¿Qué es Data Vault?
Metodología de modelado de datos que utiliza tablas centrales, de enlace y satélite con seguimiento histórico, capacidad de auditoría y control de versiones integrado para almacenamiento empresarial
- Las tablas de hub almacenan claves empresariales únicas y metadatos (fecha de carga, origen) que representan entidades empresariales clave como clientes, productos y pedidos sin atributos descriptivos, lo que permite un modelado flexible de relaciones y un seguimiento histórico.
- Las tablas de enlace capturan relaciones de muchos a muchos entre hubs con claves externas y atributos de contexto, lo que facilita procesos empresariales complejos y la evolución de las relaciones sin modificar las estructuras existentes.
- Las tablas satélite contienen atributos descriptivos, seguimiento temporal (fechas de entrada en vigor) e historial de atributos para hubs y enlaces, implementando dimensiones de cambio gradual con total auditabilidad y admitiendo la carga paralela desde múltiples fuentes.

¿Qué es un Data Vault?
Una bóveda de datos es un patrón de diseño de modelado de datos utilizado para construir un almacenamiento de datos para análisis a escala empresarial. La bóveda de datos tiene tres tipos de entidades: concentradores, enlaces y satélites.
Los concentradores representan conceptos básicos de la empresa, los enlaces representan las relaciones entre los concentradores y los satélites almacenan información sobre los concentradores y las relaciones entre ellos.
La bóveda de datos es un modelo de datos bien adaptado para las organizaciones que están adoptando el paradigma de lakehouse.
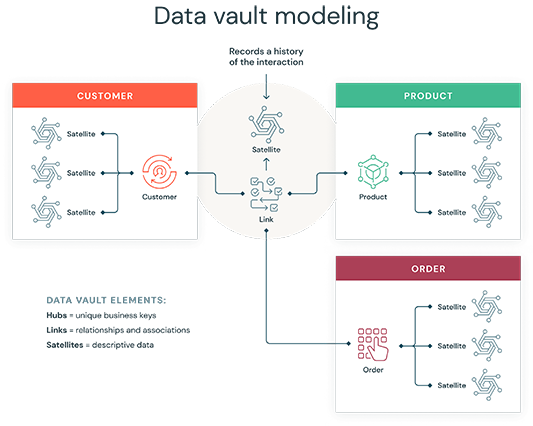
Modelado de bóvedas de datos: concentradores, enlaces y satélites
- Concentrador: cada concentrador representa un concepto empresarial central, como el identificador de cliente, el número de producto o el número de identificación del vehículo (VIN). Los usuarios usarán una clave empresarial para obtener información sobre un concentrador. La clave empresarial puede tener una combinación de ID de concepto de negocio e ID de secuencia, fecha de carga y otra información de metadatos.
- Enlaces: los enlaces representan la relación entre los concentradores.
- Satélites: los satélites llenan el vacío al proporcionar la información descriptiva que falta sobre los conceptos empresariales fundamentales. Los satélites almacenan información que pertenece al concentrador y a las relaciones entre ellos.
Algunas cosas adicionales a considerar:
- Un satélite no puede tener una conexión directa con otro satélite.
- Un concentrador o enlace puede tener uno o más satélites.
La guía de IA agéntica para la empresa

Beneficios de la bóveda de datos
- Ágil
- Estructurada, con flexibilidad para la refactorización
- Extremadamente escalable, hasta volúmenes de PB
- Emplea patrones que admiten la generación de código de ETL
- Arquitectura familiar: capas de datos, ETL, esquemas en estrella
Las bóvedas de datos se basan en metodologías y técnicas ágiles, lo que significa que pueden adaptarse a los rápidos y cambiantes requerimientos del negocio. Uno de los principales beneficios de emplear la metodología de bóveda de datos es que los trabajos de ETL necesitan menos refactorización cuando cambia el modelo.
Técnicas de modelado por capa de lakehouse
Con estos conceptos en mente, exploremos cómo la bóveda de datos se integra con nuestras capas de datos de bronce, plata y oro, donde los datos pasan de un estado bruto a uno refinado, listo para el análisis. En esta arquitectura de medallón, los datos sin procesar se almacenan en una capa de bronce con una transformación mínima y una estructura de datos lo más cercana posible al sistema de origen. La metodología de bóveda de datos se puede aplicar a la capa de plata, donde los datos se transforman en concentradores, enlaces y satélites.
En la capa de oro, se pueden construir múltiples data marts/almacenamientos de datos según el modelado dimensional/metodología Kimball. Como dijimos antes, la capa de oro se utiliza para la generación de informes y emplea modelos de datos más desnormalizados y optimizados para la lectura, con menos combinaciones. A veces, las tablas de la capa de oro pueden desnormalizarse por completo, en general, cuando los científicos de datos así lo desean para alimentar sus algoritmos para la ingeniería de características.
Usar un modelo de bóveda de datos en la capa de plata simplifica y reduce significativamente los cambios necesarios para hacer ETL en los data marts y almacenamientos de datos, ya que los concentradores facilitan la gestión de claves (claves suplentes/claves naturales). Los satélites facilitan la carga de dimensiones porque tienen todos los atributos, y los enlaces hacen que cargar tablas de hechos sea bastante sencillo porque tienen todas las relaciones.
RECURSOS
- Plataforma Data Lakehouse de Databricks
- Página del producto Databricks SQL
- Blog de Databricks: Diferentes técnicas de modelado de almacenamiento de datos y cómo implementarlas en la plataforma Databricks Lakehouse
- Blog de Databricks: qué es una bóveda de datos y cómo implementarla en la plataforma Lakehouse de Databricks
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.