Novidades na plataforma de AI: agentes para engenharia de ML, nossa plataforma de deep learning e novos recursos para ML em tempo real
Use o Genie Code para acelerar todo o ciclo de vida de ML, o AI Runtime para treinar modelos de deep learning em larga escala e o Feature e Model Serving para impulsionar ML em tempo real em escala.
- Crie sistemas de ML mais rapidamente com o Genie Code, um agente de codificação que ajuda cientistas de dados e engenheiros de ML a desenvolver, avaliar e aprimorar sistemas tradicionais de machine learning.
- Treine e ajuste modelos de AI em GPUs serverless com o AI Runtime, uma plataforma unificada de deep learning otimizada para treinamento e experimentação em GPU de larga escala.
- Impulsione ML em tempo real em escala com novos recursos de Feature Store e Model Serving, incluindo recursos de streaming e serviço de alto QPS para as cargas de trabalho de produção mais exigentes.
Nunca houve um momento tão dinâmico e empolgante para criar seus próprios modelos e sistemas de IA. Da previsão de demanda e detecção de fraudes a buscas, recomendações, personalização e IA multimodal, o machine learning está impulsionando aplicações críticas em todos os setores.
No Data + AI Summit 2026, temos o prazer de anunciar os seguintes novos recursos na Databricks AI Platform:
- Genie Code for ML: O Genie Code agora vem com inteligência aprimorada para engenharia de ML e integrações nativas em todos os componentes da Databricks ML Platform: engenharia de atributos, treinamento, serviço e monitoramento de modelos.
- AI Runtime (Public Preview): um ambiente de treinamento de GPU serverless, que permite deep learning de nível de pesquisa e fine-tuning sem o gerenciamento complexo de infraestrutura.
- Suporte aprimorado para ML em tempo real: incluindo suporte de baixa latência e alto QPS em nossos produtos Feature Store e Model Serving.
Juntos, esses recursos simplificam o caminho da experimentação à produção, permitindo que as organizações criem, implantem e dimensionem aplicações de IA de forma significativamente mais rápida do que nunca.
Vamos dar uma olhada mais de perto nas novidades.
Genie Code para Machine Learning
Hoje, levar um modelo de ML para a produção pode levar meses, com as equipes gastando inúmeras horas em tarefas repetitivas ao longo do ciclo de vida de ML — desde a engenharia de atributos e gerenciamento de experimentos até a avaliação e implantação de modelos. Mas os agentes transformaram a forma como as equipes técnicas e de engenharia operam. Para esse fim, no DAIS deste ano, temos o prazer de anunciar o suporte do Genie Code para todo o ciclo de vida de ML.
A criação e a operação de modelos de ML exigem decisões detalhadas que os agentes de codificação genéricos não conseguem tomar. Posso confiar na atualização e na qualidade deste conjunto de dados como um atributo? Esse atributo causará vazamento de dados futuros no modelo? Esse endpoint de serviço está começando a apresentar desvio (drift)? Acertar os detalhes em ML exige um contexto profundo, e esse contexto só vem de uma integração estreita com a plataforma de dados e ML: seus dados e sua qualidade, linhagem de atributos, histórico de experimentos, infraestrutura de treinamento e desempenho em produção.
É aí que entra o Genie Code:
- Contexto sobre seus dados via Unity Catalog: O Genie Code entende seus dados, a semântica de negócios e o modelo de governança. Por meio de sua integração com o Unity Catalog, ele sabe quais tabelas e atributos são de alta qualidade para ML, como os dados fluem por seus pipelines de ML e quais controles de acesso e políticas devem ser respeitados.
- Contexto sobre a pilha de ML da Databricks: O Genie Code foi desenvolvido para ML na Databricks e se integra profundamente com o Feature Store, Serverless Compute, AI Runtime, Model Serving e Inference Tables. Ele pode otimizar jobs de treinamento, diagnosticar problemas de serviço, avaliar modelos desafiantes e agir em toda a pilha de ML, não apenas gerar código que interage com ela.
- Contexto sobre seu ciclo de vida e fluxos de trabalho de ML: Por meio do MLflow, o Genie Code entende todo o ciclo de vida de ML, desde a engenharia de atributos e experimentação até a implantação, monitoramento, detecção de desvio (drift), retreinamento e operações de produção. Ele não para quando um modelo é implantado; ele ajuda a garantir que as métricas de negócios que o modelo impulsiona, como CTR, conversão ou receita, permaneçam saudáveis na produção.
E assim, com o Genie Code, suas equipes de ML podem avançar mais rápido do que nunca.
O Genie Code lida com a engenharia de atributos da mesma forma que seu engenheiro de ML sênior faria — aprendendo os padrões existentes da sua equipe, reutilizando transformações comprovadas e criando atributos consistentes com o que já está em produção.
O Genie Code não apenas escreve código de ML — ele treina e ajusta modelos de nível de produção. Ele seleciona e configura automaticamente a infraestrutura correta, seja CPU para experimentos leves ou GPU para treinamento distribuído, e registra cada execução de forma nativa no MLflow.
O Genie Code leva os modelos do notebook para a produção em um único fluxo — registrando no Unity Catalog, implantando em um endpoint de serviço e mantendo a governança intacta em cada etapa do caminho.
O Genie Code mudou completamente a minha forma de trabalhar. Eu executo mais de 15 threads paralelas direcionadas a diferentes notebooks e ativos todos os dias, e gerenciar tudo isso em várias abas é uma das maiores fontes de atrito no meu fluxo de trabalho. O Genie Code em página inteira com sessões simultâneas me daria um verdadeiro espaço de trabalho para executar tudo em paralelo sem perder o contexto constantemente.—Moritz Schiek, Consultor de Soluções, Bosch
Com o Genie Code, passamos de dados brutos para um fluxo de trabalho de ML governado e pronto para produção em 90 minutos. Como ele entende de forma única os fluxos de trabalho de ML em produção na Databricks, ele nos ajudou a criar tabelas Delta, explorar os dados, treinar e comparar modelos, registrá-los no MLflow e no Unity Catalog e implantar o modelo campeão em um endpoint de serviço, sobrando tempo para otimizar o resultado de negócios mais importante.—Radu Dragusin, Engenheiro Principal, Data & AI, Danfoss
Para saber mais sobre o Genie Code, comece por aqui!
Apresentando o AI Runtime: uma plataforma de GPU de nível de pesquisa no Lakehouse
As GPUs impulsionam as cargas de trabalho de IA mais avançadas de hoje — desde previsões e recomendações até modelos de fundação multimodais. Mas as equipes de deep learning enfrentam dificuldades para adquirir e gerenciar a infraestrutura de GPU, configurar ambientes de treinamento distribuídos e resolver gargalos de desempenho. Elas preferem focar na modelagem em vez da infraestrutura.
Em março, lançamos uma prévia do AI Runtime e, hoje, temos o prazer de compartilhar, como parte do Data + AI Summit, que o AI Runtime agora suporta treinamento multinó de alto desempenho. Com o AI Runtime, os usuários da Databricks agora têm:
- GPUs NVIDIA sob demanda e serverless: basta configurar seu notebook em 2 a 3 cliques e obter conexão rápida a GPUs Serverless A10 e H100 para iniciar o treinamento — sem a necessidade de cluster. Pague apenas pelas GPUs que usar, sem se preocupar com tempo ocioso, utilização ou compromissos iniciais.
- Ferramentas de orquestração robustas: use todo o poder do pacote de orquestração da Databricks com suporte a Lakeflow Jobs e DABs para cargas de trabalho de GPU de longa execução.
- Treinamento distribuído otimizado: o AIR inclui melhorias de desempenho de GPU distribuída, como RDMA e carregamento de dados de alto desempenho, para obter o desempenho ideal para suas cargas de trabalho de GPU.
- Governança e observabilidade centralizadas: execute, observe e governe cargas de trabalho de GPU exatamente onde seus dados residem, com gerenciamento de experimentos integrado via MLflow, gerenciamento de acesso com o Unity Catalog e depuração assistida pelo Genie Code.
Com esse lançamento, os clientes da Databricks agora podem aproveitar a mesma plataforma de GPU de nível de pesquisa que nossa própria equipe usou para impulsionar o treinamento de modelos de fundação como o DBRX e o KARL. Hoje, o AI Runtime impulsiona cargas de trabalho de fronteira para centenas de clientes da Databricks — ajudando a levar a IA de última geração da pesquisa para aplicações empresariais em produção.
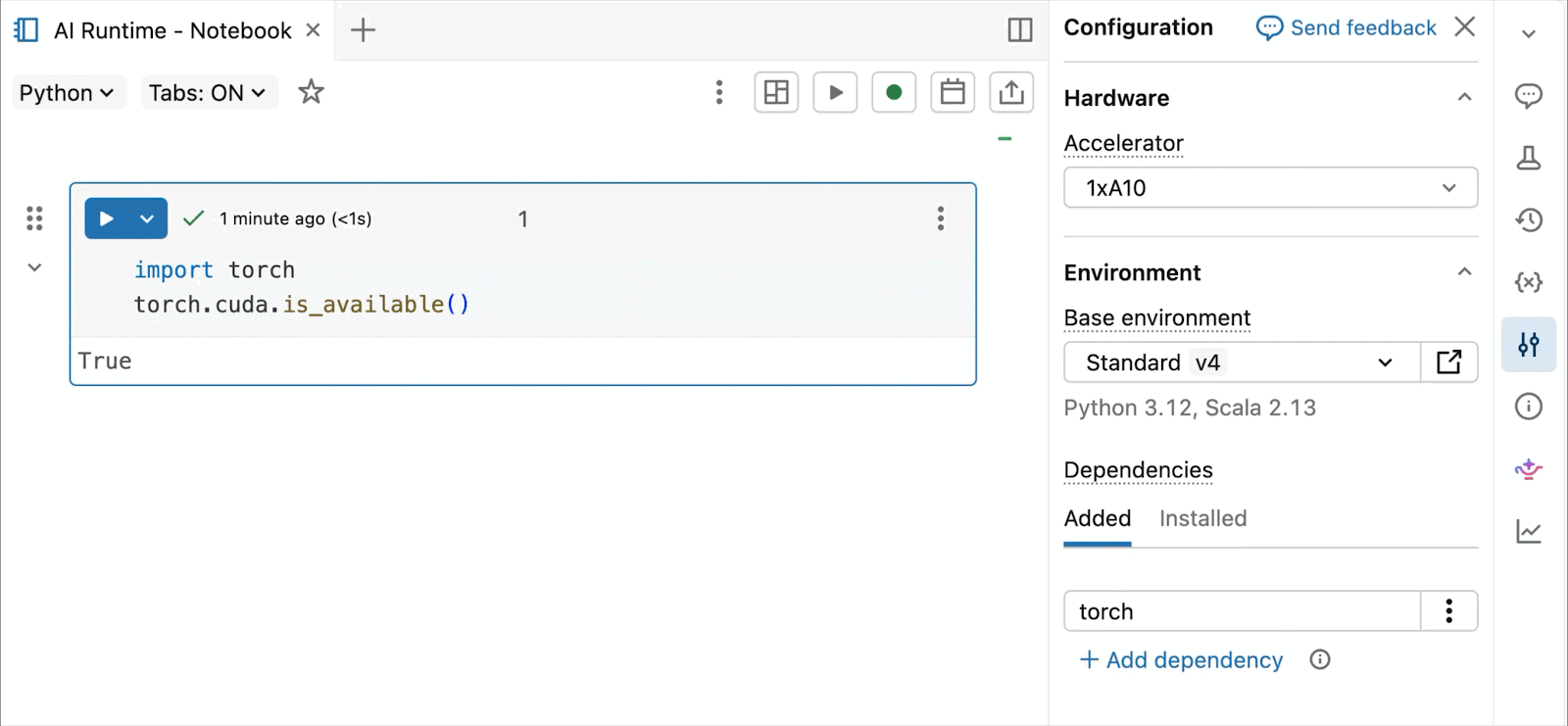
Conecte GPUs Serverless A10 e H100 ao seu notebook em 2 a 3 cliques. Sem necessidade de gerenciamento de cluster; pague apenas pelo que usar.
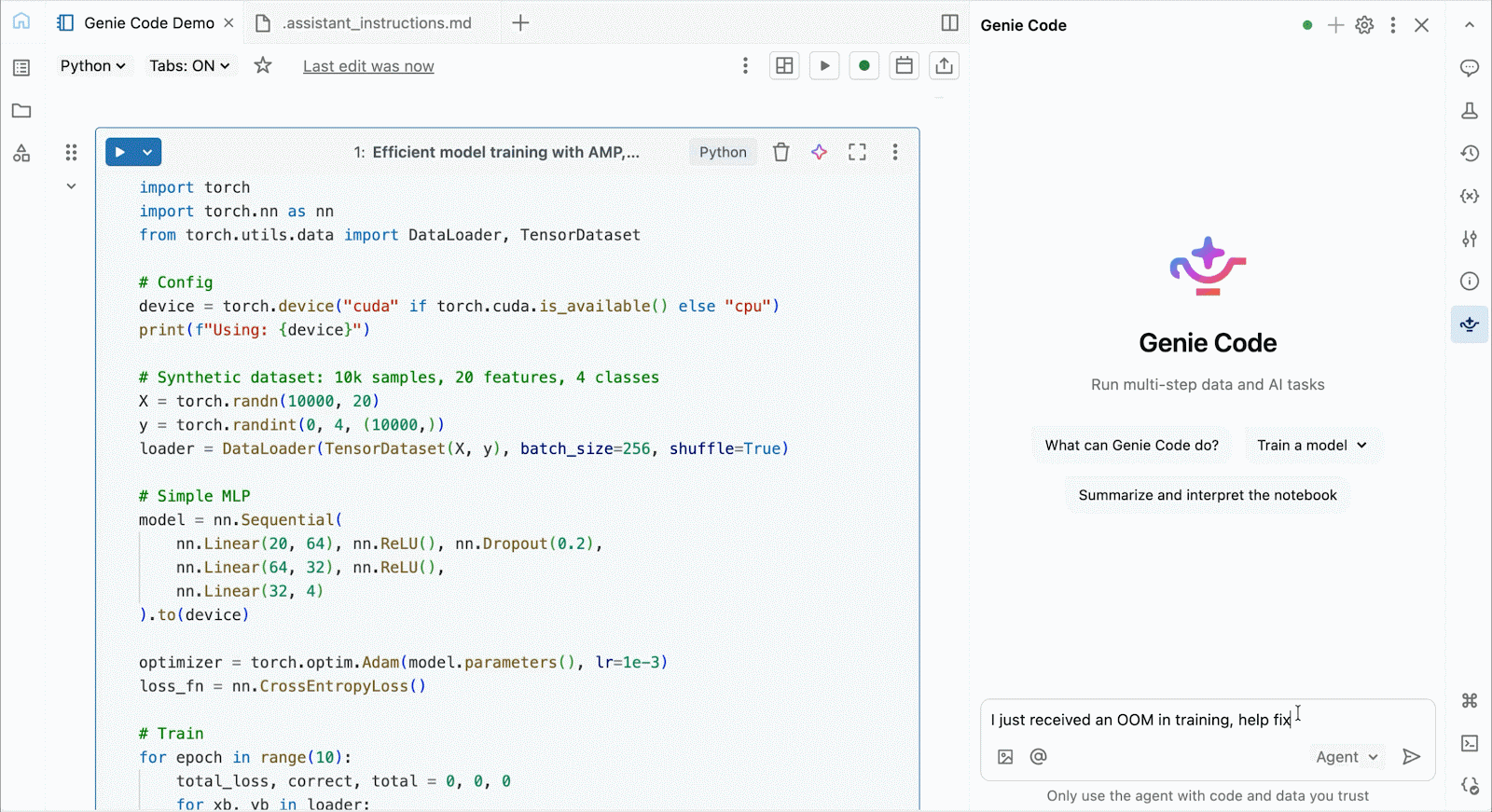
Use o Genie Code para ajudar a resolver gargalos de desempenho, experimentar novas arquiteturas ou depurar bugs complexos relacionados à convergência de modelos ou erros enigmáticos de framework.
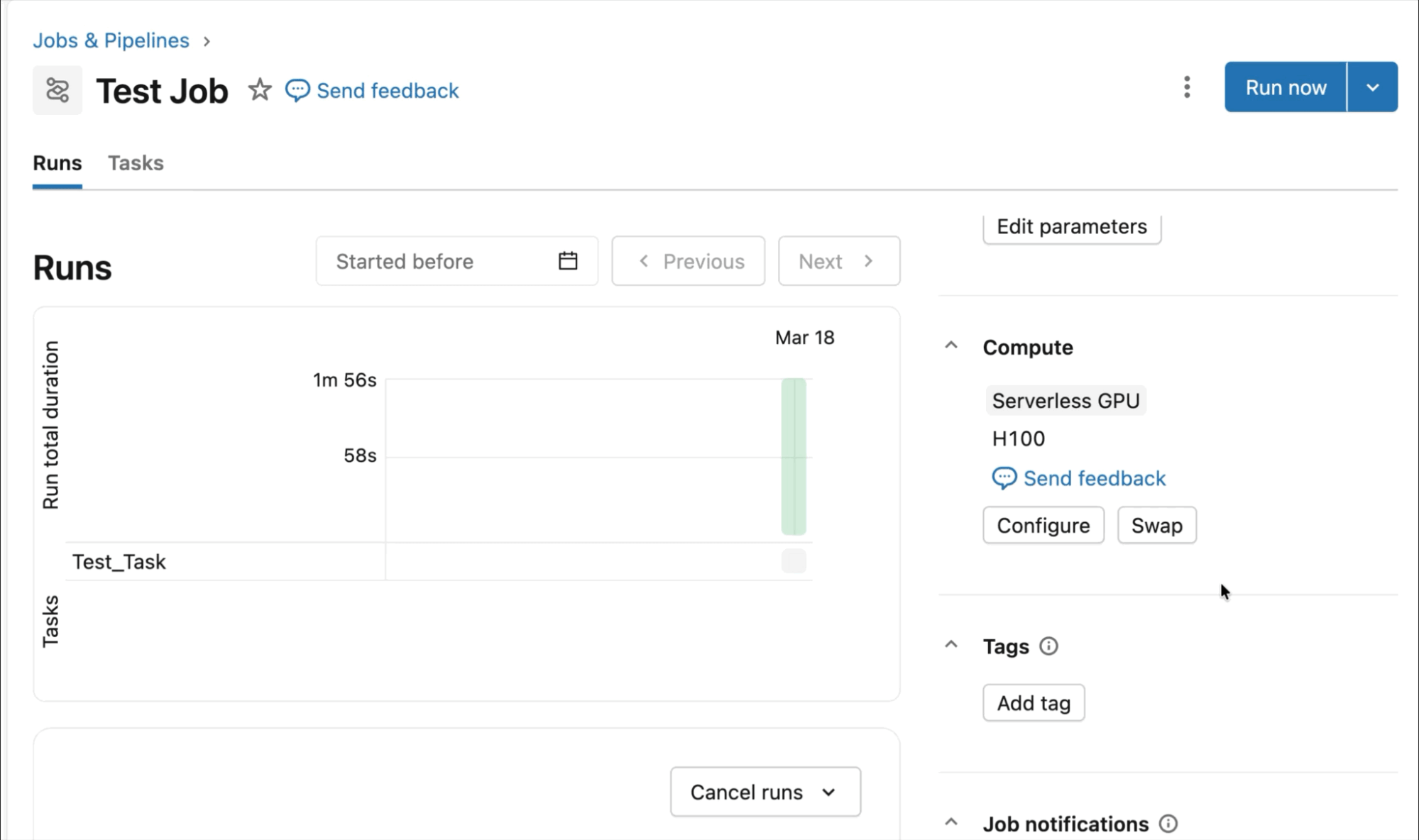
O AI Runtime é uma plataforma de nível de produção para computação acelerada. Desenvolva seu código de deep learning em notebooks interativos e use todo o poder do Lakeflow para enviar e orquestrar jobs em computação de GPU.
O AI Runtime do Databricks simplificou bastante o processo de treinamento de um modelo personalizado de Text To Formula (TTF). Sem configuração de infraestrutura ou atrasos, foi fácil escolher a computação ideal com base no tamanho do prompt e na geração de tokens de saída. Isso nos permitiu agir rapidamente, manter nossos fluxos de trabalho do Lakehouse e entregar um modelo de alta qualidade com governança total, reduzindo o tempo de configuração, treinamento e implantação do nosso modelo de dias para horas.—Nikhil Sunderraj, Engenheiro Principal de Machine Learning, FactSet Research Systems, Inc.
Para começar a treinar seu próximo modelo em GPUs, consulte nossos exemplos e documentação aqui!
ML em tempo real em escala: Feature Store e Model Serving
As aplicações de machine learning mais impactantes operam em tempo real: servindo recomendações em milissegundos, interrompendo transações fraudulentas antes que sejam aprovadas e entregando resultados de busca que parecem instantâneos.
Implantar um modelo em produção é um equilíbrio delicado: cada solicitação precisa ser concluída em poucos milissegundos, mesmo durante picos de tráfego — mas seus custos devem permanecer baixos quando o tráfego estiver calmo. Manter esse equilíbrio em escala historicamente tem sido tão difícil quanto criar o próprio modelo. Sob alto QPS, a infraestrutura de serving se torna o gargalo. A latência se torna imprevisível, os custos aumentam e as equipes sobrecarregam seus melhores engenheiros reajustando contagens de réplicas, limites de simultaneidade e limites de autoscaling toda vez que um modelo ou seu tráfego muda.
No Data + AI Summit, estamos anunciando novos recursos que eliminam essa sobrecarga — e simplificam a obtenção de serving de baixa latência e alto QPS no Databricks:
- Engenharia de features declarativa — Defina features uma vez e materialize-as automaticamente para treinamento e serving.
- Streaming Features — Crie features extremamente atualizadas em seus fluxos de eventos para um ML que reage à atividade do cliente em tempo real.
- Model Serving de alto QPS — Um mecanismo de inferência aprimorado e roteamento de rede para serving de baixa latência em modelos de CPU e GPU, sem necessidade de ajustes manuais. A plataforma se adapta a cada modelo e ao seu tráfego automaticamente, alcançando mais de 300 mil QPS com menos de 10 ms de sobrecarga de latência p99.
- Online Feature Serving no Lakebase — Sirva features atualizadas com acesso de baixa latência para aplicações em produção.
- Genie ZeroOps para ML — O Genie Code pode consultar tabelas de inferência, depurar problemas de desempenho em endpoints de serving e executar análises de causa raiz em alertas, trazendo observabilidade operacional baseada em agentes para modelos em produção.
Os clientes que utilizam o Databricks Model Serving reduziram os custos de infraestrutura em até mais de 90% em comparação com pilhas autogerenciadas, melhoraram a latência p99 e p50 em até 2 vezes e escalaram para além de 100 mil QPS em produção com pouca ou nenhuma manutenção, tudo com confiabilidade e disponibilidade de nível empresarial. Equipes líderes de ML, como Grammarly, GoGuardian, e milhares de outros clientes, contam com o Databricks para servir seus sistemas de ML em tempo real.
Saiba mais no Data + AI Summit 2026!
Para o seu próximo modelo de IA, experimente estes novos recursos! Saiba mais na documentação ou em nossos posts detalhados no blog:
Veja a AI Platform em ação e saiba como organizações líderes estão criando e implantando modelos de IA em escala no Data + AI Summit 2026.
(Esta publicação no blog foi traduzida utilizando ferramentas baseadas em inteligência artificial) Publicação original
Receba os posts mais recentes na sua caixa de entrada
Assine nosso blog e receba os posts mais recentes diretamente na sua caixa de entrada.