Polares vs Pandas
Compare el procesamiento paralelo de alto rendimiento de Polars con la API versátil de Pandas para la manipulación de datos basada en DataFrame
- Comprenda las diferencias entre Polars y Pandas para las operaciones de DataFrame y los flujos de trabajo de análisis de datos.
- Aprenda cómo Polars utiliza el procesamiento paralelo basado en Rust y la evaluación diferida para un rendimiento superior en grandes conjuntos de datos.
- Descubra cuándo elegir el amplio ecosistema y la flexibilidad de Pandas frente a la velocidad y la eficiencia de memoria de Polars.
Introducción: comprender las opciones de bibliotecas de DataFrame
Los DataFrames son estructuras de datos bidimensionales, generalmente tablas, similares a hojas de cálculo, que permiten almacenar y manipular datos tabulares en filas de observaciones y columnas de variables, así como extraer información valiosa del conjunto de datos dado. Las bibliotecas DataFrame son conjuntos de herramientas de software que proporcionan una estructura similar a una hoja de cálculo para trabajar con datos en código. Las bibliotecas DataFrame son una parte esencial de una plataforma de análisis de datos porque proporcionan la abstracción central que hace que los datos sean fáciles de cargar, manipular, analizar y razonar, lo que permite establecer puentes entre el almacenamiento de datos sin procesar y las herramientas de análisis de nivel superior, aprendizaje automático y visualización.
Polars y pandas son las principales bibliotecas de DataFrame de Python para el análisis y la manipulación de datos, pero están optimizadas para diferentes casos de uso y escalas de trabajo.
Pandas es una biblioteca de código abierto escrita para el lenguaje de programación Python, que proporciona estructuras de datos y herramientas de análisis de datos rápidas y adaptables. Es la biblioteca de DataFrame más ampliamente utilizada en Python. Es una plataforma madura, con muchas funcionalidades y un amplio ecosistema con numerosas integraciones. Pandas cuenta con documentación extensa, apoyo de la comunidad y bibliotecas de visualización maduras. Es popular para conjuntos de datos pequeños a medianos y para el análisis exploratorio.
Polars es una biblioteca de DataFrame columnar, rápida y basada en Rust, con una API en Python. Está diseñada para ofrecer alto rendimiento, con paralelismo integrado y “ejecución diferida” (no se ejecuta de inmediato) para cargas de trabajo que superan la memoria disponible.
Dependiendo de sus requisitos de procesamiento de datos, pandas funciona bien para la ciencia de datos en conjuntos de datos de hasta unos pocos millones de filas. Si estás haciendo ETL, análisis o trabajando con tablas grandes, Polaris suele ser más eficiente.
Cuándo usar pandas en tu flujo de trabajo
Pandas destaca cuando la flexibilidad, la rapidez de iteración y la compatibilidad con el ecosistema son más importantes que la escala extrema. Es la biblioteca de DataFrame de facto. Prioriza la flexibilidad y ofrece integraciones profundas con Scikit-learn, NumPy, Matplotlib, statsmodels y muchas herramientas de aprendizaje automático.
Funciona bien con bases de código heredadas y resulta familiar para los equipos de procesamiento de datos que la utilizan para análisis interactivo y trabajo exploratorio, donde la flexibilidad es clave. Su formato orientado a filas se destaca en conjuntos de datos pequeños a medianos para análisis ad hoc, flujos de trabajo basados en notebooks y prototipado rápido.
Con pandas, puedes ejecutar cualquier función de Python, mientras que Polars desaconseja fuertemente la ejecución arbitraria de Python. Con pandas, los cambios in situ y la edición paso a paso son normales, lo que permite a los usuarios mutar el estado a lo largo del tiempo. Con Polars, los DataFrames son efectivamente inmutables.
Puedes ejecutar la API de pandas en Apache Spark 3.2. Esto te permite distribuir de manera uniforme las cargas de trabajo de pandas, lo que garantiza que todo se realice como corresponde.
Para el análisis exploratorio de datos, pandas proporciona operaciones rápidas e interactivas, segmentación/filtración/agrupación fácil e inspecciones visuales rápidas. A menudo, se usa para la validación/auditoría de datos y la limpieza de datos sin procesar en busca de valores faltantes, formatos inconsistentes, duplicados o tipos de datos mixtos.
Para la analítica y la generación de informes empresariales, cuando los equipos de datos necesitan generar métricas en una periodicidad definida, pandas facilita el uso de groupby y agregaciones, permite reestructurar datos con facilidad y genera salidas directamente a CSV o Excel.
Cuando los equipos de ciencia de datos preparan datos para modelos de ML, pandas facilita la experimentación mediante la creación de características naturales basadas en columnas y su estrecha integración con scikit-learn. Se utiliza a menudo para la creación rápida de prototipos y pruebas de concepto antes de escribir la lógica en SQL, Spark o en procesos de producción.
Incluso los equipos financieros y empresariales sin formación técnica utilizan pandas para automatizar los flujos de trabajo basados en Excel.
Más información:
Trabajar con DataFrames de pandas
Aprender análisis de datos con pandas
Cuándo usar Polars para tu flujo de trabajo
Polars se destaca cuando el rendimiento, la escalabilidad y la fiabilidad son más importantes que la flexibilidad ad hoc. Gracias a su motor en Rust, el multihilo, el modelo de memoria columnar y el motor de ejecución diferida, Polars puede manejar cargas de trabajo de ETL sorprendentemente grandes en una sola máquina, donde la eficiencia de la memoria es crítica. La ejecución diferida significa que las operaciones no se ejecutan de inmediato, sino que se registran, se optimizan y solo se ejecutan cuando se solicita explícitamente un resultado. Esto puede generar enormes mejoras de rendimiento, ya que se crea un único plan de ejecución optimizado en lugar de ejecutar cada operación paso a paso. Las transformaciones de datos se planifican primero y se ejecutan después, lo que permite al sistema optimizar todo el pipeline para lograr la máxima velocidad y eficiencia.
Para pipelines de datos de producción que requieren flujos de trabajo consistentes de alto rendimiento y críticos en velocidad, Polars es multihilo por defecto para aprovechar todos los núcleos de CPU disponibles y procesar cada fragmento del DataFrame en un hilo diferente. Esto lo hace mucho más rápido que las bibliotecas tradicionales de DataFrame de un solo subproceso, como pandas.
Al realizar uniones sobre decenas de millones de filas, como al combinar registros de navegación con metadatos de usuarios, las uniones de Polars son multihilo y el formato de datos columnar reduce las copias de memoria innecesarias.
En escenarios de uso con conjuntos de datos grandes, transformaciones complejas o pipelines de varios pasos, Polars se beneficia del procesamiento en paralelo, ya que cada fila puede procesarse de forma independiente, dividiendo las operaciones de uniones entre múltiples núcleos y realizando la partición hash en paralelo. En pipelines de consultas de varios pasos con muchas transformaciones, Polars puede optimizar y ejecutar todo el flujo de trabajo en paralelo. El uso de transmisión paralela y evaluación diferida permite a Polars procesar conjuntos de datos más grandes que la RAM. El procesamiento en paralelo y la evaluación diferida también facilitan las operaciones de escaneo de archivos grandes (CSV/Parquet).
Polars también obtiene importantes ventajas de rendimiento al utilizar el almacenamiento en columnas basado en Apache Arrow para la optimización de consultas. En el almacenamiento en columnas, los datos se almacenan columna por columna, no fila por fila. Esto permite que Polars lea solo las columnas requeridas, minimizando la E/S del disco y el acceso a la memoria, lo que lo hace más eficiente para el procesamiento analítico. Puede operar directamente en los búferes de memoria continua de Apache Arrow sin copiar datos.
Si estás realizando ingeniería de características de ML y exploración en conjuntos de datos extremadamente grandes, uniendo grandes tablas de hechos, realizando agregaciones pesadas y análisis OLAP, cargas de trabajo de series temporales, escaneo masivo de archivos, procesamiento más grande que la memoria y procesamiento por lotes con SLA ajustados, Polars podría ser la mejor opción.
- Enlace interno: Apache Spark (ancla: procesamiento de datos distribuido)
- Enlace interno: pipelines de datos (ancla: construcción de pipelines de datos escalables)
Representación y arquitectura de datos
Los modelos y las arquitecturas de representación de datos de pandas y Polars difieren por su propósito. El almacenamiento basado en filas utilizado por pandas almacena filas completas continuamente en la memoria, mientras que el almacenamiento en columnas que se encuentra en Polars almacena cada columna de forma contigua. Cada método puede afectar al rendimiento, dependiendo de los tipos de consultas que se ejecuten.
Para las consultas analíticas, el almacenamiento en columnas generalmente funciona mejor porque la consulta solo necesita acceder a las columnas necesarias, mientras que los almacenes de filas deben leer filas completas.
Las columnas tienen tipos uniformes que permiten mejores índices de compresión, y la vectorización permite un procesamiento por lotes rápido.
Para consultas transaccionales, como cargas de trabajo OLTP, se prefiere el almacenamiento basado en filas, ya que toda la fila se almacena junta, por lo que recuperar un registro completo requiere una sola lectura, y actualizar una fila solo modifica una región compacta de la memoria.
Los gráficos a continuación muestran las proporciones medias de rendimiento al comparar bibliotecas de DataFrame basadas en filas y columnas (en este caso, Koalas y Dask).
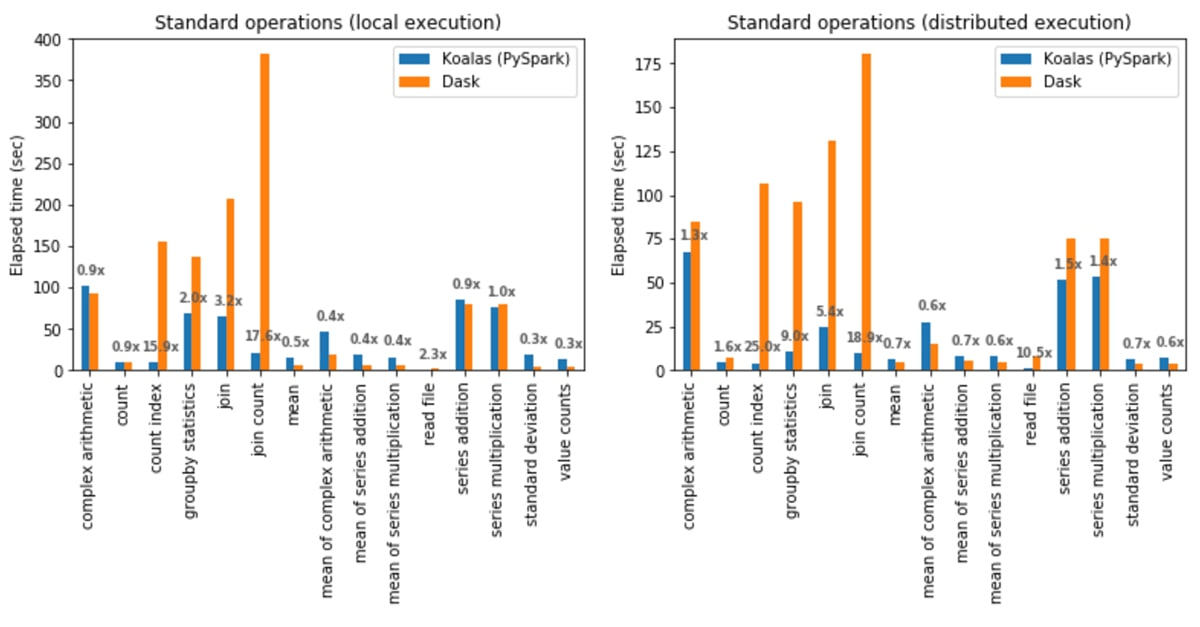
El formato columnar de Polars permite agregaciones más rápidas. Dado que cada columna se almacena de forma contigua en la memoria, puede transmitir a través de una sola columna sin escanear datos no relacionados y paraleliza las agregaciones entre los núcleos de CPU. Para conjuntos de datos grandes, el almacenamiento columnar reduce la presión sobre la RAM porque solo lee las columnas que requiere la consulta.
El diseño columnar en Polars permite la ejecución vectorizada utilizando Apache Arrow, lo que habilita el intercambio de datos sin copias. Polars puede realizar filtrado y corte sin copiar los búferes de datos subyacentes.
El modelo de almacenamiento basado en filas que utiliza pandas significa que cada fila de un DataFrame se almacena como una colección de objetos de Python agrupados. Este modelo está optimizado para operaciones que recuperan o modifican registros completos. Puede recuperar todos los datos de un registro en una sola búsqueda, lo que lo hace más adecuado para muchas operaciones pequeñas con cargas de trabajo mixtas que para vectores grandes. Admite tipos de datos heterogéneos, como objetos de Python, cadenas, números, listas y datos anidados. Dicha flexibilidad es útil para datos desordenados del mundo real, JSON dentro de registros CSV y conjuntos de características de tipo mixto.
Para consultas que requieren acceder a muchas o todas las columnas de una sola fila, como recuperar registros a nivel de usuario y serializar datos a nivel de fila para API, pandas no necesita reconstruir la fila accediendo a múltiples búferes de columna. También es más rápido para cargas de trabajo con mutaciones frecuentes, ya que permite la mutación in situ de las celdas de DataFrame.
Cuando los datos caben cómodamente en la memoria, pandas es muy conveniente y proporciona un rendimiento suficientemente rápido para conjuntos de datos pequeños a medianos.
Rendimiento: evaluación de la velocidad y el uso de recursos
Polars suele ser más rápido y eficiente en recursos que pandas, en especial, para trabajos de ingeniería de datos y a medida que crecen los datos y la complejidad. Polars es columnar, multihilo por defecto y puede ejecutar planes de consulta diferidos y optimizados. Pandas es en su mayoría monohilo para las operaciones sobre DataFrame y utiliza evaluación inmediata, en la que cada línea se ejecuta al instante y materializa DataFrames intermedios. Pandas puede ser más rápido con datos pequeños y en algunas operaciones vectorizadas simples, y es más flexible, pero esa flexibilidad puede implicar un mayor consumo de CPU y memoria.
El gráfico a continuación muestra cómo la cantidad de subprocesos puede afectar el rendimiento.
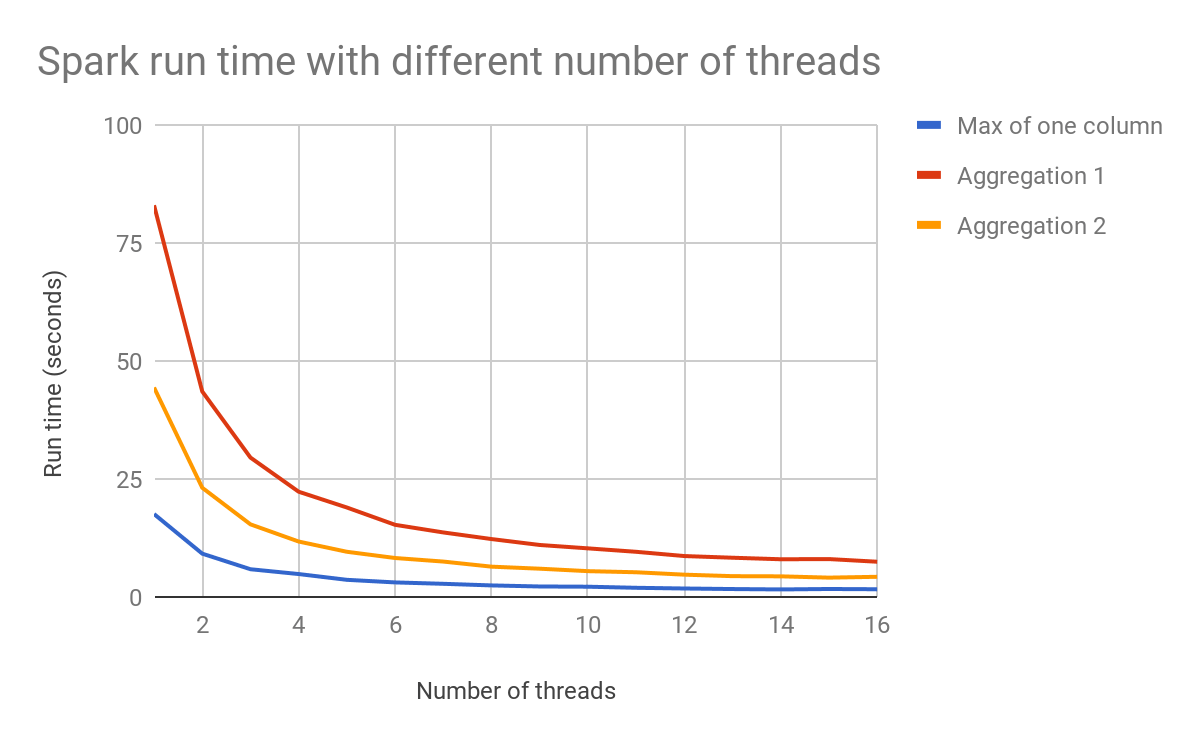
Con la planificación y el optimizador de consultas LazyFrame de Polars, tu código construye primero un plan de consulta, y Polars optimiza el plan y lo ejecuta cuando tú se lo indicas. Eso por sí solo representa la mayor parte de la ventaja de Polars en términos de velocidad y uso de memoria.
En pandas, la evaluación inmediata implica que los cálculos se realizan al instante, se crea un objeto intermedio en memoria y luego ese intermedio se pasa al siguiente paso, lo que provoca una pérdida de rendimiento por realizar múltiples pasadas sobre los datos (a menudo creando varios intermedios de tamaño completo). Dado que pandas no puede ver el pipeline completo, no puede optimizarlo de forma global. Pero pandas es potente cuando los datos caben cómodamente en la memoria, cuando las operaciones son pequeñas e interactivas, y cuando se desea obtener una respuesta inmediata después de cada línea. Como regla general, se debe elegir pandas cuando:
- estás haciendo un EDA rápido
- los conjuntos de datos son pequeños/medianos
- quieres una inspección y depuración paso a paso
- tu lógica es muy personalizada en Python (por filas)
Elige Polars cuando:
- estás haciendo procesos ETL/analítica repetibles
- los conjuntos de datos son grandes o amplios
- lees mucho Parquet/Arrow
- te preocupa la velocidad, la memoria y menos copias intermedias
Debido a sus diferencias filosóficas (pandas está diseñado para la flexibilidad y Polars para la velocidad), ambas bibliotecas manejan los datos faltantes y los valores nulos de manera distinta, lo que también puede afectar el rendimiento.
Pandas puede tratar varios valores diferentes como “faltantes”, lo que lo mantiene flexible, pero a veces inconsistente y puede ralentizar las operaciones debido al manejo de objetos de Python. Polars utiliza “null” como el único valor que falta en todos los tipos de datos para que coincida estrechamente con la semántica de SQL, que es más rápida y más eficiente en memoria a escala.
Como se ve en el gráfico de abajo, que muestra comparaciones de tiempo de ejecución para flujos de trabajo representativos, cuando pandas se ve obligado a realizar ejecuciones a nivel de Python (por fila) en grandes conjuntos de datos, se generan muchas copias intermedias y las operaciones se ralentizan.
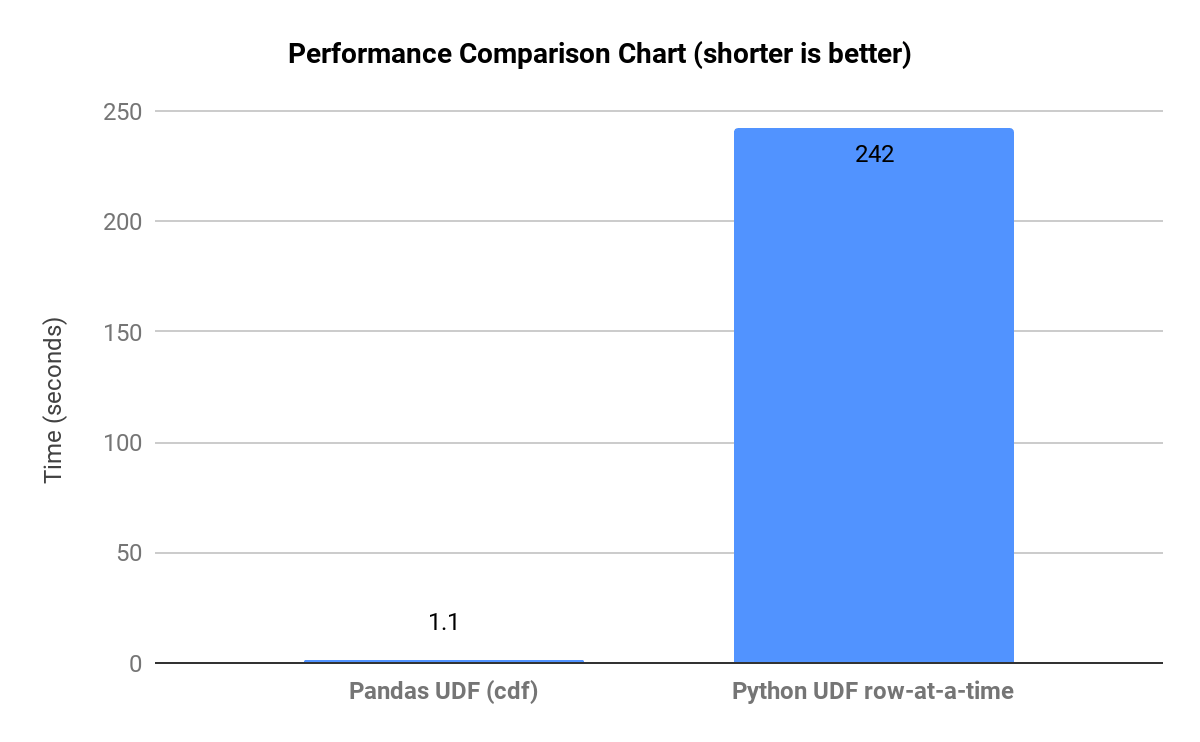
Polars también puede presentar cuellos de botella de rendimiento cuando se rompe la vectorización y se impide la optimización de consultas, o cuando no se utiliza el modo lazy en pipelines grandes. La optimización de Polars también puede verse afectada negativamente en uniones de muchos a muchos muy grandes.
El siguiente gráfico muestra que el consumo de memoria de pandas aumenta linealmente con el tamaño de los datos.
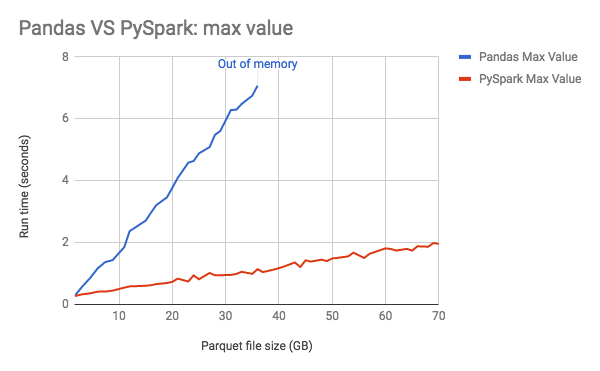
Guía de rendimiento:
- Si tu carga de trabajo consiste en agrupar, unir o escanear archivos Parquet de gran tamaño, Polars suele ser la mejor opción.
- Si tu flujo de trabajo es de EDA con mucha lógica personalizada en Python, pandas suele ser más conveniente.
Evaluación comparativa
Para entender las diferencias de rendimiento, a continuación se presentan algunos enfoques de evaluación que puedes implementar:
Rápido ad-hoc
- Usa
time.perf_counter()para medir el tiempo de reloj - Repite varias veces
- Informa la
mediana/p95.
Microevaluaciones repetibles (para un equipo/PR)
- Usa
pytest-benchmarkoasv - Ejecuta las pruebas en una máquina estable (o en un runner de CI fijado).
- Almacena resultados entre confirmaciones
Evaluación similar a la de producción (la más significativa)
- Forma y tamaño del conjunto de datos real
- Ejecuciones con caché fría vs. caché caliente
- Sincronización integral de pipelines
- Seguimiento de memoria y CPU
Para que las comparaciones sean justas, usa el mismo formato de entrada, iguala los tipos de datos, usa los mismos agrupamientos, claves y salidas, y controla el uso de hilos (comportamiento predeterminado o un solo núcleo para una comparación directa).
- Cuando las diferencias de rendimiento son las que más importan en casos de uso concretos
- Mejoras en tiempo promedio en el mundo real con Polars en grandes conjuntos de datos
Manejo de datos faltantes y tipos de datos
La forma en que una biblioteca de DataFrame maneja los datos faltantes y los tipos de datos afecta la corrección, la calidad de los datos, el rendimiento y la facilidad de uso. Pandas ofrece un manejo flexible, pero a veces inconsistente de los datos faltantes y los tipos de datos, mientras que Polars impone un único modelo de valores nulos con tipado fuerte, lo que se traduce en un comportamiento más seguro, rápido y predecible, especialmente a escala.
El modelo de datos faltantes de pandas trata varios valores, NaN (flotante), None, NaT (fecha y hora) y pd.NA (escalar anulable), como valores faltantes. Esto ayuda a la flexibilidad, pero puede ser inconsistente cuando diferentes tipos de datos gestionan los datos faltantes de forma distinta. Al llenar los valores faltantes, pandas puede cambiar el tipo de datos de forma inesperada. La semántica nula ambigua dificulta que pandas detecte problemas de calidad de datos.
Polars emplea un único valor faltante (nulo) y emplea el mismo comportamiento en todos los tipos de datos, y todos los tipos de datos son anulables por defecto. Esto generalmente produce un comportamiento previsible y un mejor rendimiento. Al completar con valores faltantes, Polars es explícito y preserva el tipo de datos. El manejo coherente de los valores nulos por parte de Polars suele dar lugar a menos errores en la calidad de los datos.
También hay que tener en cuenta cómo los diferentes modelos de memoria afectan a las conversiones de tipos de datos y a la interoperabilidad. Históricamente, pandas se basa en NumPy (objetos de Python similares a filas que pueden contener tipos de datos mixtos), mientras que Polars es columnar nativo de Arrow, lo que lo hace más sencillo a la hora de conectarlo al resto del stack de datos de Python.
Estas son algunas de las mejores prácticas para mantener la integridad de los datos mientras se utilizan ambas bibliotecas de DataFrame:
- Para ambas bibliotecas...
Aplica y valida la unicidad y las restricciones clave de bases de datos, como la unicidad de la clave primaria, la validez de las claves foráneas y los recuentos o particiones de filas esperados. Validar uniones para evitar explosiones de filas silenciosas. Utilice transformaciones consistentes y deterministas: son mucho más fáciles de probar y reproducir. Almacene datos de “fuente de verdad” en Parquet con un esquema estable para preservar los tipos. Y no esperes hasta el final para validar. Valida en puntos clave como después de la ingestión, después de transformaciones importantes y después de la publicación.
- Con pandas...
Establece los tipos de datos de forma explícita en el momento de la lectura siempre que sea posible y da preferencia a los tipos de datos nulos, como Int64, booleano, cadena o datetime64[ns], para que pandas no recurra al objeto. Normaliza los valores faltantes pronto y observa problemas silenciosos como NaN == Naan. Evita la indexación en cadena y en forma de flecha para la lógica central.
- Con Polars...
Define explícitamente los tipos de esquema y datos, y confía en la tipificación estricta de Polars. Usa null de manera coherente y prefiere el manejo de null basado en expresiones.
Transiciones de sintaxis y API
- Diferencias principales de la API: encadenamiento de Polars vs. operaciones de pandas
- Con Polars, normalmente se crea un único canal encadenado basado en expresiones y, en modo diferido, Polars puede optimizar toda la cadena. En pandas, a menudo se escribe una secuencia de instrucciones que mutan en el método eager (paso a paso).
- Ejemplos de código en paralelo: filtrado, agrupación y agregaciones
- Filtrado y selección (encadenamiento)
- pandas
- Filtrado y selección (encadenamiento)
resultado = pdf[pdf["country"] == "US"][["user_id", "revenue"]]
- Polars
resultado = (
pldf
.filter(pl.col("country") == "EE. UU.")
.select(["user_id", "revenue"])
)
- Agrupación y agregación:
- pandas
rev_by_user = (
pdf
.groupby("user_id", as_index=False)["revenue"]
.sum()
)
- Polars
rev_by_user = (
pldf
.group_by("user_id")
.agg(pl.col("revenue").sum())
)
Fundamentos de la sintaxis polar:
Hay dos conceptos que son más importantes al aprender Polars: las expresiones y la ejecución diferida frente a la ejecución inmediata. Polars se basa en expresiones, un cálculo por columnas (similar a SQL) que describe lo que deseas calcular y un motor que decide cómo calcularlo de manera eficiente. Las expresiones no se ejecutan de inmediato. Son bloques de construcción en el modo de operación “diferido”, donde las operaciones construyen un plan de consulta y las ejecuciones ocurren solo cuando llamas.
Por el contrario, en el modo eager (comportamiento de pandas), las operaciones se ejecutan inmediatamente, lo que lo hace bueno para la exploración y la depuración, pero se ralentiza para los pipelines a gran escala. Polars puede ofrecer una ejecución rápida para la interactividad y una ejecución lenta para optimizar los procesos a gran escala.
Convertir el código Pandas existente a Polars
La conversión suele significar:
- reemplazar la indexación
df[...]row/col por.filter()/.select() - reemplazar la asignación en el lugar con
.with_columns() - reemplazar
.apply()por expresiones nativas (siempre que sea posible) - considerar el modo diferido para ETL respaldado por archivos
Ejemplo de conversión:
Pandas originales:
df = pd.read_parquet("events.parquet")
df = df[df["country"] == "US"][["user_id", "revenue", "ts"]]
df["revenue"] = df["revenue"].fillna(0)
df["day"] = pd.to_datetime(df["ts"]).dt.date
)
out = (
df.groupby(["user_id", "día"], as_index=False)
.agg(total_revenue=("revenue", "sum"))
Polars optimizado en modo diferido:
importar polars como pl
out = (
pl.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id", "revenue", "ts"])
.with_columns([
pl.col("revenue").fill_null(0),
pl.col("ts").dt.date().alias("día"),
])
.group_by(["user_id", "day"])
.agg(pl.col("revenue").sum().alias("total_revenue"))
.collect()
)
Cuando un equipo cambia de bibliotecas de datos (por ejemplo, de pandas a Polars, o agregando Polars junto a pandas), la curva de aprendizaje tiene menos que ver con la sintaxis y más con la mentalidad, los flujos de trabajo y la gestión de riesgos. La mentalidad de pandas es imprescindible: paso a paso, muta sobre la marcha e inspecciona después de cada línea. La mentalidad de Polar es declarativa, basada en expresiones, donde construye transformaciones como pipelines con datos inmutables y emplea una planificación de consultas similar a SQL.
El desafío de aprendizaje es empezar a pensar columna por columna y de forma declarativa en lugar de fila por fila. Los hábitos de depuración e inspección deben cambiar: hay que pensar en transformaciones, no en estados.
Con Polars, la estricta naturaleza de los tipos de datos puede parecer hostil cuando se fuerza la consistencia del esquema y falla rápidamente en problemas de tipo de datos, pero esas fallas previenen errores silenciosos de calidad de datos. El desafío consiste en tratar los errores de tipo de datos como señales de calidad de los datos, no como molestias.
Los equipos también pueden notar carencias de herramientas al cambiar a Polars, ya que casi todas las herramientas de datos en Python aceptan pandas y existe un vasto ecosistema de pandas con documentación. Considera un enfoque híbrido cuando se necesitan herramientas heredadas, concéntrate en Polars para la preparación de datos pesados y en pandas para modelado y trazado.
Existen capas de compatibilidad de API para reutilizar código de DataFrame similar a pandas sobre Polars. Estos adaptadores admiten los mismos nombres y firmas de métodos que pandas, con comportamientos similares, y pueden traducir las llamadas a las operaciones nativas de Polars. Pero ten cuidado, una capa API no es conversión, y puede introducir lagunas semánticas y ocultar trampas de rendimiento.
A continuación, se presentan algunos patrones de refactorización y estrategias de migración comunes al pasar de un stack de DataFrame a otro.
Patrones comunes de refactorización (pandas a Polaris):
Reemplazar la indexación booleana por .filter() y .select()
- pandas
df2 = df[df["x"] > 0][["id", "x"]]
- Polars
df2 = df.filter(pl.col("x") > 0).select(["id", "x"])
Reemplazar la mutación in situ por .with_columns()
- pandas
df["y"] = df["x"] * 2
- Polars
df = df.with_columns((pl.col("x") * 2).alias("y"))
Reemplazar np.where/asignación condicional por cuando/entonces/de lo contrario
- pandas
df["tier"] = np.where(df["revenue"] >= 100, "high", "low")
- Polars
df = df.with_columns(
pl.when(pl.col("revenue") >= 100).then("high").otherwise("low").alias("tier")
)
- Reescribir las agregaciones groupby en .agg(...) basadas en expresiones
- pandas
out = df.groupby("k", as_index=False).agg(total=("v","sum"), usuarios=("id","nunique"))
- Polars
out = df.group_by("k").agg(
pl.col("v").sum().alias("total"),
pl.col("id").n_unique().alias("users"),
)
Se deben preferir los escaneos diferidos para ETL respaldado por archivos
- pandas
df = pd.read_parquet("events.parquet")
- Polars
out = (
.scan_parquet("events.parquet")
.filter(pl.col("country") == "EE. UU.")
.select(["user_id","revenue"])
.group_by("user_id")
.agg(pl.col("revenue").sum().alias("rev"))
.collect()
)
Reemplazar .apply() por expresiones nativas (o las UDF aisladas)
- pandas
La mayoría de las migraciones de pandas se detienen en .apply (axis=1)
- Polars
Intenta expresarlo con expresiones de Polars (str.*, dt.*, list.*, when/then).
Si es inevitable, aísla una UDF en una columna o subconjunto pequeño y especifica return_dtype.
- Enlace interno: programación en Python (ancla: Python para el análisis de datos)
La guía de IA agéntica para la empresa

Integración y compatibilidad con el ecosistema
Polars y pandas están diseñadas para funcionar juntas, pero se basan en modelos de ejecución y tipo diferentes. La interoperabilidad existe a través de puntos de conversión explícitos, no de componentes internos compartidos. Dado que ambas bibliotecas pueden trabajar con Apache Arrow, Arrow puede ser una capa clave de interoperabilidad, ya que permite una transferencia columnar eficiente y una preservación más limpia de los esquemas.
- Utiliza tablas Parquet o Arrow como formato de intercambio
- Evita CSV para flujos de trabajo entre bibliotecas
La interoperabilidad es explícita e intencionada. No hay motor de ejecución compartido ni semántica de índice. Tampoco hay garantía de copia cero. Valida siempre.
Conversión de datos entre formatos: to_pandas() e importación de polars:
- pandas a Polars
- las columnas de pandas se convierten en tipos de Polars compatibles con Arrow
- El índice de pandas se elimina a menos que lo restablezcas.
- Las columnas de objetos se inspeccionan y se convierten (a menudo a Utf8 o error).
- MEJORES PRÁCTICAS
- Llamar a
pd_df.reset_index()si el índice importa - Normalizar primero los dtypes:
- usar cadena, Int64, booleano
- evitar columnas de objetos de tipo mixto
- Llamar a
- Polars a pandas
- Las columnas de Polars se convierten en pandas (a menudo con respaldo de flecha si están disponibles).
- Se crea un RangeIndex predeterminado
- Los valores nulos se asignan a representaciones faltantes de pandas.
- MEJORES PRÁCTICAS
- Convertir una vez en el límite, no repetidamente.
- Validar los tipos de datos después de la conversión (especialmente enteros con valores nulos).
- Regla general: convierte en los límites del flujo de trabajo, no dentro de bucles ni en rutas críticas.
Al integrar con bibliotecas de visualización y herramientas de trazado, la mayoría de las bibliotecas de trazado de Python esperan a pandas (o matrices de NumPy). Polars se integra bien, pero a menudo tendrás que convertir a pandas en el límite del trazado, o pasar matrices/columnas directamente.
Para la conectividad de base de datos y el soporte de formatos de archivo, pandas es la mejor opción para lecturas ad hoc y compatibilidad con el ecosistema. Polars es mejor para archivos grandes, Parquet y análisis centrados en archivos. Pandas es compatible con PostgreSQL, MySQL, SQL Server, Oracle, SQLite y cualquier base de datos con un controlador SQLAlchemy. Polars no es un cliente de base de datos completo. Se espera que los datos lleguen como archivos o tablas Arrow. Algunas bases de datos y herramientas pueden generar Arrow directamente, que Polars puede incorporar de manera eficiente.
Ambas admiten el análisis de archivos CSV. Polars es muy rápido con menor sobrecarga de memoria, mientras que pandas tiene un análisis muy flexible y maneja bien los CSV desordenados, pero el análisis tiende a ser pesado en la CPU y el uso de memoria puede aumentar.
Polars es superior para Parquet. Pandas puede leer Parquet, pero las operaciones solo son eficaces con un pushdown limitado en comparación con Polars. Con la ejecución en transmisión y un motor columnar nativo de Arrow, Polars puede producir resultados con aceleraciones de órdenes de magnitud en grandes conjuntos de datos.
La integración y compatibilidad de bibliotecas de aprendizaje automático (ML) es uno de los factores prácticos más importantes a la hora de elegir entre pandas y Polars o ejecutar ambas. La mayoría de las bibliotecas de ML esperan arreglos NumPy (X: np.ndarray, y: np.ndarray), pandas DataFrames/Series (comunes en flujos de trabajo de sklearn) o Arrow. Muchas bibliotecas tratan pandas como el contenedor tabular predeterminado. Por lo tanto, si tu stack de ML se compone principalmente de sklearn y el ecosistema relacionado, pandas sigue siendo la opción más sencilla.
La mayoría de las bibliotecas de ML aún no aceptan los DataFrames de Polars directamente como entradas de primera clase. Polars es excelente para la ingeniería de características, pero conviene planificar la conversión en el punto de frontera del flujo. Se recomienda realizar una preparación intensiva de datos en Polars y convertirlos a pandas o NumPy para el entrenamiento y la inferencia del modelo.
A continuación, se muestra una lista de verificación rápida para introducir datos en ML:
- Sin columnas de tipo mixto
- Todas las características numéricas o codificadas
- Valores nulos gestionados (modelo imputado/descartado/consciente de la ausencia)
- Orden de características estable
- Nombres de características preservados (si es necesario)
- Validación del esquema de entrenamiento/inferencia en marcha
Consideraciones de producción
Cuando se trasladan cargas de trabajo de pandas o Polars de los documentos a producción, los “inconvenientes” suelen tener menos que ver con la sintaxis y más con el tiempo de ejecución, el empaquetado, la previsibilidad del rendimiento y la operatividad. Valida el comportamiento bajo los límites reales de memoria/CPU de tu destino de implementación. Elige estrategias como recorte de columnas, filtrado temprano y escaneos en transmisión o diferidos para cargas de trabajo basadas en archivos.
Para el tiempo de ejecución y el empaquetado, asegúrate de que tu versión de producción en Python coincida con lo que pruebas localmente. Polar emplea código nativo (Rust) y pandas depende de NumPy o de motores opcionales como PyArrow y Fastparquet. Parquet/Arrow suele ser el mejor para la producción, ya que ofrece una mejor estabilidad del esquema, lecturas más rápidas y menos sorpresas de tipo de datos que CSV.
Polars emplea subprocesos múltiples de forma predeterminada. Considera la posibilidad de configurar/controlar el uso de subprocesos mediante la configuración del entorno en producción. La optimización diferida de Polars puede mejorar el rendimiento, pero los trabajos muy pequeños podrían experimentar sobrecarga por la planificación.
Los procesos de producción deben aplicar explícitamente los tipos de datos y las expectativas de nulidad (ambas bibliotecas requieren que se apliquen restricciones). Agrega comprobaciones alrededor de las uniones para evitar explosiones silenciosas en filas.
Para la observabilidad, realiza un seguimiento del tiempo de ejecución, el número de filas, el número de valores nulos de las columnas clave y el tamaño de la salida por ejecución. Agrega controles de “detención de línea” en los límites (antes de publicar los resultados). Y asegúrate de que los errores aparezcan con un contexto procesable (qué partición/archivo/tabla, qué verificación falló).
Valida las salidas (recuentos de filas, agregados, tasas nulas) y presupuestos de rendimiento (umbrales de tiempo/memoria). Ejecuta pruebas en contenedores que coincidan con el sistema operativo/glibc de producción para evitar sorpresas con las ruedas nativas.
Estrategias prácticas de migración
Estrategias de migración para mover un equipo de pandas a Polars o adoptar Polars junto con pandas:
- Patrón estrangulador: cuando necesites bajo riesgo y entrega continua, reemplaza un segmento a la vez con Polars mientras mantienes en funcionamiento el pandas antiguo. Convierte en los límites.
- Usa ambas: cuando tu cuello de botella esté en ETL/agregaciones, pero dependa de herramientas nativas de pandas más adelante, usa Polars para E/S, uniones, groupbys y cálculo de características; luego convierte el resultado final a pandas para scikit-learn, visualizaciones y bibliotecas estadísticas.
- Reescritura completa de un pipeline único: cuando busques un caso de éxito claro y patrones reutilizables, elige un flujo de principio a fin y reescríbelo totalmente en Polars para que sirva como implementación de referencia interna.
- Paridad de doble ejecución: cuando la precisión sea fundamental, ejecuta las versiones de pandas y Polars en paralelo durante un tiempo, compara los resultados, las métricas y los costos, y cambia una vez que se haya demostrado la paridad.
Perfilado de rendimiento: para identificar oportunidades de optimización, comienza a realizar un seguimiento del tiempo de espera (el tiempo que espera un usuario), la memoria máxima, los recuentos de filas, los recuentos de columnas y la corrección de la salida. La mayoría de los pipelines se congestionan en uno de los siguientes: E/S, unión, agrupación, ordenación, análisis de cadenas o UDF de Python. Añade temporizadores simples alrededor de esas etapas. Emplea los perfiladores de pandas (Python) cuando sospeches que hay trabajo a nivel de Python y los perfiladores de Polars para inspeccionar un plan de consulta perezosa. Realiza un cambio específico y vuelve a ejecutar la misma prueba de rendimiento para comparar.
Consideraciones sobre la capacitación del equipo y la transferencia de conocimientos
Tu objetivo es tener éxito sin estancar la entrega o perder la confianza en los datos. Asegúrate de que el equipo comprenda las motivaciones y pueda relacionarlas con resultados reales, es decir, qué problema(s) estamos resolviendo, qué cargas de trabajo se benefician más y qué aspectos no van a cambiar. Designa a los responsables (líder de la migración, revisores, responsables de la toma de decisiones) para garantizar la rendición de cuentas.
Usa los pipelines reales de la empresa para obtener ejemplos de relevancia y aceptación. Dado que Polars se parece más a SQL, pero con sintaxis Python, los cambios más importantes son cambios conceptuales de mentalidad:
- Imperativo a declarativo
- De fila en fila a columna en columna
- Pipelines de estado mutable a inmutable
- Ejecución inmediata a planificación y ejecución diferida
Organiza la capacitación en etapas para que los equipos se sientan productivos desde el principio. Tal vez convenga empezar con filtrado, selección y agrupación antes de avanzar a las expresiones, el manejo de valores nulos y las diferencias de tipos de datos. A continuación, aborda la ejecución diferida y la optimización antes de los patrones de migración y producción. Establece una fase híbrida con orientación clara sobre para qué se permite usar pandas, con el fin de reducir la incertidumbre. Para una transferencia de conocimiento más rápida, empareja a usuarios experimentados de Polars con usuarios que usan mucho pandas.
Valida públicamente la veracidad para generar confianza, medir y compartir los logros.
PREGUNTAS FRECUENTES
- ¿Es mejor pandas que Polars? Ninguna es universalmente mejor; la elección depende de los requisitos específicos del flujo de trabajo, el tamaño del conjunto de datos y las necesidades de rendimiento.
- ¿Qué es mejor, Polars o pandas? Pandas se destaca por su análisis interactivo y su integración en el ecosistema; Polars ofrece un mejor rendimiento en procesos de producción a gran escala.
- ¿Es Polars un sustituto de pandas? Polars complementa a pandas en lugar de sustituirla; ambas sirven eficazmente para diferentes casos de uso.
- ¿Vale la pena cambiar a Polars? Depende de si estás procesando grandes conjuntos de datos, en cuyo caso el modo lento y la optimización de consultas de Polars ofrecen ventajas cuantificables.
Conclusión
A la hora de decidir qué biblioteca de DataFrame tiene sentido para tus equipos, no hay una respuesta general. Por lo general, pandas es más adecuado para conjuntos de datos pequeños a medianos y análisis exploratorio, mientras que Polars, con su ejecución diferida, se adapta mejor a alto rendimiento en cargas de trabajo grandes (incluso mayores que la memoria disponible). Dependiendo de tus casos de uso, es posible que termines usando ambas, por lo que conviene probar pequeñas porciones de flujos de trabajo específicos con ambas bibliotecas y evaluarlas según sus tareas reales de procesamiento de datos.
Tus equipos deben entender las fortalezas y debilidades del almacenamiento columnar frente al almacenamiento basado en filas y sus participaciones para diferentes patrones de consulta. Las diferencias principales de API, sintaxis, formato de datos y conexión de base de datos requerirán una curva de aprendizaje al cambiar entre bibliotecas de DataFrame.
Recursos para seguir aprendiendo y experimentando:
Diseñar pipelines de datos escalables
Procesamiento distribuido de datos
Recibe las últimas publicaciones en tu bandeja de entrada
Suscríbete a nuestro blog y recibe las últimas publicaciones directamente en tu bandeja de entrada.