Técnicas de modelado de Data Warehousing y su implementación en la plataforma Databricks Lakehouse
Usando Data Vaults y Star Schemas en el Lakehouse
por Soham Bhatt y Deepak Sekar
El lakehouse es un nuevo paradigma de plataforma de datos que combina las mejores características de los data lakes y los data warehouses. Está diseñado como una plataforma de datos a gran escala a nivel empresarial que puede albergar muchos casos de uso y productos de datos. Puede servir como un único repositorio de datos empresarial unificado para todos sus:
- dominios de datos,
- casos de uso de streaming en tiempo real,
- data marts,
- data warehouses dispares,
- almacenes de características de ciencia de datos y sandboxes de ciencia de datos, y
- sandboxes de análisis de autoservicio departamentales.
Dada la variedad de los casos de uso — pueden aplicarse diferentes principios de organización de datos y técnicas de modelado a diferentes proyectos en un lakehouse. Técnicamente, la Plataforma Databricks Lakehouse puede soportar muchos estilos de modelado de datos diferentes. En este artículo, nuestro objetivo es explicar la implementación de los principios de organización de datos Bronce/Plata/Oro del lakehouse y cómo encajan diferentes técnicas de modelado de datos en cada capa.
¿Qué es un Data Vault?
Un Data Vault es un patrón de diseño de modelado de datos más reciente utilizado para construir data warehouses para análisis a escala empresarial en comparación con los métodos Kimball e Inmon.
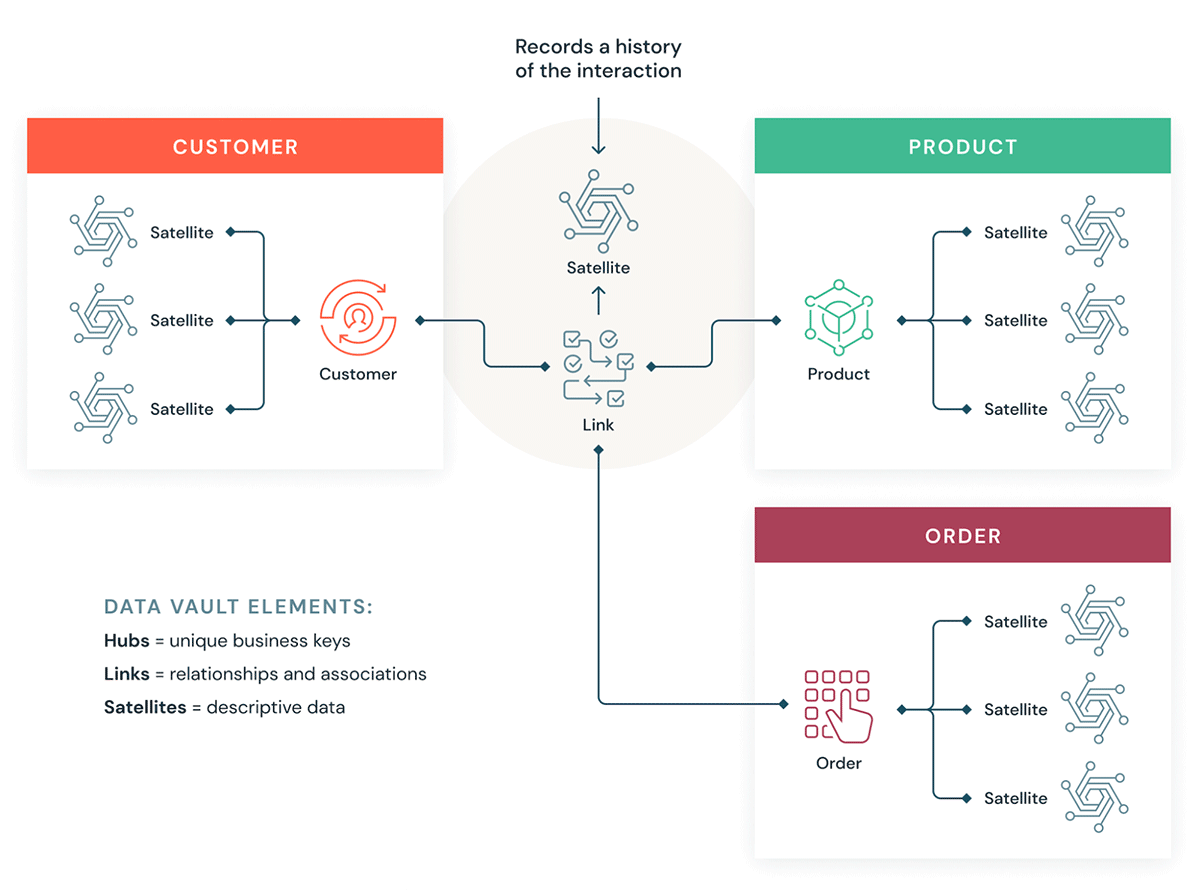
Los Data Vaults organizan los datos en tres tipos diferentes: hubs, links y satellites. Los hubs representan entidades comerciales centrales, los links representan relaciones entre hubs y los satellites almacenan atributos sobre hubs o links.
Data Vault se enfoca en el desarrollo ágil de data warehouses donde la escalabilidad, la integración de datos/ETL y la velocidad de desarrollo son importantes. La mayoría de los clientes tienen una zona de aterrizaje, una zona Vault y una zona de data mart que corresponden a los paradigmas de organización de Databricks de las capas Bronce, Plata y Oro. El estilo de modelado Data Vault de tablas hub, link y satellite típicamente encaja bien en la capa Plata del Databricks Lakehouse.
Obtenga más información sobre el modelado Data Vault en Data Vault Alliance.
¿Qué es el Modelado Dimensional?
El modelado dimensional es un enfoque de abajo hacia arriba para diseñar data warehouses con el fin de optimizarlos para el análisis. Los modelos dimensionales se utilizan para desnormalizar datos comerciales en dimensiones (como tiempo y producto) y hechos (como transacciones en montos y cantidades), y diferentes áreas temáticas se conectan a través de dimensiones conformadas para navegar a diferentes tablas de hechos.
La forma más común de modelado dimensional es el esquema de estrella. Un esquema de estrella es un modelo de datos multidimensional utilizado para organizar los datos de manera que sea fácil de entender y analizar, y muy fácil e intuitivo para ejecutar informes. Los esquemas de estrella de estilo Kimball o los modelos dimensionales son prácticamente el estándar de oro para la capa de presentación en data warehouses y data marts, e incluso para las capas semánticas y de informes. El diseño del esquema de estrella está optimizado para consultar grandes conjuntos de datos.
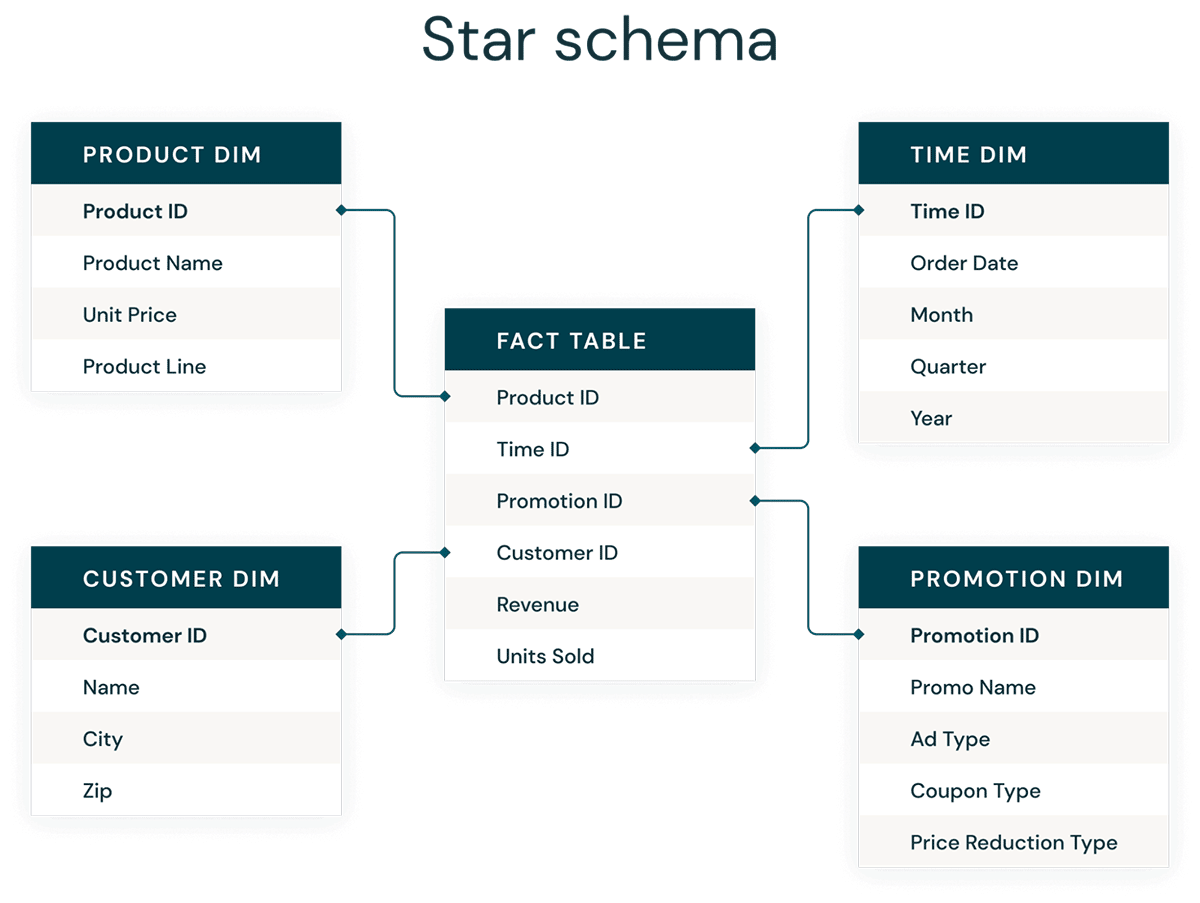
Tanto los estilos de modelado de datos Data Vault normalizados (optimizados para escritura) como los modelos dimensionales desnormalizados (optimizados para lectura) tienen un lugar en el Databricks Lakehouse. Los hubs y satellites de Data Vault en la capa Plata se utilizan para cargar las dimensiones en el esquema de estrella, y las tablas de links de Data Vault se convierten en las tablas clave que impulsan la carga de las tablas de hechos en el modelo dimensional. Obtenga más información sobre el modelado dimensional del Kimball Group.
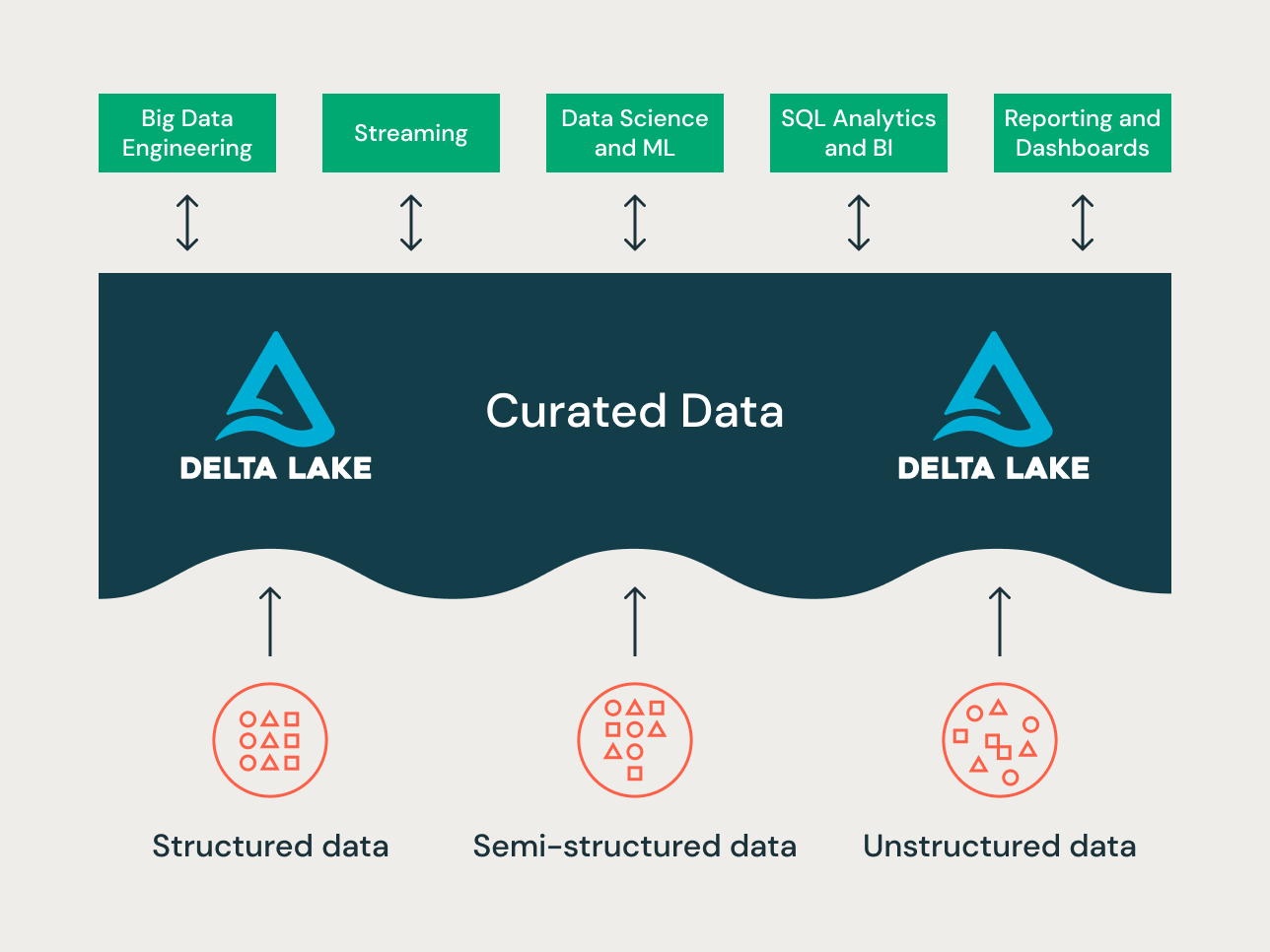
Principios de organización de datos en cada capa del Lakehouse
Un lakehouse moderno es una plataforma de datos empresarial que lo abarca todo. Es altamente escalable y de alto rendimiento para todo tipo de casos de uso diferentes, como ETL, BI, ciencia de datos y streaming, que pueden requerir diferentes enfoques de modelado de datos. Veamos cómo se organiza un lakehouse típico:
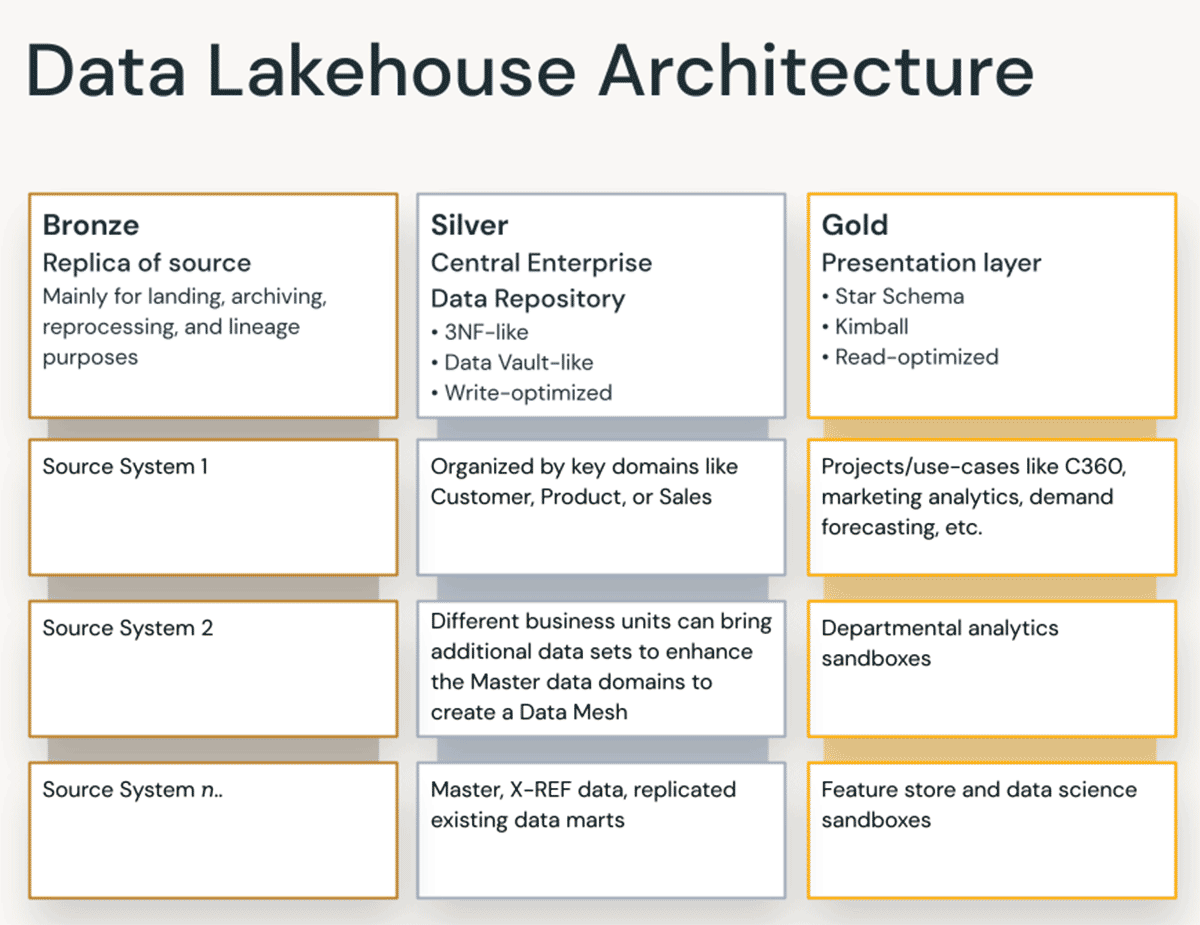
Capa Bronce — la Zona de Aterrizaje
La capa Bronce es donde aterrizamos todos los datos de los sistemas de origen. Las estructuras de tablas en esta capa corresponden a las estructuras de tablas del sistema de origen "tal cual", aparte de las columnas de metadatos opcionales que se pueden agregar para capturar la fecha/hora de carga, el ID del proceso, etc. El enfoque en esta capa está en la captura de datos de cambios (CDC), y la capacidad de proporcionar un archivo histórico de datos de origen (almacenamiento en frío), linaje de datos, auditabilidad y reprocesamiento si es necesario, sin tener que volver a leer los datos del sistema de origen.
En la mayoría de los casos, es una buena idea mantener los datos en la capa Bronce en formato Delta, para que las lecturas posteriores de la capa Bronce para ETL sean de alto rendimiento, y para que pueda realizar actualizaciones en Bronce para escribir cambios de CDC. A veces, cuando los datos llegan en formatos JSON o XML, vemos que los clientes los aterrizan en el formato de datos de origen original y luego los preparan cambiándolos a formato Delta. Por lo tanto, a veces, vemos que los clientes manifiestan la capa Bronce lógica en una zona de aterrizaje y preparación física.
Almacenar datos sin procesar en el formato de datos de origen original en una zona de aterrizaje también ayuda con la consistencia, donde se ingieren datos a través de herramientas de ingesta que no admiten Delta como destino nativo o donde los sistemas de origen envían datos directamente a almacenes de objetos. Este patrón también se alinea bien con el marco de ingesta de Autoloader, donde las fuentes aterrizan los datos en la zona de aterrizaje para archivos sin procesar y luego Databricks AutoLoader convierte los datos a la capa de preparación en formato Delta.
Capa Plata — el Repositorio Central Empresarial
En la capa Plata del Lakehouse, los datos de la capa Bronce se comparan, fusionan, conforman y limpian ("lo justo y necesario") para que la capa Plata pueda proporcionar una "visión empresarial" de todas sus entidades comerciales clave, conceptos y transacciones. Esto es similar a un Almacén de Datos Operacional Empresarial (ODS) o un Repositorio Central o dominios de datos de una Data Mesh (por ejemplo, clientes maestros, productos, transacciones no duplicadas y tablas de referencias cruzadas). Esta visión empresarial reúne los datos de diferentes fuentes y permite el análisis de autoservicio para informes ad hoc, análisis avanzados y ML. También sirve como fuente para analistas departamentales, ingenieros de datos y científicos de datos para crear proyectos de datos y análisis para responder problemas de negocio a través de proyectos de datos empresariales y departamentales en la capa Oro.
En el paradigma de Ingeniería de Datos del Lakehouse, típicamente se sigue la metodología ELT (Extract-Load-Transform) en lugar de la tradicional ETL (Extract-Transform-Load). El enfoque ELT significa que solo se aplican transformaciones y reglas de limpieza de datos mínimas o "justo lo necesario" al cargar la capa Plata. Todas las reglas de "nivel empresarial" se aplican en la capa Plata, en contraposición a las reglas de transformación específicas del proyecto, que se aplican en la capa Oro. Aquí se prioriza la velocidad y agilidad para ingerir y entregar los datos en el Lakehouse.
Desde la perspectiva del modelado de datos, la capa Plata tiene modelos de datos más similares a la 3ª Forma Normal. Las arquitecturas y modelos de datos de alto rendimiento para escritura, similares a Data Vault, se pueden utilizar en esta capa. Si se utiliza una metodología Data Vault, tanto el Data Vault sin procesar como el Business Vault encajarán en la capa Plata lógica del lake, y las vistas de presentación Point-In-Time (PIT) o las vistas materializadas se presentarán en la capa Oro.
Capa Oro — la Capa de Presentación
En la capa Oro, se pueden construir múltiples data marts o data warehouses según la metodología de modelado dimensional/Kimball. Como se discutió anteriormente, la capa Oro es para informes y utiliza modelos de datos más desnormalizados y optimizados para lectura con menos uniones en comparación con la capa Plata. A veces, las tablas en la capa Oro pueden estar completamente desnormalizadas, típicamente si los científicos de datos lo desean para alimentar sus algoritmos de ingeniería de características.
Las reglas de ETL y calidad de datos que son "específicas del proyecto" se aplican al transformar datos de la capa Silver a la capa Gold. Las capas de presentación final, como almacenes de datos, data marts o productos de datos como análisis de clientes, análisis de productos/calidad, análisis de inventario, segmentación de clientes, recomendaciones de productos, análisis de marketing/ventas, etc., se entregan en esta capa. Los modelos de datos basados en esquemas de estrella de estilo Kimball o los Data Marts de estilo Inmon encajan en esta Capa Gold del Lakehouse. Los laboratorios de ciencia de datos y los sandboxes departamentales para análisis de autoservicio también pertenecen a la Capa Gold.
El Paradigma de Organización de Datos del Lakehouse
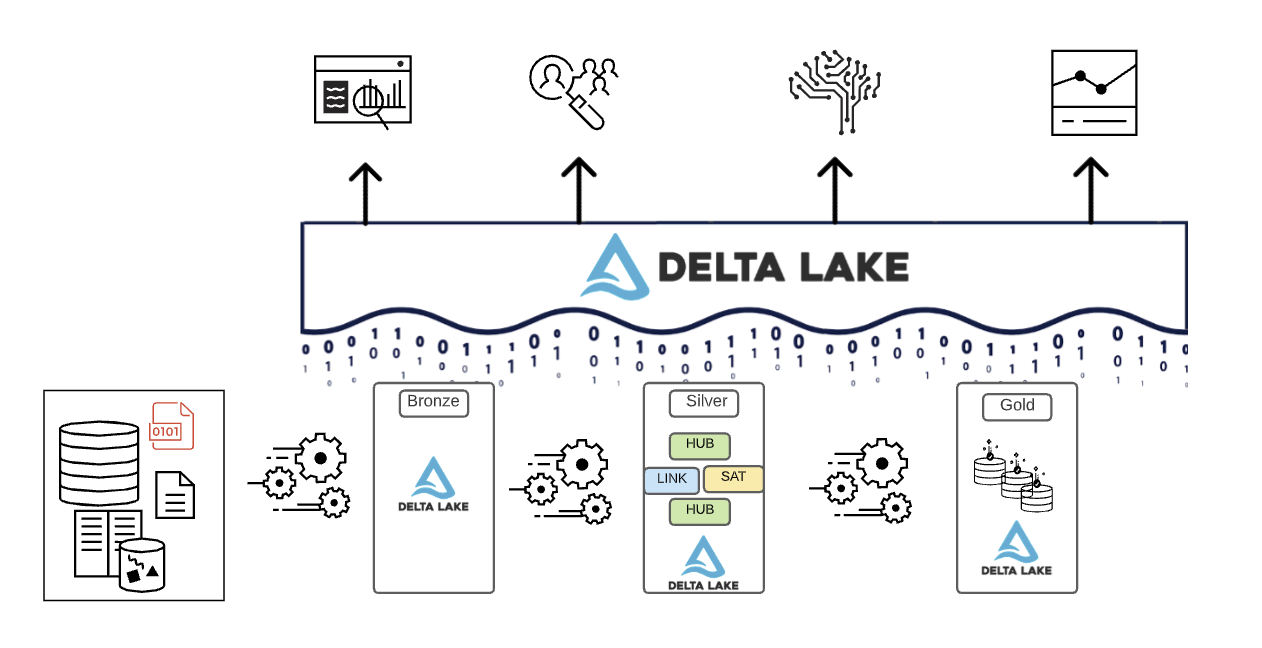
En resumen, los datos se curan a medida que se mueven a través de las diferentes capas de un Lakehouse.
- La capa Bronze utiliza los modelos de datos de los sistemas de origen. Si los datos se cargan en formatos brutos, se convierten al formato Delta Lake dentro de esta capa.
- La capa Silver reúne por primera vez los datos de diferentes fuentes y los conforma para crear una vista empresarial de los datos, utilizando típicamente modelos de datos más normalizados y optimizados para escritura que suelen ser similares a la 3ª Forma Normal o a Data Vault.
- La capa Gold es la capa de presentación con modelos de datos más desnormalizados o aplanados que la capa Silver, utilizando típicamente modelos dimensionales de estilo Kimball o esquemas de estrella. La capa Gold también alberga sandboxes departamentales y de ciencia de datos para permitir el análisis de autoservicio y la ciencia de datos en toda la empresa. Proporcionar estos sandboxes y sus propios clústeres de cómputo separados evita que los equipos de negocio creen sus propias copias de datos fuera del Lakehouse.
Este enfoque de organización de datos del Lakehouse está destinado a romper los silos de datos, unir a los equipos y empoderarlos para realizar ETL, streaming, BI e IA en una sola plataforma con la gobernanza adecuada. Los equipos de datos centrales deben ser los facilitadores de la innovación en la organización, acelerando la incorporación de nuevos usuarios de autoservicio, así como el desarrollo de muchos proyectos de datos en paralelo, en lugar de que el proceso de modelado de datos se convierta en un cuello de botella. El Unity Catalog de Databricks proporciona búsqueda y descubrimiento, gobernanza y linaje en el Lakehouse para garantizar una buena cadencia de gobernanza de datos.
Cree sus Data Vaults y almacenes de datos con esquemas de estrella con Databricks SQL hoy mismo.
Lectura adicional:
- Cinco pasos sencillos para implementar un esquema de estrella en Databricks con Delta Lake
- Mejores prácticas para implementar un modelo Data Vault en Databricks Lakehouse
- Mejores prácticas de modelado dimensional e implementación en un Lakehouse moderno
- ¡Las columnas de identidad para generar claves sustitutas ya están disponibles en un Lakehouse cerca de usted!
- Cargue un modelo dimensional EDW en tiempo real con Databricks Lakehouse
(Esta entrada del blog ha sido traducida utilizando herramientas basadas en inteligencia artificial) Publicación original
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.