Enfócate en las cargas de trabajo de datos, no en la infraestructura
Spark totalmente administrado y sin versiones para todas sus cargas de trabajo de datos y de IA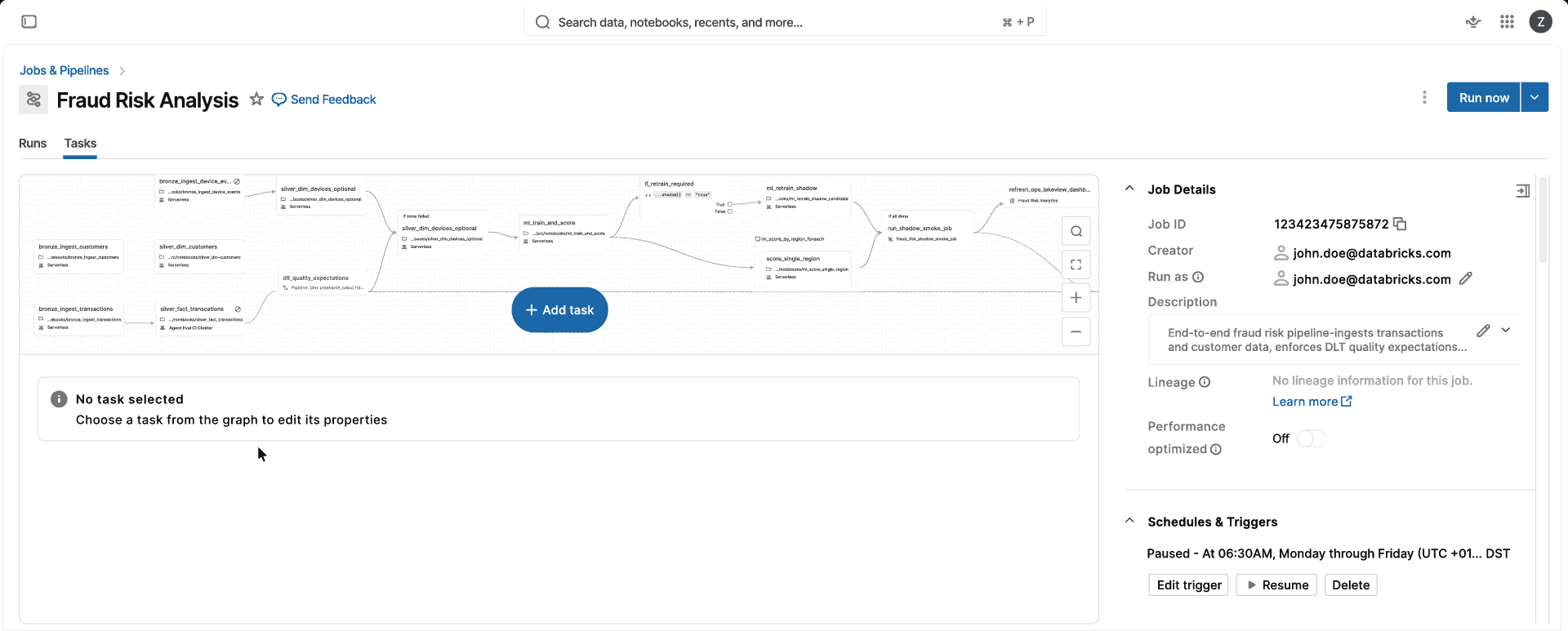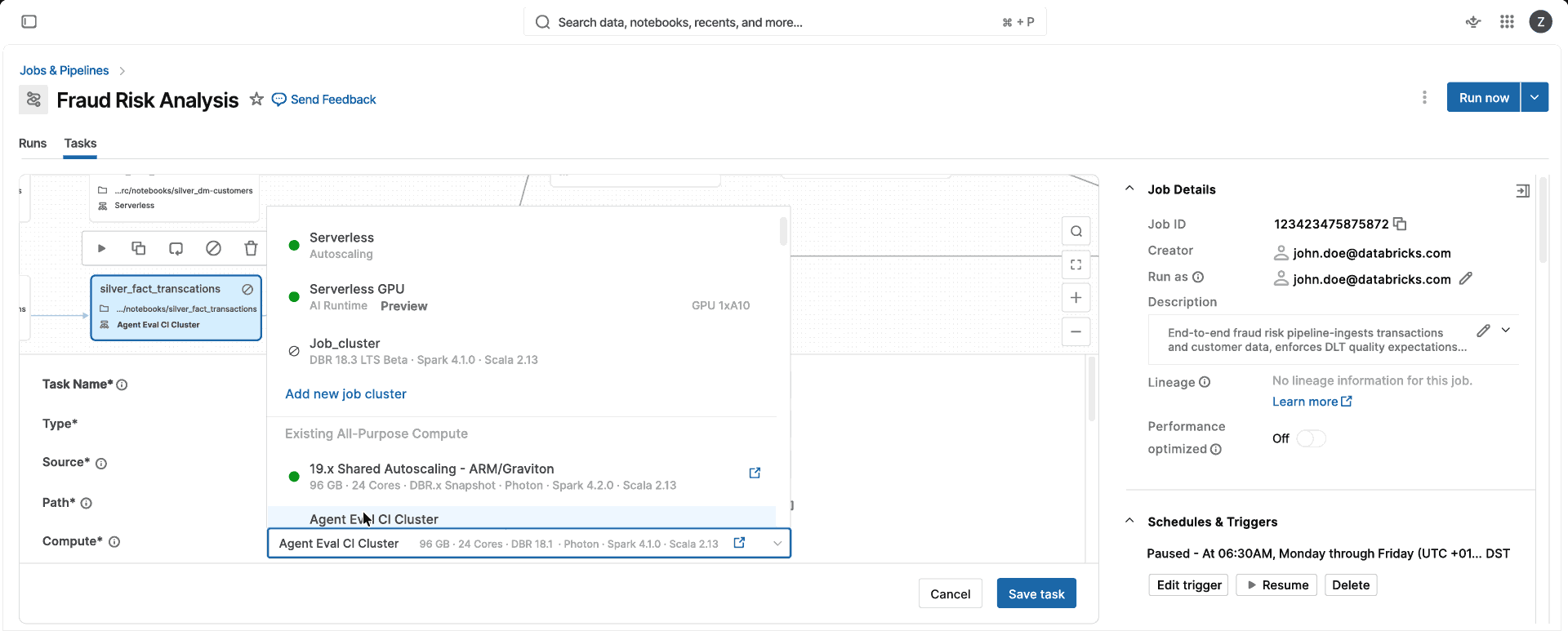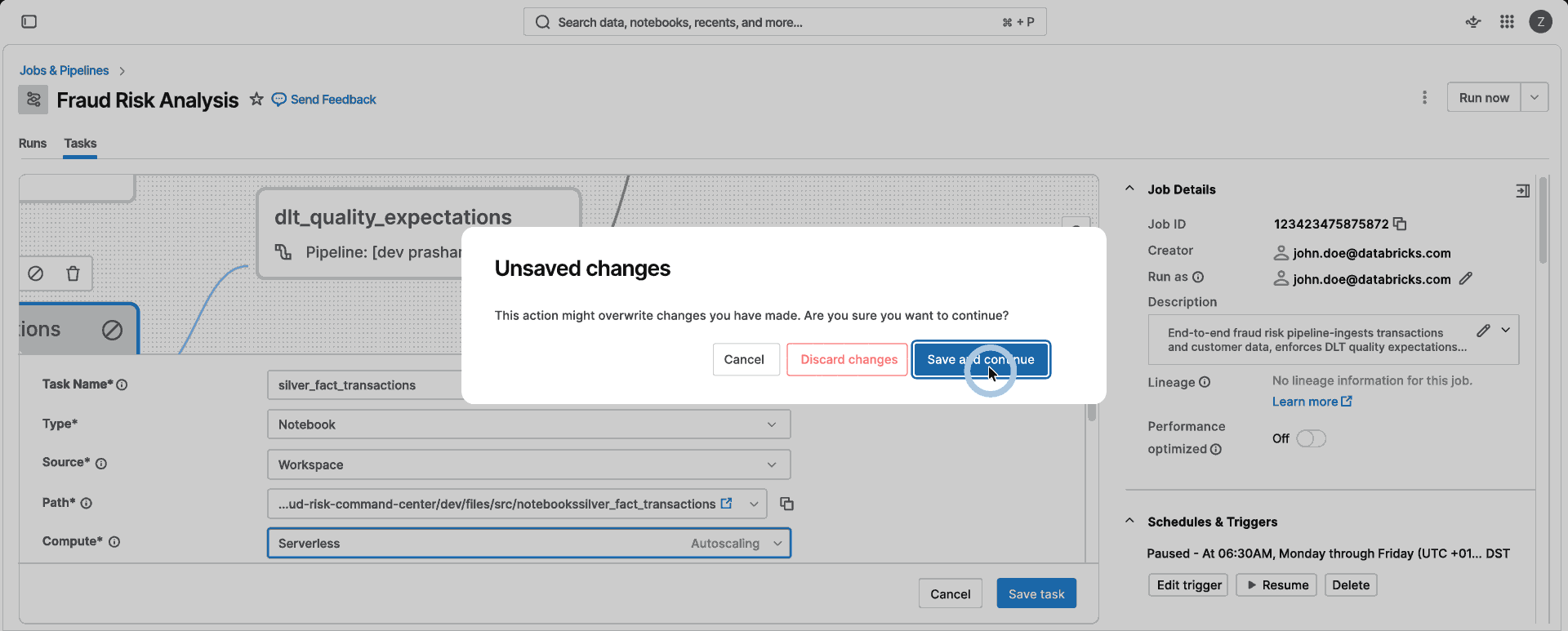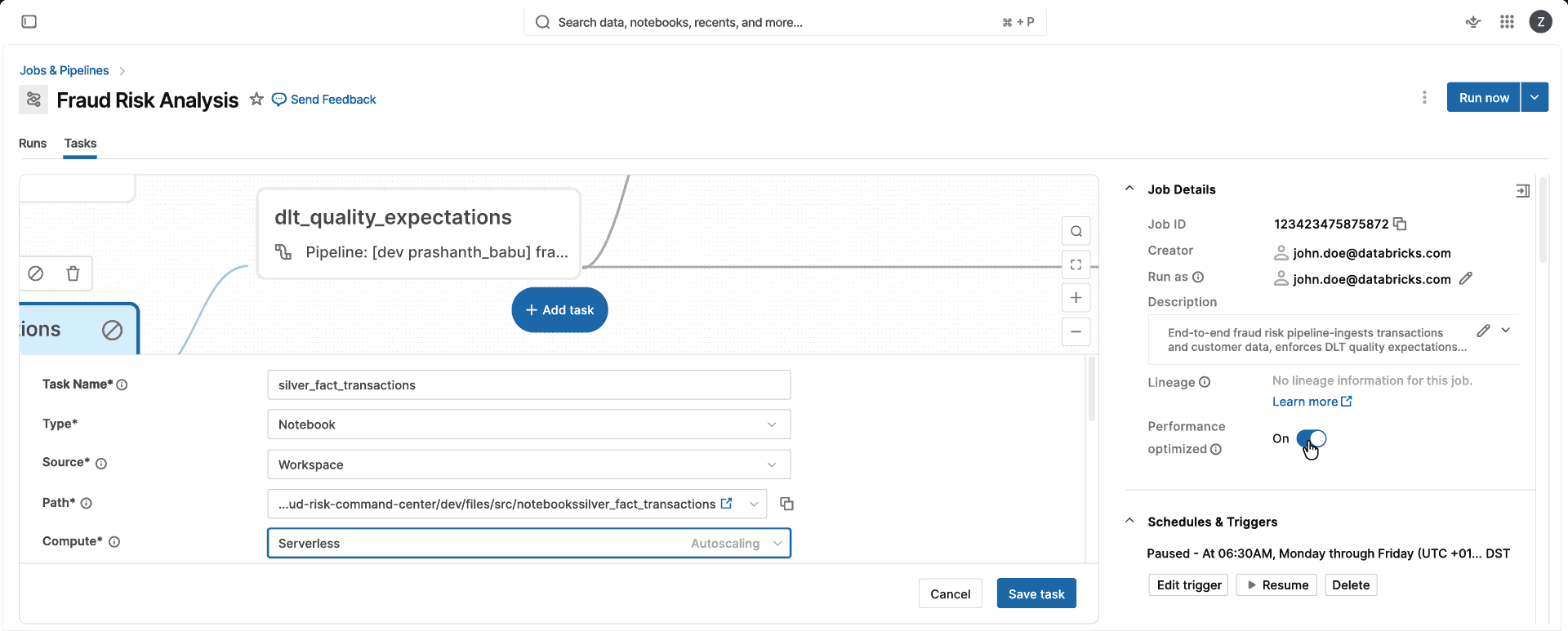
LAS PRINCIPALES EMPRESAS UTILIZAN EL CÓMPUTO SIN SERVIDOR
Elige tu objetivo de negocio, no la infraestructura
Ejecute cargas de trabajo de datos e IA en una infraestructura de cómputo que se escala, actualiza y optimiza automáticamente sin gestión de infraestructura.Totalmente administrada
Un cómputo. Sin decisiones sobre optimización para CPU, memoria o clase de instancia, ni configuración de clúster que administrar. Elija el modo Estándar o el modo Optimizado para el rendimiento, y Databricks selecciona automáticamente la instancia y los tipos de computación adecuados (una sola VM o un clúster de Spark) para usted, de modo que su equipo pueda enviar productos de datos en lugar de administrar la computación.
De alto rendimiento
Serverless se inicia en segundos, no en minutos, carga los entornos desde la caché y ajusta su tamaño automáticamente según la demanda de la carga de trabajo. El modo Estándar ofrece un procesamiento por lotes rentable, mientras que el modo Optimizado para el rendimiento generalmente ejecuta trabajos sensibles a la latencia 2 veces más rápido que los clústeres clásicos.
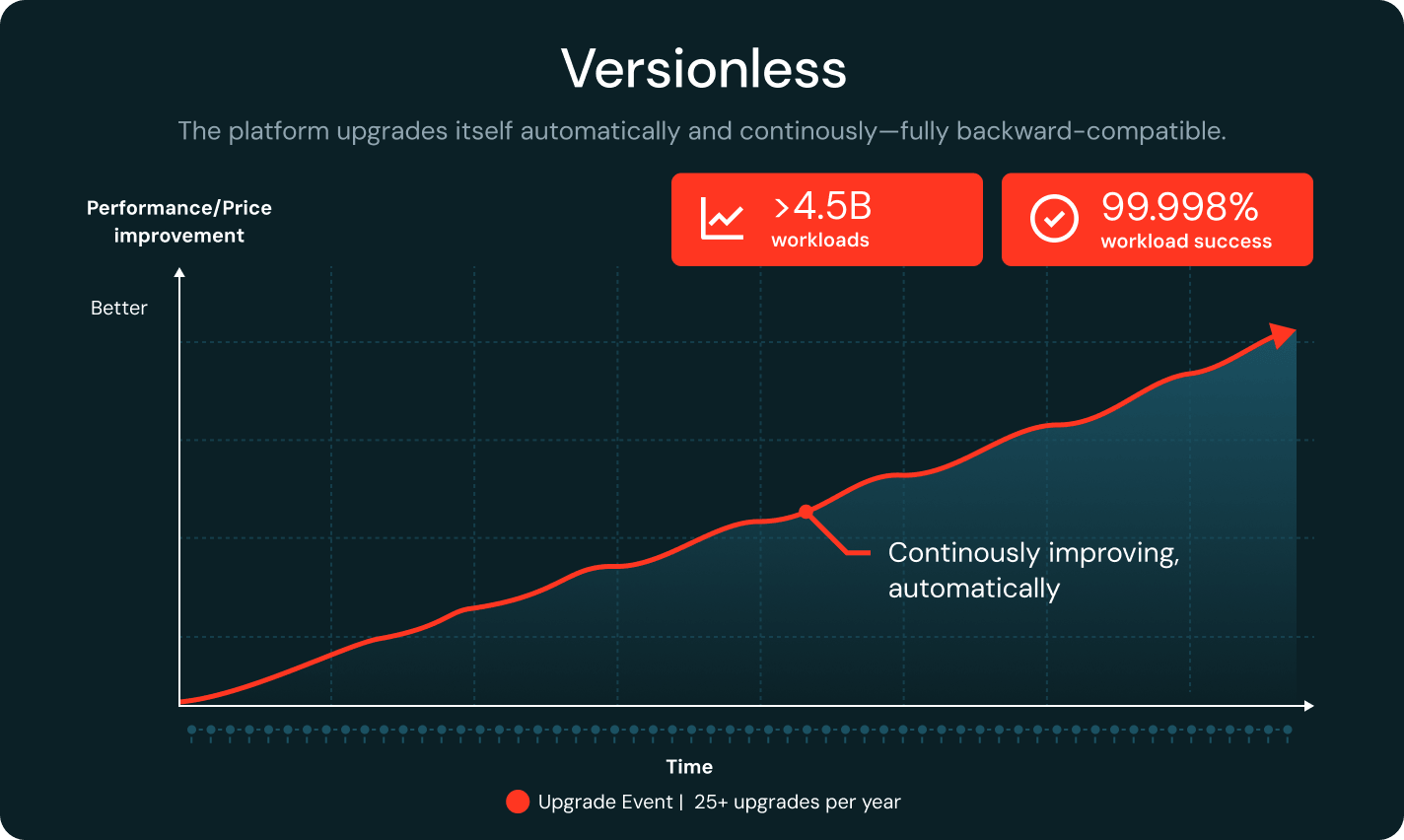
Sin versiones
Databricks actualiza continuamente el runtime y mantiene la retrocompatibilidad total. La detección de regresión fija las cargas de trabajo a versiones estables automáticamente. Con más de 25 actualizaciones por año y un 99.998% de éxito en la carga de trabajo, los equipos ahorran hasta un 20% del tiempo de ingeniería.
Cómputo que simplemente funciona
Deja de administrar la infraestructura y comienza a ejecutar tus cargas de trabajo de datos e IA en un cómputo totalmente administrado, con ajuste de escala automático y sin versiones.Serverless se actualiza de manera continua y automática sin dejar de ser totalmente retrocompatible, lo que mantiene las cargas de trabajo en ejecución sin intervención.
Elige el modo Estándar para cargas de trabajo por lotes con optimización de costos o el modo de rendimiento optimizado para trabajos sensibles a la latencia, que suele ejecutar los trabajos 2 veces más rápido que los clústeres clásicos.
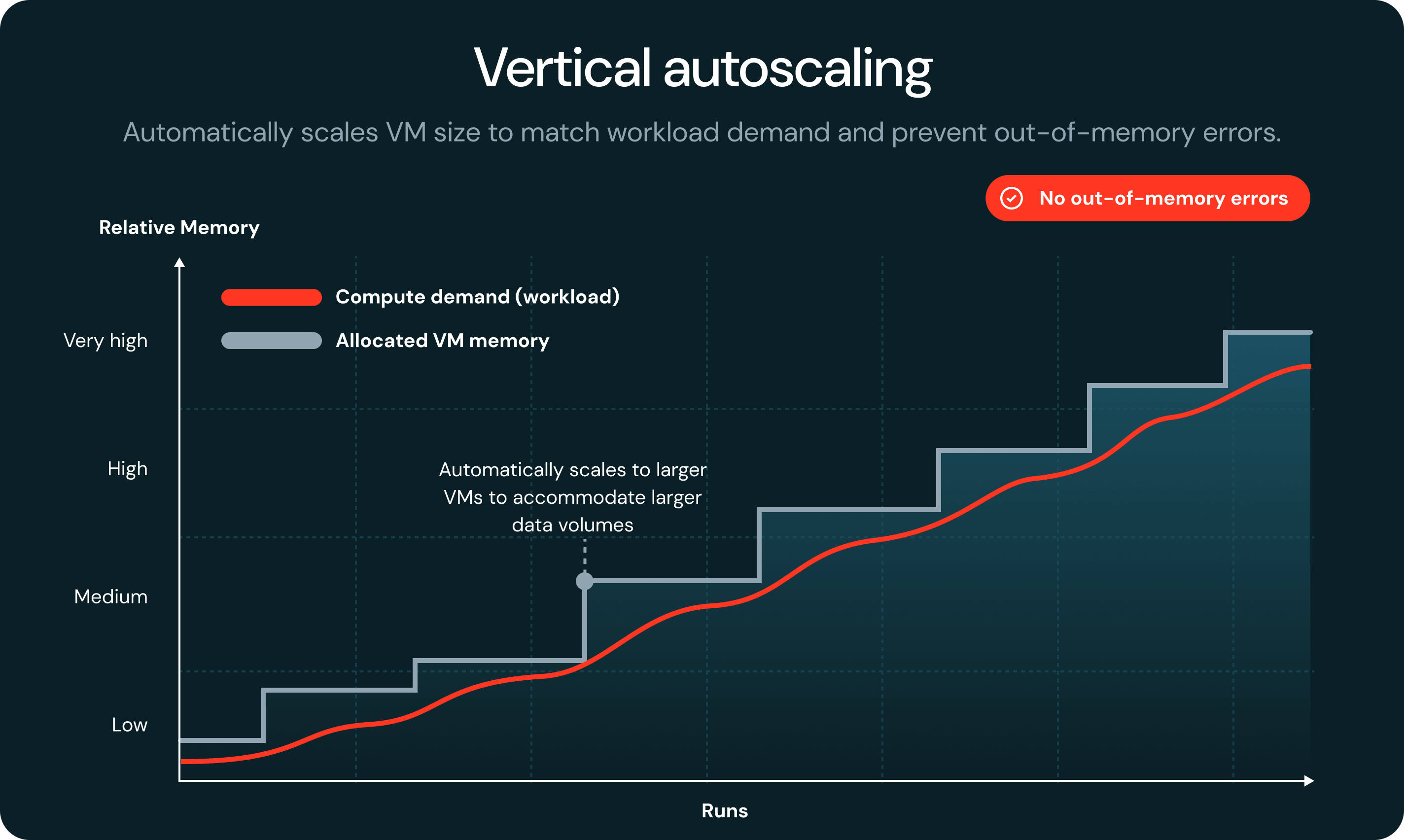
Cuando una tarea se queda sin memoria, la tecnología serverless detecta la falla automáticamente y la reinicia en una VM más grande, sin que se produzcan fallas en el trabajo ni se requiera intervención manual.
Los entornos de librerías se almacenan en caché globalmente, por lo que una vez que un usuario de tu organización ejecuta un proceso con un conjunto específico de paquetes, el entorno está listo en segundos para todos los demás.
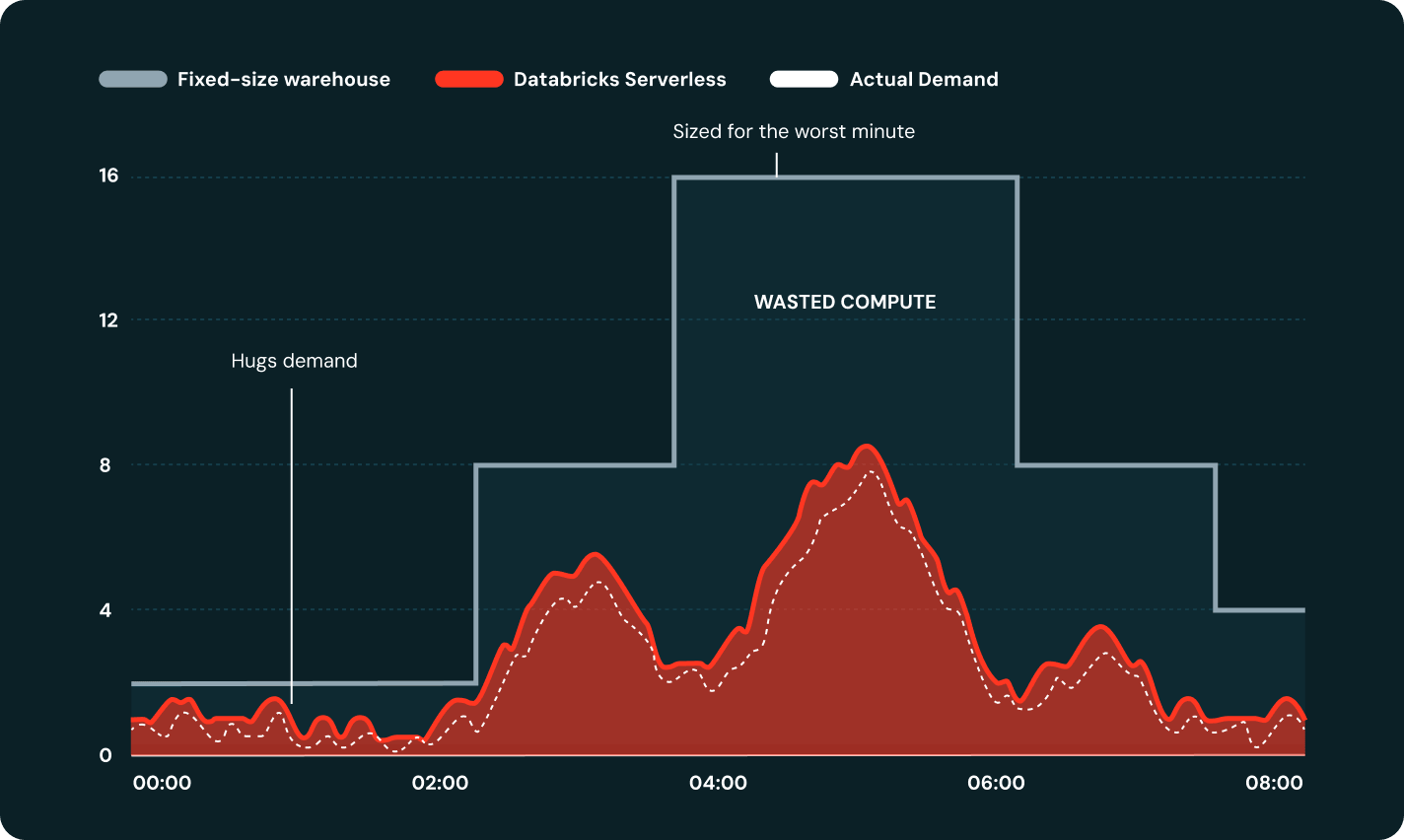
La tecnología serverless escala la capacidad de cómputo en segundos, no en minutos, y la dimensiona automáticamente según la demanda de la carga de trabajo, sin necesidad de configurar clústeres.
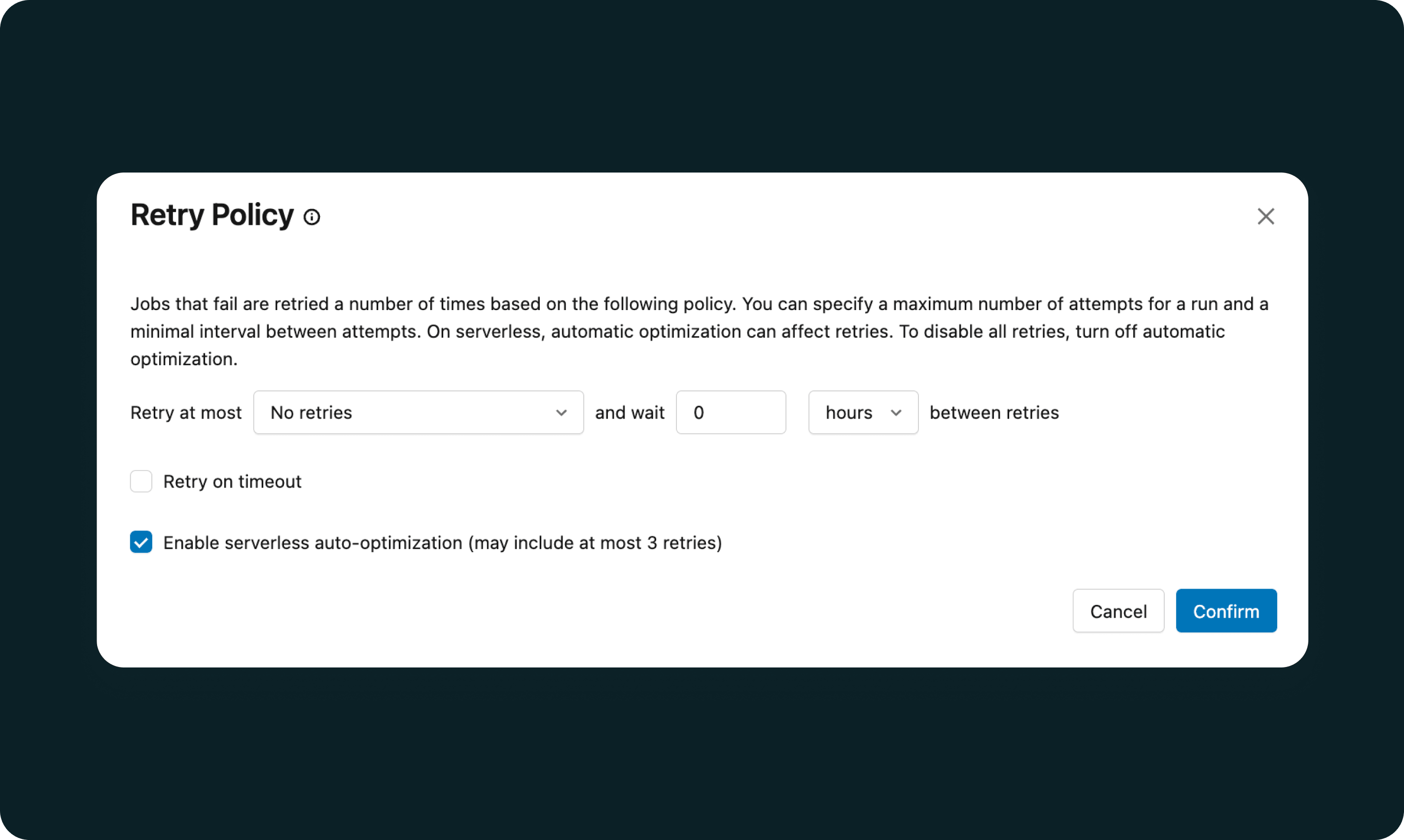
Serverless reintenta automáticamente las tareas fallidas y redirige el flujo para evitar fallas en la nube, lo que mantiene las canalizaciones según lo programado sin intervención de guardia.
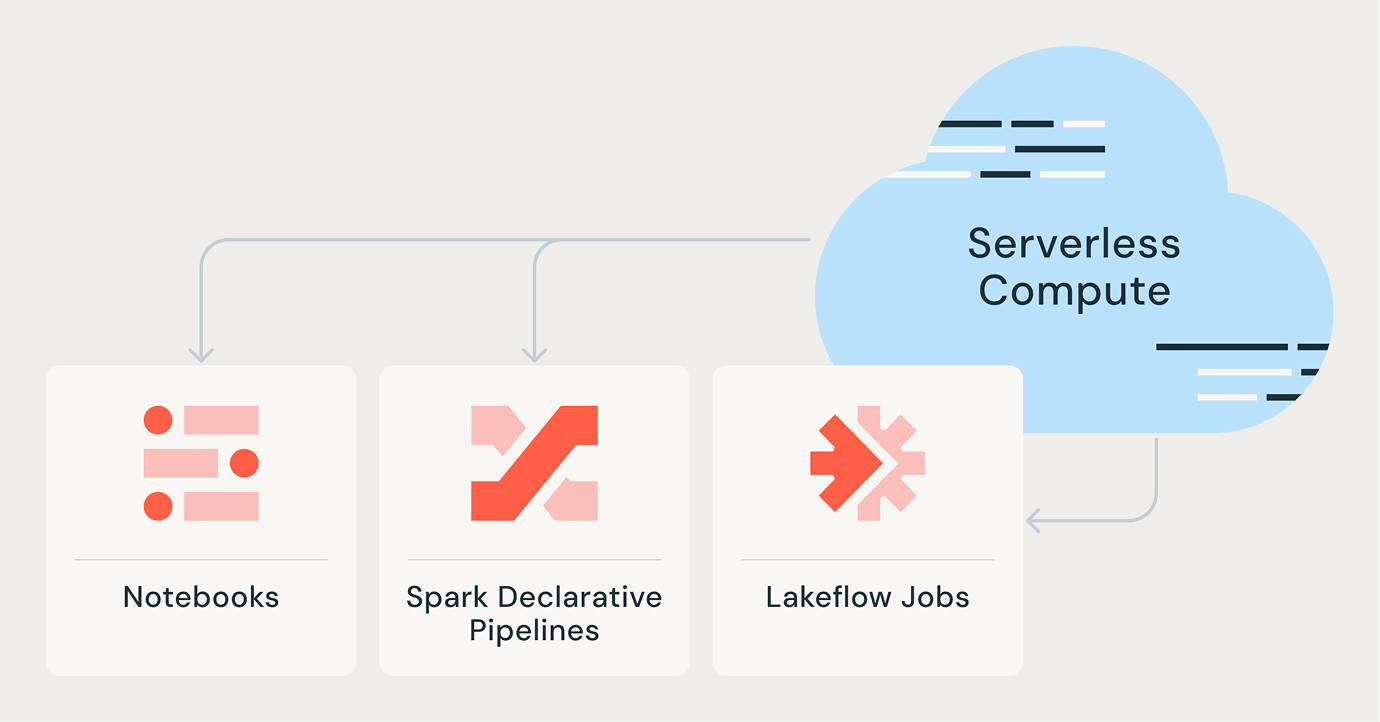
Más características
Sin servidor para toda carga de trabajo

Consulta datos sin administrar el cómputo del almacén
Los almacenes de SQL sin servidor de Databricks se inician en segundos y se escalan automáticamente para satisfacer la demanda, por lo que los analistas siempre tienen la capacidad de computación lista. Sin decisiones de dimensionamiento, sin clústeres inactivos y sin sobrecarga de infraestructura. Solo consultas rápidas y confiables.




Los precios basados en el uso mantienen el gasto bajo control
Paga solo por los productos que usas, con granularidad por segundo.Descubre más
Conoce más sobre los productos impulsados por el cómputo sin servidor
Trabajos de Lakeflow
Dota a tus equipos de herramientas para automatizar y orquestar mejor cualquier flujo de trabajo de ETL, análisis e IA con una profunda observabilidad, alta confiabilidad y amplio soporte de tipos de tareas.

Databricks SQL
Un almacenamiento de datos inteligente y autooptimizado construido con arquitectura de tipo lakehouse, que ofrece la mejor relación precio-rendimiento del mercado.

Pipelines Declarativos de Spark
Simplifica el ETL por lotes y de transmisión con calidad de datos automatizada, captura de datos modificados (CDC), ingesta de datos, transformación y gobernanza unificada.

Documentos interactivos
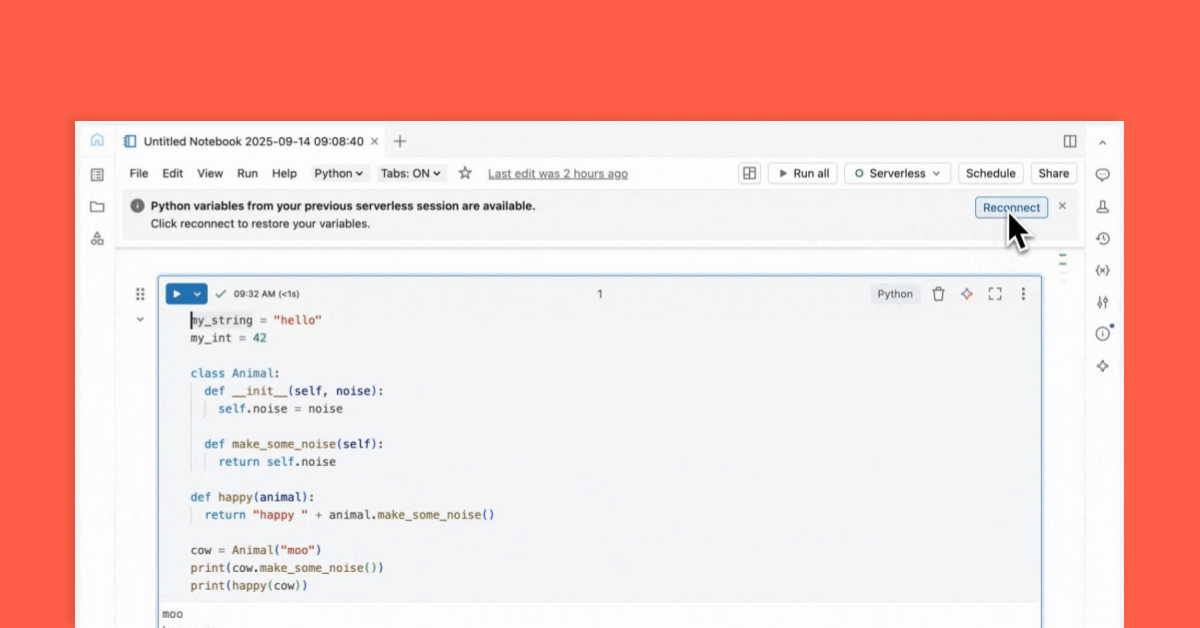
Aumenta la productividad del equipo con Databricks Notebooks, que hace posible la colaboración en tiempo real y optimiza los flujos de trabajo de ciencia de datos.

Aplicaciones de Databricks
Crea aplicaciones utilizando frameworks populares, implementación sin servidor y gobernanza integrada. Ofrece soluciones impactantes a los usuarios sin gestión compleja de infraestructura.

LAKEBASE
Postgres integrado con el lakehouse, diseñado para cargas de trabajo operativas modernas.
Da el siguiente paso
Contenido relacionado
Preguntas frecuentes sobre la computación sin servidor
¿Listo para convertirte en una empresa de datos + IA?
Da los primeros pasos en tu transformación de datos