 Las CNN emplean filtros (también conocidos como kernels) para detectar qué características, como los bordes, están presentes en una imagen. Hay cuatro operaciones principales en una CNN:
Las CNN emplean filtros (también conocidos como kernels) para detectar qué características, como los bordes, están presentes en una imagen. Hay cuatro operaciones principales en una CNN:
- Convolución
- No linealidad (ReLU)
- Agrupamiento o submuestreo
- Clasificación (capa completamente conectada)
La primera capa de una red neuronal convolucional es siempre una capa convolucional. Las capas convolucionales aplican una operación de convolución a la entrada, y pasan el resultado a la siguiente capa. Una convolución convierte todos los píxeles de su campo receptivo en un solo valor. Por ejemplo, si aplicaras una convolución a una imagen, disminuirás el tamaño de la imagen y reunirás toda la información del campo en un solo píxel. La salida final de la capa convolucional es un vector. En función del tipo de problema que necesitamos resolver y del tipo de características que buscamos aprender, podemos emplear diferentes tipos de convoluciones.
La capa de convolución 2D
El tipo más común de convolución que se utiliza es la capa de convolución 2D, que generalmente se abrevia como conv2D. Un filtro o un kernel en una capa conv2D “se desliza” sobre los datos de entrada 2D, realizando una multiplicación elemento por elemento. Como consecuencia, sumará los resultados en un único píxel de salida. El kernel realizará la misma operación para cada ubicación sobre la que se deslice, y transformará una matriz 2D de características en otra matriz 2D diferente de características.
La convolución dilatada o dilatada
Esta operación expande el tamaño de la ventana sin aumentar el número de pesos al insertar valores cero en los kernels de convolución. Las convoluciones dilatadas o atrous se pueden usar en aplicaciones en tiempo real y en aplicaciones donde la potencia de procesamiento es menor, ya que los requerimientos de RAM son menos intensivos.
La guía de IA agéntica para la empresa

Convoluciones separables
Hay dos tipos principales de convoluciones separables: convoluciones separables espaciales y convoluciones separables en profundidad. La convolución separable espacial se ocupa principalmente de las dimensiones espaciales de una imagen y un núcleo: el ancho y el alto. En comparación con las convoluciones separables espaciales, las convoluciones separables en profundidad funcionan con núcleos que no se pueden “factorizar” en dos núcleos más pequeños. Como consecuencia, se usa con más frecuencia.
Convoluciones transpuestas
Estos tipos de convoluciones también se conocen como deconvoluciones o convoluciones con pasos fraccionados. Una capa convolucional transpuesta lleva a cabo una convolución regular, pero revierte su transformación espacial.
Recursos adicionales
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.